
Lernpfad
Dateningenieur in Python
40 Std.
Der Bereich Data Engineering boomt weltweit, da Unternehmen immer mehr auf datengestützte Erkenntnisse angewiesen sind. In großen Berichten, wie dem kürzlich vom Weltwirtschaftsforum veröffentlichten, werden "Big-Data-Spezialisten" (zu denen auch Dateningenieure gehören) zu den am schnellsten wachsenden Berufen im Tech-Bereich gezählt. Entgegen früherer KI-Angstprognosen werden die Aufgaben der Datentechnik immer umfangreicher.
Dateningenieure spielen beim Aufbau der Infrastruktur für KI-Systeme eine immer wichtigere Rolle. In der Praxis bedeutet das, dass es Tausende von offenen Stellen für Dateningenieure gibt, und die Arbeitgeber in allen Branchen suchen händeringend nach Talenten.
Andere angrenzende Data-Engineering-Funktionen, wie KI- und Machine-Learning-Spezialisten und Data-Warehousing-Spezialisten, stehen ganz oben auf der Liste. In einem separaten Artikel werden einige der anderen Top-Karrieren im Bereich Analytik vorgestellt.

Wenn du darüber nachdenkst, Dateningenieur/in zu werden, findest du in diesem Blogbeitrag alles, was du wissen musst. Wir werden erkunden, was ein Data Engineer ist, welche Aufgaben und Verantwortlichkeiten er in seiner täglichen Arbeit hat und warum der Beruf des Data Engineers heute so interessant ist. Wir gehen auch auf die Fähigkeiten und Qualifikationen ein, die du brauchst, um Dateningenieur/in zu werden, und geben dir einige Tipps, die dir helfen, deine erste Stelle in der Branche zu bekommen.
Auf einen Blick sieht der Lernpfad zum/zur Technischen Dateningenieur/in jedoch folgendermaßen aus:
Viele dieser Punkte werden wir in diesem Beitrag detailliert behandeln, wenn wir erkunden, wie man Dateningenieur/in wird.
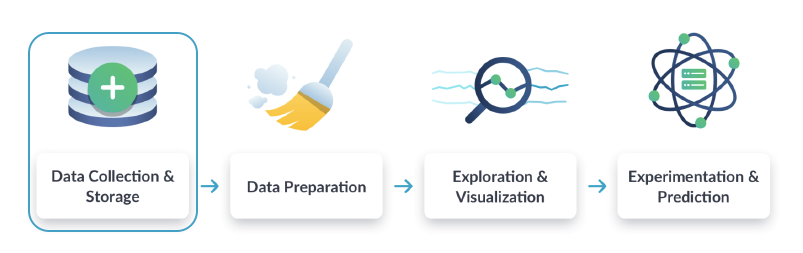
Data Engineers sind dafür verantwortlich, die Grundlagen für die Erfassung, Speicherung, Umwandlung und Verwaltung von Daten in einem Unternehmen zu schaffen. Sie kümmern sich um den Entwurf, die Erstellung und die Wartung der Datenbankarchitektur und der Datenverarbeitungssysteme und sorgen dafür, dass die anschließende Arbeit der Analyse, der Visualisierung und der Entwicklung von Machine Learning-Modellen nahtlos, kontinuierlich, sicher und effektiv durchgeführt werden kann.
Kurz gesagt: Data Engineers sind die technischsten Profile im Bereich Data Science und spielen eine wichtige Brückenfunktion zwischen Software- und Anwendungsentwicklern und den traditionellen Data Science Positionen.
Data Engineers sind für die erste Phase des traditionellen Data Science Workflows verantwortlich: die Sammlung und Speicherung von Daten. Sie sorgen dafür, dass die große Menge an Daten, die aus verschiedenen Quellen gesammelt wird, für andere Data-Science-Spezialisten wie Datenanalysten und Data Scientists als Rohmaterial zugänglich wird.
Einerseits geht es um die Entwicklung und Pflege skalierbarer Dateninfrastrukturen mit hoher Verfügbarkeit, Leistung und der Fähigkeit, neue Technologien zu integrieren. Auf der anderen Seite haben Dateningenieure auch die Aufgabe, die Bewegung und den Status von Daten in diesen Systemen zu überwachen.
