En esta era de transformación digital, comprender las tecnologías que impulsan la innovación ya no es un lujo, sino una necesidad. Una tecnología que ha estado a la vanguardia de esta transformación es el machine learning. Este artículo pretende desmitificar el machine learning, proporcionando una guía completa tanto para principiantes como para entusiastas. Profundizaremos en la definición de machine learning, sus tipos, aplicaciones y las herramientas utilizadas en este campo. También exploraremos las distintas trayectorias profesionales en machine learning y te orientaremos sobre cómo iniciar tu andadura en este apasionante campo.
¿Qué es el machine learning?
El machine learning, a menudo abreviado como ML, es un subconjunto de la inteligencia artificial (IA) que se centra en el desarrollo de algoritmos informáticos que mejoran automáticamente mediante la experiencia y el uso de datos. En términos más sencillos, el machine learning permite a los ordenadores aprender de los datos y tomar decisiones o hacer predicciones sin estar explícitamente programados para ello.
En esencia, el machine learning consiste en crear y aplicar algoritmos que faciliten estas decisiones y predicciones. Estos algoritmos están diseñados para mejorar su rendimiento con el tiempo, haciéndose más precisos y eficaces a medida que procesan más datos.
En la programación tradicional, un ordenador sigue un conjunto de instrucciones predefinidas para realizar una tarea. Sin embargo, en el machine learning, al ordenador se le da un conjunto de ejemplos (datos) y una tarea que realizar, pero depende del ordenador averiguar cómo realizar la tarea basándose en los ejemplos que se le dan.
Por ejemplo, si queremos que un ordenador reconozca imágenes de gatos, no le damos instrucciones específicas sobre el aspecto de un gato. En lugar de eso, le damos miles de imágenes de gatos y dejamos que el algoritmo de machine learning descubra los patrones y características comunes que definen a un gato. Con el tiempo, a medida que el algoritmo procesa más imágenes, mejora en el reconocimiento de gatos, incluso cuando se le presentan imágenes que nunca ha visto antes.
Esta capacidad de aprender de los datos y mejorar con el tiempo hace que el machine learning sea increíblemente potente y versátil. Es la fuerza motriz de muchos de los avances tecnológicos que vemos hoy en día, desde los asistentes de voz y los sistemas de recomendación hasta los coches autoconducidos y el análisis predictivo.
Machine learning vs. IA vs. aprendizaje profundo
El machine learning se confunde a menudo con la inteligencia artificial o el aprendizaje profundo. Veamos en qué se diferencian estos términos. Para profundizar más, consulta nuestras guías comparativas sobre IA vs. machine learning y aprendizaje automático vs. aprendizaje profundo.
La IA se refiere al desarrollo de programas que se comportan de forma inteligente e imitan la inteligencia humana mediante un conjunto de algoritmos. Este campo se centra en tres habilidades: el aprendizaje, el razonamiento y la autocorrección para obtener la máxima eficacia. La IA puede referirse a programas basados en machine learning o incluso a programas informáticos programados explícitamente.
El machine learning es un subconjunto de la IA, que utiliza algoritmos que aprenden de los datos para hacer predicciones. Estas predicciones pueden generarse mediante aprendizaje supervisado, en el que los algoritmos aprenden patrones a partir de datos existentes, o aprendizaje no supervisado, en el que descubren patrones generales en los datos. Los modelos de ML pueden predecir valores numéricos basándose en datos históricos, categorizar sucesos como verdaderos o falsos y agrupar puntos de datos basándose en puntos en común.
El aprendizaje profundo, por otra parte, es un subcampo del machine learning que se ocupa de algoritmos basados esencialmente en redes neuronales artificiales (RNA) multicapa que se inspiran en la estructura del cerebro humano.
