programa
Ingeniero de datos en Python
40 h
Como científicos de datos, no solemos implicarnos en el despliegue y el mantenimiento: construimos los modelos estadísticos y los ingenieros hacen el resto.
Sin embargo, ¡las cosas están empezando a cambiar!
Con la creciente demanda de científicos de datos que puedan salvar la distancia entre la creación de modelos y la producción, familiarizarte con la automatización y las herramientas de CI/CD (Integración Continua/Despliegue Continuo) puede ser una ventaja estratégica.
En este tutorial, conoceremos dos populares herramientas de automatización: Make (automatización local) y GitHub Actions (automatización basada en la nube). Nos centraremos principalmente en incorporar estas herramientas a nuestros proyectos de datos.

Acción GitHub y Make. Imagen de Abid Ali Awan.
Si quieres saber más sobre la automatización en el contexto de la ciencia de datos, consulta este curso sobre MLOps totalmente automatizados.
Un Makefile es un plano para construir y gestionar proyectos de software. Es un archivo que contiene instrucciones para automatizar tareas, agilizar procesos de construcción complejos y garantizar la coherencia.
Para ejecutar los comandos dentro del Makefile, utilizamos la herramienta de línea de comandos make. Esta herramienta puede ejecutarse como un programa Python, proporcionando los argumentos o simplemente ejecutándola sola.
Un Makefile suele consistir en una lista de objetivos, dependencias, acciones y variables:
python test.py.python test.py $variable_1 $variable_2.En pocas palabras, así es como podría ser la plantilla de un MakeFile:
Variable = some_value
Target: Dependencies
Actions (commands to build the target) $VariableUtilizando nuestros ejemplos anteriores, el MakeFile podría tener este aspecto:
# Define variables
variable_1 = 5
variable_2 = 10
# Target to run a test with variables
test: test_data.txt # Dependency on test data file
python test.py $variable_1 $variable_2Podemos instalar la herramienta Make CLI en todos los sistemas operativos.
Para Linux, tenemos que utilizar el siguiente comando en el terminal:
$ sudo apt install makePara macOS, podemos utilizar homebrew para instalar make:
$ brew install makeWindows es un poco diferente. La herramienta Hacer puede utilizarse de múltiples formas. Las opciones más populares son WSL (Ubuntu Linxus), w64devkit y GnuWin32.
Vamos a descargar e instalar GnuWin32 desde la página de SourceForge.
Para utilizarla como herramienta de línea de comandos en el terminal, tenemos que añadir la ubicación de la carpeta a la variable de entorno de Windows. Estos son los pasos que podemos dar:
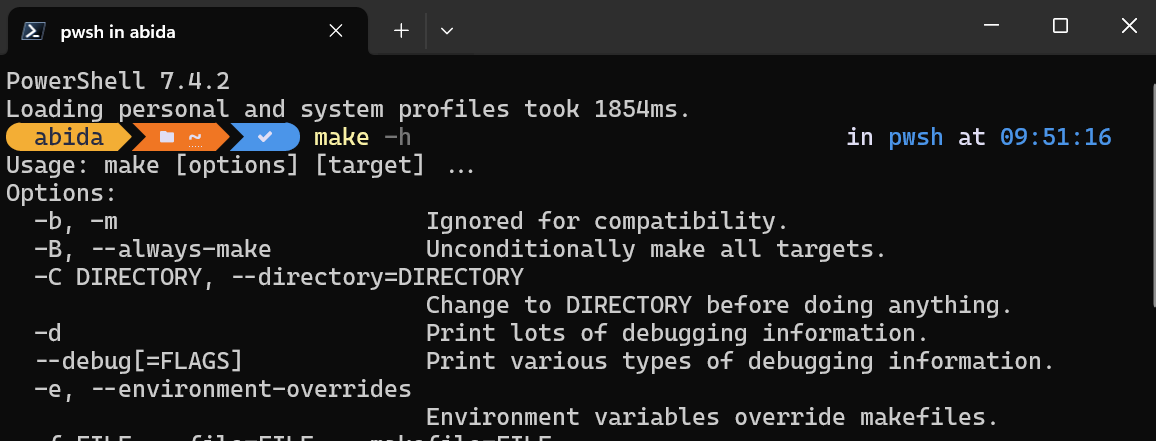
Para comprobar si Make se ha instalado correctamente, podemos escribir make -h en la PowerShell.
En esta sección, aprenderemos a utilizar las herramientas Makefile y Make CLI en un proyecto de ciencia de datos.
Utilizaremos el conjunto de datos del Informe sobre la Felicidad en el Mundo 2023 para tratar los datos, analizarlos y guardar resúmenes y visualizaciones de los mismos.
Comenzamos yendo al directorio del proyecto y creando una carpeta llamada Makefile-Action. A continuación, creamos el archivo data_processing.py dentro de esa carpeta y lanzamos el editor VSCode.
$ cd GitHub
$ mkdir Makefile-Action
$ cd .\Makefile-Action\
$ code data_processing.pyComenzamos procesando nuestros datos utilizando Python. En el bloque de código siguiente, realizamos los pasos siguientes (nota: se trata de un código de ejemplo; en un escenario real, probablemente tendríamos que realizar más pasos):
Archivo: proceso_datos.py
import sys
import pandas as pd
# Check if the data location argument is provided
if len(sys.argv) != 2:
print("Usage: python data_processing.py <data_location>")
sys.exit(1)
# Load the raw dataset (step 1)
df = pd.read_csv(sys.argv[1])
# Rename columns to more descriptive names (step 2)
df.columns = [
"Country",
"Happiness Score",
"Happiness Score Error",
"Upper Whisker",
"Lower Whisker",
"GDP per Capita",
"Social Support",
"Healthy Life Expectancy",
"Freedom to Make Life Choices",
"Generosity",
"Perceptions of Corruption",
"Dystopia Happiness Score",
"GDP per Capita",
"Social Support",
"Healthy Life Expectancy",
"Freedom to Make Life Choices",
"Generosity",
"Perceptions of Corruption",
"Dystopia Residual",
]
# Handle missing values by replacing them with the mean (step 3)
df.fillna(df.mean(numeric_only=True), inplace=True)
# Check for missing values after cleaning
print("Missing values after cleaning:")
print(df.isnull().sum())
print(df.head())
# Save the cleaned and normalized dataset to a new CSV file (step 4)
df.to_csv("processed_data\WHR2023_cleaned.csv", index=False)Ahora continuamos con el análisis de los datos y guardamos todo nuestro código en un archivo llamado análisis_datos.py. Podemos crear este archivo con el siguiente comando de terminal:
$ code data_analysis.pyTambién podemos utilizar el comando echo para crear el archivo Python y abrirlo en otro editor de código.