Data Science Workflow
Dateningenieure sind die Hauptakteure bei der Entwicklung und Pflege der Datenarchitektur eines Unternehmens. Sie sind darauf spezialisiert, große Datensätze für Analysten aufzubereiten. Wenn ein Analyst Informationen interpretieren muss, erstellt der Data Engineer Programme und Routinen, um die Daten in einem geeigneten Layout aufzubereiten.
Das bedeutet, dass der Alltag eines Dateningenieurs im Wesentlichen aus drei Prozessen besteht:
Der Prozess der Datenerfassung und -speicherung kann jedoch äußerst komplex sein. Es können verschiedene Datenquellen beteiligt sein, und diese Datenquellen können unterschiedliche Arten von Daten enthalten. Je größer das Volumen, die Vielfalt und die Geschwindigkeit der Daten sind, desto komplexer wird die Arbeit des Dateningenieurs.
Dateningenieure entwickeln sogenannte Datenpipelines, um sicherzustellen, dass die durchgeführten Aufgaben zeitnah, robust und skalierbar sind. Eine Datenpipeline verschiebt Daten in definierten Phasen, zum Beispiel beim Laden von Daten aus einer lokalen Datenbank in einen Cloud-Dienst.
Ein wichtiges Merkmal ist, dass Pipelines diese Bewegung automatisieren. Anstatt einen Datentechniker zu bitten, jedes Mal, wenn neue Daten erstellt werden, ein Programm manuell auszuführen, kann er die Aufgabe so planen, dass sie stündlich, täglich oder nach einem bestimmten Ereignis ausgelöst wird.
Da der Prozess automatisiert ist, müssen die Datenpipelines überwacht werden. Glücklicherweise können Warnmeldungen automatisch generiert werden. Datenpipelines sind nicht für alle Data-Science-Projekte notwendig, aber sie sind es, wenn du mit vielen Daten aus verschiedenen Quellen arbeitest, wie es normalerweise in datengetriebenen Unternehmen der Fall ist. Wenn du wissen willst, wie Datenpipelines in der Praxis funktionieren, empfehlen wir dir unseren Kurs Building Data Engineering Pipelines in Python.
Du fragst dich immer noch, was ein Dateningenieur macht? In unserem vollständigen Artikel erfährst du mehr.
Im Folgenden haben wir die Schritte beschrieben, die du für eine Karriere als Dateningenieur/in unternehmen musst. Die genauen Schritte hängen von deinen aktuellen Fähigkeiten und Erfahrungen ab, aber dieser Prozess kann dich dabei unterstützen, von Anfang an ein/e Dateningenieur/in zu werden.
Data Engineering ist noch ein junger Beruf. Daher bieten nur wenige Universitäten und Hochschulen einen Abschluss in Datentechnik an. Dateningenieure haben in der Regel einen Hintergrund in Datenwissenschaft, Softwaretechnik, Mathematik oder einem wirtschaftsbezogenen Fachgebiet.
Je nach Beruf oder Branche bekommen die meisten Datentechniker/innen ihren ersten Einstiegsjob nach dem Bachelor-Abschluss. Angesichts der hochspezialisierten Fähigkeiten, die für die Aufgaben von Dateningenieuren erforderlich sind, überwiegen in vielen Fällen jedoch Wissen und Kompetenzen gegenüber der Ausbildung.
Wenn du also eine formale Ausbildung machen willst, solltest du einen Abschluss wählen, der Systemarchitektur, Programmierung und Datenbankkonfiguration in den Lehrplan einschließt.
Du kannst auch Optionen wie den DataCamp Lernpfad Data Engineer with Python wählen, der dir alle Grundlagen vermittelt, die du brauchst, um eine effektive Datenarchitektur aufzubauen, die Datenverarbeitung zu optimieren und große Datensysteme zu warten.
