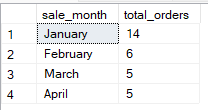

Cours
Statistiques récapitulatives et fonctions de fenêtrage PostgreSQL
4 h
125.4K
Bien que le regroupement par colonne unique soit courant, le regroupement par plusieurs colonnes vous permet de résumer de grands ensembles de données en regroupant les lignes qui partagent des valeurs communes, ce qui facilite l'identification des modèles, des tendances et des valeurs aberrantes.
Dans ce guide, je vais vous expliquer le fonctionnement de la clause « GROUP BY », les méthodes de regroupement avancées et les meilleures pratiques. Si vous débutez avec SQL, nous vous recommandons de commencer par notre cours Introduction à SQL ou notre cours SQL intermédiaire afin d'acquérir des bases solides. De plus, je trouve que l'aide-mémoire SQL Basics Cheat Sheet, que vous pouvez télécharger, est une référence utile car il contient toutes les fonctions SQL les plus courantes.
Avant d'expliquer comment regrouper plusieurs colonnes dans SQL, veuillez comprendre les concepts de base de la clause « GROUP BY ».
La clause « GROUP BY » en SQL organise les données identiques en groupes. Il analyse les lignes d'une base de données, puis regroupe les lignes présentant les mêmes valeurs dans les colonnes spécifiées, ce qui permet d'agréger les données au sein de ces groupes.
Vous pouvez utiliser la clause GROUP BY avec des fonctions d'agrégation telles que COUNT(), SUM(), AVG(), MIN() et MAX() pour effectuer des calculs de synthèse sur chaque groupe de lignes.
Supposons que vous analysiez des données de ventes et que vous souhaitiez connaître le chiffre d'affaires total par région. GROUP BY vous permet de regrouper les ventes par région et de calculer la somme pour chacune d'elles en une seule requête.
La base de données traite la clause d'GROUP BY sur une seule colonne en parcourant les lignes et en les segmentant en fonction des valeurs distinctes de cette colonne. Chaque valeur distincte forme un groupe, et les fonctions d'agrégation calculent les résultats au sein de chaque groupe.
Cependant, lorsque vous introduisez plusieurs colonnes, SQL regroupe les données en fonction de chaque combinaison unique de ces colonnes. Cela signifie que la base de données partitionne les données en groupes plus petits et plus précis, définis par toutes les valeurs de colonne spécifiées.
Cette approche de partitionnement permet une agrégation multidimensionnelle. Ceci est particulièrement utile pour l'intelligence économique et l'analyse approfondie. Il permet une analyse approfondie en résumant les données à l'intersection de plusieurs dimensions. Par exemple, vous pouvez regrouper les ventes par région et par catégorie de produits.
Comme vous avez pu le constater, le regroupement des données par plusieurs colonnes vous permet d'obtenir davantage d'informations. Examinons maintenant comment SQL gère ce regroupement.
Lorsque vous regroupez plusieurs colonnes dans SQL, le moteur de base de données traite la combinaison de colonnes comme des clés composites. Chacune de ces combinaisons uniques forme un groupe distinct. Par exemple, le regroupement des données de vente par region et product_type génère un groupe distinct pour chaque paire unique, comme ('West', 'Electronics'), ('East', 'Furniture'), etc.
Cela conduit à un modèle hiérarchique de sous-groupes, où la première colonne crée les groupes principaux, la deuxième colonne segmente ces groupes principaux en sous-groupes, et ainsi de suite. Ce regroupement par niveaux améliore la granularité des données en divisant les informations en catégories détaillées.
Veuillez également noter qu'il existe une différence entre le regroupement hiérarchique et non hiérarchique. Le regroupement hiérarchique suit le regroupement et le sous-regroupement des colonnes selon une séquence spécifique. D'autre part, le regroupement non hiérarchique considère chaque colonne comme une autre dimension et ne suit pas une hiérarchie inhérente. Néanmoins, le regroupement non hiérarchique permet de créer des combinaisons utiles pour l'analyse, par exemple lorsque vous souhaitez regrouper les ventes de produits par saison.
En SQL, l'ordre dans lequel vous listez les colonnes dans une clause GROUP BY est très important. Lorsque vous regroupez plusieurs colonnes, SQL traite ces colonnes ensemble comme une clé combinée, un peu comme si vous assembliez plusieurs pièces pour identifier chaque groupe de manière unique.
