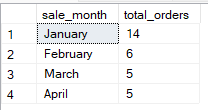

Cursus
PostgreSQL Samenvattingsstatistieken en vensterfuncties
4 Hr
127.3K
Hoewel groeperen op één kolom gebruikelijk is, kun je met groeperen op meerdere kolommen grote datasets samenvatten door rijen met dezelfde waarden te bundelen. Zo herken je makkelijker patronen, trends en uitschieters.
In deze gids leg ik uit hoe de GROUP BY-clausule werkt, geavanceerde groepeermethoden en best practices. Als je nieuw bent met SQL, begin dan met onze cursus Introduction to SQL of Intermediate SQL om een stevige basis op te bouwen. Ook vind ik de SQL Basics Cheat Sheet, die je kunt downloaden, een handige referentie omdat alle meest gebruikte SQL-functies erin staan.
Voordat ik uitleg hoe je in SQL op meerdere kolommen groepeert, kijken we eerst naar de basis van de GROUP BY-clausule.
De GROUP BY-clausule in SQL organiseert identieke data in groepen. Hij scant de rijen in een database en clustert vervolgens rijen met dezelfde waarden in de opgegeven kolommen, zodat je binnen deze groepen kunt aggregeren.
Je kunt de GROUP BY-clausule gebruiken met aggregatiefuncties zoals COUNT(), SUM(), AVG(), MIN() en MAX() om per groep berekeningen voor samenvattingen uit te voeren.
Stel dat je verkoopdata analyseert en de totale omzet per regio wilt weten. Met GROUP BY kun je verkopen per regio groeperen en in één query de som per regio berekenen.
De database verwerkt de GROUP BY-clausule op één kolom door door de rijen te lopen en ze op te delen naar de verschillende waarden in die kolom. Elke verschillende waarde vormt een groep, en aggregatiefuncties berekenen resultaten binnen elke groep.
Maar als je meerdere kolommen gebruikt, groepeert SQL de data op basis van elke unieke combinatie van die kolommen. De database verdeelt de data dus in kleinere, fijnmazigere groepen die worden bepaald door alle opgegeven kolomwaarden.
Deze partitionering maakt multidimensionale aggregatie mogelijk. Dat is nuttig voor gedetailleerde business intelligence en analytics. Het maakt diepgaande analyses mogelijk door data samen te vatten op het snijvlak van meerdere dimensies. Je kunt bijvoorbeeld verkopen groeperen per regio en productcategorie.
Zoals je hebt gezien, levert groeperen op meerdere kolommen meer inzichten op. Laten we nu bekijken hoe SQL deze groepering afhandelt.
Als je in SQL op meer dan één kolom groepeert, behandelt de database-engine de kolomcombinatie als samengestelde sleutels. Elke unieke combinatie vormt een aparte groep. Zo levert groeperen van verkoopdata op region en product_type een aparte groep op voor elk uniek paar, zoals ('West', 'Electronics'), ('East', 'Furniture'), enzovoort.
Dit leidt tot een hiërarchisch patroon van subgroeperingen, waarbij de eerste kolom de primaire groepen creëert, de tweede kolom die primaire groepen verder opdeelt in subgroepen, enzovoort. Deze gelaagde groepering vergroot de datagranulariteit door informatie op te splitsen in gedetailleerde categorieën.
Let ook op het verschil tussen hiërarchische en niet-hiërarchische groepering. Hiërarchische groepering volgt de kolomgroepering en subgroepering van de kolommen in een specifieke volgorde. Niet-hiërarchische groepering daarentegen ziet elke kolom als een extra dimensie en volgt geen inherente hiërarchie. Toch levert niet-hiërarchische groepering nuttige combinaties op voor analyse, bijvoorbeeld als je productverkopen per seizoen wilt groeperen.
In SQL is de volgorde waarin je kolommen in een GROUP BY-clausule zet echt belangrijk. Als je op meerdere kolommen groepeert, behandelt SQL die kolommen samen als een gecombineerde sleutel, een beetje alsof je meerdere puzzelstukjes samenlegt om elke groep uniek te identificeren.
