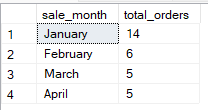

Corso
Statistiche riepilogative e funzioni finestra in PostgreSQL
4 h
127.3K
Raggruppare per una singola colonna è comune, ma raggruppare per più colonne ti permette di riassumere grandi dataset raggruppando le righe che condividono valori in comune, semplificando l’identificazione di pattern, trend e outlier.
In questa guida ti spiegherò come funziona la clausola GROUP BY, i metodi di raggruppamento avanzati e le best practice. Se sei alle prime armi con SQL, valuta di iniziare dal nostro corso Introduction to SQL o Intermediate SQL per costruire una base solida. Trovo inoltre utile lo SQL Basics Cheat Sheet, che puoi scaricare, come riferimento con tutte le funzioni SQL più comuni.
Prima di vedere come raggruppare per più colonne in SQL, capiamo i concetti di base della clausola GROUP BY.
La clausola GROUP BY in SQL organizza i dati identici in gruppi. Scansiona le righe in un database e poi raggruppa le righe con gli stessi valori nelle colonne specificate, consentendo l’aggregazione dei dati all’interno di questi gruppi.
Puoi usare la clausola GROUP BY con funzioni di aggregazione come COUNT(), SUM(), AVG(), MIN() e MAX() per effettuare calcoli riassuntivi su ciascun gruppo di righe.
Supponiamo che tu stia analizzando i dati di vendita e voglia conoscere il fatturato totale per regione. GROUP BY consente di raggruppare le vendite per regione e calcolare la somma per ciascuna in un’unica query.
Il database elabora la clausola GROUP BY su una singola colonna scorrendo le righe e segmentandole in base ai valori distinti in quella colonna. Ogni valore distinto forma un gruppo, e le funzioni di aggregazione calcolano i risultati all’interno di ciascun gruppo.
Quando però introduci più colonne, SQL raggruppa i dati in base a ogni combinazione unica di quelle colonne. Ciò significa che il database partiziona i dati in gruppi più piccoli e raffinati definiti da tutti i valori delle colonne specificate.
Questo approccio di partizionamento consente un’aggregazione multidimensionale, utile per business intelligence e analytics dettagliati. Permette un’analisi approfondita riassumendo i dati all’intersezione di più dimensioni. Ad esempio, puoi raggruppare le vendite per regione e categoria di prodotto.
Come hai visto, raggruppare i dati per più colonne ti permette di ottenere più insight. Vediamo ora come SQL gestisce questo raggruppamento.
Quando raggruppi per più di una colonna in SQL, il motore del database tratta la combinazione di colonne come chiavi composite. Ognuna di queste combinazioni uniche forma un gruppo distinto. Ad esempio, raggruppare i dati di vendita per region e product_type genera un gruppo separato per ogni coppia unica, come ('West', 'Electronics'), ('East', 'Furniture') e così via.
Questo porta a un pattern gerarchico di sotto-raggruppamenti, in cui la prima colonna crea i gruppi primari, la seconda colonna segmenta ulteriormente questi gruppi primari in sottogruppi, e così via. Questo raggruppamento a livelli aumenta la granularità dei dati suddividendoli in categorie dettagliate.
Nota anche la differenza tra raggruppamento gerarchico e non gerarchico. Il raggruppamento gerarchico segue la sequenza di colonne creando gruppi e sottogruppi in un ordine specifico. Il raggruppamento non gerarchico, invece, tratta ogni colonna come un’altra dimensione e non segue una gerarchia intrinseca. Anche così, il raggruppamento non gerarchico crea combinazioni utili per l’analisi, ad esempio quando vuoi raggruppare le vendite di prodotti per stagione.
In SQL, l’ordine con cui elenchi le colonne in una clausola GROUP BY conta davvero. Quando raggruppi per più colonne, SQL considera quelle colonne insieme come una chiave combinata, un po’ come mettere insieme più pezzi per identificare in modo univoco ciascun gruppo.