$ echo "" > data_analysis.pyEn el bloque de código siguiente
Archivo: data_analysis.py
import io
import sys
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
# Check if the data location argument is provided
if len(sys.argv) != 2:
print("Usage: python data_analysis.py <data_location>")
sys.exit(1)
# Load the clean dataset (step 1)
df = pd.read_csv(sys.argv[1])
# Data summary (step 2)
print("Data Summary:")
summary = df.describe()
data_head = df.head()
print(summary)
print(data_head)
# Collecting data information
buffer = io.StringIO()
df.info(buf=buffer)
info = buffer.getvalue()
## Write metrics to file
with open("processed_data/summary.txt", "w") as outfile:
f"\n## Data Summary\n\n{summary}\n\n## Data Info\n\n{info}\n\n## Dataframe\n\n{data_head}"
print("Data summary saved in processed_data folder!")
# Distribution of Happiness Score (step 3)
plt.figure(figsize=(10, 6))
sns.displot(df["Happiness Score"])
plt.title("Distribution of Happiness Score")
plt.xlabel("Happiness Score")
plt.ylabel("Frequency")
plt.savefig("figures/happiness_score_distribution.png")
# Top 20 countries by Happiness Score
top_20_countries = df.nlargest(20, "Happiness Score")
plt.figure(figsize=(10, 6))
sns.barplot(x="Country", y="Happiness Score", data=top_20_countries)
plt.title("Top 20 Countries by Happiness Score")
plt.xlabel("Country")
plt.ylabel("Happiness Score")
plt.xticks(rotation=90)
plt.savefig("figures/top_20_countries_by_happiness_score.png")
# Scatter plot of Happiness Score vs GDP per Capita
plt.figure(figsize=(10, 6))
sns.scatterplot(x="GDP per Capita", y="Happiness Score", data=df)
plt.title("Happiness Score vs GDP per Capita")
plt.xlabel("GDP per Capita")
plt.ylabel("Happiness Score")
plt.savefig("figures/happiness_score_vs_gdp_per_capita.png")
# Visualize the relationship between Happiness Score and Social Support
plt.figure(figsize=(10, 6))
plt.scatter(x="Social Support", y="Happiness Score", data=df)
plt.xlabel("Social Support")
plt.ylabel("Happiness Score")
plt.title("Relationship between Social Support and Happiness Score")
plt.savefig("figures/social_support_happiness_relationship.png")
# Heatmap of correlations between variables
corr_matrix = df.drop("Country", axis=1).corr()
plt.figure(figsize=(12, 10))
sns.heatmap(corr_matrix, annot=True, cmap="coolwarm", square=True)
plt.title("Correlation Heatmap")
plt.savefig("figures/correlation_heatmap.png")
print("Visualizations saved to figures folder!")Antes de crear un Makefile, tenemos que configurar un archivo requirements.txt para instalar todos los paquetes de Python necesarios en una máquina nueva. Este es el aspecto que tendrá el archivo requirements.txt:
pandas
numpy
seaborn
matplotlib
blackNuestro Makefile consta de variables, dependencias, objetivos y acciones: aprenderemos todos los componentes básicos. Creamos un archivo llamado Makefile y empezamos a añadir las acciones para los objetivos:
Archivo: Makefile
RAW_DATA_PATH = "raw_data/WHR2023.csv"
PROCESSED_DATA = "processed_data/WHR2023_cleaned.csv"
install:
pip install --upgrade pip &&\
pip install -r requirements.txt
format:
black *.py --line-length 88
process: ./raw_data/WHR2023.csv
python data_processing.py $(RAW_DATA_PATH)
analyze: ./processed_data/WHR2023_cleaned.csv
python data_analysis.py $(PROCESSED_DATA)
clean:
rm -f processed_data/* **/*.png
all: install format process analyzePara ejecutar el objetivo, utilizaremos la herramienta make e indicaremos el nombre del objetivo en el terminal.
$ make formatEl script Negro se ejecutó correctamente.

Intentemos ejecutar el script de Python para procesar los datos.
Es importante tener en cuenta que comprueba las dependencias del objetivo antes de ejecutar el objetivo process. En nuestro caso, comprueba si existe el archivo de datos brutos. Si no lo hace, el comando no se iniciará.
$ make processComo vemos, es así de sencillo.
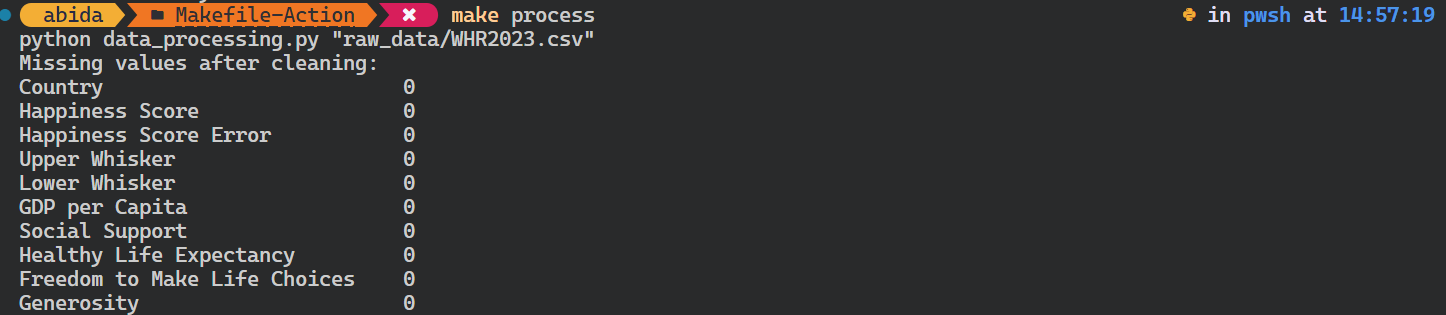
Incluso puedes anular la variable existente proporcionando un argumento adicional al comando make.