SQL verwerkt de kolommen van links naar rechts. Dat betekent dat eerst op de eerste kolom wordt gegroepeerd en vervolgens binnen elke groep verder op de volgende kolom, enzovoort. Deze volgorde kan beïnvloeden hoe efficiënt de database de query afhandelt, hoe hij indexen gebruikt en hoe tussentijdse groeperingen worden opgebouwd, vooral bij grote datasets.
Als je bijvoorbeeld je data per regio en product wilt groeperen, wordt de data eerst per regio gegroepeerd en daarbinnen per product. Wissel je de volgorde om naar (product, regio), dan verander je de groeperingshiërarchie, wat kan leiden tot andere resultaten en interpretaties in je rapporten.
Laten we de syntax en variaties van de GROUP BY-clausule in SQL bekijken om het volledig te begrijpen.
Om een GROUP BY-clausule op meerdere kolommen te gebruiken, moet je elke kolom in de SELECT-instructie opsommen, gescheiden door komma’s. De database groepeert rijen vervolgens op basis van de unieke combinaties van die kolomwaarden.
SELECT column1, column2, AGGREGATE_FUNCTION(column3)
FROM table_name
GROUP BY column1, column2;Zorg er altijd voor dat alle kolommen die in de SELECT-instructie worden gebruikt en geen deel uitmaken van aggregatiefuncties, in de GROUP BY-clausule staan om fouten te voorkomen en leesbare aggregaties te garanderen.
Stel, je hebt een Sales-tabel met de volgende structuur:
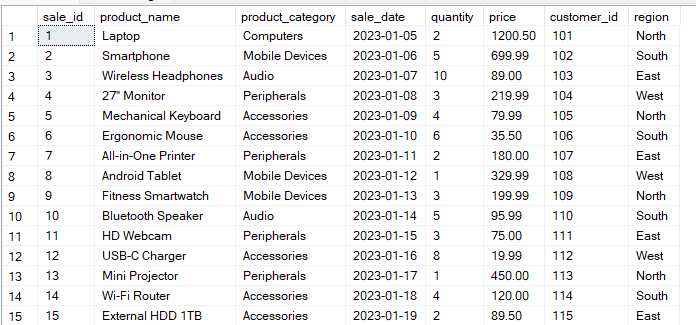
De onderstaande query groepeert de data op de kolommen region en product_category. Vervolgens berekent hij de total_sales voor elke groepscombinatie.
-- Group Sales by region and product category
SELECT region, product_category, SUM(quantity) AS total_sales
FROM Sales
GROUP BY region, product_category;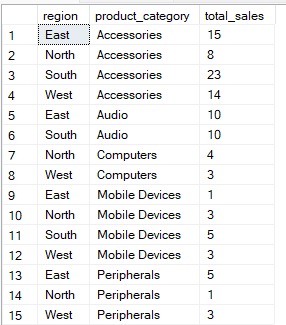
Hieronder staan de verschillende methoden om de GROUP BY-clausule op meerdere kolommen in SQL te gebruiken:
In plaats van kolomnamen te gebruiken, kun je in SQL de positie van kolommen in de GROUP BY-clausule aangeven. In ons vorige voorbeeld verwijst 1 naar de kolom region en 2 naar de kolom product_category. Deze methode wordt ondersteund in MySQL en PostgreSQL, maar niet in SQL Server.
-- Group Sales by region and product category
SELECT region, product_category, SUM(quantity) AS total_sales
FROM Sales
GROUP BY 1, 2;Je kunt ook groeperen op afgeleide expressies of berekende waarden. Dit is handig voor groeperen op getransformeerde data, zoals jaar uit een datum of substrings. In het voorbeeld hieronder worden de verkopen gegroepeerd op maand die is afgeleid van sale_date.
-- Group Sales by month derived from date column
SELECT
DATENAME(MONTH, sale_date) AS sale_month,
COUNT(*) AS total_orders
FROM Sales
GROUP BY DATENAME(MONTH, sale_date), MONTH(sale_date)
ORDER BY MONTH(sale_date);
Meerdere kolommen selecteren maar slechts op één groeperen
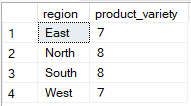
SQL laat toe dat je meerdere kolommen selecteert terwijl je maar op één groepeert, maar alleen als de extra kolommen binnen aggregatiefuncties worden gebruikt. In het onderstaande voorbeeld staat alleen region in de GROUP BY-clausule, terwijl product_id wordt gebruikt in een aggregatiefunctie (COUNT(DISTINCT)), waardoor de query geldig is.
