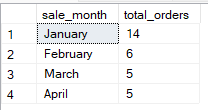

Kursus
Ringkasan Statistik dan Window Functions di PostgreSQL
4 Hr
127.3K
Meskipun pengelompokan berdasarkan satu kolom adalah hal yang umum, mengelompokkan berdasarkan beberapa kolom memungkinkan Anda untuk meringkas dataset besar dengan mengelompokkan baris yang memiliki nilai yang sama, sehingga lebih mudah mengidentifikasi pola, tren, dan outlier.
Dalam panduan ini, saya akan menjelaskan cara kerja klausa GROUP BY, metode pengelompokan lanjutan, dan praktik terbaiknya. Jika Anda baru dalam SQL, pertimbangkan untuk memulai dengan kursus Introduction to SQL atau Intermediate SQL untuk membangun fondasi yang kuat. Selain itu, saya menemukan SQL Basics Cheat Sheet yang dapat Anda unduh sangat membantu sebagai referensi karena berisi semua fungsi SQL yang paling umum.
Sebelum saya menjelaskan cara mengelompokkan berdasarkan beberapa kolom di SQL, mari pahami terlebih dahulu konsep dasar dari klausa GROUP BY.
Klausa GROUP BY dalam SQL mengatur data yang identik ke dalam grup. Klausa ini memindai baris di basis data lalu mengelompokkan baris dengan nilai yang sama pada kolom yang ditentukan, sehingga memungkinkan agregasi data di dalam grup-grup tersebut.
Anda dapat menggunakan klausa GROUP BY bersama fungsi agregat seperti COUNT(), SUM(), AVG(), MIN(), dan MAX() untuk melakukan perhitungan ringkasan pada setiap grup baris.
Misalnya, Anda menganalisis data penjualan dan ingin mengetahui total pendapatan per wilayah. GROUP BY memungkinkan Anda mengelompokkan penjualan berdasarkan wilayah dan menghitung jumlahnya untuk setiap wilayah dalam satu kueri.
Basis data memproses klausa GROUP BY pada satu kolom dengan memindai baris dan membaginya menurut nilai berbeda pada kolom tersebut. Setiap nilai berbeda membentuk satu grup, dan fungsi agregasi menghitung hasil di dalam setiap grup.
Namun, ketika Anda menambahkan beberapa kolom, SQL mengelompokkan data berdasarkan setiap kombinasi unik dari kolom-kolom tersebut. Artinya, basis data membagi data ke dalam grup yang lebih kecil dan lebih terperinci yang ditentukan oleh semua nilai kolom yang ditentukan.
Pendekatan partisi ini memungkinkan agregasi multidimensi. Ini berguna untuk business intelligence dan analitik yang mendalam. Pendekatan ini memungkinkan analisis mendalam dengan meringkas data pada perpotongan beberapa dimensi. Misalnya, Anda dapat mengelompokkan penjualan berdasarkan wilayah dan kategori produk.
Seperti yang Anda lihat, mengelompokkan data berdasarkan beberapa kolom memberi lebih banyak wawasan. Sekarang mari kita lihat bagaimana SQL menangani pengelompokan ini.
Saat Anda mengelompokkan lebih dari satu kolom di SQL, mesin basis data memperlakukan kombinasi kolom sebagai kunci komposit. Setiap kombinasi unik ini membentuk satu grup yang berbeda. Misalnya, mengelompokkan data penjualan berdasarkan region dan product_type menghasilkan grup terpisah untuk setiap pasangan unik, seperti ('West', 'Electronics'), ('East', 'Furniture'), dan seterusnya.
Ini menghasilkan pola subpengelompokan hierarkis, di mana kolom pertama membuat grup utama, kolom kedua membagi lebih lanjut grup utama tersebut menjadi subgrup, dan seterusnya. Pengelompokan berlapis ini meningkatkan tingkat kehalusan data dengan memecah informasi ke dalam kategori yang lebih rinci.
