
Leerpad
AI-ingenieur voor datawetenschappers
40 Hr
MiniMax M2.7 onderscheidt zich van veel open-weight modellen omdat het is ontworpen voor complexe agentische workflows, waaronder toolgebruik, meerstaps codetaken en productiviteitsgericht redeneren.
Hoewel het in de middenklasse valt en niet in de allerhoogste modelcategorie, is MiniMax M2.7 gepositioneerd om sterke codeer- en redeneerprestaties te leveren met een veel praktischere inzetvoetafdruk.
In deze gids gebruik ik Hyperbolic omdat het de goedkoopste on-demand H200-toegang biedt, snel te provisionen is en een eenvoudige manier om Linux GPU-machines op te starten voor lokaal-achtige model-serving.
Je leert hoe je:
Een Hyperbolic H200 Linux-machine start
llama.cpp installeert voor lokale inferentie
Unsloth’s UD-IQ4_XS GGUF -versie van MiniMax M2.7 downloadt
llama-server draait als een lokaal OpenAI-compatibel API
Het lokale model koppelt aan OpenCode voor agentische codeerworkflows
MiniMax M2.7 zet een meer agent-georiënteerde koers in dan eerdere open modellen, zoals MiniMax M2.5. Wat het onderscheidt is niet alleen de codeer- of redeneercapaciteit, maar vooral dat het is ontworpen om mee te doen aan z’n eigen verbeterproces.
Volgens MiniMax is M2.7 hun eerste model dat diep bijdraagt aan z’n eigen evolutie door te helpen bij het bouwen van complexe agent-harnassen, uitgebreide productiviteitstaken af te handelen en te werken met agent-teams, geavanceerde skills en dynamische toolzoektocht.
Een grote verschuiving met M2.7 is de self-evolution workflow. Tijdens de ontwikkeling werd het model gebruikt om z’n eigen geheugen bij te werken, complexe skills te creëren voor reinforcement learning-experimenten en z’n eigen leerproces te verfijnen op basis van de uitkomsten van die experimenten.
Dit alles maakt dat M2.7 minder aanvoelt als een standaard statisch model en meer als een systeem dat is gebouwd voor iteratieve verbetering.
Bron: MiniMaxAI/MiniMax-M2.7 · Hugging Face
Wat ik het interessantst vind, is dat MiniMax M2.7 neerzet als meer dan zomaar weer een open model. Voor mij wijst het op een duurzamere manier om modellen te verbeteren en te trainen, waarbij geavanceerde systemen een actievere rol kunnen spelen in hun eigen ontwikkeling.
In plaats van alleen te leunen op enorme verse datasets, laat het zien hoe nieuwere trainingsmethoden en zelfverbeteringslussen de modelprestaties verder kunnen stuwen.
Ga naar Hyperbolic, maak een account aan, en voeg minimaal $5 tegoed toe met je kaart. Ga dan naar het tabblad GPUs, klik op Launch Instance en selecteer de H200 SXM5-machine.
Deze gids gebruikt een externe GPU-server, dus voor je de machine start, moet je zeker weten dat je SSH-toegang klaar is. SSH zorgt ervoor dat je veilig vanaf je eigen terminal kunt verbinden met de Linux-machine die op Hyperbolic draait.
Als je SSH al gebruikt en een sleutelpaar hebt ingesteld, kun je door naar het volgende deel. Zo niet, maak er dan eerst een aan.
Open op je lokale machine een terminal en genereer een SSH-sleutel als je er nog geen hebt:
ssh-keygenDruk op Enter wanneer daarom wordt gevraagd om op de standaardlocatie op te slaan. Je kunt ook een wachtzin toevoegen voor extra beveiliging, maar dat is optioneel.
Zodra de sleutel is aangemaakt, print je je publieke sleutel zodat je die kunt kopiëren:
cat ~/.ssh/id_rsa.pubAls je systeem in plaats daarvan het Ed25519-formaat gebruikt, voer dan uit:
cat ~/.ssh/id_ed25519.pubKopieer de volledige output en voeg die toe aan je Hyperbolic-account. Zorg dat je alleen de publieke sleutel uploadt. De private sleutel blijft op je eigen computer en mag nooit worden gedeeld.
