
Kurs
Python ile Deep Learning'e Giriş
4 sa
264K
Nesne tespiti, bir görüntü veya videodaki nesneleri belirlemek ve konumlandırmak için kullanılan bir bilgisayarlı görü tekniğidir.
pip install ultralytics ile kurun ve kestirimi (inference) Python API veya CLI üzerinden çalıştırınGörüntü yerelleştirme, nesnelerin etrafındaki dikdörtgen şekillere karşılık gelen sınırlayıcı kutular kullanarak bir veya birden fazla nesnenin doğru konumunu belirleme işlemidir. Bu süreç bazen, bir görüntünün veya görüntü içindeki bir nesnenin sınıfını kategorilerden birine tahmin etmeyi amaçlayan görüntü sınıflandırma ya da görüntü tanıma ile karıştırılır.
Aşağıdaki görsel, önceki açıklamanın görsel temsilini gösterir. Görüntü içinde tespit edilen nesne bir “Kişi”dir.

Görsel: Yazar
Bu kavramsal blogda, önce nesne tespitinin faydalarını anlayacak, ardından son teknoloji nesne tespit algoritması YOLO’ya giriş yapacaksınız.
İkinci bölümde YOLO algoritmasına ve nasıl çalıştığına odaklanacağız. Sonrasında YOLO’nun gerçek hayattaki bazı uygulamalarını paylaşacağız.
Son bölümde, YOLO’nun 2015’ten 2024’e kadar nasıl evrildiğini açıklayıp sonraki adımlarla bitireceğiz.
You Only Look Once (YOLO), 2015’te Joseph Redmon, Santosh Divvala, Ross Girshick ve Ali Farhadi tarafından ünlü You Only Look Once: Unified, Real-Time Object Detection araştırma makalesinde tanıtılan, son teknoloji gerçek zamanlı bir nesne tespit algoritmasıdır.
Yazarlar, tek bir evrişimli sinir ağı (CNN) kullanarak sınırlayıcı kutuları uzamsal olarak ayırıp her tespit edilen görüntüye olasılıklar atayarak nesne tespiti problemini sınıflandırma değil regresyon görevi olarak ele almıştır.
Görüntü sınıflandırmayla ilgileniyorsanız, Keras tabanlı derin sinir ağları inşa edeceğiniz Python ile Keras’ta Görüntü İşleme kursunu inceleyin. PyTorch ilginizi daha çok çekiyorsa, PyTorch ile Derin Öğrenme kursu size evrişimli sinir ağlarını ve bunlarla çok daha güçlü modeller kurmayı öğretecektir.
YOLO’nun yarışı önde götürmesinin bazı nedenleri şunlardır:
Bu özelliklere daha yakından bakalım.
YOLO, karmaşık boru hatlarıyla uğraşmadığı için son derece hızlıdır. Görüntüleri saniyede 45 kare (FPS) hızında işleyebilir. Ayrıca, YOLO diğer gerçek zamanlı sistemlere kıyasla ortalama Ortalama Doğruluk (mAP) değerini iki kattan fazla yakalar; bu da onu gerçek zamanlı işleme için harika bir aday yapar.
Aşağıdaki grafikten, YOLO’nun 91 FPS ile diğer nesne dedektörlerinin çok ilerisinde olduğunu gözlemliyoruz.
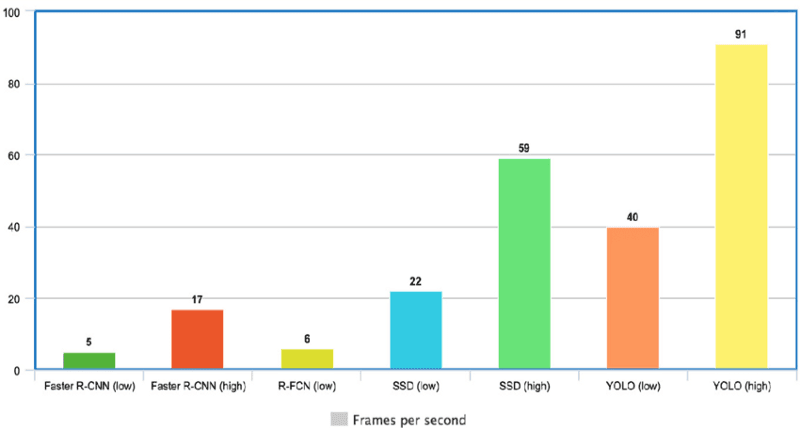
Diğer son teknoloji nesne dedektörleriyle karşılaştırıldığında YOLO hızı (kaynak)
YOLO, çok az arka plan hatasıyla doğruluk açısından diğer son teknoloji modellere göre bariz üstünlük gösterir.
Bu özellikle, yazının ilerleyen kısımlarında ele alınacak yeni YOLO sürümleri için geçerlidir. Bu gelişmelerle birlikte YOLO, yeni alanlar için daha iyi genelleme sağlayarak hızlı ve sağlam nesne tespitine dayanan uygulamalar için harika bir seçenek hâline gelmiştir.
Örneğin, YOLO Derin Evrişimli Sinir Ağlarıyla Melanomun Otomatik Tespiti makalesi, ilk sürüm olan YOLOv1’in, melanom hastalığının otomatik tespitinde YOLOv2 ve YOLOv3’e kıyasla en düşük mAP değerine sahip olduğunu göstermektedir.
YOLO’nun açık kaynak olması, topluluğun modeli sürekli geliştirmesine olanak tanıdı. YOLO’nun bu kadar kısa sürede bu denli çok iyileştirme yapmasının nedenlerinden biri de budur.
YOLO mimarisi, GoogleNet’e benzer. Aşağıda gösterildiği gibi 24 evrişim katmanı, dört maksimum havuzlama katmanı ve iki tam bağlı katmandan oluşur.