SQL elabora le colonne da sinistra a destra. Ciò significa che prima raggruppa i dati in base alla prima colonna elencata, poi, all’interno di ciascuno di questi gruppi, raggruppa ulteriormente per la colonna successiva, e così via. Questo ordine può influire sull’efficienza con cui il database gestisce la query, sull’uso degli indici e sulla costruzione dei raggruppamenti intermedi, soprattutto con dataset di grandi dimensioni.
Per esempio, se vuoi raggruppare i dati per regione e prodotto, i dati vengono prima raggruppati per regione e poi, all’interno di ogni regione, per prodotto. Ma se inverti l’ordine in (prodotto, regione), cambi la gerarchia di raggruppamento, il che può portare a risultati e interpretazioni diverse nei tuoi report.
Esaminiamo la sintassi e le varianti della clausola GROUP BY in SQL per capirla appieno.
Per usare una clausola GROUP BY su più colonne, devi elencare ogni colonna nell’istruzione SELECT, separandole con virgole. Il database raggrupperà quindi le righe in base alle combinazioni uniche di quei valori di colonna.
SELECT column1, column2, AGGREGATE_FUNCTION(column3)
FROM table_name
GROUP BY column1, column2;Assicurati sempre che tutte le colonne usate nell’istruzione SELECT che non fanno parte di funzioni di aggregazione compaiano nella clausola GROUP BY per evitare errori e garantire aggregazioni leggibili.
Poniamo di avere una tabella Sales con la seguente struttura:
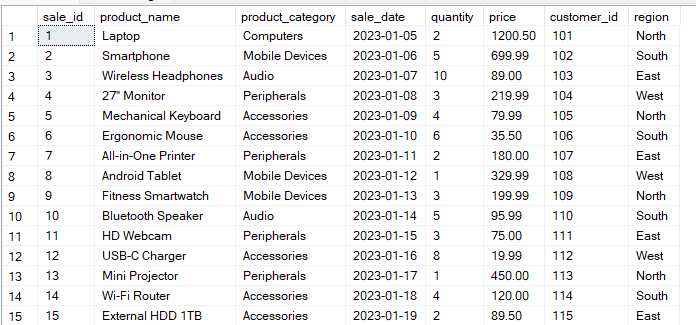
La query seguente raggruppa i dati per le colonne region e product_category. Poi calcola le total_sales per ogni combinazione di gruppo.
-- Group Sales by region and product category
SELECT region, product_category, SUM(quantity) AS total_sales
FROM Sales
GROUP BY region, product_category;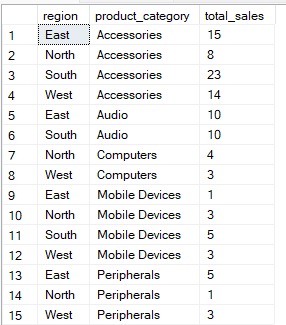
Di seguito trovi i diversi metodi con cui puoi usare la clausola GROUP BY su più colonne in SQL:
Invece di usare i nomi delle colonne, SQL permette di indicare la posizione delle colonne nella clausola GROUP BY. Nel nostro esempio precedente, 1 si riferisce alla colonna region e 2 alla colonna product_category. Questo metodo è supportato in MySQL e PostgreSQL, ma non in SQL Server.
-- Group Sales by region and product category
SELECT region, product_category, SUM(quantity) AS total_sales
FROM Sales
GROUP BY 1, 2;Puoi anche raggruppare per espressioni derivate o valori calcolati. È utile per raggruppare dati trasformati, come l’anno da una data o le sottostringhe. Ad esempio, la query seguente raggruppa le vendite per mese derivato da sale_date.
