
Curso
Introducción a la ciencia de datos con Python
4 h
498.3K

El ingeniero de datos desarrolla, construye, prueba y mantiene arquitecturas como bases de datos y sistemas de procesamiento a gran escala. El científico de datos, en cambio, limpia, masajea y organiza los (grandes) datos.
Puede que la elección del verbo "masajear" te parezca especialmente exótica, pero sólo refleja aún más la diferencia entre ingenieros de datos y científicos de datos.
En general, los esfuerzos que ambas partes tendrán que hacer para obtener los datos en un formato utilizable son considerablemente diferentes.
Los ingenieros de datos tratan con datos brutos que contienen errores humanos, de máquinas o de instrumentos. Los datos podrían no estar validados y contener registros sospechosos. No tendrá formato y puede contener códigos específicos del sistema.
Los ingenieros de datos tendrán que recomendar y, a veces, aplicar formas de mejorar la fiabilidad, eficacia y calidad de los datos. Para ello, tendrán que emplear diversos lenguajes y herramientas para casar los sistemas entre sí o cazar oportunidades para adquirir nuevos datos de otros sistemas, de modo que los códigos específicos del sistema, por ejemplo, puedan convertirse en información para su posterior procesamiento por parte de los científicos de datos.
Muy estrechamente relacionado con estos dos aspectos está el hecho de que los ingenieros de datos tendrán que asegurarse de que la arquitectura que se establezca sea compatible con los requisitos de los científicos de datos, las partes interesadas y la empresa.
Por último, el equipo de ingeniería de datos tendrá que desarrollar procesos de conjunto de datos para el modelado, la minería y la producción de datos, a fin de entregar los datos al equipo de ciencia de datos.
Descubre más sobre lo que hace un ingeniero de datos en nuestro artículo completo.

Por lo general, los científicos de datos ya obtienen datos que han superado una primera ronda de limpieza y manipulación, que pueden utilizar para alimentar programas de análisis sofisticados y métodos estadísticos y de aprendizaje automático para preparar los datos para su uso en modelos predictivos y prescriptivos. Por supuesto, para construir modelos, necesitan investigar sobre cuestiones industriales y empresariales, y tendrán que aprovechar grandes volúmenes de datos de fuentes internas y externas para responder a las necesidades empresariales. Esto también implica a veces explorar y examinar los datos para encontrar patrones ocultos.
Una vez que los científicos de datos hayan realizado los análisis, tendrán que presentar una historia clara a las principales partes interesadas. Cuando se acepten los resultados, tendrán que asegurarse de que el trabajo se automatiza para que los conocimientos puedan entregarse a las partes interesadas de la empresa diaria, mensual o anualmente.
Está claro que ambas partes tienen que trabajar juntas para manejar los datos y proporcionar información que permita tomar decisiones críticas para la empresa. Existe un claro solapamiento de competencias, pero ambas se están diferenciando gradualmente en el sector: mientras que el ingeniero de datos trabajará con sistemas de bases de datos, API de datos y herramientas para fines de ETL y participará en el modelado de datos y la creación de soluciones de almacén de datos, el científico de datos necesita saber de estadística, matemáticas y aprendizaje automático para crear modelos predictivos.
El científico de datos debe conocer la informática distribuida, ya que necesitará acceder a los datos procesados por el equipo de ingeniería de datos. También tendrá que ser capaz de informar a las partes interesadas de la empresa, por lo que es esencial centrarse en la narración y la visualización.
Lo que esto significa en términos de enfoque en los pasos del flujo de trabajo de la ciencia de datos, puedes verlo en la imagen de abajo:

Por supuesto, esta diferencia de competencias se traduce en diferencias en los idiomas, las herramientas y el software que ambos utilizan. El siguiente resumen incluye alternativas comerciales y de código abierto.
