
programa
Ingeniero de datos en Python
40 h
Apache Kafka permite a los usuarios analizar datos en tiempo real, almacenar registros en el orden en que fueron creados, y publicar y suscribirse a ellos.
Los componentes principales de Apache Kafka | Fuente: Inicia tu pipeline en tiempo real con Apache Kafka por Alex Kam
Apache Kafka es un clúster de servidores básicos escalable horizontalmente que procesa datos en tiempo real de múltiples sistemas y aplicaciones "productores" (por ejemplo, aplicaciones de registro, monitorización, sensores e Internet de las Cosas) y los pone a disposición de múltiples sistemas y aplicaciones "consumidores" (por ejemplo, análisis en tiempo real) con una latencia muy baja, como se muestra en el diagrama anterior.
Ten en cuenta que tanto las aplicaciones que dependen del procesamiento de datos en tiempo real como los sistemas de análisis pueden considerarse consumidores. Por ejemplo, una aplicación de micromarketing o logística basada en la localización.
He aquí algunos términos clave que debes conocer para comprender mejor los componentes básicos de Kafka:
A menudo se recomienda iniciar Apache Kafka con Zookeeper para una compatibilidad óptima. Además, Kafka puede encontrarse con varios problemas cuando se instala en Windows porque no está diseñado de forma nativa para su uso con este sistema operativo. En consecuencia, se aconseja utilizar lo siguiente para lanzar Apache Kafka en Windows:
No se aconseja utilizar la JVM para ejecutar Kafka en Windows, ya que no tiene algunas de las características POSIX propias de Linux. Al final encontrarás dificultades si intentas ejecutar Kafka en Windows sin WSL2.
Dicho esto, el primer paso para instalar Apache Kafka en Windows es instalar WSL2.
WSL2, o Subsistema Windows para Linux 2, da acceso a tu PC Windows a un entorno Linux sin necesidad de una máquina virtual.
La mayoría de los comandos de Linux son compatibles con WSL2, lo que acerca el proceso de instalación de Kafka a las instrucciones ofrecidas para Mac y Linux.
Consejo: Asegúrate de que estás ejecutando Windows 10 versión 2004 o superior (Build 19041 y superior) antes de instalar WSL2. Pulsa la tecla del logotipo de Windows + R, escribe "winver" y haz clic en Aceptar para ver tu versión de Windows.
La forma más sencilla de instalar el Subsistema de Windows para Linux (WSL) es ejecutando el siguiente comando en un PowerShell de administrador o en el Símbolo del sistema de Windows y, a continuación, reiniciando el ordenador:
wsl --installTen en cuenta que se te pedirá que crees una cuenta de usuario y una contraseña para la distribución de Linux que acabas de instalar.
Sigue los pasos del sitio web de Microsoft Docs si te quedas atascado.
Si Java no está instalado en tu máquina, tendrás que descargar la última versión.
Paso 3: Instalar Apache Kafka
En el momento de escribir este artículo, la última versión estable de Apache Kafka es la 3.7.0, publicada el 27 de febrero de 2024. Esto puede cambiar en cualquier momento. Para asegurarte de que utilizas la versión más actualizada y estable de Kafka, consulta la página de descargas.
Descarga la última versión desde Descargas binarias.
Una vez finalizada la descarga, navega hasta la carpeta donde se descargó Kafka y extrae todos los archivos de la carpeta comprimida. Observa que hemos llamado a nuestra nueva carpeta "Kafka".
Zookeeper es necesario para la gestión de clusters en Apache Kafka. Por lo tanto, Zookeeper debe lanzarse antes que Kafka. No es necesario instalar Zookeeper por separado porque forma parte de Apache Kafka.
