Kurs
Einführung in Deep Learning mit Python
4 Std.
263.5K
Die Objekterkennung ist eine Technik, die in der Computer Vision zur Identifizierung und Lokalisierung von Objekten in einem Bild oder einem Video verwendet wird.
Bei der Bildlokalisierung wird die korrekte Position eines oder mehrerer Objekte mithilfe von Begrenzungsrahmen (Bounding Boxes) bestimmt, die rechteckigen Formen um die Objekte entsprechen.
Dieser Prozess wird manchmal mit der Bildklassifizierung oder Bilderkennung verwechselt, die darauf abzielt, die Klasse eines Bildes oder eines Objekts innerhalb eines Bildes in eine der Kategorien oder Klassen vorherzusagen.
Die folgende Abbildung entspricht der visuellen Darstellung der vorherigen Erklärung. Das im Bild erkannte Objekt ist "Person".

Bild vom Autor
In diesem konzeptionellen Blog wirst du zunächst die Vorteile der Objekterkennung verstehen, bevor du YOLO, den modernsten Algorithmus zur Objekterkennung, kennenlernst.
Im zweiten Teil werden wir uns mehr mit dem YOLO-Algorithmus und seiner Funktionsweise beschäftigen. Danach werden wir einige Anwendungen aus der Praxis vorstellen, bei denen YOLO zum Einsatz kommt.
Im letzten Abschnitt wird erklärt, wie sich YOLO von 2015 bis 2020 entwickelt hat, bevor wir die nächsten Schritte abschließen.
You Only Look Once (YOLO) ist ein hochmoderner Echtzeit-Algorithmus zur Objekterkennung, der 2015 von Joseph Redmon, Santosh Divvala, Ross Girshick und Ali Farhadi in ihrer berühmten Forschungsarbeit "You Only Look Once" vorgestellt wurde: Einheitliche Objektdetektion in Echtzeit".
Die Autoren betrachten das Problem der Objekterkennung als ein Regressionsproblem anstelle einer Klassifizierungsaufgabe, indem sie Bounding Boxes räumlich trennen und jedem der erkannten Bilder Wahrscheinlichkeiten zuordnen, indem sie ein einzelnes Faltungsneuronales Netzwerk (CNN) verwenden.
Wenn du den Kurs Bildverarbeitung mit Keras in Python belegst, wirst du in der Lage sein, Keras-basierte tiefe neuronale Netze für Bildklassifizierungsaufgaben zu erstellen.
Wenn du dich mehr für Pytorch interessierst, lernst du in Deep Learning with Pytorch mehr über Faltungsneuronale Netze und wie du mit ihnen viel leistungsfähigere Modelle bauen kannst.
Einige der Gründe, warum YOLO den Wettbewerb anführt, sind seine:
YOLO ist extrem schnell, weil es nicht mit komplexen Pipelines arbeitet. Er kann Bilder mit 45 Bildern pro Sekunde (FPS) verarbeiten. Außerdem erreicht YOLO im Vergleich zu anderen Echtzeitsystemen eine mehr als doppelt so hohe mittlere Genauigkeit (mAP), was es zu einem hervorragenden Kandidaten für die Echtzeitverarbeitung macht.
Aus der untenstehenden Grafik geht hervor, dass YOLO mit 91 FPS weit vor den anderen Objektdetektoren liegt.
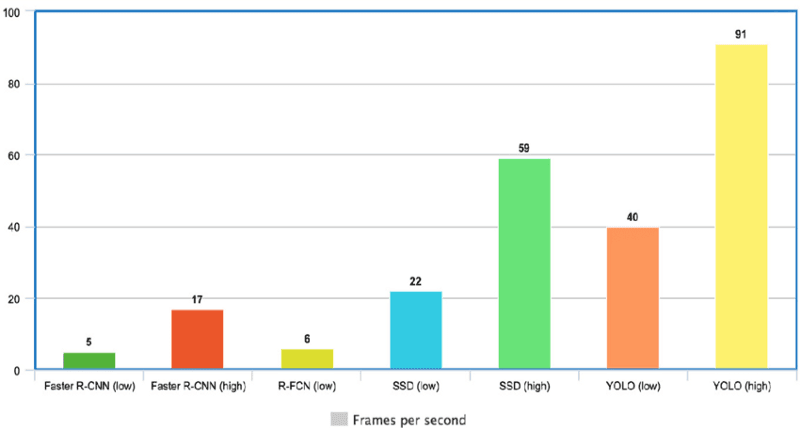
YOLO Geschwindigkeit im Vergleich zu anderen modernen Objektdetektoren(Quelle)
YOLO übertrifft die Genauigkeit anderer moderner Modelle bei weitem und weist nur sehr wenige Hintergrundfehler auf.
Das gilt vor allem für die neuen Versionen von YOLO, auf die wir später in diesem Artikel eingehen werden. Mit diesen Fortschritten ist YOLO noch einen Schritt weiter gegangen, indem es eine bessere Verallgemeinerung für neue Bereiche bietet, was es für Anwendungen, die auf eine schnelle und robuste Objekterkennung angewiesen sind, ideal macht.
So zeigt zum Beispiel das Paper Automatic Detection of Melanoma with Yolo Deep Convolutional Neural Networks, dass die erste Version YOLOv1 im Vergleich zu YOLOv2 und YOLOv3 die niedrigste durchschnittliche Genauigkeit bei der automatischen Erkennung von Melanomen aufweist.
Die Veröffentlichung von YOLO als Open Source führte dazu, dass die Gemeinschaft das Modell ständig verbesserte. Das ist einer der Gründe, warum YOLO in so kurzer Zeit so viele Verbesserungen vorgenommen hat.
Die Architektur von YOLO ist ähnlich wie die von GoogleNet. Wie unten dargestellt, hat es insgesamt 24 Faltungsschichten, vier Max-Pooling-Schichten und zwei voll verknüpfte Schichten.