-- Group Sales by month derived from date column
SELECT
DATENAME(MONTH, sale_date) AS sale_month,
COUNT(*) AS total_orders
FROM Sales
GROUP BY DATENAME(MONTH, sale_date), MONTH(sale_date)
ORDER BY MONTH(sale_date);
Selezionare più colonne ma raggruppare per una sola
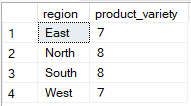
SQL ti permette di selezionare più colonne raggruppando per una sola, ma solo se le colonne aggiuntive sono usate dentro funzioni di aggregazione. Nell’esempio seguente, solo region è nella clausola GROUP BY, mentre product_id è usato in una funzione di aggregazione (COUNT(DISTINCT)), rendendo la query valida.
-- Group Sales by region only
SELECT region, COUNT(DISTINCT sale_id) AS product_variety
FROM Sales
GROUP BY region;
Ti consiglio di provare il progetto Analyzing and Formatting PostgreSQL Sales Data per capire come manipolare i dati in PostgreSQL. Inoltre, il MySQL Basics Cheat Sheet è una pratica guida di riferimento per interrogare le tabelle, filtrare e aggregare i dati, soprattutto se preferisci usare MySQL.
Il vantaggio della clausola GROUP BY in SQL è che puoi usarla con funzioni di aggregazione per ottenere un riepilogo dei dati raggruppati.
Le funzioni di aggregazione offrono insight multidimensionali su varie combinazioni di dati quando si raggruppa per più colonne. Queste sono le funzioni più usate con la clausola GROUP BY:
SUM(): Somma tutti i valori in una colonna numerica per ciascun gruppo.
COUNT(): Conta il numero di righe o di valori non nulli in ciascun gruppo.
AVG(): Calcola il valore medio all’interno di ciascun gruppo.
MIN(): Trova il valore più piccolo in ciascun gruppo.
MAX(): Trova il valore più grande in ciascun gruppo.
Per esempio, la query seguente calcola le vendite totali e il conteggio dei record di vendita per ogni combinazione di regione e categoria di prodotto
-- Group by region, product_category then aggregate
SELECT region, product_category, SUM(quantity) AS total_sales, COUNT(*) AS sales_count
FROM Sales
GROUP BY region, product_category;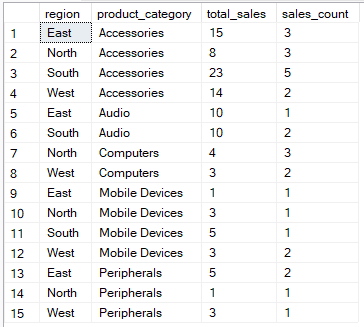
Negli esempi sopra hai visto che la clausola GROUP BY viene usata con le funzioni di aggregazione. Tuttavia, puoi usarla senza aggregazioni se vuoi raggruppare le righe per le colonne specificate ma senza un riepilogo.
Per esempio, la query seguente restituisce coppie uniche di regione e categoria di prodotto senza aggregazione. Puoi quindi usare questo metodo per verificare la consistenza dei dati.
--Group by multiple columns without aggregate
SELECT region, product_category
FROM Sales
GROUP BY region, product_category;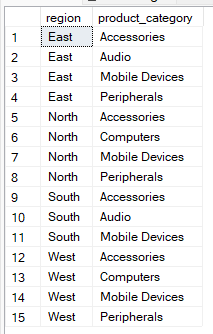
Ora che abbiamo visto come possiamo raggruppare per più colonne, vediamo le diverse operazioni avanzate di raggruppamento usate con la clausola GROUP BY.
L’operazione ROLLUP estende la clausola GROUP BY standard creando livelli di riepilogo che si “arrotolano” lungo le colonne specificate. Oltre a mostrare i gruppi dettagliati, aggiunge anche subtotali e un totale generale aggregando passo dopo passo da destra a sinistra attraverso le colonne di raggruppamento.
Per esempio, nella query seguente ottieni la total_quantity per ogni combinazione di region e product_category. I risultati includono i subtotali per ciascuna regione (dove product_category appare come NULL) e un totale generale che somma tutto su tutte le regioni e categorie.