A diferencia de los algoritmos convencionales de machine learning, los algoritmos de aprendizaje profundo son menos lineales, más complejos y jerárquicos, capaces de aprender de enormes cantidades de datos y de producir resultados muy precisos. La traducción de idiomas, el reconocimiento de imágenes y la medicina personalizada son algunos ejemplos de aplicaciones del aprendizaje profundo.

Comparación de diferentes términos industriales
La importancia del machine learning
En el siglo XXI, los datos son el nuevo petróleo, y el machine learning es el motor que impulsa este mundo impulsado por los datos. Es una tecnología fundamental en la era digital actual, y no se puede exagerar su importancia. Esto se refleja en las previsiones de crecimiento del sector: la Oficina de Estadísticas Laborales de Estados Unidos prevé un aumento del 21 % del empleo entre 2021 y 2031.
He aquí algunas razones por las que es tan esencial en el mundo moderno:
- Tratamiento de datos. Una de las principales razones por las que el machine learning es tan importante es su capacidad para manejar y dar sentido a grandes volúmenes de datos. Con la explosión de datos digitales procedentes de las redes sociales, los sensores y otras fuentes, los métodos tradicionales de análisis de datos se han vuelto inadecuados. Los algoritmos de machine learning pueden procesar estas enormes cantidades de datos, descubrir patrones ocultos y proporcionar valiosos conocimientos que pueden impulsar la toma de decisiones.
- Impulsar la innovación. El machine learning está impulsando la innovación y la eficiencia en diversos sectores. He aquí algunos ejemplos:
- Sanidad. Los algoritmos se utilizan para predecir brotes de enfermedades, personalizar los planes de tratamiento de los pacientes y mejorar la precisión de las imágenes médicas.
- Finanzas. El machine learning se utiliza para la puntuación crediticia, el comercio algorítmico y la detección del fraude.
- Venta al por menor. Los sistemas de recomendación, las cadenas de suministro y el servicio al cliente pueden beneficiarse del machine learning.
- Las técnicas utilizadas también encuentran aplicaciones en sectores tan diversos como la agricultura, la educación y el ocio.
