
Cours
Introduction au Deep Learning en Python
4 h
263.5K
La détection d'objets est une technique de vision par ordinateur qui permet d'identifier et de localiser des objets dans une image ou une vidéo.
La localisation d'images est le processus d'identification de l'emplacement correct d'un ou de plusieurs objets à l'aide de boîtes de délimitation, qui correspondent à des formes rectangulaires autour des objets. Ce processus est parfois confondu avec la classification ou la reconnaissance d'images, qui vise à prédire la classe d'une image ou d'un objet dans une image dans l'une des catégories ou classes.
L'illustration ci-dessous correspond à la représentation visuelle de l'explication précédente. L'objet détecté dans l'image est une "personne".

Image par l'auteur
Dans ce blog conceptuel, vous comprendrez d'abord les avantages de la détection d'objets avant de présenter YOLO, l'algorithme de détection d'objets le plus avancé.
Dans la deuxième partie, nous nous concentrerons davantage sur l'algorithme YOLO et son fonctionnement. Ensuite, nous présenterons quelques applications réelles utilisant YOLO.
La dernière section expliquera comment YOLO a évolué de 2015 à 2024 avant de conclure sur les prochaines étapes.
You Only Look Once (YOLO) est un algorithme de pointe de détection d'objets en temps réel introduit en 2015 par Joseph Redmon, Santosh Divvala, Ross Girshick et Ali Farhadi dans leur célèbre article de recherche You Only Look Once : Détection unifiée d'objets en temps réel.
Les auteurs présentent le problème de la détection d'objets comme une tâche de régression plutôt que de classification en séparant spatialement les boîtes de délimitation et en associant des probabilités à chaque image détectée à l'aide d'un seul réseau neuronal convolutionnel (CNN).
Si vous êtes intéressé par la classification d'images, envisagez de suivre le cours Image Processing with Keras in Python, dans lequel vous construirez des réseaux neuronaux profonds basés sur Keras pour des tâches de classification d'images. Si vous êtes plus intéressé par Pytorch, Deep Learning with Pytorch vous apprendra à connaître les réseaux neuronaux convolutifs et à les utiliser pour construire des modèles beaucoup plus puissants.
Parmi les raisons pour lesquelles YOLO est en tête de la compétition, on peut citer les suivantes :
Voyons ces caractéristiques plus en détail.
YOLO est extrêmement rapide parce qu'il ne traite pas de pipelines complexes. Il peut traiter des images à une vitesse de 45 images par seconde (FPS). En outre, YOLO atteint plus de deux fois la précision moyenne (mAP) par rapport à d'autres systèmes en temps réel, ce qui en fait un excellent candidat pour le traitement en temps réel.
Le graphique ci-dessous montre que YOLO dépasse largement les autres détecteurs d'objets avec 91 FPS.
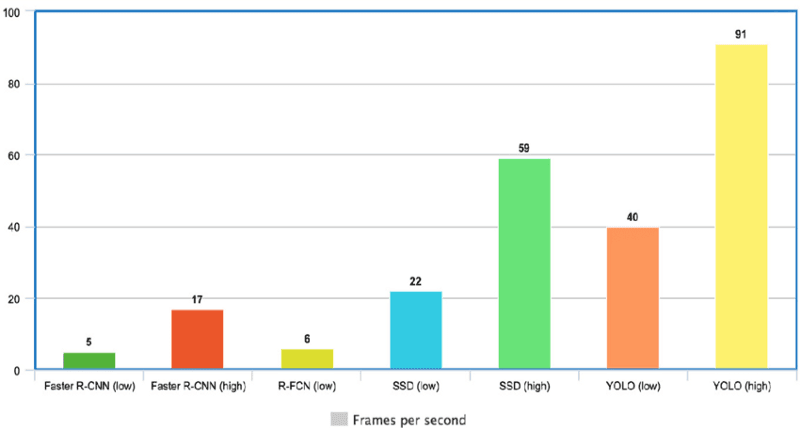
Vitesse de YOLO comparée à celle d'autres détecteurs d'objets à la pointe de la technologie(source)
YOLO dépasse largement les autres modèles de pointe en termes de précision, avec très peu d'erreurs de fond.
C'est particulièrement vrai pour les nouvelles versions de YOLO, dont il sera question plus loin dans l'article. Grâce à ces avancées, YOLO est allé un peu plus loin en offrant une meilleure généralisation pour de nouveaux domaines, ce qui le rend idéal pour les applications reposant sur une détection d'objets rapide et robuste.
Par exemple, l'article intitulé "Automatic Detection of Melanoma with Yolo Deep Convolutional Neural Networks" montre que la première version, YOLOv1, a le mAP le plus bas pour la détection automatique du mélanome, par rapport à YOLOv2 et YOLOv3.
Le fait de rendre YOLO open-source a conduit la communauté à améliorer constamment le modèle. C'est l'une des raisons pour lesquelles YOLO a apporté tant d'améliorations en si peu de temps.
L'architecture de YOLO est similaire à celle de GoogleNet. Comme illustré ci-dessous, il comporte 24 couches convolutives, quatre couches de mise en commun maximale et deux couches entièrement connectées.