Aunque las herramientas utilizadas por ambas partes dependen en gran medida de cómo se conciba el papel en el contexto de la empresa, los ingenieros de datos suelen trabajar con herramientas como SAP, Oracle, Cassandra, MySQL, Redis, Riak, PostgreSQL, MongoDB, Neo4j, Hive y Sqoop.
Los científicos de datos utilizarán lenguajes como SPSS, R, Python, SAS, Stata y Julia para construir modelos. Las herramientas más populares aquí son, sin duda, Python y R. Cuando trabajes con Python y R para la ciencia de datos, lo más habitual es que recurras a paquetes como ggplot2 para hacer asombrosas visualizaciones de datos en R o a la biblioteca de manipulación de datos de Python Pandas. Por supuesto, hay muchos más paquetes que te resultarán útiles cuando trabajes en proyectos de ciencia de datos, como scikit-learn, NumPy, Matplotlib, Statsmodels, etc.
En la industria, también encontrarás que las comerciales SAS y SPSS funcionan bien, pero otras herramientas como Tableau, Rapidminer, Matlab, Excel y Gephi se abrirán camino en la caja de herramientas del científico de datos.
Vuelves a ver que una de las principales distinciones entre los ingenieros de datos y los científicos de datos, el énfasis en la visualización de datos y la narración de historias, se refleja en las herramientas mencionadas.
Como ya habrás adivinado, Scala, Java y C # son herramientas, lenguajes y software que ambas partes tienen en común.

Estos lenguajes no son necesariamente populares entre los científicos de datos y los ingenieros. Se podría argumentar que Scala es más popular entre los ingenieros de datos porque su integración con Spark es especialmente práctica para configurar grandes flujos ETL.
Lo mismo ocurre con el lenguaje Java: por el momento, su popularidad va en aumento entre los científicos de datos, pero en general, no es muy utilizado a diario por los profesionales. Pero, en general, verás que estas lenguas aparecen en las ofertas de trabajo para ambos puestos. Lo mismo puede decirse de las herramientas que ambas partes podrían tener en común, como Hadoop, Storm y Spark.
Por supuesto, la comparación en herramientas, lenguajes y software debe verse en el contexto específico en el que se trabaja y cómo se interpretan las funciones de la ciencia de datos en cuestión; la ciencia de datos y la ingeniería de datos pueden estar estrechamente unidas en algunos casos concretos, en los que la distinción entre los equipos de ciencia de datos y de ingeniería de datos es, de hecho, tan pequeña que, a veces, los dos equipos se fusionan.
Si esto es una gran idea o no, es material suficiente para otro debate, que queda fuera del ámbito del blog de hoy.
Además de todo esto, los científicos de datos y los ingenieros de datos también pueden tener algo en común: su formación en informática. Esta zona de estudio es muy popular para ambas profesiones. Por supuesto, también verás que los científicos de datos a menudo han estudiado econometría, matemáticas, estadística e investigación operativa. A menudo tienen un poco más de visión empresarial que los ingenieros de datos. A menudo ves que los ingenieros de datos también proceden de la ingeniería; lo más frecuente es que hayan tenido algún tipo de formación previa en ingeniería informática.
Sin embargo, esto no significa que no encuentres ingenieros de datos que hayan adquirido conocimientos sobre operaciones y visión empresarial en estudios anteriores.

Tienes que darte cuenta de que, en general, el sector de la ciencia de datos está formado por profesionales que proceden de distintos ámbitos: no es raro que físicos, biólogos o meteorólogos encuentren su camino en la ciencia de datos. Otros han cambiado de carrera a la ciencia de datos y proceden del desarrollo web, la administración de bases de datos, etc.
En EE.UU., el salario medio anual de los científicos de datos es de 123.069 $, con un rango de 78.000 a 194.000 $. En los distintos países, la tendencia es similar, y el salario medio de los científicos de datos es al menos un 30% superior a la media nacional (¡y en la India, esta cifra es significativamente superior!).