-- Group by region, product_category and ROLLUP by region
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY ROLLUP(region, product_category);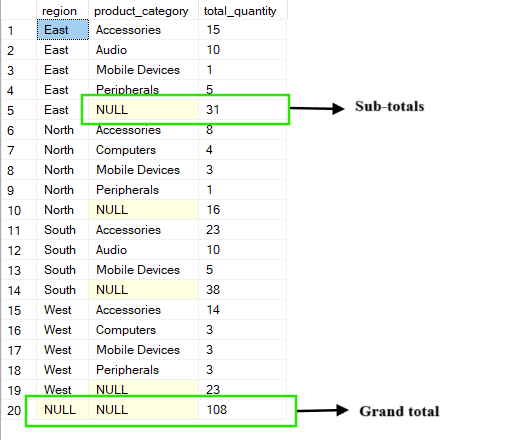
L’operazione CUBE genera tutte le possibili combinazioni delle colonne di raggruppamento. A differenza di ROLLUP, che produce una gerarchia, CUBE produce un cubo di dati completo di aggregazioni.
Fornisce una tabella a doppia entrata di aggregazioni per ogni sottoinsieme delle colonne specificate. L’output dell’operazione CUBE include riepiloghi per ciascuna colonna, per ogni combinazione di colonne e il totale generale.
Per esempio, se interroghiamo la tabella sopra e raggruppiamo per le colonne (region, product_category), l’operazione CUBE produrrà le seguenti combinazioni:
(region, product_category)
(region, NULL)
(NULL, product_category)
(NULL, NULL) che è il totale generale
-- Group by multiple columns using CUBE operation
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY CUBE(region, product_category);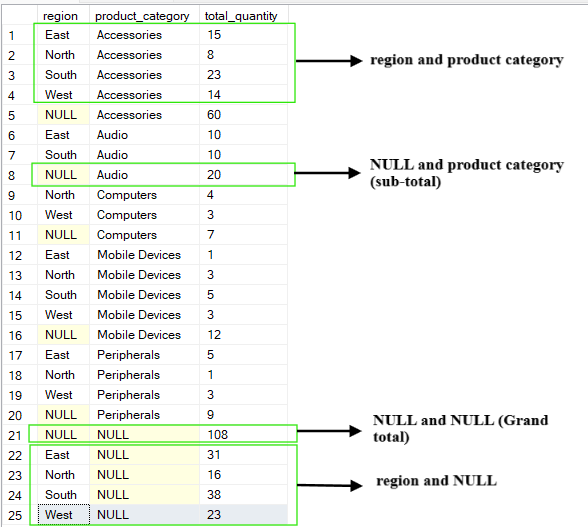
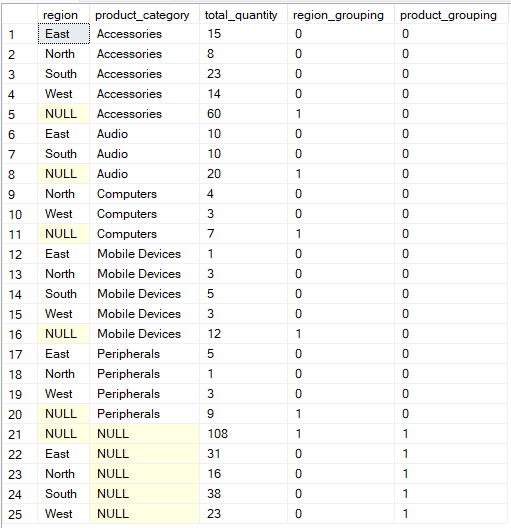
Se vuoi un controllo più flessibile su come vengono raggruppati i dati, l’operazione GROUPING SETS ti permette di definire esplicitamente più raggruppamenti in un’unica query.
In questo caso, la funzione GROUPING() fornisce metadati su quali colonne sono aggregate in ciascuna riga del risultato, identificando i NULL che rappresentano righe di subtotale o totale piuttosto che dati effettivamente mancanti.
