Course
Introduction to Deep Learning in Python
4 hr
263.5K
Object detection is a computer vision technique for identifying and localizing objects within an image or a video.
pip install ultralytics and run inference using the Python API or CLIImage localization is the process of identifying the correct location of one or multiple objects using bounding boxes, which correspond to rectangular shapes around the objects. This process is sometimes confused with image classification or image recognition, which aims to predict the class of an image or an object within an image into one of the categories or classes.
The illustration below corresponds to the visual representation of the previous explanation. The object detected within the image is a “Person.”

Image by Author
In this conceptual blog, you will first understand the benefits of object detection before introducing YOLO, the state-of-the-art object detection algorithm.
In the second part, we will focus more on the YOLO algorithm and how it works. After that, we will provide some real-life applications using YOLO.
The last section will explain how YOLO evolved from 2015 to 2024 before concluding on the next steps.
You Only Look Once (YOLO) is a state-of-the-art, real-time object detection algorithm introduced in 2015 by Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi in their famous research paper You Only Look Once: Unified, Real-Time Object Detection.
The authors frame the object detection problem as a regression rather than a classification task by spatially separating bounding boxes and associating probabilities to each detected image using a single convolutional neural network (CNN).
If you're interested in image classification, consider taking the Image Processing with Keras in Python course, where you'll build Keras-based deep neural networks for image classification tasks. If you are more interested in Pytorch, Deep Learning with PyTorch will teach you about convolutional neural networks and how to use them to build much more powerful models.
Some of the reasons why YOLO is leading the competition include its:
Let's see these features in more detail.
YOLO is extremely fast because it does not deal with complex pipelines. It can process images at 45 Frames Per Second (FPS). In addition, YOLO reaches more than twice the mean Average Precision (mAP) compared to other real-time systems, which makes it a great candidate for real-time processing.
From the graphic below, we observe that YOLO is far beyond the other object detectors with 91 FPS.
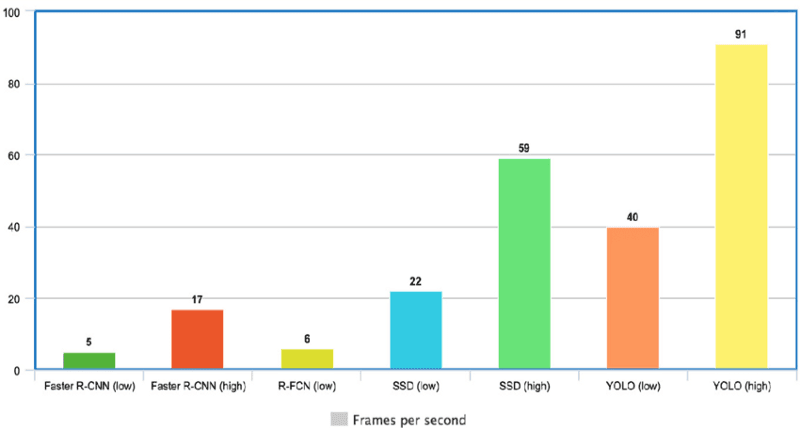
YOLO speed compared to other state-of-the-art object detectors (source)
YOLO is far beyond other state-of-the-art models in accuracy, with very few background errors.
This is especially true for the new versions of YOLO, which will be discussed later in the article. With those advancements, YOLO has gone a little further by providing better generalization for new domains, which makes it great for applications relying on fast and robust object detection.
For instance, the Automatic Detection of Melanoma with Yolo Deep Convolutional Neural Networks paper shows that the first version, YOLOv1, has the lowest mAP for the automatic detection of melanoma disease, compared to YOLOv2 and YOLOv3.
Making YOLO open-source has led the community to improve the model constantly. This is one of the reasons why YOLO has made so many improvements in such a limited time.
YOLO architecture is similar to GoogleNet. As illustrated below, it has 24 convolutional layers, four max-pooling layers, and two fully connected layers.
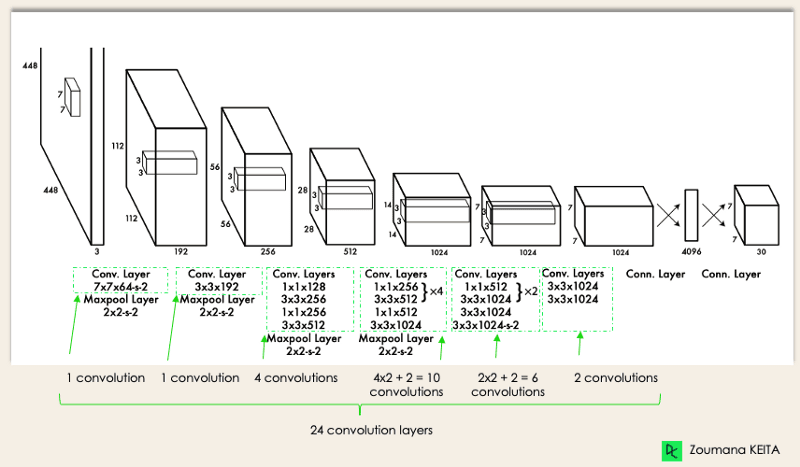
YOLO Architecture from the original paper (Modified by Author)
The architecture works as follows:
By completing the Deep Learning in Python track or the PyTorch CNN Tutorial, you will be ready to use Keras to train and test complex, multi-output networks and dive deeper into deep learning.