El salario medio anual de los ingenieros de datos en EE.UU.es de 125.686 $; en otros países, el salario medio es muy similar al de un científico de datos.
Ambas funciones están muy solicitadas. En el momento de escribir estas líneas, Indeed enumera más de 10.000 puestos de científico de datos y más de 5.000 de ingeniero de datos en Estados Unidos. Empresas líderes como Spotify, Meta, Amazon, Google y Microsoft casi siempre contratan para ambos puestos.

Como se ha descrito antes, la creación de funciones y títulos es necesaria para reflejar las necesidades cambiantes, pero otras veces se crean como forma de diferenciarse de otras empresas de contratación.
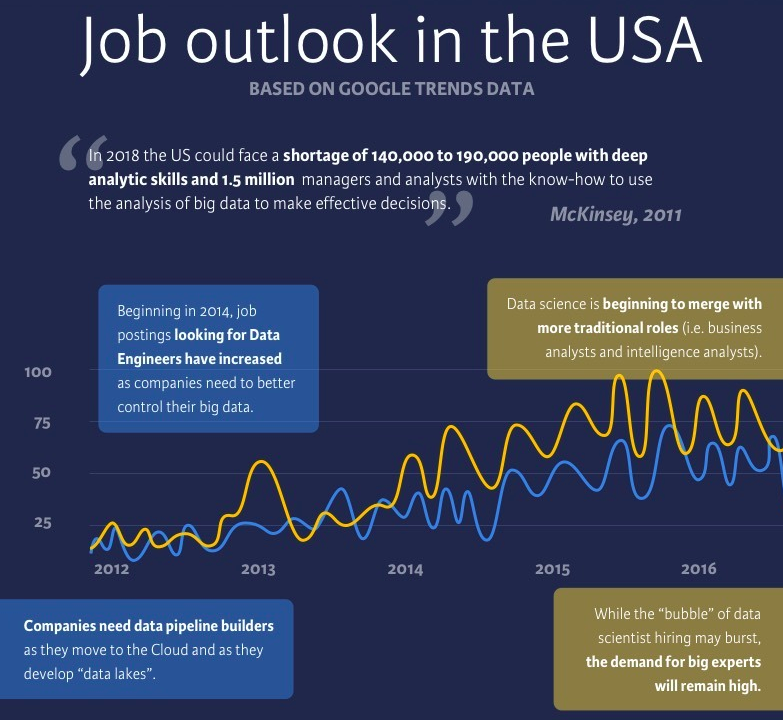
Además del aumento del interés por las cuestiones relacionadas con la gestión de datos, las empresas buscan soluciones más baratas, flexibles y escalables para almacenar y gestionar sus datos. Quieren trasladar sus datos a la Nube y, para ello, necesitan construir "lagos de datos" que complementen los almacenes de datos que ya tienen instalados o sustituyan al Almacén de Datos Operativos (ODS).
Los flujos de datos tendrán que ser reorientados y sustituidos en los próximos años, y como resultado, la atención y el número de ofertas de empleo para contratar ingenieros de datos ha aumentado gradualmente a lo largo de los años.
El papel de científico de datos ha estado en demanda desde el principio del bombo, pero hoy en día, las empresas buscan componer equipos de ciencia de datos en lugar de contratar científicos de datos unicornios que posean habilidades de comunicación, creatividad, ingenio, curiosidad, conocimientos técnicos, etc. Para los reclutadores, es difícil encontrar personas que encarnen todas las cualidades que buscan las empresas, y la demanda supera claramente a la oferta.
Se podría argumentar que la "burbuja de los científicos de datos" ha estallado. O tal vez estaba a punto de estallar hasta que los avances de la IA como la GPT-3 y la GPT-4 tomaron el mundo por asalto.
