
Leerpad
Data-engineer in Python
40 Hr
Het vakgebied data engineering groeit wereldwijd explosief nu organisaties meer vertrouwen op datagestuurde inzichten. Grote rapporten, zoals het recent gepubliceerde rapport van het World Economic Forum, plaatsen “big dataspecialisten” (waaronder data engineers) bij de snelstgroeiende techbanen. In tegenstelling tot vroege AI-angstscenario’s breiden data-engineeringfuncties zich juist uit.
Data engineers zijn steeds crucialer bij het bouwen van de infrastructuur die AI-systemen aandrijft. In de praktijk betekent dit dat er duizenden vacatures zijn voor data engineers, met werkgevers in diverse sectoren die naar talent zoeken.
Andere aanpalende data-engineeringrollen, zoals AI- en machinelearningspecialisten en datawarehousespecialisten, staan bovenaan de lijst. Een apart artikel bespreekt enkele andere topcarrières in analytics.

Als je overweegt om data engineer te worden, vind je in deze blogpost alles wat je moet weten. Ik bespreek wat een data engineer is, hoe de dagelijkse taken en verantwoordelijkheden eruitzien en waarom data engineering in 2026 zo’n lonende carrière is. Ook loop ik door de benodigde skills en kwalificaties en deel ik tips om je eerste baan in de sector te veroveren.
In vogelvlucht ziet het technische leerpad voor data engineers er als volgt uit:
We behandelen veel van deze punten uitgebreid verderop in deze post, terwijl we verkennen hoe je data engineer wordt.
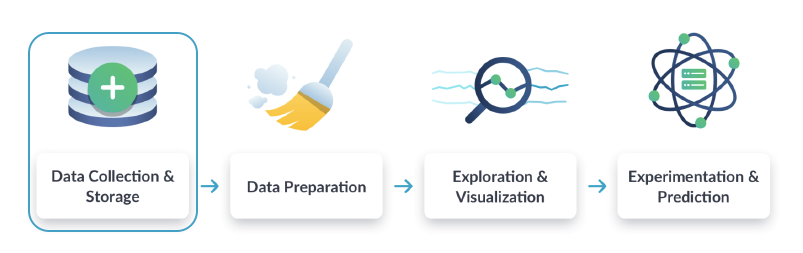
Data engineers leggen de basis voor het verwerven, opslaan, transformeren en beheren van data binnen een organisatie. Ze beheren het ontwerp, de creatie en het onderhoud van de databasearchitectuur en dataverwerkingssystemen, zodat vervolgwerk zoals analyse, visualisatie en het bouwen van machinelearningmodellen naadloos, continu, veilig en effectief kan plaatsvinden.
Kort gezegd zijn data engineers de meest technische profielen binnen data science, met een cruciale brugfunctie tussen software- en applicatieontwikkelaars en traditionele data-sciencefuncties.
Data engineers zijn verantwoordelijk voor de eerste fase van de traditionele data-scienceworkflow: het proces van dataverzameling en -opslag. Ze zorgen ervoor dat de grote hoeveelheid data uit verschillende bronnen toegankelijk ruwe grondstof wordt voor andere dataspecialisten, zoals data-analisten en data scientists.
Aan de ene kant betekent dit het ontwikkelen en onderhouden van schaalbare datainfrastructuren met hoge beschikbaarheid, performance en het vermogen om nieuwe technologieën te integreren. Aan de andere kant houden data engineers ook toezicht op de beweging en status van data door deze systemen heen.
Data-scienceworkflow
Data engineers spelen een sleutelrol bij de ontwikkeling en het onderhoud van de data-architectuur van elk bedrijf. Ze zijn specialisten in het voorbereiden van grote datasets voor analisten. Wanneer een analist informatie moet interpreteren, maakt de data engineer programma’s en routines om data in een geschikt format te brengen.
Daardoor beweegt de dagelijkse praktijk van een data engineer zich grofweg tussen drie processen:
Toch kan het proces van dataverzameling en -opslag extreem complex zijn. Er kunnen verschillende databronnen betrokken zijn, en die bronnen kunnen verschillende datatypes hebben. Naarmate het volume, de variatie en de snelheid van de beschikbare data toenemen, neemt ook de complexiteit van het werk van de data engineer toe.