- Habilitar la automatización. El machine learning es un factor clave de la automatización. Al aprender de los datos y mejorar con el tiempo, los algoritmos de machine learning pueden realizar tareas que antes eran manuales, liberando a los humanos para que se centren en tareas más complejas y creativas. Esto no sólo aumenta la eficacia, sino que también abre nuevas posibilidades de innovación.
¿Cómo funciona el machine learning?
Comprender cómo funciona el machine learning implica adentrarse en un proceso paso a paso que transforma los datos brutos en ideas valiosas. Desglosemos este proceso:
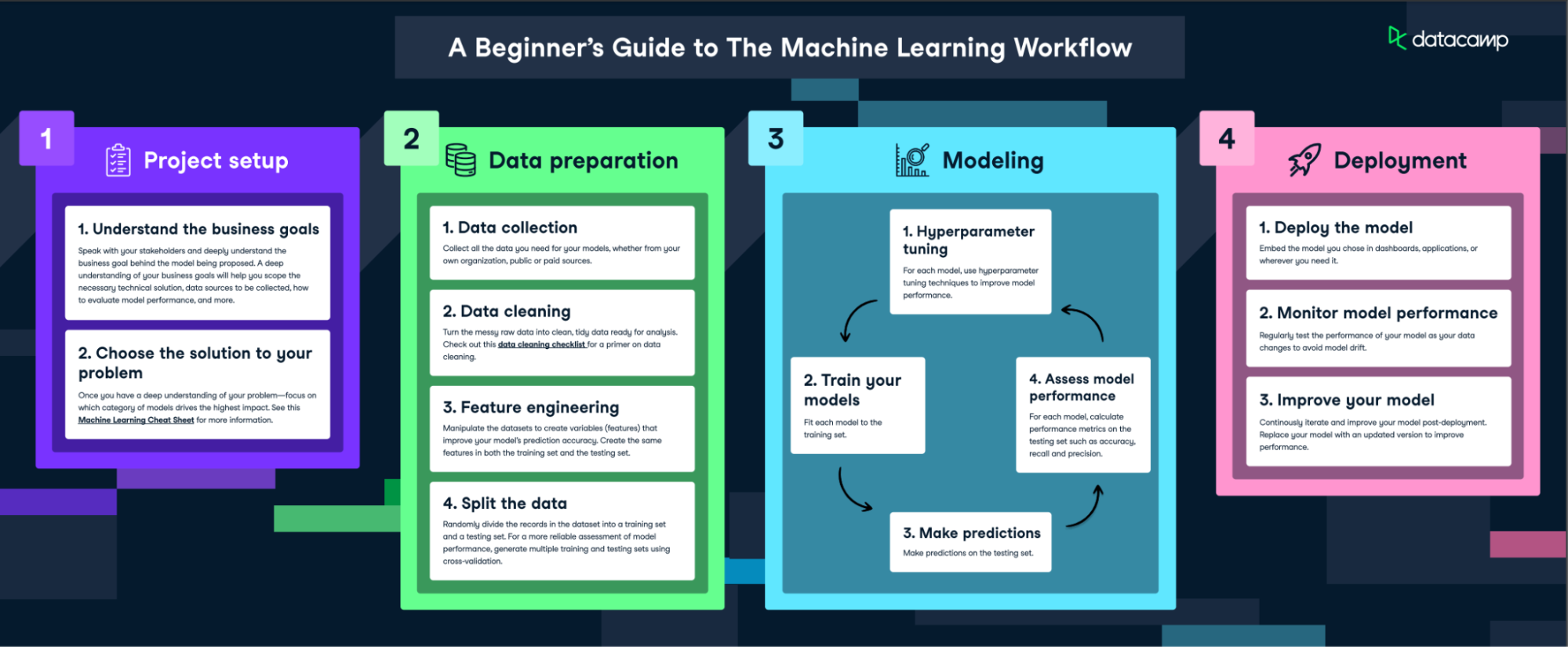
Ver el flujo de trabajo completo aquí
Paso 1: Recogida de datos
El primer paso en el proceso de machine learning es la recopilación de datos. Los datos son el alma del machine learning: la calidad y la cantidad de tus datos pueden influir directamente en el rendimiento de tu modelo. Los datos pueden obtenerse de diversas fuentes, como bases de datos, archivos de texto, imágenes, archivos de audio o incluso raspados de la web.
Una vez recopilados, los datos deben prepararse para el machine learning. Este proceso implica organizar los datos en un formato adecuado, como un archivo CSV o una base de datos, y asegurarse de que los datos son relevantes para el problema que intentas resolver.
Paso 2: Preprocesamiento de datos
El preprocesamiento de datos es un paso crucial en el proceso de machine learning. Implica limpiar los datos (eliminar duplicados, corregir errores), tratar los datos que faltan (eliminándolos o rellenándolos) y normalizar los datos (ajustarlos a un formato estándar).
El preprocesamiento mejora la calidad de tus datos y garantiza que tu modelo de machine learning pueda interpretarlos correctamente. Este paso puede mejorar significativamente la precisión de tu modelo. Nuestro curso, Preprocesamiento para el machine learning en Python, explora cómo preparar tus datos depurados para el modelado.
Paso 3: Elegir el modelo adecuado
Una vez preparados los datos, el siguiente paso es elegir un modelo de machine learning. Hay muchos tipos de modelos entre los que elegir, como la regresión lineal, los árboles de decisión y las redes neuronales. La elección del modelo depende de la naturaleza de tus datos y del problema que intentas resolver.
Los factores que hay que tener en cuenta al elegir un modelo son el tamaño y el tipo de tus datos, la complejidad del problema y los recursos informáticos disponibles. Puedes obtener más información sobre los distintos modelos de machine learning en otro artículo.
