
Programma
Ingegnere dei dati in Python
40 h
Il settore del data engineering è in forte crescita in tutto il mondo, dato che le organizzazioni fanno sempre più affidamento su insight basati sui dati. Report importanti, come quello pubblicato di recente dal World Economic Forum, collocano i “big data specialists” (che includono i data engineer) tra i lavori tech in più rapida crescita. Contrariamente alle prime previsioni allarmistiche sull’AI, i ruoli di data engineering stanno aumentando.
I data engineer sono sempre più cruciali nella costruzione dell’infrastruttura che alimenta i sistemi di AI. In pratica, questo significa che ci sono migliaia di offerte di lavoro per data engineer, con datori di lavoro in tutti i settori alla ricerca di talenti.
Altri ruoli affini al data engineering, come gli specialisti di AI e machine learning e gli specialisti di data warehousing, sono ai primi posti. Un articolo a parte illustra alcune delle altre migliori carriere nell’analytics.

Se stai pensando di diventare data engineer, in questo post trovi tutto ciò che ti serve. Vedremo cos’è un data engineer, quali sono ruoli e responsabilità nel lavoro quotidiano e perché il data engineering è una carriera così gratificante nel 2026. Ti illustrerò anche le competenze e le qualifiche necessarie e condividerò consigli per aiutarti a ottenere la tua prima posizione nel settore.
In breve, il percorso tecnico per diventare data engineer è il seguente:
Approfondiremo molti di questi punti nel post, esplorando come diventare data engineer.
I data engineer sono responsabili di gettare le basi per l’acquisizione, l’archiviazione, la trasformazione e la gestione dei dati in un’organizzazione. Gestiscono la progettazione, la creazione e la manutenzione dell’architettura dei database e dei sistemi di elaborazione dei dati, assicurando che il successivo lavoro di analisi, visualizzazione e sviluppo di modelli di machine learning possa essere svolto in modo fluido, continuo, sicuro ed efficace.
In sintesi, i data engineer sono i profili più tecnici nell’ambito della data science, svolgendo un ruolo di collegamento fondamentale tra sviluppatori software e di applicazioni e le posizioni tradizionali di data science.
I data engineer sono responsabili della prima fase del workflow tradizionale di data science: il processo di raccolta e archiviazione dei dati. Si assicurano che l’enorme mole di dati raccolti da fonti diverse diventi materia prima accessibile per altri specialisti dei dati, come data analyst e data scientist.
Da un lato, ciò comporta lo sviluppo e la manutenzione di infrastrutture dati scalabili con alta disponibilità, prestazioni e capacità di integrare nuove tecnologie. Dall’altro, ai data engineer spetta anche il monitoraggio del movimento e dello stato dei dati all’interno di questi sistemi.
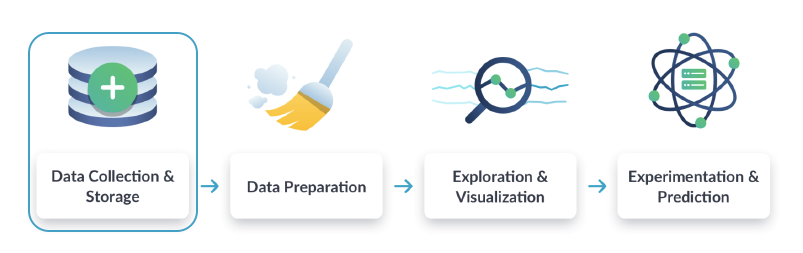
Workflow di Data Science
I data engineer sono figure chiave nello sviluppo e nella manutenzione dell’architettura dati di qualsiasi azienda. Sono specialisti nel preparare grandi dataset per l’uso da parte degli analyst. Quando un analista deve interpretare informazioni, il data engineer crea programmi e routine per preparare i dati in un formato adatto.
