Curso
Introdução a Deep Learning em Python
4 h
263.5K
A detecção de objetos é uma técnica usada na visão computacional para a identificação e a localização de objetos em uma imagem ou em um vídeo.
A localização de imagens é o processo de identificar o local correto de um ou vários objetos usando caixas delimitadoras, que correspondem a formas retangulares ao redor dos objetos.
Às vezes, esse processo é confundido com a classificação ou o reconhecimento de imagens, que visa prever a classe de uma imagem ou de um objeto dentro de uma imagem em uma das categorias ou classes.
A ilustração abaixo corresponde à representação visual da explicação anterior. O objeto detectado na imagem é "Pessoa".

Imagem do autor
Neste blog conceitual, você entenderá primeiro os benefícios da detecção de objetos, antes de apresentar o YOLO, o algoritmo de detecção de objetos de última geração.
Na segunda parte, vamos nos concentrar mais no algoritmo YOLO e em como ele funciona. Depois disso, forneceremos alguns aplicativos reais usando o YOLO.
A última seção explicará como o YOLO evoluiu de 2015 a 2020 antes de concluir sobre as próximas etapas.
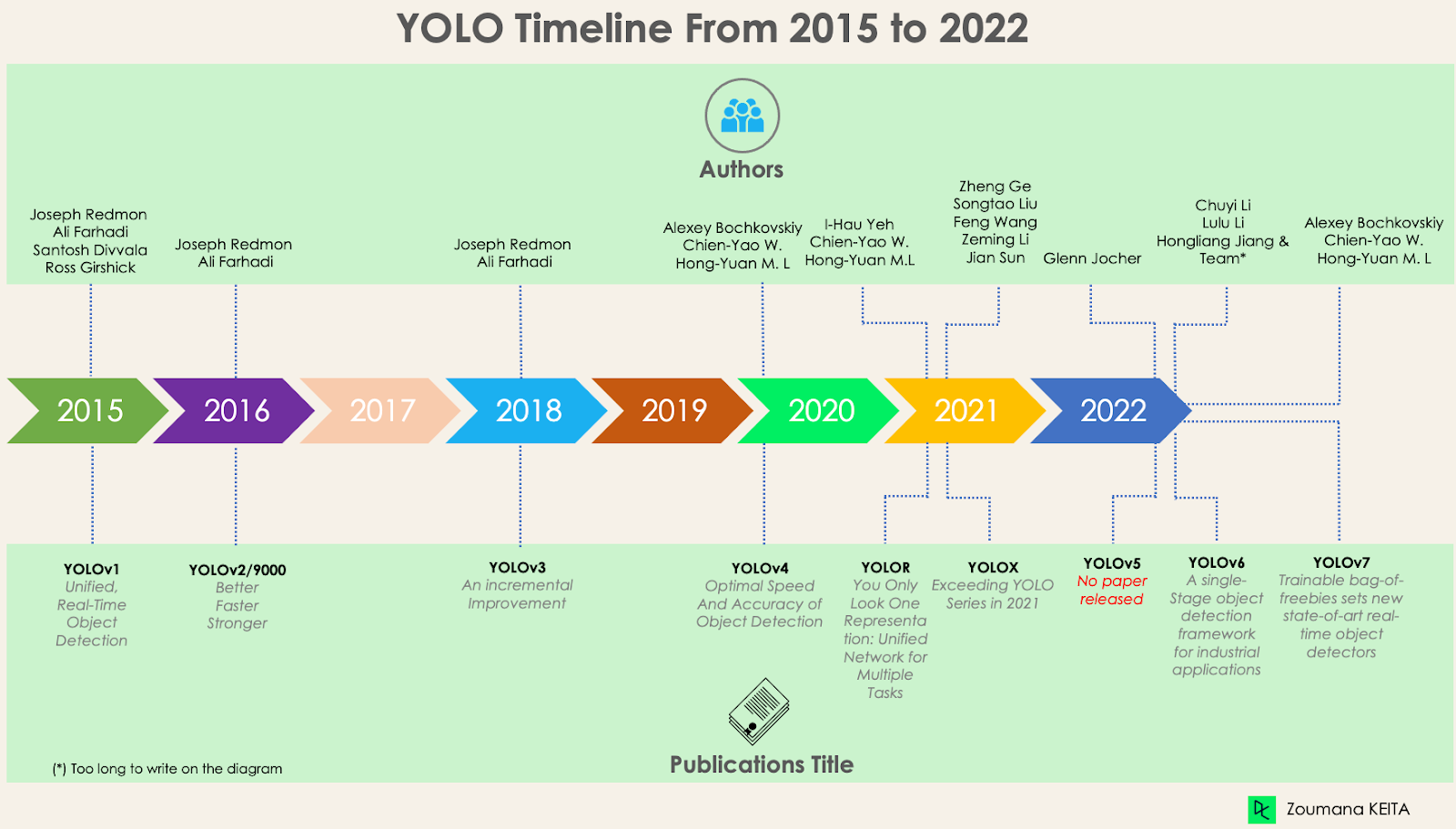
O You Only Look Once (YOLO) é um algoritmo de detecção de objetos em tempo real de última geração, apresentado em 2015 por Joseph Redmon, Santosh Divvala, Ross Girshick e Ali Farhadi em seu famoso artigo de pesquisa "You Only Look Once: Detecção de objetos unificada e em tempo real".
Os autores enquadram o problema de detecção de objetos como um problema de regressão em vez de uma tarefa de classificação, separando espacialmente as caixas delimitadoras e associando probabilidades a cada uma das imagens detectadas usando uma única rede neural convolucional (CNN).