SQL traite les colonnes de gauche à droite. Cela signifie qu'il regroupe d'abord les données en fonction de la première colonne que vous indiquez, puis, au sein de chacun de ces groupes, il les regroupe à nouveau en fonction de la colonne suivante, et ainsi de suite. Cet ordre peut influencer l'efficacité avec laquelle la base de données traite la requête, utilise les index et construit les regroupements intermédiaires, en particulier lorsque vous travaillez avec des ensembles de données volumineux.
Par exemple, si vous souhaitez regrouper vos données par région et par produit, les données sont d'abord regroupées par région, puis, au sein de chaque région, elles sont regroupées par produit. Cependant, si vous inversez l'ordre en (produit, région), vous modifiez la hiérarchie de regroupement, ce qui peut entraîner des résultats et des interprétations différents dans vos rapports.
Examinons la syntaxe et les variantes de la clause « GROUP BY » en SQL afin de bien la comprendre.
Pour utiliser une clause d'GROUP BY dans plusieurs colonnes, vous devez répertorier chaque colonne dans l'instruction SELECT, séparées par des virgules. La base de données regroupera ensuite les lignes en fonction des combinaisons uniques de ces valeurs de colonne.
SELECT column1, column2, AGGREGATE_FUNCTION(column3)
FROM table_name
GROUP BY column1, column2;Veuillez toujours vous assurer que toutes les colonnes utilisées dans l'instruction ` SELECT `, qui ne font pas partie des fonctions d'agrégation, apparaissent dans la clause ` GROUP BY ` afin d'éviter les erreurs et de garantir la lisibilité de l'agrégation.
Supposons que vous disposiez d'un tableau « Sales » avec la structure suivante :
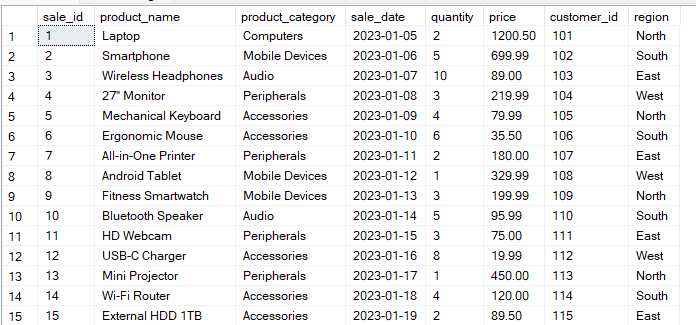
La requête ci-dessous regroupe les données par colonnes « region » et « product_category ». Il calcule ensuite l'total_sales e pour chaque combinaison de groupes.
-- Group Sales by region and product category
SELECT region, product_category, SUM(quantity) AS total_sales
FROM Sales
GROUP BY region, product_category;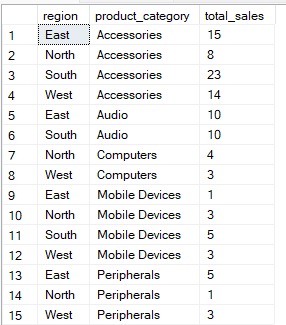
Vous trouverez ci-dessous les différentes méthodes permettant d'utiliser la clause « GROUP BY » sur plusieurs colonnes dans SQL :
Au lieu d'utiliser des noms de colonnes, SQL vous permet d'indiquer la position des colonnes dans la clause d'GROUP BY. Dans notre exemple précédent, 1 fait référence à la colonne region et 2 à la colonne product_category. Cette méthode est prise en charge dans MySQL et PostgreSQL, mais pas dans SQL Server.
-- Group Sales by region and product category
SELECT region, product_category, SUM(quantity) AS total_sales
FROM Sales
GROUP BY 1, 2;Vous pouvez également regrouper par expressions dérivées ou valeurs calculées. Ceci est utile pour regrouper des données transformées, telles que l'année à partir d'une date ou des sous-chaînes. Par exemple, la requête ci-dessous regroupe les ventes par mois à partir de sale_date.