Now that you understand the architecture let’s take a high-level overview of how the YOLO algorithm performs object detection using a simple use case.
“Imagine you built a YOLO application that detects players and soccer balls from a given image.
But how can you explain this process to someone, especially non-initiated people?
→ That is the whole point of this section. You will understand the whole process of how YOLO performs object detection and how to get image (B) from image (A).”
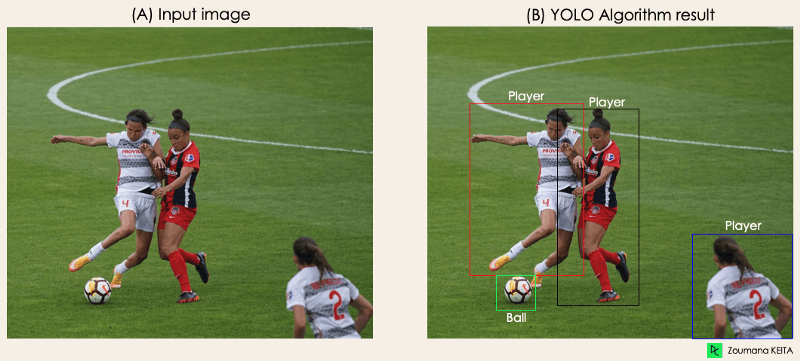 Image by Author
Image by Author
The algorithm works based on the following four approaches:
Let’s have a closer look at each one of them.
This first step starts by dividing the original image (A) into NxN grid cells of equal shape, where N, in our case, is 4, as shown in the image on the right. Each cell in the grid is responsible for localizing and predicting the class of the object that it covers, along with the probability/confidence value.

Image by Author
The next step is to determine the bounding boxes corresponding to rectangles, highlighting all the objects in the image. We can have as many bounding boxes as there are objects within a given image.
YOLO determines the attributes of these bounding boxes using a single regression module in the following format, where Y is the final vector representation for each bounding box.
Y = [pc, bx, by, bh, bw, c1, c2]
This is especially important during the training phase of the model.
pc corresponds to the probability score of the grid containing an object. For instance, all the grids in red will have a probability score higher than zero. The image on the right is the simplified version since the probability of each yellow cell is zero (insignificant). 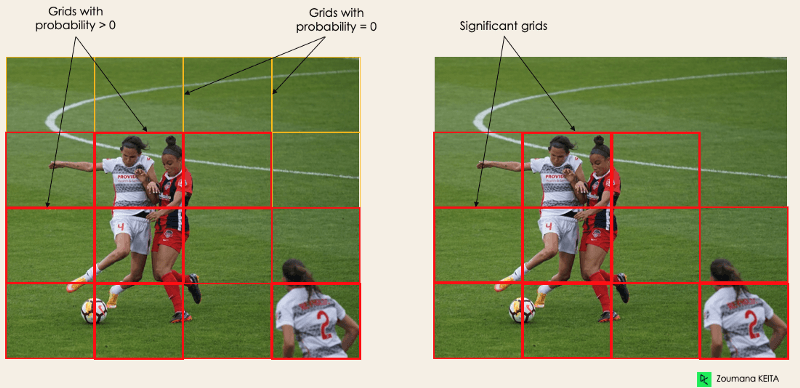
Image by Author
bx, by are the x and y coordinates of the center of the bounding box with respect to the enveloping grid cell. bh, bw correspond to the height and the width of the bounding box with respect to the enveloping grid cell. c1 and c2 correspond to the two classes, Player and Ball. We can have as many classes as your use case requires. To understand, let’s pay closer attention to the player on the bottom right.
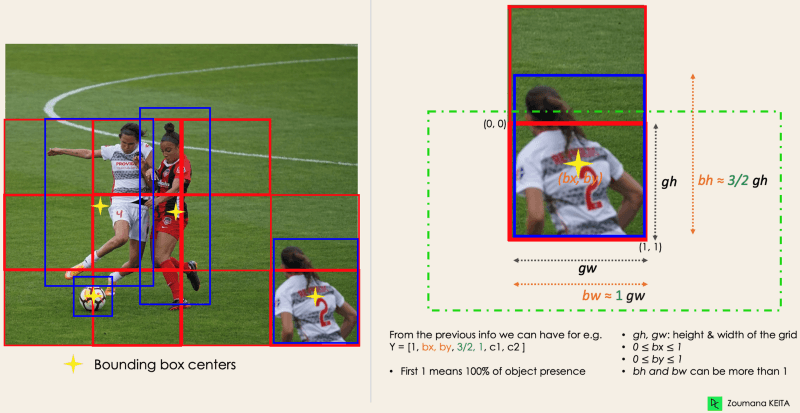 Image by Author
Image by Author
Most of the time, a single object in an image can have multiple grid box candidates for prediction, even though not all are relevant. The goal of the IOU (a value between 0 and 1) is to discard such grid boxes to only keep those that are relevant. Here is the logic behind it:
Below is an illustration of applying the grid selection process to the bottom left object. We can observe that the object originally had two grid candidates, and only “Grid 2” was selected at the end.