Paso 4: Entrenamiento del modelo
Tras elegir un modelo, el siguiente paso es entrenarlo utilizando los datos preparados. El entrenamiento consiste en introducir los datos en el modelo y permitir que ajuste sus parámetros internos para predecir mejor el resultado.
Durante el entrenamiento, es importante evitar el sobreajuste (cuando el modelo funciona bien con los datos de entrenamiento pero mal con los nuevos datos) y el infraajuste (cuando el modelo funciona mal tanto con los datos de entrenamiento como con los nuevos datos). Puedes aprender más sobre el proceso completo de machine learning en nuestro programa Fundamentos del machine learning con Python, que explora los conceptos esenciales y cómo aplicarlos.
Paso 5: Evaluar el modelo
Una vez entrenado el modelo, es importante evaluar su rendimiento antes de desplegarlo. Esto implica probar el modelo con nuevos datos que no ha visto durante el entrenamiento.
Las métricas habituales para evaluar el rendimiento de un modelo incluyen la fiabilidad (para problemas de clasificación), la precisión y la exhaustividad (para problemas de clasificación binaria) y el error cuadrático medio (para problemas de regresión). Cubrimos este proceso de evaluación con más detalle en nuestro seminario web sobre IA responsable.
Paso 6: Ajuste y optimización de hiperparámetros
Tras evaluar el modelo, puede que necesites ajustar sus hiperparámetros para mejorar su rendimiento. Este proceso se conoce como ajuste de parámetros u optimización de hiperparámetros.
Las técnicas de ajuste de hiperparámetros incluyen la búsqueda en cuadrícula (en la que pruebas distintas combinaciones de parámetros) y la validación cruzada (en la que divides tus datos en subconjuntos y entrenas tu modelo en cada subconjunto para asegurarte de que funciona bien en datos distintos).
Tenemos un artículo aparte sobre la optimización de hiperparámetros en modelos de machine learning, que trata el tema con más detalle.
Paso 7: Predicciones e implementación
Una vez que el modelo está entrenado y optimizado, está listo para hacer predicciones sobre nuevos datos. Este proceso implica introducir nuevos datos en el modelo y utilizar el resultado del modelo para la toma de decisiones o para análisis posteriores.
Desplegar el modelo implica integrarlo en un entorno de producción donde pueda procesar datos del mundo real y proporcionar información en tiempo real. Este proceso suele conocerse como MLOps. Descubre más sobre MLOps en otro tutorial.
Tipos de machine learning
El machine learning puede clasificarse a grandes rasgos en tres tipos en función de la naturaleza del sistema de aprendizaje y de los datos disponibles: aprendizaje supervisado, aprendizaje no supervisado y aprendizaje por refuerzo. Profundicemos en cada uno de ellos:
Aprendizaje supervisado
El aprendizaje supervisado es el tipo más común de machine learning. En este enfoque, el modelo se entrena con un conjunto de datos etiquetados. En otras palabras, los datos van acompañados de una etiqueta que el modelo intenta predecir. Puede ser cualquier cosa, desde una etiqueta de categoría hasta un número de valor real.
El modelo aprende una correspondencia entre la entrada (características) y la salida (etiqueta) durante el proceso de entrenamiento. Una vez entrenado, el modelo puede predecir el resultado de nuevos datos no vistos.
Algunos ejemplos habituales de algoritmos de aprendizaje supervisado son la regresión lineal para problemas de regresión y la regresión logística, los árboles de decisión y las máquinas de vectores de soporte para problemas de clasificación. En términos prácticos, esto podría parecerse a un proceso de reconocimiento de imágenes, en el que un conjunto de datos de imágenes en el que cada foto se etiqueta como "gato", "perro", etc., un modelo supervisado puede reconocer y categorizar nuevas imágenes con precisión.
Aprendizaje no supervisado
En cambio, el aprendizaje no supervisado consiste en entrenar el modelo con un conjunto de datos sin etiquetar. Se deja que el modelo encuentre por sí mismo patrones y relaciones en los datos.