Data engineers ontwikkelen zogenoemde datapijplijnen om te zorgen dat de taken tijdig, robuust en schaalbaar worden uitgevoerd. Een datapijplijn verplaatst data door gedefinieerde stadia, bijvoorbeeld het laden van data uit een on-premises database naar een clouddienst.
Een belangrijk kenmerk is dat pijplijnen deze verplaatsing automatiseren. In plaats van een data engineer te vragen om elke keer handmatig een programma te draaien wanneer er nieuwe data ontstaat, kun je de taak zo inplannen dat deze elk uur, dagelijks of bij een bepaalde gebeurtenis wordt gestart.
Omdat het proces geautomatiseerd is, moeten datapijplijnen worden gemonitord. Gelukkig kunnen meldingen automatisch worden gegenereerd. Datapijplijnen zijn niet voor alle data-scienceprojecten nodig, maar wel wanneer je met veel data uit verschillende bronnen werkt, zoals normaal is in datagedreven bedrijven. Wil je leren hoe datapijplijnen in de praktijk werken, bekijk dan onze cursus Building Data Engineering Pipelines in Python.
Vraag je je nog steeds af wat een data engineer doet? Bekijk dan ons volledige artikel voor meer informatie.
Data engineering overlapt met andere datarollen, wat voor verwarring kan zorgen bij het plannen van je carrière. Zo verhouden de drie belangrijkste datarollen zich tot elkaar:
| Aspect | Data Engineer | Data Scientist | Data Analyst |
|---|---|---|---|
| Primaire focus | Bouwen van datainfrastructuur en -pijplijnen | Inzichten halen met ML-modellen | Business intelligence en rapportage |
| Kerntools | SQL, Python, Spark, Kafka, Airflow | Python, R, TensorFlow, scikit-learn | SQL, Excel, Tableau, Power BI |
| Belangrijkste output | Geautomatiseerde ETL-pijplijnen, datawarehouses | Predictieve modellen, experimenten | Dashboards, rapporten, KPI’s |
| Kernvaardigheid | Gedistribueerde systemen en cloudarchitectuur | Statistisch modelleren en ML | Datavisualisatie en storytelling |
Kortom: data engineers bouwen de systemen die data toegankelijk maken, data scientists analyseren die data om patronen te vinden en data-analisten vertalen bevindingen naar zakelijke inzichten. Leer meer over de verschillen in ons artikel over wat data engineering is.
Hieronder zetten we de stappen uiteen die je moet nemen om een carrière als data engineer na te streven. De exacte stappen hangen af van je huidige skills en ervaring, maar dit proces kan je begeleiden om vanaf nul data engineer te worden.
Data engineering is nog steeds een opkomend beroep. Slechts weinig universiteiten en hogescholen bieden een opleiding data engineering aan. Data engineers hebben doorgaans een achtergrond in Data Science, Software Engineering, Wiskunde of een bedrijfskundig vakgebied.
Afhankelijk van baan of sector krijgen de meeste data engineers hun eerste juniorfunctie na het behalen van hun bachelordiploma. Maar gezien de zeer specialistische skillset die nodig is voor de taken van data engineers, wegen kennis en competenties in veel gevallen zwaarder dan formele opleiding.
Wil je toch een formele opleiding volgen, kies dan een studie waarin systeemarchitectuur, programmeren en databaseconfiguratie in het curriculum zitten.
Je kunt ook kiezen voor opties zoals de DataCamp Data Engineer in Python career track, die je alle basis leert die je nodig hebt om een effectieve data-architectuur te bouwen, dataverwerking te stroomlijnen en grootschalige datasystemen te onderhouden.
Data engineers hebben een aanzienlijk pakket aan technische skills nodig voor hun taken. Het is echter lastig om een gedetailleerde en volledige lijst te maken van alle vaardigheden en kennis die je in elke data-engineeringrol nodig hebt; het data-science-ecosysteem ontwikkelt zich snel, en nieuwe technologieën en systemen verschijnen continu. Dit betekent dat data engineers constant moeten blijven leren om gelijke tred te houden met technologische doorbraken.