Zodra je SSH-sleutel is toegevoegd, ga je naar het Hyperbolic-dashboard, open je het tabblad GPUs en klik je op Launch Instance. Kies in de lijst met beschikbare machines de H200 SXM5-instance voor deze setup.
Geef de instance, voordat je de machine start, een duidelijke en herkenbare naam. Dat maakt het later veel makkelijker terug te vinden, vooral als je meer dan één machine start of er na enige tijd op terugkomt.
Bekijk daarna de instellingen van de instance, bevestig dat je SSH-sleutel is gekoppeld en start de machine. Het platform begint vervolgens met het provisionen van de GPU-server voor jou.
Zodra de machine volledig klaar is, verschijnt deze als actief in het dashboard. Op dat moment zie je ook het SSH-commando dat je nodig hebt om vanaf je lokale terminal te verbinden. Dat commando gebruik je in de volgende stap.
Open nu je lokale terminal en voer het SSH-commando uit met port forwarding vanaf het begin ingeschakeld:
ssh -L 8001:127.0.0.1:8001 root@<H200-Instance-IP>Dit verbindt je lokale machine met de externe Linux-server en forwardt ook poort 8001, zodat je later de llama.cpp-server in je browser kunt openen via http://127.0.0.1:8001.
Als dit de eerste keer is dat je met de server verbindt, vraagt SSH je om de fingerprint te bevestigen. Typ yes en druk op Enter.
Als je een wachtzin hebt ingesteld bij het aanmaken van je SSH-sleutel, zal SSH erom vragen voordat de verbinding wordt voltooid. Typ je wachtzin en druk op Enter. Het gebruik van een wachtzin wordt aanbevolen omdat dit een extra beveiligingslaag aan je private sleutel toevoegt.
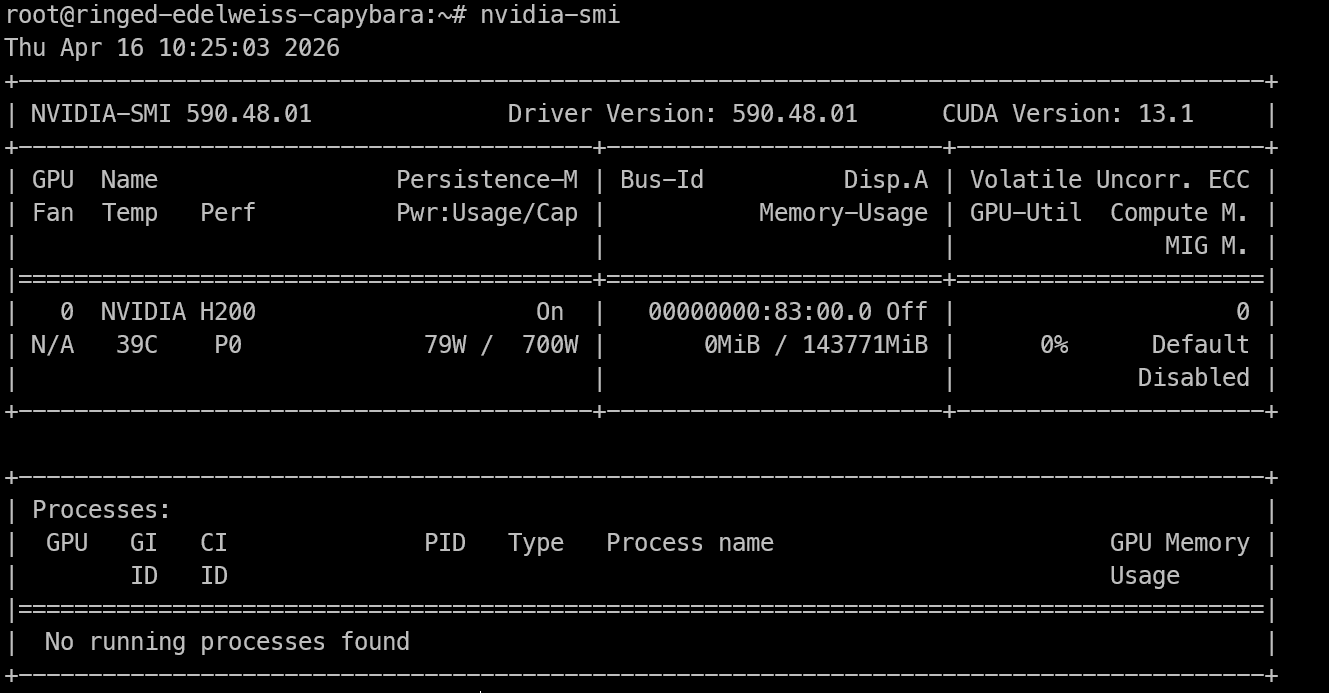
Zodra je remote toegang tot de H200-machine hebt, is het eerste wat je controleert of de GPU zichtbaar is en de NVIDIA-drivers correct werken.