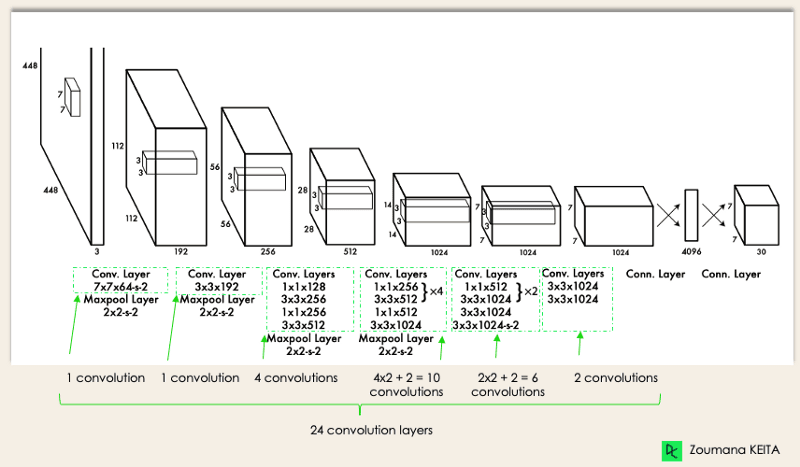
YOLO Mimarisi orijinal makaleden (Yazar tarafından düzenlendi)
Mimari şu şekilde çalışır:
Python’da Derin Öğrenme kariyer yolunu veya PyTorch CNN Eğitimini tamamlayarak, Keras ile karmaşık, çok çıkışlı ağları eğitip test etmeye ve derin öğrenmeye daha derinlemesine dalmaya hazır olacaksınız.
Artık mimariyi anladığınıza göre, basit bir kullanım senaryosu üzerinden YOLO algoritmasının nesne tespitini nasıl gerçekleştirdiğine üst düzeyden bakalım.
“Diyelim ki, verilen bir görüntüden oyuncuları ve futbol toplarını tespit eden bir YOLO uygulaması geliştirdiniz.
Peki bu süreci, özellikle konuya yabancı birine nasıl açıklarsınız?
→ Bu bölümün amacı tam olarak bu. YOLO’nun nesne tespitini baştan sona nasıl gerçekleştirdiğini ve (A) görselinden (B) görseline nasıl geçildiğini anlayacaksınız.”
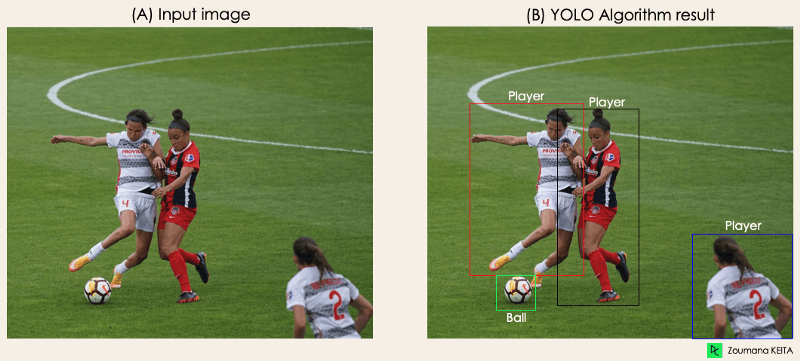 Görsel: Yazar
Görsel: Yazar
Algoritma aşağıdaki dört yaklaşıma dayanır:
Şimdi her birine daha yakından bakalım.
İlk adımda, orijinal görüntü (A) sağdaki görselde gösterildiği gibi eşit şekilli NxN ızgara hücrelerine bölünür; burada N bizim örneğimizde 4’tür. Izgaradaki her hücre, kapladığı nesnenin konumunu ve sınıfını olasılık/güven değeriyle birlikte belirlemekten sorumludur.

Görsel: Yazar
Bir sonraki adım, görüntüdeki tüm nesneleri vurgulayan dikdörtgenlere karşılık gelen sınırlayıcı kutuları belirlemektir. Verilen bir görüntüdeki nesne sayısı kadar sınırlayıcı kutu olabilir.
YOLO, bu sınırlayıcı kutuların özniteliklerini aşağıdaki biçimde tek bir regresyon modülüyle belirler; burada Y, her sınırlayıcı kutu için nihai vektör temsilidir.
Y = [pc, bx, by, bh, bw, c1, c2]
Bu, özellikle modelin eğitim aşamasında önemlidir.
pc, bir nesne içeren ızgaranın olasılık puanına karşılık gelir. Örneğin, kırmızı olan tüm ızgaralar sıfırdan büyük olasılık puanına sahip olacaktır. Sağdaki görsel basitleştirilmiş hâlidir; çünkü sarı hücrelerin olasılığı sıfırdır (önemsiz). 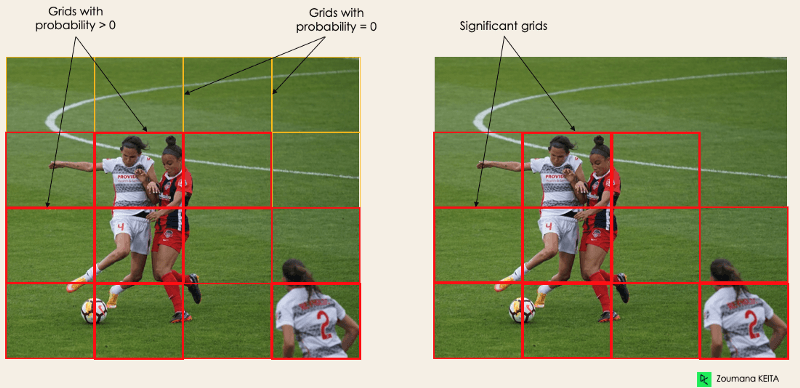
Görsel: Yazar
bx, by, sınırlayıcı kutunun merkezinin, onu saran ızgara hücresine göre x ve y koordinatlarıdır. bh, bw, sınırlayıcı kutunun, onu saran ızgara hücresine göre yüksekliği ve genişliğidir. c1 ve c2, İ oyuncu ve Top olmak üzere iki sınıfa karşılık gelir. Kullanım durumunuza göre daha fazla sınıf olabilir. Anlamak için sağ alttaki oyuncuya daha yakından bakalım.