Desondanks vind je hier een niet-uitputtende lijst van skills die je moet ontwikkelen om data engineer te worden:
Data engineers besteden een aanzienlijk deel van hun dagelijkse werk aan het bedienen van databases, of het nu gaat om het verzamelen, opslaan, verplaatsen, opschonen of raadplegen van data. Daarom moeten data engineers goed thuis zijn in databasemanagement. Dat betekent vloeiend zijn in SQL (Structured Query Language), de basistaal om met databases te werken, en ervaring hebben met populaire SQL-dialecten zoals MySQL, SQL Server en PostgreSQL.
Naast relationele databases moeten data engineers bekend zijn met NoSQL (“Not only SQL”)-databases, die snel de standaard worden voor Big Data en realtime toepassingen.
Hoewel het aantal NoSQL-engines toeneemt, zouden data engineers op z’n minst het verschil tussen NoSQL-databasetypen en de use-cases voor elk type moeten begrijpen. Als je in de war bent over NoSQL en hoe het verschilt van SQL, is onze cursus NoSQL Concepts een goede plek om duidelijkheid te krijgen.
Net als in andere data-sciencefuncties is coderen een verplichte vaardigheid voor data engineers. Naast SQL gebruiken data engineers andere programmeertalen voor een breed scala aan taken. Er zijn veel programmeertalen voor data engineering die je kunt inzetten, maar Python is zeker een van de beste opties.
Python is de lingua franca in data science en perfect voor het uitvoeren van ETL-jobs en het schrijven van datapijplijnen. Je kunt in een aparte post meer lezen over waar Python voor wordt gebruikt.
Een andere reden om Python te gebruiken is de sterke integratie met tools en frameworks die cruciaal zijn in data engineering, zoals Apache Airflow en Apache Spark. Veel van deze open-sourceframeworks draaien op de Java Virtual Machine. Als je bedrijf met deze frameworks werkt, moet je waarschijnlijk ook Java of Scala leren.
De afgelopen jaren zijn gedistribueerde systemen alomtegenwoordig geworden in data science. Een gedistribueerd systeem is een computingsomgeving waarin verschillende componenten zijn verspreid over meerdere computers (ook wel een cluster) in een netwerk.
Gedistribueerde systemen verdelen het werk over het cluster en coördineren de inspanningen om de taak efficiënter te voltooien. Frameworks voor gedistribueerde computing, zoals Apache Hadoop en Apache Spark, zijn ontworpen voor het verwerken van enorme hoeveelheden data en vormen de basis voor enkele van de indrukwekkendste Big Data-toepassingen. Expertise in een van deze frameworks is belangrijk voor elke aspirant-data engineer. Onze cursus Foundations of PySpark is een uitstekend startpunt voor gedistribueerde dataverwerking.
Cloud computing is een van de heetste topics in data science. De vraag naar cloudoplossingen verandert het speelveld razendsnel. Tegenwoordig betekent data engineer zijn voor een groot deel het koppelen van de bedrijfsystemen van je organisatie aan cloudgebaseerde systemen.
Met de opkomst van diensten als Amazon Web Services (AWS), Azure en Google Cloud kan de hele dataworkflow in de cloud plaatsvinden. Daarom moet een goede data engineer bekend zijn met clouddiensten, hun voor- en nadelen en hun toepassing in Big Data-projecten. Je zou op z’n minst vertrouwd moeten zijn met een platform zoals AWS of Azure, aangezien die het meest verspreid zijn.
Wil je eerste praktische ervaring opdoen met cloud data warehouses, probeer dan ons Exploring London’s Travel Network Project. Dit biedt een mooie kans om direct in je browser te werken met Amazon Redshift, Google BigQuery en Snowflake.
Een van de belangrijkste rollen van data engineers is het creëren van datapijplijnen met ETL-technologieën en orkestratieframeworks. Er zijn in deze context veel technologieën te noemen, maar een data engineer zou de bekendste moeten kennen of ermee uit de voeten kunnen, zoals Apache Airflow en Apache NiFi. Airflow is een orkestratieframework. Het is een open-sourcetool voor het plannen, genereren en volgen van datapijplijnen. NiFi is perfect voor een basis, herhaalbaar big data-ETL-proces.
Enkele van de meest innovatieve data-sciencetoepassingen gebruiken realtime data. Daardoor groeit de vraag naar kandidaten die bekend zijn met streamverwerkingsframeworks. Daarom is het leren gebruiken van streamingtools zoals Flink, Kafka Streams of Spark Streaming een sterke zet voor data engineers die hun carrière naar een hoger niveau willen tillen.
