Curso
Machine learning con modelos basados en árboles en Python
5 h
116.5K
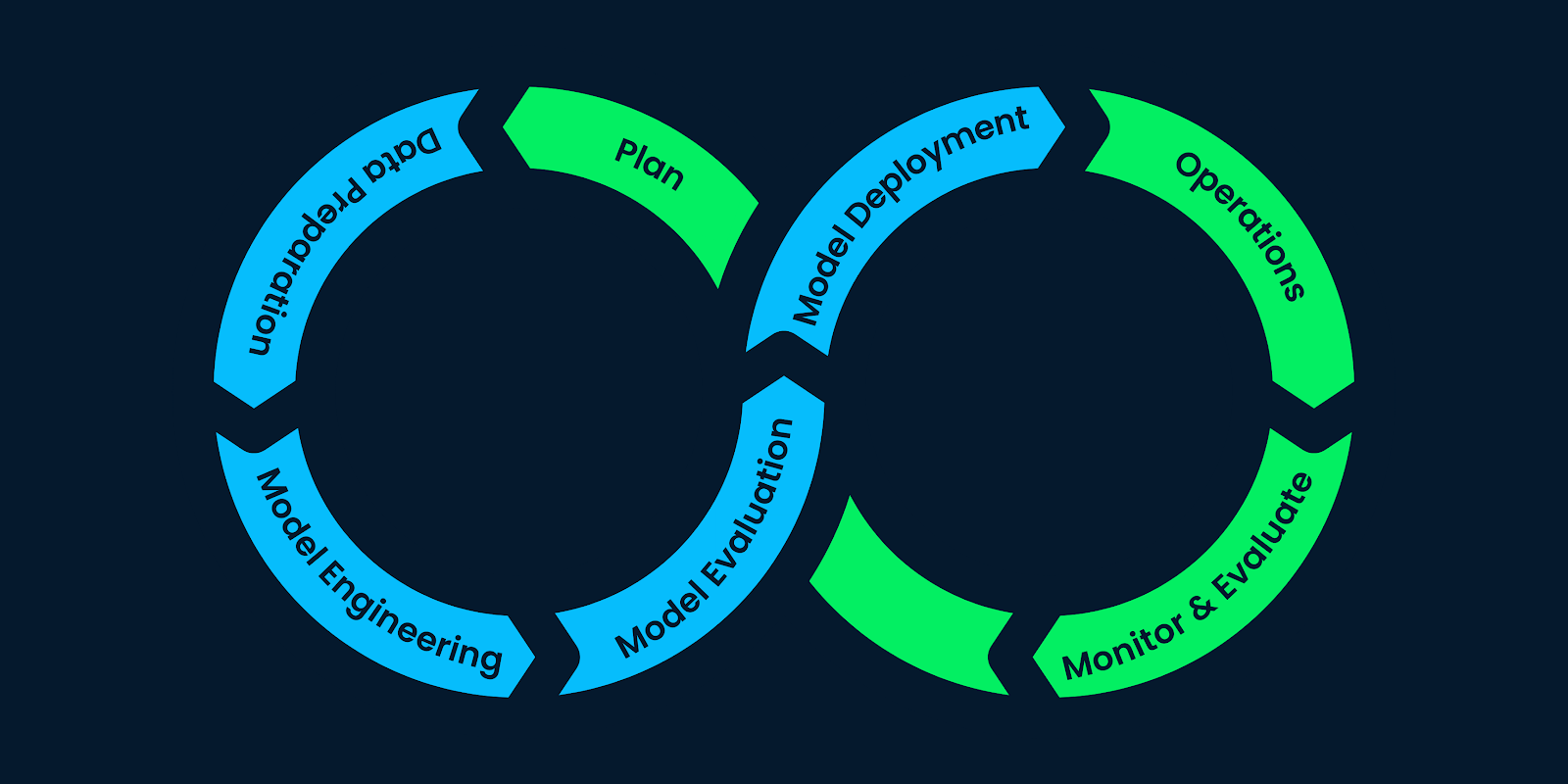
Solemos pensar que los proyectos de machine learning (ML) implican procesamiento de datos, y entrenamiento e implementación de modelos. Pero son mucho más que eso.