-- Group Sales by month derived from date column
SELECT
DATENAME(MONTH, sale_date) AS sale_month,
COUNT(*) AS total_orders
FROM Sales
GROUP BY DATENAME(MONTH, sale_date), MONTH(sale_date)
ORDER BY MONTH(sale_date);
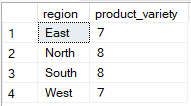
Sélectionner plusieurs colonnes mais regrouper selon une seule
SQL vous permet de sélectionner plusieurs colonnes tout en les regroupant par une seule, mais uniquement si les colonnes supplémentaires sont utilisées dans des fonctions d'agrégation. Dans l'exemple ci-dessous, seul region figure dans la clause GROUP BY, tandis que product_id est utilisé dans une fonction d'agrégation (COUNT(DISTINCT)), ce qui rend la requête valide.
-- Group Sales by region only
SELECT region, COUNT(DISTINCT sale_id) AS product_variety
FROM Sales
GROUP BY region;
Je vous recommande d'essayer notre projet Analyse et formatage des données de ventes PostgreSQL pour comprendre comment manipuler les données dans PostgreSQL. De plus, le fiche de référence MySQL Basics sera un guide de référence pratique pour les requêtes de base dans les tableaux, le filtrage et l'agrégation des données, en particulier si vous préférez utiliser MySQL.
L'avantage de la clause GROUP BY en SQL est qu'elle peut être utilisée avec des fonctions d'agrégation pour obtenir un résumé des données regroupées.
Les fonctions d'agrégation offrent des informations multidimensionnelles sur diverses combinaisons de données lors du regroupement par plusieurs colonnes. Voici les fonctions couramment utilisées avec la clause GROUP BY:
SUM(): Additionne toutes les valeurs d'une colonne numérique pour chaque groupe.
COUNT(): Compte le nombre de lignes ou de valeurs non nulles dans chaque groupe.
AVG(): Calcule la valeur moyenne au sein de chaque groupe.
MIN(): Recherche la plus petite valeur dans chaque groupe.
MAX(): Recherche la valeur la plus élevée dans chaque groupe.
Par exemple, la requête ci-dessous calcule le total des ventes et le nombre d'enregistrements de ventes pour chaque combinaison de région et de catégorie de produit.
-- Group by region, product_category then aggregate
SELECT region, product_category, SUM(quantity) AS total_sales, COUNT(*) AS sales_count
FROM Sales
GROUP BY region, product_category;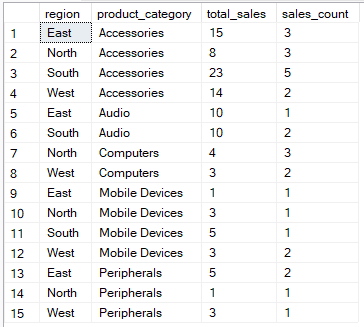
GROUP BY Dans les exemples ci-dessus, vous avez observé que la clause d'agrégation est utilisée avec les fonctions d'agrégation. fonctions d'agrégation. Cependant, vous pouvez l'utiliser sans agrégation si vous souhaitez regrouper les lignes selon les colonnes spécifiées, mais sans le résumé.
Par exemple, la requête ci-dessous affiche des paires uniques de région et de catégorie de produit sans agrégation. Par conséquent, vous pouvez utiliser cette méthode pour vérifier la cohérence des données.
--Group by multiple columns without aggregate
SELECT region, product_category
FROM Sales
GROUP BY region, product_category;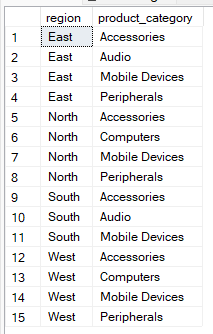
Maintenant que nous avons examiné comment regrouper des données selon plusieurs colonnes, examinons les différentes opérations de regroupement avancées utilisées avec la clause GROUP BY.
L'opération ROLLUP s'appuie sur la clause standard d'GROUP BY en créant des niveaux de synthèse qui s'agrégent le long des colonnes spécifiées. En plus d'afficher des groupes détaillés, il ajoute également des sous-totaux et un total général en effectuant une agrégation étape par étape, de droite à gauche, dans les colonnes que vous regroupez.
Par exemple, dans la requête ci-dessous, vous obtenez l'total_quantity pour chaque combinaison de region et product_category.. Les résultats incluent des sous-totaux pour chaque région (où product_category apparaît sous la forme NULL) et un total général qui additionne tous les éléments de toutes les régions et catégories.