Una cosa permanecerá constante a lo largo de todo esto: la demanda de expertos apasionados por los temas de la ciencia de datos siempre existirá. Las perspectivas laborales para estos expertos son muy positivas. Por ejemplo, la Oficina de Estadísticas Laborales de EE.UU. prevé 20.800 vacantes de científicos de datos al año durante la próxima década, con un crecimientoprevisto del 36% de 2023 a 2033, mucho más rápido que la media de todas las ocupaciones. Las perspectivas son igualmente alcistas en para las vacantes de ingeniero de datos.
| Aspecto | Científico de datos | Ingeniero de datos | Similitudes |
|---|---|---|---|
| Enfoque principal | Analizar e interpretar los datos para obtener información | Construir y mantener la infraestructura de datos | Trabajar con datos para facilitar la toma de decisiones |
| Responsabilidades | Modelización, análisis estadístico y narración de historias | Creación de canalizaciones de datos, procesos ETL y almacenamiento de datos | Colabora para garantizar que los datos estén limpios, sean accesibles y utilizables |
| Competencias básicas | Aprendizaje automático, estadística, visualización | Arquitectura de datos, gestión de bases de datos y herramientas en la nube | Competencia en programación y manejo de conjuntos de datos a gran escala |
| Herramientas y software | Python, R, TensorFlow, PyTorch, Tableau, Power BI | Python, Apache Spark, Kafka, Airflow, dbt, Snowflake, Databricks | Uso compartido de herramientas como Spark, Hadoop y SQL |
| Lenguajes de programación | Python, R, SQL | Python, SQL, Scala, Java | El dominio de Python y SQL es valioso tanto para |
| Tratamiento de datos | Se centra en la manipulación de datos y la formación de modelos utilizando herramientas como Pandas, NumPy | Diseña tuberías ETL robustas con Apache Spark, Apache Flink | Colaborar a menudo en los procesos de preparación de datos |
| Visualización | Hace hincapié en la narración de datos mediante Tableau, Power BI, Matplotlib | La visualización puede producirse durante la validación de los datos, pero no es un objetivo principal | Puede utilizar herramientas compartidas como Looker para elaborar informes |
| Formación académica | Estadística, matemáticas, informática | Informática, ingeniería de datos, ingeniería de software | Formación compartida en disciplinas técnicas como la informática |
| Salario (media de EE.UU.) | ~123.000 $/año | ~125.000 $/año | Salarios competitivos y gran demanda en ambas funciones |
| Perspectivas laborales | Creciente atención a la extracción de información procesable y a la IA | Necesidad creciente de sistemas de gestión de datos robustos y escalables | Fuerte crecimiento de las industrias basadas en datos |
Si quieres trazar tu camino para iniciar una carrera en cualquiera de los dos puestos, nuestras guías son un buen punto de partida:
Si quieres entrar directamente en tu viaje de aprendizaje, DataCamp te tiene cubierto. Tenemos muchos cursos ideales si quieres empezar a aprender ingeniería de datos. Por ejemplo, los cursos Importar datos en Python y Importar datos en R de DataCamp. Nuestra Certificación de Ingeniero de Datos es otra gran opción para demostrar a los responsables de contratación que tienes las aptitudes necesarias para un puesto de nivel inicial.
Para quienes quieran iniciarse en la ciencia de datos, están los cursos Análisis Exploratorio de Datos, Introducción a R para la Ciencia de Datos, Caja de Herramientas de Aprendizaje Automático e Introducción a Python para la Ciencia de Datos. Asimismo, nuestra Certificación de Científico de Datos goza de gran prestigio y te ayudará a entrar en empresas líderes.
¡Aprende más sobre ciencia de datos e ingeniería de datos con estos cursos!
Curso
Curso
Curso
blog
Joleen Bothma
11 min
blog
Abid Ali Awan
15 min
blog
Matt Crabtree
15 min
blog
Jose Jorge Rodriguez Salgado
12 min
blog
Artur Sannikov
12 min
blog
Javier Canales Luna
8 min