En nuestro caso, hemos cambiado la ruta de los datos brutos.
$ make process RAW_DATA_PATH="WHR2022.csv"El script de Python se ejecutó con el argumento de entrada diferente.
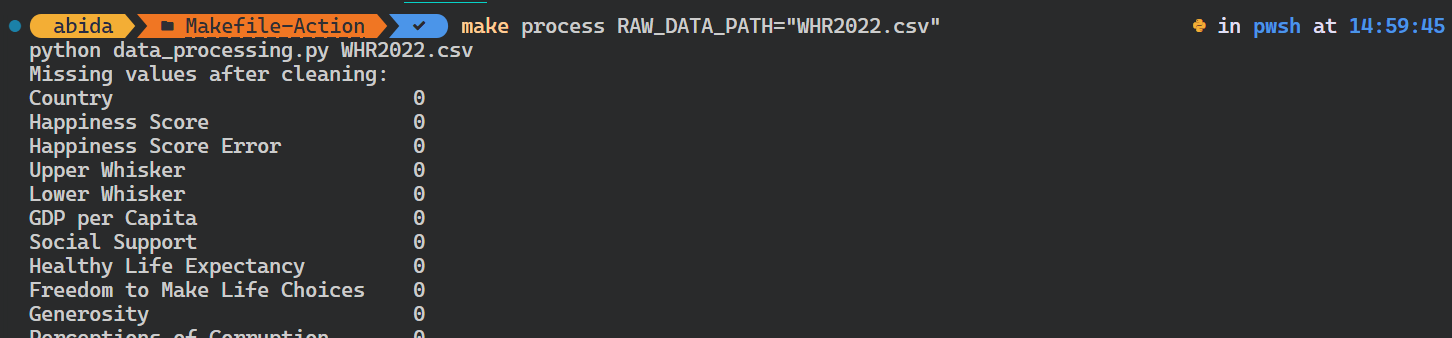
Para automatizar todo el flujo de trabajo, utilizaremos all como objetivo, que aprenderá, instalará, formateará, procesará y analizará los objetivos uno a uno.
$ make allEl comando make instaló los paquetes de Python, formateó el código, procesó los datos y guardó el resumen y las visualizaciones.
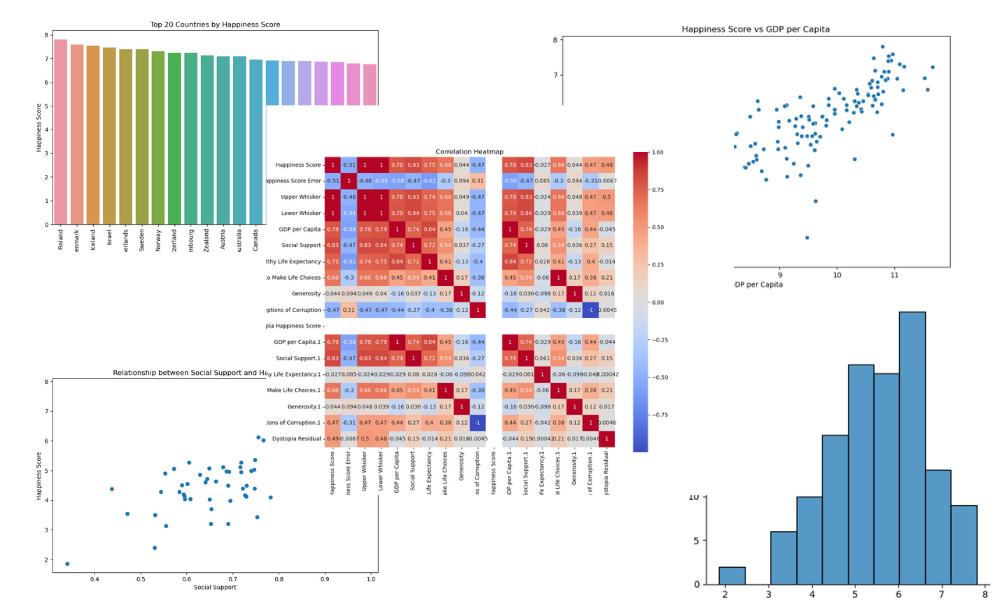
Este es el aspecto que debería tener el directorio de tu proyecto después de ejecutar el comando make all:
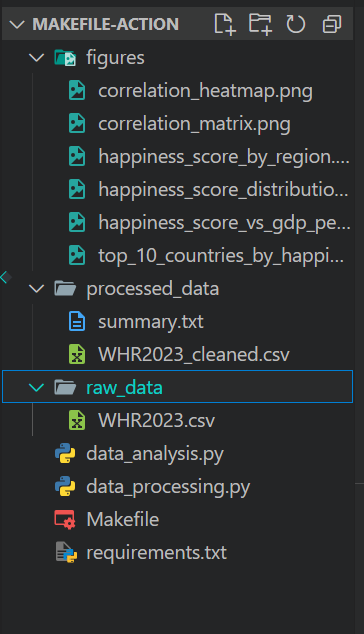
Mientras que Make destaca en la automatización local dentro de nuestro entorno de desarrollo, GitHub Actions ofrece una alternativa basada en la nube.
GitHub Actions se utiliza generalmente para CI/CD, que permite a los desarrolladores compilar, construir, probar y desplegar la aplicación a producción directamente desde GitHub.
Por ejemplo, podemos crear un flujo de trabajo personalizado que se active en función de eventos específicos, como solicitudes push o pull. Ese flujo de trabajo ejecutará scripts shell y scripts Python, o incluso podemos utilizar acciones preconstruidas. El flujo de trabajo personalizado es un archivo YML, y suele ser bastante sencillo de entender y empezar a escribir ejecuciones y acciones personalizadas.