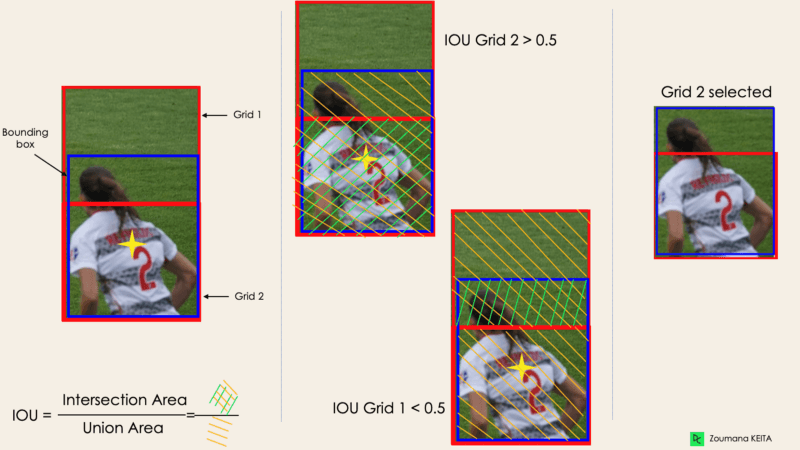
Image by Author
Setting a threshold for the IOU is not always enough because an object can have multiple boxes with IOU beyond the threshold, and leaving all those boxes might include noise. Here is where we can use NMS to keep only the boxes with the highest probability detection score.
YOLO object detection has different applications in our day-to-day life. In this section, we will cover some of them in the following domains: healthcare, agriculture, security surveillance, and self-driving cars.
Object detection has been introduced in many practical industries, such as healthcare and agriculture. Let’s understand each one with specific examples.
Specifically, in surgery, it can be challenging to localize organs in real time due to biological diversity from one patient to another. Kidney Recognition in CT used YOLOv3 to facilitate localizing kidneys in 2D and 3D from computerized tomography (CT) scans.
The Biomedical Image Analysis in Python course can help you learn the fundamentals of exploring, manipulating, and measuring biomedical image data using Python.
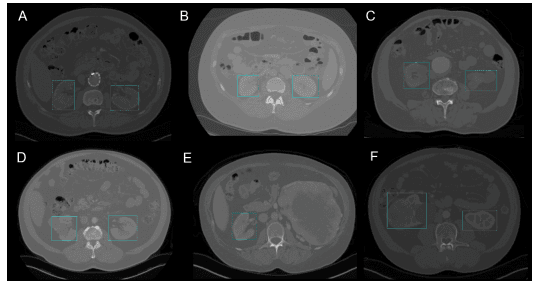
2D Kidney detection by YOLOv3 (Image from Kidney Recognition in CT using YOLOv3)
Artificial Intelligence and robotics play a major role in modern agriculture. Harvesting robots are vision-based robots that were introduced to replace manual picking of fruits and vegetables. One of the best models in this field uses YOLO. In Tomato detection based on a modified YOLOv3 framework, the authors describe how they used YOLO to identify the types of fruits and vegetables for efficient harvest.

Image from Tomato detection based on modified YOLOv3 framework (source)
Even though object detection is mostly used in security surveillance, it is not the only application. YOLOv3 has been used during the COVID-19 pandemic to estimate social distance violations between people.
You can further your reading on this topic from A deep-learning-based social distance monitoring framework for COVID-19.
Real-time object detection is part of the DNA of autonomous vehicle systems. This integration is vital for autonomous vehicles because they need to properly identify the correct lanes and all the surrounding objects and pedestrians to increase road safety. YOLO's real-time aspect makes it a better candidate compared to simple image segmentation approaches.
Since its first release in 2015, YOLO has evolved greatly, with different versions. In this section, we will understand the differences between these versions.
This first version of YOLO was a game changer for object detection because it could quickly and efficiently recognize objects.
However, like many other solutions, the first version of YOLO has its own limitations:
YOLOv2 was created in 2016 with the idea of making the YOLO model better, faster and stronger.
The improvement includes but is not limited to the use of Darknet-19 as new architecture, batch normalization, higher resolution of inputs, convolution layers with anchors, dimensionality clustering, and (5) Fine-grained features.
Adding a batch normalization layer improved the performance by 2% mAP. This batch normalization included a regularization effect, preventing overfitting.