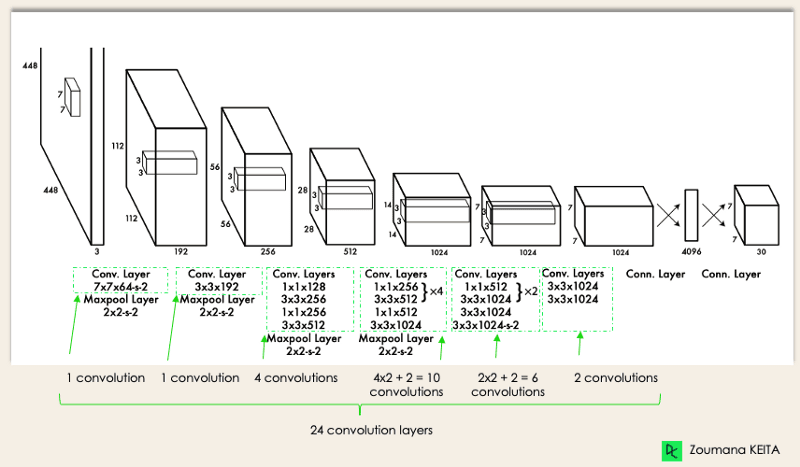
YOLO-Architektur aus dem Originalbeitrag (vom Autor geändert)
Die Architektur funktioniert folgendermaßen:
Nach Abschluss des Kurses Deep Learning in Python bist du in der Lage, mit Keras komplexe Netzwerke mit mehreren Ausgängen zu trainieren und zu testen und tiefer in das Deep Learning einzutauchen.
Nachdem du nun die Architektur verstanden hast, wollen wir uns einen Überblick darüber verschaffen, wie der YOLO-Algorithmus die Objekterkennung anhand eines einfachen Anwendungsfalls durchführt.
"Stell dir vor, du hast eine YOLO-Anwendung entwickelt, die Spieler und Fußbälle in einem bestimmten Bild erkennt.
Aber wie kannst du diesen Prozess jemandem erklären, vor allem nicht eingeweihten Menschen?
→ Das ist der ganze Sinn dieses Abschnitts. Du wirst verstehen, wie YOLO die Objekterkennung durchführt und wie man Bild (B) aus Bild (A) erhält.
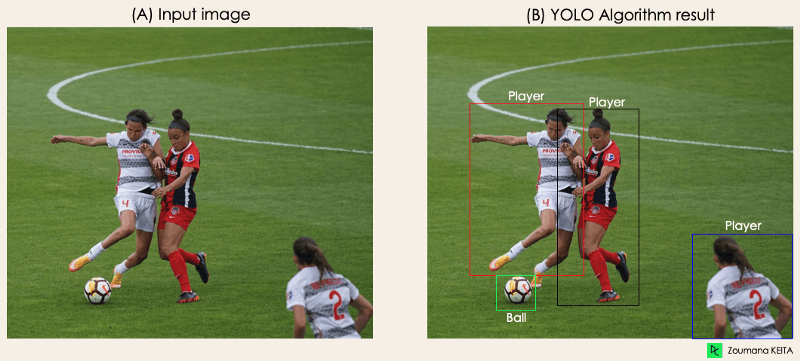 Bild vom Autor
Bild vom Autor
Der Algorithmus funktioniert auf der Grundlage der folgenden vier Ansätze:
Schauen wir uns jede einzelne von ihnen genauer an.
In diesem ersten Schritt wird das Originalbild (A) in NxN gleich große Gitterzellen unterteilt, wobei N in unserem Fall 4 ist (siehe Bild rechts). Jede Zelle im Raster ist für die Lokalisierung und Vorhersage der Klasse des Objekts verantwortlich, das sie abdeckt, zusammen mit dem Wahrscheinlichkeits-/Vertrauenswert.

Bild vom Autor
Im nächsten Schritt werden die Bounding Boxes bestimmt, die den Rechtecken entsprechen, die alle Objekte im Bild markieren. Wir können so viele Bounding Boxes haben, wie es Objekte in einem bestimmten Bild gibt.
YOLO bestimmt die Attribute dieser Boundingboxen mithilfe eines einzigen Regressionsmoduls im folgenden Format, wobei Y die endgültige Vektordarstellung für jede Boundingbox ist.
Y = [pc, bx, by, bh, bw, c1, c2]
Dies ist vor allem während der Trainingsphase des Modells wichtig.
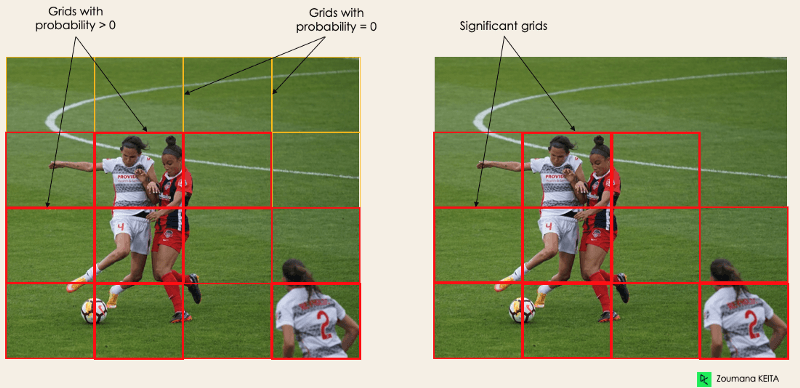
Bild vom Autor
Um das zu verstehen, schauen wir uns den Spieler unten rechts genauer an.
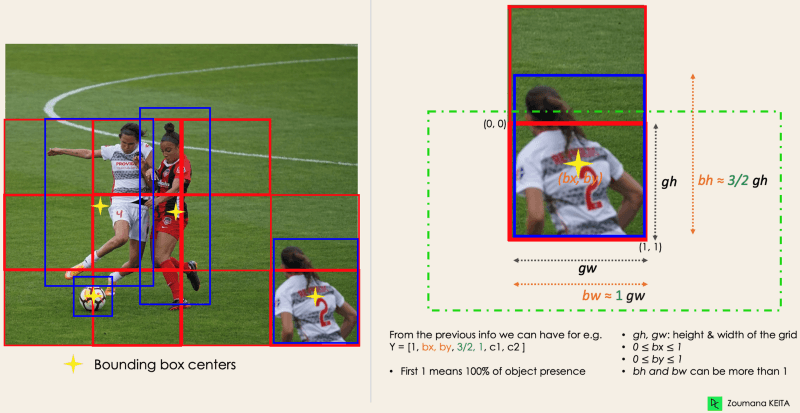 vom Autor
vom Autor
Meistens gibt es für ein einzelnes Objekt in einem Bild mehrere Gitterboxen, die für eine Vorhersage in Frage kommen, auch wenn nicht alle von ihnen relevant sind. Das Ziel des IOU (ein Wert zwischen 0 und 1) ist es, solche Gitterboxen zu verwerfen und nur die zu behalten, die relevant sind. Hier ist die Logik dahinter:
Unten siehst du eine Illustration der Anwendung des Rasterauswahlverfahrens auf das Objekt unten links. Wir können sehen, dass das Objekt ursprünglich zwei Raster-Kandidaten hatte, dann wurde am Ende nur "Raster 2" ausgewählt.
