
El aprendizaje no supervisado, un tipo fundamental de machine learning, sigue evolucionando. Este enfoque, que se centra en vectores de entrada sin valores objetivo correspondientes, ha experimentado notables avances en su capacidad para agrupar e interpretar la información basándose en similitudes, patrones y diferencias. Los últimos avances en modelos de aprendizaje profundo no supervisado han mejorado esta capacidad, permitiendo una comprensión más matizada de conjuntos de datos complejos.
En 2024, los algoritmos de aprendizaje no supervisado, que tradicionalmente no se basan en mapeos de entrada-salida, se han vuelto aún más autónomos y eficientes a la hora de descubrir las estructuras subyacentes de los datos no etiquetados. Esta independencia de "un maestro" se ha visto reforzada por la aparición de sofisticadas técnicas deaprendizaje autosupervisado, que reducen significativamente la dependencia de los datos etiquetados.
Además, este campo ha avanzado en la integración del aprendizaje no supervisado con otras disciplinas de la IA, como el aprendizaje por refuerzo, lo que ha dado lugar a sistemas más adaptativos e inteligentes. Estos sistemas destacan en la identificación de patrones y anomalías en los datos, allanando el camino para aplicaciones innovadoras en diversos sectores. Este artículo profundiza en el aprendizaje no supervisado, explorando los distintos tipos y para qué se utilizan.
Aprendizaje supervisado vs. Aprendizaje no supervisado
En la tabla siguiente, hemos comparado algunas de las principales diferencias entre el aprendizaje no supervisado y el supervisado:
|
Aprendizaje supervisado |
Aprendizaje no supervisado |
|
|
Objetivo |
Para aproximar una función que asigna entradas a salidas a partir de pares de entrada-salida de ejemplo. |
Construir una representación concisa de los datos y generar contenidos imaginativos a partir de ellos. |
|
Precisión |
Gran precisión y fiabilidad. |
Menos preciso y fiable. |
|
Complejidad |
Método más sencillo. |
Computacionalmente complejo. |
|
Clases |
El número de clases es conocido. |
El número de clases es desconocido. |
|
Salida |
Un valor de salida deseado (también llamado señal de supervisión). |
No hay valores de salida correspondientes. |
Tipos de aprendizaje no supervisado
En la introducción, mencionamos que el aprendizaje no supervisado es un método que utilizamos para agrupar datos cuando no hay etiquetas presentes. Como no hay etiquetas, se suelen aplicar métodos de aprendizaje no supervisado para construir una representación concisa de los datos, de modo que podamos derivar de ellos un contenido imaginativo.
Por ejemplo, si lanzáramos un nuevo producto, podemos utilizar métodos de aprendizaje no supervisado para identificar quién será el mercado objetivo del nuevo producto: esto se debe a que no hay información histórica sobre quién es el cliente objetivo y sus datos demográficos.
Pero el aprendizaje no supervisado puede dividirse en tres tareas principales:
- Agrupación
- Reglas de asociación
- Reducción de la dimensionalidad.
Profundicemos en cada una de ellas:
Agrupación
Desde un punto de vista teórico, las instancias de un mismo grupo tienden a tener propiedades similares. Puedes observar este fenómeno en la tabla periódica. Los miembros de un mismo grupo, separados por dieciocho columnas, tienen el mismo número de electrones en las capas más externas de sus átomos y forman enlaces del mismo tipo.
Esta es la idea que está en juego en los algoritmos de agrupación; los métodos de agrupación consisten en agrupar datos no etiquetados basándose en sus similitudes y diferencias. Cuando dos instancias aparecen en grupos diferentes, podemos deducir que tienen propiedades distintas.
La agrupación es un tipo popular de enfoque de aprendizaje no supervisado. Incluso puedes desglosarlo aún más en distintos tipos de agrupación; por ejemplo:
- Agrupación excluyente: los datos se agrupan de forma que un único punto de datos pertenezca exclusivamente a un conglomerado.
- Agrupación solapada: un conglomerado blando en el que un único punto de datos puede pertenecer a varios conglomerados con distintos grados de pertenencia.
- Agrupación jerárquica: un tipo de agrupación en la que se crean grupos de forma que instancias similares estén dentro del mismo grupo y objetos diferentes estén en otros grupos.
- Agrupación probabilística: las agrupaciones se crean utilizando la distribución de probabilidad.
Minería de reglas de asociación
Este tipo de machine learning no supervisado adopta un enfoque basado en reglas para descubrir relaciones interesantes entre las características de un conjunto de datos determinado. Funciona utilizando una medida de interés para identificar las reglas fuertes que se encuentran en un conjunto de datos.
Normalmente, la minería de reglas de asociación se utiliza para el análisis de la cesta de la compra: se trata de una técnica de minería de datos que utilizan los minoristas para comprender mejor los patrones de compra de los clientes basándose en las relaciones entre varios productos.