YOLOv2 directly uses a higher resolution 448×448 input instead of 224×224, which makes the model adjust its filter to perform better on higher resolution images. This approach increased the accuracy by 4% mAP, after being trained for 10 epochs on the ImageNet data.
Instead of predicting the exact coordinates of the objects' bounding boxes as YOLOv1 operates, YOLOv2 simplifies the problem by replacing the fully connected layers with anchor boxes. This approach slightly decreases the accuracy but improves the model recall by 7%, which gives more room for improvement.
YOLOv2 automatically finds the previously mentioned anchor boxes using k-means dimensionality clustering with k=5 instead of performing a manual selection. This novel approach provides a good tradeoff between the recall and the precision of the model.
For a better understanding of the k-means dimensionality clustering, take a look at our K-Means Clustering in Python with scikit-learn and K-Means Clustering in R tutorials. They dive into the concept of k-means clustering using Python and R.
YOLOv2 predictions generate 13x13 feature maps, which is of course enough for large object detection. But for much finer objects detection, the architecture can be modified by turning the 26 × 26 × 512 feature map into a 13 × 13 × 2048 feature map, concatenated with the original features. This approach improved the model performance by 1%.
An incremental improvement has been performed on the YOLOv2 to create YOLOv3.
The change mainly includes a new network architecture: Darknet-53. This is a 106-layer neural network, with upsampling networks and residual blocks. It is much bigger, faster, and more accurate compared to Darknet-19, which is the backbone of YOLOv2. This new architecture has been beneficial on many levels:
A logistic regression model is used by YOLOv3 to predict the objectness score for each bounding box.
Instead of using softmax as performed in YOLOv2, independent logistic classifiers have been introduced to accurately predict the class of the bounding boxes. This is even useful when facing more complex domains with overlapping labels (e.g. Person → Soccer Player). Using a softmax would constrain each box to have only one class, which is not always true.
YOLOv3 performs three predictions at different scales for each location within the input image to help with the upsampling from the previous layers. This strategy allows getting fine-grained and more meaningful semantic information for a better quality output image.
This version of YOLO has an Optimal Speed and Accuracy of Object Detection compared to all the previous versions and other state-of-the-art object detectors.
The image below shows the YOLOv4 outperforming YOLOv3 and FPS in speed by 10% and 12% respectively.
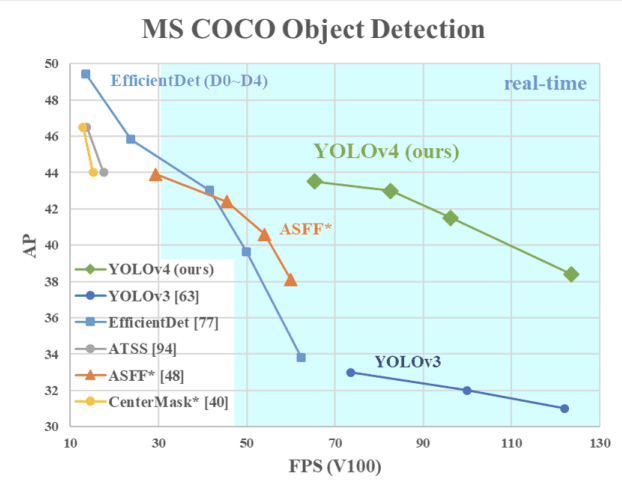
YOLOv4 Speed compared to YOLOv3 and other state-of-the-art object detectors (source)
YOLOv4 is specifically designed for production systems and optimized for parallel computations.
The backbone of YOLOv4’s architecture is CSPDarknet53, a network containing 29 convolution layers with 3 × 3 filters and approximately 27.6 million parameters.
This architecture, compared to YOLOv3, adds the following information for better object detection:
As a Unified Network for Multiple Tasks, YOLOR is based on the unified network which is a combination of explicit and implicit knowledge approaches.
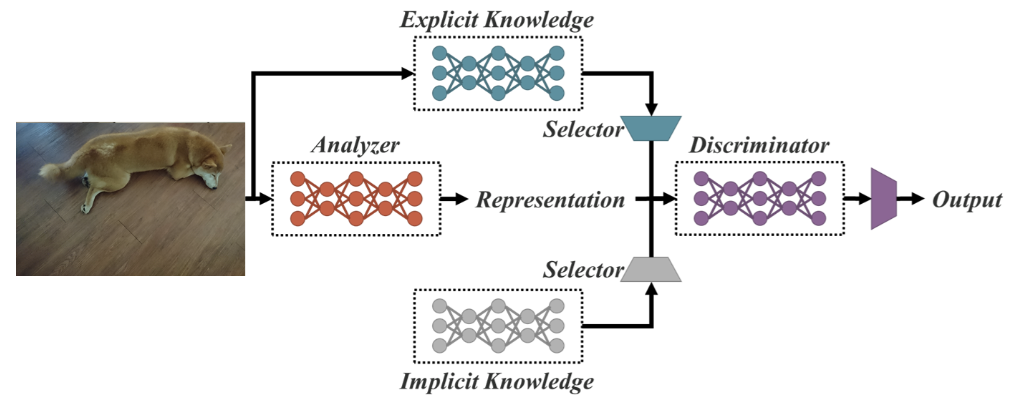
Unified network architecture (source)
Explicit knowledge is normal or conscious learning. Implicit learning on the other hand is one performed subconsciously (from experience).