Exploremos los componentes principales de las Acciones de GitHub:
En esta sección, aprenderemos a utilizar las Acciones de GitHub e intentaremos replicar los comandos que utilizamos anteriormente en el Makefile.
Para transferir nuestro código a GitHub, tenemos que convertir nuestra carpeta de proyecto en un repositorio Git utilizando:
$ git initA continuación, creamos un nuevo repositorio en GitHub y copiamos la URL.
En el terminal, escribimos los siguientes comandos para:
master a la rama remota main.$ git remote add github https://github.com/kingabzpro/Makefile-Actions.git
$ git pull github main
$ git add .
$ git commit -m "adding all the files"
$ git push github master:mainComo nota al margen, si necesitas una breve recapitulación sobre GitHub o Git, echa un vistazo a este tutorial para principiantes sobre GitHub y Git. Te ayudará a versionar tu proyecto de ciencia de datos y a compartirlo con el equipo utilizando la herramienta Git CLI.
Continuando con nuestra lección, vemos que todos los archivos se han transferido correctamente al repositorio remoto.
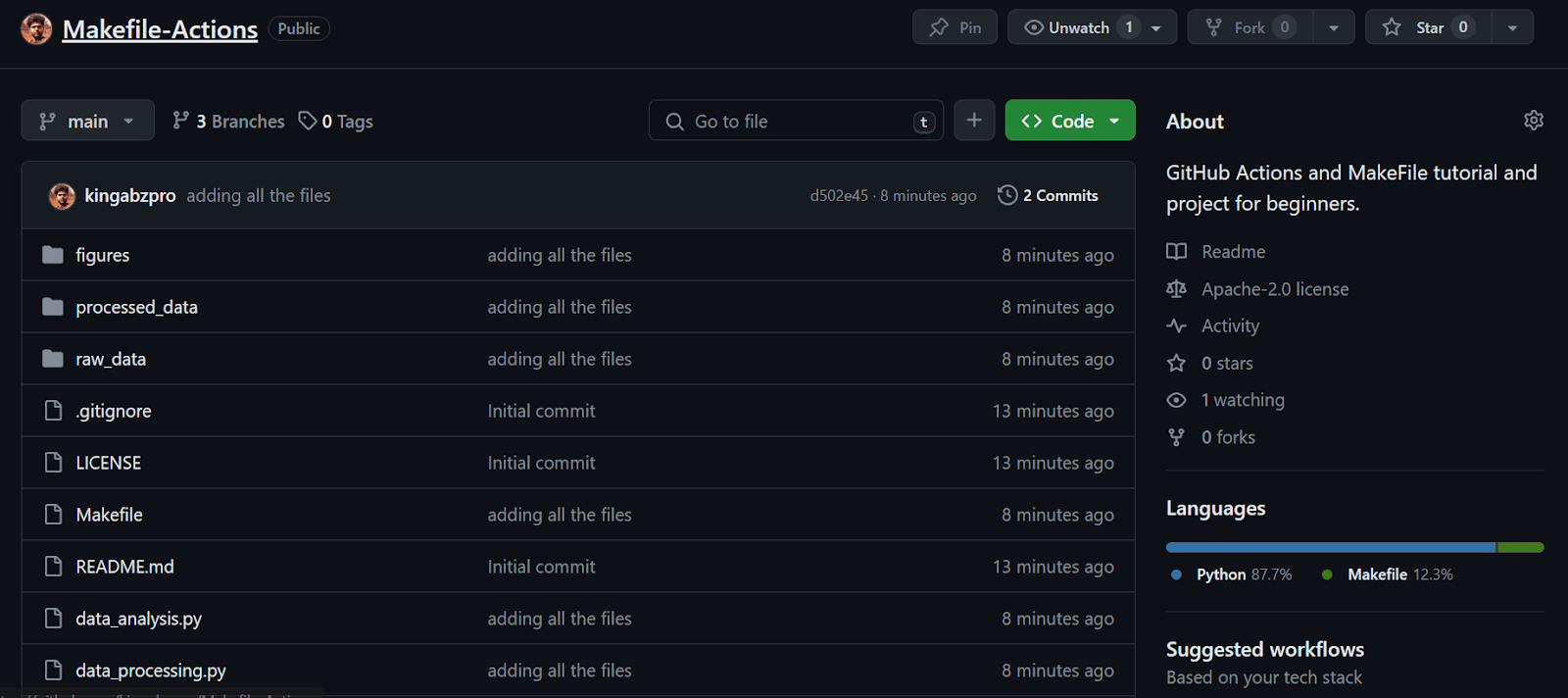
A continuación, crearemos un flujo de trabajo de Acción GitHub. Primero tenemos que ir a la pestaña Acciones de nuestro repositorio kingabzpro/Makefile-Actions. A continuación, hacemos clic en el texto azul "configura tú mismo un flujo de trabajo".