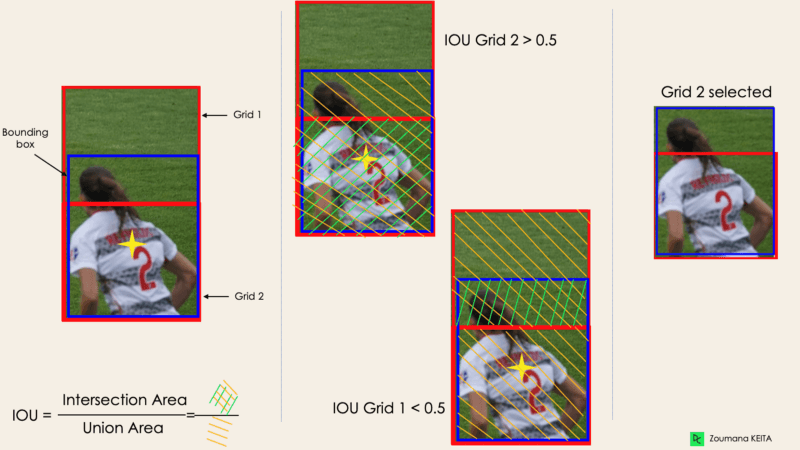
Bild vom Autor
Es reicht nicht immer aus, einen Schwellenwert für den IOU festzulegen, denn ein Objekt kann mehrere Kästchen mit IOU über dem Schwellenwert haben, und alle diese Kästchen zu verlassen, könnte Rauschen enthalten. Hier können wir NMS nutzen, um nur die Kisten mit der höchsten Aufdeckungswahrscheinlichkeit zu behalten.
Die YOLO-Objekterkennung hat verschiedene Anwendungen in unserem täglichen Leben. In diesem Abschnitt werden wir einige von ihnen in den folgenden Bereichen behandeln: Gesundheitswesen, Landwirtschaft, Sicherheitsüberwachung und selbstfahrende Autos.
Die Objekterkennung hat sich in vielen praktischen Branchen wie dem Gesundheitswesen und der Landwirtschaft durchgesetzt. Lasst uns jede einzelne mit konkreten Beispielen verstehen.
Gerade in der Chirurgie kann es aufgrund der biologischen Vielfalt von Patient zu Patient eine Herausforderung sein, Organe in Echtzeit zu lokalisieren. Die Nierenerkennung im CT verwendet YOLOv3, um die Lokalisierung von Nieren in 2D und 3D auf Computertomografiescans (CT) zu erleichtern.
Der Kurs Biomedizinische Bildanalyse in Python hilft dir, die Grundlagen der Erforschung, Bearbeitung und Messung biomedizinischer Bilddaten mit Python zu erlernen.
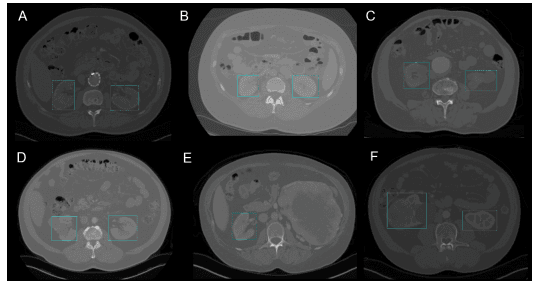
2D Nierenerkennung durch YOLOv3 (Bild aus Nierenerkennung im CT mit YOLOv3)
Künstliche Intelligenz und Robotik spielen in der modernen Landwirtschaft eine große Rolle. Ernteroboter sind bildverarbeitungsbasierte Roboter, die eingeführt wurden, um das manuelle Pflücken von Obst und Gemüse zu ersetzen. Eines der besten Modelle in diesem Bereich verwendet YOLO. In Tomato detection based on modified YOLOv3 framework (Tomatenerkennung auf Basis eines modifizierten YOLOv3-Frameworks) beschreiben die Autoren, wie sie YOLO eingesetzt haben, um die Obst- und Gemüsesorten für eine effiziente Ernte zu identifizieren.

Bild aus der Tomatenerkennung basierend auf dem modifizierten YOLOv3 Framework(Quelle)
Auch wenn die Objekterkennung vor allem in der Sicherheitsüberwachung eingesetzt wird, ist das nicht die einzige Anwendung. YOLOv3 wurde während der Covid19-Pandemie eingesetzt, um Verletzungen der sozialen Distanz zwischen Menschen abzuschätzen.
Du kannst deine Lektüre zu diesem Thema unter A deep-learning-based social distance monitoring framework for COVID-19 fortsetzen.
Die Erkennung von Objekten in Echtzeit ist Teil der DNA von autonomen Fahrzeugsystemen. Diese Integration ist für autonome Fahrzeuge von entscheidender Bedeutung, denn sie müssen die richtigen Fahrspuren und alle umliegenden Objekte und Fußgänger richtig erkennen, um die Verkehrssicherheit zu erhöhen. Der Echtzeitaspekt von YOLO macht es im Vergleich zu einfachen Bildsegmentierungsansätzen zu einem besseren Kandidaten.
Seit der ersten Veröffentlichung von YOLO im Jahr 2015 hat es sich mit verschiedenen Versionen stark weiterentwickelt. In diesem Abschnitt werden wir die Unterschiede zwischen den einzelnen Versionen verstehen.