Dateningenieure und -ingenieurinnen benötigen eine ganze Reihe von technischen Fähigkeiten, um ihre hochkomplexen Aufgaben zu bewältigen. Es ist jedoch sehr schwierig, eine detaillierte und umfassende Liste von Fähigkeiten und Kenntnissen zu erstellen, die für eine erfolgreiche Tätigkeit im Bereich Data Engineering erforderlich sind; schließlich entwickelt sich das Data-Science-Ökosystem schnell weiter und es kommen ständig neue Technologien und Systeme auf. Das bedeutet, dass Dateningenieure und -ingenieurinnen ständig lernen müssen, um mit den technologischen Durchbrüchen Schritt zu halten.
Nichtsdestotrotz gibt es hier eine nicht erschöpfende Liste von Fähigkeiten, die du entwickeln musst, um Dateningenieur/in zu werden:
Datentechniker/innen verbringen einen beträchtlichen Teil ihrer täglichen Arbeit damit, Datenbanken zu bedienen, entweder um Daten zu sammeln, zu speichern, zu übertragen, zu bereinigen oder einfach nur abzufragen. Deshalb müssen Datentechniker/innen über gute Kenntnisse im Datenbankmanagement verfügen. Das bedeutet, dass du SQL (Structured Query Language), die grundlegende Sprache für die Interaktion mit Datenbanken, fließend beherrschst und dich mit einigen der beliebtesten SQL-Dialekte auskennst, darunter MySQL, SQL Server und PostgreSQL.
Neben relationalen Datenbanken müssen Dateningenieure auch mit NoSQL-Datenbanken ("Not only SQL") vertraut sein, die sich für Big Data und Echtzeitanwendungen immer mehr durchsetzen.
Auch wenn die Zahl der NoSQL-Engines zunimmt, sollten Dateningenieure daher zumindest den Unterschied zwischen den NoSQL-Datenbanktypen und die Anwendungsfälle für jede von ihnen verstehen. Wenn du verwirrt bist, was NoSQL ist und wie es sich von SQL unterscheidet, ist unser Kurs NoSQL-Konzepte ein guter Ort, um Klarheit zu schaffen.
Wie in anderen Bereichen der Datenwissenschaft ist das Programmieren eine Pflichtaufgabe für Dateningenieure. Neben SQL verwenden Data Engineers auch andere Programmiersprachen für eine Vielzahl von Aufgaben. Es gibt viele Programmiersprachen, die im Data Engineering eingesetzt werden können, aber Python ist sicherlich eine der besten Optionen.
Python ist die Lingua franca in der Datenwissenschaft und eignet sich perfekt für die Ausführung von ETL-Jobs und das Schreiben von Datenpipelines. Mehr darüber, wofür Python verwendet wird, erfährst du in einem anderen Beitrag.
Ein weiterer Grund, Python zu verwenden, ist die hervorragende Integration mit Tools und Frameworks, die für das Data Engineering wichtig sind, wie Apache Airflow und Apache Spark. Viele dieser Open-Source-Frameworks laufen auf der Java Virtual Machine. Wenn dein Unternehmen mit diesen Frameworks arbeitet, wirst du wahrscheinlich auch Java oder Scala lernen müssen.
In den letzten Jahren sind verteilte Systeme in der Datenwissenschaft allgegenwärtig geworden. Ein verteiltes System ist eine Computerumgebung, in der verschiedene Komponenten auf mehrere Computer (auch als Cluster bezeichnet) in einem Netzwerk verteilt sind.
Verteilte Systeme teilen die Arbeit auf den Cluster auf und koordinieren die Anstrengungen, um die Arbeit effizienter zu erledigen. Verteilte Computing-Frameworks wie Apache Hadoop und Apache Spark sind für die Verarbeitung riesiger Datenmengen konzipiert und bilden die Grundlage für einige der beeindruckendsten Big-Data-Anwendungen. Die Beherrschung eines dieser Frameworks ist für jeden angehenden Dateningenieur wichtig.
Cloud Computing ist eines der heißesten Themen in der Datenwissenschaft. Die Nachfrage nach Cloud-basierten Lösungen verändert die Landschaft rapide. Als Datentechniker/in musst du heute in hohem Maße die Geschäftssysteme deines Unternehmens mit Cloud-basierten Systemen verbinden.