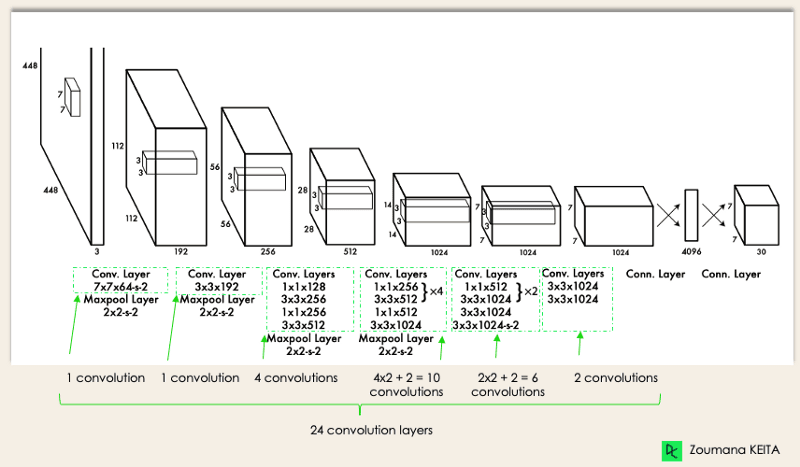
Architecture YOLO de l'article original (Modifié par l'auteur)
L'architecture fonctionne comme suit :
En suivant le cours Deep Learning in Python, vous serez prêt à utiliser Keras pour entraîner et tester des réseaux complexes à sorties multiples et vous plonger plus profondément dans l'apprentissage profond.
Maintenant que vous avez compris l'architecture, voyons comment l'algorithme YOLO effectue la détection d'objets à l'aide d'un cas d'utilisation simple.
"Imaginez que vous ayez créé une application YOLO qui détecte les joueurs et les ballons de football à partir d'une image donnée.
Mais comment expliquer ce processus à quelqu'un, en particulier aux non-initiés ?
→ C'est tout l'intérêt de cette section. Vous comprendrez comment YOLO procède à la détection d'objets et comment obtenir l'image (B) à partir de l'image (A)".
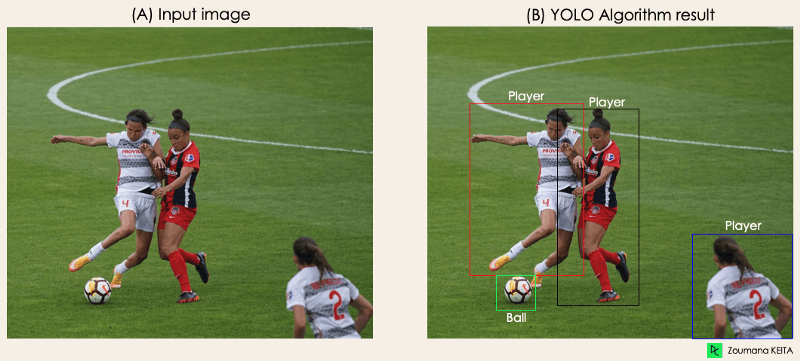 Image par l'auteur
Image par l'auteur
L'algorithme fonctionne selon les quatre approches suivantes :
Examinons chacun d'entre eux de plus près.
Cette première étape commence par la division de l'image originale (A) en NxN cellules de grille de forme égale, où N, dans notre cas, est 4, comme le montre l'image de droite. Chaque cellule de la grille est chargée de localiser et de prédire la classe de l'objet qu'elle recouvre, ainsi que la valeur de probabilité/confiance.

Image par l'auteur
L'étape suivante consiste à déterminer les boîtes de délimitation correspondant aux rectangles, en mettant en évidence tous les objets de l'image. Il peut y avoir autant de boîtes englobantes qu'il y a d'objets dans une image donnée.
YOLO détermine les attributs de ces boîtes de délimitation à l'aide d'un seul module de régression dans le format suivant, où Y est la représentation vectorielle finale de chaque boîte de délimitation.
Y = [pc, bx, by, bh, bw, c1, c2]
Ceci est particulièrement important pendant la phase de formation du modèle.
pc correspond au score de probabilité de la grille contenant un objet. Par exemple, toutes les grilles en rouge auront un score de probabilité supérieur à zéro. L'image de droite est la version simplifiée puisque la probabilité de chaque cellule jaune est nulle (non significative). 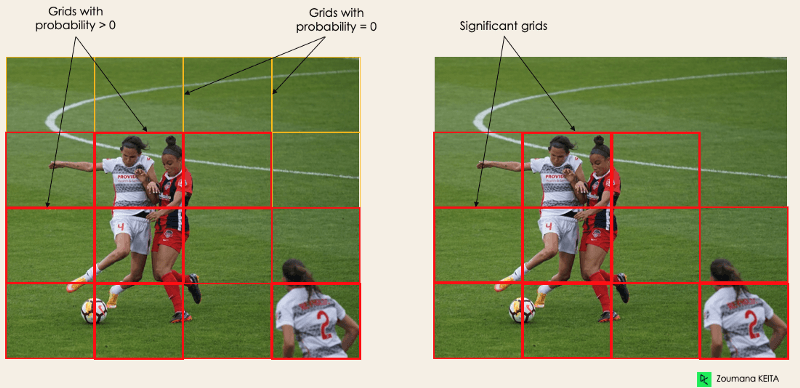
Image par l'auteur
bx, by sont les coordonnées x et y du centre de la boîte englobante par rapport à la cellule de la grille enveloppante. bhbw correspondent à la hauteur et à la largeur de la boîte de délimitation par rapport à la maille enveloppante. c1 et c2 correspondent aux deux classes Joueur et Balle. Nous pouvons avoir autant de classes que votre cas d'utilisation l'exige. Pour comprendre, regardons de plus près le joueur en bas à droite.