Este tipo de aprendizaje se utiliza a menudo para la agrupación y la reducción de la dimensionalidad. La agrupación consiste en agrupar puntos de datos similares, mientras que la reducción de la dimensionalidad consiste en reducir el número de variables aleatorias consideradas obteniendo un conjunto de variables principales.
Algunos ejemplos habituales de algoritmos de aprendizaje no supervisado son k-means para problemas de agrupación y el Análisis de Componentes Principales (ACP ) para problemas de reducción de la dimensionalidad. De nuevo, en términos prácticos, en el campo del marketing, el aprendizaje no supervisado se utiliza a menudo para segmentar la base de clientes de una empresa. Examinando los patrones de compra, los datos demográficos y otra información, el algoritmo puede agrupar a los clientes en segmentos que muestren comportamientos similares sin etiquetas preexistentes.
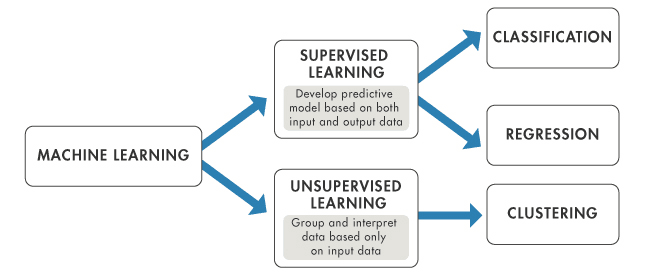
Comparación del aprendizaje supervisado y no supervisado
Aprendizaje por refuerzo
El aprendizaje por refuerzo es un tipo de machine learning en el que un agente aprende a tomar decisiones interactuando con su entorno. El agente es recompensado o penalizado (con puntos) por las acciones que realiza, y su objetivo es maximizar la recompensa total.
A diferencia del aprendizaje supervisado y no supervisado, el aprendizaje por refuerzo es especialmente adecuado para problemas en los que los datos son secuenciales, y la decisión tomada en cada paso puede afectar a los resultados futuros.
Algunos ejemplos habituales de aprendizaje por refuerzo son los juegos, la robótica, la gestión de recursos y muchos más.
Comprender el impacto del machine learning
El machine learning ha tenido un impacto transformador en diversos sectores, revolucionando los procesos tradicionales y allanando el camino a la innovación. Exploremos algunos de estos impactos:
"El machine learning es la tecnología más transformadora de nuestro tiempo. Va a transformar todas las verticales."
- Satya Nadella, CEO de Microsoft
Sanidad
En sanidad, el machine learning se utiliza para predecir brotes de enfermedades, personalizar los planes de tratamiento de los pacientes y mejorar la precisión de las imágenes médicas. Por ejemplo, DeepMind Health de Google trabaja con médicos para crear modelos de machine learning que permitan detectar antes las enfermedades y mejorar la atención al paciente.
Finanzas
El sector financiero también se ha beneficiado enormemente del machine learning. Se utiliza para la puntuación crediticia, el comercio algorítmico y la detección del fraude. Una encuesta reciente reveló que el 56 % de los ejecutivos mundiales afirmaron que la inteligencia artificial (IA) y el machine learning se han implantado en los programas de cumplimiento de la normativa sobre delitos financieros.
Transporte
El machine learning está en el centro de la revolución de los coches autónomos. Empresas como Tesla y Waymo utilizan algoritmos de machine learning para interpretar los datos de los sensores en tiempo real, lo que permite a sus vehículos reconocer objetos, tomar decisiones y circular por carreteras de forma autónoma. Del mismo modo, la Administración de Transportes sueca ha empezado a trabajar recientemente con especialistas en visión por ordenador y machine learning para optimizar la gestión de las infraestructuras viarias del país.