Mit dem Aufkommen von Diensten wie Amazon Web Services (AWS), Azure und Google Cloud kann der gesamte Datenworkflow in der Cloud stattfinden. Deshalb muss ein guter Dateningenieur die Cloud-Dienste, ihre Vor- und Nachteile und ihre Anwendung in Big-Data-Projekten kennen und Erfahrung mit ihnen haben. Du solltest zumindest mit einer Plattform wie AWS oder Azure vertraut sein, da sie am weitesten verbreitet sind.
Um erste praktische Erfahrungen mit Cloud Data Warehouses zu sammeln, probiere unser Exploring London's Travel Network Project aus. Es bietet eine großartige Möglichkeit, direkt in deinem Browser mit Amazon Redshift, Google BigQuery und Snowflake zu arbeiten.
Eine der Hauptaufgaben von Data Engineers ist es, mit ETL-Technologien und Orchestrierungs-Frameworks Datenpipelines zu erstellen. In diesem Abschnitt könnten wir viele Technologien aufzählen, aber der Data Engineer sollte einige der bekanntesten kennen oder mit ihnen vertraut sein, wie z.B. Apache Airflow und Apache NiFi. Airflow ist ein Orchestrierungs-Framework. Es ist ein Open-Source-Tool zur Planung, Erstellung und Verfolgung von Datenpipelines. NiFi ist perfekt für einen grundlegenden, wiederholbaren Big Data ETL-Prozess.
Einige der innovativsten Data Science-Anwendungen nutzen Echtzeitdaten. Daher steigt die Nachfrage nach Bewerbern, die mit Stream-Processing-Frameworks vertraut sind. Deshalb ist das Erlernen des Umgangs mit Streaming-Processing-Tools wie Flink, Kafka Streams oder Spark Streaming ein guter Schritt für Datentechniker/innen, die ihre Karriere auf die nächste Stufe heben wollen.
Die meisten Jobs und Routinen der Cloud und anderer Big-Data-Tools und -Frameworks werden mit Shell-Befehlen und Skripten ausgeführt. Datentechniker müssen mit dem Terminal vertraut sein, um Dateien zu bearbeiten, Befehle auszuführen und im System zu navigieren. Lerne mehr mit unserem Bash-Skript-Tutorial.
Nicht zuletzt brauchen Dateningenieure auch Kommunikationsfähigkeiten, um abteilungsübergreifend zu arbeiten und die Bedürfnisse von Datenanalysten, Datenwissenschaftlern und Geschäftsführern zu verstehen. Je nach Unternehmen müssen Dateningenieure auch wissen, wie man Dashboards, Berichte und andere Visualisierungen entwickelt, um mit den Stakeholdern zu kommunizieren.
Der nächste Schritt auf dem Weg zum Dateningenieur ist die Arbeit an einigen Projekten, in denen du deine Fähigkeiten und dein Verständnis der Kernthemen unter Beweis stellen kannst. In unserem Leitfaden zum Aufbau eines Data Science Portfolios findest du einige Anregungen.
Um potenzielle Arbeitgeber zu beeindrucken, musst du die bereits erwähnten Fähigkeiten unter Beweis stellen, was bedeutet, dass du an verschiedenen Projekten arbeiten musst. DataLab bietet ein kollaboratives Cloud-basiertes Notebook, mit dem du an deinen eigenen Projekten arbeiten kannst. Das heißt, du kannst Daten analysieren, mit anderen zusammenarbeiten und Erkenntnisse teilen.
Du kannst dein Wissen auch in verschiedenen Data-Science-Projekten anwenden. So kannst du reale Probleme über deinen Browser lösen und gleichzeitig einen Beitrag zu deinem Data-Engineering-Portfolio leisten.
Wenn du dich bereit fühlst, ein bestimmtes Geschäftsfeld deiner Wahl zu erkunden, kannst du dich darauf konzentrieren, Fachwissen zu erwerben und an einzelnen Projekten zu arbeiten, die mit diesem speziellen Bereich zusammenhängen.
Data Engineering ist eine der gefragtesten Positionen in der Data-Science-Branche. Von Big Tech im Silicon Valley bis hin zu kleinen datengetriebenen Start-ups in allen Branchen suchen Unternehmen nach Dateningenieuren, die ihnen helfen, ihre Datenressourcen zu skalieren und optimal zu nutzen. Gleichzeitig haben die Unternehmen Schwierigkeiten, die richtigen Bewerber/innen zu finden, da sie ein breites und hochspezialisiertes Spektrum an Fähigkeiten benötigen, um die Anforderungen eines Unternehmens zu erfüllen.