Voer uit:
nvidia-smiDit commando zou de geïnstalleerde NVIDIA GPU, de driverversie, CUDA-versie en het beschikbare geheugen moeten tonen. Als je de H200 hier ziet staan, is de machine klaar voor inferentiewerk.
Installeer nu de systeempakketten die nodig zijn om llama.cpp te bouwen en het model lokaal te draaien.
Voer uit:
apt-get update
apt-get install -y pciutils build-essential cmake git curl wget libcurl4-openssl-dev tmux python3 python3-pipDeze pakketten geven je de tools die je nodig hebt voor de rest van de setup.:
build-essential en cmake zijn vereist om llama.cpp te compileren
git laat je de repository clonen
curl en wget helpen bestanden te downloaden
tmux is handig als je langlopende processen actief wilt houden, ook na het sluiten van de terminal.
Nu de machine klaar is, is de volgende stap het installeren van llama.cpp, waarmee we MiniMax M2.7 lokaal draaien. Dit levert zowel de commandoregeltools om het model te testen als de server die we later als een OpenAI-compatibel API beschikbaar maken.
Begin met het clonen van de officiële llama.cpp-repository op de externe machine:
git clone https://github.com/ggml-org/llama.cppHiermee wordt een nieuwe llama.cpp-map gemaakt in je huidige directory met alle bronbestanden die nodig zijn om het project te bouwen.
Voer vervolgens CMake uit om de build te configureren. In deze setup schakelen we CUDA in zodat llama.cpp de H200-GPU kan gebruiken voor inferentie.
cmake llama.cpp -B llama.cpp/build -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ONDit commando bereidt de buildbestanden voor in de map llama.cpp/build.
Compileer nu de tools die we nodig hebben:
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-cli llama-server llama-gguf-splitDit bouwt drie hoofd-binaries:
llama-cli om het model vanuit de terminal te testen en draaien
llama-server om het model te serven via een lokale API en browserinterface
llama-gguf-split om met gesplitste GGUF-modellbestanden te werken
Kopieer de binaries naar de hoofdmap
Zodra de build is voltooid, kopieer je de gecompileerde binaries naar de hoofdmap van llama.cpp:
cp llama.cpp/build/bin/llama-* llama.cppHierdoor kun je de tools makkelijker uitvoeren zonder elke keer het volledige buildpad te hoeven typen.
Voer tot slot de help-commando’s hieronder uit om zeker te weten dat alles correct is geïnstalleerd:
./llama.cpp/llama-cli --help
./llama.cpp/llama-server --helpAls beide commando’s gebruiksinformatie geven in plaats van een fout, is llama.cpp succesvol geïnstalleerd en ben je klaar om het MiniMax M2.7-model te downloaden.
Installeer voor je het model downloadt de Hugging Face-downloadtools op de externe machine:
pip -q install -U "huggingface_hub[hf_xet]" hf-xet hf_transferDit installeert de hf CLI samen met hf-xet, wat helpt grote bestandsdownloads efficiënter te verwerken.
Maak vervolgens een map voor de modelbestanden en download de UD-IQ4_XS GGUF-versie van MiniMax M2.7.
Voer uit:
mkdir -p /models/minimax-m27
hf download unsloth/MiniMax-M2.7-GGUF \
--local-dir /models/minimax-m27 \
--include "*UD-IQ4_XS*"
Dit maakt een aparte modelmap aan en downloadt alleen de UD-IQ4_XS-bestanden, de 4-bit gequantiseerde versie die in deze gids wordt gebruikt.
De download is groot, ongeveer 108 GB, dus het kan even duren afhankelijk van de netwerksnelheid van je instance.
