Become an ML Scientist
What is Machine Learning?
Machine Learning, often abbreviated as ML, is a subset of artificial intelligence (AI) that focuses on the development of computer algorithms that improve automatically through experience and by the use of data. In simpler terms, machine learning enables computers to learn from data and make decisions or predictions without being explicitly programmed to do so.
At its core, machine learning is all about creating and implementing algorithms that facilitate these decisions and predictions. These algorithms are designed to improve their performance over time, becoming more accurate and effective as they process more data.
In traditional programming, a computer follows a set of predefined instructions to perform a task. However, in machine learning, the computer is given a set of examples (data) and a task to perform, but it's up to the computer to figure out how to accomplish the task based on the examples it's given.
For instance, if we want a computer to recognize images of cats, we don't provide it with specific instructions on what a cat looks like. Instead, we give it thousands of images of cats and let the machine learning algorithm figure out the common patterns and features that define a cat. Over time, as the algorithm processes more images, it gets better at recognizing cats, even when presented with images it has never seen before.
This ability to learn from data and improve over time makes machine learning incredibly powerful and versatile. It's the driving force behind many of the technological advancements we see today, from voice assistants and recommendation systems to self-driving cars and predictive analytics.
Machine learning vs AI vs deep learning
Machine learning is often confused with artificial intelligence or deep learning. Let's take a look at how these terms differ from one another. For a more in-depth look, check out our comparison guides on AI vs machine learning and machine learning vs deep learning.
AI refers to the development of programs that behave intelligently and mimic human intelligence through a set of algorithms. The field focuses on three skills: learning, reasoning, and self-correction to obtain maximum efficiency. AI can refer to either machine learning-based programs or explicitly programmed computer programs.
Machine learning is a subset of AI that uses algorithms that learn from data to make predictions. These predictions can be generated through supervised learning, where algorithms learn patterns from existing data, or unsupervised learning, where they discover general patterns in data. ML models can predict numerical values based on historical data, categorize events as true or false, and cluster data points based on commonalities.
Deep learning, on the other hand, is a subfield of machine learning dealing with algorithms based essentially on multi-layered artificial neural networks (ANN) that are inspired by the structure of the human brain.
Unlike conventional machine learning algorithms, deep learning algorithms are less linear, more complex, and hierarchical, capable of learning from enormous amounts of data, and able to produce highly accurate results. Language translation, image recognition, and personalized medicines are some examples of deep learning applications.

Comparing different industry terms
The Importance of Machine Learning
In today’s digital landscape, data fuels every major industry, and machine learning is the engine that powers this data-driven world. It is a critical technology in today's digital age, and its importance cannot be overstated. This is reflected in the industry’s projected growth, with the US Bureau of Labor Statistics predicting a 20% growth in computer and information research scientist jobs between 2024 and 2034, far outpacing the average for all occupations.
Here are some reasons why it’s so essential in the modern world:
- Data processing. One of the primary reasons machine learning is so important is its ability to handle and make sense of large volumes of data. With the explosion of digital data from social media, sensors, and other sources, traditional data analysis methods have become inadequate. Machine learning algorithms can process these vast amounts of data, uncover hidden patterns, and provide valuable insights that can drive decision-making.
- Driving innovation. Machine learning is driving innovation and efficiency across various sectors. Here are a few examples:
- Healthcare. Algorithms are used to predict disease outbreaks, personalize patient treatment plans, and improve medical imaging accuracy.
- Finance. Machine learning is used for credit scoring, algorithmic trading, and fraud detection.
- Retail. Recommendation systems, supply chains, and customer service can all benefit from machine learning.
- Other fields. The techniques used also find applications in sectors as diverse as agriculture, education, and entertainment.
- Enabling automation. Machine learning is a key enabler of automation. By learning from data and improving over time, machine learning algorithms can perform previously manual tasks, freeing humans to focus on more complex and creative tasks. This not only increases efficiency but also opens up new possibilities for innovation.
How Does Machine Learning Work?