Perlu Anda catat juga bahwa ada perbedaan antara pengelompokan hierarkis dan non-hierarkis. Pengelompokan hierarkis mengikuti pengelompokan kolom dan subpengelompokan kolom dalam urutan tertentu. Di sisi lain, pengelompokan non-hierarkis memperlakukan setiap kolom sebagai dimensi lain, dan tidak mengikuti hierarki yang melekat. Meski begitu, pengelompokan non-hierarkis menciptakan kombinasi yang berguna untuk analisis, seperti saat Anda ingin mengelompokkan penjualan produk berdasarkan musim.
Dalam SQL, urutan Anda mencantumkan kolom dalam klausa GROUP BY sangat penting. Saat Anda mengelompokkan berdasarkan beberapa kolom, SQL memperlakukan kolom-kolom tersebut bersama-sama sebagai kunci gabungan, seperti menyatukan beberapa bagian untuk mengidentifikasi setiap grup secara unik.
SQL memproses kolom dari kiri ke kanan. Artinya, SQL terlebih dahulu mengelompokkan data berdasarkan kolom pertama yang Anda cantumkan, lalu di dalam masing-masing grup itu, SQL akan mengelompokkan lebih lanjut berdasarkan kolom berikutnya, dan seterusnya. Urutan ini dapat memengaruhi seberapa efisien basis data menangani kueri, bagaimana indeks digunakan, dan bagaimana pengelompokan sementara dibangun, terutama saat bekerja dengan dataset besar.
Sebagai contoh, jika Anda ingin mengelompokkan data berdasarkan wilayah dan produk, data terlebih dahulu dikelompokkan berdasarkan wilayah, lalu di dalam setiap wilayah, dikelompokkan berdasarkan produk. Namun jika Anda menukar urutannya menjadi (produk, wilayah), Anda mengubah hierarki pengelompokan, yang dapat menghasilkan hasil dan interpretasi yang berbeda dalam laporan Anda.
Mari kita telaah sintaks dan variasi klausa GROUP BY di SQL untuk memahaminya sepenuhnya.
Untuk menggunakan klausa GROUP BY pada beberapa kolom, Anda harus mencantumkan setiap kolom dalam pernyataan SELECT, dipisahkan dengan koma. Basis data kemudian akan mengelompokkan baris berdasarkan kombinasi unik dari nilai kolom-kolom tersebut.
SELECT column1, column2, AGGREGATE_FUNCTION(column3)
FROM table_name
GROUP BY column1, column2;Selalu pastikan bahwa semua kolom yang digunakan dalam pernyataan SELECT, yang bukan bagian dari fungsi agregat, harus muncul dalam klausa GROUP BY untuk menghindari kesalahan dan memastikan agregasi yang mudah dibaca.
Misalkan Anda memiliki tabel Sales dengan struktur berikut:
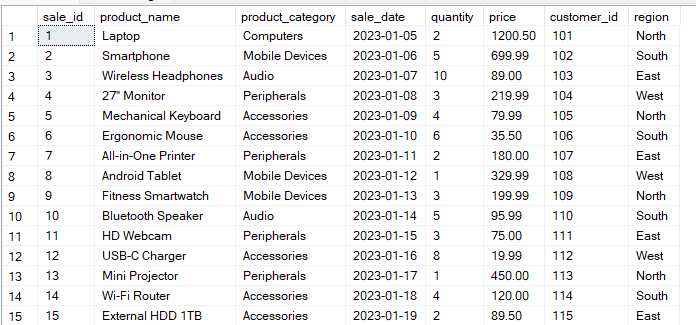
Kueri di bawah ini mengelompokkan data berdasarkan kolom region dan product_category. Kemudian menghitung total_sales untuk setiap kombinasi grup.