Necesitamos comprensión del negocio y de los datos, técnicas de recopilación de datos, análisis de datos, construcción de modelos y evaluación de modelos. Además, tras la implementación, necesitamos una supervisión y un mantenimiento constantes.
El ciclo de vida del machine learning consta de pasos que proporcionan estructura al proyecto de machine learning y dividen eficazmente los recursos de la empresa. Seguir estos pasos ayuda a las empresas a crear productos de IA sostenibles, rentables y de calidad.
En este post, utilizaremos el Cross-Industry Standard Process (CRISP) para el desarrollo de aplicaciones de machine learning con metodología de garantía de calidad (CRISP-ML(Q)) para explicar cada paso del ciclo de vida del machine learning. CRISP-ML(Q) es una norma industrial para crear aplicaciones sostenibles de machine learning.
Cada fase del ciclo de machine learning sigue un marco de garantía de calidad para la mejora y el mantenimiento constantes, siguiendo estrictamente los requisitos y las limitaciones. Aprende más sobre la garantía de calidad leyendo el blog CRISP-ML(Q).
Para personas no técnicas y directivos, consulta nuestro breve curso sobre Comprensión de los fundamentos del machine learning. Les ayudará a comprender el machine learning en general, el modelado y el aprendizaje profundo (IA). También puedes explorar las diferencias entre IA y machine learning en otro artículo.

Imagen del autor
La fase de planificación implica evaluar el alcance, la métrica de éxito y la viabilidad de la aplicación del ML. Tienes que entender el negocio y cómo utilizar el machine learning para mejorar el proceso actual. Por ejemplo: ¿necesitamos machine learning? ¿Podemos conseguir peticiones similares con una programación sencilla?
También tienes que comprender el análisis coste-beneficio y cómo enviarás la solución en varias fases. Además, tienes que definir métricas de éxito claras y mensurables para el negocio, los modelos de machine learning (precisión, puntuación F1, AUC) y económicas (indicadores clave de rendimiento).
Por último, tienes que crear un informe de viabilidad.
Consistirá en la información sobre:
Los líderes empresariales pueden aprender los fundamentos del machine learning realizando un curso de Machine learning para empresas y aplicando estas lecciones para crear estrategias empresariales e implantar soluciones de ML.
 Imagen del autor
Imagen del autor
La sección de preparación de datos se divide a su vez en cuatro partes: obtención y etiquetado de datos, limpieza, gestión y procesamiento.
Primero tenemos que decidir cómo vamos a recopilar los datos: recopilando los datos internos, de código abierto, comprándolos a los vendedores o generando datos sintéticos. Cada método tiene pros y contras, y en algunos casos, obtenemos los datos de las cuatro metodologías.
Tras la recogida, tenemos que etiquetar los datos. Comprar datos limpios y etiquetados no es factible para todas las empresas, y también puede que tengas que hacer cambios en la selección de datos durante el proceso de desarrollo. Por eso no puedes comprarlos al por mayor y los datos pueden acabar siendo inútiles para la solución.
La recogida de datos y el etiquetado requieren la mayor parte de los recursos de la empresa: dinero, tiempo, profesionales, expertos en la materia y acuerdos legales.
A continuación, limpiaremos los datos imputando los valores que faltan, analizando los datos mal etiquetados, eliminando los valores atípicos y reduciendo el ruido. Crearás una canalización de datos para automatizar este proceso y realizar la verificación de la calidad de los datos.
La etapa de procesamiento de datos implica la selección de características, el tratamiento de las clases desequilibradas, la ingeniería de características, el aumento de datos y la normalización y escalado de los datos.
Para la reproducibilidad, almacenaremos y versionaremos los metadatos, el modelado de datos, las canalizaciones de transformación y los almacenes de características.
Por último, descubriremos soluciones de almacenamiento de datos, versionado de datos para su reproducibilidad, almacenamiento de metadatos y creación de canalizaciones ETL. Esta parte garantizará un flujo constante de datos para el entrenamiento del modelo.

Imagen del autor
En esta fase, utilizaremos toda la información de la fase de planificación para construir y entrenar un modelo de machine learning. Por ejemplo: seguimiento de las métricas del modelo, garantía de escalabilidad y robustez, y optimización de los recursos de almacenamiento y computación.
Nos centraremos en la arquitectura de los modelos, la calidad del código, los experimentos de machine learning, el entrenamiento de los modelos y el ensamblaje.
Las características, los hiperparámetros, los experimentos de ML, la arquitectura del modelo, el entorno de desarrollo y los metadatos se almacenan y versionan para su reproducibilidad.
Conoce los pasos que hay que dar en la ingeniería de modelos siguiendo el programa de carrera Científico de machine learning con Python. Te ayudará a dominar las habilidades necesarias para conseguir un trabajo como ingeniero de machine learning.
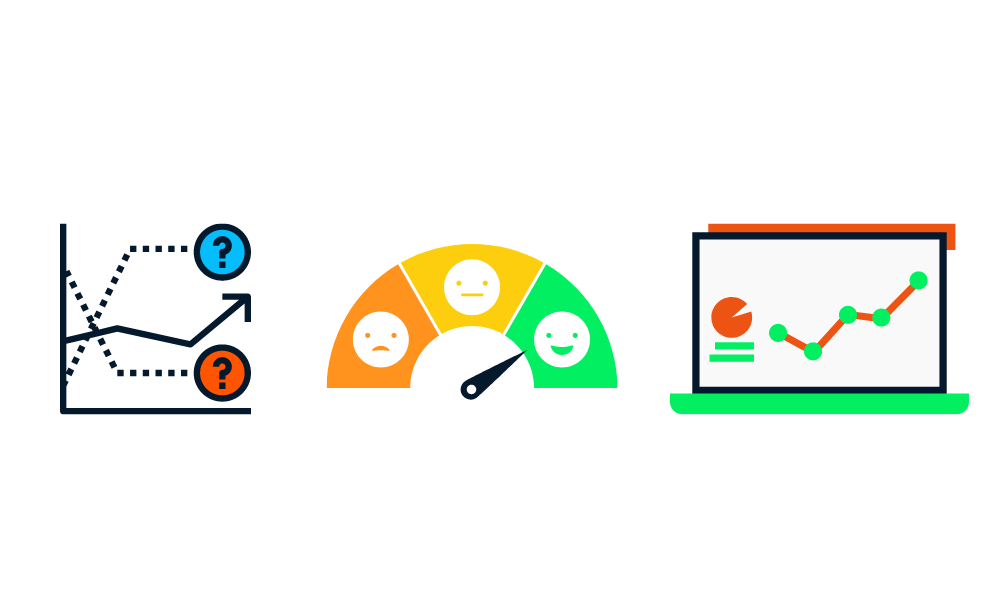 Imagen del autor
Imagen del autor
Ahora que hemos finalizado la versión del modelo, es el momento de probar varias métricas. ¿Por qué? Así podremos asegurarnos de que nuestro modelo está listo para la producción.
Primero probaremos nuestro modelo en un conjunto de datos de prueba y nos aseguraremos de implicar a expertos en la materia para identificar el error en las predicciones.
También tenemos que asegurarnos de que seguimos los marcos industriales, éticos y legales para construir soluciones de IA.
Además, comprobaremos la solidez de nuestro modelo con datos aleatorios y del mundo real. Asegurarse de que el modelo infiere lo bastante rápido para aportar valor.
Por último, compararemos los resultados con las métricas de éxito previstas y decidiremos si implantar el modelo o no. En esta fase, cada proceso se registra y versiona para mantener la calidad y la reproducibilidad.