Combining these two technics, YOLOR is able to create a more robust architecture based on three processes: (1) feature alignment, (2) prediction alignment for object detection, and (3) canonical representation for multi-task learning
This approach introduces an implicit representation into the feature map of every feature pyramid network (FPN), which improves the precision by about 0.5%.
The model predictions are refined by adding implicit representation to the output layers of the network.
Performing multi-task training requires the execution of the joint optimization on the loss function shared across all the tasks. This process can decrease the overall performance of the model, and this issue can be mitigated with the integration of the canonical representation during the model training.
From the following graphic, we can observe that YOLOR achieved on the MS COCO data state-of-the-art inference speed compared to other models.
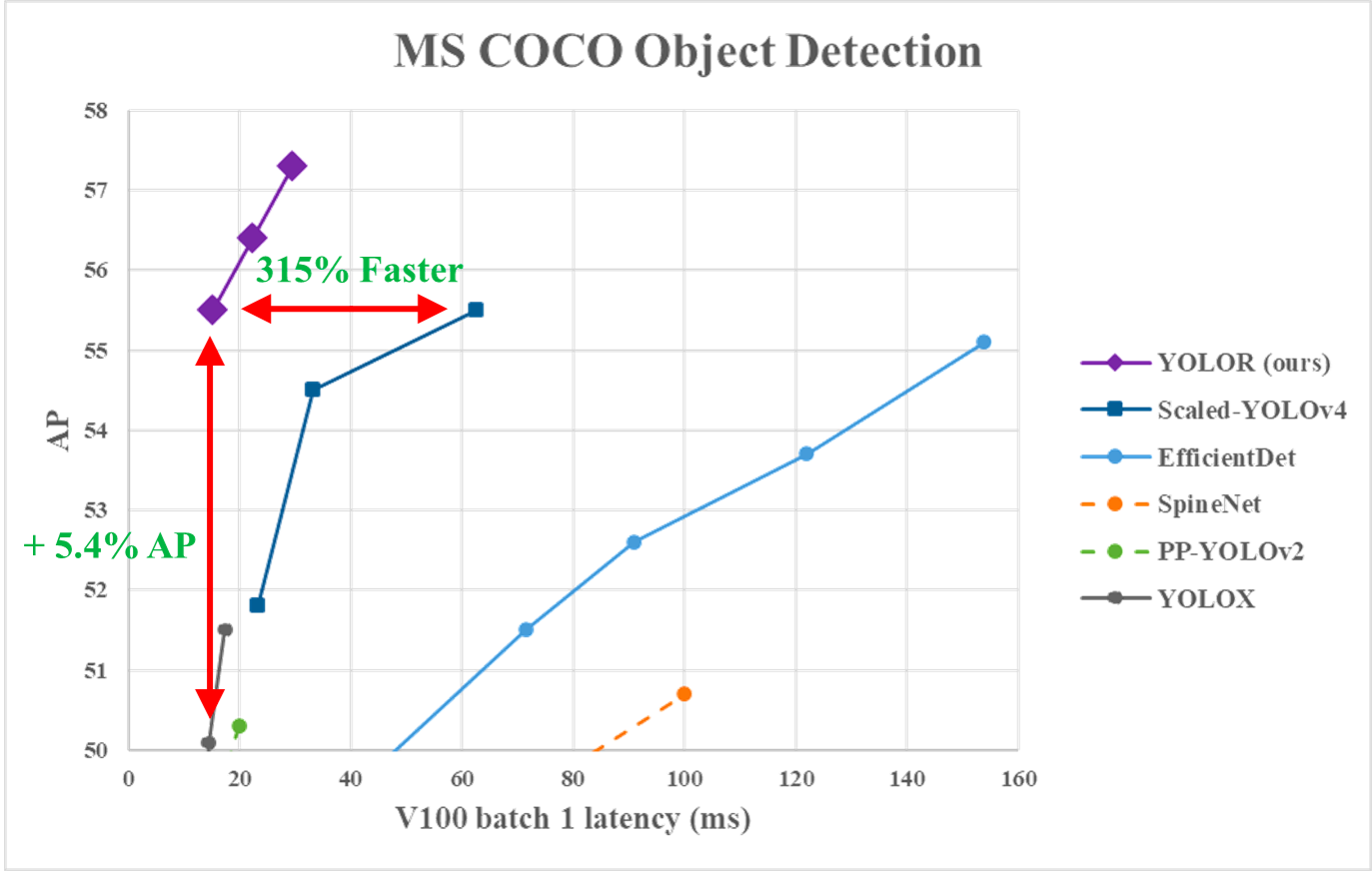
YOLOR performance vs. YOLOv4 and other models (source)
This uses a baseline that is a modified version of YOLOv3, with Darknet-53 as its backbone.