Vor diesem Hintergrund gibt es keine perfekte Formel, um deinen ersten Job als Dateningenieur zu bekommen. In vielen Fällen kommen Data Engineers in ihre Position, nachdem sie aus anderen Data-Science-Rollen innerhalb desselben Unternehmens, wie z.B. Data Scientist oder Datenbankadministrator, gewechselt sind.
Wenn du stattdessen in Jobportalen nach Stellenangeboten im Bereich Data Engineering suchst, solltest du beachten, dass es viele Stellenangebote gibt, die den Titel "Data Engineer" enthalten, darunter Cloud Data Engineer, Big Data Engineer und Data Architect. Die spezifischen Fähigkeiten und Anforderungen sind von Stelle zu Stelle unterschiedlich. Der Schlüssel ist also, eine bessere Übereinstimmung zwischen deinen Kenntnissen und den Anforderungen des Unternehmens zu finden.
In unserem ausführlichen Leitfaden für Bewerbungen in der Datenwissenschaft erfährst du, wie du dich von anderen Bewerbern abheben kannst. Du brauchst wahrscheinlich ein umfangreiches Portfolio, das eine Reihe von Fähigkeiten zeigt. Nützliche Informationen darüber, was Personalchefs wollen, findest du auch in unserem Artikel über das Verfassen einer Stellenbeschreibung für Datentechniker.
Die Antwort ist einfach: Lerne weiter. Es gibt viele Wege, um dein Fachwissen zu vertiefen und dein Data Engineering-Toolkit zu erweitern.
Du könntest dich auch für eine weitere formale Ausbildung entscheiden, sei es ein Bachelor-Abschluss in Datenwissenschaft oder Informatik, einem eng verwandten Bereich, oder ein Master-Abschluss in Data Engineering.
Neben der Ausbildung ist die Praxis der Schlüssel zum Erfolg. Die Arbeitgeber in diesem Bereich suchen nach Bewerbern mit einzigartigen Fähigkeiten und einer starken Beherrschung von Software und Programmiersprachen. Je mehr du deine Programmierfähigkeiten in persönlichen Projekten trainierst und Big-Data-Tools und -Frameworks ausprobierst, desto mehr Chancen hast du, dich im Bewerbungsprozess abzuheben. Um dein Fachwissen unter Beweis zu stellen, ist es eine gute Option, dich in Data Engineering zertifizieren zu lassen.
Wenn du Schwierigkeiten hast, deine erste Stelle als Data Engineer zu finden, kannst du dich auch auf andere Einstiegspositionen im Bereich Data Science bewerben. Letztendlich ist Data Science ein kollaboratives Feld mit vielen Themen und Fähigkeiten, die übergreifend für alle Datenfunktionen sind. Diese Stellen bieten dir wertvolle Einblicke und Erfahrungen, die dir helfen werden, deine Traumstelle als Dateningenieur zu bekommen.
Vorstellungsgespräche in der Datentechnik werden normalerweise in technische und nicht-technische Teile unterteilt. In unserem vollständigen Leitfaden findest du die wichtigsten Fragen und Antworten zu Data Engineering-Interviews.
Kurz gesagt, kannst du Fragen zu vier Themen erwarten:
Personalverantwortliche wollen wissen, welche Erfahrungen du in Bezug auf die Stelle als Datentechniker/in gemacht hast. Achte darauf, dass du in deinem Lebenslauf deine bisherige Arbeit in Data-Science-Positionen und -Projekten hervorhebst, und bereite dich darauf vor, alle Details darüber zu nennen, denn diese Informationen sind für Personalverantwortliche wichtig, um deine technischen Fähigkeiten, deine Problemlösungskompetenz, deine Kommunikationsfähigkeit und dein Projektmanagement zu beurteilen.
Dies ist wahrscheinlich der stressigste Teil eines Vorstellungsgesprächs in der Datenwissenschaft. In der Regel wirst du gebeten, ein Problem in wenigen Zeilen Code innerhalb kurzer Zeit mit Python oder einem Daten-Framework wie Spark zu lösen.