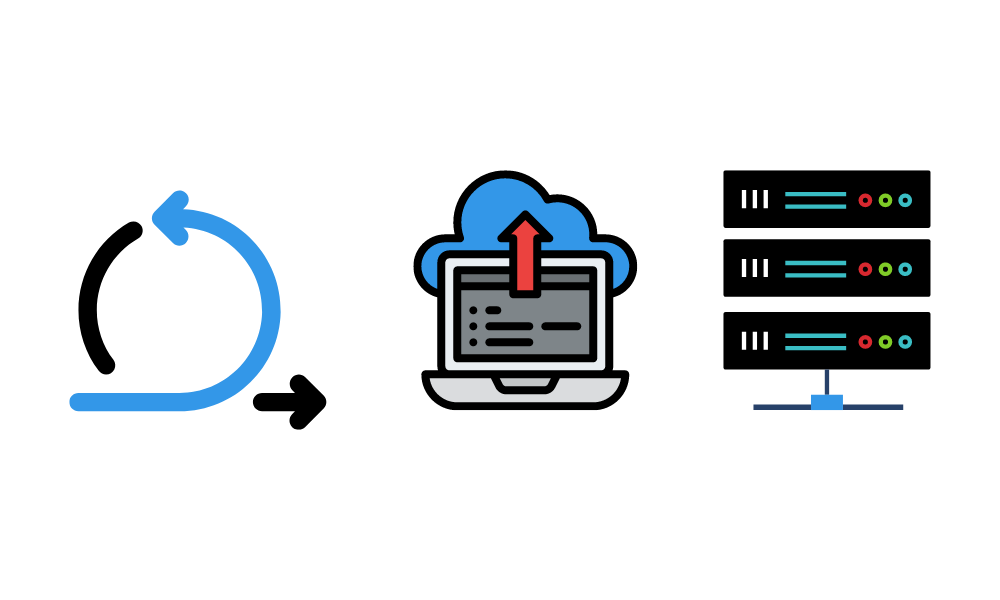 Imagen por Autor
Imagen por Autor
En esta fase, implementamos modelos de machine learning en el sistema actual. Por ejemplo: introducir el etiquetado automático del almacén utilizando la forma del producto. Implantaremos un modelo de visión por ordenador en el sistema actual, que utilizará las imágenes de la cámara para imprimir las etiquetas.
Generalmente, los modelos pueden desplegarse en la nube y en el servidor local, navegador web, paquete como software y dispositivo de borde. Después, puedes utilizar la API, la aplicación web, los plugins o el panel de control para acceder a las predicciones.
En el proceso de despliegue, definimos el hardware de inferencia. Tenemos que asegurarnos de que tenemos suficiente RAM, almacenamiento y potencia de cálculo para producir resultados rápidos. Después, evaluaremos el rendimiento del modelo en producción mediante pruebas A/B, garantizando la aceptabilidad del usuario.
La estrategia de despliegue es importante. Tienes que asegurarte de que los cambios son fluidos y de que han mejorado la experiencia del usuario. Además, un director de proyecto debe preparar un plan de gestión de catástrofes. Debe incluir una estrategia de emergencia, supervisión constante, detección de anomalías y minimización de pérdidas.
 Imagen del autor
Imagen del autor
Después de desplegar el modelo en producción, necesitamos supervisar y mejorar constantemente el sistema. Controlaremos las métricas del modelo, el rendimiento del hardware y el software, y la satisfacción del cliente.
La supervisión se realiza de forma totalmente automática, y se notifica a los profesionales las anomalías, la reducción del rendimiento del modelo y del sistema, y las malas críticas de los clientes.
Cuando recibamos una alerta de rendimiento reducido, evaluaremos los problemas e intentaremos entrenar el modelo con nuevos datos o realizar cambios en las arquitecturas del modelo. Es un proceso continuo.
En raras ocasiones, tenemos que renovar todo el ciclo de vida del machine learning para mejorar las técnicas de procesamiento de datos y entrenamiento de modelos, actualizar el nuevo software y hardware, e introducir un nuevo marco para la integración continua.
El estudiante de ciencia de datos en la mayoría de las universidades sólo aprende sobre procesamiento de datos, construcción y entrenamiento de modelos y, en algunos casos, despliegue. No se les enseña la práctica industrial estándar de garantía de calidad, las técnicas de recogida y etiquetado de datos, las canalizaciones de machine learning, el versionado de datos, el seguimiento de los experimentos de ML y la supervisión y el mantenimiento constantes.