Understanding how machine learning works involves delving into a step-by-step process that transforms raw data into valuable insights. Let's break down this process:
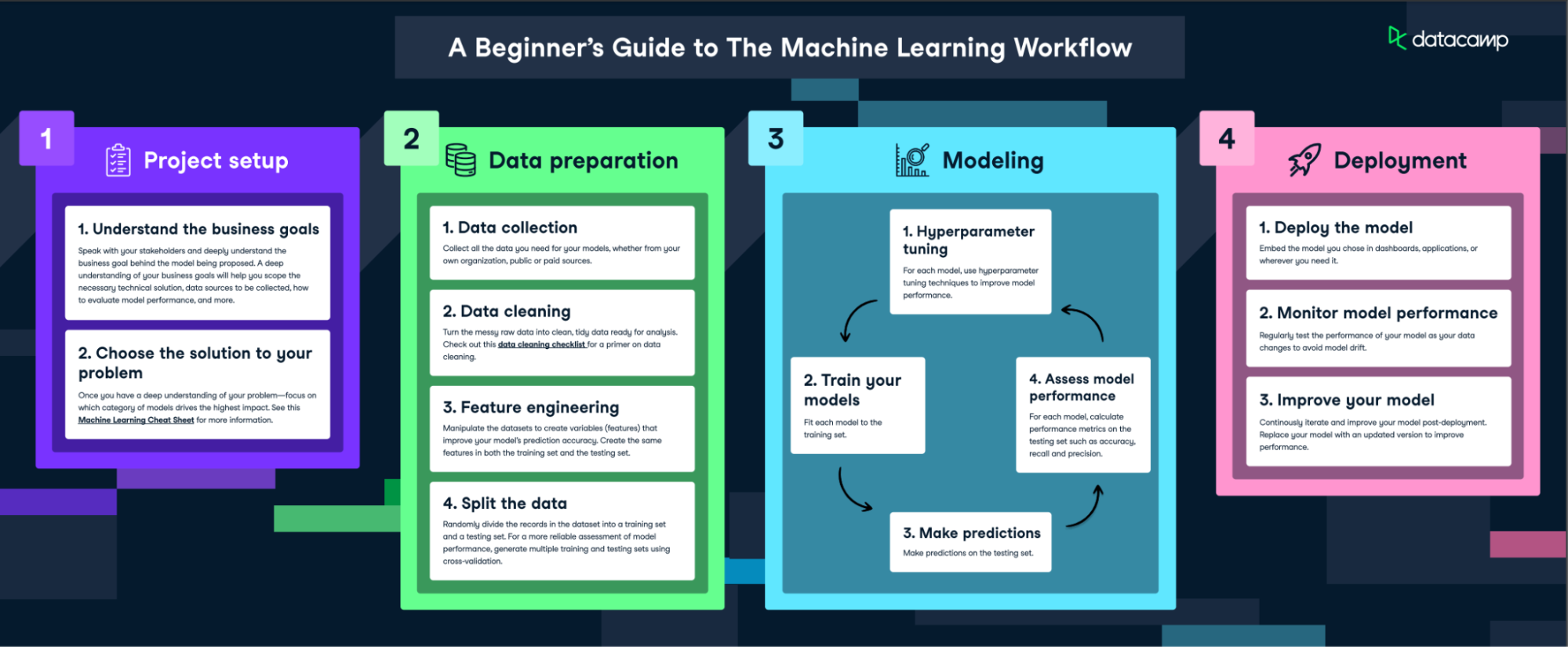
Step 1: Data collection
The first step in the machine learning process is data collection. Data is the lifeblood of machine learning - the quality and quantity of your data can directly impact your model's performance. Data can be collected from various sources such as databases, text files, images, audio files, or even scraped from the web.
Once collected, the data needs to be prepared for machine learning. This process involves organizing the data in a suitable format, such as a CSV file or a database, and ensuring that the data is relevant to the problem you're trying to solve.