Published in the paper Exceeding YOLO Series in 2021, YOLOX brings to the table the following four key characteristics to create a better model compared to the older versions.
The coupled head used in the previous YOLO versions is shown to reduce the models’ performance. YOLOX uses a decoupled instead, which allows separating classification and localization tasks, thus increasing the performance of the model.
Integration of Mosaic and MixUp into the data augmentation approach considerably increased YOLOX’s performance.
Anchor-based algorithms perform clustering under the hood, which increases the inference time. Removing the anchor mechanism in YOLOX reduced the number of predictions per image, and significantly improved inference time.
Instead of using the intersection of union (IoU) approach, the author introduced SimOTA, a more robust label assignment strategy that achieves state-of-the-art results by not only reducing the training time but also avoiding extra hyperparameter issues. In addition to that, it improved the detection mAP by 3%.
YOLOv5, compared to other versions, does not have a published research paper, and it is the first version of YOLO to be implemented in Pytorch, rather than Darknet.
Released by Glenn Jocher in June 2020, YOLOv5, similarly to YOLOv4, uses CSPDarknet53 as the backbone of its architecture. The release includes five different model sizes: YOLOv5s (smallest), YOLOv5m, YOLOv5l, and YOLOv5x (largest).
One of the major improvements in YOLOv5 architecture is the integration of the Focus layer, represented by a single layer, which is created by replacing the first three layers of YOLOv3. This integration reduced the number of layers, and number of parameters and also increased both forward and backward speed without any major impact on the mAP.
The following illustration compares the training time between YOLOv4 and YOLOv5s.
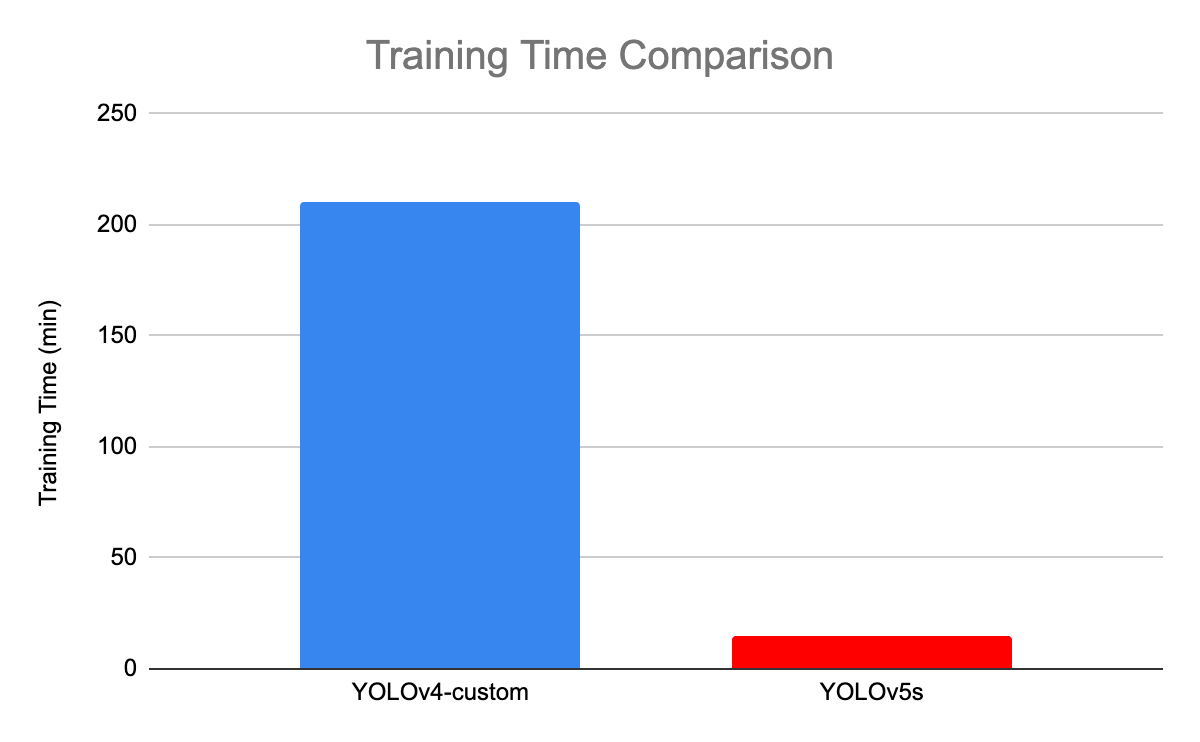
Training time comparison between YOLOv4 and YOLOv5 (source)
Dedicated to industrial applications with hardware-friendly efficient design and high performance, the YOLOv6 (MT-YOLOv6) framework was released by Meituan, a Chinese e-commerce company.