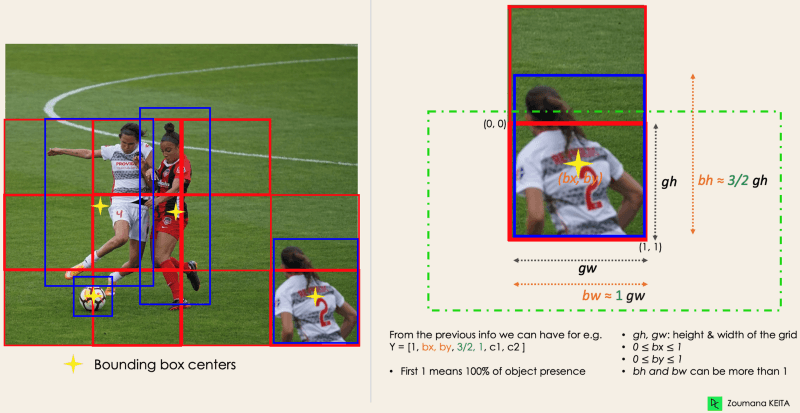 Görsel: Yazar
Görsel: Yazar
Çoğu zaman, bir görüntüdeki tek bir nesne için birden fazla ızgara kutusu adayı olabilir; ancak bunların hepsi anlamlı değildir. IOU’nun (0 ile 1 arasında bir değer) amacı, yalnızca anlamlı olanları tutmak için bu ızgara kutularını elemekten ibarettir. Mantık şöyledir:
Aşağıda, sol alt nesneye ızgara seçimi sürecinin uygulanmasına ilişkin bir görselleştirme yer alır. Başlangıçta nesnenin iki ızgara adayı olduğunu ve sonunda yalnızca “Izgara 2”nin seçildiğini görebiliriz.
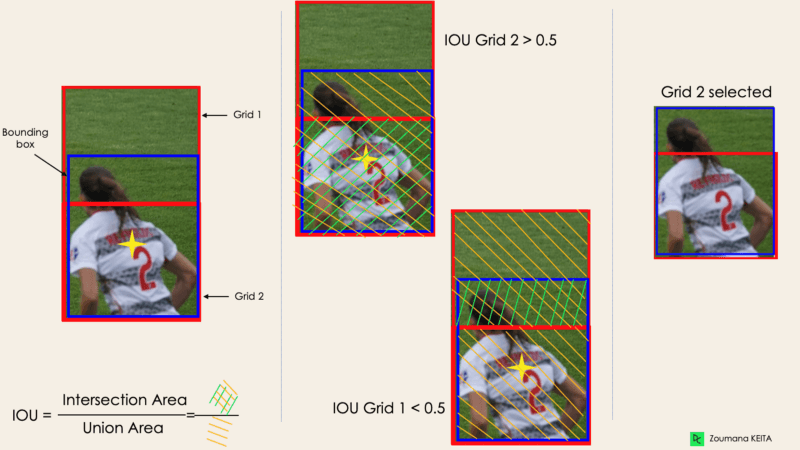
Görsel: Yazar
IOU için bir eşik belirlemek her zaman yeterli değildir; çünkü bir nesnenin eşik üzerindeki IOU’ya sahip birden fazla kutusu olabilir ve hepsini bırakmak gürültüye yol açabilir. En yüksek olasılık tespit puanına sahip kutuları tutmak için burada NMS kullanılır.
YOLO nesne tespiti, günlük hayatımızda farklı uygulamalara sahiptir. Bu bölümde sağlık, tarım, güvenlik gözetimi ve otonom araçlar alanlarından bazılarını ele alacağız.
Nesne tespiti sağlık ve tarım gibi birçok pratik sektörde kullanılmaktadır. Her birini somut örneklerle anlayalım.
Özellikle cerrahide, bir hastadan diğerine biyolojik çeşitlilik nedeniyle organları gerçek zamanlı yerelleştirmek zor olabilir. BT’de Böbrek Tanıma çalışması YOLOv3’ü kullanarak bilgisayarlı tomografi (BT) taramalarından böbrekleri 2B ve 3B’de yerelleştirmeyi kolaylaştırmıştır.
Python ile Biyomedikal Görüntü Analizi kursu, Python kullanarak biyomedikal görüntü verilerini keşfetme, işleme ve ölçmenin temellerini öğrenmenize yardımcı olabilir.
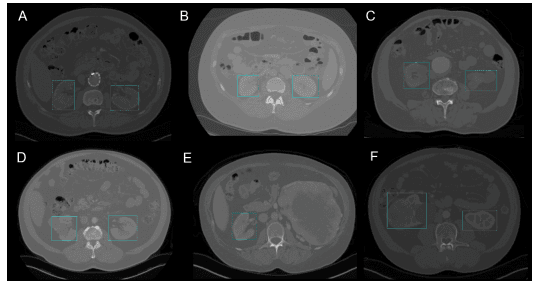
YOLOv3 ile 2B böbrek tespiti (BT’de YOLOv3 ile Böbrek Tanıma çalışmasından görüntü)
Yapay Zekâ ve robotik modern tarımda büyük rol oynar. Hasat robotları, meyve ve sebzelerin elle toplanmasının yerini almak üzere geliştirilen görsel tabanlı robotlardır. Bu alandaki en iyi modellerden biri YOLO kullanır. Değiştirilmiş bir YOLOv3 çerçevesine dayalı domates tespiti çalışmasında yazarlar, verimli hasat için meyve ve sebze türlerini tanımlamak üzere YOLO’yu nasıl kullandıklarını açıklar.

Görsel: Değiştirilmiş YOLOv3 çerçevesine dayalı domates tespiti çalışmasından (kaynak)
Nesne tespiti çoğunlukla güvenlik gözetiminde kullanılsa da tek uygulama alanı değildir. COVID-19 pandemisi sırasında YOLOv3, insanlar arasındaki sosyal mesafe ihlallerini tahmin etmek için kullanılmıştır.
Bu konu hakkında COVID-19 için derin öğrenme tabanlı sosyal mesafe izleme çerçevesi çalışmasını okuyabilirsiniz.
Gerçek zamanlı nesne tespiti, otonom araç sistemlerinin DNA’sının bir parçasıdır. Bu entegrasyon, otonom araçların doğru şeritleri ve çevredeki tüm nesneleri ile yayaları doğru şekilde tanımlaması gerektiğinden yol güvenliği için kritiktir. YOLO’nun gerçek zamanlı yapısı, onu basit görüntü bölütleme yaklaşımlarına kıyasla daha iyi bir aday yapar.