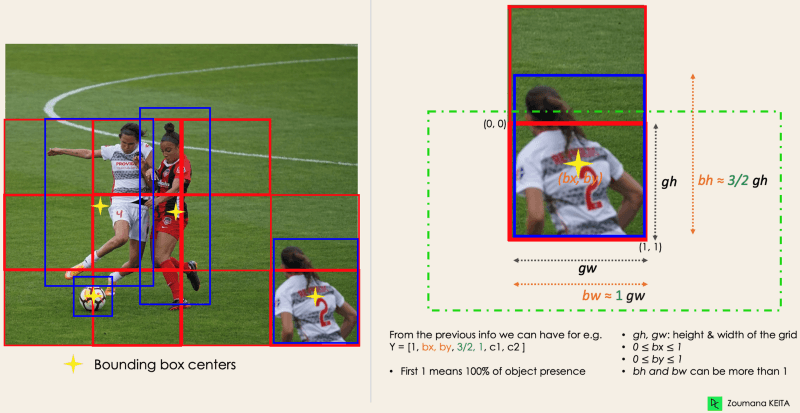 l'auteur
l'auteur
La plupart du temps, un seul objet dans une image peut avoir plusieurs boîtes à grille candidates à la prédiction, même si toutes ne sont pas pertinentes. L'objectif de l'IOU (une valeur entre 0 et 1) est d'écarter ces cases de la grille pour ne garder que celles qui sont pertinentes. En voici la logique :
Vous trouverez ci-dessous une illustration de l'application du processus de sélection de la grille à l'objet situé en bas à gauche. Nous pouvons observer que l'objet avait à l'origine deux candidats à la grille, et que seule la "grille 2" a été sélectionnée à la fin.
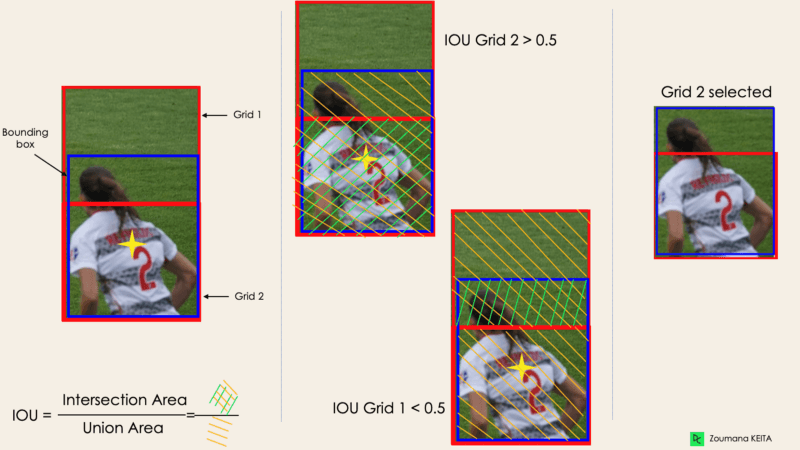
Image par l'auteur
La fixation d'un seuil pour la reconnaissance de dette n'est pas toujours suffisante, car un objet peut comporter plusieurs cases avec une reconnaissance de dette supérieure au seuil, et le fait de laisser toutes ces cases peut inclure du bruit. C'est ici que nous pouvons utiliser le SGN pour ne conserver que les boîtes dont la probabilité de détection est la plus élevée.
La détection d'objets YOLO a différentes applications dans notre vie quotidienne. Dans cette section, nous aborderons certaines d'entre elles dans les domaines suivants : soins de santé, agriculture, surveillance de la sécurité et voitures autonomes.
La détection d'objets a été introduite dans de nombreux secteurs pratiques, tels que les soins de santé et l'agriculture. Comprenons chacun d'entre eux à l'aide d'exemples concrets.
En particulier, en chirurgie, il peut être difficile de localiser les organes en temps réel en raison de la diversité biologique d'un patient à l'autre. Kidney Recognition in CT utilise YOLOv3 pour faciliter la localisation des reins en 2D et 3D à partir de tomographies informatisées (CT).
Le cours Biomedical Image Analysis in Python peut vous aider à apprendre les principes fondamentaux de l'exploration, de la manipulation et de la mesure des données d'images biomédicales à l'aide de Python.
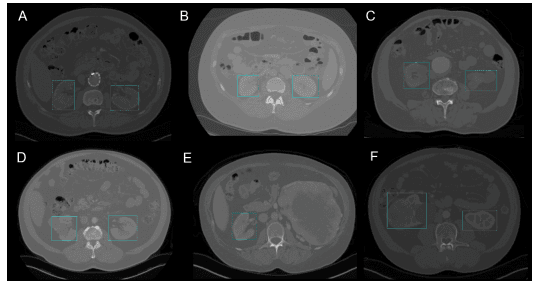
Détection des reins en 2D par YOLOv3 (Image tirée de Kidney Recognition in CT using YOLOv3)
L'intelligence artificielle et la robotique jouent un rôle majeur dans l'agriculture moderne. Les robots de récolte sont des robots basés sur la vision qui ont été introduits pour remplacer la cueillette manuelle des fruits et légumes. L'un des meilleurs modèles dans ce domaine est celui de YOLO. Dans Tomato detection based on a modified YOLOv3 framework, les auteurs décrivent comment ils ont utilisé YOLO pour identifier les types de fruits et légumes à récolter efficacement.

Image de la détection des tomates basée sur le cadre YOLOv3 modifié(source)
Même si la détection d'objets est principalement utilisée dans la surveillance de sécurité, ce n'est pas la seule application. YOLOv3 a été utilisé pendant la pandémie COVID-19 pour estimer les violations de la distance sociale entre les personnes.