Written in Pytorch, this new version was not part of the official YOLO but still got the name YOLOv6 because its backbone was inspired by the original one-stage YOLO architecture.
YOLOv6 introduced three significant improvements to the previous YOLOv5: a hardware-friendly backbone and neck design, an efficient decoupled head, and a more effective training strategy.
YOLOv6 provides outstanding results compared to the previous YOLO versions in terms of accuracy and speed on the COCO dataset as illustrated below.
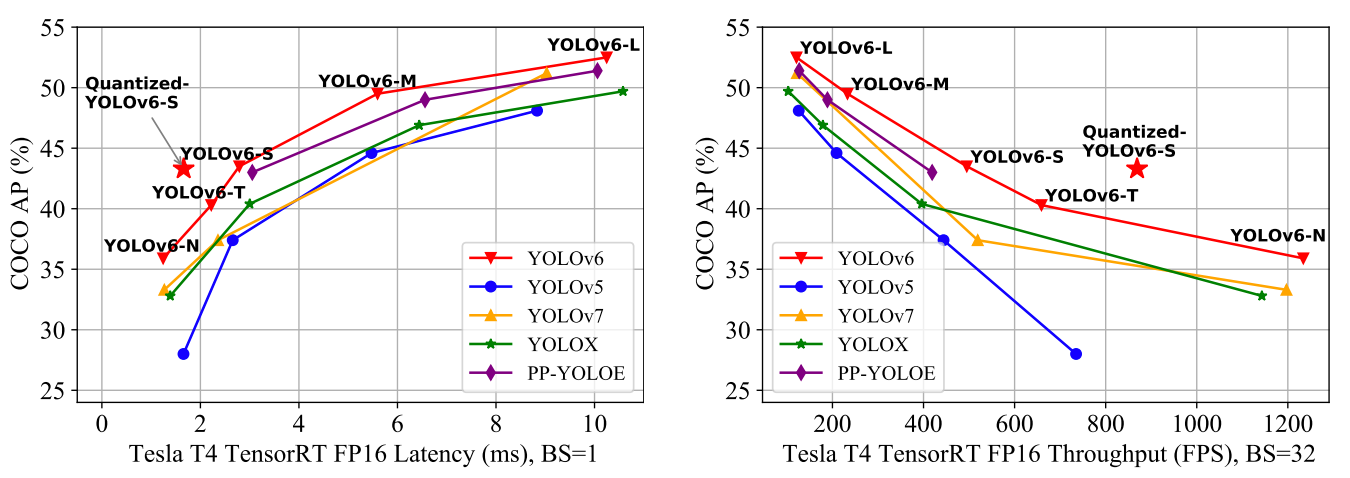
Comparison of state-of-the-art efficient object detectors. All models are tested with TensorRT 7 except that the quantized model is with TensorRT 8 (source)
All these characteristics make YOLOv6 the right algorithm for industrial applications.
YOLOv7 was released in July 2022 in the paper Trained bag-of-freebies sets new state-of-the-art for real-time object detectors. This version is making a significant move in the field of object detection, and it surpassed all the previous models in terms of accuracy and speed.
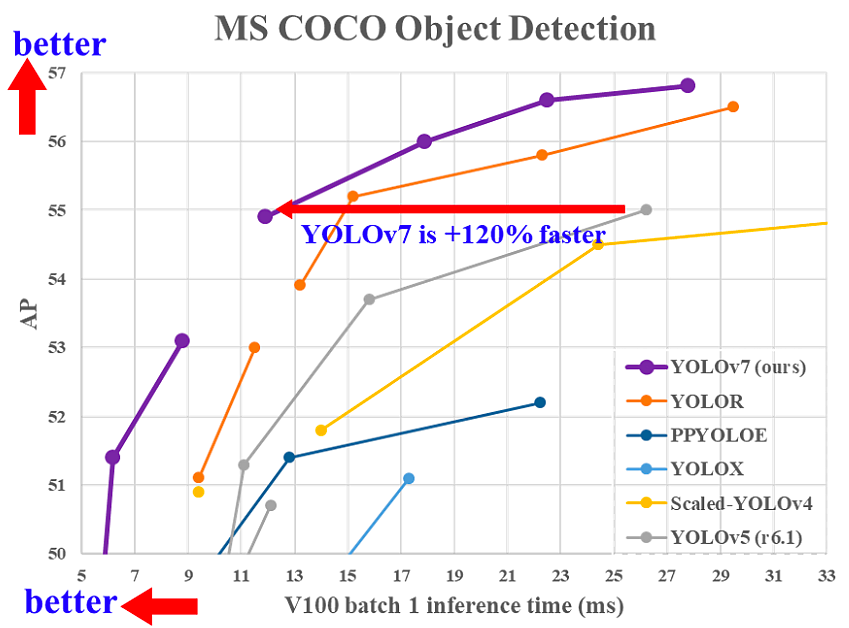
Comparison of YOLOv7 inference time with other real-time object detectors (source)
YOLOv7 has made a major change in its (1) architecture and (2) at the Trainable bag-of-freebies level:
YOLOv7 reformed its architecture by integrating the Extended Efficient Layer Aggregation Network (E-ELAN) which allows the model to learn more diverse features for better learning.