Abre el símbolo del sistema y navega hasta el directorio raíz de Kafka. Una vez allí, ejecuta el siguiente comando para iniciar Zookeeper:
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.propertiesAbre otro símbolo del sistema y ejecuta el siguiente comando desde la raíz de Apache Kafka para iniciar Apache Kafka:
.\bin\windows\kafka-server-start.bat .\config\server.propertiesPara crear un tema, inicia un nuevo símbolo del sistema desde el directorio raíz de Kafka y ejecuta el siguiente comando:
.\bin\windows\kafka-topics.bat --create --topic MyFirstTopic --bootstrap-server localhost:9092Esto creará un nuevo tema Kafka llamado "MiPrimerTema".
Nota: para confirmar que se ha creado correctamente, al ejecutar el comando aparecerá "Crear tema <nombre del tema>".
Debe iniciarse un productor para poner un mensaje en el tema Kafka. Ejecuta el siguiente comando para hacerlo:
.\bin\windows\kafka-console-producer.bat --topic MyFirstTopic --bootstrap-server localhost:9092Abre otro símbolo del sistema desde el directorio raíz de Kafka y ejecuta el siguiente comando para enviar a stat el consumidor de Kafka:
.\bin\windows\kafka-console-consumer.bat --topic MyFirstTopic --from-beginning --bootstrap-server localhost:9092Ahora, cuando se produce un mensaje en el Productor, el Consumidor lo lee en tiempo real.
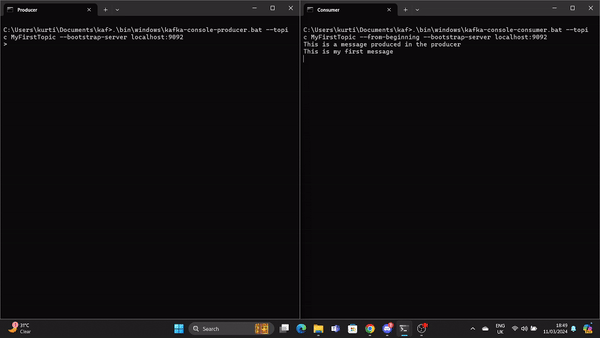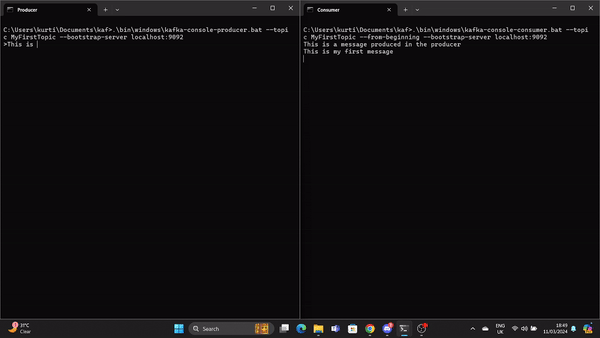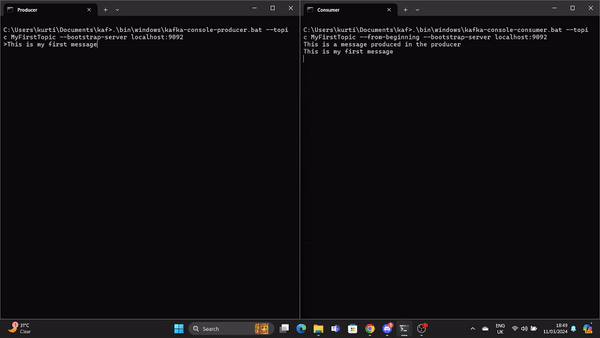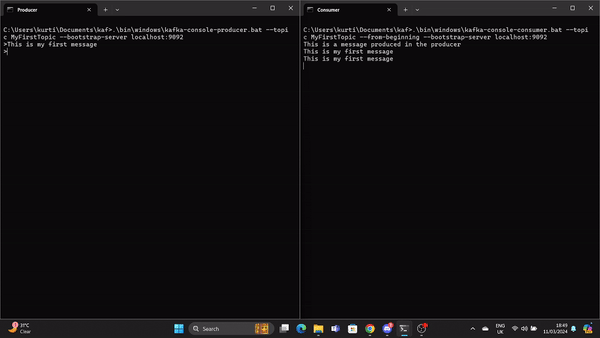
Un GIF muestra un mensaje producido por el Productor y leído por el Consumidor Kafka en tiempo real.
Ahí lo tienes... Acabas de crear tu primer tema Kafka.
Aquí tienes algunas funciones avanzadas de Kafka...
Con Apache Kafka, los desarrolladores pueden crear sólidas aplicaciones de procesamiento de flujos con la ayuda de Kafka Streams. Ofrece API y un Lenguaje Específico de Dominio (DSL) de alto nivel para manejar, convertir y evaluar flujos continuos de datos.
Algunas características clave son:
El procesamiento en tiempo real de flujos de registros es posible gracias a Kafka Streams. Te permite recibir datos de temas Kafka, procesarlos y transformarlos, y luego devolver la información procesada a los temas Kafka. El procesamiento de flujos permite el análisis, la supervisión y el enriquecimiento de datos casi en tiempo real. Puede aplicarse a grabaciones individuales o a agregaciones con ventanas.
Utilizando las marcas de tiempo adjuntas a los registros, puedes manejar registros fuera de orden con el soporte de Kafka Streams para el procesamiento de eventos en tiempo real. Proporciona operaciones de ventana con semántica de tiempo de evento, permitiendo la unión de ventanas, la sesionización y las agregaciones basadas en el tiempo.
Kafka Streams proporciona una serie de operaciones de ventana que permiten a los usuarios realizar cálculos sobre ventanas de sesión, ventanas giratorias, ventanas deslizantes y ventanas de tiempo fijo.
Los disparadores basados en eventos, los análisis sensibles al tiempo y las agregaciones basadas en el tiempo son posibles mediante procedimientos de ventana.
Durante el procesamiento de flujos, Kafka Streams permite a los usuarios mantener y actualizar el estado. Se proporciona soporte integrado para almacenes estatales. Ten en cuenta que un almacén de estados es un almacén clave-valor que puede actualizarse y consultarse dentro de una topología de procesamiento.
Las funciones avanzadas de procesamiento de flujos, como las uniones, las agregaciones y la detección de anomalías, son posibles gracias a las operaciones con estado.
Kafka Streams proporciona una semántica de extremo a extremo para el procesamiento exactamente una vez, garantizando que cada registro se gestiona precisamente una vez, incluso en caso de fallo. Esto se consigue utilizando las sólidas garantías de durabilidad y las funciones transaccionales de Kafka.
El marco de integración de datos declarativo y conectable para Kafka se llama Kafka Connect. Es un componente gratuito y de código abierto de Apache Kafka que actúa como un concentrador de datos centralizado para la integración sencilla de datos entre sistemas de archivos, bases de datos, índices de búsqueda y almacenes de valores clave.
La distribución de Kafka incluye Kafka Connect por defecto. Para instalarlo, sólo tienes que iniciar un proceso obrero.
Utiliza el siguiente comando desde el directorio raíz de Kafka para lanzar el proceso de trabajador de Kafka Connect:
.\bin\windows\connect-distributed.bat
.\config\connect-distributed.propertiesEsto lanzará el trabajador de Kafka Connect en modo distribuido, permitiendo la alta disponibilidad y escalabilidad de ejecutar numerosos trabajadores en un clúster.
Nota: El archivo .\config\connect-distributed.properties especifica la información del broker de Kafka y otras propiedades de configuración para Kafka Connect.
Los conectores son utilizados por Kafka Connect para transferir datos entre sistemas externos y temas Kafka. Los conectores pueden instalarse y configurarse para adaptarse a tus requisitos exclusivos de integración de datos.
Descargar y añadir el archivo JAR del conector al directorio plugin.path mencionado en el archivo .\config\connect-distributed.properties es todo lo que se necesita para instalar un conector.
Hay que crear un archivo de configuración para el conector, en el que se especifique la clase del conector y cualquier otra característica. La API REST de Kafka Connect y las herramientas de línea de comandos pueden utilizarse para construir y mantener conectores.
A continuación, para combinar datos de otros sistemas, debes configurar el Conector Kafka. Kafka Connect ofrece varios conectores para integrar datos de diversos sistemas, como sistemas de archivos, colas de mensajes y bases de datos. Selecciona un conector en función de las necesidades de integración que tengas: consulta la documentación para ver la lista de conectores.
He aquí algunos casos de uso común de Apache Kafka.
Una plataforma de comercio electrónico en línea puede utilizar Kafka para seguir la actividad de los usuarios en tiempo real. Cada acción del usuario, como ver productos, añadir artículos al carrito, comprar, dejar opiniones, hacer búsquedas, etc., puede publicarse como un evento en temas Kafka concretos.
Otros microservicios pueden almacenar o utilizar estos eventos para la detección de fraudes en tiempo real, informes, ofertas personalizadas y recomendaciones.
Con su rendimiento mejorado, partición incorporada, replicación, tolerancia a fallos y capacidades de escalado, Kafka es un buen sustituto de los corredores de mensajes convencionales.
Una aplicación de transporte basado en microservicios puede utilizarlo para facilitar el intercambio de mensajes entre varios servicios.
Por ejemplo, la empresa de reservas de viajes puede utilizar Kafka para comunicarse con el servicio de búsqueda de conductores cuando un conductor hace una reserva. El servicio de búsqueda de conductores puede entonces, casi en tiempo real, localizar a un conductor en la zona y responder con un mensaje.
Normalmente, esto implica obtener archivos de registro físicos de los servidores y almacenarlos en una ubicación central para su procesamiento, como un servidor de archivos o un lago de datos. Kafka abstrae los datos como un flujo de mensajes y filtra la información específica del archivo. Esto permite procesar los datos con una latencia reducida y adaptarse más fácilmente al consumo de datos distribuidos y a diferentes fuentes de datos.
Una vez publicados los registros en Kafka, una herramienta de análisis de registros o un sistema de gestión de eventos e información de seguridad (SIEM) pueden utilizarlos para solucionar problemas, supervisar la seguridad y elaborar informes de cumplimiento.
Varios usuarios de Kafka procesan datos en pipelines de procesamiento multietapa. Los datos de entrada sin procesar se toman de temas Kafka, se agregan, se enriquecen o se transforman de otro modo en nuevos temas para su consumo o procesamiento adicional.
Por ejemplo, un banco puede utilizar Kafka para procesar transacciones en tiempo real. Cada transacción que inicia un cliente se publica en un tema Kafka como un evento. Posteriormente, una aplicación puede recoger estos eventos, verificar y gestionar las transacciones, detener las dudosas y actualizar instantáneamente los saldos de los clientes.
Un proveedor de servicios en la nube podría utilizar Kafka para agregar estadísticas de aplicaciones distribuidas y generar flujos centralizados de datos operativos en tiempo real. Las métricas de cientos de servidores, como el consumo de CPU y memoria, el recuento de peticiones, las tasas de error, etc., podrían notificarse a Kafka. Las aplicaciones de monitorización podrían entonces utilizar estas métricas para la identificación de anomalías, alertas y visualización en tiempo real.
Kafka es un marco para el procesamiento de flujos que permite a las aplicaciones publicar, consumir y procesar grandes cantidades de flujos de registros de forma rápida y fiable. Teniendo en cuenta la creciente prevalencia del flujo de datos en tiempo real, se ha convertido en una herramienta vital para los desarrolladores de aplicaciones de datos.
En este artículo, cubrimos por qué uno puede decidir utilizar Kafka, los componentes básicos, cómo empezar a utilizarlo, las funciones avanzadas y las aplicaciones del mundo real. Para seguir aprendiendo, consulta
Nuestros programas de certificación te ayudan a destacar y a demostrar que tus aptitudes están preparadas para el trabajo a posibles empleadores.

¡Comienza hoy tu viaje como Ingeniero de Datos!
programa
Curso
Curso
blog
Adejumo Ridwan Suleiman
13 min
blog
Kurtis Pykes
11 min
blog
Abid Ali Awan
13 min
Tutorial
Tim Lu
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