Controleer zodra de download klaar is of alle GGUF-shards aanwezig zijn door uit te voeren:
find /models/minimax-m27 -name "*.gguf"Je zou vier GGUF-bestanden moeten zien, vergelijkbaar met dit:
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00003-of-00004.gguf
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00002-of-00004.gguf
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00001-of-00004.gguf
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00004-of-00004.ggufAls alle vier de bestanden er zijn, is het model correct gedownload en ben je klaar om in de volgende stap de server te starten.
Het is nu tijd om het model te starten met llama-server. Dit laadt het MiniMax M2.7 GGUF-model, draait het op de GPU en stelt het beschikbaar via een lokale server op poort 8001.
Start voordat je de modelserver lanceert een tmux-sessie, zodat het proces blijft draaien als je SSH-verbinding wegvalt of je het terminalvenster sluit.
Voer uit:
tmux new -s minimaxDit maakt een nieuwe tmux -sessie aan met de naam minimax, die we gebruiken om de server te draaien.
Navigeer nu naar de map llama.cpp en start de server met het modelpad en de inferentie-instellingen:
cd llama.cpp
./llama-server \
--model /models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00001-of-00004.gguf \
--alias "MiniMax-M2.7" \
--host 0.0.0.0 \
--port 8001 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--threads 16 \
--parallel 1 \
--flash-attn on \
--n-gpu-layers 999 \
--temp 1.0 \
--top-p 0.95 \
--top-k 40Dit start de server op poort 8001 en laadt het model. Kijk tijdens het laden naar de logs in de terminal.

Als het model succesvol in het GPU-geheugen laadt, zie je een melding dat de server luistert op het geconfigureerde adres en poort.
Zodra het model volledig geladen is, kun je het laten draaien binnen tmux en loskoppelen van de sessie zonder het te stoppen.
Druk op Ctrl+B, daarna op D. Je keert dan terug naar je normale terminal terwijl de modelserver actief blijft op de achtergrond.
Als je later de logs weer wilt bekijken, koppel je opnieuw aan de sessie met:
tmux attach -t minimaxOpen na het starten van de server een andere terminalsessie en voer uit:
curl http://127.0.0.1:8001/v1/modelsJe zou output moeten zien zoals dit:
{"models":[{"name":"MiniMax-M2.7","model":"MiniMax-M2.7","modified_at":"","size":"","digest":"","type":"model","description":"","tags":[""],"capabilities":["completion"],"parameters":"","details":{"parent_model":"","format":"gguf","family":"","families":[""],"parameter_size":"","quantization_level":""}}],"object":"list","data":[{"id":"MiniMax-M2.7","aliases":["MiniMax-M2.7"],"tags":[],"object":"model","created":1776336809,"owned_by":"llamacpp","meta":{"vocab_type":2,"n_vocab":200064,"n_ctx_train":196608,"n_embd":3072,"n_params":228689764864,"size":108405492736}}]}Als je het MiniMax-M2.7-model ziet staan, draait de server correct.
Omdat je SSH al met port forwarding op 8001 hebt gestart, kun je de llama.cpp WebUI nu direct in je browser openen via http://127.0.0.1:8001.
Dit geeft je directe toegang tot de modelinterface vanuit je lokale browser.
Op dit punt zou het model klaar moeten zijn voor gebruik. Je kunt het testen in de WebUI of via API-verzoeken vanuit de terminal om te controleren of alles correct werkt.
In mijn setup reageerde MiniMax M2.7 extreem snel, met zo’n 120 tokens per seconde. Het voelde eerlijk gezegd als het snelste lokale model dat ik tot nu toe op dit formaat heb gedraaid, zeker gezien hoe responsief het was, zelfs bij langere en technischere prompts.
Zodra het correct reageert, draait MiniMax M2.7 volledig lokaal en is het klaar om aan je codeerworkflow te worden gekoppeld.
Nu de lokale llama.cpp-server draait, is de volgende stap om deze te koppelen aan OpenCode. OpenCode is een terminalgebaseerde codeeragent die custom providers ondersteunt via z’n configbestand. Als je er meer over wilt weten, bekijk dan onze vergelijking OpenCode vs Claude Code.
Voor lokale modellen zoals llama.cpp is de schoonste setup om OpenCode te wijzen naar het lokale OpenAI-compatibele endpoint op http://127.0.0.1:8001/v1.