Di conseguenza, la giornata tipo di un data engineer si muove fondamentalmente tra tre processi:
Tuttavia, il processo di raccolta e archiviazione può essere estremamente complesso. Possono essere coinvolte diverse fonti, con tipologie di dati differenti. All’aumentare del volume, della varietà e della velocità dei dati, cresce anche la complessità del lavoro del data engineer.
I data engineer sviluppano le cosiddette data pipeline per garantire che le attività siano tempestive, robuste e scalabili. Una data pipeline sposta i dati attraverso fasi definite; un esempio è il caricamento di dati da un database on-premise a un servizio cloud.
Una caratteristica chiave è che le pipeline automatizzano questo movimento. Invece di chiedere a un data engineer di eseguire manualmente un programma ogni volta che vengono creati nuovi dati, si può schedulare l’attività perché si attivi ogni ora, ogni giorno o al verificarsi di un certo evento.
Poiché il processo è automatizzato, le pipeline devono essere monitorate. Fortunatamente, è possibile generare avvisi automaticamente. Le pipeline non sono necessarie in tutti i progetti di data science, ma lo sono quando si lavora con molti dati provenienti da fonti diverse, come avviene normalmente nelle aziende data-driven. Se ti interessa capire come funzionano le data pipeline in pratica, ti consigliamo il corso Building Data Engineering Pipelines in Python.
Hai ancora dubbi su cosa fa un data engineer? Dai un’occhiata al nostro articolo completo per saperne di più.
Il data engineering si sovrappone ad altri ruoli data, il che può creare confusione nella pianificazione della carriera. Ecco come si confrontano i tre ruoli principali:
| Aspetto | Data Engineer | Data Scientist | Data Analyst |
|---|---|---|---|
| Focus principale | Costruzione di infrastrutture e pipeline dati | Estrazione di insight con modelli di ML | Business intelligence e reporting |
| Strumenti core | SQL, Python, Spark, Kafka, Airflow | Python, R, TensorFlow, scikit-learn | SQL, Excel, Tableau, Power BI |
| Output chiave | Pipeline ETL automatizzate, data warehouse | Modelli predittivi, esperimenti | Dashboard, report, metriche |
| Competenza chiave | Sistemi distribuiti e architetture cloud | Modellazione statistica e ML | Data visualization e storytelling |
In breve, i data engineer costruiscono i sistemi che rendono i dati accessibili, i data scientist analizzano quei dati per trovare pattern e i data analyst traducono i risultati in insight di business. Scopri di più sulle differenze nel nostro articolo su cos’è il data engineering.
Di seguito abbiamo delineato i passi da seguire per intraprendere una carriera da data engineer. I passaggi esatti dipendono dalle tue competenze ed esperienze attuali, ma questo percorso può guidarti per diventare data engineer da zero.
Il data engineering è ancora un lavoro emergente. Di conseguenza, poche università e college offrono lauree specifiche in data engineering. I data engineer hanno in genere un background in Data Science, Ingegneria del Software, Matematica o in un’area legata al business.
A seconda del lavoro o del settore, la maggior parte dei data engineer ottiene il primo ruolo entry-level dopo la laurea triennale. Tuttavia, dato l’insieme di competenze altamente specializzate richieste, in molti casi conoscenze e capacità prevalgono sul titolo di studio.
Quindi, se vuoi seguire un percorso formale, assicurati di scegliere un corso di laurea che includa architettura dei sistemi, programmazione e configurazione dei database nel piano di studi.
Puoi anche valutare opzioni come il career track di DataCamp Data Engineer in Python, che ti insegnerà tutte le basi per costruire un’architettura dati efficace, ottimizzare l’elaborazione e mantenere sistemi su larga scala.
I data engineer necessitano di un set significativo di competenze tecniche per svolgere i propri compiti. Tuttavia, è molto difficile stilare un elenco dettagliato e completo delle competenze per avere successo in qualsiasi ruolo di data engineering; l’ecosistema della data science evolve rapidamente e nuove tecnologie e sistemi compaiono di continuo. Questo significa che i data engineer devono imparare costantemente per tenere il passo con i progressi tecnologici.