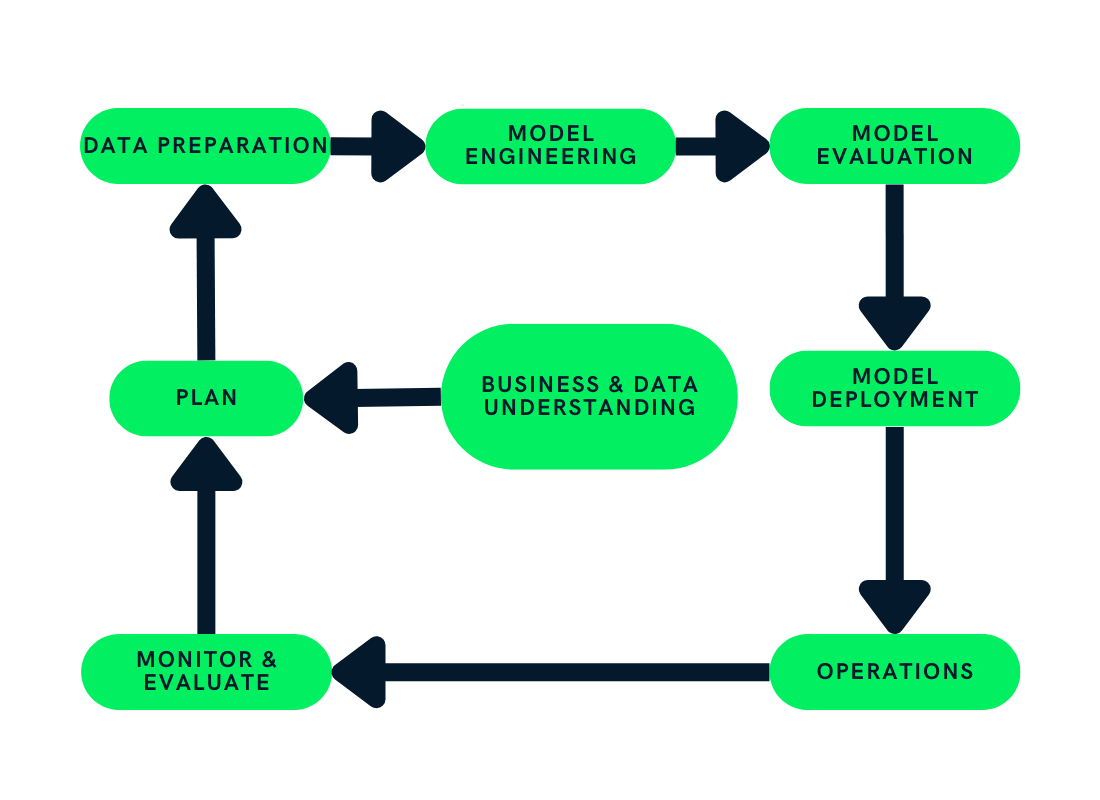 Imagen del autor
Imagen del autor
Incluso si eres un profesional de la ciencia de datos, necesitas aprender cómo las cinco grandes empresas tecnológicas están creando aplicaciones sostenibles de machine learning para miles de millones de clientes. También puedes aprender a Diseñar flujos de trabajo de machine learning en Python para construir canalizaciones que resistan el paso del tiempo. Te enseñará el flujo de trabajo estándar, los procesos humanos en bucle, la gestión del ciclo de vida de los modelos y el flujo de trabajo no supervisado.
En este artículo, hemos aprendido sobre la planificación de proyectos de machine learning basada en requisitos y limitaciones, recopilación y etiquetado de datos, ingeniería de modelos, evaluación de modelos, implementación de modelos, y supervisión y mantenimiento. Aparte de eso, hemos aprendido varias formas de mantener la calidad, reproducir los resultados y depurar el proceso en caso de fallo.
Cursos de machine learning
Curso
Curso
Curso
blog
Natassha Selvaraj
15 min
blog
Zoumana Keita
14 min
blog
Matt Crabtree
14 min
blog
Moez Ali
8 min
blog
Abid Ali Awan
11 min