Vous pouvez poursuivre votre lecture sur ce sujet en lisant A deep-learning-based social distance monitoring framework for COVID-19.
La détection d'objets en temps réel fait partie de l'ADN des systèmes de véhicules autonomes. Cette intégration est vitale pour les véhicules autonomes, car ils doivent identifier correctement les voies de circulation et tous les objets et piétons environnants afin d'accroître la sécurité routière. L'aspect temps réel de YOLO en fait un meilleur candidat que les simples approches de segmentation d'images.
Depuis sa première sortie en 2015, YOLO a beaucoup évolué, avec différentes versions. Dans cette section, nous allons comprendre les différences entre ces versions.
Cette première version de YOLO a changé la donne en matière de détection d'objets, car elle permettait de reconnaître rapidement et efficacement les objets.
Cependant, comme beaucoup d'autres solutions, la première version de YOLO a ses propres limites :
YOLOv2 a été créé en 2016 avec l'idée de rendre le modèle YOLO meilleur, plus rapide et plus fort.
L'amélioration comprend, sans s'y limiter, l'utilisation de Darknet-19 comme nouvelle architecture, la normalisation des lots, une résolution plus élevée des entrées, des couches de convolution avec des ancres, le regroupement des dimensions et (5) des caractéristiques à grain fin.
L'ajout d'une couche de normalisation par lots a permis d'améliorer les performances de 2% mAP. Cette normalisation par lots inclut un effet de régularisation, empêchant l'ajustement excessif.
YOLOv2 utilise directement une entrée de plus haute résolution 448×448 au lieu de 224×224, ce qui oblige le modèle à ajuster son filtre pour obtenir de meilleures performances sur les images de plus haute résolution. Cette approche a permis d'augmenter la précision de 4% mAP, après avoir été entraînée pendant 10 époques sur les données ImageNet.
Au lieu de prédire les coordonnées exactes des boîtes de délimitation des objets comme le fait YOLOv1, YOLOv2 simplifie le problème en remplaçant les couches entièrement connectées par des boîtes d'ancrage. Cette approche diminue légèrement la précision mais améliore le rappel du modèle de 7 %, ce qui laisse une plus grande marge d'amélioration.
YOLOv2 trouve automatiquement les boîtes d'ancrage mentionnées précédemment en utilisant le regroupement dimensionnel k-means avec k=5 au lieu d'effectuer une sélection manuelle. Cette nouvelle approche offre un bon compromis entre le rappel et la précision du modèle.
Pour une meilleure compréhension du clustering de dimensionnalité k-means, consultez nos tutoriels K-Means Clustering in Python with scikit-learn et K-Means Clustering in R. Ils se plongent dans le concept de clustering k-means en utilisant Python et R.
Les prédictions de YOLOv2 génèrent des cartes de caractéristiques 13x13, ce qui est bien sûr suffisant pour la détection d'objets de grande taille. Mais pour la détection d'objets beaucoup plus fins, l'architecture peut être modifiée en transformant la carte de caractéristiques 26 × 26 × 512 en une carte de caractéristiques 13 × 13 × 2048, concaténée avec les caractéristiques d'origine. Cette approche a permis d'améliorer la performance du modèle de 1 %.
Une amélioration progressive a été apportée à YOLOv2 pour créer YOLOv3.
Le changement comprend principalement une nouvelle architecture de réseau : Darknet-53. Il s'agit d'un réseau de 106 neurones, avec des réseaux de suréchantillonnage et des blocs résiduels. Il est beaucoup plus grand, plus rapide et plus précis que Darknet-19, qui est l'épine dorsale de YOLOv2. Cette nouvelle architecture a été bénéfique à bien des égards :
YOLOv3 utilise un modèle de régression logistique pour prédire le score d'objectivité de chaque boîte englobante.
Au lieu d'utiliser la méthode softmax comme dans YOLOv2, des classificateurs logistiques indépendants ont été introduits pour prédire avec précision la classe des boîtes englobantes. Cela s'avère même utile lorsque vous êtes confronté à des domaines plus complexes dont les étiquettes se chevauchent (par exemple, Personne → Joueur de football). L'utilisation d'une softmax contraindrait chaque boîte à n'avoir qu'une seule classe, ce qui n'est pas toujours le cas.
YOLOv3 effectue trois prédictions à différentes échelles pour chaque emplacement de l'image d'entrée afin de faciliter le rééchantillonnage des couches précédentes. Cette stratégie permet d'obtenir des informations sémantiques plus fines et plus significatives pour une image de sortie de meilleure qualité.
Cette version de YOLO offre une vitesse et une précision optimales de détection des objets par rapport à toutes les versions précédentes et à d'autres détecteurs d'objets à la pointe de la technologie.
L'image ci-dessous montre que YOLOv4 surpasse YOLOv3 et FPS en vitesse de 10% et 12% respectivement.