Detto ciò, ecco un elenco non esaustivo di competenze che dovrai sviluppare per diventare data engineer:
I data engineer trascorrono una parte considerevole del lavoro quotidiano operando sui database, per raccogliere, archiviare, trasferire, pulire o semplicemente consultare i dati. Pertanto devono avere una buona conoscenza della gestione dei database. Ciò significa padroneggiare SQL (Structured Query Language), il linguaggio base per interagire con i database, ed avere esperienza con alcuni dei dialect più diffusi, tra cui MySQL, SQL Server e PostgreSQL.
Oltre ai database relazionali, i data engineer devono conoscere i database NoSQL (“Not only SQL”), che stanno rapidamente diventando la scelta preferita per Big Data e applicazioni real-time.
Perciò, anche se il numero di engine NoSQL è in aumento, i data engineer dovrebbero almeno comprendere le differenze tra i tipi di database NoSQL e i casi d’uso di ciascuno. Se ti confonde la distinzione tra NoSQL e SQL, il nostro corso NoSQL Concepts è un ottimo punto di partenza.
Come in altri ruoli di data science, il coding è una competenza indispensabile per i data engineer. Oltre a SQL, utilizzano altri linguaggi per un’ampia gamma di attività. Esistono molti linguaggi di programmazione per il data engineering, ma Python è certamente una delle opzioni migliori.
Python è una lingua franca nella data science ed è perfetto per eseguire job ETL e scrivere pipeline dati. Puoi leggere di più su a cosa serve Python in un post dedicato.
Un altro motivo per usare Python è la sua ottima integrazione con strumenti e framework fondamentali nel data engineering, come Apache Airflow e Apache Spark. Molti di questi framework open source girano sulla Java Virtual Machine. Se la tua azienda usa questi framework, probabilmente dovrai imparare anche Java o Scala.
Negli ultimi anni i sistemi distribuiti sono diventati ubiqui nella data science. Un sistema distribuito è un ambiente di calcolo in cui vari componenti sono distribuiti su più computer (un cluster) in rete.
I sistemi distribuiti suddividono il lavoro nel cluster, coordinando gli sforzi per completarlo in modo più efficiente. I framework di calcolo distribuito, come Apache Hadoop e Apache Spark, sono progettati per l’elaborazione di enormi quantità di dati e forniscono le basi per alcune delle applicazioni Big Data più impressionanti. Avere esperienza in uno di questi framework è importante per ogni aspirante data engineer. Il nostro corso Foundations of PySpark è un ottimo inizio per l’elaborazione distribuita.
Il cloud computing è uno dei temi più caldi nella data science. La domanda di soluzioni cloud sta cambiando rapidamente il panorama. Oggi, essere data engineer significa in larga misura collegare i sistemi aziendali a sistemi basati sul cloud.
Con la diffusione di servizi come Amazon Web Services (AWS), Azure e Google Cloud, l’intero workflow dei dati può avvenire nel Cloud. Pertanto, un buon data engineer deve conoscere e saper usare i servizi cloud, i loro vantaggi, svantaggi e l’applicazione nei progetti Big Data. Dovresti almeno familiarizzare con una piattaforma come AWS o Azure, poiché sono le più diffuse.
Per fare esperienza pratica con i data warehouse nel cloud, prova il nostro progetto Exploring London’s Travel Network. Offre un’ottima opportunità per lavorare con Amazon Redshift, Google BigQuery e Snowflake direttamente dal browser.
Uno dei ruoli principali dei data engineer è creare pipeline dati con tecnologie ETL e framework di orchestrazione. Qui potremmo elencare molte tecnologie, ma il data engineer dovrebbe conoscere o sentirsi a proprio agio con alcune tra le più note, come Apache Airflow e Apache NiFi. Airflow è un framework di orchestrazione: è uno strumento open source per pianificare, generare e tracciare data pipeline. NiFi è perfetto per un processo ETL di big data di base e ripetibile.