Deine Übung könnte zum Beispiel darin bestehen, eine einfache Datenpipeline zum Laden und Bereinigen von Daten zu erstellen. Auch wenn das Problem nicht sehr komplex sein sollte, kann sich die Anspannung des Augenblicks negativ auf deine Leistung auswirken. Wenn du mit dieser Art von Test nicht vertraut bist, kannst du vorher mit einigen Kodierfragen üben.
Ohne solide SQL-Kenntnisse wirst du in deiner Karriere als Dateningenieur nicht weit kommen. Deshalb kann es sein, dass du zusätzlich zum Programmiertest eine Aufgabe lösen sollst, bei der du SQL verwenden musst. Normalerweise besteht die Übung darin, effiziente Abfragen zu schreiben, um einige Daten in Datenbanken zu verarbeiten.
Dies ist der konzeptionellste Teil des technischen Interviews und wahrscheinlich auch der schwierigste. Der Entwurf von Datenarchitekturen ist eine der wichtigsten Aufgaben von Dateningenieuren. In diesem Teil wirst du aufgefordert, eine Datenlösung von Anfang bis Ende zu entwerfen, die normalerweise drei Aspekte umfasst: Datenspeicherung, Datenverarbeitung und Datenmodellierung.
In Anbetracht des schnell wachsenden Umfangs der Data Science-Ökosysteme sind die Möglichkeiten für die Gestaltung endlos. Du musst bereit sein, das Für und Wider und die möglichen Nachteile deiner Entscheidungen zu diskutieren.
Wenn du den technischen Teil abgeschlossen hast, besteht der letzte Schritt des Data-Engineering-Interviews aus einem persönlichen Gespräch mit einem oder mehreren deiner potenziellen Teammitglieder. Das Ziel? Um herauszufinden, wer du bist und wie du in das Team passen würdest.
Aber denk daran, dass das Gespräch mit dem Datentechniker ein zweiseitiges Gespräch ist, d.h. du solltest ihm auch Fragen stellen, um herauszufinden, ob du dich als Teil des Teams sehen könntest.
Die Gehälter für Dateningenieure sind im Vergleich zu vielen IT-Berufen hoch, was die Nachfrage widerspiegelt. Die Zahlen variieren je nach Land, Stadt und Dienstalter, aber wir können einige ungefähre Spannen skizzieren (alle Zahlen sind Jahresgehälter vor Steuern):
Vereinigte Staaten: Der nationale Durchschnitt liegt zwischen 120.000 und 130.000 $(Indeed berichtet über 126.300 $).). Glassdoor nennt sogar ~$153K als durchschnittliches Gehalt für Datentechniker/innen im Jahr 2024. Berufsanfänger in den USA (0-3 Jahre) verdienen in der Regel zwischen $80 und 90.000, in der Mitte der Karriere (~3-5 Jahre) etwa $110-115.000 und im höheren Alter oft über $140.000.. (Zum Beispiel ergab eine Umfrage, dass Junior ~$80K, Mid ~$114K, und Senior ~$142K.) Top-Technologiestandorte zahlen sogar noch mehr: Positionen im Silicon Valley oder in New York können leicht $180K+ für leitende Positionen erreichen.
Vereinigtes Königreich/Europa: In London verdienen Dateningenieure auf mittlerer Ebene oft zwischen £75 und 100.000. Morgan McKinley berichtet, dass die Spanne für Dateningenieure in London zwischen £75 und £100 liegt, wobei Junior-Positionen (~0-3 Jahre) etwa £50-75K und Senior-Positionen (5+ Jahre) bis zu £125K betragen.. In Kontinentaleuropa sind die Gehälter in der Regel niedriger als in den USA: So verdienen Data Engineers in Deutschland im Durchschnitt etwa 50-70 T€.und ähnliche Zahlen (oft im Bereich von 60-80 000 €) sind in Westeuropa üblich.