Veel taken en routines in de cloud en andere Big Data-tools en -frameworks worden uitgevoerd met shellcommando’s en scripts. Data engineers moeten zich op hun gemak voelen in de terminal om bestanden te bewerken, opdrachten uit te voeren en door het systeem te navigeren. Leer meer met onze bash-scripttutorial.
Last but not least hebben data engineers ook communicatieve vaardigheden nodig om afdelingen te overstijgen en de behoeften van data-analisten, data scientists en businessleiders te begrijpen. Afhankelijk van de organisatie moeten data engineers mogelijk ook weten hoe ze dashboards, rapporten en andere visualisaties ontwikkelen om met stakeholders te communiceren.
Moderne data engineers gebruiken steeds vaker gespecialiseerde transformatieraamwerken om datapijplijnen te beheren. dbt (Data Build Tool) is uitgegroeid tot de industriestandaard voor SQL-gebaseerde datatransformaties, met versiebeheer, testen en documentatie voor je datamodellen. Inzicht in dimensionele modelleringstechnieken (sterren- en sneeuwvlokschema’s) en de medaillonarchitectuur (bronze-, silver-, gold-lagen) helpt je datawarehouses te ontwerpen die analisten efficiënt kunnen bevragen.
Naarmate datapijplijnen complexer worden, wordt het borgen van datakwaliteit een kernverantwoordelijkheid. Tools zoals Great Expectations en Monte Carlo helpen data engineers data te valideren, afwijkingen te detecteren en datalinage te volgen. Leren hoe je data governance-praktijken implementeert, inclusief datacontracten en schemavalidatie, zorgt ervoor dat je pijplijnen data opleveren die teams kunnen vertrouwen voor besluitvorming en AI-toepassingen.
De volgende stap om data engineer te worden is werken aan data-engineeringprojecten die je skills en begrip van kernthema’s laten zien. Je kunt onze volledige gids over het bouwen van een data-scienceportfolio raadplegen voor inspiratie.
Je wilt de skills laten zien die we al hebben benoemd om indruk te maken op potentiële werkgevers, wat betekent dat je aan uiteenlopende projecten werkt. DataLab biedt een collaboratieve cloudgebaseerde notebook waarmee je aan eigen projecten kunt werken, zodat je data kunt analyseren, samenwerken en inzichten delen.
Je kunt je kennis ook toepassen op diverse data-scienceprojecten, zodat je realistische problemen vanuit je browser oplost en tegelijk aan je data-engineeringportfolio bouwt.
Wanneer je klaar bent om een specifiek zakelijk domein te verkennen, kun je je focussen op het opdoen van domeinkennis en werken aan individuele projecten binnen dat domein.
Data engineering is een van de meest gevraagde functies in de data-sciencesector. Van big tech in Silicon Valley tot kleine datagedreven startups in allerlei sectoren: bedrijven willen data engineers aannemen om op te schalen en hun data-assets optimaal te benutten. Tegelijkertijd hebben bedrijven moeite om de juiste kandidaten te vinden, gezien de brede en zeer gespecialiseerde skillset die nodig is om aan de behoeften van een organisatie te voldoen.
Gegeven deze context is er geen perfecte formule om je eerste data-engineeringbaan te bemachtigen. In veel gevallen belanden data engineers in hun rol via een overstap vanuit andere data-sciencefuncties binnen hetzelfde bedrijf, zoals data scientist of databasebeheerder.
Zoek je juist naar data-engineeringkansen op vacatureplatforms, onthoud dan dat er veel vacatures zijn met de titel “data engineer”, waaronder cloud data engineer, big data engineer en data architect. De specifieke vaardigheden en vereisten verschillen per functie, dus de sleutel is om een zo goed mogelijke match te vinden tussen wat jij kunt en wat het bedrijf nodig heeft.
Je kunt onze volledige gids over solliciteren op data-sciencebanen bekijken om te leren hoe je je onderscheidt van andere kandidaten. Waarschijnlijk heb je een redelijk uitgebreid portfolio nodig dat een reeks vaardigheden aantoont. Je vindt ook nuttige info over wat hiring managers willen in ons artikel over het schrijven van een functieomschrijving voor data engineers.