Alcune delle applicazioni di data science più innovative utilizzano dati in tempo reale. Di conseguenza, cresce la domanda di candidati che conoscono i framework di stream processing. Ecco perché imparare a usare strumenti di streaming come Flink, Kafka Streams o Spark Streaming è una mossa vincente per i data engineer che vogliono fare un salto di qualità.
La maggior parte dei job e delle routine nel Cloud e in altri strumenti e framework Big Data viene eseguita con comandi e script da shell. I data engineer devono sentirsi a proprio agio nel terminale per modificare file, eseguire comandi e navigare nel sistema. Scopri di più con il nostro tutorial sul bash scripting.
Dulcis in fundo, i data engineer hanno anche bisogno di competenze comunicative per lavorare tra reparti e comprendere le esigenze di data analyst, data scientist e business leader. A seconda dell’organizzazione, potrebbe essere necessario saper sviluppare dashboard, report e altre visualizzazioni per comunicare con gli stakeholder.
I data engineer moderni usano sempre più framework di trasformazione dedicati per gestire le pipeline. dbt (Data Build Tool) è diventato uno standard per le trasformazioni basate su SQL, offrendo controllo di versione, test e documentazione per i tuoi modelli. Comprendere le tecniche di modellazione dimensionale (schema a stella, snowflake) e la medallion architecture (livelli bronze, silver, gold) aiuta a progettare data warehouse interrogabili in modo efficiente dagli analyst.
Con l’aumento della complessità delle pipeline, garantire la qualità dei dati diventa una responsabilità centrale. Strumenti come Great Expectations e Monte Carlo aiutano i data engineer a validare i dati, rilevare anomalie e tracciare la data lineage. Imparare a implementare pratiche di data governance, inclusi data contract e validazione degli schemi, garantisce che le pipeline producano dati affidabili per decisioni e applicazioni di AI.
Il passo successivo per diventare data engineer è lavorare su progetti di data engineering che dimostrino le tue competenze e la comprensione dei temi chiave. Puoi consultare la nostra guida completa su come costruire un portfolio di data science per trarre ispirazione.
Vorrai mostrare le competenze già elencate per impressionare i potenziali datori di lavoro, il che significa lavorare su progetti vari. DataLab offre un notebook collaborativo su cloud che ti permette di lavorare su progetti tuoi, così puoi analizzare dati, collaborare e condividere insight.
Puoi anche applicare le tue conoscenze a vari progetti di data science, risolvendo problemi reali dal browser e arricchendo il tuo portfolio di data engineering.
Quando ti sentirai pronto a esplorare un’area di business specifica, potrai iniziare a concentrarti sull’acquisizione di conoscenze di dominio e lavorare su progetti mirati a quello specifico ambito.
Il data engineering è uno dei ruoli più richiesti nell’industria della data science. Dalle big tech della Silicon Valley alle piccole startup data-driven nei vari settori, le aziende cercano data engineer per scalare e valorizzare al massimo le proprie risorse dati. Allo stesso tempo, le aziende faticano a trovare i candidati giusti, dato l’insieme ampio e altamente specializzato di competenze necessarie per soddisfare le esigenze organizzative.
In questo contesto, non esiste una formula perfetta per ottenere il primo lavoro da data engineer. In molti casi, si arriva al ruolo tramite una transizione da altre posizioni data nella stessa azienda, come data scientist o database administrator.
Se invece cerchi opportunità di data engineering su portali di lavoro, tieni presente che ci sono molte posizioni con il titolo “data engineer”, tra cui cloud data engineer, big data engineer e data architect. Le competenze e i requisiti specifici variano da posizione a posizione, quindi la chiave è trovare la corrispondenza più stretta tra ciò che sai e ciò di cui l’azienda ha bisogno.
Puoi leggere la nostra guida completa su come candidarti a lavori di data science per distinguerti dagli altri candidati. Probabilmente ti servirà un portfolio piuttosto solido che dimostri un’ampia gamma di competenze. Puoi trovare informazioni utili anche su ciò che cercano i recruiter nel nostro articolo su come scrivere una job description per data engineer.