-- Group Sales by region and product category
SELECT region, product_category, SUM(quantity) AS total_sales
FROM Sales
GROUP BY region, product_category;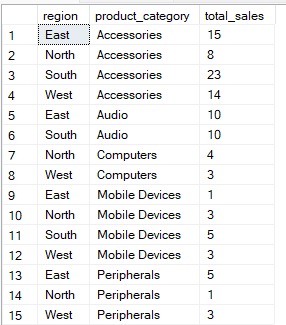
Berikut adalah berbagai metode untuk menggunakan klausa GROUP BY pada beberapa kolom di SQL:
Alih-alih menggunakan nama kolom, SQL memungkinkan Anda menunjukkan posisi kolom dalam klausa GROUP BY. Dari contoh sebelumnya, 1 merujuk ke kolom region dan 2 ke kolom product_category. Metode ini didukung di MySQL dan PostgreSQL, tetapi tidak di SQL Server.
-- Group Sales by region and product category
SELECT region, product_category, SUM(quantity) AS total_sales
FROM Sales
GROUP BY 1, 2;Anda juga dapat mengelompokkan berdasarkan ekspresi turunan atau nilai yang dihitung. Ini berguna untuk mengelompokkan berdasarkan data yang ditransformasi, seperti tahun dari tanggal atau substring. Misalnya, kueri di bawah ini mengelompokkan penjualan berdasarkan bulan yang diturunkan dari sale_date.
-- Group Sales by month derived from date column
SELECT
DATENAME(MONTH, sale_date) AS sale_month,
COUNT(*) AS total_orders
FROM Sales
GROUP BY DATENAME(MONTH, sale_date), MONTH(sale_date)
ORDER BY MONTH(sale_date);
Memilih beberapa kolom tetapi mengelompokkan hanya satu
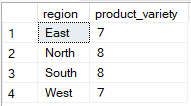
SQL memungkinkan Anda memilih beberapa kolom sambil mengelompokkan hanya satu, tetapi hanya jika kolom tambahan digunakan di dalam fungsi agregat. Pada contoh di bawah, hanya region yang ada dalam klausa GROUP BY, sementara product_id digunakan dalam fungsi agregat (COUNT(DISTINCT)), sehingga kueri valid.
-- Group Sales by region only
SELECT region, COUNT(DISTINCT sale_id) AS product_variety
FROM Sales
GROUP BY region;
Saya merekomendasikan untuk mencoba proyek Analyzing and Formatting PostgreSQL Sales Data untuk memahami cara memanipulasi data di PostgreSQL. Selain itu, MySQL Basics Cheat Sheet akan menjadi panduan referensi yang berguna untuk kueri dasar tabel, memfilter data, dan mengagregasi data, terutama jika Anda lebih suka menggunakan MySQL.
Keunggulan klausa GROUP BY di SQL adalah Anda dapat menggunakannya bersama fungsi agregat untuk mendapatkan ringkasan data yang dikelompokkan.
Fungsi agregat menawarkan wawasan multidimensi di berbagai kombinasi data saat mengelompokkan berdasarkan beberapa kolom. Berikut fungsi yang umum digunakan dengan klausa GROUP BY:
SUM(): Menjumlahkan semua nilai dalam kolom numerik untuk setiap grup.
COUNT(): Menghitung jumlah baris atau nilai non-null di setiap grup.
AVG(): Menghitung nilai rata-rata dalam setiap grup.
MIN(): Menemukan nilai terkecil di setiap grup.
MAX(): Menemukan nilai terbesar di setiap grup.
Sebagai contoh, kueri di bawah ini menghitung total penjualan dan jumlah catatan penjualan untuk setiap kombinasi wilayah dan kategori produk
-- Group by region, product_category then aggregate
SELECT region, product_category, SUM(quantity) AS total_sales, COUNT(*) AS sales_count
FROM Sales
GROUP BY region, product_category;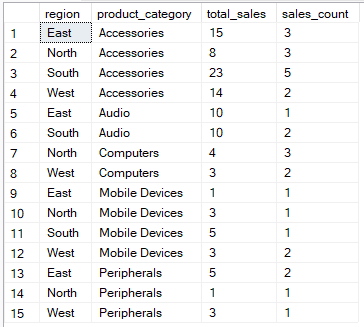
Pada contoh di atas, Anda telah melihat bahwa klausa GROUP BY digunakan bersama fungsi agregat. Namun, Anda dapat menggunakannya tanpa agregasi jika Anda ingin mengelompokkan baris berdasarkan kolom yang ditentukan, tetapi tanpa ringkasan.