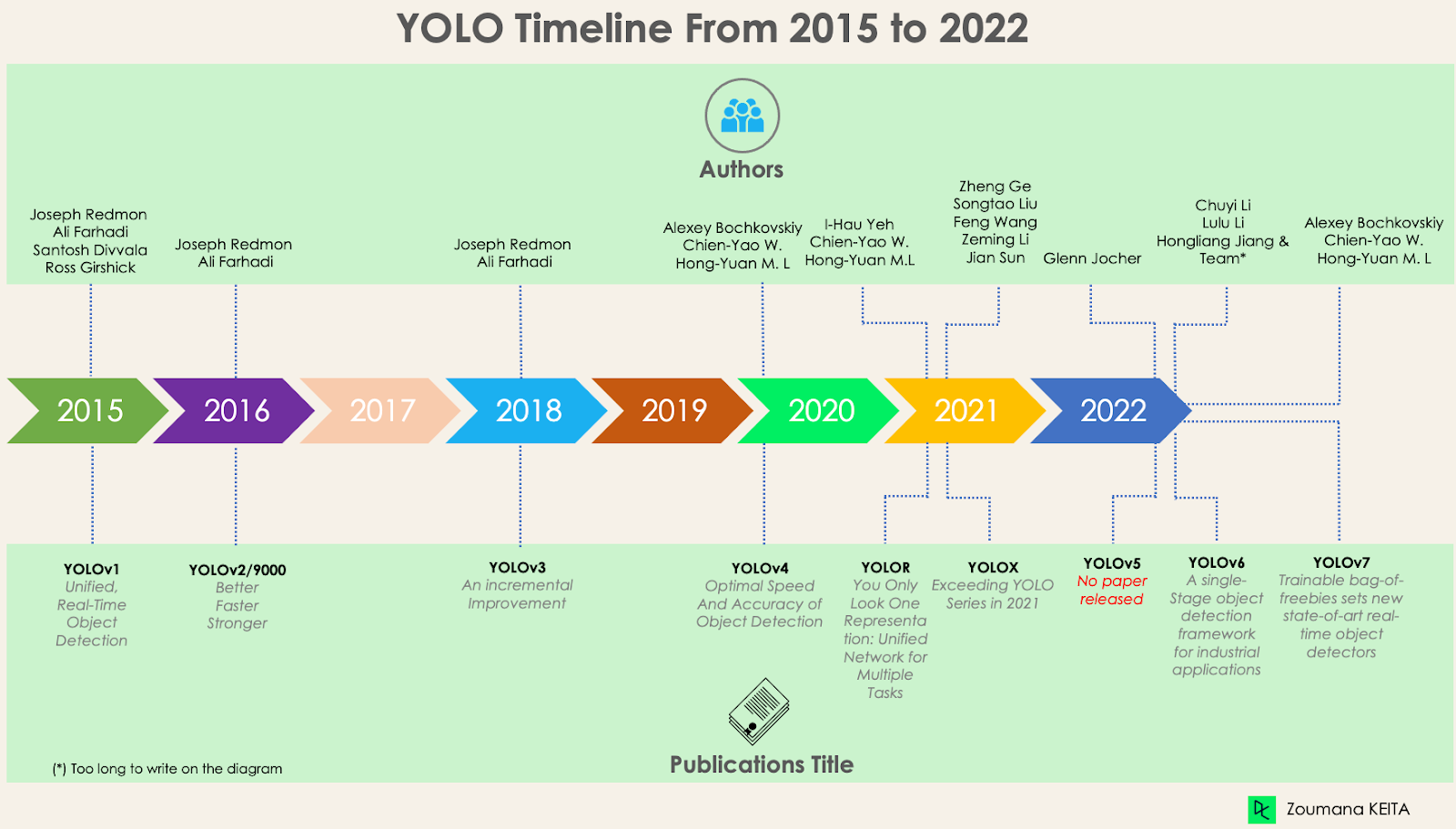
Diese erste Version von YOLO war für die Objekterkennung bahnbrechend, da sie Objekte schnell und effizient erkennen konnte.
Doch wie viele andere Lösungen hat auch die erste Version von YOLO ihre eigenen Grenzen:
YOLOv2 wurde 2016 mit der Idee entwickelt, das YOLO-Modell besser, schneller und stärker zu machen.
Zu den Verbesserungen gehören u. a. die Verwendung von Darknet-19 als neue Architektur, Batch-Normalisierung, höhere Auflösung der Eingaben, Faltungsschichten mit Ankern, Dimensionalitätsclusterung und (5) feinkörnige Merkmale.
Das Hinzufügen einer Batch-Normalisierungsschicht verbesserte die Leistung um 2% mAP. Diese Batch-Normalisierung beinhaltet einen Regularisierungseffekt, der eine Überanpassung verhindert.
YOLOv2 verwendet direkt eine höhere Auflösung von 448×448 anstelle von 224×224, wodurch das Modell seinen Filter so anpasst, dass er bei Bildern mit höherer Auflösung besser funktioniert. Dieser Ansatz erhöhte die Genauigkeit um 4% mAP, nachdem er für 10 Epochen auf den ImageNet-Daten trainiert wurde.
Anstatt die genauen Koordinaten der Boundingboxen der Objekte vorherzusagen, wie es YOLOv1 tut, vereinfacht YOLOv2 das Problem, indem es die vollständig verbundenen Schichten durch Ankerboxen ersetzt. Dieser Ansatz verringerte die Genauigkeit leicht, verbesserte aber die Rückrufquote des Modells um 7 %, was mehr Raum für Verbesserungen lässt.
Die zuvor erwähnten Ankerboxen werden von YOLOv2 automatisch durch k-means Dimensionalitätsclusterung mit k=5 gefunden, anstatt eine manuelle Auswahl zu treffen. Dieser neuartige Ansatz bot einen guten Kompromiss zwischen dem Recall und der Präzision des Modells.
Für ein besseres Verständnis der k-means Dimensionalitäts-Clustering Methode, schau dir unsere Tutorials K-Means Clustering in Python mit scikit-learn und K-Means Clustering in R an. Sie tauchen ein in das Konzept des k-means Clustering mit Python und R.