İlk sürümünden (2015) bu yana YOLO, farklı sürümlerle büyük ölçüde evrildi. Bu bölümde bu sürümler arasındaki farkları anlayacağız.
YOLO’nun ilk sürümü, nesne tespiti için oyunun kurallarını değiştirdi; çünkü nesneleri hızlı ve verimli şekilde tanıyabiliyordu.
Ancak birçok çözüm gibi YOLO’nun ilk sürümünün de kendi sınırlamaları vardı:
YOLOv2, YOLO modelini daha iyi, daha hızlı ve daha güçlü yapmak amacıyla 2016’da oluşturuldu.
İyileştirmeler arasında yeni mimari olarak Darknet-19’un kullanımı, toplu normalleştirme, daha yüksek girdi çözünürlüğü, çapanlı (anchor) evrişim katmanları, boyutlandırma kümeleme ve (5) ince taneli özellikler yer alır.
Bir toplu normalleştirme katmanı eklemek, performansı %2 mAP artırdı. Bu katman, aşırı uyumu önleyen düzenlendirici bir etki sağladı.
YOLOv2, 224×224 yerine doğrudan 448×448 daha yüksek çözünürlüklü girdi kullanır; bu da modelin filtrelerini yüksek çözünürlüklü görüntülerde daha iyi performans için ayarlamasını sağlar. Bu yaklaşım, ImageNet verisi üzerinde 10 dönemlik eğitimden sonra doğruluğu %4 mAP artırdı.
YOLOv1’in yaptığı gibi nesnelerin sınırlayıcı kutularının tam koordinatlarını öngörmek yerine, YOLOv2 tam bağlı katmanları çapa kutularıyla değiştirerek problemi basitleştirir. Bu yaklaşım doğruluğu biraz düşürür; ancak geri çağırmayı %7 artırarak iyileştirme için daha fazla alan bırakır.
YOLOv2, manuel seçim yapmak yerine k=5 ile k-ortalama boyutlandırma kümelenmesi kullanarak bahsedilen çapa kutularını otomatik olarak bulur. Bu yeni yaklaşım, modelin geri çağırma ve kesinliği arasında iyi bir denge sağlar.
K-ortalama boyutlandırma kümelenmesini daha iyi anlamak için scikit-learn ile Python’da K-ortalama Kümelenme ve R’da K-ortalama Kümelenme eğitimlerimize göz atın. Bu içerikler, Python ve R ile k-ortalama kavramına derinlemesine dalar.
YOLOv2 tahminleri 13x13 öznitelik haritaları üretir; bu, elbette büyük nesne tespiti için yeterlidir. Ancak çok daha ince nesne tespiti için mimari, 26 × 26 × 512 öznitelik haritasını 13 × 13 × 2048 öznitelik haritasına dönüştürüp orijinal özelliklerle birleştirecek şekilde değiştirilebilir. Bu yaklaşım, model performansını %1 artırmıştır.
Artımsal bir iyileştirme, YOLOv2 üzerinde yapılarak YOLOv3 oluşturulmuştur.
Değişim, esas olarak yeni bir ağ mimarisini kapsar: Darknet-53. Bu; üst örnekleme ağları ve artık bloklara sahip 106 katmanlı bir sinir ağıdır. YOLOv2’nin belkemiği olan Darknet-19’a kıyasla çok daha büyük, hızlı ve doğrudur. Bu yeni mimari birçok açıdan fayda sağlamıştır:
YOLOv3, her sınırlayıcı kutu için nesne olasılık puanını tahmin etmek üzere lojistik regresyon modeli kullanır.
YOLOv2’deki softmax yerine, sınırlayıcı kutuların sınıfını doğru şekilde tahmin etmek için bağımsız lojistik sınıflandırıcılar getirilmiştir. Bu, etiketlerin çakıştığı (ör. Kişi → Futbolcu) daha karmaşık alanlarda da kullanışlıdır. Softmax kullanmak, her kutuyu yalnızca bir sınıfa zorlayacaktır; bu ise her zaman doğru değildir.
YOLOv3, önceki katmanlardan üst örneklemeye yardımcı olmak için girdi görüntüsündeki her konumda üç farklı ölçekte tahmin yapar. Bu strateji, daha kaliteli çıktı görüntüsü için ince taneli ve daha anlamlı anlamsal bilgi elde edilmesini sağlar.
Bu YOLO sürümü, önceki sürümler ve diğer son teknoloji nesne dedektörlerine kıyasla Optimal Hız ve Doğruluk sunar.
Aşağıdaki görsel, YOLOv4’ün hızda YOLOv3 ve FPS’yi sırasıyla %10 ve %12 oranında geride bıraktığını gösterir.
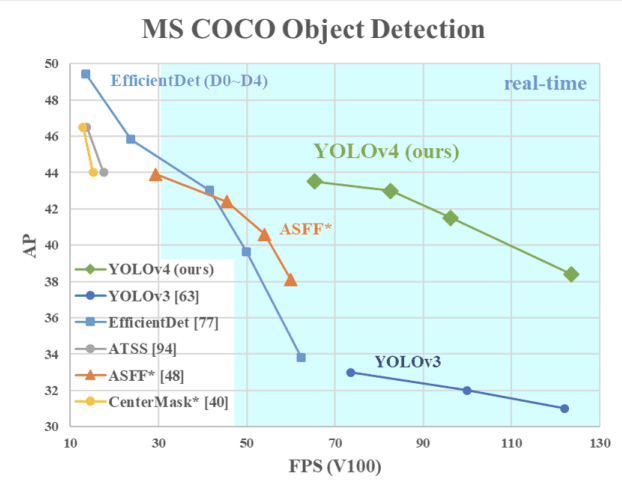
YOLOv4’ün YOLOv3 ve diğer son teknoloji nesne dedektörleriyle hız karşılaştırması (kaynak)
YOLOv4, özellikle üretim sistemleri için tasarlanmış ve paralel hesaplamalar için optimize edilmiştir.
YOLOv4’ün mimari belkemiği, 3 × 3 filtrelere sahip 29 evrişim katmanlı ve yaklaşık 27,6 milyon parametreli bir ağ olan CSPDarknet53’tür.