Step 2: Data preprocessing
Data preprocessing is a crucial step in the machine learning process. It involves cleaning the data (removing duplicates, correcting errors), handling missing data (either by removing it or filling it in), and normalizing the data (scaling the data to a standard format).
Preprocessing improves the quality of your data and ensures that your machine learning model can interpret it correctly. This step can significantly improve the accuracy of your model. Our course, Preprocessing for Machine Learning in Python, explores how to get your cleaned data ready for modeling.
Step 3: Choosing the right model
Once the data is prepared, the next step is to choose a machine learning model. There are many types of models to choose from, including linear regression, decision trees, and neural networks. The choice of model depends on the nature of your data and the problem you're trying to solve.
Factors to consider when choosing a model include the size and type of your data, the complexity of the problem, and the computational resources available. You can read more about the different machine learning models in a separate article.
Step 4: Training the model
After choosing a model, the next step is to train it using the prepared data. Training involves feeding the data into the model and allowing it to adjust its internal parameters to better predict the output.
During training, it's important to avoid overfitting (where the model performs well on the training data but poorly on new data) and underfitting (where the model performs poorly on both the training data and new data). You can learn more about the full machine learning process in our Machine Learning Fundamentals with Python skill track, which explores the essential concepts and how to apply them.
Step 5: Evaluating the model
Once a model is trained, evaluating its performance on unseen data is essential before deployment. With MLOps, monitoring doesn’t stop at this initial stage; it involves ongoing evaluation to detect model drift (when a model’s performance declines due to changes in data patterns) and maintaining model quality over time. Continuous monitoring and retraining workflows help organizations ensure their models remain effective and reliable in production environments.
Common metrics for evaluating a model's performance include accuracy (for classification problems), precision and recall (for binary classification problems), and mean squared error (for regression problems). We cover this evaluation process in more detail in our Responsible AI webinar.
Step 6: Hyperparameter tuning and optimization
Beyond tuning for accuracy, hyperparameter optimization within an MLOps pipeline includes tools for automated hyperparameter searches, ensuring efficiency and reproducibility. Many teams employ MLOps platforms that support hyperparameter tuning, so experiments are repeatable and well-documented, allowing for consistent optimization over time.
Techniques for hyperparameter tuning include grid search (where you try out different combinations of parameters) and cross validation (where you divide your data into subsets and train your model on each subset to ensure it performs well on different data).
We have a separate article on hyperparameter optimization in machine learning models, which covers the topic in more detail.
Step 7: Predictions and deployment
Deploying a machine learning model involves integrating it into a production environment, where it can deliver real-time predictions or insights. MLOps (Machine Learning Operations) has emerged as a standard practice to streamline this process. It encompasses version control, monitoring, and automated testing to ensure models are reproducible, reliable, and robust. MLOps frameworks like MLflow or Kubeflow support these goals by providing seamless workflows for deployment, retraining, and model rollback if issues arise.
Discover more about MLOps in a separate tutorial.
Machine Learning Trends in 2026
The machine learning landscape continues to evolve rapidly. Here are the key trends shaping the field in 2026:
- Generative AI integration. Large language models (LLMs) and diffusion models are now embedded into enterprise workflows for content generation, code assistance, and data analysis. Over 80% of organizations believe generative AI will transform their operations.
- AI agents. Autonomous AI agents that can plan, reason, and execute multi-step tasks are emerging as the next frontier. The autonomous AI agent market is expected to reach $35 billion by 2030.
- Edge ML and IoT. Machine learning models are increasingly deployed on edge devices like smartphones, sensors, and IoT hardware for real-time inference with lower latency and enhanced data privacy.
- Explainable AI (XAI). As ML models are deployed in high-stakes domains like healthcare and finance, explainability has become critical. The explainable AI market is projected to reach $24.58 billion by 2030.
- MLOps maturity. Organizations are standardizing ML deployment with MLOps practices (version control, automated testing, monitoring, and model governance) to ensure production ML systems remain reliable and reproducible.