Het antwoord is simpel: blijf leren. Er zijn veel routes om je expertise te verdiepen en je toolkit voor data engineering te verbreden.
Je kunt ook kiezen voor verdere formele opleiding, of het nu een bachelor is in data science of informatica, een aanverwant vakgebied, of een master in data engineering.
Naast opleiding is oefening de sleutel tot succes. Werkgevers zoeken kandidaten met unieke skills en een sterke beheersing van software en programmeertalen. Hoe meer je je codeerskills traint in persoonlijke projecten en big data-tools en -frameworks uitprobeert, hoe groter je kans om op te vallen in het sollicitatieproces. Om je expertise te bewijzen, is gecertificeerd raken in data engineering een goede optie.
Industriecertificeringen kunnen je skills valideren en je positie op de arbeidsmarkt verbeteren. Overweeg deze certificeringen naarmate je vordert:
Begin met een platformonafhankelijke certificering en voeg daarna een cloudspecifieke toe die aansluit bij de platforms die jouw beoogde werkgevers gebruiken.
Als het niet lukt om meteen je eerste baan als data engineer te vinden, overweeg dan te solliciteren op andere junior data-sciencefuncties. Uiteindelijk is data science een samenwerkingsveld met veel onderwerpen en skills die rollen overstijgen. Deze functies geven je waardevolle inzichten en ervaring die je helpen je droombaan in data engineering te bemachtigen.
Naarmate je carrière vordert, kun je je in verschillende richtingen specialiseren:
Veel data engineers stromen ook door naar rollen als ML engineer, cloudarchitect of engineeringmanager naarmate ze ervaring opdoen.
Sollicitatiegesprekken voor data engineering zijn meestal opgedeeld in technische en niet-technische delen. Je kunt onze volledige gids met de belangrijkste interviewvragen en -antwoorden voor data engineering bekijken.
Kort samengevat kun je vragen verwachten rond vier onderwerpen:
Recruiters willen weten welke ervaringen je hebt die relevant zijn voor de data-engineeringfunctie. Zorg dat je je eerdere werk in data-sciencefuncties en -projecten in je cv uitlicht en bereid je voor om daar volledig over uit te weiden, omdat deze informatie cruciaal is voor recruiters om je technische skills, probleemoplossend vermogen, communicatie en projectmanagement te beoordelen.
Dit is waarschijnlijk het meest stressvolle deel van een data-sciencegesprek. Over het algemeen wordt je gevraagd om binnen korte tijd een probleem op te lossen in een paar regels code met Python of een dataframework zoals Spark.
Zo kan je oefening bestaan uit het maken van een eenvoudige datapijplijn om data te laden en op te schonen. Hoewel het probleem doorgaans te doen is, kan de druk van het moment je prestaties negatief beïnvloeden. Als je niet bekend bent met dit soort tests, oefen dan vooraf met enkele codeervragen.
Zonder solide SQL-expertise kom je niet ver in je carrière als data engineer. Daarom kan je naast de programmeertest ook gevraagd worden een probleem op te lossen dat SQL vereist. Meestal bestaat de oefening uit het schrijven van efficiënte queries om data in databases te verwerken.
Dit is het meest conceptuele deel van het technische gesprek en vaak het meest veeleisend. Het ontwerpen van data-architecturen is een van de meest impactvolle taken van data engineers. In dit deel wordt je gevraagd een end-to-end datasolution te ontwerpen, die normaal drie aspecten omvat: dataopslag, dataverwerking en datamodellering.
Gezien de snel groeiende omvang van data-science-ecosystemen zijn de ontwerpmogelijkheden eindeloos. Je moet klaar zijn om de voor- en nadelen en de mogelijke trade-offs van je keuzes te bespreken.
Nadat je het technische deel hebt afgerond, volgt als laatste stap een persoonlijk gesprek met een of meer van je toekomstige teamleden. Het doel? Ontdekken wie je bent en hoe je in het team past.
Maar onthoud: het gesprek voor data engineers is tweerichtingsverkeer, wat betekent dat je ook vragen aan hen moet stellen om te bepalen of jij jezelf als onderdeel van het team ziet.