Misalnya, kueri di bawah ini menghasilkan pasangan unik dari wilayah dan kategori produk tanpa agregasi. Oleh karena itu, Anda dapat menggunakan metode ini untuk memeriksa konsistensi data.
--Group by multiple columns without aggregate
SELECT region, product_category
FROM Sales
GROUP BY region, product_category;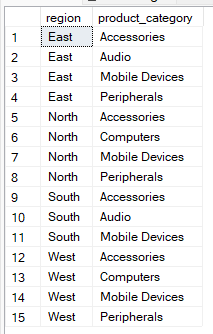
Setelah kita melihat cara mengelompokkan berdasarkan beberapa kolom, mari lihat berbagai operasi pengelompokan lanjutan yang digunakan dengan klausa GROUP BY.
Operasi ROLLUP dibangun di atas klausa GROUP BY standar dengan membuat tingkat ringkasan yang naik (roll up) sepanjang kolom yang ditentukan. Selain menampilkan grup terperinci, operasi ini juga menambahkan subtotal dan total keseluruhan dengan mengagregasi selangkah demi selangkah dari kanan ke kiri melalui kolom yang Anda kelompokkan.
Sebagai contoh, dalam kueri di bawah ini, Anda mendapatkan total_quantity untuk setiap kombinasi region dan product_category. Hasilnya mencakup subtotal untuk setiap wilayah (di mana product_category muncul sebagai NULL) dan total keseluruhan yang menjumlahkan semuanya di seluruh wilayah dan kategori.
-- Group by region, product_category and ROLLUP by region
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY ROLLUP(region, product_category);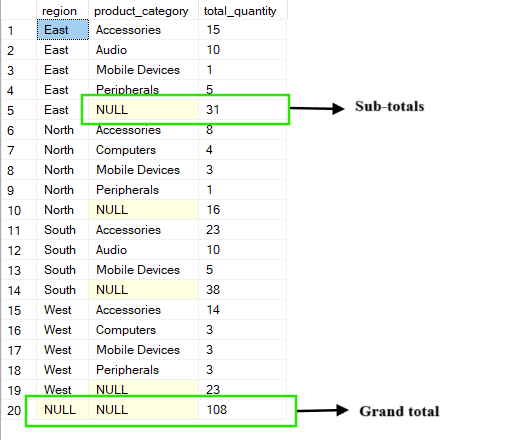
Operasi CUBE menghasilkan semua kombinasi yang mungkin dari kolom pengelompokan. Tidak seperti operasi ROLLUP yang menghasilkan hierarki, CUBE menghasilkan kubus data (data cube) agregasi yang lengkap.
Operasi ini menyediakan tabulasi silang agregasi untuk setiap subset dari kolom yang ditentukan. Output dari operasi CUBE mencakup ringkasan untuk setiap kolom, setiap kombinasi kolom, dan total keseluruhan.