Algunas aplicaciones del machine learning
Las aplicaciones de machine learning están a nuestro alrededor, a menudo trabajando entre bastidores para mejorar nuestra vida cotidiana. He aquí algunos ejemplos del mundo real:
Sistemas de recomendación
Los sistemas de recomendación son una de las aplicaciones más visibles del machine learning. Empresas como Netflix y Amazon utilizan machine learning para analizar tu comportamiento anterior y recomendarte productos o películas que podrían gustarte. Aprende a construir un motor de recomendación en Python con nuestro curso online.
Asistentes de voz
Los asistentes de voz como Siri, Alexa y Google Assistant utilizan machine learning para entender tus órdenes de voz y ofrecer respuestas relevantes. Aprenden continuamente de tus interacciones para mejorar su rendimiento.
Detección del fraude
Los bancos y las empresas de tarjetas de crédito utilizan el machine learning para detectar transacciones fraudulentas. Analizando patrones de comportamiento normal y anormal, pueden señalar actividades sospechosas en tiempo real. Tenemos un curso de detección del fraude en Python, que explora el concepto con más detalle.
Redes sociales
Las plataformas de redes sociales utilizan el machine learning para diversas tareas, desde personalizar tu feed hasta filtrar contenidos inapropiados.

Nuestra hoja de trucos sobre machine learning cubre diferentes algoritmos y sus usos
Herramientas de machine learning
En el mundo del machine learning, disponer de las herramientas adecuadas es tan importante como comprender los conceptos. Estas herramientas, que incluyen lenguajes de programación y bibliotecas, proporcionan los componentes básicos para implantar y desplegar algoritmos de machine learning. Exploremos algunas de las herramientas más populares del machine learning:
Python para Machine Learning
Python es un lenguaje popular para el machine learning debido a su sencillez y legibilidad, lo que lo convierte en una gran opción para los principiantes. También cuenta con un sólido ecosistema de bibliotecas adaptadas al machine learning.
Bibliotecas como NumPy y Pandas se utilizan para la manipulación y el análisis de datos, mientras que Matplotlib se utiliza para la visualización de datos. Scikit-learn proporciona una amplia gama de algoritmos de machine learning, y TensorFlow y PyTorch se utilizan para construir y entrenar redes neuronales.
Recursos para empezar
- Programa de habilidades Fundamentos de machine learning con Python
- Programa de carrera Científico de machine learning con Python
- Tutorial de Introducción al machine learning en Python
R para Machine Learning
R es otro lenguaje muy utilizado en machine learning, sobre todo para el análisis estadístico. Tiene un rico ecosistema de paquetes que facilitan la implementación de algoritmos de machine learning.
Paquetes como caret, mlr y randomForest proporcionan una gran variedad de algoritmos de machine learning, desde regresión y clasificación hasta agrupamiento y reducción dimensional.
Recursos para empezar
- Programa de habilidades Fundamentos de machine learning con R
- Programa de carrera Científico de machine learning con Python
- Tutorial de machine learning en R para principiantes
TensorFlow
TensorFlow es una potente biblioteca de código abierto para el cálculo numérico, especialmente adecuada para el machine learning a gran escala. Ha sido desarrollado por el equipo de Google Brain y es compatible tanto con CPU como con GPU.
TensorFlow te permite construir y entrenar redes neuronales complejas, lo que lo convierte en una opción popular para aplicaciones de aprendizaje profundo.
Recursos para empezar
- Curso de Introducción a TensorFlow en Python
- Tutorial de TensorFlow para principiantes
- Tutorial de Python sobre Redes Neuronales Convolucionales (CNN) con TensorFlow
Scikit-Learn
Scikit-learn es una biblioteca de Python que proporciona una amplia gama de algoritmos de machine learning para el aprendizaje supervisado y no supervisado. Es conocido por su API clara y su documentación detallada.
Scikit-learn se utiliza a menudo para la minería y el análisis de datos, y se integra bien con otras bibliotecas de Python como NumPy y Pandas.