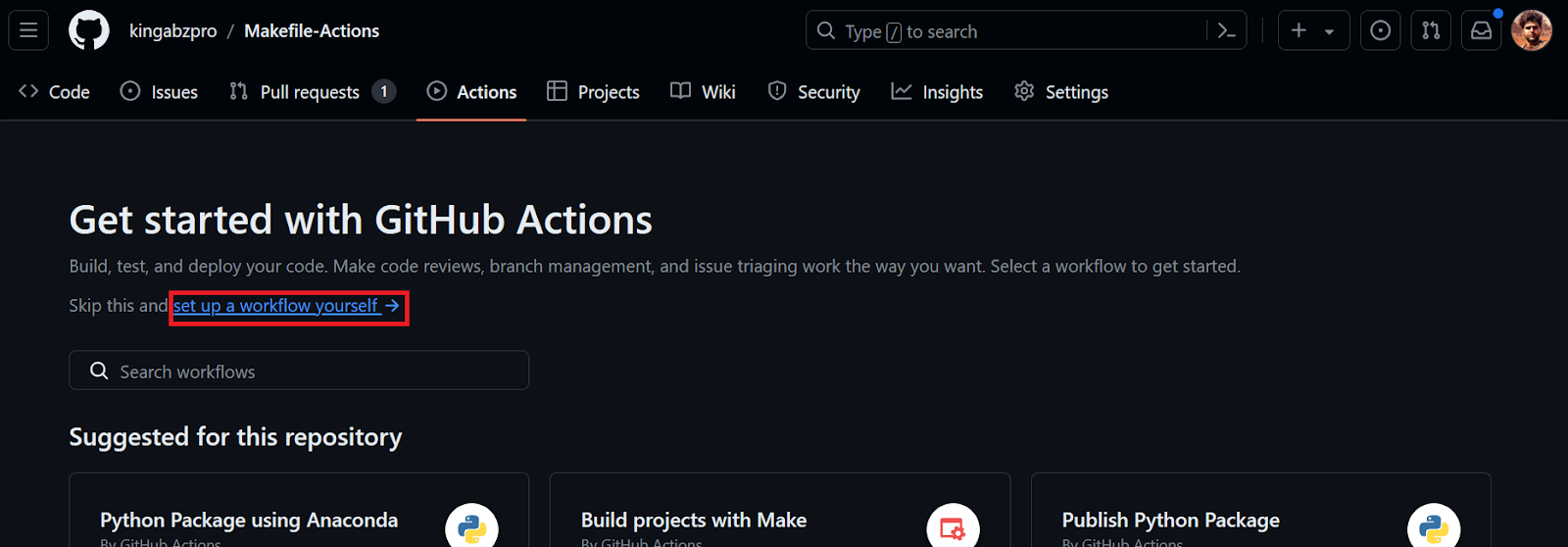
Se nos redirigirá al archivo YML, donde escribiremos todo el código para configurar el entorno y ejecutar los comandos. Lo haremos:
main o haya una solicitud de pull en la rama main.name: Data Processing and Analysis
on:
push:
branches: [ "main" ]
pull_request:
branches: [ "main" ]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Install Packages
run: |
pip install --upgrade pip
pip install -r requirements.txt
- name: Format
run: black *.py --line-length 88
- name: Data Processing
env:
RAW_DATA_DIR: "./raw_data/WHR2023.csv"
run: python data_processing.py $RAW_DATA_DIR
- name: Data Analysis
env:
CLEAN_DATA_DIR: "./processed_data/WHR2023_cleaned.csv"
run: python data_analysis.py $CLEAN_DATA_DIRDespués de confirmar el archivo de flujo de trabajo con el mensaje, se iniciará automáticamente la ejecución del flujo de trabajo.
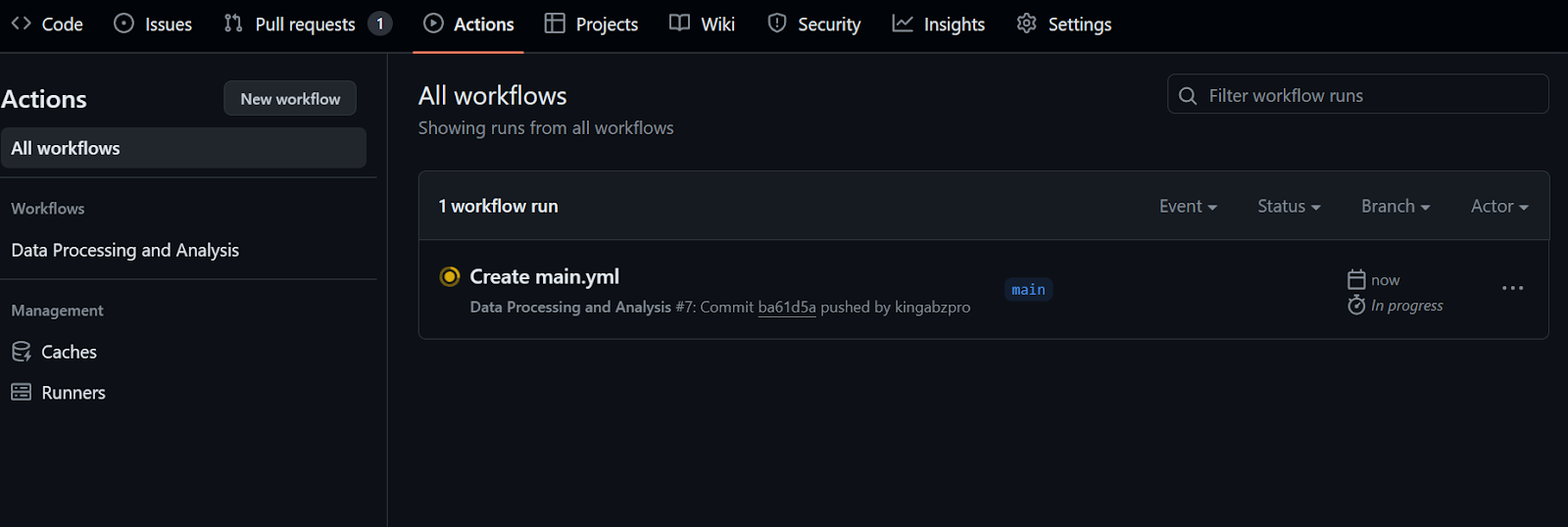
Tardarás al menos 20 segundos en terminar todos los pasos.
Para comprobar los registros, primero hacemos clic en la ejecución del flujo de trabajo, luego en el botón Construir y, a continuación, hacemos clic en cada trabajo para acceder a los registros.