Misalnya, jika kita melakukan kueri pada tabel di atas dan mengelompokkan berdasarkan kolom (region, product_category), operasi CUBE akan menghasilkan kombinasi berikut:
(region, product_category)
(region, NULL)
(NULL, product_category)
(NULL, NULL) yang merupakan total keseluruhan
-- Group by multiple columns using CUBE operation
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY CUBE(region, product_category);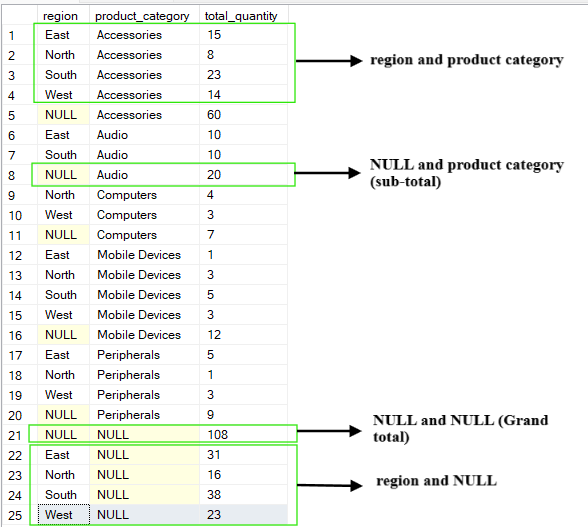
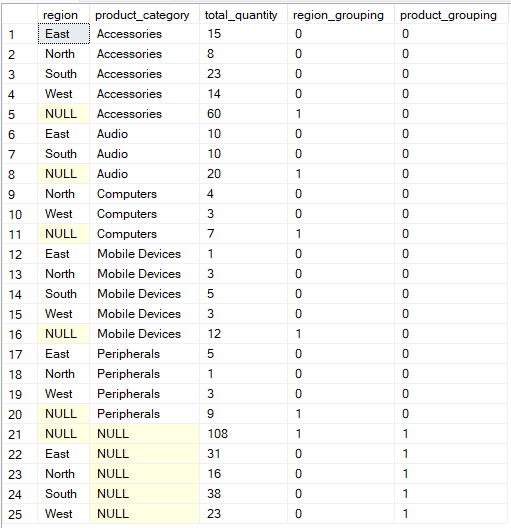
Jika Anda menginginkan kontrol yang lebih fleksibel atas bagaimana data Anda dikelompokkan, maka operasi GROUPING SETS memungkinkan Anda secara eksplisit mendefinisikan beberapa pengelompokan dalam satu kueri.
Dalam hal ini, fungsi GROUPING() menyediakan metadata tentang kolom mana yang diagregasi di setiap baris hasil, mengidentifikasi NULL yang merepresentasikan baris subtotal atau total, bukan data yang benar-benar hilang.
-- Group by multiple columns using GROUPING SETS operation
SELECT region, product_category, SUM(quantity) AS total_quantity,
GROUPING(region) AS region_grouping,
GROUPING(product_category) AS product_grouping
FROM Sales
GROUP BY GROUPING SETS (
(region, product_category),
(region),
(product_category),
()
);
Saat menulis kueri yang mengelompokkan berdasarkan beberapa kolom, penting untuk mengoptimalkannya demi efisiensi yang lebih baik dan kinerja basis data secara keseluruhan. Di bawah ini beberapa tips praktis yang saya gunakan untuk membantu optimasi kueri dan pengelolaan sumber daya
Agar kueri Anda berjalan lancar dan menggunakan sumber daya minimal:
Identifikasi hambatan performa: Kueri GROUP BY bisa melambat saat berhadapan dengan dataset besar karena harus memindai, mengurutkan, dan mengagregasi banyak data. Untuk menghindari masalah ini, selalu lakukan filter lebih awal dengan klausa WHERE dan hindari mengambil data yang tidak Anda butuhkan.
Gunakan pengindeksan secara efektif: Mengindeks kolom mempercepat performa GROUP BY. Membuat indeks komposit pada kolom yang digunakan dalam klausa GROUP BY membantu mesin basis data dengan cepat menemukan dan mengelompokkan baris tanpa pemindaian tabel penuh atau pengurutan yang mahal.
Batasi kolom: Hanya sertakan kolom yang diperlukan untuk pengelompokan dan analisis Anda guna mengurangi kompleksitas dan meningkatkan performa.
Manfaatkan rencana kueri: Jika tersedia, periksa execution plan atau gunakan petunjuk kueri untuk membimbing optimizer basis data ke strategi terbaik.
Memori berperan besar dalam seberapa baik kueri GROUP BY berjalan. Mengurutkan dan mengelompokkan data sering memerlukan penyimpanan data sementara di memori. Jika memori tidak cukup, kinerja akan menurun secara signifikan.