Die YOLOv2-Vorhersagen erzeugen 13x13 Feature Maps, was natürlich für die Erkennung großer Objekte ausreicht. Für die Erkennung von viel feineren Objekten kann die Architektur jedoch modifiziert werden, indem die 26 × 26 × 512-Merkmalskarte in eine 13 × 13 × 2048-Merkmalskarte umgewandelt wird, die mit den ursprünglichen Merkmalen verkettet wird. Dieser Ansatz verbesserte die Modellleistung um 1 %.
YOLOv2 wurde schrittweise verbessert, um YOLOv3 zu schaffen.
Die Veränderung beinhaltet vor allem eine neue Netzwerkarchitektur: Darknet-53. Dies ist ein 106 neuronales Netz mit Upsampling-Netzen und Restblöcken. Es ist viel größer, schneller und genauer als das Darknet-19, das das Rückgrat von YOLOv2 ist. Diese neue Architektur war auf vielen Ebenen von Vorteil:
YOLOv3 verwendet ein logistisches Regressionsmodell, um den Objektivitätswert für jede Bounding Box vorherzusagen.
Anstatt Softmax wie in YOLOv2 zu verwenden, wurden unabhängige logistische Klassifikatoren eingeführt, um die Klasse der Bounding Boxen genau vorherzusagen. Das ist sogar bei komplexeren Domänen mit sich überschneidenden Bezeichnungen (z. B. Person → Fußballspieler) nützlich. Mit einer Softmax würde jede Box nur eine Klasse haben, was nicht immer der Fall ist.
YOLOv3 führt drei Vorhersagen in verschiedenen Maßstäben für jeden Ort im Eingangsbild durch, um das Upsampling der vorherigen Schichten zu unterstützen. Diese Strategie ermöglicht es, feinkörnige und aussagekräftigere semantische Informationen zu erhalten, um eine bessere Bildqualität zu erhalten.
Diese Version von YOLO hat eine optimale Geschwindigkeit und Genauigkeit bei der Objekterkennung im Vergleich zu allen Vorgängerversionen und anderen modernen Objektdetektoren.
Das Bild unten zeigt, dass die YOLOv4 die YOLOv3 und die FPS bei der Geschwindigkeit um 10% bzw. 12% übertrifft.
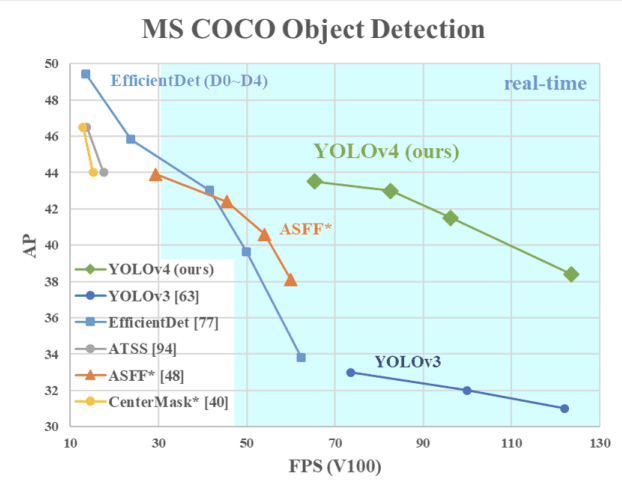
YOLOv4 Geschwindigkeit im Vergleich zu YOLOv3 und anderen modernen Objektdetektoren(Quelle)
YOLOv4 ist speziell für Produktionssysteme konzipiert und für parallele Berechnungen optimiert.
Das Rückgrat der YOLOv4-Architektur ist CSPDarknet53, ein Netz mit 29 Faltungsschichten mit 3 × 3 Filtern und etwa 27,6 Millionen Parametern.
Diese Architektur fügt im Vergleich zu YOLOv3 die folgenden Informationen für eine bessere Objekterkennung hinzu:
Als einheitliches Netzwerk für mehrere Aufgaben basiert YOLOR auf dem einheitlichen Netzwerk, das eine Kombination aus expliziten und impliziten Wissensansätzen ist.
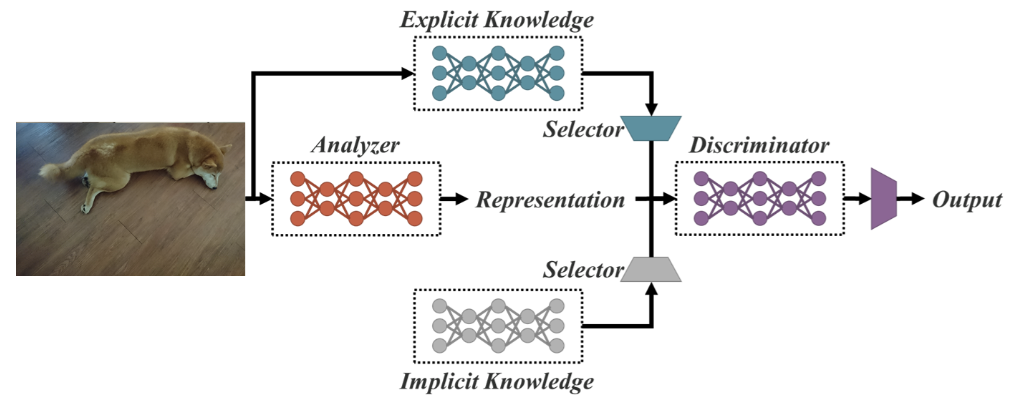
Vereinheitlichte Netzwerkarchitektur (Quelle)
Explizites Wissen ist normales oder bewusstes Lernen. Implizites Lernen hingegen erfolgt unbewusst (aus Erfahrung).
Durch die Kombination dieser beiden Techniken ist YOLOR in der Lage, eine robustere Architektur zu schaffen, die auf drei Prozessen basiert: (1) Feature Alignment, (2) Prediction Alignment für die Objekterkennung und (3) Kanonische Repräsentation für Multi-Task-Lernen
Dieser Ansatz führt eine implizite Repräsentation in die Feature-Map jedes Feature-Pyramidennetzes (FPN) ein, was die Genauigkeit um etwa 0,5 % verbessert.
Die Modellvorhersagen werden verfeinert, indem den Ausgangsschichten des Netzes eine implizite Darstellung hinzugefügt wird.