Ao fazer o curso Image Processing with Keras in Python, você poderá criar redes neurais profundas baseadas em Keras para tarefas de classificação de imagens.
Se você estiver mais interessado no Pytorch, o Deep Learning with Pytorch ensinará a você sobre redes neurais convolucionais e como usá-las para criar modelos muito mais avançados.
Alguns dos motivos pelos quais a YOLO está liderando a concorrência são
O YOLO é extremamente rápido porque não lida com pipelines complexos. Ele pode processar imagens a 45 quadros por segundo (FPS). Além disso, o YOLO atinge mais de duas vezes a precisão média (mAP) em comparação com outros sistemas em tempo real, o que o torna um ótimo candidato para o processamento em tempo real.
No gráfico abaixo, observamos que o YOLO está muito além dos outros detectores de objetos, com 91 FPS.
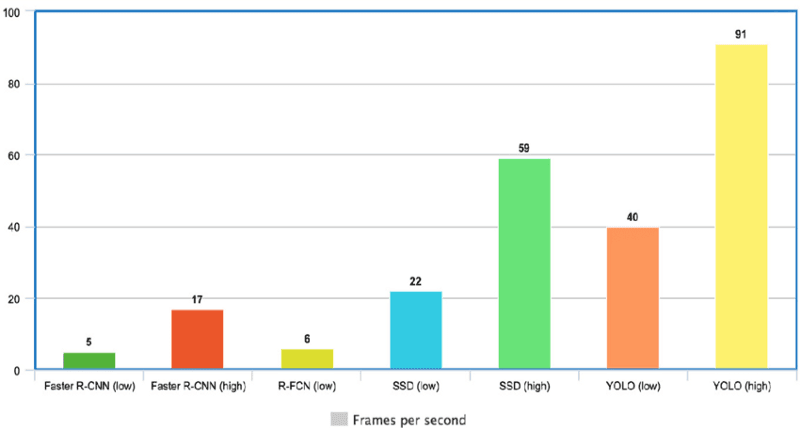
Velocidade do YOLO em comparação com outros detectores de objetos de última geração(fonte)
O YOLO está muito além de outros modelos de última geração em termos de precisão, com pouquíssimos erros de fundo.
Isso é especialmente verdadeiro para as novas versões do YOLO, que serão discutidas mais adiante neste artigo. Com esses avanços, o YOLO foi um pouco mais longe, fornecendo uma melhor generalização para novos domínios, o que o torna excelente para aplicativos que dependem da detecção rápida e robusta de objetos.
Por exemplo, o artigo Automatic Detection of Melanoma with Yolo Deep Convolutional Neural Networks (Detecção automática de melanoma com redes neurais convolucionais profundas Yolo ) mostra que a primeira versão YOLOv1 tem a menor precisão média para a detecção automática de melanoma, em comparação com YOLOv2 e YOLOv3.
Tornar o YOLO de código aberto levou a comunidade a aprimorar constantemente o modelo. Esse é um dos motivos pelos quais a YOLO fez tantos aprimoramentos em um período tão limitado.
A arquitetura do YOLO é semelhante à do GoogleNet. Conforme ilustrado abaixo, ele tem um total de 24 camadas convolucionais, quatro camadas de pooling máximo e duas camadas totalmente conectadas.
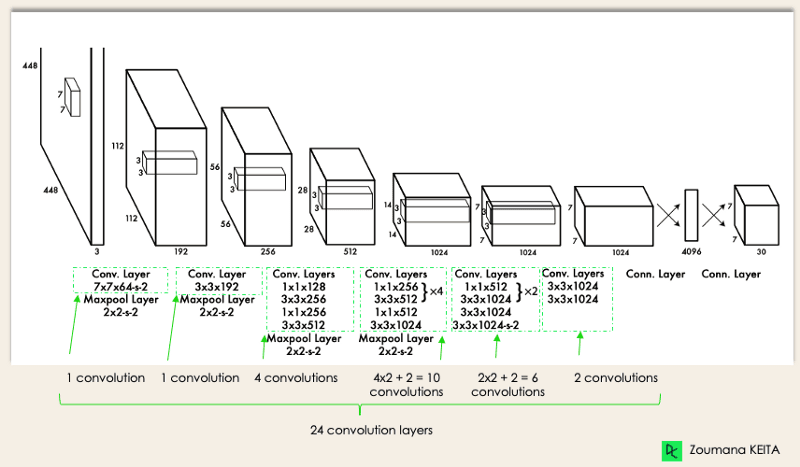
Arquitetura YOLO do artigo original (Modificado pelo autor)
A arquitetura funciona da seguinte forma:
Ao concluir o curso Aprendizagem profunda em Python, você estará pronto para usar o Keras para treinar e testar redes complexas de várias saídas e se aprofundar na aprendizagem profunda.
Agora que você entende a arquitetura, vamos ter uma visão geral de alto nível de como o algoritmo YOLO realiza a detecção de objetos usando um caso de uso simples.
"Imagine que você criou um aplicativo YOLO que detecta jogadores e bolas de futebol a partir de uma determinada imagem.
Mas como você pode explicar esse processo para alguém, especialmente para pessoas não iniciadas?
→ Esse é o ponto principal desta seção. Você entenderá todo o processo de como o YOLO realiza a detecção de objetos; como obter a imagem (B) a partir da imagem (A)"
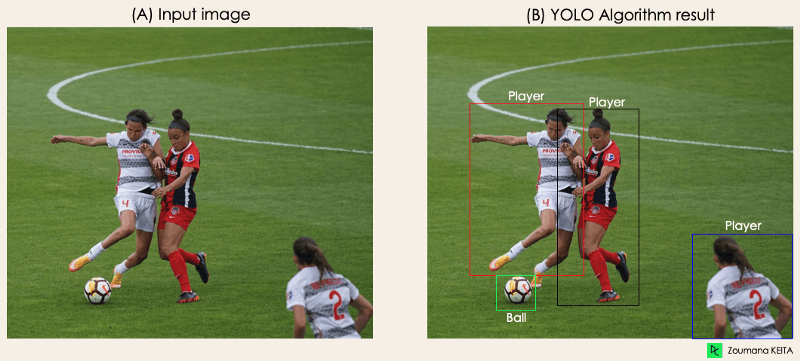 Imagem do autor
Imagem do autor
O algoritmo funciona com base nas quatro abordagens a seguir:
Vamos dar uma olhada mais de perto em cada um deles.
Essa primeira etapa começa dividindo a imagem original (A) em células de grade NxN de formato igual, onde N, no nosso caso, é 4, mostrado na imagem à direita. Cada célula da grade é responsável por localizar e prever a classe do objeto que ela cobre, juntamente com o valor de probabilidade/confiança.

Imagem do autor
A próxima etapa é determinar as caixas delimitadoras que correspondem aos retângulos que destacam todos os objetos na imagem. Você pode ter tantas caixas delimitadoras quanto o número de objetos em uma determinada imagem.
O YOLO determina os atributos dessas caixas delimitadoras usando um único módulo de regressão no seguinte formato, em que Y é a representação vetorial final de cada caixa delimitadora.
Y = [pc, bx, by, bh, bw, c1, c2]
Isso é especialmente importante durante a fase de treinamento do modelo.
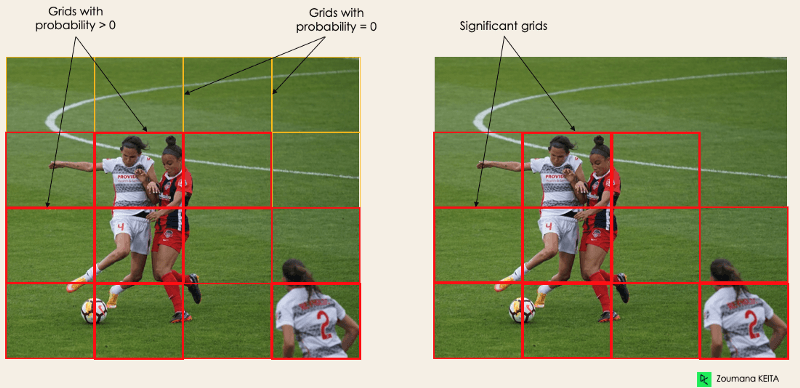
Imagem do autor
Para entender, vamos prestar mais atenção ao player no canto inferior direito.
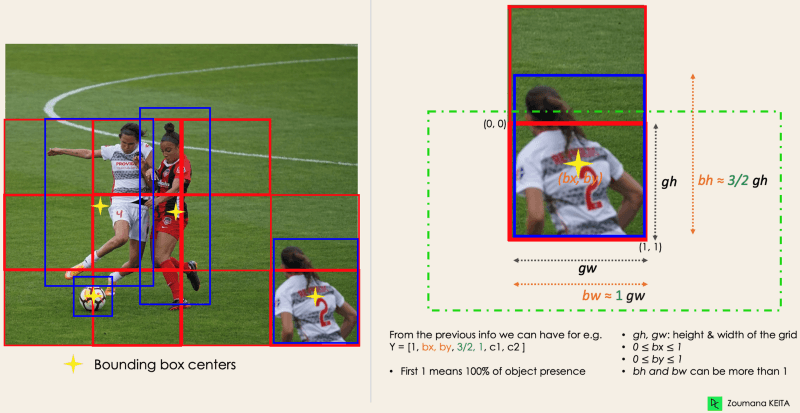 do autor
do autor
Na maioria das vezes, um único objeto em uma imagem pode ter vários candidatos a caixas de grade para previsão, mesmo que nem todos sejam relevantes. O objetivo do IOU (um valor entre 0 e 1) é descartar essas caixas de grade para manter apenas aquelas que são relevantes. Aqui está a lógica por trás disso:
A seguir, você verá uma ilustração da aplicação do processo de seleção de grade ao objeto inferior esquerdo. Podemos observar que o objeto tinha originalmente duas grades candidatas e, no final, apenas a "Grade 2" foi selecionada.
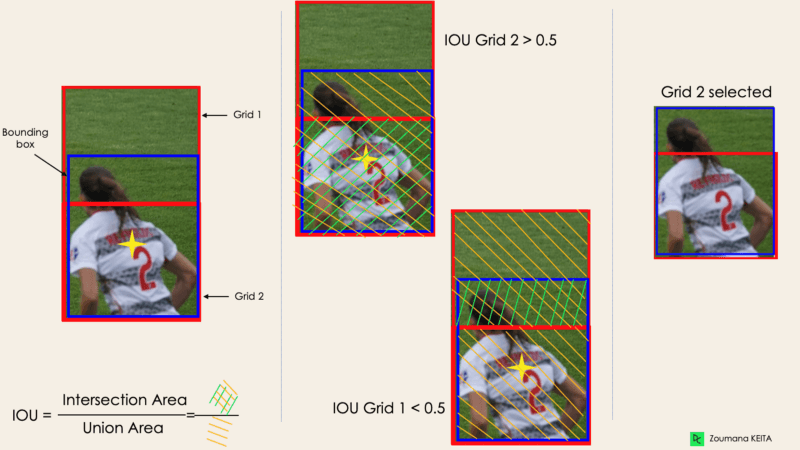
Imagem do autor
Definir um limite para o IOU nem sempre é suficiente porque um objeto pode ter várias caixas com IOU além do limite, e deixar todas essas caixas pode incluir ruído. É aqui que podemos usar o NMS para manter apenas as caixas com a maior pontuação de probabilidade de detecção.
A detecção de objetos YOLO tem diferentes aplicações em nossa vida cotidiana. Nesta seção, abordaremos alguns deles nos seguintes domínios: saúde, agricultura, vigilância de segurança e carros autônomos.
A detecção de objetos foi introduzida em muitos setores práticos, como saúde e agricultura. Vamos entender cada uma delas com exemplos específicos.
Especificamente na cirurgia, pode ser um desafio localizar órgãos em tempo real, devido à diversidade biológica de um paciente para outro. O Kidney Recognition in CT usou o YOLOv3 para facilitar a localização de rins em 2D e 3D a partir de exames de tomografia computadorizada (CT).
O curso Biomedical Image Analysis in Python pode ajudar você a aprender os fundamentos da exploração, manipulação e medição de dados de imagens biomédicas usando Python.
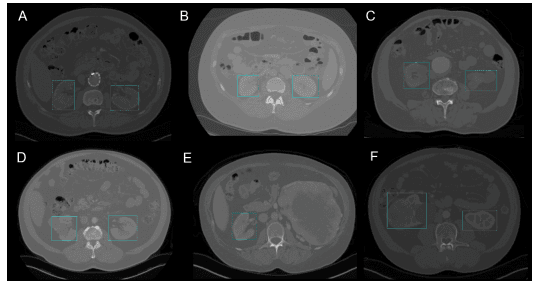
Detecção de rim em 2D pelo YOLOv3 (Imagem de Reconhecimento de rim em CT usando YOLOv3)
A Inteligência Artificial e a robótica estão desempenhando um papel importante na agricultura moderna. Os robôs de colheita são robôs baseados em visão que foram introduzidos para substituir a colheita manual de frutas e legumes. Um dos melhores modelos nesse campo é o YOLO. Em Tomato detection based on modified YOLOv3 framework, os autores descrevem como usaram o YOLO para identificar os tipos de frutas e legumes para uma colheita eficiente.

Imagem da detecção de tomates com base na estrutura YOLOv3 modificada(fonte)
Embora a detecção de objetos seja usada principalmente na vigilância de segurança, essa não é a única aplicação. O YOLOv3 foi usado durante a pandemia de covid-19 para estimar as violações de distância social entre as pessoas.
Você pode aprofundar sua leitura sobre esse tópico em Uma estrutura de monitoramento de distância social baseada em aprendizagem profunda para a COVID-19.
A detecção de objetos em tempo real faz parte do DNA dos sistemas de veículos autônomos. Essa integração é vital para os veículos autônomos, pois eles precisam identificar adequadamente as faixas corretas e todos os objetos e pedestres ao redor para aumentar a segurança nas estradas. O aspecto em tempo real do YOLO o torna um candidato melhor em comparação com abordagens simples de segmentação de imagens.
Desde o primeiro lançamento do YOLO em 2015, ele evoluiu muito com diferentes versões. Nesta seção, entenderemos as diferenças entre cada uma dessas versões.
Essa primeira versão do YOLO foi um divisor de águas na detecção de objetos, devido à sua capacidade de reconhecer objetos de forma rápida e eficiente.
No entanto, como muitas outras soluções, a primeira versão do YOLO tem suas próprias limitações:
O YOLOv2 foi criado em 2016 com a ideia de tornar o modelo YOLO melhor, mais rápido e mais forte.
O aprimoramento inclui, entre outros, o uso da Darknet-19 como nova arquitetura, normalização de lotes, maior resolução de entradas, camadas de convolução com âncoras, agrupamento de dimensionalidade e (5) recursos de granulação fina.
A adição de uma camada de normalização em lote melhorou o desempenho em 2% mAP. Essa normalização em lote incluiu um efeito de regularização, evitando o ajuste excessivo.
O YOLOv2 usa diretamente uma entrada de resolução mais alta, 448×448, em vez de 224×224, o que faz com que o modelo ajuste seu filtro para ter um desempenho melhor em imagens de resolução mais alta. Essa abordagem aumentou a precisão em 4% mAP, depois de ser treinada por 10 épocas nos dados do ImageNet.
Em vez de prever a coordenada exata das caixas delimitadoras dos objetos, como opera o YOLOv1, o YOLOv2 simplifica o problema substituindo as camadas totalmente conectadas por caixas de ancoragem. Essa abordagem diminuiu ligeiramente a precisão, mas melhorou a recuperação do modelo em 7%, o que dá mais espaço para melhorias.
As caixas-âncora mencionadas anteriormente são encontradas automaticamente pelo YOLOv2 usando o agrupamento de dimensionalidade k-means com k=5, em vez de realizar uma seleção manual. Essa nova abordagem proporcionou uma boa compensação entre a recuperação e a precisão do modelo.
Para entender melhor o agrupamento de dimensionalidade k-means, dê uma olhada em nossos tutoriais K-Means Clustering in Python with scikit-learn e K-Means Clustering in R. Eles se aprofundam no conceito de agrupamento k-means usando Python e R.
As previsões do YOLOv2 geram mapas de recursos de 13x13, o que, obviamente, é suficiente para a detecção de objetos grandes. Mas para a detecção de objetos muito mais finos, a arquitetura pode ser modificada transformando o mapa de recursos 26 × 26 × 512 em um mapa de recursos 13 × 13 × 2048, concatenado com os recursos originais. Essa abordagem melhorou o desempenho do modelo em 1%.
Um aprimoramento incremental foi realizado no YOLOv2 para criar o YOLOv3.
A mudança inclui principalmente uma nova arquitetura de rede: Darknet-53. Trata-se de uma rede neural 106, com redes de upsampling e blocos residuais. Ele é muito maior, mais rápido e mais preciso em comparação com a Darknet-19, que é a espinha dorsal do YOLOv2. Essa nova arquitetura tem sido benéfica em vários níveis:
Um modelo de regressão logística é usado pelo YOLOv3 para prever a pontuação de objetividade para cada caixa delimitadora.
Em vez de usar o softmax, como feito no YOLOv2, foram introduzidos classificadores logísticos independentes para prever com precisão a classe das caixas delimitadoras. Isso é útil até mesmo quando você enfrenta domínios mais complexos com rótulos sobrepostos (por exemplo, Pessoa → Jogador de futebol). O uso de um softmax restringiria cada caixa a ter apenas uma classe, o que nem sempre é verdade.
O YOLOv3 executa três previsões em escalas diferentes para cada local dentro da imagem de entrada para ajudar com o upsampling das camadas anteriores. Essa estratégia permite que você obtenha informações semânticas mais detalhadas e significativas para obter uma imagem de saída de melhor qualidade.
Esta versão do YOLO tem uma velocidade e precisão ideais de detecção de objetos em comparação com todas as versões anteriores e outros detectores de objetos de última geração.
A imagem abaixo mostra que o YOLOv4 supera o YOLOv3 e o FPS em velocidade em 10% e 12%, respectivamente.
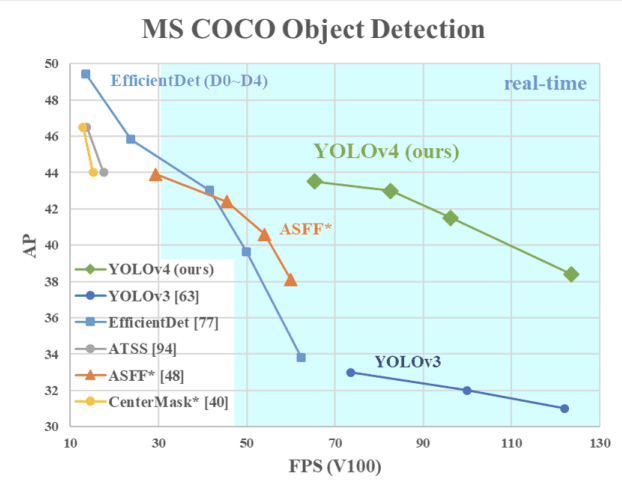
Velocidade do YOLOv4 em comparação com o YOLOv3 e outros detectores de objetos de última geração(fonte)
O YOLOv4 foi projetado especificamente para sistemas de produção e otimizado para cálculos paralelos.
A espinha dorsal da arquitetura do YOLOv4 é a CSPDarknet53, uma rede que contém 29 camadas de convolução com filtros 3 × 3 e aproximadamente 27,6 milhões de parâmetros.
Essa arquitetura, comparada à do YOLOv3, acrescenta as seguintes informações para melhorar a detecção de objetos:
Como uma rede unificada para várias tarefas, o YOLOR se baseia na rede unificada, que é uma combinação de abordagens de conhecimento explícito e implícito.
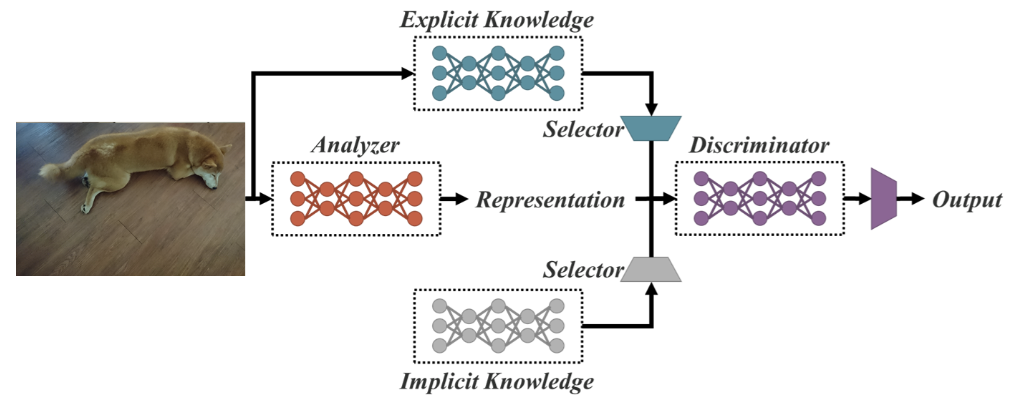
Arquitetura de rede unificada (fonte)
O conhecimento explícito é o aprendizado normal ou consciente. O aprendizado implícito, por outro lado, é aquele realizado subconscientemente (a partir da experiência).
Combinando essas duas técnicas, a YOLOR é capaz de criar uma arquitetura mais robusta com base em três processos: (1) alinhamento de recursos, (2) alinhamento de previsão para detecção de objetos e (3) representação canônica para aprendizado multitarefa
Essa abordagem introduz uma representação implícita no mapa de recursos de cada rede de pirâmide de recursos (FPN), o que melhora a precisão em cerca de 0,5%.
As previsões do modelo são refinadas com a adição de representação implícita às camadas de saída da rede.
A realização do treinamento multitarefa requer a execução da otimização conjunta na função de perda compartilhada por todas as tarefas. Esse processo pode diminuir o desempenho geral do modelo, e esse problema pode ser atenuado com a integração da representação canônica durante o treinamento do modelo.
No gráfico a seguir, podemos observarque o YOLOR atingiu a velocidade de inferência de última geraçãonos dados do MS COCO em comparação com outros modelos.