La risposta è semplice: continua a imparare. Ci sono molti percorsi per approfondire la tua esperienza e ampliare la tua cassetta degli attrezzi da data engineer.
Puoi anche optare per un’ulteriore formazione formale, che sia una laurea in data science o informatica, un’area affine, oppure un master in data engineering.
Oltre alla formazione, la pratica è la chiave del successo. I datori di lavoro cercano candidati con competenze distintive e una solida padronanza di software e linguaggi di programmazione. Più alleni le tue abilità di coding con progetti personali e provi strumenti e framework Big Data, maggiori saranno le chance di distinguerti nel processo di selezione. Per dimostrare la tua esperienza, una buona opzione è ottenere una certificazione in data engineering.
Le certificazioni riconosciute dal settore possono convalidare le tue competenze e migliorare la tua spendibilità. Considera queste certificazioni man mano che progredisci:
Inizia con una certificazione indipendente dalla piattaforma, poi aggiungine una specifica per il cloud in linea con le piattaforme usate dai tuoi datori di lavoro target.
Infine, se hai difficoltà a trovare il tuo primo lavoro da data engineer, valuta di candidarti ad altre posizioni entry-level in ambito data science. In fin dei conti, la data science è un campo collaborativo con molti temi e competenze trasversali tra i ruoli. Queste posizioni ti daranno insight ed esperienza preziosi che ti aiuteranno a ottenere il tuo ruolo dei sogni nel data engineering.
Con l’avanzare della carriera, puoi specializzarti in diverse direzioni:
Molti data engineer passano anche a ruoli come ML engineer, cloud architect o engineering manager con l’esperienza.
I colloqui per data engineer sono solitamente suddivisi in parti tecniche e non tecniche. Puoi consultare la nostra guida completa con le principali domande e risposte dei colloqui di data engineering.
In breve, puoi aspettarti domande su quattro argomenti:
I recruiter vorranno conoscere le tue esperienze legate alla posizione di data engineering. Assicurati di evidenziare nel CV i tuoi precedenti lavori e progetti in ambito data science e preparati a fornirne i dettagli, perché queste informazioni sono cruciali per valutare competenze tecniche, problem solving, comunicazione e gestione dei progetti.
Probabilmente è la parte più stressante di un colloquio data. In genere ti verrà chiesto di risolvere un problema in poche righe di codice in poco tempo usando Python o un framework come Spark.
Per esempio, l’esercizio potrebbe consistere nel creare una semplice pipeline per caricare e pulire dati. Pur essendo di solito gestibile, la pressione del momento può influire negativamente sulla performance. Se non hai familiarità con questo tipo di test, prova ad allenarti prima con alcune domande di coding.
Non andrai lontano nella tua carriera di data engineer senza una solida esperienza in SQL. Ecco perché, oltre al test di programmazione, potresti dover risolvere un problema che richiede l’uso di SQL. In genere, l’esercizio consiste nello scrivere query efficienti per elaborare dati nei database.
È la parte più concettuale del colloquio tecnico e spesso la più impegnativa. Progettare architetture dati è una delle attività più impattanti dei data engineer. In questa fase ti verrà chiesto di progettare una soluzione dati end-to-end, che normalmente comprende tre aspetti: archiviazione, elaborazione e modellazione dei dati.
Dato il rapido ampliarsi degli ecosistemi di data science, le opzioni progettuali sono infinite. Devi essere pronto a discutere pro e contro e i possibili trade-off delle tue scelte.
Una volta conclusa la parte tecnica, l’ultimo step del colloquio prevede un’intervista personale con uno o più potenziali membri del team. L’obiettivo? Conoscere chi sei e come ti inseriresti nel team.
Ricorda però che il colloquio è una conversazione a doppio senso, il che significa che dovresti porre a tua volta domande per capire se ti vedi parte del team.