Das Multitasking-Training erfordert eine gemeinsame Optimierung der Verlustfunktion, die für alle Aufgaben gilt. Dieser Prozess kann die Gesamtleistung des Modells verringern. Dieses Problem kann durch die Integration der kanonischen Darstellung während des Modelltrainings gemildert werden.
Aus der folgenden Grafik geht hervor, dass YOLOR bei den MS COCO-Daten im Vergleich zu den anderen Modellen die höchste Inferenzgeschwindigkeiterreicht.
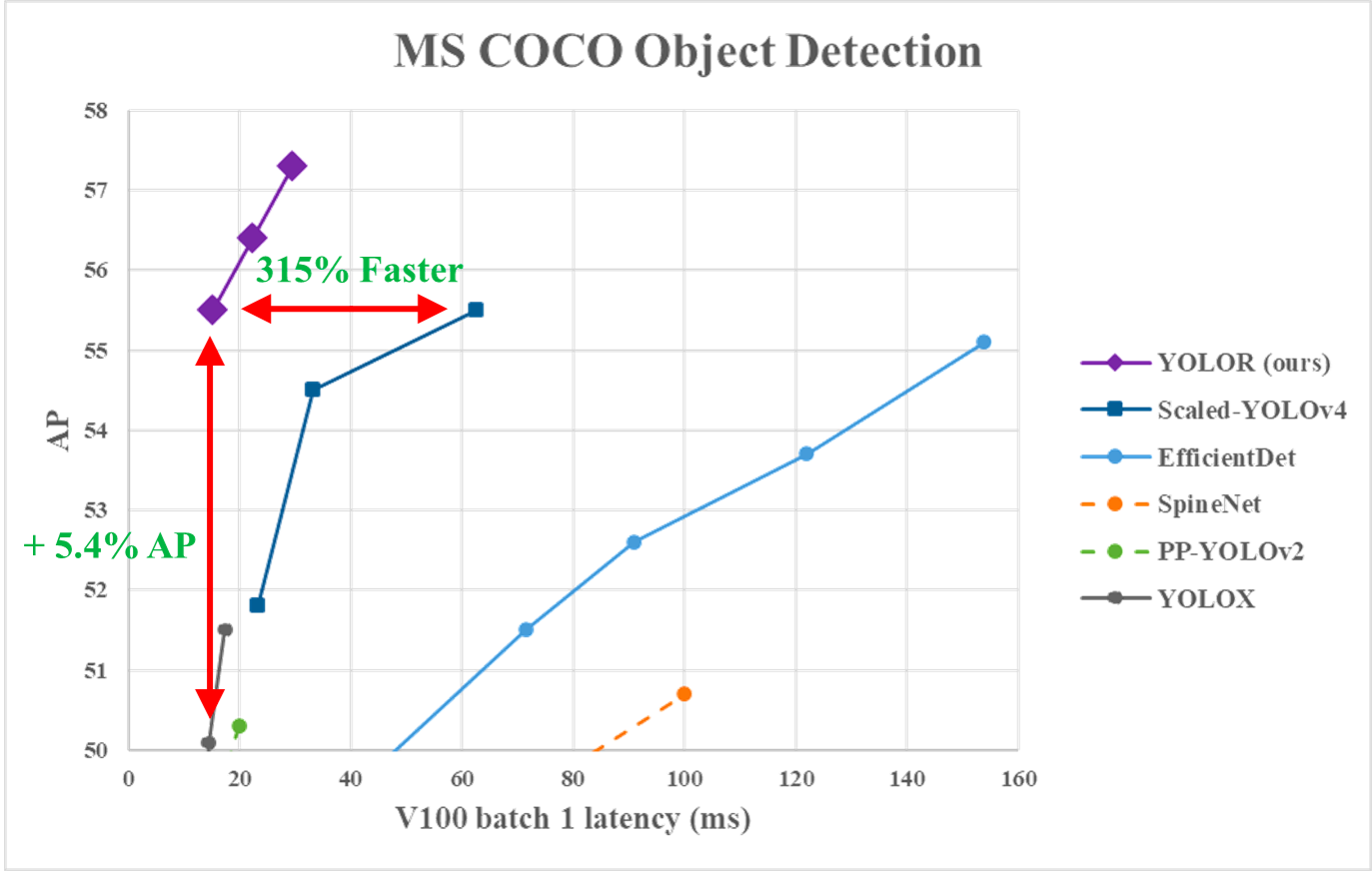
YOLOR Leistung vs. YOLOv4 und andere Modelle (Quelle)
Die Basis ist eine modifizierte Version von YOLOv3 mit Darknet-53 als Backbone.
In der Veröffentlichung Exceeding YOLO Series in 2021 bringt YOLOX die folgenden vier Schlüsseleigenschaften ein, um ein besseres Modell im Vergleich zu den älteren Versionen zu schaffen.
Es hat sich gezeigt, dass der gekoppelte Kopf, der in den vorherigen YOLO-Versionen verwendet wurde, die Leistung der Modelle verringert. YOLOX verwendet stattdessen ein entkoppeltes Modell, das die Trennung von Klassifizierungs- und Lokalisierungsaufgaben ermöglicht und so die Leistung des Modells erhöht.
Die Integration von Mosaic und MixUp in den Datenerweiterungsansatz hat die Leistung von YOLOX erheblich gesteigert.
Anker-basierte Algorithmen führen unter der Haube ein Clustering durch, was die Inferenzzeit erhöht. Durch das Entfernen des Ankermechanismus in YOLOX wurde die Anzahl der Vorhersagen pro Bild reduziert und die Inferenzzeit deutlich verbessert.
Anstelle des IoU-Ansatzes (Intersection of Union) hat der Autor SimOTA eingeführt, eine robustere Strategie für die Labelzuweisung, die nicht nur die Trainingszeit verkürzt, sondern auch zusätzliche Hyperparameter vermeidet und damit die besten Ergebnisse erzielt. Außerdem wurde die mAP-Erkennung um 3% verbessert.
Für YOLOv5 gibt es im Vergleich zu anderen Versionen kein veröffentlichtes Forschungspapier und es ist die erste Version von YOLO, die in Pytorch und nicht in Darknet implementiert wurde.