Salarissen voor data engineers liggen hoog in vergelijking met veel IT-banen, wat de vraag weerspiegelt. Bedragen variëren per land, stad en senioriteit, maar we kunnen indicatieve bandbreedtes schetsen (alle bedragen zijn bruto jaarsalarissen):
Verenigde Staten: Landelijke gemiddelden liggen rond $120K–$130K (Indeed rapporteert ongeveer $126.300). Glassdoor noemt ~ $153K als gemiddeld salaris voor data engineers, met senior rollen die $180K overstijgen in grote techhubs. Junior data engineers in de VS (0–3 jaar) verdienen typisch rond de $80–90K, mid-career (~3–5 jaar) rond $110–115K, en seniors vaak boven de $140K. (Eén survey toonde bijvoorbeeld junior ~ $80K, mid ~ $114K en senior ~ $142K.) Toptechhubs betalen nog meer: rollen in Silicon Valley of New York kunnen voor seniorposities makkelijk richting $180K+ gaan.
Verenigd Koninkrijk/Europa: In Londen verdienen mid-level data engineers vaak zo’n £75–100K. Morgan McKinley meldt een Londense bandbreedte van £75–100K voor data engineers, met junior rollen (~0–3 jr) rond £50–75K en seniors (5+ jr) tot £125K. Op het vasteland van Europa liggen salarissen over het algemeen lager dan in de VS: zo verdienen data engineers in Duitsland grofweg €50–70K gemiddeld, en vergelijkbare bedragen (vaak €60–80K) komen veel voor in West-Europa.
Azië-Pacific (APAC): De variatie is groot. In Singapore verdienen data engineers ongeveer S$120–170K per jaar (circa US$90–125K), met senior rollen boven S$240K, volgens recruitmentdata. In Australië verdienen data engineers in Sydney gemiddeld zo’n A$155K (~US$100K). In India liggen salarissen daarentegen veel lager: een typische data engineer verdient rond ₹9–10 lakh (circa US$12K) per jaar voor junior/midniveaus (al kan dit stijgen met ervaring en vooral in MNO’s of startuphubs).
Deze cijfers onderstrepen zowel het effect van senioriteit als regionale verschillen. Als richtlijn levert instappen (junior) ongeveer 50–70% op van het mid-level markttarief, terwijl senior/lead-rollen vaak 20–40% boven het gemiddelde voor mid-career liggen. Uiteindelijk hangt de beloning af van de kosten van levensonderhoud en de lokale markt in elke regio, maar de trend is duidelijk: data engineering betaalt zeer concurrerend, wat de strategische waarde weerspiegelt.
De rol van de data engineer evolueert mee met nieuwe technologieën. Belangrijke trends die het vakgebied beïnvloeden zijn onder meer:
Integratie van AI en machine learning: Nu bedrijven AI omarmen, spelen data engineers een cruciale rol bij het leveren van hoogwaardige data aan ML-systemen. In plaats van data engineering te vervangen, stuwen generatieve AI en ML-tools de vraag naar betere datapijplijnen op. Data engineers bouwen en onderhouden nu de infrastructuur voor het trainen van modellen en het streamen van voorspellingen in productie. Ze implementeren vaak DataOps/MLOps-praktijken om workflows te automatiseren en te zorgen dat modellen toegang hebben tot de data die ze nodig hebben. Kortom, data engineers worden enablers van AI – ze bouwen de grote, schone datasets die AI nodig heeft om te slagen.
Realtime en streamingdata: Het tijdperk van alleen batch-ETL loopt ten einde. Bedrijven hebben in toenemende mate realtime inzichten nodig, dus wenden data engineers zich tot streamingplatforms (Kafka, Flink, Spark Streaming) en zelfs edge computing. Moderne streamingsystemen stellen bedrijven in staat om gebeurtenissen te verwerken en analytics direct te updaten, wat een groot concurrentievoordeel is. Vooruitgang in 5G en edge computing betekent dat data dicht bij de bron met zeer lage latency kan worden verzameld en verwerkt. Data engineers moeten daarom pijplijnen met lage latency ontwerpen en vloeiend zijn in streamverwerkingsframeworks. In de praktijk werk je vaak aan pijplijnen die continu data inladen en transformeren (bijvoorbeeld clickstreams, sensordata of logfeeds) om live dashboards en geautomatiseerde meldingen aan te sturen.