El algoritmo más utilizado para el aprendizaje de reglas de asociación es el algoritmo Apriori. Sin embargo, se utilizan otros algoritmos para este tipo de aprendizaje no supervisado, como los algoritmos Eclat y FP-crecimiento.
Reducción de la dimensionalidad
Entre los algoritmos más utilizados para reducir la dimensionalidad están el análisis de componentes principales (ACP) y la descomposición de valores singulares (DVS). Estos algoritmos tratan de transformar los datos de espacios de alta dimensión a espacios de baja dimensión sin comprometer las propiedades significativas de los datos originales. Estas técnicas suelen aplicarse durante el análisis exploratorio de datos (AED) o el procesamiento de datos para preparar los datos para el modelado.
Es útil reducir la dimensionalidad de un conjunto de datos durante el AED para ayudar a visualizar los datos: esto se debe a que visualizar los datos en más de tres dimensiones es difícil. Desde el punto de vista del tratamiento de datos, reducir la dimensionalidad de los datos simplifica el problema del modelado.
Cuando se introducen más características de entrada en el modelo, éste debe aprender una función de aproximación más compleja. Este fenómeno puede resumirse con un dicho llamado "maldición de la dimensionalidad".
Aplicaciones del aprendizaje no supervisado
La mayoría de los ejecutivos no tendrían ningún problema en identificar casos de uso para tareas supervisadas de machine learning; no puede decirse lo mismo del aprendizaje no supervisado.
Una de las razones puede ser la simple naturaleza del riesgo. El aprendizaje no supervisado introduce muchos más riesgos que el aprendizaje no supervisado, ya que no hay una forma clara de medir los resultados con respecto a la verdad básica de forma offline, y puede ser demasiado arriesgado realizar una evaluación online.
No obstante, hay varios casos valiosos de uso del aprendizaje no supervisado a nivel empresarial. Además de utilizar técnicas no supervisadas para explorar datos, algunos casos de uso común en el mundo real incluyen:
- Procesamiento del lenguaje natural (PLN). Se sabe que Google Noticias aprovecha el aprendizaje no supervisado para categorizar artículos basados en la misma historia de varios medios de noticias. Por ejemplo, los resultados de la ventana de traspasos de fútbol pueden clasificarse todos en la categoría de fútbol.
- Análisis de imágenes y vídeos. Las tareas de percepción visual, como el reconocimiento de objetos, aprovechan el aprendizaje no supervisado.
- Detección de anomalías. El aprendizaje no supervisado se utiliza para identificar puntos de datos, sucesos y/u observaciones que se desvían del comportamiento normal de un conjunto de datos.
- Segmentación de clientes. Se pueden crear interesantes perfiles de personas compradoras utilizando el aprendizaje no supervisado. Esto ayuda a las empresas a comprender los rasgos comunes y los hábitos de compra de sus clientes, lo que les permite adaptar mejor sus productos.
- Motores de recomendación. El comportamiento de compra anterior, junto con el aprendizaje no supervisado, puede utilizarse para ayudar a las empresas a descubrir tendencias de datos que podrían utilizar para desarrollar estrategias eficaces de venta cruzada.
Ejemplo de aprendizaje no supervisado en Python
El análisis de componentes principales (ACP) es el proceso de calcular los componentes principales y luego utilizarlos para realizar un cambio de base en los datos. En otras palabras, el ACP es una técnica de reducción de la dimensionalidad de aprendizaje no supervisado.
Es útil reducir la dimensionalidad de un conjunto de datos por dos razones principales:
- Cuando hay demasiadas dimensiones en un conjunto de datos para visualizarlas
- Identificar las n dimensiones más predictivas para la selección de rasgos al construir un modelo predictivo.
En esta sección, implementaremos el algoritmo ACP en Python sobre el conjunto de datos Iris y luego lo visualizaremos utilizando matplotlib. Consulta este espacio de trabajo de DataCamp para seguir el código utilizado en este tutorial.
Empecemos por importar las bibliotecas necesarias y los datos.
from sklearn.datasets import load_iris # Dataset
from sklearn.decomposition import PCA # Algorithm
import matplotlib.pyplot as plt # Visualization
# Load the data
iris_data = load_iris(as_frame=True)
# Preview
iris_data.data.head()|
longitud del sépalo (cm) |
anchura del sépalo (cm) |
longitud de los pétalos (cm) |
anchura de los pétalos (cm) |
|
|
0 |
5,1 |
3,5 |
1,4 |
0,2 |
|
1 |
4,9 |
3 |
1,4 |
0,2 |
|
2 |
4,7 |
3,2 |
1,3 |
0,2 |
|
3 |
4,6 |
3,1 |
1,5 |
0,2 |
|
4 |
5 |
3,6 |
1,4 |
0,2 |
El conjunto de datos del iris tiene cuatro características. Intentar visualizar datos en cuatro dimensiones o más es imposible porque no tenemos ni idea de cómo serían las cosas en una dimensión tan alta. Lo siguiente que podríamos hacer es representarlo en tres dimensiones, lo cual no es imposible, pero sigue siendo un reto.