Installeer OpenCode op de externe machine met:
curl -fsSL https://opencode.ai/install | bash
Laad vervolgens je shell opnieuw en controleer de versie om te bevestigen dat het correct is geïnstalleerd:
source ~/.bashrc
opencode --version1.4.6Maak daarna een opencode.json-bestand aan dat OpenCode vertelt om je lokale llama.cpp-server te gebruiken als een OpenAI-compatibele provider.
cat > opencode.json <<'EOF'
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"llama.cpp": {
"npm": "@ai-sdk/openai-compatible",
"name": "llama-server (local)",
"options": {
"baseURL": "http://127.0.0.1:8001/v1",
"timeout": 600000,
"chunkTimeout": 120000
},
"models": {
"MiniMax-M2.7": {}
}
}
},
"model": "MiniMax-M2.7"
}
EOFDeze config wijst OpenCode naar de lokale server, zet het standaardmodel op MiniMax-M2.7 en gebruikt dezelfde OpenAI-compatibele providerbenadering die OpenCode documenteert voor custom providers. In OpenCode kun je ook modellen selecteren binnen de app met het /models-commando.
Maak nu een eenvoudige projectmap en start OpenCode erin:
mkdir ml-app
cd ml-app/
OpencodeZodra OpenCode opent, typ je /models en selecteer je MiniMax-M2.7 onder je lokale provider.
Zodra het model is geselecteerd, geef je het een echte codeerprompt. Bijvoorbeeld:
Build a simple machine learning API app with FastAPI using just two files: one app.py file for the API and model loading/prediction logic, and one test_app.py file for basic endpoint tests.In de praktijk is dit waar de setup indrukwekkend begint te voelen. Het model begint bijna meteen te werken, maakt een taakplan en begint de bestanden op te zetten. In mijn tests voelde het zeer responsief, wat past bij hoe snel het model al draaide via llama.cpp.
Uiteindelijk kon het de bestanden aanmaken, de tests draaien en de resultaten tonen.
Daarna kun je het verder pushen door het te vragen de ML API-endpoints te testen, de app-structuur te verbeteren of nieuwe features toe te voegen. Omdat OpenCode is gebouwd voor terminalgebaseerde codeerworkflows, is dit het moment waarop de lokale MiniMax-setup begint te voelen als een praktische codeeragent in plaats van alleen een model dat op een server draait.
In mijn geval werkte de lokale ML API-app tegen het einde van de run correct. We draaiden unittests, deden smoke testing en zorgden dat er geen fouten waren tijdens het draaien en testen van de code. In totaal duurde het ongeveer 2 minuten om alles te voltooien, wat laat zien hoe snel dit model aanvoelt in een lokale codeerworkflow.
Ik begon oorspronkelijk met vLLM, maar ik kwam best wat issues tegen, vooral bij het proberen draaien van een 4-bit AWQ-model. Voor dit soort setup vond ik llama.cpp veel makkelijker om mee te werken. De installatie voelde eenvoudiger, de workflow was rechtlijniger en het was veel sneller om alles goed aan de praat te krijgen.
Wat ik ook fijn vond aan llama.cpp is dat het met een ingebouwde WebUI komt, zodat je het model meteen kunt testen in een ChatGPT-achtige interface vanuit je browser. Dat maakt het veel makkelijker om snel prompts te checken, reacties te testen en te zorgen dat het model werkt voordat je het koppelt aan iets als OpenCode.
Voor lokaal gebruik vind ik MiniMax M2.7 een van de beste modellen die ik tot nu toe heb gedraaid. Het is kleiner dan GLM 5.1, voelt sneller aan, begrijpt code goed en presteert sterk in agentische codetaken. Zelfs de 4-bit versie deed het erg goed op complexere taken, waardoor het praktisch aanvoelde voor echt gebruik en niet alleen iets om mee te experimenteren.
De snelheid is een groot deel van waarom deze setup eruit springt. In mijn geval draaide MiniMax M2.7 op ongeveer 120 tokens per seconde met zeer vloeiende generatie, en via SSH port forwarding kon ik het vanuit mijn lokale browser of API gebruiken alsof het op mijn eigen machine draaide. Dat maakte de hele workflow snel, simpel en erg praktisch.
AI-engineeringcursussen
Leerpad
Leerpad
Cursus