Gli stipendi dei data engineer sono elevati rispetto a molti lavori IT, a riflettere la domanda. Le cifre variano per paese, città e seniority, ma possiamo delineare alcuni intervalli indicativi (importi lordi annui):
Stati Uniti: Le medie nazionali sono nell’ordine di 120–130K $ (Indeed riporta circa 126.300 $). Glassdoor indica ~153K $ come media per i data engineer, con ruoli senior oltre 180K $ nei principali hub tecnologici. I profili entry-level (0–3 anni) in genere guadagnano 80–90K $, a metà carriera (~3–5 anni) circa 110–115K $, e i senior spesso superano 140K $. (Per esempio, un sondaggio mostrava junior ~80K $, mid ~114K $ e senior ~142K $.) I maggiori hub tech pagano ancora di più: nella Silicon Valley o a New York i ruoli senior possono facilmente arrivare a 180K $+.
Regno Unito/Europa: A Londra, i data engineer di livello intermedio guadagnano spesso circa £75–100K. Morgan McKinley riporta un range londinese di £75–100K, con ruoli junior (~0–3 anni) intorno a £50–75K e senior (5+ anni) fino a £125K. In Europa continentale, gli stipendi sono generalmente inferiori rispetto agli USA: per esempio, in Germania i data engineer guadagnano in media circa €50–70K, e cifre simili (spesso tra €60–80K) sono comuni in Europa occidentale.
Asia-Pacifico (APAC): Le variazioni sono ampie. A Singapore, i data engineer guadagnano circa S$120–170K l’anno (circa 90–125K US$), con ruoli senior oltre S$240K, secondo dati di recruiting. In Australia, i data engineer di Sydney guadagnano in media circa A$155K (~100K US$). Al contrario, in India gli stipendi sono molto più bassi: un data engineer tipico può guadagnare circa ₹9–10 lakh (circa 12K US$) l’anno a livello entry/mid (anche se possono crescere con l’esperienza, soprattutto in MNC o hub di startup).
Queste cifre evidenziano sia l’effetto della seniority sia le differenze regionali. Indicativamente, l’ingresso nel campo (junior) si colloca forse al 50–70% del livello di mid-level, mentre i ruoli senior/lead stanno spesso al 20–40% sopra la media mid-career. In definitiva, la retribuzione dipende dal costo della vita e dal mercato locale di ciascuna regione, ma la tendenza è chiara: il data engineering è molto competitivo, a riflettere la sua importanza strategica.
Il ruolo del data engineer evolve insieme alle nuove tecnologie. I principali trend che influenzano il settore includono:
Integrazione di AI e machine learning: Man mano che le aziende adottano l’AI, i data engineer hanno un ruolo cruciale nel fornire ai sistemi di ML dati di alta qualità. Piuttosto che sostituire il data engineering, gli strumenti di AI generativa e ML stanno aumentando la domanda di pipeline dati migliori. I data engineer ora costruiscono e mantengono l’infrastruttura per l’addestramento dei modelli e lo streaming delle predizioni in produzione. Spesso implementano pratiche DataOps/MLOps per automatizzare i workflow e garantire che i modelli possano accedere ai dati necessari. In sostanza, i data engineer diventano abilitatori dell’AI, costruendo grandi dataset puliti di cui l’AI ha bisogno per avere successo.
Dati in tempo reale e streaming: L’era dell’ETL solo batch sta tramontando. Le aziende richiedono sempre più insight in tempo reale, quindi i data engineer si orientano verso piattaforme di streaming (Kafka, Flink, Spark Streaming) e persino l’edge computing. I sistemi di streaming moderni consentono di elaborare eventi e aggiornare la reportistica all’istante, un enorme vantaggio competitivo. I progressi nel 5G e nell’edge computing permettono di raccogliere ed elaborare i dati vicino alla loro fonte con latenza molto bassa. Pertanto, i data engineer devono progettare pipeline a bassa latenza ed essere competenti nei framework di stream processing. In pratica, lavorerai spesso su pipeline che acquisiscono e trasformano continuamente dati (per esempio clickstream, sensori o log) per alimentare dashboard live e avvisi automatici.