-- Group by region, product_category and ROLLUP by region
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY ROLLUP(region, product_category);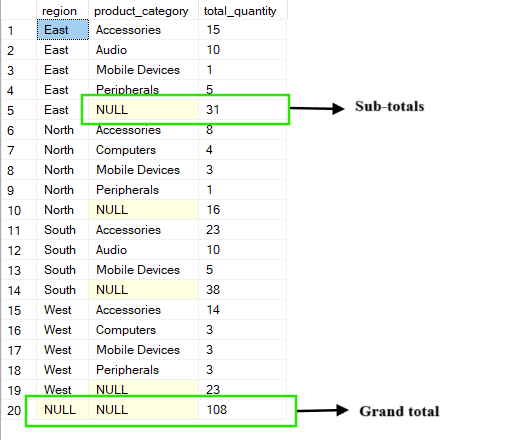
L'opération CUBE génère toutes les combinaisons possibles des colonnes de regroupement. Contrairement à l'opération d'ROLLUP, qui produit une hiérarchie, l'opération d'CUBE produit un cube de données complet d'agrégations.
Il fournit un tableau croisé des agrégations pour chaque sous-ensemble des colonnes spécifiées. Le résultat de l'opération d'CUBE ion comprend des résumés pour chaque colonne, chaque combinaison de colonnes et le total général.
Par exemple, si nous interrogeons le tableau ci-dessus et regroupons les colonnes (region, product_category), l'opération d'CUBE produira les combinaisons suivantes :
(region, product_category)
(region, NULL)
(NULL, product_category)
(NULL, NULL), ce qui correspond au total général.
-- Group by multiple columns using CUBE operation
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY CUBE(region, product_category);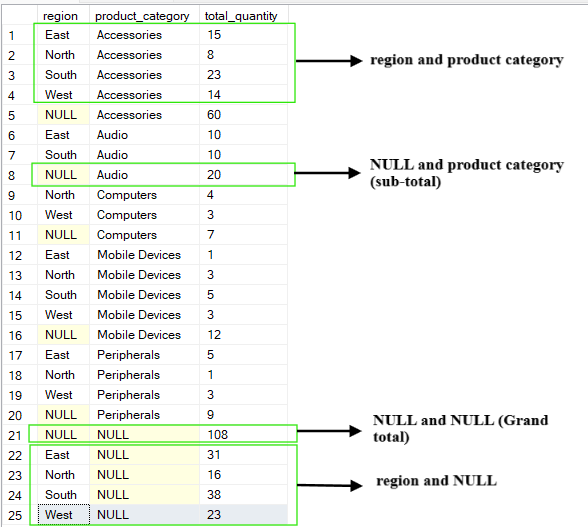
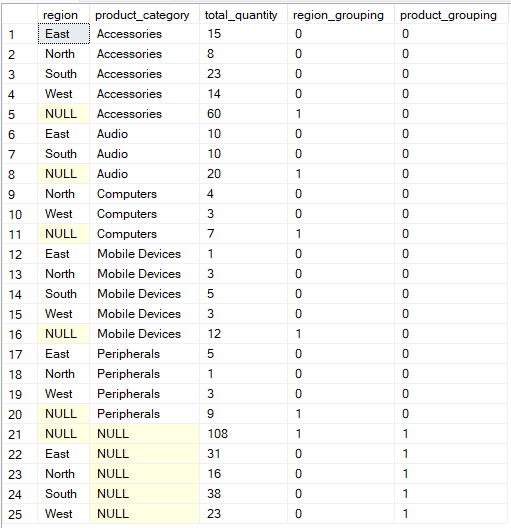
Si vous souhaitez contrôler plus précisément la manière dont vos données sont regroupées, l'opération « GROUPING SETS » vous permet de définir explicitement plusieurs regroupements dans une seule requête.
Dans ce cas, la fonction ` GROUPING() ` fournit des métadonnées sur les colonnes agrégées dans chaque ligne du résultat, en identifiant les valeurs NULL qui représentent des lignes de sous-total ou de total plutôt que des données manquantes réelles.
-- Group by multiple columns using GROUPING SETS operation
SELECT region, product_category, SUM(quantity) AS total_quantity,
GROUPING(region) AS region_grouping,
GROUPING(product_category) AS product_grouping
FROM Sales
GROUP BY GROUPING SETS (
(region, product_category),
(region),
(product_category),
()
);
Lors de la rédaction de requêtes qui regroupent plusieurs colonnes, il est important de les optimiser pour améliorer leur efficacité et les performances globales de la base de données. Voici quelques conseils pratiques que j'ai utilisés pour optimiser les requêtes et gérer les ressources.