Recursos para empezar
- Curso de machine learning con scikit-learn | DataCamp
- Curso Aprendizaje Supervisado con scikit-learn | DataCamp
- Machine Learning en Python: tutorial de Scikit-Learn
- Hoja de trucos de Scikit-Learn: Machine Learning en Python
Keras
Keras es una API de redes neuronales de alto nivel, escrita en Python y capaz de ejecutarse sobre TensorFlow, CNTK o Theano. Se desarrolló centrándose en permitir una experimentación rápida.
Keras proporciona una interfaz fácil de usar para construir y entrenar redes neuronales, por lo que es una gran opción para los principiantes en el aprendizaje profundo.
Recursos para empezar
- Curso Introducción al aprendizaje profundo con Keras
- Curso de Aprendizaje profundo avanzado con Keras
- Tutorial de Keras: aprendizaje profundo en Python
- Hoja de trucos de Keras: redes neuronales en Python
PyTorch
PyTorch es una biblioteca de machine learning de código abierto basada en la biblioteca Torch. Es conocido por su flexibilidad y eficacia, lo que lo hace popular entre los investigadores.
PyTorch admite una amplia gama de aplicaciones, desde la visión por ordenador al procesamiento del lenguaje natural. Una de sus características clave es el gráfico computacional dinámico, que permite un cálculo flexible y optimizado.
Recursos para empezar
- Curso de Introducción al Aprendizaje Profundo en PyTorch
- Curso Aprendizaje profundo con PyTorch
- Tutorial de PyTorch: Construir una red neuronal sencilla desde cero
- PyTorch 2.0: Desvelando las últimas actualizaciones y perspectivas con ejemplos de código
Las mejores carreras de machine learning en 2023
El machine learning ha abierto un amplio abanico de oportunidades profesionales. Desde la ciencia de datos a la ingeniería de IA, los profesionales con conocimientos de machine learning están muy solicitados. Exploremos algunas de estas trayectorias profesionales:
Científico de datos
Un científico de datos utiliza métodos, procesos, algoritmos y sistemas científicos para extraer conocimientos e ideas de datos estructurados y no estructurados. El machine learning es una herramienta clave en el arsenal de un científico de datos, que le permite hacer predicciones y descubrir patrones en los datos.
Habilidades clave:
- Análisis estadístico
- Programación (Python, R)
- Machine learning
- Visualización de datos
- Resolución de problemas
Herramientas imprescindibles:
- Python
- R
- SQL
- Hadoop
- Spark
- Tableau
Ingeniero de machine learning
Un ingeniero de machine learning diseña e implementa sistemas de machine learning. Realizan experimentos de machine learning utilizando lenguajes de programación como Python y R, trabajan con conjuntos de datos y aplican algoritmos y bibliotecas de machine learning.
Habilidades clave:
- Programación (Python, Java, R)
- Algoritmos de machine learning
- Estadísticas
- Diseño de sistemas
Herramientas imprescindibles:
- Python
- TensorFlow
- Scikit-Learn
- PyTorch
- Keras
Científico investigador
Un científico investigador en machine learning lleva a cabo investigaciones para hacer avanzar el campo del machine learning. Trabajan tanto en el mundo académico como en la industria, desarrollando nuevos algoritmos y técnicas.