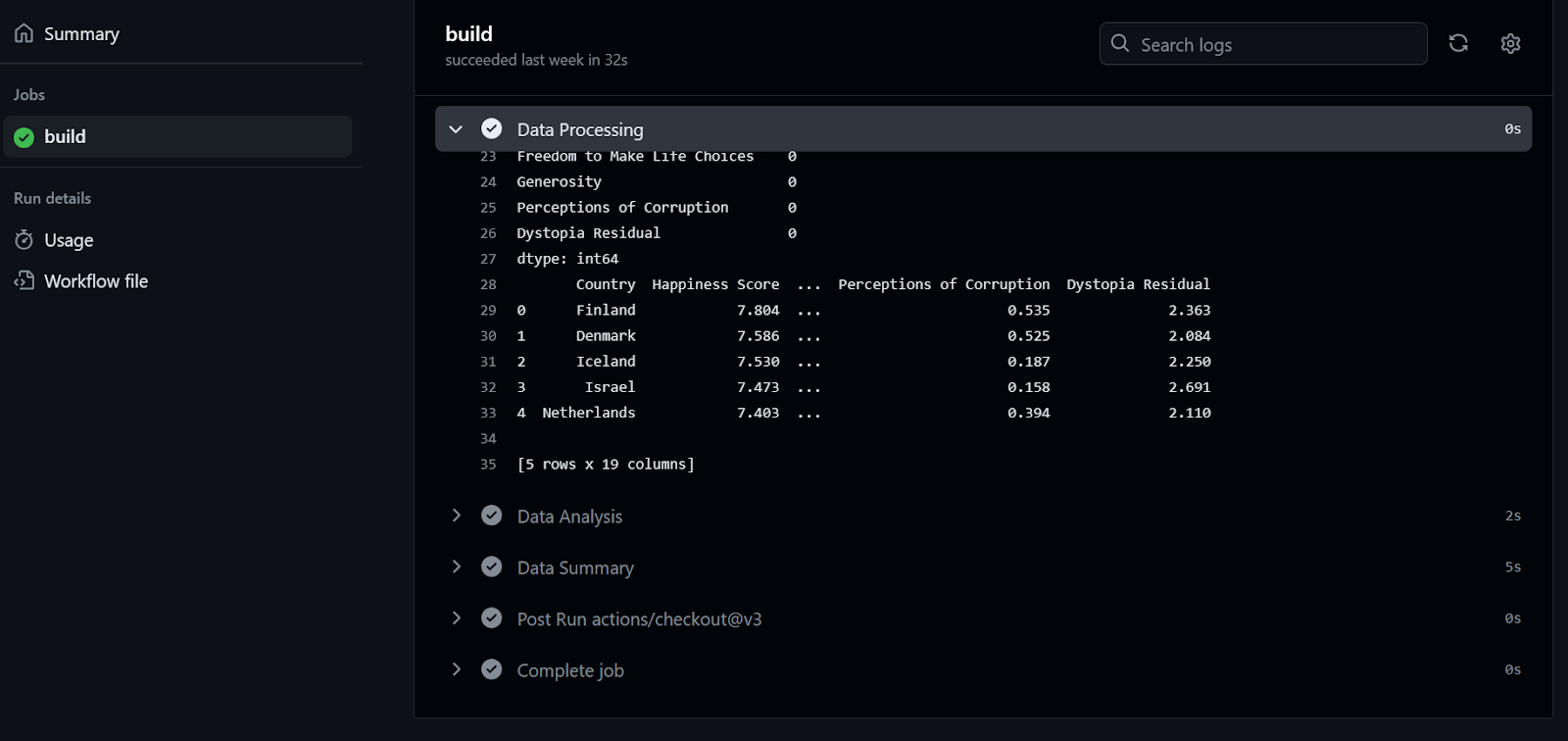
Si esto te ha parecido divertido, seguro que disfrutarás con esta Guía para principiantes sobre CI/CD para el aprendizaje automático, que cubre los aspectos básicos de la creación y automatización de un flujo de trabajo de aprendizaje automático.
Para simplificar y estandarizar los flujos de trabajo de las Acciones de GitHub, los desarrolladores utilizan comandos Make dentro del archivo del flujo de trabajo. En esta sección, aprenderemos a simplificar el código de nuestro flujo de trabajo mediante el comando Make y aprenderemos a utilizar la acción de aprendizaje automático continuo (CML).
Antes de empezar, tenemos que extraer el archivo de flujo de trabajo del repositorio remoto.
$ git pullContinuous Machine Learning (CML) es una biblioteca de código abierto de iterative.ai que nos permite implementar la integración continua en nuestro proyecto de ciencia de datos.
En este proyecto, utilizaremos la Acción GitHub iterative/setup-cml que utiliza funciones CML en el flujo de trabajo para generar el informe de análisis con cifras y estadísticas de datos.
El informe se creará y adjuntará a nuestro commit de GitHub para que nuestro equipo lo revise y apruebe antes de fusionarlo.
Modificaremos el Makefile y añadiremos otro objetivo "resumen". Ten en cuenta que:
cml para crear un informe analítico de datos y mostrarlo bajo los comentarios de confirmación.Imagina añadir tantas líneas al archivo de flujo de trabajo de GitHub: sería difícil de leer y modificar. En su lugar, utilizaremos make summary.
Archivo: Makefile
summary: ./processed_data/summary.txt
echo "# Data Summary" > report.md
cat ./processed_data/summary.txt >> report.md
echo '\n# Data Analysis' >> report.md
echo '\n## Correlation Heatmap' >> report.md
echo '' >> report.md
echo '\n## Happiness Score Distribution' >> report.md
echo '' >> report.md
echo '\n## Happiness Score vs GDP per Capita' >> report.md
echo '' >> report.md
echo '\n## Social Support vs Happiness Relationship' >> report.md
echo '' >> report.md
echo '\n## Top 20 Countries by Happiness Score' >> report.md
echo '' >> report.md
cml comment create report.md
Ahora editaremos nuestro archivo main.yml, que podemos encontrar en el directorio .github/workflows.