Bu mimari, YOLOv3’e kıyasla daha iyi nesne tespiti için şu unsurları ekler:
Birden Fazla Görev için Birleşik Ağ olarak YOLOR, açık ve örtük bilgi yaklaşımlarının birleşimi olan birleşik ağa dayanır.
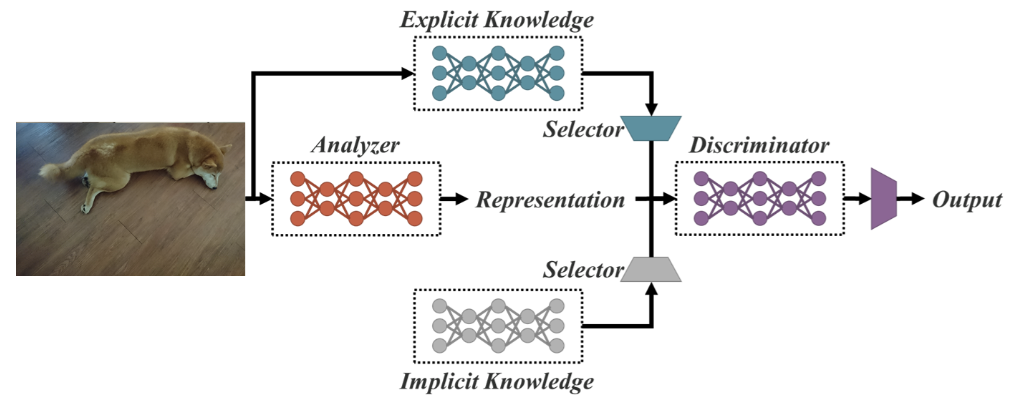
Birleşik ağ mimarisi (kaynak)
Açık bilgi normal ya da bilinçli öğrenmedir. Örtük öğrenme ise deneyimden kaynaklanan, bilinçdışı şekilde gerçekleşendir.
Bu iki tekniği birleştirerek YOLOR, üç sürece dayalı daha sağlam bir mimari oluşturur: (1) özellik hizalaması, (2) nesne tespiti için tahmin hizalaması ve (3) çoklu görev öğrenimi için kanonik temsil
Bu yaklaşım, her öznitelik piramit ağının (FPN) öznitelik haritasına örtük bir temsil ekler; bu da doğruluğu yaklaşık %0,5 artırır.
Model tahminleri, ağın çıkış katmanlarına örtük temsil eklenerek iyileştirilir.
Çoklu görev eğitimi yapmak, tüm görevler arasında paylaşılan kayıp fonksiyonu üzerinde ortak optimizasyonun yürütülmesini gerektirir. Bu süreç, modelin genel performansını düşürebilir; bu sorun, model eğitimi sırasında kanonik temsilin entegrasyonuyla hafifletilebilir.
Aşağıdaki grafikten, YOLOR’un MS COCO verisinde diğer modellere kıyasla son teknoloji çıkarım hızına ulaştığını gözlemleyebiliriz.
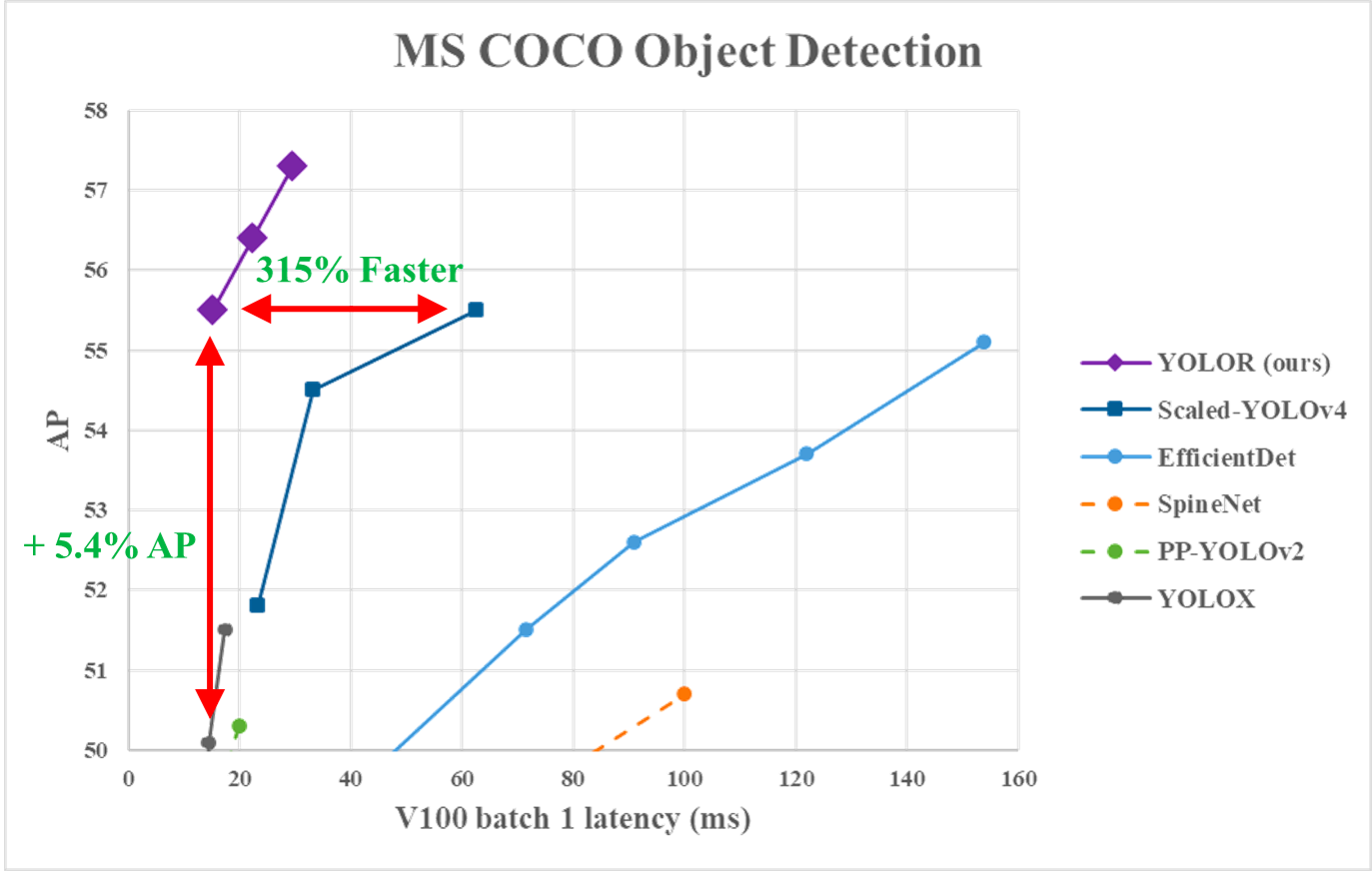
YOLOR performansı vs. YOLOv4 ve diğer modeller (kaynak)
Bu yaklaşım, belkemiği olarak Darknet-53 kullanan, YOLOv3’ün değiştirilmiş bir sürümünü temel alır.