- Human-AI collaboration. The focus has shifted from replacing human work to augmenting it. ML systems increasingly serve as co-pilots that enhance human decision-making rather than operating autonomously.
Types of Machine Learning
Machine learning can be broadly classified into three types based on the nature of the learning system and the data available:
- Supervised learning
- Unsupervised learning
- Reinforcement learning
- Semi-supervised learning
- Self-supervised learning
Let's look at each of these:
Supervised learning
Supervised learning is the most common type of machine learning. In this approach, the model is trained on a labeled dataset. In other words, the data is accompanied by a label that the model is trying to predict. This could be anything from a category label to a real-valued number.
The model learns a mapping between the input (features) and the output (label) during the training process. Once trained, the model can predict the output for new, unseen data.
Common examples of supervised learning algorithms include linear regression for regression problems and logistic regression, decision trees, and support vector machines for classification problems. In practical terms, this could look like an image recognition process, wherein a dataset of images where each picture is labeled as "cat," "dog," etc., a supervised model can recognize and categorize new images accurately.
Unsupervised learning
Unsupervised learning, on the other hand, involves training the model on an unlabeled dataset. The model is left to find patterns and relationships in the data on its own.
This type of learning is often used for clustering and dimensionality reduction. Clustering involves grouping similar data points together, while dimensionality reduction involves reducing the number of random variables under consideration by obtaining a set of principal variables.
Common examples of unsupervised learning algorithms include k-means for clustering problems and Principal Component Analysis (PCA) for dimensionality reduction problems. Again, in practical terms, in the field of marketing, unsupervised learning is often used to segment a company's customer base. By examining purchasing patterns, demographic data, and other information, the algorithm can group customers into segments that exhibit similar behaviors without any pre-existing labels.
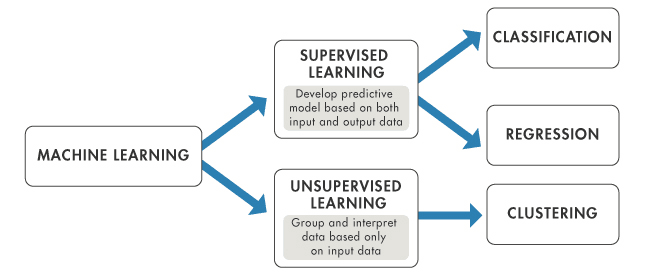
Comparing supervised and unsupervised learning
Reinforcement learning
Reinforcement learning is a type of machine learning where an agent learns to make decisions by interacting with its environment. The agent is rewarded or penalized (with points) for the actions it takes, and its goal is to maximize the total reward.
Unlike supervised and unsupervised learning, reinforcement learning is particularly suited to problems where the data is sequential, and the decision made at each step can affect future outcomes.
Common examples of reinforcement learning include game playing, robotics, resource management, and many more.
Semi-supervised and self-supervised learning
Beyond the three main types, two additional approaches have become increasingly important in modern machine learning:
Semi-supervised learning combines a small amount of labeled data with a large amount of unlabeled data during training. This approach is practical because labeling data is often expensive and time-consuming, while unlabeled data is abundant. It bridges the gap between supervised and unsupervised learning.
Self-supervised learning has become a cornerstone of modern AI, powering large language models (LLMs) and foundation models. In this approach, the model generates its own labels from the input data (for example, predicting masked words in a sentence or the next frame in a video). This technique enabled breakthroughs like GPT and other transformer-based models that form the basis of today’s generative AI applications.
Understanding the Impact of Machine Learning
In 2026, machine learning is a key driver in diverse fields like healthcare, finance, and climate science. With generative AI now deeply integrated into enterprise workflows, marketing teams create personalized content at scale, while healthcare providers use ML for early disease diagnosis and treatment personalization. The global ML market reached over $91 billion in 2025 and is projected to grow to $1.88 trillion by 2035, reflecting the technology's rapid adoption across industries. Amid these advancements, regulatory bodies are increasingly focused on ethical standards and data privacy, ensuring ML continues to evolve responsibly.