Cambiamos todos los comandos y scripts de Python con el comando make y damos permiso a la Acción CML para crear el informe de datos en el comentario de confirmación. Además, asegurémonos de no olvidarnos de añadir la Acción iterative/setup-cml@v3 a nuestra ejecución.
name: Data Processing and Analysis
on:
push:
branches: [ "main" ]
pull_request:
branches: [ "main" ]
permissions: write-all
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: iterative/setup-cml@v3
- name: Install Packages
run: make install
- name: Format
run: make format
- name: Data Processing
env:
RAW_DATA_DIR: "./raw_data/WHR2023.csv"
run: make process RAW_DATA_PATH=$RAW_DATA_DIR
- name: Data Analysis
env:
CLEAN_DATA_DIR: "./processed_data/WHR2023_cleaned.csv"
run: make analyze PROCESSED_DATA=$CLEAN_DATA_DIR
- name: Data Summary
env:
REPO_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: make summaryPara ejecutar el flujo de trabajo, sólo tenemos que confirmar todos los cambios y sincronizarlos con la rama remota main.
$ git commit -am "makefile and github action combo"
$ git push github master:main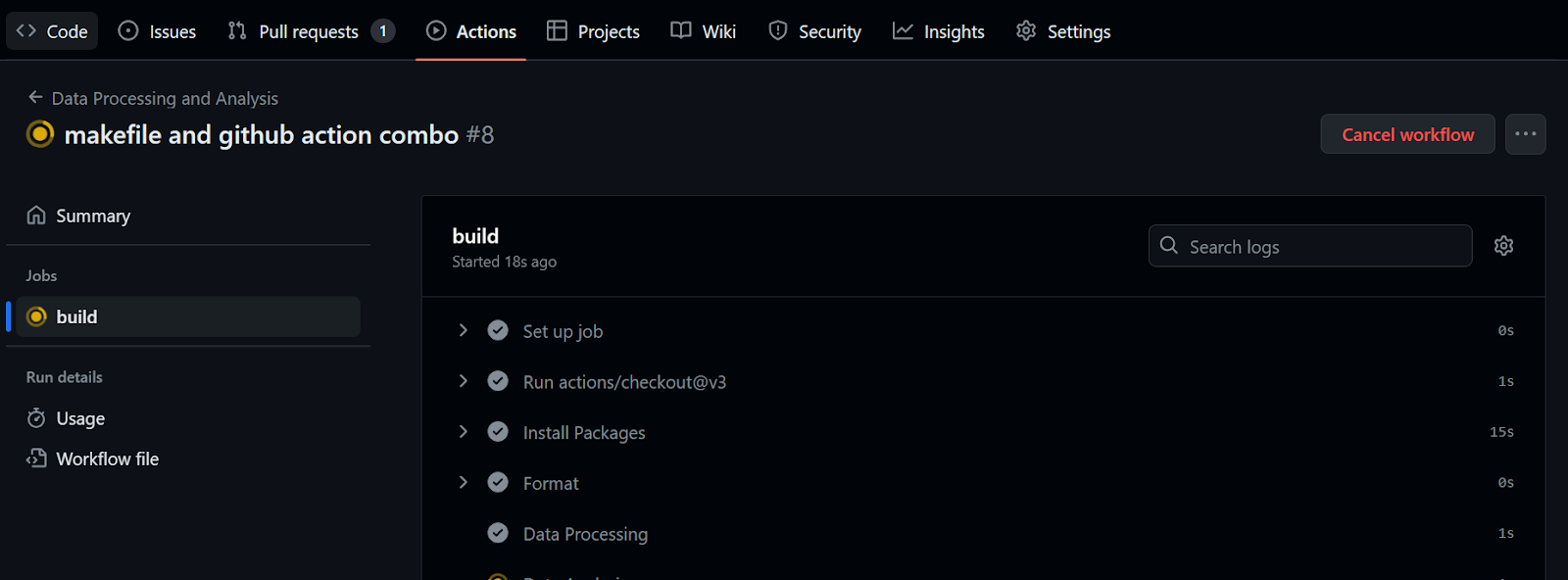
Se tardaron 32 segundos en ejecutar el flujo de trabajo: nuestro informe está listo para ser revisado. Para ello, vamos al resumen de construcción, nos desplazamos hacia abajo para hacer clic en la pestaña Resumen de datos y, a continuación, hacemos clic en el enlace de comentarios (el enlace que ves en la línea 20 de la figura de abajo):
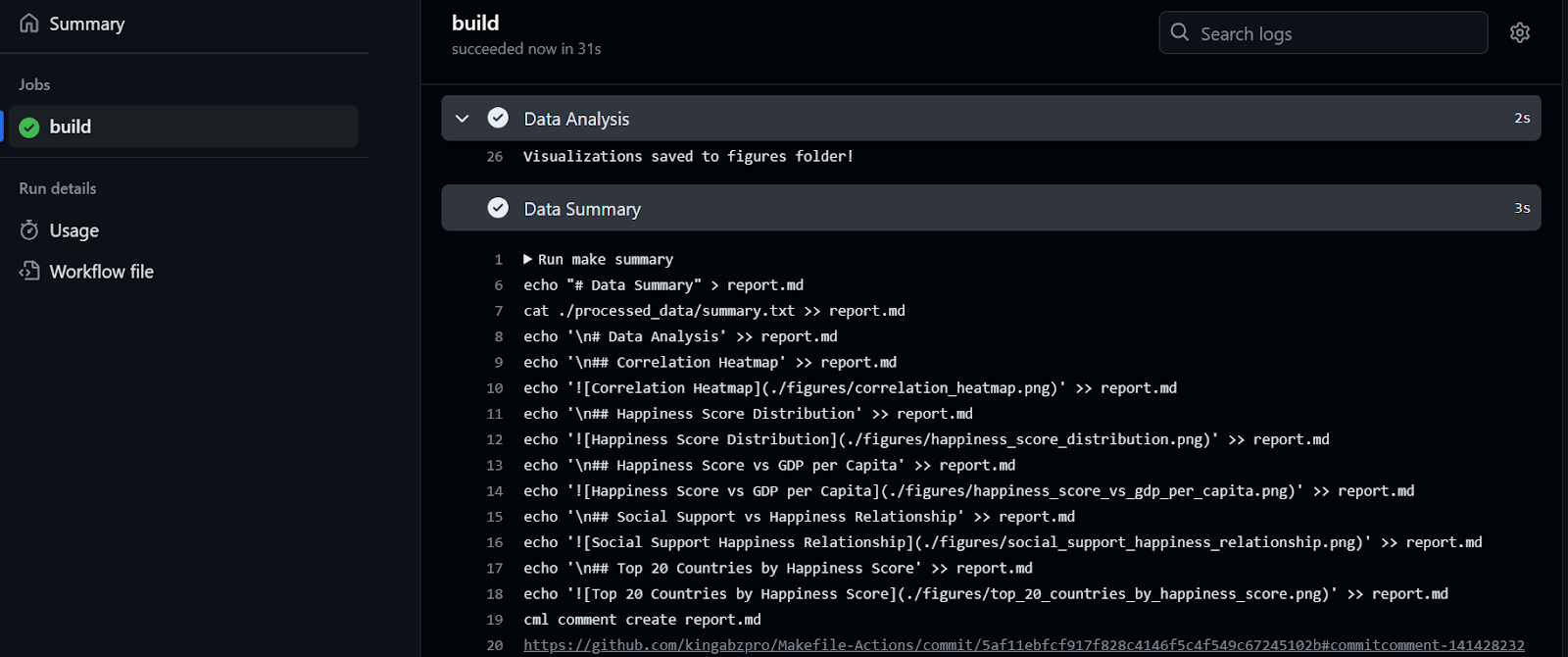
Como podemos ver, el resumen de datos y las visualizaciones de datos se adjuntan a nuestro commit.