-- Group by multiple columns using GROUPING SETS operation
SELECT region, product_category, SUM(quantity) AS total_quantity,
GROUPING(region) AS region_grouping,
GROUPING(product_category) AS product_grouping
FROM Sales
GROUP BY GROUPING SETS (
(region, product_category),
(region),
(product_category),
()
);
Quando scrivi query che raggruppano per più colonne, è importante ottimizzarle per una migliore efficienza e prestazioni complessive del database. Di seguito trovi alcuni consigli pratici che uso per l’ottimizzazione delle query e la gestione delle risorse
Per mantenere le query fluide e con un uso minimo di risorse:
Individua i colli di bottiglia delle prestazioni: le query GROUP BY possono rallentare con dataset grandi a causa di scansione, ordinamento e aggregazione di molti dati. Per evitare il problema, filtra sempre in anticipo con una clausola WHERE ed evita di recuperare dati non necessari.
Usa efficacemente gli indici: indicizzare le colonne accelera le prestazioni di GROUP BY. Creare indici compositi sulle colonne usate nella clausola GROUP BY aiuta il motore del database a individuare e raggruppare rapidamente le righe evitando costose scansioni o ordinamenti dell’intera tabella.
Limita le colonne: includi solo le colonne necessarie per il tuo raggruppamento e analisi per ridurre la complessità e migliorare le prestazioni.
Sfrutta i piani di esecuzione: dove possibile, controlla i piani di esecuzione o usa hint di query per indirizzare l’ottimizzatore del database verso le strategie migliori.
La memoria gioca un ruolo importante nelle prestazioni delle query GROUP BY. L’ordinamento e il raggruppamento dei dati spesso richiedono di mantenere in memoria dati intermedi. Se la memoria non è sufficiente, le prestazioni calano sensibilmente.
Per gestire meglio le risorse:
Ricorda anche che la dimensione dei dati ha un grande impatto sulle prestazioni. Dataset ampi con molte combinazioni di gruppi uniche usano più memoria e potenza di calcolo. Tecniche come il partizionamento di tabelle grandi, la creazione preventiva di tabelle di riepilogo o l’uso di viste materializzate aiutano a mantenere la situazione gestibile.
La clausola GROUP BY si integra bene con altre clausole SQL, rendendo le query più potenti e flessibili. Di seguito vedrai esempi pratici di come combinare GROUP BY con diverse clausole SQL per migliorare l’analisi.
La clausola WHERE filtra le righe prima che avvenga il raggruppamento. Limita il dataset in modo che solo le righe richieste siano incluse nel processo di aggregazione. Per esempio, la query seguente raggruppa per region and product_category` ma include i record in cui la regione è ‘North’.
-- Group by multiple columns, filter using WHERE clause
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
WHERE region = 'North'
GROUP BY region, product_category;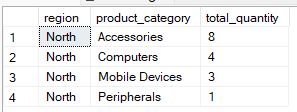
La clausola HAVING, invece, filtra dopo l’aggregazione. Si usa per limitare quali gruppi compaiono nel risultato finale in base ai valori aggregati. La query seguente raggruppa per region and product_category ma include i record in cui la total_quantity` è maggiore di 5.
-- Group by multiple columns, filter using HAVING clause
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY region, product_category
HAVING SUM(quantity) > 4;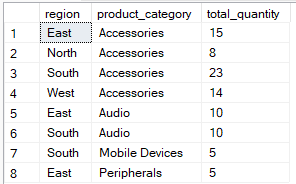
Nell’ ordine di esecuzione SQL, la clausola ORDER BY viene dopo la clausola GROUP BY ed è usata per ordinare i risultati raggruppati, rendendoli più facili da leggere o da elaborare ulteriormente. Usando gli indici giusti e scegliendo con attenzione l’ordine delle colonne nella clausola ORDER BY, puoi velocizzare la query riducendo il lavoro necessario per ordinare i dati.
Per esempio, questa query raggruppa i dati per region e product_category, poi ordina i risultati in modo che i gruppi con la total_quantity più alta compaiano per primi.