Habilidades clave:
- Conocimiento profundo de los algoritmos de machine learning
- Programación (Python, R)
- Metodología de la investigación
- Sólidos conocimientos matemáticos
Herramientas imprescindibles:
- Python
- R
- TensorFlow
- PyTorch
- MATLAB
|
Carrera profesional |
Habilidades clave |
Herramientas imprescindibles |
|
Científico de datos |
Análisis estadístico, Programación (Python, R), Machine learning, Visualización de datos, Resolución de problemas |
Python, R, SQL, Hadoop, Spark, Tableau |
|
Ingeniero de machine learning |
Programación (Python, Java, R), Algoritmos de machine learning, Estadística, Diseño de sistemas |
Python, TensorFlow, Scikit-learn, PyTorch, Keras |
|
Científico investigador |
Conocimiento profundo de los algoritmos de machine learning, Programación (Python, R), Metodología de la investigación, Sólidos conocimientos matemáticos |
Python, R, TensorFlow, PyTorch, MATLAB |
Cómo iniciarse en el machine learning
Comenzar un viaje en el machine learning puede parecer desalentador, pero con el enfoque y los recursos adecuados, cualquiera puede aprender este apasionante campo. Aquí tienes algunos pasos para empezar:
Comprender los fundamentos
Antes de sumergirse en el machine learning, es importante tener una base sólida en matemáticas (especialmente estadística y álgebra lineal) y programación (Python es una opción popular debido a su simplicidad y a la disponibilidad de bibliotecas de machine learning).
Hay muchos recursos disponibles para aprender estos conceptos básicos. Plataformas en línea como Khan Academy y Coursera ofrecen cursos de matemáticas y programación. Libros como "Think Stats" y "Python Crash Course" también son buenos puntos de partida.
Elige las herramientas adecuadas
Elegir las herramientas adecuadas es crucial en el machine learning. Python, junto con bibliotecas como NumPy, Pandas y Scikit-learn, es una opción popular debido a su sencillez y versatilidad.
Para empezar a utilizar estas herramientas, puedes seguir tutoriales en línea o hacer cursos en plataformas como DataCamp. Nuestro programa de Fundamentos del machine learning es el lugar ideal para empezar.
Aprende algoritmos de machine learning
Una vez que te sientas cómodo con los conceptos básicos, puedes empezar a aprender sobre algoritmos de machine learning. Empieza con algoritmos sencillos, como la regresión lineal y los árboles de decisión, antes de pasar a otros más complejos, como las redes neuronales.
Trabajar en proyectos
Trabajar en proyectos es una forma estupenda de adquirir experiencia práctica y reforzar lo que has aprendido. Empieza con proyectos sencillos, como predecir el precio de la vivienda o clasificar las especies de iris, y ve asumiendo poco a poco proyectos más complejos. Tenemos un artículo que explora 25 proyectos de machine learning para todos los niveles, que puede ayudarte a encontrar algo apropiado.
Mantente al día
El machine learning es un campo que evoluciona rápidamente, por lo que es importante mantenerse al día de los últimos avances. Seguir blogs relevantes, asistir a conferencias y participar en comunidades online puede ayudarte a mantenerte informado. El Podcast de DataFramed y nuestros seminarios web y formaciones en directo son una forma estupenda de estar al día de los temas de moda en el sector.
Reflexiones finales
Desde la sanidad y las finanzas hasta el transporte y el entretenimiento, los algoritmos de machine learning están impulsando la innovación y la eficiencia en diversos sectores. Como hemos visto, iniciarse en el machine learning requiere una sólida base en matemáticas y programación, una buena comprensión de los algoritmos de machine learning y experiencia práctica trabajando en proyectos.
Tanto si estás interesado en convertirte en un científico de datos, un ingeniero de machine learning, un especialista en IA o un científico investigador, hay una gran cantidad de oportunidades en el campo del machine learning. Con las herramientas y los recursos adecuados, cualquiera puede aprender machine learning y contribuir a este apasionante campo.
Recuerda que aprender machine learning es un viaje. Es un campo que evoluciona constantemente, por lo que es importante estar al día de los últimos avances. Sigue blogs relevantes, asiste a conferencias y participa en comunidades online para seguir aprendiendo y creciendo.
El machine learning no es sólo una palabra de moda: es una poderosa herramienta que está cambiando nuestra forma de vivir y trabajar. Al comprender qué es el machine learning, cómo funciona y cómo empezar, estarás dando el primer paso hacia un futuro en el que podrás aprovechar el poder del machine learning para resolver problemas complejos y tener un impacto real.