-- Group Sales by region only
SELECT region, COUNT(DISTINCT sale_id) AS product_variety
FROM Sales
GROUP BY region;
Ik raad je aan om ons project Analyzing and Formatting PostgreSQL Sales Data te proberen om te begrijpen hoe je data in PostgreSQL manipuleert. Ook is de MySQL Basics Cheat Sheet een handige referentie voor basisselecties, data filteren en data aggregeren, vooral als je liever met MySQL werkt.
Het voordeel van de GROUP BY-clausule in SQL is dat je die met aggregatiefuncties kunt gebruiken om een samenvatting van gegroepeerde data te krijgen.
Aggregatiefuncties bieden multidimensionale inzichten over verschillende datacombinaties wanneer je op meerdere kolommen groepeert. Dit zijn de functies die vaak met de GROUP BY-clausule worden gebruikt:
SUM(): Tel alle waarden in een numerieke kolom per groep bij elkaar op.
COUNT(): Tel het aantal rijen of niet-NULL-waarden in elke groep.
AVG(): Bereken de gemiddelde waarde binnen elke groep.
MIN(): Vind de kleinste waarde in elke groep.
MAX(): Vind de grootste waarde in elke groep.
De onderstaande query berekent bijvoorbeeld de totale verkopen en het aantal verkooprecords voor elke combinatie van regio en productcategorie
-- Group by region, product_category then aggregate
SELECT region, product_category, SUM(quantity) AS total_sales, COUNT(*) AS sales_count
FROM Sales
GROUP BY region, product_category;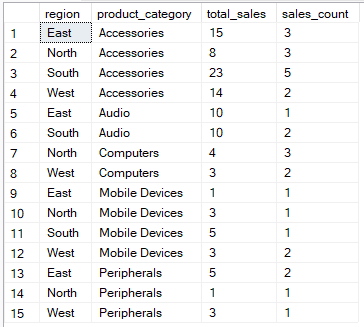
In de bovenstaande voorbeelden zag je dat de GROUP BY-clausule wordt gebruikt met aggregatiefuncties. Je kunt het echter ook zonder aggregatie gebruiken als je rijen wilt groeperen op de opgegeven kolommen, maar zonder samenvatting.
De onderstaande query geeft bijvoorbeeld unieke paren van regio en productcategorie zonder aggregatie. Je kunt deze methode dus gebruiken om dataconsistentie te controleren.
--Group by multiple columns without aggregate
SELECT region, product_category
FROM Sales
GROUP BY region, product_category;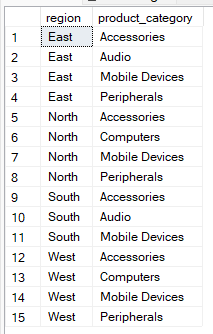
Nu we hebben bekeken hoe we op meerdere kolommen kunnen groeperen, bekijken we de verschillende geavanceerde groeperingsoperaties die met de GROUP BY-clausule worden gebruikt.
De ROLLUP-operatie bouwt voort op de standaard GROUP BY-clausule door samenvattingsniveaus te creëren die oplopen langs de opgegeven kolommen. Naast gedetailleerde groepen voegt hij ook subtotalen en een totaaltelling toe door stap voor stap van rechts naar links te aggregeren over de kolommen waarop je groepeert.
In de onderstaande query krijg je bijvoorbeeld de total_quantity voor elke combinatie van region en product_category. De resultaten bevatten subtotalen per regio (waar product_category als NULL verschijnt) en een totaaltelling die alles over alle regio’s en categorieën optelt.