-- Group by multiple columns, ORDER BY total_quantity
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY region, product_category
ORDER BY total_quantity DESC;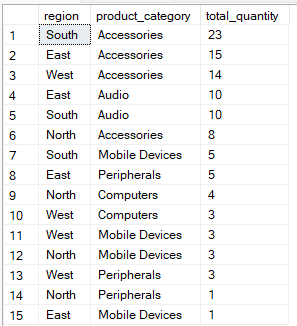
Puoi anche combinare le operazioni di JOIN con la clausola GROUP BY per raggruppare i dati su più tabelle correlate. Fai attenzione usando questo metodo, perché può introdurre complessità a causa dell’unione di dati di dimensioni maggiori.
-- Retrieve the number of sales per region and product category
SELECT
c.region,
p.product_category,
COUNT(*) AS sales_count
-- Join customer, sales, and product data
FROM customers c
JOIN sales_data s
ON c.customer_id = s.customer_id
JOIN products p
ON s.product_id = p.product_id
-- Group results by region and product category
GROUP BY c.region, p.product_category
-- Order results by region first, then sales count in descending order
ORDER BY c.region, sales_count DESC;Ti consiglio il nostro corso Joining Data in SQL per imparare i diversi tipi di join e come usarli in query annidate. Puoi scaricare anche la nostra guida SQL Joins Cheat Sheet come riferimento per saperne di più sull’unione dei dati in SQL.
L’espressione CASE in GROUP BY consente raggruppamenti personalizzati trasformando dinamicamente i valori delle colonne durante il processo di raggruppamento.
La query seguente categorizza i prodotti per fascia di prezzo e conta la quantità totale venduta per regione e categoria di prodotto.
-- Categorize products by price range and count total quantity sold per region & product category
SELECT
region,
product_category,
-- Categorize based on product price
CASE
WHEN price >= 1000 THEN 'High-Priced Products'
WHEN price >= 500 THEN 'Mid-Priced Products'
ELSE 'Low-Priced Products'
END AS price_category,
SUM(quantity) AS total_quantity
FROM Sales
-- Group by region, product category, and price category
GROUP BY
region,
product_category,
CASE
WHEN price >= 1000 THEN 'High-Priced Products'
WHEN price >= 500 THEN 'Mid-Priced Products'
ELSE 'Low-Priced Products'
END
-- Sort results for easier interpretation
ORDER BY
region,
product_category,
total_quantity DESC;
Man mano che continui a usare la clausola GROUP BY per raggruppare più colonne, riconoscerai pattern ricorrenti per migliorare il tuo utilizzo. Discuteremo queste occorrenze comuni con considerazioni sulle prestazioni.
Avrai notato che molti dataset hanno gerarchie intrinseche, come geografia (continente → paese → città), categorie di prodotto o strutture organizzative. La clausola GROUP BY è quindi ideale per riassumere i dati a diversi livelli di queste gerarchie.
Quando i dati includono date e timestamp, l’analisi temporale può aiutare a individuare trend, stagionalità e comportamenti nel tempo raggruppando per parti della data come anno, trimestre, mese o giorno.
In precedenza, abbiamo parlato di due tipi di pattern di raggruppamento. I raggruppamenti gerarchici coinvolgono colonne con una relazione naturale e annidata, come raggruppare prima per reparto e poi, all’interno di ciascun reparto, per team. Al contrario, i raggruppamenti non gerarchici mescolano dimensioni non correlate, come tipo di prodotto e metodo di pagamento, mostrando combinazioni senza alcun ordine o struttura implicita.
Quando usi GROUP BY con più colonne, puoi migliorare le prestazioni seguendo questi consigli pratici:
Limita le colonne di raggruppamento: assicurati sempre di raggruppare solo per le colonne necessarie all’analisi per ridurre l’overhead computazionale dei gruppi.
Ottimizzazione degli indici: assicurati che le colonne raggruppate siano indicizzate per velocizzare le query aiutando il database a gestire le operazioni di ordinamento in modo più efficiente.