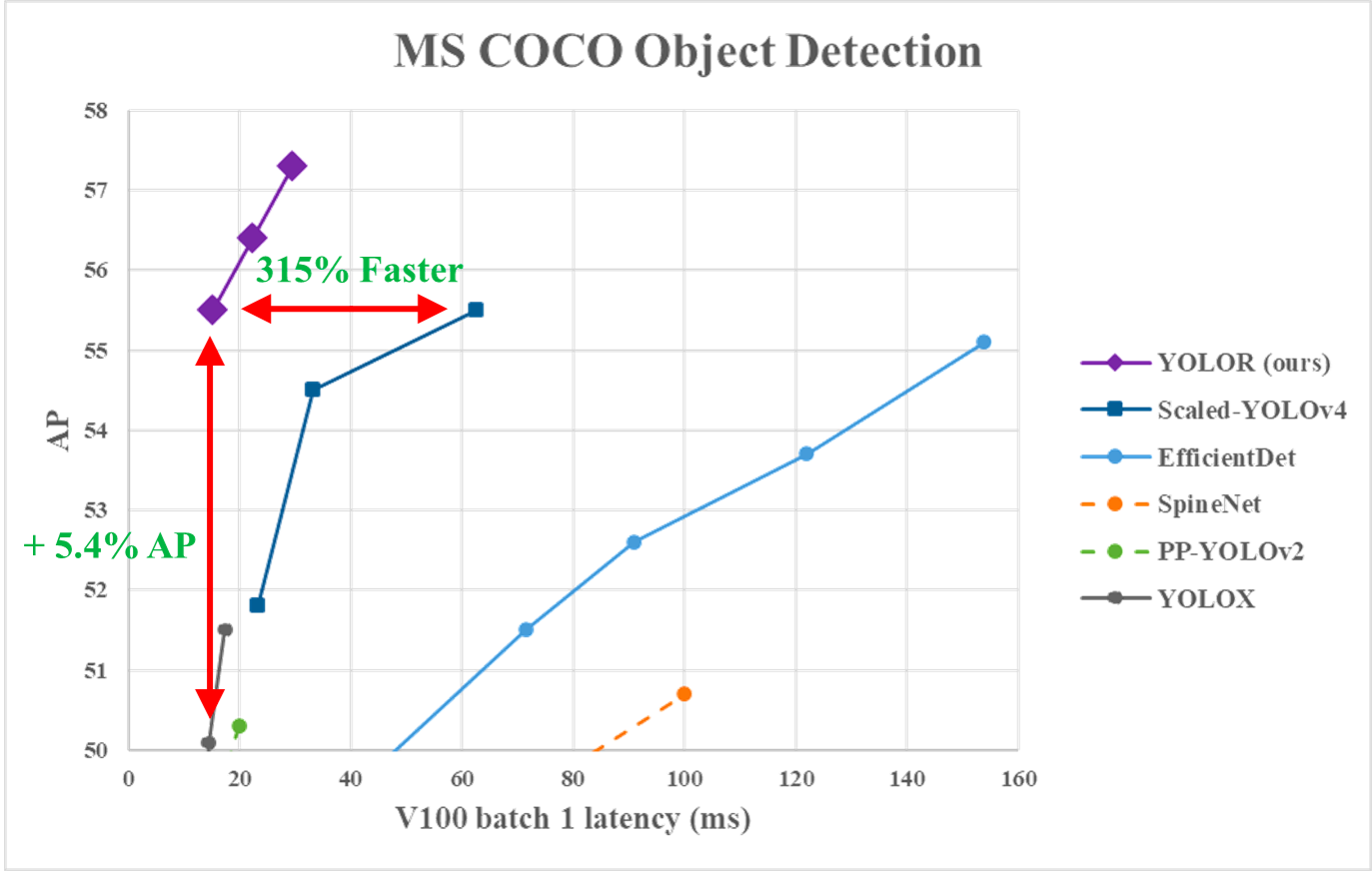
Desempenho do YOLOR em relação a você. YOLOv4 e outros modelos (fonte)
Isso usa uma linha de base que é uma versão modificada do YOLOv3, com o Darknet-53 como seu backbone.
Publicado no artigo Exceeding YOLO Series in 2021 (Superando a série YOLO em 2021), o YOLOX apresenta as quatro características principais a seguir para criar um modelo melhor em comparação com as versões anteriores.
O cabeçote acoplado usado nas versões anteriores do YOLO reduz o desempenho dos modelos. Em vez disso, o YOLOX usa um modelo desacoplado, que permite separar as tarefas de classificação e localização, aumentando assim o desempenho do modelo.
A integração do Mosaic e do MixUp na abordagem de aumento de dados aumentou consideravelmente o desempenho da YOLOX.
Os algoritmos baseados em âncoras executam o agrupamento de forma oculta, o que aumenta o tempo de inferência. A remoção do mecanismo de ancoragem no YOLOX reduziu o número de previsões por imagem e melhorou significativamente o tempo de inferência.
Em vez de usar a abordagem de interseção de união (IoU), o autor introduziu o SimOTA, uma estratégia de atribuição de rótulos mais robusta que alcança resultados de última geração, não apenas reduzindo o tempo de treinamento, mas também evitando problemas extras de hiperparâmetros. Além disso, ele melhorou o mAP de detecção em 3%.
O YOLOv5, em comparação com outras versões, não tem um artigo de pesquisa publicado e é a primeira versão do YOLO a ser implementada no Pytorch, e não na Darknet.
Lançado por Glenn Jocher em junho de 2020, o YOLOv5, assim como o YOLOv4, usa o CSPDarknet53 como a espinha dorsal de sua arquitetura. O lançamento inclui cinco tamanhos diferentes de modelos: YOLOv5s (menor), YOLOv5m, YOLOv5l e YOLOv5x (maior).