2021’de YOLO Serisini Aşmak makalesinde yayımlanan YOLOX, önceki sürümlere kıyasla daha iyi bir model oluşturmak için şu dört temel özelliği sunar.
Önceki YOLO sürümlerinde kullanılan birleştirilmiş baş, modellerin performansını düşürmektedir. YOLOX bunun yerine sınıflandırma ve yerelleştirme görevlerini ayıran ayrık baş kullanır; böylece modelin performansını artırır.
Veri artırma yaklaşımına Mozaik ve MixUp entegrasyonu, YOLOX’un performansını önemli ölçüde artırmıştır.
Çapa tabanlı algoritmalar, perde arkasında kümelenme gerçekleştirir; bu da çıkarım süresini artırır. YOLOX’ta çapa mekanizmasının kaldırılması, görüntü başına tahmin sayısını azaltmış ve çıkarım süresini önemli ölçüde iyileştirmiştir.
Kesişim/Birleşim (IoU) yaklaşımı yerine yazar, yalnızca eğitim süresini azaltmakla kalmayıp ek hiperparametre sorunlarından da kaçınan, son teknoloji sonuçlar elde eden daha sağlam bir etiket atama stratejisi olan SimOTA’yı tanıtmıştır. Buna ek olarak, tespit mAP’ini %3 artırmıştır.
YOLOv5, diğer sürümlere kıyasla yayımlanmış bir araştırma makalesine sahip değildir ve Darknet yerine PyTorch’ta uygulanan ilk YOLO sürümüdür.
Glenn Jocher tarafından Haziran 2020’de yayımlanan YOLOv5, tıpkı YOLOv4 gibi, mimarisinin belkemiği olarak CSPDarknet53 kullanır. Sürüm; YOLOv5s (en küçük), YOLOv5m, YOLOv5l ve YOLOv5x (en büyük) olmak üzere beş farklı model boyutu içerir.
YOLOv5 mimarisindeki önemli iyileştirmelerden biri, YOLOv3’ün ilk üç katmanının değiştirilmesiyle tek bir katman olarak temsil edilen Focus katmanının entegrasyonudur. Bu entegrasyon, katman sayısını ve parametre sayısını azalttı; ileri ve geri yöndeki hızı artırdı ve mAP üzerinde büyük bir etki yaratmadan bunu başardı.
Aşağıdaki görsel, YOLOv4 ile YOLOv5s arasındaki eğitim süresi karşılaştırmasını göstermektedir.
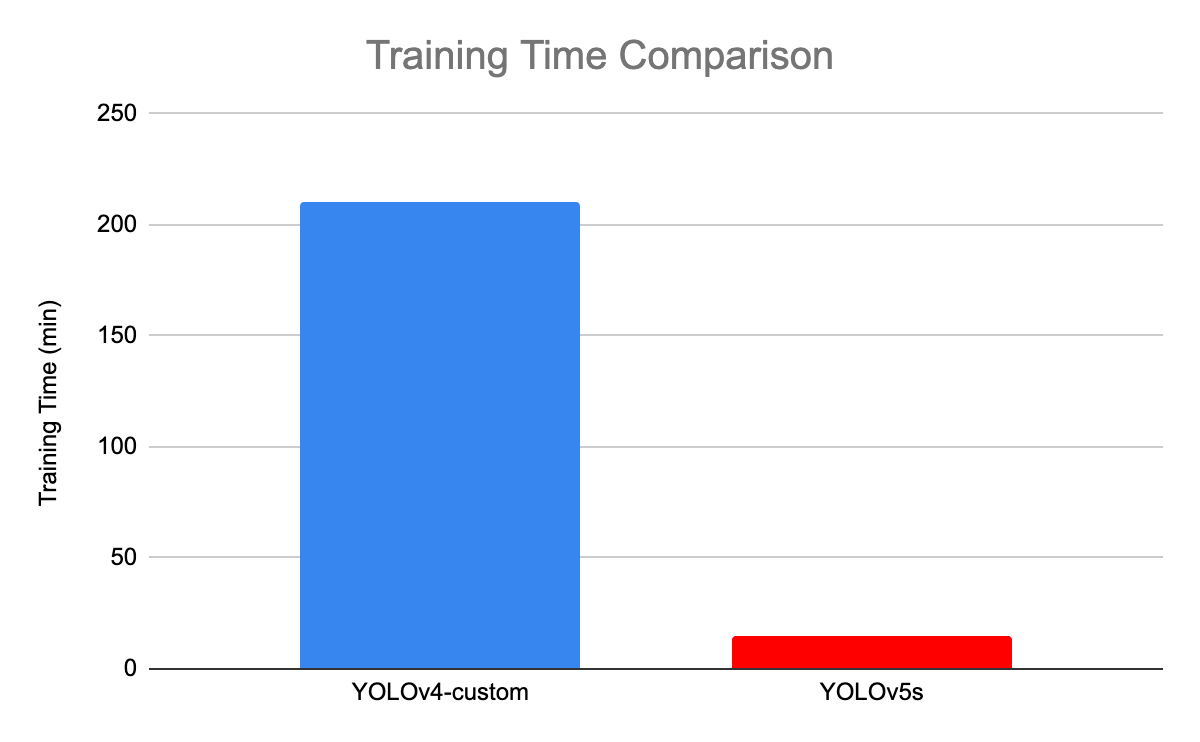
YOLOv4 ve YOLOv5 arasındaki eğitim süresi karşılaştırması (kaynak)
Donanım dostu verimli tasarım ve yüksek performansla endüstriyel uygulamalara adanan YOLOv6 (MT-YOLOv6) çerçevesi, Çinli bir e-ticaret şirketi olan Meituan tarafından yayımlandı.