YOLOv5 wurde von Glenn Jocher im Juni 2020 veröffentlicht und nutzt, ähnlich wie YOLOv4, CSPDarknet53 als Rückgrat seiner Architektur. Die Veröffentlichung umfasst fünf verschiedene Modellgrößen: YOLOv5s (kleinste), YOLOv5m, YOLOv5l, und YOLOv5x (größte).
Eine der wichtigsten Verbesserungen in der YOLOv5-Architektur ist die Integration des Focus-Layers, der durch einen einzigen Layer dargestellt wird, der durch den Ersatz der ersten drei Layer von YOLOv3 entstanden ist. Durch diese Integration wurde die Anzahl der Schichten und der Parameter reduziert und die Vorwärts- und Rückwärtsgeschwindigkeit erhöht, ohne dass sich dies wesentlich auf die mAP auswirkte.
Die folgende Abbildung vergleicht die Ausbildungszeit zwischen YOLOv4 und YOLOv5s.
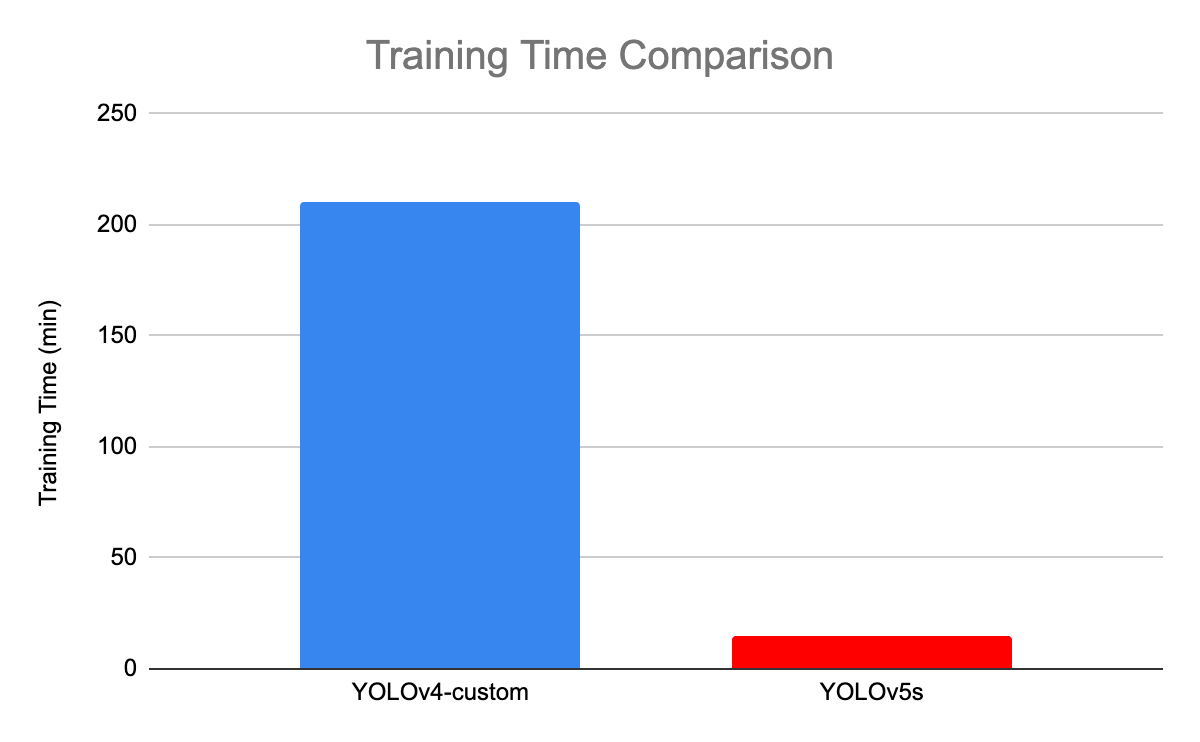
Trainingszeitvergleich zwischen YOLOv4 und YOLOv5(Quelle)
Das YOLOv6 (MT-YOLOv6) Framework wurde von Meituan, einem chinesischen E-Commerce-Unternehmen, speziell für industrielle Anwendungen mit hardwarefreundlichem, effizientem Design und hoher Leistung entwickelt.
Diese neue, in Pytorch geschriebene Version war nicht Teil des offiziellen YOLO, erhielt aber dennoch den Namen YOLOv6, weil ihr Grundgerüst von der ursprünglichen einstufigen YOLO-Architektur inspiriert war.
YOLOv6 bietet drei wesentliche Verbesserungen gegenüber dem Vorgänger YOLOv5: ein hardwarefreundliches Design von Rückgrat und Hals, einen effizienten entkoppelten Kopf und eine effektivere Trainingsstrategie.
YOLOv6 liefert im Vergleich zu den vorherigen YOLO-Versionen hervorragende Ergebnisse in Bezug auf Genauigkeit und Geschwindigkeit auf dem COCO-Datensatz, wie unten dargestellt.