Untuk mengelola sumber daya dengan lebih baik:
Ingat juga bahwa ukuran data Anda sangat memengaruhi performa. Dataset besar dengan banyak kombinasi grup unik menggunakan lebih banyak memori dan daya pemrosesan. Teknik seperti mempartisi tabel besar, membuat tabel ringkasan terlebih dahulu, atau menggunakan materialized view membantu menjaga semuanya tetap terkendali.
Klausa GROUP BY bekerja baik dengan klausa SQL lain, membuat kueri Anda lebih kuat dan fleksibel. Berikutnya, Anda akan melihat contoh praktis cara menggabungkan GROUP BY dengan berbagai klausa SQL untuk meningkatkan analisis Anda.
Klausa WHERE memfilter baris sebelum pengelompokan terjadi. Klausa ini membatasi dataset sehingga hanya baris yang diperlukan yang disertakan dalam proses agregasi. Misalnya, kueri di bawah ini mengelompokkan berdasarkan region and product_category` tetapi hanya menyertakan catatan di mana region adalah ‘North.’
-- Group by multiple columns, filter using WHERE clause
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
WHERE region = 'North'
GROUP BY region, product_category;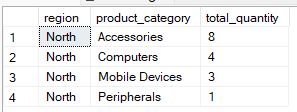
Klausa HAVING, di sisi lain, memfilter setelah agregasi. Klausa ini digunakan untuk membatasi grup mana yang muncul dalam hasil akhir berdasarkan nilai agregat. Kueri di bawah ini mengelompokkan berdasarkan region and product_category tetapi hanya menyertakan catatan di mana total_quantity` lebih dari 5.
-- Group by multiple columns, filter using HAVING clause
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY region, product_category
HAVING SUM(quantity) > 4;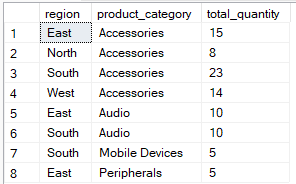
Dalam urutan eksekusi SQL, tKlausa ORDER BY berada setelah klausa GROUP BY dan digunakan untuk mengurutkan hasil yang telah dikelompokkan, sehingga lebih mudah dibaca atau diproses lebih lanjut. Dengan menggunakan indeks yang tepat dan memilih urutan kolom dengan cermat dalam klausa ORDER BY, Anda dapat mempercepat kueri dengan mengurangi pekerjaan yang diperlukan untuk mengurutkan data.
Sebagai contoh, kueri ini mengelompokkan data berdasarkan region dan product_category, lalu mengurutkan hasil sehingga grup dengan total_quantity tertinggi muncul terlebih dahulu.
-- Group by multiple columns, ORDER BY total_quantity
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY region, product_category
ORDER BY total_quantity DESC;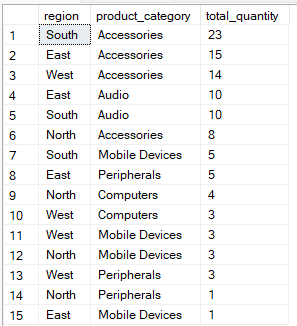
Anda juga dapat menggabungkan operasi JOIN dengan klausa GROUP BY untuk mengelompokkan data di beberapa tabel terkait. Anda harus berhati-hati saat menggunakan metode ini, karena dapat menambah kompleksitas akibat penggabungan data berukuran lebih besar.
-- Retrieve the number of sales per region and product category
SELECT
c.region,
p.product_category,
COUNT(*) AS sales_count
-- Join customer, sales, and product data
FROM customers c
JOIN sales_data s
ON c.customer_id = s.customer_id
JOIN products p
ON s.product_id = p.product_id
-- Group results by region and product category
GROUP BY c.region, p.product_category
-- Order results by region first, then sales count in descending order
ORDER BY c.region, sales_count DESC;Saya menyarankan mengikuti kursus Joining Data in SQL untuk mempelajari berbagai jenis join dan cara menggunakannya dalam kueri bertingkat. Anda dapat mengunduh panduan SQL Joins Cheat Sheet kami sebagai referensi untuk mempelajari lebih lanjut tentang penggabungan data di SQL.