-- Group by region, product_category and ROLLUP by region
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY ROLLUP(region, product_category);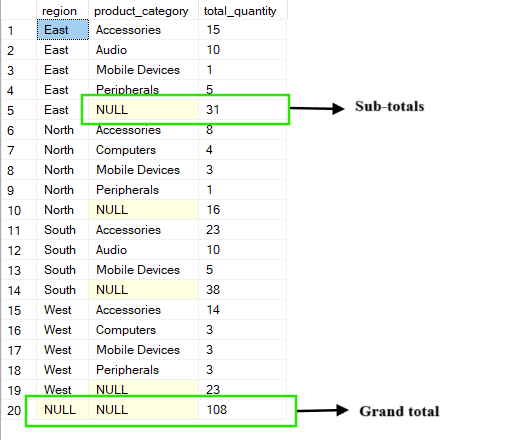
De CUBE-operatie genereert alle mogelijke combinaties van de groepeer-kolommen. In tegenstelling tot de ROLLUP-operatie, die een hiërarchie oplevert, produceert CUBE een volledige datacube met aggregaties.
Het levert een kruistabel van aggregaties op voor elke subset van de opgegeven kolommen. De output van de CUBE-operatie bevat samenvattingen per kolom, voor elke kolomcombinatie en de totaaltelling.
Als we bijvoorbeeld de bovenstaande tabel bevragen en groeperen op de kolommen (region, product_category), levert de CUBE-operatie de volgende combinaties op:
(region, product_category)
(region, NULL)
(NULL, product_category)
(NULL, NULL) wat de totaaltelling is
-- Group by multiple columns using CUBE operation
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY CUBE(region, product_category);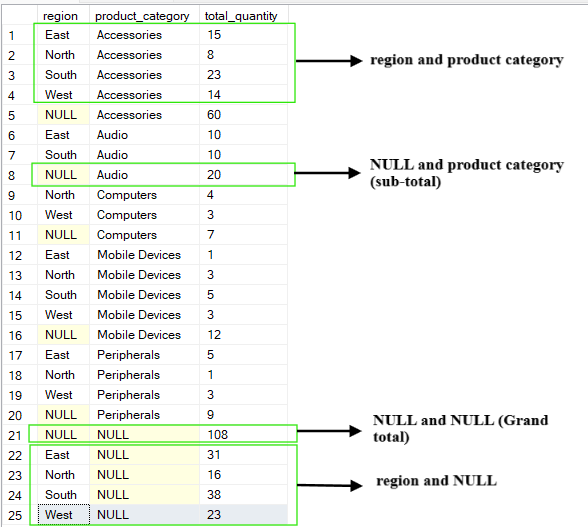
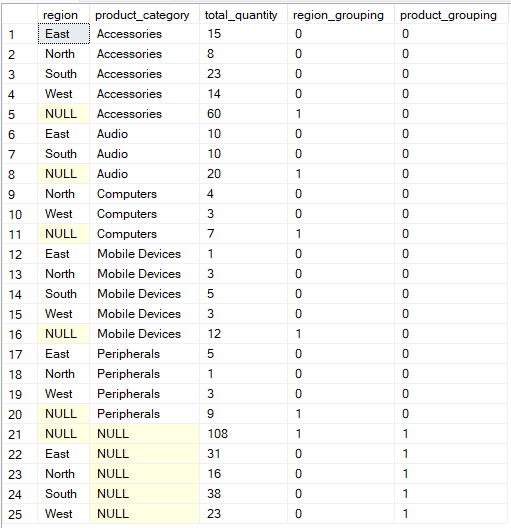
Als je flexibeler wilt bepalen hoe je data wordt gegroepeerd, laat de GROUPING SETS-operatie je meerdere groeperingen expliciet definiëren in één query.
In dit geval biedt de functie GROUPING() metadata over welke kolommen in elke rij van het resultaat zijn geaggregeerd. Zo kun je NULL-waarden herkennen die subtotalen of totaalkopjes voorstellen in plaats van echt ontbrekende data.
-- Group by multiple columns using GROUPING SETS operation
SELECT region, product_category, SUM(quantity) AS total_quantity,
GROUPING(region) AS region_grouping,
GROUPING(product_category) AS product_grouping
FROM Sales
GROUP BY GROUPING SETS (
(region, product_category),
(region),
(product_category),
()
);
Als je queries schrijft die op meerdere kolommen groeperen, is het belangrijk ze te optimaliseren voor meer efficiëntie en algehele databaseprestaties. Hieronder staan enkele praktische tips die ik gebruik voor query-optimalisatie en middelenbeheer
Houd je queries soepel draaiend en verbruik zo min mogelijk resources:
Identificeer prestatieknelpunten: GROUP BY-queries kunnen traag worden bij grote datasets door het scannen, sorteren en aggregeren van veel data. Om dit te voorkomen, filter altijd vroeg met een WHERE-clausule en haal geen data op die je niet nodig hebt.