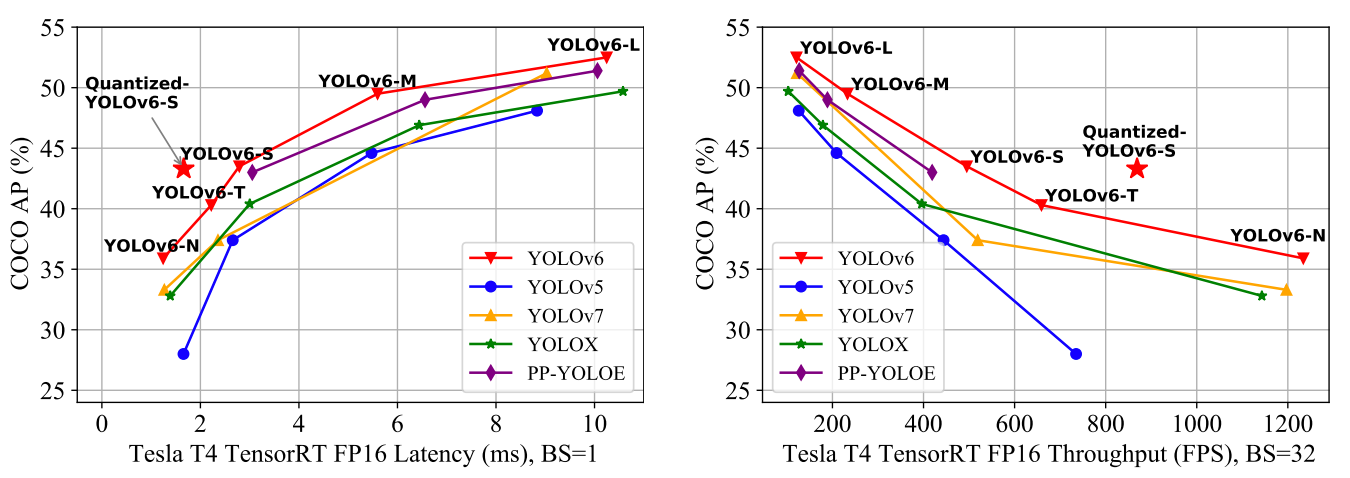
Vergleich der modernsten effizienten Objektdetektoren. Alle Modelle wurden mit TensorRT 7 getestet, außer das quantisierte Modell mit TensorRT 8(Quelle)
All diese Eigenschaften machen YOLOv5 zu dem richtigen Algorithmus für industrielle Anwendungen.
YOLOv7 wurde im Juli 2022 in der Zeitung Trainierte Beutestücke setzen neue Maßstäbe für Echtzeit-Objektdetektoren. Diese Version macht einen bedeutenden Schritt im Bereich der Objekterkennung und übertrifft alle Vorgängermodelle in Bezug auf Genauigkeit und Geschwindigkeit.
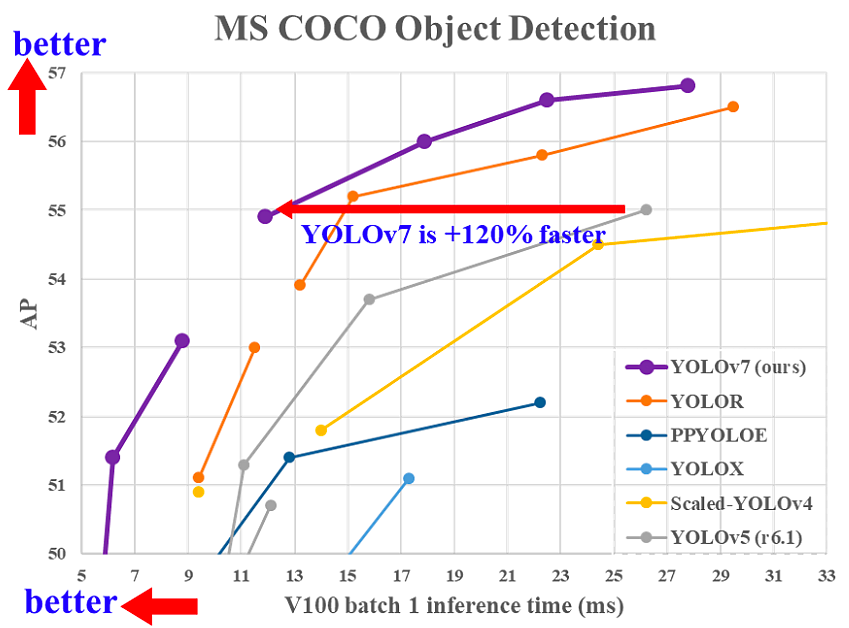
Vergleich der YOLOv7-Inferenzzeit mit anderen Echtzeit-Objektdetektoren(Quelle)
YOLOv7 hat eine große Veränderung in seiner (1) Architektur und (2) auf der Ebene der Trainable bag-of-freebies vorgenommen:
YOLOv7 hat seine Architektur reformiert, indem es das Extended Efficient Layer Aggregation Network (E-ELAN) integriert hat, das es dem Modell ermöglicht, mehr verschiedene Merkmale zu lernen, um besser zu lernen.
Außerdem skaliert YOLOv7 seine Architektur, indem es die Architektur der Modelle, von denen es abgeleitet ist, wie YOLOv4, Scaled YOLOv4 und YOLO-R, miteinander verknüpft. Auf diese Weise kann das Modell den Anforderungen unterschiedlicher Schlussfolgerungsgeschwindigkeiten gerecht werden.
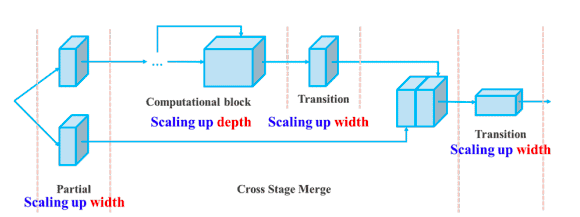
Zusammengesetzte Skalierung in Tiefe und Breite für das verkettungsbasierte Modell(Quelle)
Der Begriff "Bag-of-Freebies" bedeutet, dass die Genauigkeit des Modells verbessert wird, ohne die Trainingskosten zu erhöhen. Das ist der Grund, warum YOLOv7 nicht nur die Inferenzgeschwindigkeit, sondern auch die Erkennungsgenauigkeit erhöht hat.
In diesem Artikel werden die Vorteile von YOLO im Vergleich zu anderen modernen Objekterkennungsalgorithmen und seine Entwicklung von 2015 bis 2020 vorgestellt.
Angesichts der rasanten Entwicklung von YOLO gibt es keinen Zweifel daran, dass es noch sehr lange führend im Bereich der Objekterkennung bleiben wird.
Der nächste Schritt in diesem Artikel wird die Anwendung des YOLO-Algorithmus auf reale Fälle sein. Bis dahin kann dir unser Kurs Einführung in Deep Learning in Python helfen, die Grundlagen neuronaler Netze zu erlernen und Deep-Learning-Modelle mit Keras 2.0 in Python zu erstellen.
Deep Learning Kurse
Kurs
Kurs
Kurs
Blog
Tutorial
Moez Ali
Tutorial
Laiba Siddiqui
Tutorial
Matt Crabtree
Tutorial
Sejal Jaiswal
Tutorial
Sejal Jaiswal