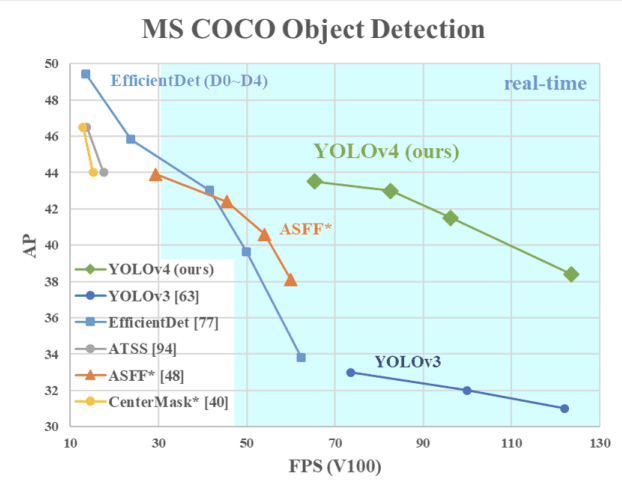
Vitesse de YOLOv4 comparée à celle de YOLOv3 et d'autres détecteurs d'objets de pointe(source)
YOLOv4 est spécifiquement conçu pour les systèmes de production et optimisé pour les calculs parallèles.
L'épine dorsale de l'architecture de YOLOv4 est CSPDarknet53, un réseau contenant 29 couches de convolution avec 3 × 3 filtres et environ 27,6 millions de paramètres.
Cette architecture, comparée à YOLOv3, ajoute les informations suivantes pour une meilleure détection des objets :
En tant que réseau unifié pour des tâches multiples, YOLOR est basé sur le réseau unifié qui est une combinaison d'approches de connaissances explicites et implicites.
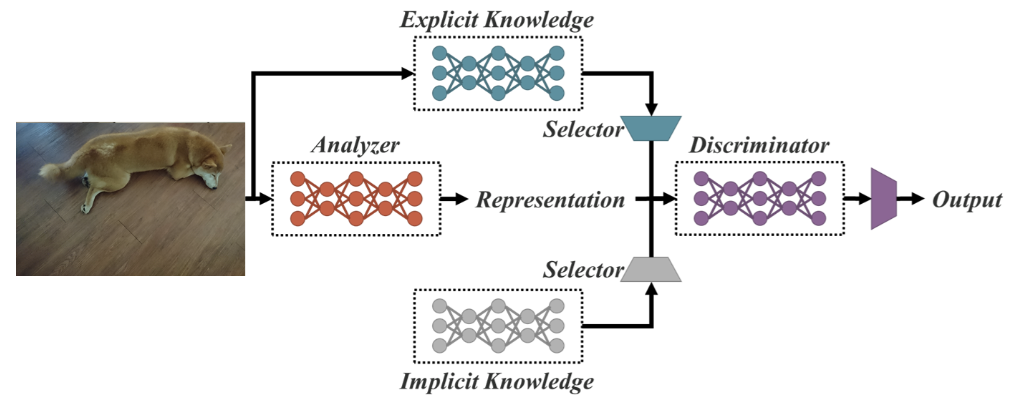
Architecture de réseau unifiée (source)
La connaissance explicite est l'apprentissage normal ou conscient. L'apprentissage implicite, quant à lui, est réalisé de manière subconsciente (à partir de l'expérience).
En combinant ces deux techniques, YOLOR est capable de créer une architecture plus robuste basée sur trois processus : (1) alignement des caractéristiques, (2) alignement des prédictions pour la détection d'objets, et (3) représentation canonique pour l'apprentissage multitâche.
Cette approche introduit une représentation implicite dans la carte des caractéristiques de chaque réseau pyramidal de caractéristiques (FPN), ce qui améliore la précision d'environ 0,5 %.
Les prédictions du modèle sont affinées en ajoutant une représentation implicite aux couches de sortie du réseau.
L'entraînement multitâche nécessite l'exécution de l'optimisation conjointe de la fonction de perte partagée entre toutes les tâches. Ce processus peut diminuer les performances globales du modèle, et ce problème peut être atténué par l'intégration de la représentation canonique lors de l'apprentissage du modèle.
Le graphique suivant montreque YOLOR a atteint, sur les données MS COCO, une vitesse d'inférence de pointe par rapport aux autres modèles.
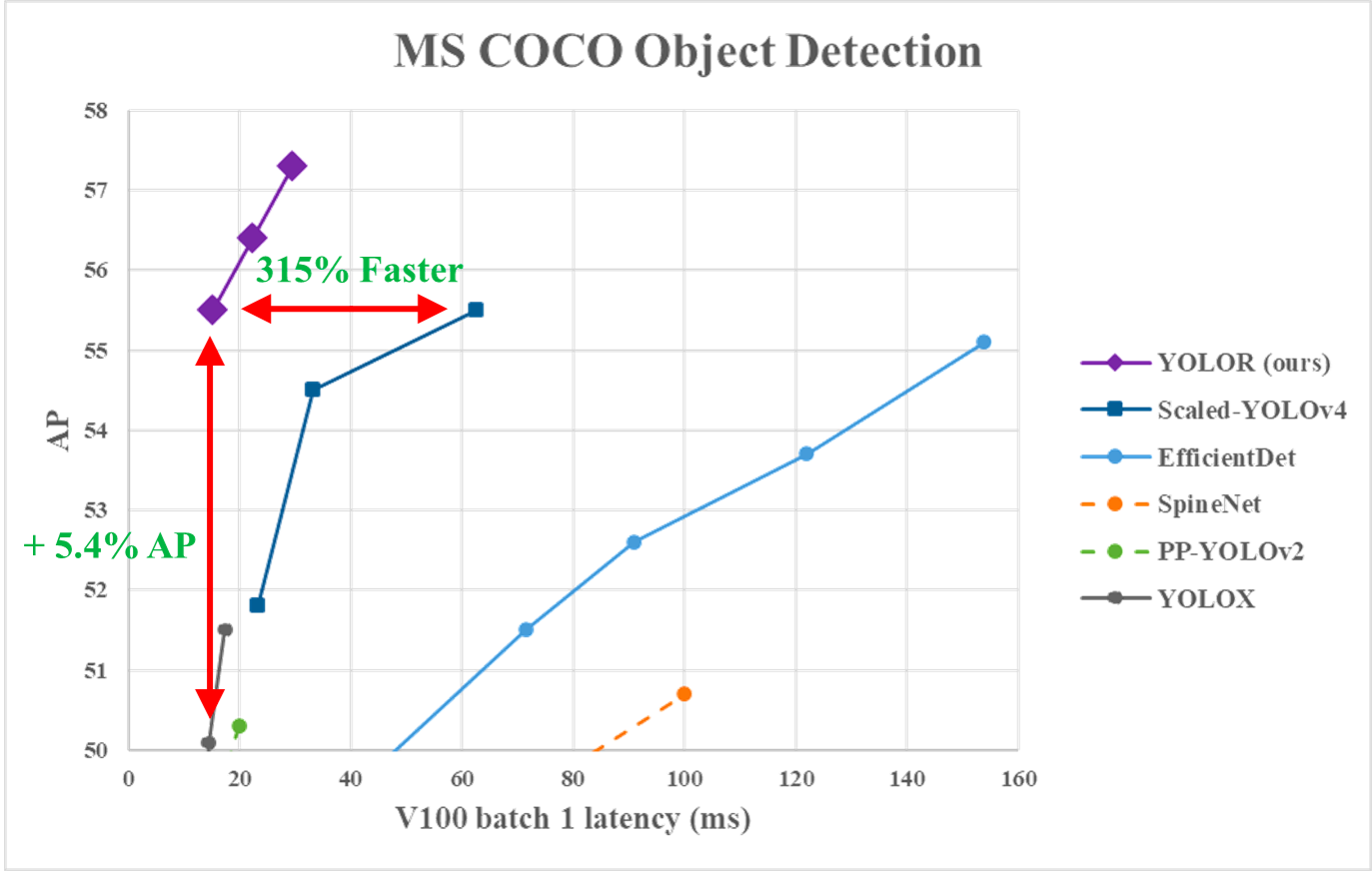
Performance de YOLOR vs. YOLOv4 et autres modèles (source)
Il s'agit d'une version modifiée de YOLOv3, dont l'épine dorsale est Darknet-53.