PyTorch ile yazılan bu yeni sürüm, resmî YOLO’nun bir parçası değildir; ancak belkemiği orijinal tek aşamalı YOLO mimarisinden esinlendiği için YOLOv6 adını almıştır.
YOLOv6, önceki YOLOv5’e üç önemli iyileştirme getirdi: donanım dostu belkemiği ve boyun (neck) tasarımı, verimli ayrık baş ve daha etkili bir eğitim stratejisi.
YOLOv6, COCO veri setinde doğruluk ve hız açısından önceki YOLO sürümlerine kıyasla olağanüstü sonuçlar sunar; aşağıda gösterildiği gibi.
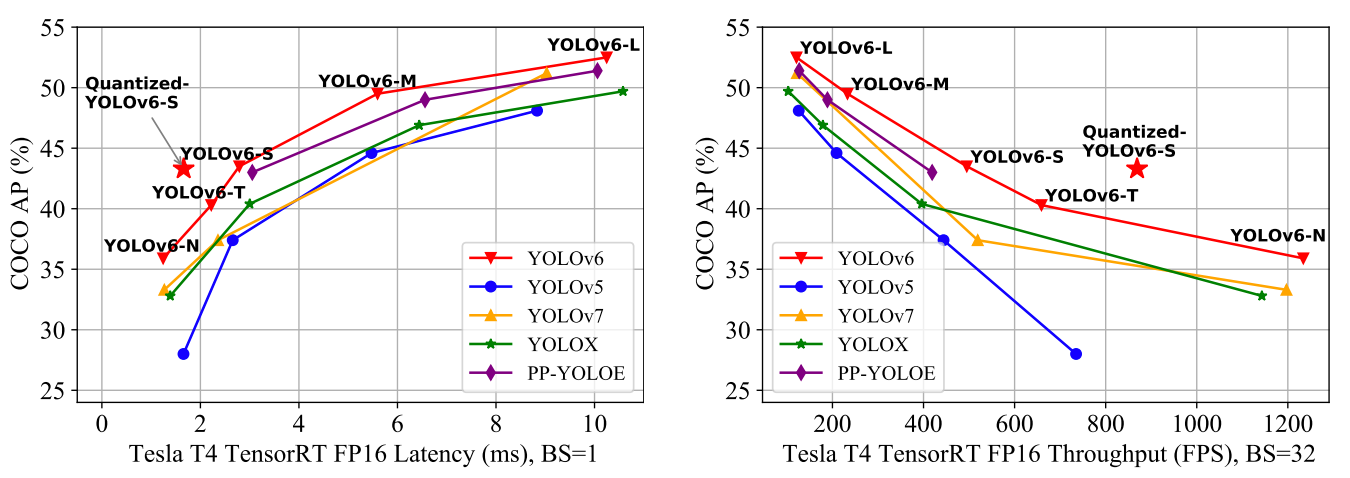
Son teknoloji verimli nesne dedektörlerinin karşılaştırması. Tüm modeller TensorRT 7 ile test edilmiştir; nicemli model ise TensorRT 8 ile test edilmiştir (kaynak)
Tüm bu özellikler, YOLOv6’yı endüstriyel uygulamalar için doğru algoritma yapar.
YOLOv7, Temmuz 2022’de Eğitilmiş ücretsiz çanta setleri gerçek zamanlı nesne dedektörleri için yeni son teknoloji belirliyor makalesinde yayımlandı. Bu sürüm, nesne tespiti alanında önemli bir adım atmış ve doğruluk ile hız açısından tüm önceki modelleri geride bırakmıştır.
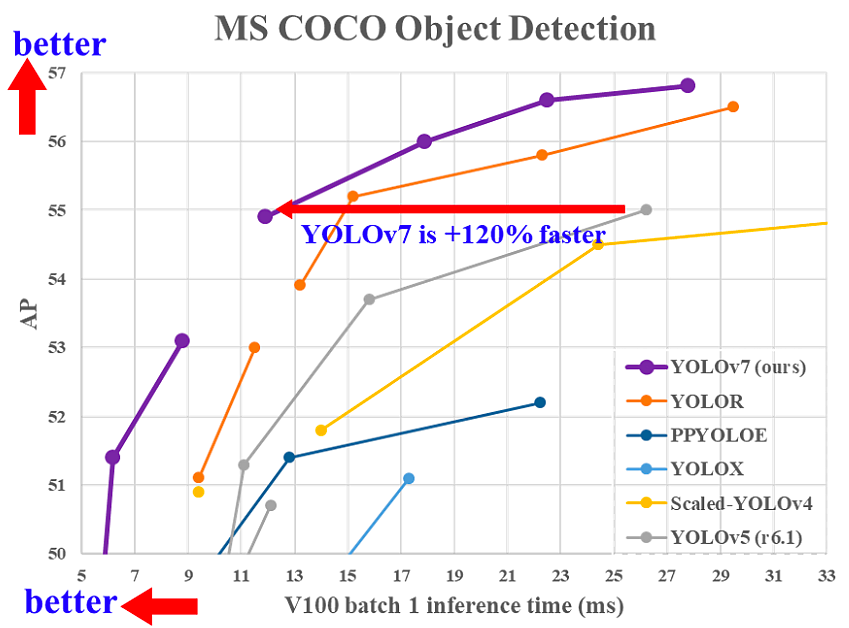
YOLOv7 çıkarım süresinin diğer gerçek zamanlı nesne dedektörleriyle karşılaştırılması (kaynak)
YOLOv7, (1) mimari ve (2) Eğitilebilir ücretsiz çantalar düzeyinde büyük bir değişim yapmıştır:
YOLOv7, modelin daha iyi öğrenme için daha çeşitli özellikler öğrenmesini sağlayan Genişletilmiş Verimli Katman Toplama Ağı’nı (E-ELAN) entegre ederek mimarisini yenilemiştir.
Ek olarak, YOLOv7; YOLOv4, Ölçekli YOLOv4 ve YOLO-R gibi türetildiği modellerin mimarilerini birleştirerek mimarisini ölçeklendirir. Bu, modelin farklı çıkarım hızı gereksinimlerini karşılamasını sağlar.