Data mesh- en data fabric-architecturen: Naarmate dataplatforms opschalen, heroverwegen organisaties gecentraliseerde architecturen. Het concept data mesh – elk bedrijfsdomein behandelen als een “mini-dataproduct” in eigendom van het eigen domeinteam – wint aan populariteit. Data engineers werken mogelijk in crossfunctionele teams die specifieke datadomeinen (marketingdata, salesdata, etc.) bezitten, in plaats van dat alle data door één centraal team wordt beheerd. Ondertussen ontstaan ook data fabric-architecturen – die gebruikmaken van uniforme metadata- en integratielagen om data uit meerdere silo’s te verbinden.
Gartner merkt op dat beide benaderingen (mesh en fabric) hot topics zijn: mesh voor decentralisatie en “data als product”, en fabric voor het integreren van gedistribueerde data. In de praktijk helpen nieuwe platforms en tools (zoals domeinspecifieke lakes, catalogusservices en geautomatiseerde datapijplijnen) om deze patronen te implementeren. De kern voor een data engineer: wees voorbereid om in domeingerichte teams te werken en begrijp moderne metadata-/catalogussystemen. (Belangrijk: analisten waarschuwen dat data mesh nog in ontwikkeling is en vaak samen met data-fabricoplossingen wordt gebruikt.)
Cloud-native modernisering: Vrijwel alle data engineering draait nu in de cloud. Bedrijven migreren van on-prem datawarehouses naar cloud datawarehouses en lakehouses (Snowflake, Redshift, Azure Synapse, Databricks, enz.). Cloud-native architecturen – serverloze pijplijnen, beheerde streaming (bijv. Kinesis, Pub/Sub) en schaalbare opslag – zijn sleuteltrends. Data engineers moeten daarom bedreven zijn in clouddiensten en automatisering (Infrastructure-as-Code, CI/CD voor datapijplijnen). Door cloud-native tools te omarmen kun je rekenkracht on demand op- en afschalen, kosten optimaliseren en je focussen op datalogica in plaats van serverbeheer. Kort gezegd: dataplatforms worden gemoderniseerd voor het cloudtijdperk, en data engineers sturen die modernisering aan.
Data governance- en kwaliteitstools: Met groeiende datavolumes en regelgeving rijpen tools voor data governance, lineage en kwaliteit (datacatalogi, contractgedreven pijplijnen, observability). Datacontracten en schemaregisters (die afspraken tussen dataproducenten en -consumenten automatiseren) zijn in opkomst en zorgen ervoor dat teams elkaars pijplijnen niet breken. Als data engineer werk je mogelijk met nieuwe governancekaders en tools (zoals Great Expectations, Monte Carlo of open-source datacatalogi) om je organisatie te helpen haar data te vertrouwen. (Een trend is bijvoorbeeld het gebruik van “datacontracten” om consistente schema’s tussen teams af te dwingen.)
DevOps en automatisering: Tot slot vervaagt de grens tussen software engineering en data engineering verder. Veel organisaties adopteren DevOps-praktijken voor data (vaak DataOps of MLOps genoemd). Dit betekent versiebeheer voor datacode, geautomatiseerd testen van datapijplijnen en continuous delivery van datainfrastructuur. Automatiseringsframeworks (zoals Apache Airflow voor pijplijnen, Terraform of CloudFormation voor infrastructuur) zijn nu standaard. Vaardig blijven in deze DevOps-tools en -praktijken helpt je om datasolutions sneller en betrouwbaarder te deployen.
Data engineering is een van de meest gevraagde banen in het data-scencelandschap en zeker een uitstekende carrièrekeuze voor ambitieuze dataprofessionals. Als je vastbesloten bent om data engineer te worden maar niet weet waar te beginnen, raad ik je sterk aan om onze career track Data Engineer in Python te volgen, die je de praktische kennis geeft om vol vertrouwen als data engineer aan de slag te gaan. Je kunt ook starten met onze cursus Introduction to Data Engineering of de volledige gids om data engineering vanaf nul te leren verkennen.
Leer meer over data engineering met deze cursussen!
Leerpad
Leerpad
Cursus
blog
Adel Nehme
15 min