Gebruik indexering effectief: Het indexeren van kolommen versnelt de GROUP BY-prestaties. Het maken van samengestelde indexen op de kolommen in de GROUP BY-clausule helpt de database-engine om rijen snel te vinden en te groeperen zonder dure volledige tablescans of sorts.
Beperk kolommen: Neem alleen kolommen op die nodig zijn voor je groepering en analyse om de complexiteit te verminderen en de prestaties te verbeteren.
Maak gebruik van queryplannen: Bekijk waar mogelijk uitvoeringsplannen of gebruik query hints om de database-optimizer naar de beste strategieën te sturen.
Geheugen speelt een grote rol in hoe goed GROUP BY-queries presteren. Sorteren en groeperen van data vereist vaak dat tussentijdse data in het geheugen wordt gehouden. Als er niet genoeg geheugen is, wordt alles een stuk trager.
Beheer je resources beter door:
Onthoud ook dat de omvang van je data een grote impact heeft op de prestaties. Grote datasets met veel unieke groepscombinaties gebruiken meer geheugen en rekenkracht. Technieken zoals het partitioneren van grote tabellen, het vooraf maken van samenvattingstabellen of het gebruiken van materialized views helpen om alles beheersbaar te houden.
De GROUP BY-clausule werkt goed samen met andere SQL-clausules, waardoor je queries krachtiger en flexibeler worden. Hierna zie je praktische voorbeelden van het combineren van GROUP BY met verschillende SQL-clausules om je analyse te verbeteren.
De WHERE-clausule filtert rijen vóórdat er gegroepeerd wordt. Hij beperkt de dataset zodat alleen de benodigde rijen in het aggregatieproces worden meegenomen. In de onderstaande query wordt bijvoorbeeld gegroepeerd op region and product_category`, maar worden alleen records opgenomen waar de regio ‘North’ is.
-- Group by multiple columns, filter using WHERE clause
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
WHERE region = 'North'
GROUP BY region, product_category;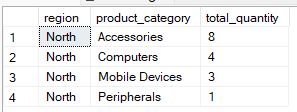
De HAVING-clausule daarentegen filtert na de aggregatie. Die gebruik je om te bepalen welke groepen in het eindresultaat verschijnen op basis van aggregaatwaarden. De onderstaande query groepeert op region and product_category maar neemt alleen records op waar de total_quantity` groter is dan 5.
-- Group by multiple columns, filter using HAVING clause
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY region, product_category
HAVING SUM(quantity) > 4;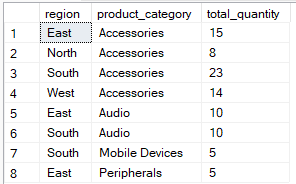
In SQL order of execution, de ORDER BY-clausule komt na de GROUP BY-clausule en wordt gebruikt om de gegroepeerde resultaten te sorteren, zodat ze makkelijker te lezen of verder te verwerken zijn. Door de juiste indexen te gebruiken en de kolomvolgorde in de ORDER BY-clausule zorgvuldig te kiezen, kun je je query versnellen door het sorteerwerk te verminderen.
In dit voorbeeld wordt de data gegroepeerd op region en product_category, en vervolgens gesorteerd zodat de groepen met de hoogste total_quantity eerst verschijnen.
-- Group by multiple columns, ORDER BY total_quantity
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY region, product_category
ORDER BY total_quantity DESC;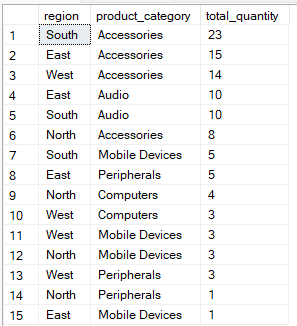
Je kunt ook JOIN-operaties combineren met de GROUP BY-clausule om data te groeperen over meerdere gerelateerde tabellen. Wees voorzichtig met deze methode, want die kan complexiteit introduceren door het joinen van grotere datasets.