In addition, YOLOv7 scales its architecture by concatenating the architecture of the models it is derived from such as YOLOv4, Scaled YOLOv4, and YOLO-R. This allows the model to meet the needs of different inference speeds.
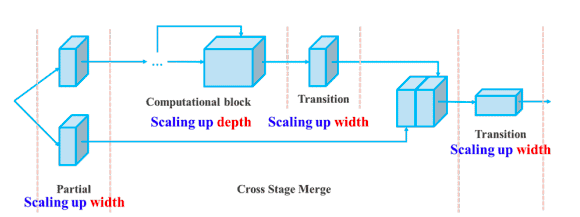
Compound scaling up depth and width for concatenation-based model (source)
The term bag-of-freebies refers to improving the model’s accuracy without increasing the training cost, and this is the reason why YOLOv7 increased not only the inference speed but also the detection accuracy.
YOLOv8 introduces a more modular and flexible design, allowing easier customization and fine-tuning. Built-in support for various tasks beyond object detection, such as segmentation and pose estimation.
YOLO-NAS utilizes Neural Architecture Search (NAS) to automatically design an optimized architecture, maximizing performance without manual tuning.
YOLO-World, developed by Tencent's AI Lab, introduces a new paradigm: "prompt then detect." Unlike traditional YOLO models that require training on specific object classes, YOLO-World can detect objects based on text prompts without fine-tuning.
This zero-shot capability eliminates the need for just-in-time text encoding, achieving up to 74.1 FPS on a V100 GPU. YOLO-World is particularly useful when you need to detect custom objects without collecting training data.
Launched in 2024, the v9 version of YOLO introduces several innovative techniques, such as the following:
YOLOv9 sets new benchmarks on the MS COCO dataset, demonstrating superior performance compared to previous versions, particularly in terms of precision and adaptability across various tasks. Although developed by a separate open-source team, YOLOv9 builds upon the codebase of Ultralytics YOLOv5, showing a collaborative effort within the AI community to push the boundaries of object detection.
This latest version highlights substantial advancements in both the training process and the architecture, focusing on efficiency, adaptability, and precision for real-time applications.
Released in May 2024 by researchers from Tsinghua University, YOLOv10 represents a significant advancement in real-time object detection. The key innovation is the elimination of Non-Maximum Suppression (NMS) during inference, which traditionally added latency to the detection pipeline.
YOLOv10 introduces consistent dual assignments for NMS-free training, combining one-to-many and one-to-one label assignments. This approach maintains training efficiency while enabling NMS-free inference. According to the paper, YOLOv10-S is 1.8× faster than RT-DETR-R18 with similar accuracy, while using 2.8× fewer parameters.
Developed by Ultralytics (creators of YOLOv5 and YOLOv8), YOLOv11 supports multiple computer vision tasks: object detection, instance segmentation, image classification, keypoint detection, and oriented bounding box (OBB) detection. The YOLOv11x model achieves 54.7% mAP on the MS COCO benchmark.
YOLOv12 introduces attention mechanisms into the YOLO architecture, improving the model's ability to focus on relevant image regions. This version achieves better accuracy on complex scenes with overlapping objects while maintaining real-time performance.
YOLO26, released in January 2026 by Ultralytics, is an end-to-end, edge-optimized model supporting five core tasks: object detection, instance segmentation, pose estimation, oriented object detection (OBB), and image classification. It achieves the highest accuracy in the YOLO lineage while maintaining fast inference speeds.
YOLO26 offers multiple model sizes (Nano, Small, Medium, Large, Extra Large) to balance accuracy and speed for different deployment scenarios. Install and use it with:
from ultralytics import YOLO
# Load the model
model = YOLO("yolo26m.pt")
# Run inference
results = model("image.jpg")
results[0].show()This article has covered the benefits of YOLO compared to other state-of-the-art object detection algorithms, and its evolution from 2015 to 2026 with a highlight of its key improvements.
Given the rapid advancement of YOLO, there is no doubt that it will remain the leader in the field of object detection for a very long time.
The next step of this article will be the application of the YOLO algorithm to real-world cases. Until then, our Introduction to Deep Learning in Python course can help you learn the fundamentals of neural networks and how to build deep learning models using Keras 2.0 in Python.
Deep Learning Courses
Course
Course
Course
blog
Kurtis Pykes
15 min
blog
Kurtis Pykes
8 min
cheat-sheet
Richie Cotton
Tutorial
Lars Hulstaert
Tutorial
Natassha Selvaraj
code-along
Serg Masis