Pour garantir le bon déroulement de vos requêtes et utiliser un minimum de ressources :
Identifiez les goulots d'étranglement en matière de performances : les requêtes d' GROUP BY s peuvent ralentir lors du traitement de grands ensembles de données en raison de l'analyse, du tri et de l'agrégation d'un grand nombre de données. Pour éviter ce problème, veuillez toujours filtrer dès le début à l'aide d'une clause « WHERE » et éviter de récupérer des données dont vous n'avez pas besoin.
Utilisez efficacement l'indexation : L'indexation des colonnes accélère les performances de l'GROUP BY. La création d'index composites sur les colonnes utilisées dans la clause d'GROUP BY permet au moteur de base de données de localiser et de regrouper rapidement les lignes sans avoir à effectuer de coûteuses analyses ou tris complets des tableaux.
Limiter les colonnes : N'incluez que les colonnes nécessaires à votre regroupement et à votre analyse afin de réduire la complexité et d'améliorer les performances.
Optimisez les plans de requête : Si possible, veuillez vérifier les plans d'exécution ou utiliser des conseils de requête pour guider l'optimiseur de base de données vers les meilleures stratégies.
La mémoire joue un rôle important dans les performances des requêtes d'GROUP BY. Le tri et le regroupement des données nécessitent souvent de conserver des données intermédiaires en mémoire. Si la mémoire est insuffisante, le système ralentit considérablement.
Pour mieux gérer les ressources :
N'oubliez pas non plus que la taille de vos données a un impact considérable sur les performances. Les ensembles de données volumineux comportant de nombreuses combinaisons de groupes uniques nécessitent davantage de mémoire et de puissance de traitement. Des techniques telles que le partitionnement de grands tableaux, la création préalable de tableaux récapitulatifs ou l'utilisation de vues matérialisées permettent de garder les données gérables.
La clause « GROUP BY » fonctionne bien avec d'autres clauses SQL, ce qui rend vos requêtes plus puissantes et plus flexibles. Ensuite, vous découvrirez des exemples pratiques illustrant comment associer GROUP BY à différentes clauses SQL afin d'améliorer votre analyse.
La clause WHERE filtre les lignes avant que le regroupement ne se produise. Il limite l'ensemble de données afin que seules les lignes requises soient incluses dans le processus d'agrégation. Par exemple, la requête ci-dessous regroupe les enregistrements par region and product_category`, mais inclut les enregistrements dont la région est « North ».
-- Group by multiple columns, filter using WHERE clause
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
WHERE region = 'North'
GROUP BY region, product_category;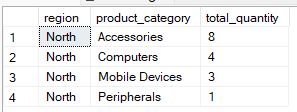
Les HAVING, quant à elle, effectue le filtrage après l'agrégation. Il est utilisé pour limiter les groupes qui apparaissent dans le résultat final en fonction des valeurs agrégées. La requête ci-dessous regroupe les produits dont le code produit ( region and ) et la quantité totale ( but includes records where the ) sont supérieurs à 5.
-- Group by multiple columns, filter using HAVING clause
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY region, product_category
HAVING SUM(quantity) > 4;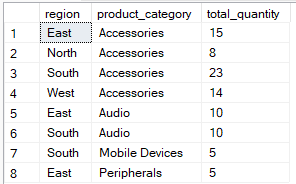
Dans l'ordre d'exécution SQL, tla clause « ORDER BY » suit la clause « GROUP BY » et sert à trier les résultats regroupés, ce qui facilite leur lecture ou leur traitement ultérieur. En utilisant les index appropriés et en choisissant soigneusement l'ordre des colonnes dans la clause ORDER BY, vous pouvez accélérer votre requête en réduisant le travail nécessaire au tri des données.
Par exemple, cette requête regroupe les données par region et product_category, puis trie les résultats de manière à ce que les groupes ayant la plus grande total_quantity apparaissent en premier.
-- Group by multiple columns, ORDER BY total_quantity
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY region, product_category
ORDER BY total_quantity DESC;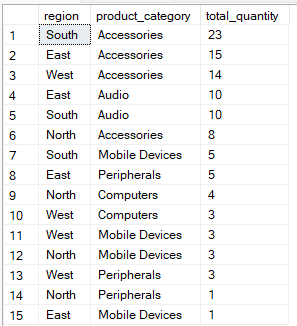
Vous pouvez également combiner les opérations d'JOIN avec la clause GROUP BY pour regrouper les données de plusieurs tableaux associés. Veuillez faire preuve de prudence lorsque vous utilisez cette méthode, car elle peut introduire une certaine complexité en raison de la jonction de données volumineuses.