Filtra in anticipo: usa la clausola WHERE per limitare il dataset prima del raggruppamento e ridurre la quantità di dati elaborati.
Usa piani e hint di query: rivedi i piani di esecuzione o aggiungi hint di query se il database li supporta per aiutare a ottimizzare il processo di raggruppamento.
Sfrutta le funzionalità SQL avanzate: valuta l’uso di tecniche come ROLLUP o GROUPING SETS per creare riepiloghi in modo più efficiente ed evitare di eseguire query ripetitive, soprattutto con dati gerarchici o multidimensionali.
GROUP BY può essere anche un modo pratico per ripulire i dati rimuovendo i duplicati in base a campi specifici. È utile quando il tuo dataset ha righe identiche o parzialmente duplicate.
Per esempio, per rimuovere record di vendita duplicati, raggrupperai per region, product_category e product_name, quindi selezionerai il prezzo più alto per gruppo per mantenere il record più rilevante.
-- Remove duplicate sales records by keeping only unique combinations
-- of region, product_category, and product_name
SELECT
region,
product_category,
product_name,
MAX(price) AS price,
SUM(quantity) AS total_quantity
FROM Sales
GROUP BY
region,
product_category,
product_name
ORDER BY
region,
product_category,
product_name;Quando lavori con GROUP BY su più colonne, tieni presenti queste insidie comuni:
Uno degli errori più frequenti nelle query GROUP BY è legato a una specifica errata delle colonne. SQL richiede che quando si selezionano più colonne non incluse in una funzione di aggregazione, esse debbano essere incluse nella clausola GROUP BY. In caso contrario si ottiene un errore. Quindi, includi sempre le colonne non aggregate nella clausola GROUP BY se sono presenti nell’istruzione SELECT.
Potresti anche incorrere in errori se i dati che stai raggruppando presentano incongruenze, soprattutto quando raggruppi per espressioni. Supponiamo che tu stia raggruppando i dati per una data formattata: in tal caso, otterrai un errore se i valori di data hanno formati o livelli di precisione diversi, portando a risultati inattesi o errati.
Usare query GROUP BY a volte può rallentare il database, soprattutto se raggruppi per colonne con molti valori unici (alta cardinalità) o se tali colonne non sono indicizzate. I dataset grandi richiedono anche memoria sufficiente per gestire i passaggi di ordinamento e raggruppamento, aumentando il carico.
Per evitare questi problemi, indicizza sempre le colonne e filtra usando WHERE per limitare i dati interrogati.
È anche importante sapere come SQL gestisce i valori NULL nel raggruppamento: tutti i NULL in una colonna di raggruppamento sono trattati come lo stesso gruppo, indipendentemente da quanti siano. Tuttavia, NULL non è mai considerato uguale a un qualsiasi valore effettivo (non NULL), quindi quei gruppi restano distinti.
Usare la clausola GROUP BY per raggruppare più colonne in SQL è una tecnica potente che consente un’analisi più profonda e multidimensionale aggregando i dati su combinazioni di campi. Permette agli analisti di andare oltre i riepiloghi di base e ottenere più insight su pattern e relazioni nei dati. Questa capacità è importante per reporting, monitoraggio delle performance e decisioni nel business moderno.
Con la crescita della complessità e del volume dei dati, SQL rimane uno strumento fondamentale nell’analisi. Per migliorare ulteriormente le tue competenze, esplora le window function, le common table expression (CTE) e le viste materializzate, che aprono la strada a trasformazioni dei dati e flussi di reporting ancora più avanzati.
Ti consiglio il nostro corso PostgreSQL Summary Stats and Window Functions per imparare a scrivere query per business analytics usando le Window function come un professionista. Ti sfido anche a provare i nostri progetti: Analyzing Industry Carbon Emissions e Analyzing Motorcycle Part Sales per mettere alla prova le tue abilità SQL e dimostrare la tua padronanza nell’uso di SQL per risolvere problemi di business.
Impara SQL con DataCamp
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