Publié dans l'article Dépasser la série YOLO en 2021, YOLOX apporte les quatre caractéristiques clés suivantes pour créer un meilleur modèle par rapport aux anciennes versions.
Il est démontré que la tête couplée utilisée dans les versions précédentes de YOLO réduit les performances des modèles. YOLOX utilise un modèle découplé, qui permet de séparer les tâches de classification et de localisation, augmentant ainsi les performances du modèle.
L'intégration de Mosaic et de MixUp dans l'approche d'augmentation des données a considérablement accru les performances de YOLOX.
Les algorithmes basés sur l'ancrage effectuent le regroupement sous le capot, ce qui augmente le temps d'inférence. La suppression du mécanisme d'ancrage dans YOLOX a permis de réduire le nombre de prédictions par image et d'améliorer considérablement le temps d'inférence.
Au lieu d'utiliser l'approche de l'intersection de l'union (IoU), l'auteur a introduit SimOTA, une stratégie d'attribution d'étiquettes plus robuste qui permet d'obtenir des résultats de pointe non seulement en réduisant le temps d'apprentissage mais aussi en évitant les problèmes d'hyperparamètres supplémentaires. En outre, il a permis d'améliorer le taux de détection de 3 %.
Par rapport aux autres versions, YOLOv5 n'a pas fait l'objet d'un article de recherche publié, et c'est la première version de YOLO à être mise en œuvre dans Pytorch, plutôt que dans Darknet.
Publié par Glenn Jocher en juin 2020, YOLOv5, comme YOLOv4, utilise CSPDarknet53 comme colonne vertébrale de son architecture. La version comprend cinq modèles de tailles différentes : YOLOv5s (le plus petit), YOLOv5m, YOLOv5l et YOLOv5x (le plus grand).
L'une des principales améliorations de l'architecture de YOLOv5 est l'intégration de la couche Focus, représentée par une seule couche, créée en remplaçant les trois premières couches de YOLOv3. Cette intégration a permis de réduire le nombre de couches et le nombre de paramètres et d'augmenter la vitesse d'avance et de recul sans impact majeur sur le mAP.
L'illustration suivante compare le temps de formation entre YOLOv4 et YOLOv5s.