Architetture data mesh e data fabric: Con la scalabilità delle piattaforme dati, le organizzazioni stanno ripensando le architetture centralizzate. Il concetto di data mesh – trattare ogni dominio di business come un “mini prodotto dati” di proprietà del team di dominio – ha guadagnato popolarità. I data engineer possono lavorare in team cross-funzionali proprietari di specifici domini (marketing, vendite, ecc.) invece che in un unico team centrale. Nel frattempo, le architetture di data fabric – che usano livelli unificati di metadati e integrazione per collegare dati in più silos – stanno emergendo.
Gartner osserva che entrambi gli approcci (mesh e fabric) sono temi caldi: mesh per la decentralizzazione e il “dato come prodotto”, e fabric per integrare dati distribuiti. In pratica, nuove piattaforme e strumenti (come lake specifici di dominio, servizi di catalogo e pipeline automatizzate) aiutano a implementare questi pattern. Per un data engineer, la lezione è prepararsi a lavorare in team orientati al dominio e comprendere i moderni sistemi di metadati/catalogo. (Importante: gli analisti avvertono che il data mesh è ancora una pratica in evoluzione e spesso viene usata insieme a soluzioni di data fabric.)
Modernizzazione cloud-native: Quasi tutto il data engineering oggi gira sul cloud. Le aziende stanno migrando da data warehouse on-prem a data warehouse e lakehouse nel cloud (Snowflake, Redshift, Azure Synapse, Databricks, ecc.). Le architetture cloud-native – pipeline serverless, streaming gestito (ad es. Kinesis, Pub/Sub) e storage scalabile – sono trend chiave. I data engineer dovrebbero quindi padroneggiare servizi cloud e automazione (Infrastructure-as-Code, CI/CD per le pipeline). Adottare strumenti cloud-native consente di scalare il compute on demand, ottimizzare i costi e concentrarsi sulla logica dei dati invece che sulle operazioni server. In breve, le piattaforme dati vengono modernizzate per l’era del cloud, e i data engineer guidano questa modernizzazione.
Governance e qualità dei dati: Con l’aumento dei volumi e delle normative, strumenti per la data governance, la lineage e la qualità (cataloghi dati, pipeline basate su contratti, osservabilità) stanno maturando. I data contract e i registry degli schemi (che automatizzano gli accordi tra produttori e consumatori di dati) sono in crescita, assicurando che i team non si rompano le pipeline a vicenda. Come data engineer, potresti lavorare con nuovi framework e strumenti di governance (come Great Expectations, Monte Carlo o cataloghi open source) per aiutare l’organizzazione a fidarsi dei propri dati. (Un trend, per esempio, è usare “data contract” per far rispettare schemi coerenti tra i team.)
DevOps e automazione: Infine, il confine tra software engineering e data engineering continua ad assottigliarsi. Molte organizzazioni adottano pratiche DevOps per i dati (spesso chiamate DataOps o MLOps). Ciò significa controllo di versione per il codice dati, test automatizzati delle pipeline e delivery continua dell’infrastruttura dati. I framework di automazione (come Apache Airflow per le pipeline, Terraform o CloudFormation per l’infrastruttura) sono ormai standard. Saper usare questi strumenti e pratiche DevOps ti aiuterà a distribuire soluzioni dati più rapidamente e in modo affidabile.
Il data engineering è uno dei lavori più richiesti nel panorama della data science ed è certamente un’ottima scelta di carriera per chi aspira a ruoli data. Se sei determinato a diventare data engineer ma non sai da dove cominciare, ti consiglio vivamente di seguire il career track Data Engineer in Python, che ti dà le conoscenze pratiche per diventare un data engineer sicuro di sé. Puoi anche iniziare con il corso Introduction to Data Engineering o esplorare la guida completa per imparare il data engineering da zero.
Approfondisci il data engineering con questi corsi!
Programma
Programma
Corso
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min