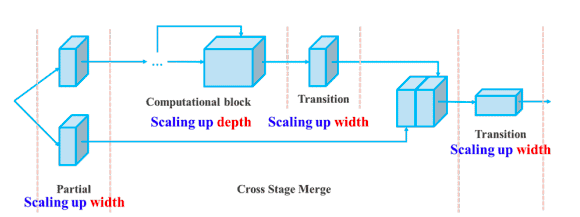
Birleştirme tabanlı model için derinlik ve genişliğin bileşik ölçeklemesi (kaynak)
Ücretsiz çantalar terimi, eğitim maliyetini artırmadan modelin doğruluğunu iyileştirmeyi ifade eder; işte bu nedenle YOLOv7 yalnızca çıkarım hızını değil, tespit doğruluğunu da artırmıştır.
YOLOv8, daha modüler ve esnek bir tasarım sunarak daha kolay özelleştirme ve ince ayar sağlar. Nesne tespitinin ötesinde, bölümleme ve pozu kestirme gibi çeşitli görevler için yerleşik destek sunar.
YOLO-NAS, el ile ayarlama olmaksızın performansı en üst düzeye çıkaran, optimize edilmiş bir mimariyi otomatik olarak tasarlamak için Sinirsel Mimari Arama (NAS) kullanır.
Tencent’in AI Lab’i tarafından geliştirilen YOLO-World, yeni bir paradigma sunar: "önce istem, sonra tespit." Belirli nesne sınıflarında eğitim gerektiren geleneksel YOLO modellerinin aksine, YOLO-World, ince ayar yapmadan metin istemlerine dayalı olarak nesneleri tespit edebilir.
Bu sıfır atış yeteneği, anlık metin kodlaması ihtiyacını ortadan kaldırır ve V100 GPU’da 74,1 FPS’ye kadar ulaşır. YOLO-World, eğitim verisi toplamadan özel nesneleri tespit etmeniz gerektiğinde özellikle kullanışlıdır.
2024’te yayımlanan YOLO’nun v9 sürümü, aşağıdakiler gibi çeşitli yenilikçi teknikler tanıtmıştır:
YOLOv9, MS COCO veri setinde yeni ölçütler belirleyerek; özellikle hassasiyet ve çeşitli görevlere uyarlanabilirlik açısından önceki sürümlere göre üstün performans sergiler. Ayrı bir açık kaynak ekip tarafından geliştirilmiş olsa da YOLOv9, Ultralytics YOLOv5’in kod tabanı üzerine inşa edilmiştir ve nesne tespitinin sınırlarını zorlamak için yapay zekâ topluluğu içindeki ortak çabayı gösterir.
Bu son sürüm, eğitim süreci ve mimaride önemli ilerlemelere dikkat çekerek gerçek zamanlı uygulamalar için verimlilik, uyarlanabilirlik ve hassasiyete odaklanır.
Mayıs 2024’te Tsinghua Üniversitesi araştırmacıları tarafından yayımlanan YOLOv10, gerçek zamanlı nesne tespitinde önemli bir atılımı temsil eder. Temel yenilik, çıkarım sırasında geleneksel olarak tespit hattına gecikme ekleyen Maksimum Olmayan Bastırma’nın (NMS) ortadan kaldırılmasıdır.
YOLOv10, NMS’siz eğitimi mümkün kılmak için tutarlı çiftli atamaları tanıtır; birden çoğa ve birden bire etiket atamalarını birleştirir. Bu yaklaşım, NMS’siz çıkarımı etkinleştirirken eğitim verimliliğini korur. Makaleye göre YOLOv10-S, benzer doğrulukla RT-DETR-R18’den 1,8× daha hızlıdır ve 2,8× daha az parametre kullanır.
Ultralytics (YOLOv5 ve YOLOv8’in geliştiricileri) tarafından geliştirilen YOLOv11; nesne tespiti, örnek bölümleme, görüntü sınıflandırma, kilit nokta tespiti ve yönlendirilmiş sınırlayıcı kutu (OBB) tespiti dahil birden çok bilgisayarlı görü görevini destekler. YOLOv11x modeli, MS COCO karşılaştırmasında %54,7 mAP değerine ulaşır.
YOLOv12, YOLO mimarisine dikkat mekanizmalarını ekleyerek modelin ilgili görüntü bölgelerine odaklanma becerisini geliştirir. Bu sürüm, çakışan nesnelerin bulunduğu karmaşık sahnelerde daha iyi doğruluk sunarken gerçek zamanlı performansı korur.
Ocak 2026’da Ultralytics tarafından yayımlanan YOLO26, beş temel görevi destekleyen, uç (edge) için optimize edilmiş uçtan uca bir modeldir: nesne tespiti, örnek bölümleme, poz kestirimi, yönlendirilmiş nesne tespiti (OBB) ve görüntü sınıflandırma. YOLO soy ağacındaki en yüksek doğruluğa ulaşırken hızlı çıkarım hızlarını korur.
YOLO26, farklı dağıtım senaryoları için doğruluk ve hızı dengelemek üzere birden çok model boyutu (Nano, Small, Medium, Large, Extra Large) sunar. Kurup kullanmak için:
from ultralytics import YOLO
# Load the model
model = YOLO("yolo26m.pt")
# Run inference
results = model("image.jpg")
results[0].show()Bu yazı, YOLO’nun diğer son teknoloji nesne tespit algoritmalarına kıyasla faydalarını ve 2015’ten 2026’ya kadar evrimini, temel iyileştirmelerine vurgu yaparak ele aldı.
YOLO’nun hızlı gelişimi göz önüne alındığında, nesne tespiti alanında çok uzun süre liderliğini sürdüreceğinden şüphe yok.
Bu yazının bir sonraki adımı, YOLO algoritmasının gerçek dünya vakalarına uygulanması olacaktır. O zamana kadar, Python’da Derin Öğrenmeye Giriş kursumuz, sinir ağlarının temellerini ve Python’da Keras 2.0 kullanarak derin öğrenme modelleri kurmayı öğrenmenize yardımcı olabilir.
Derin Öğrenme Kursları
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