-- Retrieve the number of sales per region and product category
SELECT
c.region,
p.product_category,
COUNT(*) AS sales_count
-- Join customer, sales, and product data
FROM customers c
JOIN sales_data s
ON c.customer_id = s.customer_id
JOIN products p
ON s.product_id = p.product_id
-- Group results by region and product category
GROUP BY c.region, p.product_category
-- Order results by region first, then sales count in descending order
ORDER BY c.region, sales_count DESC;Ik raad je onze cursus Joining Data in SQL aan om de verschillende soorten joins te leren en hoe je ze in geneste queries gebruikt. Je kunt onze gids SQL Joins Cheat Sheet downloaden als naslag om meer te leren over data joinen in SQL.
De CASE-expressie in GROUP BY maakt aangepaste groeperingen mogelijk door kolomwaarden dynamisch te transformeren binnen het groeperingsproces.
De onderstaande query categoriseert producten op prijsrange en telt de totale verkochte hoeveelheid per regio & productcategorie.
-- Categorize products by price range and count total quantity sold per region & product category
SELECT
region,
product_category,
-- Categorize based on product price
CASE
WHEN price >= 1000 THEN 'High-Priced Products'
WHEN price >= 500 THEN 'Mid-Priced Products'
ELSE 'Low-Priced Products'
END AS price_category,
SUM(quantity) AS total_quantity
FROM Sales
-- Group by region, product category, and price category
GROUP BY
region,
product_category,
CASE
WHEN price >= 1000 THEN 'High-Priced Products'
WHEN price >= 500 THEN 'Mid-Priced Products'
ELSE 'Low-Priced Products'
END
-- Sort results for easier interpretation
ORDER BY
region,
product_category,
total_quantity DESC;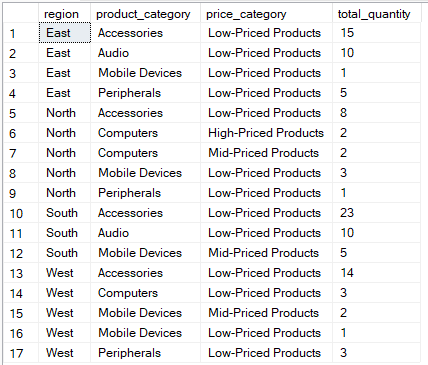
Als je de GROUP BY-clausule blijft gebruiken om op meerdere kolommen te groeperen, ga je terugkerende patronen herkennen die je gebruik verbeteren. We bespreken deze veelvoorkomende situaties met prestatie-overwegingen.
Je hebt vast gemerkt dat de meeste datasets inherente hiërarchieën hebben, zoals geografie (continent → land → stad), productcategorieën of organisatiestructuren. De GROUP BY-clausule is daarom ideaal om data op verschillende niveaus van deze hiërarchieën samen te vatten.
Als je data met datums en tijdstempels hebt, kan temporele analyse helpen trends, seizoensinvloeden en tijdsgebonden gedrag te herkennen door te groeperen op datumonderdelen zoals jaar, kwartaal, maand of dag.
Eerder hadden we het over twee soorten groeperingspatronen. Hiërarchische groeperingen omvatten kolommen met een natuurlijke, geneste relatie, zoals eerst groeperen op afdeling en daarbinnen op team. Niet-hiërarchische groeperingen daarentegen mengen niet-gerelateerde dimensies, zoals producttype en betaalmethode, en tonen combinaties zonder impliciete volgorde of structuur.
Als je GROUP BY met meerdere kolommen gebruikt, kun je de prestaties verbeteren met deze praktische tips:
Beperk groepeer-kolommen: Zorg dat je alleen groepeert op kolommen die nodig zijn voor de analyse om de rekenlast van groepen te verkleinen.
Indexoptimalisatie: Zorg dat de gegroepeerde kolommen geïndexeerd zijn om de query te versnellen doordat de database sorteertaken efficiënter afhandelt.