Let's explore some of these impacts:
“Machine learning is the most transformative technology of our time. It’s going to transform every single vertical.”
- Satya Nadella, CEO at Microsoft
Healthcare
Machine learning is revolutionizing healthcare by enhancing diagnostic accuracy and personalizing treatment plans. For instance, Google has developed medical AI models like Med-Gemini, large language models fine-tuned for medical applications that assist clinicians in interpreting complex medical information, thereby improving patient care. You can read more about AI in healthcare in our separate guide.
Finance
In the financial sector, machine learning is integral to fraud detection and risk management. Major banks like JPMorgan have developed AI-based chatbots to assist asset and wealth management employees, streamlining operations and enhancing client interactions. We have a separate guide about AI in finance which explores the potential in greater detail.
Transportation
Machine learning is at the heart of the self-driving car revolution. Companies like Tesla and Waymo use machine learning algorithms to interpret sensor data in real-time, allowing their vehicles to recognize objects, make decisions, and navigate roads autonomously. Similarly, the Swedish Transport Administration recently started working with computer vision and machine learning specialists to optimize the country’s road infrastructure management.
Some Applications of Machine Learning
Machine learning applications are all around us, often working behind the scenes to enhance our daily lives. Here are some real-world examples:
Recommendation systems
Recommendation systems are one of the most visible applications of machine learning. Companies like Netflix and Amazon use machine learning to analyze your past behavior and recommend products or movies you might like. Learn how to build a recommendation engine in Python with our online course.
Voice assistants
Voice assistants like Siri, Alexa, and Google Assistant use machine learning to understand your voice commands and provide relevant responses. They continually learn from your interactions to improve their performance.
Fraud detection
Banks and credit card companies use machine learning to detect fraudulent transactions. By analyzing patterns of normal and abnormal behavior, they can flag suspicious activity in real-time. We have a fraud detection in Python course, which explores the concept in more detail.
Social media
Social media platforms use machine learning for a variety of tasks, from personalizing your feed to filtering out inappropriate content.
Generative AI and large language models
Machine learning also powers generative AI applications that can create text, images, code, and audio. Large language models (LLMs) like GPT-4 and open-source alternatives use deep learning architectures called transformers to generate human-like content. These models have rapidly moved from research novelties to production tools used across industries for content creation, code generation, customer service, and data analysis.

Our machine learning cheat sheet covers different algorithms and their uses
Machine Learning Tools
In the world of machine learning, having the right tools is just as important as understanding the concepts. These tools, which include programming languages and libraries, provide the building blocks to implement and deploy machine learning algorithms. Let's explore some of the most popular tools in machine learning:
Python for machine learning
Python is a popular language for machine learning due to its simplicity and readability, making it a great choice for beginners. It also has a strong ecosystem of libraries that are tailored for machine learning.
Libraries such as NumPy and Pandas are used for data manipulation and analysis, while Matplotlib is used for data visualization. Scikit-learn provides a wide range of machine learning algorithms, and TensorFlow and PyTorch are used for building and training neural networks. PyTorch is particularly popular among researchers, and PyTorch 2.x introduced torch.compile for significant speed improvements along with enhanced ease of use
Python remains the dominant language in machine learning, but it’s worth emphasizing its versatility across fields with libraries like:
- Hugging Face Transformers for natural language processing (NLP) and generative AI.
- LangChain for building language model-based applications.
- JAX for high-performance numerical computation and ML research at scale.
Resources to get you started
- Machine Learning Fundamentals with Python Skill Track
- Machine Learning Scientist with Python Career Track
- Introduction to Machine Learning in Python Tutorial
- How Transformers Work Tutorial
- Developing LLM Applications with LangChain course
R for machine learning
R is another language widely used in machine learning, particularly for statistical analysis. It has a rich ecosystem of packages that make it easy to implement machine learning algorithms.