Um dos principais aprimoramentos na arquitetura do YOLOv5 é a integração da camada Focus, representada por uma única camada, que é criada pela substituição das três primeiras camadas do YOLOv3. Essa integração reduziu o número de camadas e o número de parâmetros e também aumentou a velocidade de avanço e retrocesso sem nenhum impacto significativo no mAP.
A ilustração a seguir compara o tempo de treinamento entre o YOLOv4 e o YOLOv5s.
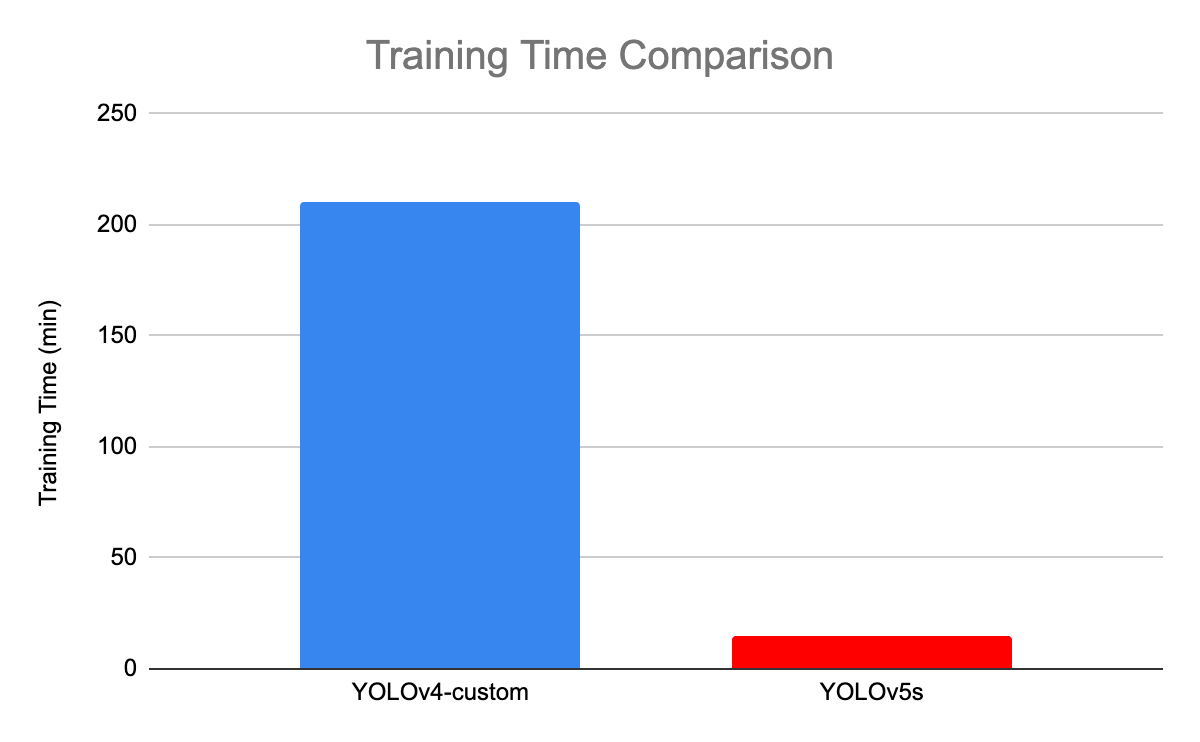
Comparação do tempo de treinamento entre YOLOv4 e YOLOv5(fonte)
Dedicada a aplicações industriais com design eficiente e de alto desempenho, amigável ao hardware, a estrutura YOLOv6 (MT-YOLOv6) foi lançada pela Meituan, uma empresa chinesa de comércio eletrônico.
Escrita em Pytorch, essa nova versão não fazia parte do YOLO oficial, mas ainda assim recebeu o nome de YOLOv6 porque sua estrutura foi inspirada na arquitetura YOLO original de um estágio.
O YOLOv6 introduziu três aprimoramentos significativos em relação ao YOLOv5 anterior: um design de backbone e pescoço compatível com o hardware, um cabeçote desacoplado eficiente e uma estratégia de treinamento mais eficaz.
O YOLOv6 oferece resultados excelentes em comparação com as versões anteriores do YOLO em termos de precisão e velocidade no conjunto de dados COCO, conforme ilustrado abaixo.
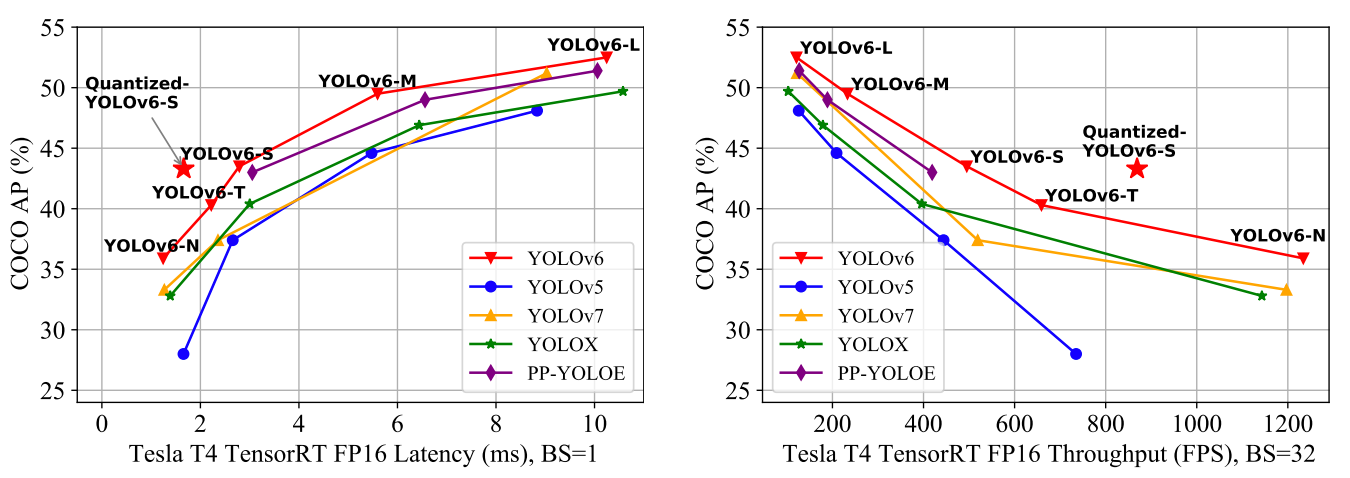
Comparação de detectores de objetos eficientes de última geração. Todos os modelos foram testados com o TensorRT 7, exceto o modelo quantizado, que foi testado com o TensorRT 8(fonte)
Todas essas características fazem do YOLOv5 o algoritmo certo para aplicações industriais.