-- Retrieve the number of sales per region and product category
SELECT
c.region,
p.product_category,
COUNT(*) AS sales_count
-- Join customer, sales, and product data
FROM customers c
JOIN sales_data s
ON c.customer_id = s.customer_id
JOIN products p
ON s.product_id = p.product_id
-- Group results by region and product category
GROUP BY c.region, p.product_category
-- Order results by region first, then sales count in descending order
ORDER BY c.region, sales_count DESC;Je vous recommande de suivre notre cours Joindre des données dans SQL pour découvrir les différents types de jointures et leur utilisation dans les requêtes imbriquées. Vous pouvez télécharger notre guide pratique des jointures SQL pour en savoir plus sur la jointure de données dans SQL.
L'expression d'CASE s dans GROUP BY permet de créer des regroupements personnalisés en transformant dynamiquement les valeurs des colonnes au cours du processus de regroupement.
La requête ci-dessous classe les produits par gamme de prix et indique le nombre total d'unités vendues par région et par catégorie de produit.
-- Categorize products by price range and count total quantity sold per region & product category
SELECT
region,
product_category,
-- Categorize based on product price
CASE
WHEN price >= 1000 THEN 'High-Priced Products'
WHEN price >= 500 THEN 'Mid-Priced Products'
ELSE 'Low-Priced Products'
END AS price_category,
SUM(quantity) AS total_quantity
FROM Sales
-- Group by region, product category, and price category
GROUP BY
region,
product_category,
CASE
WHEN price >= 1000 THEN 'High-Priced Products'
WHEN price >= 500 THEN 'Mid-Priced Products'
ELSE 'Low-Priced Products'
END
-- Sort results for easier interpretation
ORDER BY
region,
product_category,
total_quantity DESC;
À mesure que vous continuerez à utiliser la clause GROUP BY pour regrouper plusieurs colonnes, vous identifierez les modèles récurrents qui vous permettront d'améliorer votre utilisation. Nous aborderons ces situations courantes en tenant compte des considérations relatives aux performances.
Vous avez peut-être remarqué que la plupart des ensembles de données présentent des hiérarchies inhérentes, telles que la géographie (continent → pays → ville), les catégories de produits ou les structures organisationnelles. Par conséquent, la clause « GROUP BY » est idéale pour résumer des données à différents niveaux de ces hiérarchies.
Lorsque vous disposez de données comportant des dates et des horodatages, l'analyse temporelle peut vous aider à identifier les tendances, la saisonnalité et les comportements basés sur le temps en regroupant les données par éléments de date tels que l'année, le trimestre, le mois ou le jour.
Précédemment, nous avons abordé deux types de modèles de regroupement. Les regroupements hiérarchiques impliquent des colonnes qui ont une relation naturelle et imbriquée, comme le regroupement d'abord par service, puis au sein de chaque service par équipe. En revanche, les regroupements non hiérarchiques mélangent des dimensions sans rapport entre elles, telles que le type de produit et le mode de paiement, et présentent des combinaisons sans ordre ni structure implicite.
Lorsque vous utilisez l'GROUP BY avec plusieurs colonnes, vous pouvez améliorer les performances en suivant ces conseils pratiques :
Limiter le regroupement des colonnes : Veuillez toujours vous assurer de regrouper les colonnes nécessaires à l'analyse afin de réduire la charge de calcul des groupes.
Optimisation de l'indexation : Veuillez vous assurer que les colonnes regroupées sont indexées afin d'accélérer les performances des requêtes en aidant la base de données à gérer plus efficacement les opérations de tri.
Filtrez dès le début : Utilisez la clause « WHERE » pour limiter votre ensemble de données avant le regroupement afin de réduire la quantité de données traitées.
Utilisez des plans de requête et des astuces : Veuillez examiner les plans d'exécution ou ajouter des indications de requête si votre base de données les prend en charge afin d'optimiser le processus de regroupement.
Tirez parti des fonctionnalités SQL avancées : Envisagez d'utiliser des techniques telles que ROLLUP ou GROUPING SETS pour créer des résumés plus efficacement et éviter d'exécuter des requêtes répétitives, en particulier lorsque vous travaillez avec des données hiérarchiques ou multidimensionnelles.