Por ejemplo:
"""
Credit: Rishikesh Kumar Rishi
Link: https://www.tutorialspoint.com/how-to-make-a-4d-plot-with-matplotlib-using-arbitrary-data
"""
plt.rcParams["figure.figsize"] = [7.00, 3.50]
plt.rcParams["figure.autolayout"] = True
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
sepal_length = iris_data.data["sepal length (cm)"]
sepal_width = iris_data.data["sepal width (cm)"]
petal_length = iris_data.data["petal length (cm)"]
petal_width = iris_data.data["petal width (cm)"]
ax.scatter(sepal_length, sepal_width, petal_length, c=petal_width)
plt.show()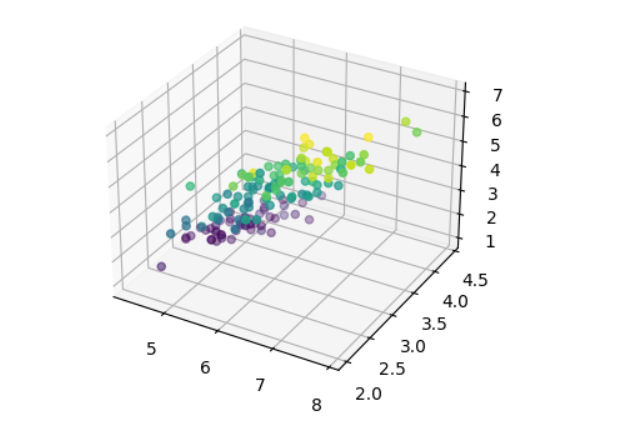
Es bastante difícil obtener información de esta visualización, porque todas las instancias están mezcladas, ya que sólo tenemos acceso a un punto de vista cuando visualizamos datos en tres dimensiones en este escenario.
Con el ACP, podemos reducir las dimensiones de los datos a dos, lo que facilitaría la visualización de nuestros datos y la distinción de las clases.
Nota: Aprende a implementar el ACP en R en "Tutorial de análisis de componentes principales en R."
# Instantiate PCA with 2 components
pca = PCA(n_components=2)
# Train the model
pca.fit(iris_data.data)
iris_data_reduced = pca.fit_transform(iris_data.data)
# Plot data
plt.scatter(
iris_data_reduced[:,0],
iris_data_reduced[:,1],
c=iris_data.target
)
plt.show()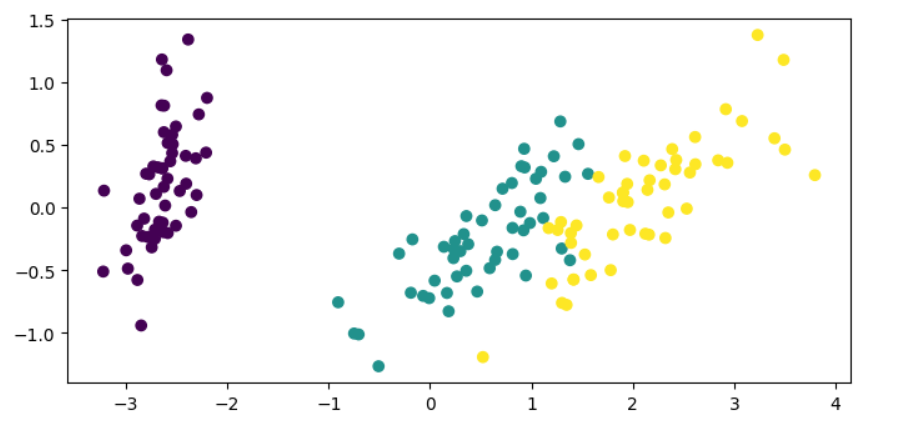
En el código anterior, transformamos las características del conjunto de datos del iris, manteniendo sólo dos componentes, y luego trazamos los datos reducidos en un plano bidimensional.
Ahora, nos resulta mucho más fácil reunir información sobre los datos y cómo se separan las clases. Podemos utilizar esta información para decidir qué pasos dar si tuviéramos que ajustar un modelo de machine learning a nuestros datos.
Reflexiones finales
El aprendizaje no supervisado se refiere a una clase de problemas en machine learning en los que se utiliza un modelo para caracterizar o extraer relaciones en los datos.
A diferencia del aprendizaje supervisado, los algoritmos de aprendizaje no supervisado descubren la estructura subyacente de un conjunto de datos utilizando sólo las características de entrada. Esto significa que los modelos de aprendizaje no supervisado no necesitan un profesor que los corrija, a diferencia de lo que ocurre en el aprendizaje supervisado.
En este artículo, has aprendido los tres tipos principales de aprendizaje no supervisado, que son la minería de reglas de asociación, la agrupación y la reducción de dimensionalidad. También aprendiste varias aplicaciones del aprendizaje no supervisado, y cómo hacer reducción de dimensionalidad utilizando el algoritmo PCA en Python.
Echa un vistazo a estos recursos para seguir formándote:
