In today's rapidly evolving technological landscape, two terms often dominate the discourse: Artificial Intelligence (AI) and Machine Learning (ML). These technologies are not just buzzwords; they are shaping the future of industries, from healthcare and finance to retail and beyond. Yet, despite their prevalence, there is considerable confusion about what these terms actually mean and how they differ.
This article aims to demystify AI and ML, breaking down their complexities into digestible insights. Whether you're a business leader looking to leverage these technologies for strategic advantage, a data science beginner seeking foundational knowledge, or simply a curious mind, this guide will provide you with a clear understanding of these transformative fields. We'll explore their definitions, applications, and the intricate relationship between them, all while laying the groundwork for more advanced explorations.
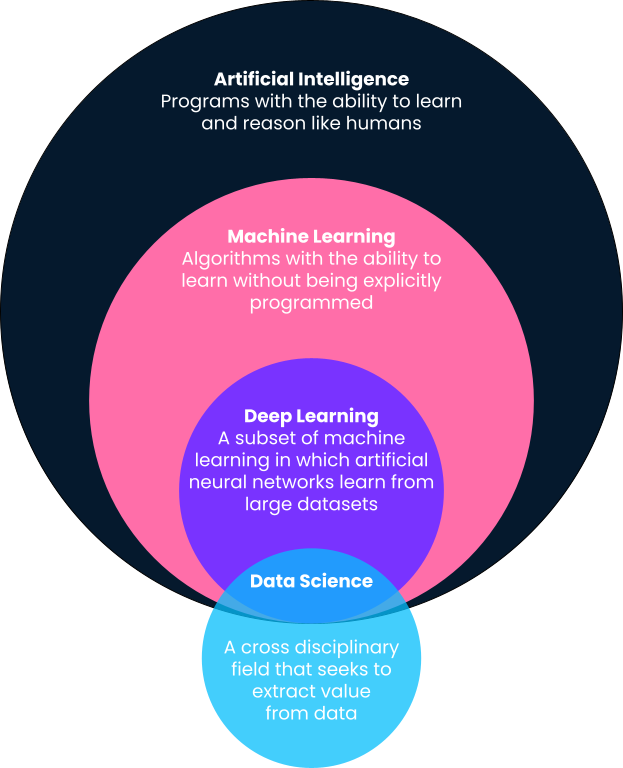
By the end of this article, you'll have a comprehensive understanding of AI and ML, empowering you to make informed decisions and engage in meaningful conversations around these pivotal technologies. For an exploration of deep learning vs machine learning, check out our separate article.
What is AI?
We explore the basics of AI in our comprehensive AI Quick-Start Guide for Beginners. However, to summarise, artificial intelligence is a broad field of computer science focused on creating intelligent systems capable of performing tasks that would typically require human intelligence. These tasks range from understanding natural language and recognizing patterns to making decisions and solving complex problems.
AI is essentially a huge set of tools for making computers behave intelligently, and in an automated fashion. This includes voice assistants, recommendation systems, and self-driving cars.
What is Machine Learning?
Again, we have a dedicated guide covering what machine learning is. In brief, machine learning (ML) is a specialized branch within the expansive field of AI. Its primary aim is to design and fine-tune algorithms that become more accurate and efficient as they interact with data over time.
Put simply, machine learning equips computers with the ability to analyze data, draw insights, and make informed decisions or forecasts, all without requiring explicit programming for these tasks.
Comparing different industry terms
Machine Learning vs AI: Key Similarities and Differences
The terms Artificial Intelligence (AI) and machine learning (ML) are often used interchangeably, but they are not the same. While they share some similarities, they also have distinct characteristics that set them apart. Understanding these nuances is crucial for anyone looking to delve into these transformative technologies.
Key Similarities
Let’s start by looking at where these two disciplines overlap, as this can help us understand the foundation of both of them:
- Data-driven. Both AI and ML rely heavily on data. AI uses data to make informed decisions, while ML uses data to learn and improve.
- Automation. Both fields aim to automate tasks that would otherwise require human intervention, be it decision-making in AI or data analysis in ML.
- Improvement over time. AI systems can become more effective as they gather more data, and ML algorithms improve their performance as they are exposed to more data for training.
- Computational complexity. Both AI and ML require significant computational power, often requiring specialized hardware like GPUs for complex tasks.
- Interdisciplinary fields. Both AI and ML draw from various disciplines, including computer science, statistics, mathematics, and engineering.
Key Differences
Now let’s look at what makes AI and machine learning different. In doing so, we can better understand when each should be used:
- Scope. AI has a broader scope, encompassing anything that allows computers to mimic human intelligence, including robotics, problem-solving, and language recognition. ML, on the other hand, is specifically focused on the development of algorithms that can learn from data.
- Goal. The ultimate goal of AI is to create systems that can perform tasks that would ordinarily require human intelligence. ML aims to enable machines to learn from data so that they can give accurate predictions or decisions.
- Learning. AI does not necessarily have to learn from data. For example, rule-based expert systems make decisions based on a set of explicit rules. ML specifically involves learning from data; as more data becomes available, an ML system can learn and improve.
- Dependency. Machine learning is a subset of AI, meaning that all machine learning is AI, but not all AI is machine learning.
- Types of learning. ML can be supervised, unsupervised, or reinforced. AI can either be rule-based and not learn from data at all, or it can use a variety of learning, including but not limited to machine learning techniques.
- Human intervention. In AI, the role of human intervention can vary; some systems require manual tuning and rule-setting, while others are more autonomous. ML specifically aims to minimize human intervention as much as possible, automating the learning process from data.
When to Use AI vs Machine Learning
The decision to use Artificial Intelligence (AI) or Machine Learning (ML) in a project or application depends on various factors, including the problem you're trying to solve, the nature of the data available, and the level of automation desired. Below, we outline some scenarios where one might be more suitable than the other.
When to use AI
Here are just some of the ways you can use AI today. As you'll see, the scope is broad, and there will certainly be times when an approach requires both AI and machine learning, as well as various other disciplines.
Complex decision-making
If your project involves making complex decisions based on multiple variables, AI, especially rule-based systems, can be highly effective.
Natural language understanding
For applications like chatbots or voice-activated systems where understanding human language is crucial, AI technologies like Natural Language Processing (NLP) are more appropriate.
Robotics
If your project involves physical tasks like moving objects or navigating through space, robotics, a subset of AI, is the way to go.
Broad scope
If your application requires a range of intelligent behaviors, from problem-solving and planning to perception and social intelligence, a broader AI approach is advisable.
Fixed rules with no learning
If your system operates based on a fixed set of rules and doesn't require learning from data, rule-based AI systems are suitable.
When to use machine learning
Again, these are just some of the instances where using ML is the preferred choice. That's not to say, however, that AI and other approaches can be applied in conjunction.
Data-driven predictions
If your primary goal is to make predictions based on data, ML is the ideal choice.
Pattern recognition
For tasks like fraud detection, recommendation systems, or customer segmentation, ML algorithms excel at identifying patterns in data.
Continuous improvement
If your application benefits from improving its performance over time through exposure to more data, ML is the way to go.
Anomaly detection
ML algorithms are highly effective at identifying outliers or anomalies in data sets, useful in fields like cybersecurity and quality control.
Natural language generation
For generating text based on data, such as automated reporting systems, ML techniques like text generation algorithms can be highly effective.
Hybrid Approaches
In many modern applications, AI and ML are used in tandem to leverage the strengths of both. For example, an AI system might use ML algorithms as one of its components for specific tasks like data analysis or prediction.

As seen in our Generative AI Tools cheat sheet, there are many applications for AI and ML
AI vs Machine Learning Examples
Choosing between artificial intelligence and machine learning for a project or application depends on various factors. To provide a clearer understanding, let's delve into some real-world examples.
Real examples of AI
Complex decision-making: Autonomous vehicles
- Situation: Self-driving cars need to navigate through traffic, obey traffic rules, and make split-second decisions to avoid accidents.
- Why AI: AI algorithms can process multiple sensor inputs, such as cameras, radars, and Lidar, to make complex decisions in real-time. These decisions can range from lane-keeping and adaptive cruise control to emergency braking and collision avoidance.
- Outcome: The use of AI enables autonomous vehicles to operate safely and efficiently, reducing the likelihood of human error.
Natural language understanding: Virtual assistants like Siri and Alexa
- Situation: Users interact with virtual assistants using natural language to perform tasks like setting reminders, playing music, or getting weather updates.
- Why AI: AI-powered Natural Language Processing (NLP) algorithms can understand the context and semantics of human speech, allowing for more accurate and nuanced responses.
- Outcome: The AI capabilities make virtual assistants more effective and user-friendly, enhancing user experience.
Real examples of machine learning
Data-driven predictions: Predictive healthcare analytics
- Situation: Healthcare providers and researchers aim to predict patient outcomes and disease progression to tailor interventions and optimize healthcare delivery.
- Why ML: Machine Learning algorithms can process and analyze extensive healthcare data, including patient records, lab results, and medical images, to identify patterns and risk factors associated with various health conditions. These algorithms continuously learn and refine their predictions as more data becomes available, allowing for personalized and proactive healthcare approaches.
- Outcome: The implementation of ML in healthcare enables the early identification of high-risk patients and the prediction of disease outbreaks, contributing to improved patient outcomes, more efficient healthcare delivery, and reduced costs.
Pattern recognition: Fraud detection in banking
- Situation: Banks need to identify potentially fraudulent transactions in real-time to protect customer accounts.
- Why ML: Machine Learning algorithms can analyze transaction data to identify unusual patterns or anomalies that may indicate fraudulent activity. These algorithms are trained on historical fraud data and can update their models in real-time.
- Outcome: ML-based fraud detection systems can flag suspicious transactions with high accuracy, allowing banks to take immediate action, thereby enhancing customer trust and security.
Conclusion and Next Steps
Understanding the nuances between Artificial Intelligence (AI) and Machine Learning (ML) is crucial for anyone looking to delve into these transformative technologies. Whether you're a business leader, a data science beginner, or a tech enthusiast, knowing when to use AI or ML can significantly impact the success of your projects.
Next steps for learning
If you’re eager to learn more about these fascinating fields, here are some resources to help you get started:
- Foundational knowledge. If you're new to these fields, start with DataCamp's AI Fundamentals and Understanding Machine Learning courses to build a strong foundation.
- Advanced topics. For those who want to go beyond the basics, consider advanced courses like Deep Learning in Python or Natural Language Processing.
- Hands-on practice. DataCamp has compiled various AI projects and ML projects that allow you to apply what you've learned in real-world scenarios.
By taking these steps, you'll not only gain a comprehensive understanding of AI and ML but also acquire the skills needed to apply them effectively in your projects.