GROUP BY peut également être un moyen pratique de nettoyer vos données en supprimant les doublons. supprimant les doublons en fonction de champs spécifiques. Cette option est utile lorsque votre ensemble de données contient plusieurs lignes identiques ou partiellement en double.
Par exemple, pour supprimer les enregistrements de ventes en double, vous regrouperez par region, product_category et product_name, puis sélectionnerez le prix le plus élevé par groupe afin de conserver l'enregistrement le plus pertinent.
-- Remove duplicate sales records by keeping only unique combinations
-- of region, product_category, and product_name
SELECT
region,
product_category,
product_name,
MAX(price) AS price,
SUM(quantity) AS total_quantity
FROM Sales
GROUP BY
region,
product_category,
product_name
ORDER BY
region,
product_category,
product_name;Lorsque vous utilisez la fonction d'GROUP BY ion sur plusieurs colonnes, veuillez garder à l'esprit les pièges courants suivants :
L'une des erreurs les plus fréquentes dans les requêtes d'GROUP BY s est liée à une spécification incorrecte des colonnes. SQL exige que, lors de la sélection de plusieurs colonnes, celles qui ne sont pas encapsulées dans une fonction d'agrégation soient incluses dans la clause GROUP BY. Si vous ne le faites pas, une erreur se produira. Par conséquent, veuillez toujours inclure les colonnes non agrégées dans la clause « GROUP BY » si elles sont incluses dans l'instruction « SELECT ».
Vous pourriez également rencontrer des erreurs si les données que vous regroupez présentent des incohérences, en particulier lorsque vous effectuez un regroupement par expressions. Supposons que vous regroupiez vos données selon une date formatée. Dans ce cas, vous obtiendrez une erreur si les valeurs de date ont des formats ou des niveaux de précision différents, ce qui entraînera des résultats inattendus ou incorrects.
L'utilisation de requêtes GROUP BY peut parfois ralentir votre base de données, en particulier si vous effectuez un regroupement par colonnes comportant de nombreuses valeurs uniques (cardinalité élevée) ou si ces colonnes ne sont pas indexées. Les grands ensembles de données nécessitent également une mémoire suffisante pour gérer les étapes de tri et de regroupement, ce qui augmente la charge.
Pour éviter ces problèmes, indexez toujours les colonnes et filtrez à l'aide de l'WHERE afin de limiter les données que vous interrogez.
Il est également important de savoir comment SQL traite les valeurs NULL dans le regroupement : toutes les valeurs NULL d'une colonne de regroupement sont considérées comme appartenant au même groupe, quel que soit leur nombre. Cependant, NULL n'est jamais considéré comme égal à une valeur réelle (non NULL), de sorte que ces groupes restent distincts.
L'utilisation de la clause « GROUP BY » pour regrouper plusieurs colonnes dans SQL est une technique puissante qui permet une analyse multidimensionnelle plus approfondie en agrégeant les données à travers des combinaisons de champs. Il permet aux analystes d'aller au-delà des résumés de base et d'obtenir davantage d'informations sur les tendances et les relations entre les données. Cette fonctionnalité est importante pour la création de rapports, le suivi des performances et la prise de décision dans les environnements professionnels modernes.
À mesure que les données gagnent en complexité et en volume, SQL demeure un outil fondamental dans le domaine de l'analyse. Pour approfondir vos compétences, envisagez d'explorer les fonctions de fenêtre, les expressions de table commune (CTE) et les vues matérialisées, qui ouvrent la voie à des transformations de données et des workflows de reporting encore plus avancés.
Je vous recommande de suivre notre cours « Statistiques récapitulatives et fonctions de fenêtre PostgreSQL » pour apprendre à rédiger des requêtes pour l'analyse commerciale à l'aide des fonctions de fenêtre comme un professionnel. Je vous invite également à essayer nos projets : Analyse des émissions de carbone dans l'industrie et analyse des ventes de pièces détachées pour motos afin de tester vos compétences en SQLet de démontrer votre maîtrise de l'utilisation de SQL pour résoudre des problèmes commerciaux.
Apprenez le SQL avec DataCamp
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
Tutoriel
DataCamp Team
Tutoriel
Tutoriel
Matt Crabtree
Tutoriel
Kurtis Pykes
Tutoriel
Mark Pedigo