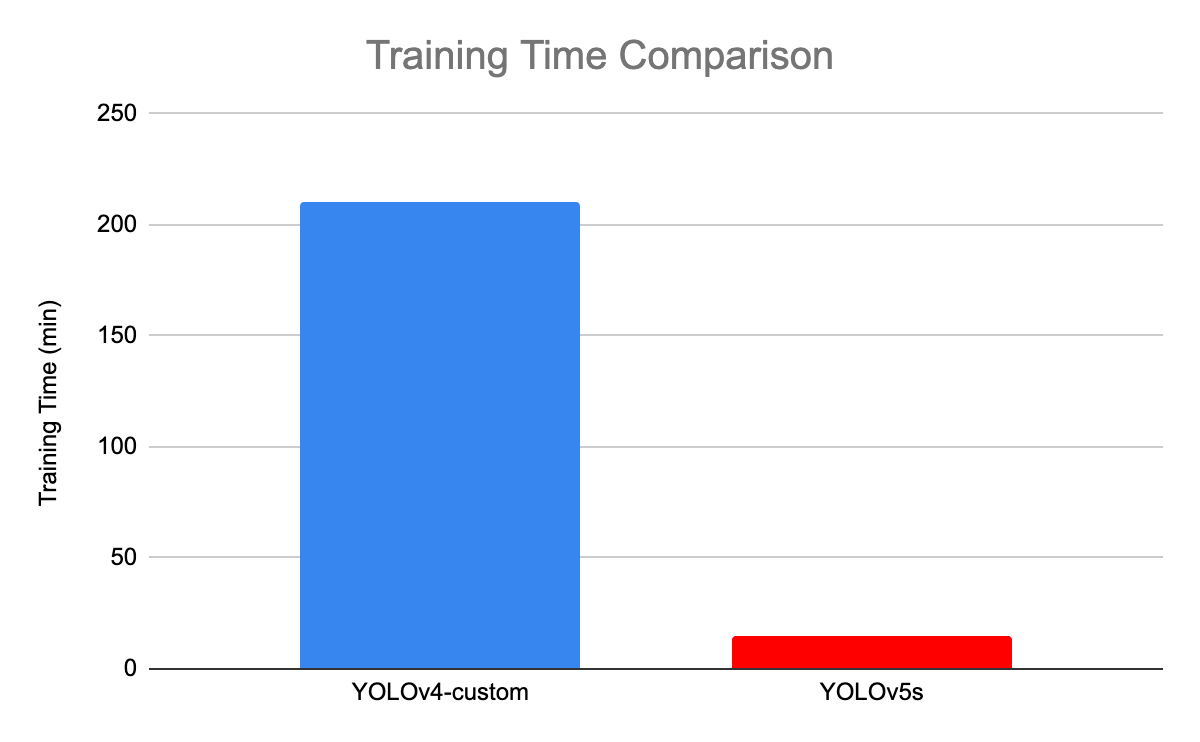
Comparaison des temps de formation entre YOLOv4 et YOLOv5(source)
Dédié aux applications industrielles avec une conception efficace et conviviale et des performances élevées, le framework YOLOv6 (MT-YOLOv6) a été lancé par Meituan, une société chinoise de commerce électronique.
Écrite en Pytorch, cette nouvelle version ne faisait pas partie de la version officielle de YOLO, mais a tout de même reçu le nom de YOLOv6, car son ossature s'inspirait de l'architecture originale de YOLO à une étape.
YOLOv6 a introduit trois améliorations significatives par rapport à YOLOv5 : une conception de l'épine dorsale et du cou adaptée au matériel, une tête découplée efficace et une stratégie d'entraînement plus efficace.
YOLOv6 fournit des résultats exceptionnels par rapport aux versions précédentes de YOLO en termes de précision et de rapidité sur l'ensemble de données COCO, comme illustré ci-dessous.
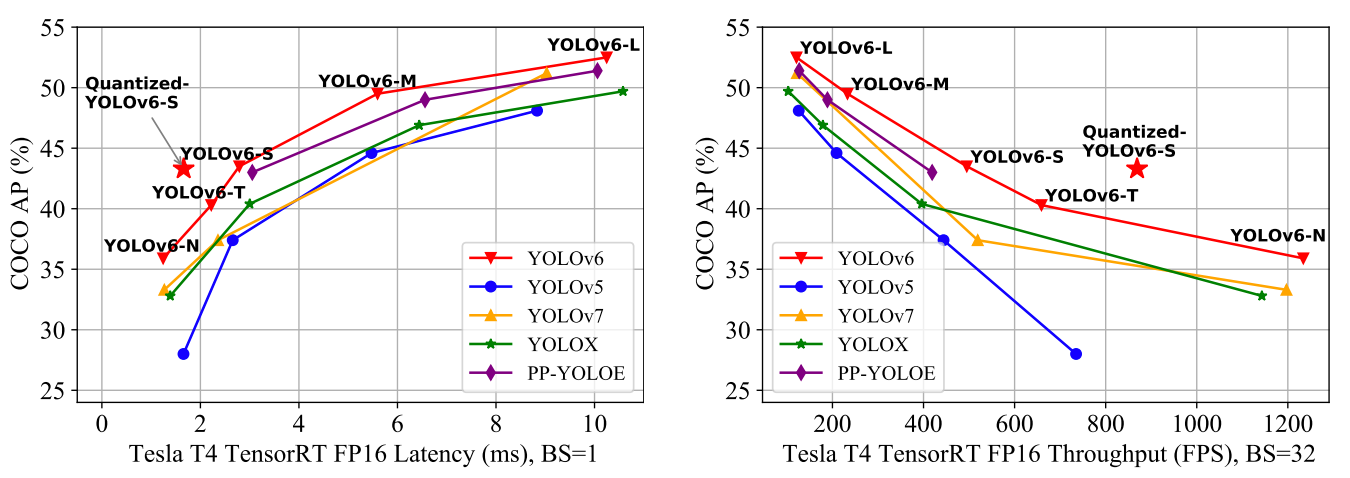
Comparaison de l'état de l'art des détecteurs d'objets efficaces. Tous les modèles sont testés avec TensorRT 7 sauf le modèle quantifié qui est testé avec TensorRT 8(source).
Toutes ces caractéristiques font de YOLOv5 l'algorithme idéal pour les applications industrielles.
YOLOv7 a été publié en juillet 2022 dans le journal Trained bag-of-freebies sets new state-of-the-art for real-time object detectors. Cette version constitue une avancée significative dans le domaine de la détection d'objets et surpasse tous les modèles précédents en termes de précision et de rapidité.