Ekspresi CASE dalam GROUP BY memungkinkan pengelompokan khusus dengan mentransformasikan nilai kolom secara dinamis di dalam proses pengelompokan.
Kueri di bawah ini mengkategorikan produk berdasarkan rentang harga dan menghitung total kuantitas yang terjual per wilayah & kategori produk.
-- Categorize products by price range and count total quantity sold per region & product category
SELECT
region,
product_category,
-- Categorize based on product price
CASE
WHEN price >= 1000 THEN 'High-Priced Products'
WHEN price >= 500 THEN 'Mid-Priced Products'
ELSE 'Low-Priced Products'
END AS price_category,
SUM(quantity) AS total_quantity
FROM Sales
-- Group by region, product category, and price category
GROUP BY
region,
product_category,
CASE
WHEN price >= 1000 THEN 'High-Priced Products'
WHEN price >= 500 THEN 'Mid-Priced Products'
ELSE 'Low-Priced Products'
END
-- Sort results for easier interpretation
ORDER BY
region,
product_category,
total_quantity DESC;
Seiring Anda terus menggunakan klausa GROUP BY untuk mengelompokkan beberapa kolom, Anda akan mengenali pola berulang untuk meningkatkan penggunaannya. Kita akan membahas kejadian umum ini beserta pertimbangan performanya.
Anda mungkin memperhatikan bahwa sebagian besar dataset memiliki hierarki yang melekat, seperti geografi (benua → negara → kota), kategori produk, atau struktur organisasi. Oleh karena itu, klausa GROUP BY ideal untuk meringkas data pada berbagai tingkat hierarki ini.
Saat dihadapkan dengan data bertanggal dan bertimestamp, analisis temporal dapat membantu mengidentifikasi tren, musiman, dan perilaku berbasis waktu dengan mengelompokkan berdasarkan bagian tanggal seperti tahun, kuartal, bulan, atau hari.
Sebelumnya, kita membahas dua jenis pola pengelompokan. Pengelompokan hierarkis melibatkan kolom yang memiliki hubungan bertingkat alami, seperti mengelompokkan terlebih dahulu berdasarkan departemen, lalu di dalam setiap departemen berdasarkan tim. Sebaliknya, pengelompokan non-hierarkis mencampurkan dimensi yang tidak terkait, seperti jenis produk dan metode pembayaran, menampilkan kombinasi tanpa urutan atau struktur yang tersirat.
Saat menggunakan GROUP BY dengan beberapa kolom, Anda dapat meningkatkan performa dengan mengikuti tips praktis berikut:
Batasi kolom pengelompokan: Selalu pastikan Anda mengelompokkan berdasarkan kolom yang diperlukan untuk analisis guna mengurangi beban komputasi grup.
Optimasi indeks: Pastikan kolom yang dikelompokkan diindeks untuk mempercepat performa kueri dengan membantu basis data menangani operasi pengurutan lebih efisien.
Filter sedini mungkin: Gunakan klausa WHERE untuk membatasi dataset Anda sebelum pengelompokan guna mengurangi jumlah data yang diproses.
Gunakan rencana dan petunjuk kueri: Tinjau execution plan atau tambahkan petunjuk kueri jika didukung basis data Anda untuk membantu mengoptimalkan proses pengelompokan.
Manfaatkan fitur SQL lanjutan: Pertimbangkan menggunakan teknik seperti ROLLUP atau GROUPING SETS untuk membuat ringkasan lebih efisien dan menghindari menjalankan kueri berulang, terutama saat bekerja dengan data hierarkis atau multidimensi.
GROUP BY juga bisa menjadi cara yang berguna untuk membersihkan data Anda dengan menghapus duplikasi berdasarkan bidang tertentu. Ini berguna ketika dataset Anda memiliki beberapa baris yang identik atau sebagian duplikat.