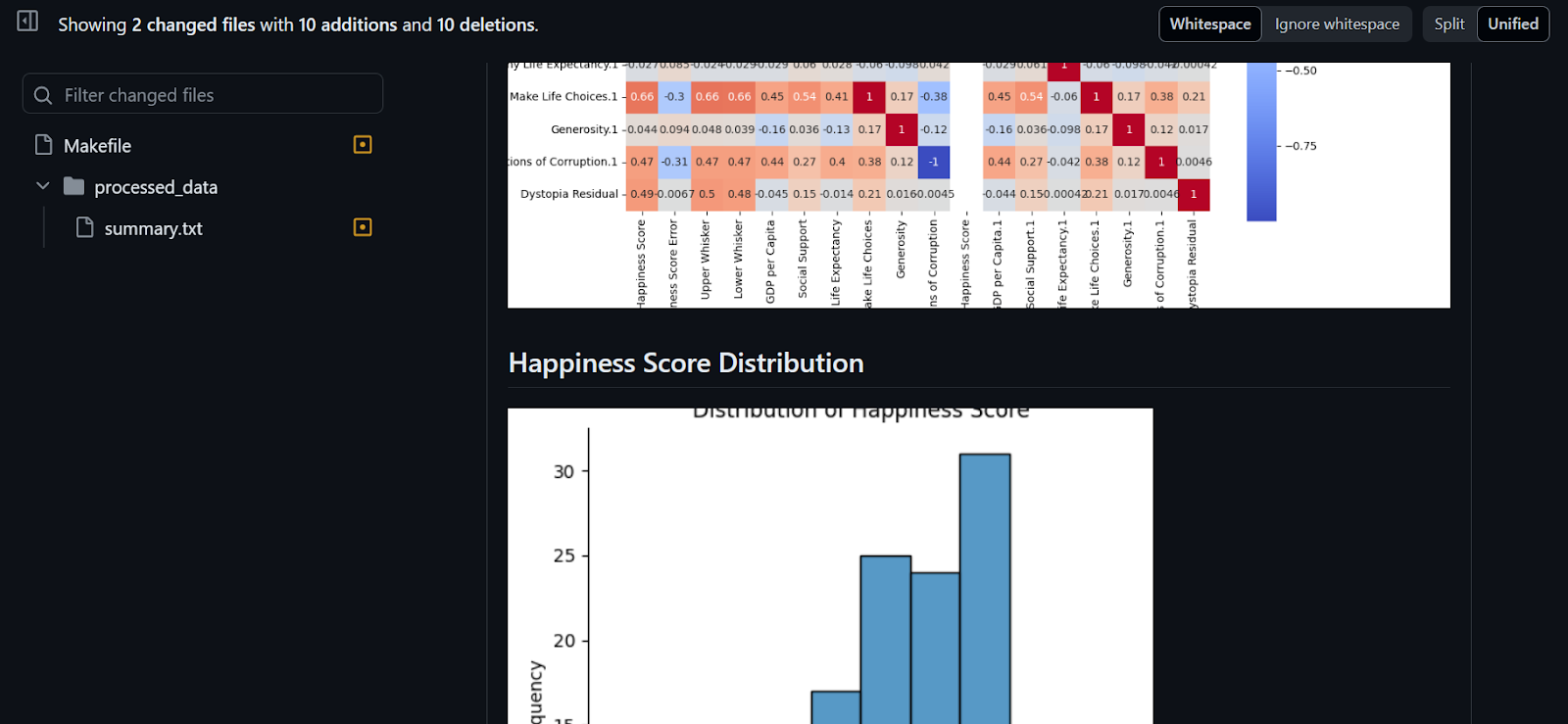
El proyecto está disponible en kingabzpro/Makefile-Actions, y puedes utilizarlo como guía cuando te atasques. El repositorio es público, ¡así que haz un fork y experimenta la magia tú mismo!
En este tutorial, nos centramos en Makefile y las Acciones de GitHub para automatizar la generación de informes analíticos de datos.
También aprendimos a construir y ejecutar el flujo de trabajo y a utilizar la herramienta Make dentro del flujo de trabajo de GitHub para optimizar y simplificar el proceso de automatización. En lugar de escribir varias líneas de código, podemos utilizar make summary para generar un informe de análisis de datos que se adjuntará a nuestro commit.
Si quieres dominar el arte del CI/CD para la ciencia de datos, prueba este curso sobre CI/CD para el Aprendizaje Automático. Cubre los fundamentos de CI/CD, Acciones de GitHub, versionado de datos y automatización de la optimización y evaluación de hiperparámetros de modelos.
¡Conviértete en ingeniero de aprendizaje automático!
programa
programa
Curso
Tutorial
Abid Ali Awan
Tutorial
Olivia Smith
Tutorial
Kurtis Pykes
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