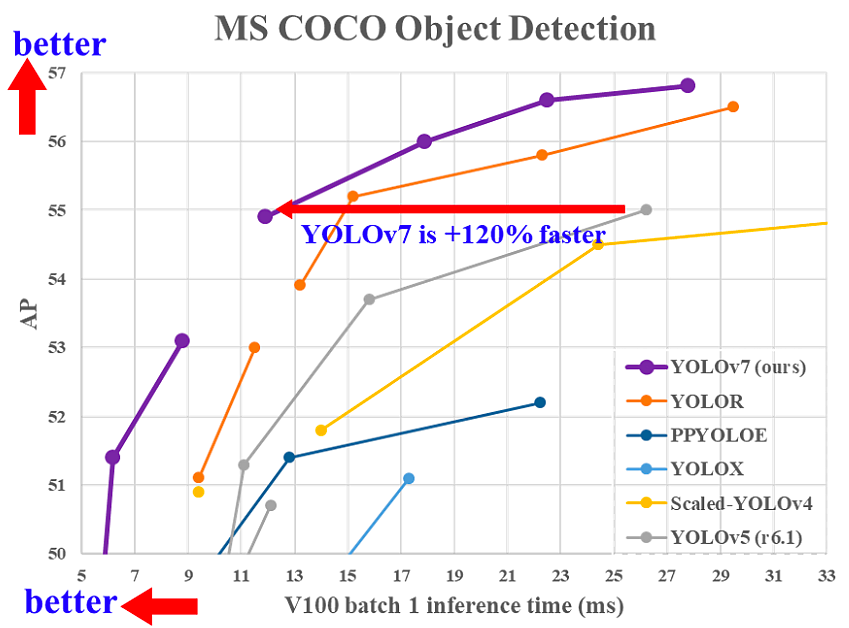
Comparaison du temps d'inférence de YOLOv7 avec d'autres détecteurs d'objets en temps réel(source)
YOLOv7 a apporté un changement majeur (1) dans son architecture et (2) au niveau de la pochette de formation (Trainable bag-of-freebies) :
YOLOv7 a réformé son architecture en intégrant le réseau E-ELAN (Extended Efficient Layer Aggregation Network) qui permet au modèle d'apprendre des caractéristiques plus diverses pour un meilleur apprentissage.
En outre, YOLOv7 fait évoluer son architecture en concaténant l'architecture des modèles dont il est dérivé, tels que YOLOv4, Scaled YOLOv4 et YOLO-R. Cela permet au modèle de répondre aux besoins des différentes vitesses d'inférence.
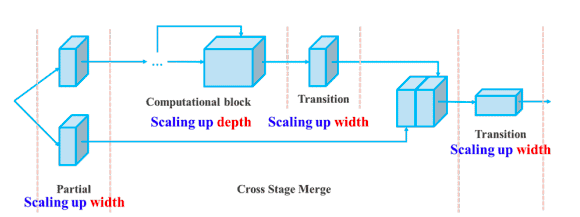
Composé augmentant la profondeur et la largeur pour le modèle basé sur la concaténation(source)
Le terme " bag-of-freebies" fait référence à l'amélioration de la précision du modèle sans augmenter le coût de formation. C'est la raison pour laquelle YOLOv7 a permis d'augmenter non seulement la vitesse d'inférence mais aussi la précision de la détection.
YOLOv8 introduit une conception plus modulaire et plus flexible, permettant une personnalisation et un réglage plus faciles. Prise en charge intégrée de diverses tâches au-delà de la détection d'objets, telles que la segmentation et l'estimation de la pose.
YOLO-NAS utilise la recherche d'architecture neuronale (NAS) pour concevoir automatiquement une architecture optimisée, maximisant les performances sans réglage manuel.
Lancée en 2024, la version v9 de YOLO introduit plusieurs techniques innovantes, telles que les suivantes :
YOLOv9 établit de nouvelles références sur l'ensemble de données MS COCO, démontrant des performances supérieures à celles des versions précédentes, notamment en termes de précision et d'adaptabilité à diverses tâches. Bien que développé par une équipe open-source distincte, YOLOv9 s'appuie sur la base de code d'Ultralytics YOLOv5, témoignant d'un effort de collaboration au sein de la communauté de l'IA pour repousser les limites de la détection d'objets.
Cette dernière version présente des avancées substantielles tant au niveau du processus de formation que de l'architecture, en mettant l'accent sur l'efficacité, l'adaptabilité et la précision pour les applications en temps réel.
Cet article présente les avantages de YOLO par rapport à d'autres algorithmes de détection d'objets de pointe, ainsi que son évolution de 2015 à 2020, en mettant l'accent sur ses avantages.
Compte tenu des progrès rapides de YOLO, il ne fait aucun doute qu'il restera pendant très longtemps le leader dans le domaine de la détection d'objets.
La prochaine étape de cet article sera l'application de l'algorithme YOLO à des cas réels. D'ici là, notre cours Introduction à l'apprentissage profond en Python peut vous aider à apprendre les principes fondamentaux des réseaux neuronaux et à construire des modèles d'apprentissage profond à l'aide de Keras 2.0 en Python.
Cours sur l'apprentissage profond
Cours
Cours
Cours
blog
blog
Kurtis Pykes
9 min
blog
Kurtis Pykes
15 min
Tutoriel
Samuel Shaibu
Tutoriel
Moez Ali
Tutoriel