Asien-Pazifik (APAC): Es gibt große Unterschiede. In Singapur verdienen Dateningenieure ungefähr S$120-170K pro Jahr (etwa US$90-125K)mit leitenden Positionen von mehr als 240.000 S$, wie aus den Rekrutierungsdaten hervorgeht. In Australien verdienen Dateningenieure in Sydney im Durchschnitt etwa A$155K (~US$100K).. Im Gegensatz dazu sind die Gehälter in Indien viel niedriger: Ein typischer Dateningenieur verdient etwa ₹9-10 lakh (ca. 12.000 US$) pro Jahr für Einsteiger/Mittelstufe (mit zunehmender Erfahrung und vor allem in multinationalen Unternehmen oder Start-up-Zentren kann dieser Wert jedoch steigen).
Diese Zahlen unterstreichen den Senioritätseffekt und die regionalen Unterschiede. Als Richtwert gilt, dass man als Berufseinsteiger (Junior) etwa 50-70% des mittleren Marktlohns erhält, während Senior-/Leader-Positionen oft 20-40% über dem mittleren Karrieredurchschnitt liegen. Letztlich hängt die Vergütung von den Lebenshaltungskosten und dem lokalen Markt in jeder Region ab, aber der allgemeine Trend ist klar: Die Bezahlung in der Datentechnik ist sehr wettbewerbsfähigund spiegelt damit seine strategische Bedeutung wider.
Die Rolle des Dateningenieurs entwickelt sich mit den neuen Technologien weiter. Zu den wichtigsten Trends in diesem Bereich gehören:
Integration von KI und maschinellem Lernen: Wenn Unternehmen KI einsetzen, spielen Datentechniker/innen eine entscheidende Rolle bei der Versorgung von ML-Systemen mit hochwertigen Daten. Generative KI- und ML-Tools ersetzen das Data Engineering nicht, sondern steigern die Nachfrage nach besseren Datenpipelines.. Dateningenieure bauen jetzt die Infrastruktur für das Training von Modellen und das Streaming von Vorhersagen in der Produktion auf und pflegen sie. Sie setzen häufig DataOps/MLOps-Verfahren ein, um Arbeitsabläufe zu automatisieren und sicherzustellen, dass die Modelle auf die benötigten Daten zugreifen können. Dateningenieurinnen und -ingenieure werden zu Befähigerinnen und Befähigern von KI - sie erstellen die großen, sauberen Datensätze, die KI für ihren Erfolg braucht.
Daten in Echtzeit und Streaming: Die Ära der reinen Batch-ETL geht zu Ende. Unternehmen benötigen immer mehr Echtzeit-Einsichten, daher wenden sich Dateningenieure Streaming-Plattformen (Kafka, Flink, Spark Streaming) und sogar Edge Computing zu. Moderne Streaming-Systeme ermöglichen es Unternehmen, Ereignisse zu verarbeiten und Analysen sofort zu aktualisieren, was ein wichtiger Wettbewerbsvorteil ist. Fortschritte bei 5G und Edge Computing bedeuten, dass Daten nahe an der Quelle mit sehr geringer Latenz gesammelt und verarbeitet werden können. Dateningenieure müssen daher Pipelines mit geringer Latenz entwerfen und sich mit Stream-Processing-Frameworks auskennen. In der Praxis arbeitest du oft an Pipelines, die kontinuierlich Daten aufnehmen und umwandeln (z. B. Clickstreams, Sensordaten oder Log-Feeds), um Live-Dashboards und automatische Warnmeldungen zu erstellen.
Data Mesh und Data Fabric Architekturen: Da die Datenplattformen immer größer werden, überdenken Unternehmen ihre zentralisierten Architekturen. Das Konzept des Datennetzes, bei dem jeder Unternehmensbereich als "Mini-Datenprodukt" behandelt wird, das dem jeweiligen Bereichsteam gehört, hat an Popularität gewonnen. Datentechniker/innen können in funktionsübergreifenden Teams arbeiten, die für bestimmte Datenbereiche zuständig sind (Marketingdaten, Verkaufsdaten usw.), anstatt dass alle Daten von einem einzigen zentralen Team verwaltet werden. In der Zwischenzeit sind auch Data-Fabric-Architekturen auf dem Vormarsch, die einheitliche Metadaten und Integrationsschichten nutzen, um Daten aus verschiedenen Silos miteinander zu verbinden.