Packages like caret, mlr, and randomForest provide a variety of machine learning algorithms, from regression and classification to clustering and dimensionality reduction.
Resources to get you started
- Machine Learning Fundamentals in R Skill Track
- Machine Learning Scientist with R Career Track
- Machine Learning in R for Beginners Tutorial
TensorFlow
TensorFlow is a powerful open-source library for numerical computation, particularly well-suited for large-scale machine learning. It was developed by the Google Brain team and supports both CPUs and GPUs.
TensorFlow allows you to build and train complex neural networks, making it a popular choice for deep learning applications.
Resources to get you started
- Introduction to TensorFlow in Python Course
- TensorFlow Tutorial For Beginners
- Python Convolutional Neural Networks (CNN) with TensorFlow Tutorial
Scikit-learn
Scikit-learn is a Python library that provides a wide range of machine learning algorithms for both supervised and unsupervised learning. It's known for its clear API and detailed documentation.
Scikit-learn is often used for data mining and data analysis, and it integrates well with other Python libraries like NumPy and Pandas.
Resources to get you started
- Machine Learning with scikit-learn Course | DataCamp
- Supervised Learning with scikit-learn Course | DataCamp
- Python Machine Learning: Scikit-Learn Tutorial
- Scikit-Learn Cheat Sheet: Python Machine Learning
Keras
Keras is a high-level neural networks API, written in Python and now fully integrated into TensorFlow as its official high-level API. It was developed with a focus on enabling fast experimentation.
Keras provides a user-friendly interface for building and training neural networks, making it a great choice for beginners in deep learning. Since Keras is now part of TensorFlow (as tf.keras), learning Keras also means learning TensorFlow’s high-level API.
Resources to get you started
- Introduction to Deep Learning with Keras Course
- Advanced Deep Learning with Keras Course
- Keras Tutorial: Deep Learning in Python
- Keras Cheat Sheet: Neural Networks in Python
PyTorch
PyTorch is an open-source machine learning library based on the Torch library. It's known for its flexibility and efficiency, making it popular among researchers.
PyTorch supports a wide range of applications, from computer vision to natural language processing. One of its key features is the dynamic computational graph, which allows for flexible and optimized computation.
Resources to get you started
- Introduction to Deep Learning in PyTorch Course
- Deep Learning with PyTorch Course
- PyTorch Tutorial: Building a Simple Neural Network From Scratch
- PyTorch 2.0: Unveiling the Latest Updates and Insights with Code Examples
The Top Machine Learning Careers in 2026
Machine learning has opened up a wide range of career opportunities. From data science to AI engineering, professionals with machine learning skills are in high demand. Let's explore some of these career paths:
Data scientist
A data scientist uses scientific methods, processes, algorithms, and systems to extract knowledge and insights from structured and unstructured data. Machine learning is a key tool in a data scientist's arsenal, allowing them to make predictions and uncover patterns in data.
Key skills:
- Statistical analysis
- Programming (Python, R)
- Machine learning
- Data visualization
- Problem-solving
Essential tools:
- Python
- R
- SQL
- Hadoop
- Spark
- Tableau
Machine learning engineer
A machine learning engineer designs and implements machine learning systems. They run machine learning experiments using programming languages like Python and R, work with datasets, and apply machine learning algorithms and libraries.
Key skills:
- Programming (Python, Java, R)
- Machine learning algorithms
- Statistics
- System design
Essential tools:
- Python
- TensorFlow
- Scikit-learn
- PyTorch
- Keras
- MLflow, Kubeflow, Docker, and Kubernetes for scalable model deployment.
Research scientist
A research scientist in machine learning conducts research to advance the field of machine learning. They work in both academic and industry settings, developing new algorithms and techniques.
Key skills:
- Deep understanding of machine learning algorithms
- Programming (Python, R)
- Research methodology
- Strong mathematical skills
Essential tools:
- Python
- R
- TensorFlow
- PyTorch
- MATLAB
- Hugging Face Model Hub
AI engineer
An AI engineer focuses on integrating AI models—particularly large language models and generative AI—into production applications. This emerging role bridges the gap between model development and end-user products.