Filter vroeg: Gebruik de WHERE-clausule om je dataset te beperken vóór het groeperen, zodat er minder data wordt verwerkt.
Gebruik queryplannen en hints: Bekijk uitvoeringsplannen of voeg hints toe als je database die ondersteunt om het groeperingsproces te optimaliseren.
Maak gebruik van geavanceerde SQL-functies: Overweeg technieken zoals ROLLUP of GROUPING SETS om efficiënter samenvattingen te maken en herhaalde queries te vermijden, vooral bij hiërarchische of multidimensionale data.
GROUP BY kan ook handig zijn om je data op te schonen door duplicaten te verwijderen op basis van specifieke velden. Dit is nuttig wanneer je dataset meerdere identieke of deels dubbele rijen bevat.
Om bijvoorbeeld dubbele verkooprecords te verwijderen, groepeer je op region, product_category en product_name, en selecteer je vervolgens de hoogste prijs per groep om het meest relevante record te behouden.
-- Remove duplicate sales records by keeping only unique combinations
-- of region, product_category, and product_name
SELECT
region,
product_category,
product_name,
MAX(price) AS price,
SUM(quantity) AS total_quantity
FROM Sales
GROUP BY
region,
product_category,
product_name
ORDER BY
region,
product_category,
product_name;Houd bij het werken met GROUP BY op meerdere kolommen rekening met deze veelvoorkomende valkuilen:
Een van de meest voorkomende fouten in GROUP BY-queries heeft te maken met onjuiste kolomspecificatie. SQL vereist dat als je meerdere kolommen selecteert die niet in een aggregatiefunctie zijn gewikkeld, ze in de GROUP BY-clausule moeten staan. Doe je dat niet, dan resulteert dat in een fout. Neem dus altijd de niet-geaggregeerde kolommen op in de GROUP BY-clausule als ze in de SELECT-instructie staan.
Je kunt ook fouten tegenkomen als de data die je groepeert inconsistenties bevat, vooral wanneer je groepeert op expressies. Stel dat je je data groepeert op een geformatteerde datum. In dat geval krijg je een fout als de datumwaarden verschillende formaten of precisieniveaus hebben, wat tot onverwachte of onjuiste resultaten leidt.
Het gebruik van GROUP BY-queries kan je database soms vertragen, vooral als je groepeert op kolommen met veel unieke waarden (hoge cardinaliteit) of als die kolommen niet zijn geïndexeerd. Grote datasets hebben ook voldoende geheugen nodig voor de sorteer- en groepeerstappen, wat de belasting verhoogt.
Om dit te vermijden, indexeer de kolommen altijd en filter met WHERE om de data die je opvraagt te beperken.
Het is ook belangrijk om te weten hoe SQL omgaat met NULL-waarden bij groeperen: alle NULL’s in een groepeer-kolom worden als één groep behandeld, hoeveel er ook zijn. NULL wordt echter nooit als gelijk aan een echte (niet-NULL) waarde beschouwd, dus die groepen blijven onderscheiden.
De GROUP BY-clausule gebruiken om in SQL op meerdere kolommen te groeperen is een krachtige techniek die diepere, multidimensionale analyses mogelijk maakt door data over combinaties van velden te aggregeren. Het stelt analisten in staat verder te gaan dan basis-samenvattingen en meer inzicht te krijgen in patronen en relaties binnen data. Deze mogelijkheid is belangrijk voor rapportage, prestatiebewaking en besluitvorming in moderne bedrijfsomgevingen.
Naarmate data complexer en omvangrijker wordt, blijft SQL een fundament in analytics. Verken om je vaardigheden verder te vergroten windowfuncties, common table expressions (CTE’s) en materialized views, die de deur openen naar nog geavanceerdere datatransformaties en rapportage-workflows.
Ik raad je onze cursus PostgreSQL Summary Stats and Window Functions aan om te leren hoe je queries voor business analytics schrijft met windowfuncties als een pro. Ik daag je ook uit om onze projecten te proberen: Analyzing Industry Carbon Emissions en Analyzing Motorcycle Part Sales om je SQL-vaardigheden te testen en te laten zien dat je SQL beheerst om bedrijfsproblemen op te lossen.
Leer SQL met DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