Gartner stellt fest, dass beide Ansätze (Mesh und Fabric) ein heißes Thema sind: Mesh für Dezentralisierung und "Daten als Produkt" und Fabric für die Integration verteilter Daten. In der Praxis helfen neue Plattformen und Tools (wie domänenspezifische Seen, Katalogdienste und automatisierte Datenpipelines) bei der Umsetzung dieser Muster. Ein Dateningenieur sollte darauf vorbereitet sein, in fachlich orientierten Teams zu arbeiten und moderne Metadaten-/Katalogsysteme zu verstehen. (Analysten weisen darauf hin, dass sich die Datenverflechtung noch in der Entwicklung befindet und oft zusammen mit Data-Fabric-Lösungen verwendet wird..)
Cloud-native Modernisierung: Nahezu die gesamte Datentechnik läuft heute in der Cloud. Unternehmen migrieren von On-Prem-Data Warehouses zu Cloud Data Warehouses und Lakehouses (Snowflake, Redshift, Azure Synapse, Databricks usw.). Cloud-native Architekturen - serverlose Pipelines, verwaltetes Streaming (z. B. Kinesis, Pub/Sub) und skalierbarer Speicher - sind wichtige Trends. Dateningenieure sollten daher mit Cloud-Diensten und Automatisierung (Infrastructure-as-Code, CI/CD für Datenpipelines) vertraut sein. Der Einsatz von Cloud-nativen Tools bedeutet, dass du die Rechenleistung nach Bedarf skalieren, die Kosten optimieren und dich auf die Datenlogik statt auf den Serverbetrieb konzentrieren kannst. Kurz gesagt: Datenplattformen werden für die Cloud-Ära modernisiert, und Dateningenieure treiben diese Modernisierung voran.
Tools für Datenmanagement und -qualität: Mit dem wachsenden Datenvolumen und den immer strenger werdenden Vorschriften reifen auch die Werkzeuge für Data Governance, Lineage und Qualität (Datenkataloge, vertragsgesteuerte Pipelines, Beobachtbarkeit). Datenverträge und Schemaregistrierungen (die Vereinbarungen zwischen Datenproduzenten und -konsumenten automatisieren) liegen im Trend und sorgen dafür, dass sich die Teams nicht gegenseitig die Pipelines kaputt machen. Als Data Engineer arbeitest du vielleicht mit neuen Governance-Frameworks und Tools (wie Great Expectations, Monte Carlo oder Open-Source-Datenkatalogen), damit dein Unternehmen seinen Daten vertrauen kann. (Ein Trend ist zum Beispiel die Verwendung von "Datenverträgen", um einheitliche Schemata in verschiedenen Teams durchzusetzen..)
DevOps und Automatisierung: Schließlich verschwimmt die Grenze zwischen Software Engineering und Data Engineering immer mehr. Viele Unternehmen übernehmen DevOps-Praktiken für Daten (oft DataOps oder MLOps genannt). Das bedeutet Versionskontrolle für Datencode, automatisierte Tests von Datenpipelines und kontinuierliche Bereitstellung der Dateninfrastruktur. Automatisierungsframeworks (wie Apache Airflow für Pipelines, Terraform oder CloudFormation für die Infrastruktur) sind heute Standard. Wenn du diese DevOps-Tools und -Praktiken beherrschst, kannst du Datenlösungen schneller und zuverlässiger bereitstellen.
Data Engineering ist einer der gefragtesten Berufe in der Data-Science-Landschaft und sicherlich eine gute Berufswahl für angehende Datenexperten. Wenn du unbedingt Dateningenieur/in werden willst, aber nicht weißt, wie du anfangen sollst, empfehlen wir dir unseren Lernpfad Dateningenieur/in mit Python, der dir das solide und praktische Wissen vermittelt, das du brauchst, um ein/e Experte/in für Datentechnik zu werden.
Unsere Zertifizierungsprogramme helfen dir, dich von anderen abzuheben und potenziellen Arbeitgebern zu beweisen, dass deine Fähigkeiten für den Job geeignet sind.

Lerne mehr über Data Engineering mit diesen Kursen!
Lernpfad
Lernpfad
Kurs
Blog
Matt Crabtree
14 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Tutorial
Laiba Siddiqui