Sebagai contoh, untuk menghapus catatan penjualan duplikat, Anda akan mengelompokkan berdasarkan region, product_category, dan product_name, lalu memilih harga tertinggi per grup untuk mempertahankan catatan yang paling relevan.
-- Remove duplicate sales records by keeping only unique combinations
-- of region, product_category, and product_name
SELECT
region,
product_category,
product_name,
MAX(price) AS price,
SUM(quantity) AS total_quantity
FROM Sales
GROUP BY
region,
product_category,
product_name
ORDER BY
region,
product_category,
product_name;Saat bekerja dengan GROUP BY pada beberapa kolom, ingatlah jebakan umum berikut:
Salah satu kesalahan yang paling sering terjadi dalam kueri GROUP BY terkait dengan spesifikasi kolom yang tidak benar. SQL mengharuskan when selecting multiple columns not wrapped dalam fungsi agregat, kolom-kolom tersebut harus disertakan dalam klausa GROUP BY. Jika tidak, akan terjadi kesalahan. Jadi, selalu sertakan kolom non-agregat dalam klausa GROUP BY jika disertakan dalam pernyataan SELECT.
Anda juga mungkin mengalami kesalahan jika data yang Anda kelompokkan memiliki ketidakcocokan, terutama saat Anda mengelompokkan berdasarkan ekspresi. Misalkan Anda mengelompokkan data berdasarkan tanggal yang diformat. Dalam kasus tersebut, Anda akan mendapatkan kesalahan jika nilai tanggal memiliki format atau tingkat presisi yang berbeda, sehingga menghasilkan hasil yang tidak terduga atau tidak benar.
Menggunakan kueri GROUP BY terkadang dapat memperlambat basis data Anda, terutama jika Anda mengelompokkan berdasarkan kolom dengan banyak nilai unik (kardinalitas tinggi) atau jika kolom-kolom tersebut tidak diindeks. Dataset besar juga memerlukan memori yang cukup untuk menangani langkah pengurutan dan pengelompokan, yang menambah beban.
Untuk menghindari masalah ini, selalu indeks kolom dan lakukan filter menggunakan WHERE untuk membatasi data yang Anda kueri.
Selain itu, penting untuk mengetahui bagaimana SQL menangani nilai NULL dalam pengelompokan: semua NULL dalam kolom pengelompokan diperlakukan sebagai satu grup yang sama, berapa pun jumlahnya. Namun, NULL tidak pernah dianggap sama dengan nilai aktual (non-NULL) mana pun, sehingga grup-grup tersebut tetap terpisah.
Menggunakan klausa GROUP BY untuk mengelompokkan beberapa kolom di SQL adalah teknik yang kuat yang memungkinkan analisis yang lebih dalam dan multidimensi dengan mengagregasi data di berbagai kombinasi bidang. Teknik ini memungkinkan analis melampaui ringkasan dasar dan mendapatkan lebih banyak wawasan tentang pola dan hubungan dalam data. Kapabilitas ini penting untuk pelaporan, pelacakan kinerja, dan pengambilan keputusan di lingkungan bisnis modern..
Seiring data tumbuh dalam kompleksitas dan volume, SQL tetap menjadi alat fundamental dalam analitik. Untuk semakin meningkatkan keterampilan Anda, pertimbangkan untuk mengeksplorasi window function, common table expressions (CTE), dan materialized view, yang membuka pintu bagi transformasi data dan alur kerja pelaporan yang lebih canggih.
Saya merekomendasikan mengambil kursus PostgreSQL Summary Stats and Window Functions untuk mempelajari cara menulis kueri untuk analitik bisnis menggunakan Window function seperti seorang profesional. Saya juga menantang Anda untuk mencoba proyek: Analyzing Industry Carbon Emissions dan Analyzing Motorcycle Part Sales untuk menguji keterampilan SQL Anda dan menunjukkan penguasaan Anda dalam menggunakan SQL untuk memecahkan masalah bisnis.
Belajar SQL bersama DataCamp
Kursus
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Javier Canales Luna
14 mnt