O YOLOv7 foi lançado em julho de 2022 no artigo Trained bag-of-freebies sets new state-of-the-art for real-time object detectors. Essa versão está fazendo um movimento significativo no campo da detecção de objetos e superou todos os modelos anteriores em termos de precisão e velocidade.
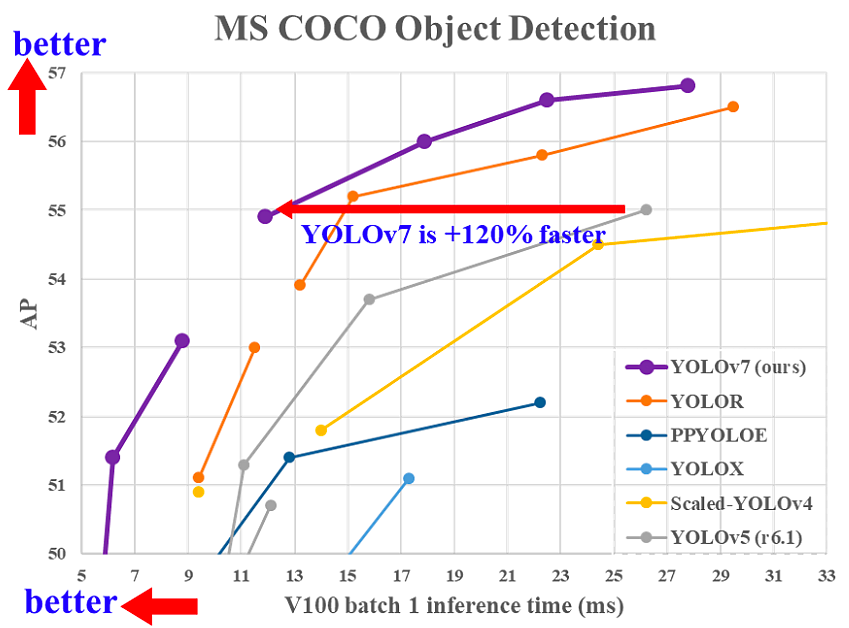
Comparação do tempo de inferência do YOLOv7 com outros detectores de objetos em tempo real(fonte)
O YOLOv7 fez uma grande mudança em sua (1) arquitetura e (2) no nível do pacote de brindes treináveis:
O YOLOv7 reformou sua arquitetura integrando a Rede de Agregação de Camada Eficiente Estendida (E-ELAN), que permite que o modelo aprenda mais recursos diversos para um aprendizado melhor.
Além disso, o YOLOv7 dimensiona sua arquitetura concatenando a arquitetura dos modelos dos quais é derivado, como o YOLOv4, o YOLOv4 dimensionado e o YOLO-R. Isso permite que o modelo atenda às necessidades de diferentes velocidades de inferência.
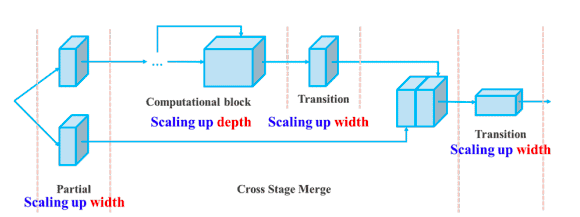
Dimensionamento composto de profundidade e largura para o modelo baseado em concatenação(fonte)
O termo bag-of-freebies refere-se ao aprimoramento da precisão do modelo sem aumentar o custo de treinamento, e esse é o motivo pelo qual o YOLOv7 aumentou não apenas a velocidade de inferência, mas também a precisão da detecção.
Este artigo abordou os benefícios do YOLO em comparação com outros algoritmos de detecção de objetos de última geração e sua evolução de 2015 a 2020, com destaque para seus benefícios.
Dado o rápido avanço do YOLO, não há dúvida de que ele continuará sendo o líder no campo da detecção de objetos por muito tempo.
A próxima etapa deste artigo será a aplicação do algoritmo YOLO a casos do mundo real. Até lá, nosso curso Introdução à aprendizagem profunda em Python pode ajudar você a aprender os fundamentos das redes neurais e como criar modelos de aprendizagem profunda usando o Keras 2.0 em Python.
Cursos de aprendizagem profunda
Curso
Curso
Curso
blog
Abid Ali Awan
8 min
blog
Kurtis Pykes
8 min
blog
Natassha Selvaraj
15 min
Tutorial
Natassha Selvaraj
Tutorial
Zoumana Keita