Key skills:
- Prompt engineering and LLM fine-tuning
- API integration and system design
- Python and ML frameworks
- RAG (Retrieval-Augmented Generation) pipelines
Essential tools:
- LangChain, LlamaIndex
- OpenAI API, Hugging Face
- Vector databases (Pinecone, Weaviate)
- Docker, cloud platforms (AWS, GCP, Azure)
If becoming an AI engineer is a path you want to pursue, I highly recommend enrolling in our Associate AI Engineer for Data Scientists career track.
|
Career |
Key Skills |
Essential Tools |
|
Data Scientist |
Statistical analysis, Programming (Python, R), Machine learning, Data visualization, Problem-solving |
Python, R, SQL, Hadoop, Spark, Tableau, |
|
Machine Learning Engineer |
Programming (Python, Java, R), Machine learning algorithms, Statistics, System design |
Python, TensorFlow, Scikit-learn, PyTorch, Keras, MLflow, Kubeflow, Docker, Kubernetes |
|
Research Scientist |
Deep understanding of machine learning algorithms, Programming (Python, R), Research methodology, Strong mathematical skills |
Python, R, TensorFlow, PyTorch, MATLAB, Hugging Face Model Hub |
How to Get Started in Machine Learning
Starting a journey in machine learning can seem daunting, but with the right approach and resources, anyone can learn this exciting field. Here are some steps to get you started:
Understand the basics
Before diving into machine learning, it's important to have a strong foundation in mathematics (especially statistics and linear algebra) and programming (Python is a popular choice due to its simplicity and the availability of machine learning libraries).
There are many resources available to learn these basics. Online platforms like Khan Academy and Coursera offer courses in mathematics and programming. Books like "Think Stats" and "Python Crash Course" are also good starting points.
Choose the right tools
Choosing the right tools is crucial in machine learning. Python, along with libraries like NumPy, Pandas, and Scikit-learn, is a popular choice due to its simplicity and versatility.
To get started with these tools, you can follow online tutorials or take courses on platforms like DataCamp. Our Machine Learning Fundamentals skills track is the ideal place to start.
Learn machine learning algorithms
Once you're comfortable with the basics, you can start learning about machine learning algorithms. Start with simple algorithms like linear regression and decision trees before moving on to more complex ones like neural networks.
Work on projects
Working on projects is a great way to gain practical experience and reinforce what you've learned. Start with simple projects like predicting house prices or classifying iris species, and gradually take on more complex projects. We have an article exploring 25 machine learning projects for all levels, which can help you find something appropriate.
Stay up-to-date
Machine learning is a rapidly evolving field, so it's important to stay up-to-date with the latest developments. Following relevant blogs, attending conferences, and participating in online communities can help you stay informed. The DataFramed Podcast and our webinars and live trainings are a great way to keep up with trending topics in the industry.
Final Thoughts
From healthcare and finance to transportation and entertainment, machine learning algorithms are driving innovation and efficiency across various sectors. As we've seen, getting started in machine learning requires a strong foundation in mathematics and programming, a good understanding of machine learning algorithms, and practical experience working on projects.
Whether you're interested in becoming a data scientist, a machine learning engineer, an AI specialist, or a research scientist, there's a wealth of opportunities in the field of machine learning. With the right tools and resources, anyone can learn machine learning and contribute to this exciting field.
Remember, learning machine learning is a journey. It's a field that's constantly evolving, so it's important to stay up-to-date with the latest developments. Follow relevant blogs, attend conferences, and participate in online communities to keep learning and growing.
Machine learning is not just a buzzword - it's a powerful tool that's changing the way we live and work. By understanding what machine learning is, how it works, and how to get started, you're taking the first step towards a future where you can harness the power of machine learning to solve complex problems and make a real impact.
Get started with machine learning today with our Machine Learning Fundamentals in Python skill track!

