Manipular los datos manualmente puede retrasar los resultados y ralentizar el avance del proyecto. Por eso los ingenieros y analistas de datos siempre buscan LLM más rápidos y baratos para realizar las tareas diarias.
Dolly es un modelo de IA de código abierto de Databricks que, entre otras cosas, puede ayudar a analistas, ingenieros y otros profesionales a facilitar su trabajo en diversos sectores. Como es de código abierto, cualquiera puede utilizar su código de formación para construir LLM mejores y más personalizados según sus necesidades.
Vamos a aprender más sobre esto en nuestro tutorial Dolly de Databricks.
¿Por qué Databricks Dolly?
Lo que hace que Databricks Dolly sea una gran alternativa a otras herramientas es su enfoque para crear soluciones personalizadas para empresas de todos los tamaños. Transforma los LLM de tecnologías exclusivas y de alto coste a herramientas versátiles que toda empresa puede poseer y personalizar.

Fuente: Databricks
Las ventajas de Dolly
Así es como Dolly puede ayudarte:
- Personalización: Personaliza los LLM según las necesidades de tu organización, facilitando la gestión de los flujos de trabajo.
- Rentable: Facilita la creación de modelos personalizados de seguimiento de la instrucción de forma barata y eficaz.
- Ágil: Permite a las empresas optimizar sus flujos de trabajo de datos, automatizar procesos complejos y generar conocimientos de forma más eficaz.
- Accesible: Aumenta la eficacia operativa haciendo que la IA avanzada sea más accesible y adaptable a los casos de uso empresarial.
- Seguro: Presenta una solución viable para desarrollar aplicaciones de IA sin desencadenar problemas de seguridad de los datos o de cumplimiento normativo, comúnmente asociados a las herramientas que dependen de API.
¿Quieres saber más sobre lo que son capaces de hacer los grandes modelos lingüísticos? Haz este curso sobre conceptos LLM.
Primeros pasos con Databricks Dolly
Ahora, veamos cómo puedes utilizar Dolly para tus necesidades.
Visión general de la funcionalidad de Databricks Dolly
Dolly se afina en un conjunto de datos especializado databricks-dolly-15k para desbloquear funcionalidades similares a modelos más masivos como GPT. Por eso puedes crear LLM personalizados para aportar ideas, generar texto y realizar tareas específicas a la carta.
Configurar tu entorno en Databricks Dolly
Sigue estas instrucciones para configurar tu entorno Dolly de Databricks para la generación de respuestas.
Si tienes una máquina con GPU A100, puedes utilizar este modelo con la biblioteca de transformadores.
Paso 1: Ejecuta el siguiente código en tu bloc de notas Databricks para instalar las bibliotecas transformers y accelerate:
%pip install "accelerate>=0.16.0,<1" "transformers[torch]>=4.28.1,<5" "torch>=1.13.1,<2"Paso 2: A continuación, importa la tubería de la biblioteca de transformadores:
from transformers import pipeline
import torch
instruct_pipeline = pipeline(model="databricks/dolly-v2-12b", torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto")Paso 3: A continuación, puedes generar respuestas a partir de la canalización:
instruct_pipeline("Explain to me the difference between nuclear fission and fusion.")Trabajar con Databricks Dolly LLM
Operaciones básicas con Dolly
Estas son algunas de las operaciones básicas que puedes realizar con Dolly:
Generación de texto
- Los escritores y creadores de contenidos pueden generar borradores, esquemas o escritos completos sobre cualquier tema. Esto les ahorrará tiempo y esfuerzo en el proceso de redacción.
- Las empresas y los vendedores pueden crear textos atractivos, descripciones de productos o campañas de marketing.

Diferencia entre el resultado del modelo original y los resultados ajustados de Dolly. [Fuente: Databricks]
Lluvia de ideas
- Los empresarios y líderes empresariales pueden explorar nuevos productos, servicios o modelos de negocio potenciales.
- Escritores, artistas y diseñadores pueden utilizar Dolly en busca de inspiración e ideas excepcionales para incitar sus proyectos creativos.
- Incluso puedes hacer una lluvia de ideas en entornos personales para planificar eventos o afrontar retos cotidianos.

Diferencia entre el resultado del modelo original y los resultados ajustados de Dolly. [Fuente: Databricks]
Preguntas y respuestas abiertas
- Los alumnos pueden hacer preguntas y recibir explicaciones en profundidad sobre temas complejos.
- Los profesionales e investigadores pueden solicitar información de fondo sobre temas concretos.
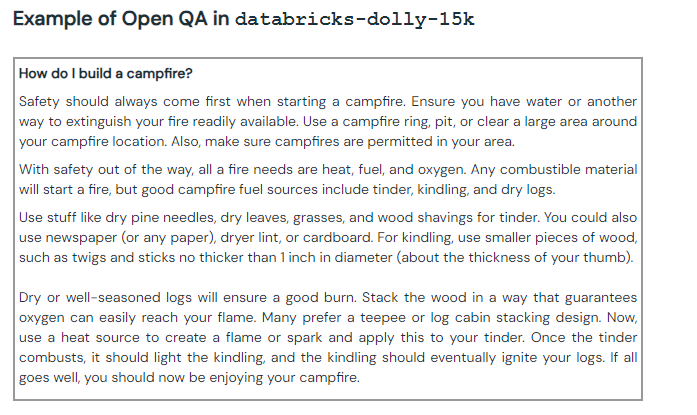
Ejemplo de pregunta/respuesta abierta con Dolly. [Fuente: Databricks]
Técnicas avanzadas
Dolly no se limita a las operaciones básicas; también puedes aplicarle varias técnicas avanzadas:
Ajuste fino de los datos personalizados
Puedes utilizar modelos lingüísticos preentrenados más grandes como base para afinar tus LLM personalizados. Esto mejorará su capacidad de seguir instrucciones y te permitirá realizar tareas adaptadas a tus necesidades.
Conservación de datos de instrucción específicos del ámbito
Para especializar tus LLM en sectores concretos, complementa los datos de instrucción estándar con indicaciones personalizadas adaptadas a cualquier ámbito que desees (sanidad, finanzas, ingeniería, etc.).
Afinando conjuntos de datos específicos que contengan vocabulario, formatos y conocimientos, el modelo puede proporcionar resultados precisos y relevantes, contextualizados para el lenguaje y las convenciones de ese dominio.
Incorpora entradas de datos dinámicas
Puedes entrenar tu modelo para que incorpore entradas dinámicas como imágenes, vídeo y datos de audio. Esto le permitirá ir más allá de la comprensión del texto y generar contenidos que extraigan ideas de múltiples flujos de datos simultáneamente.
Construir aplicaciones con Databricks Dolly
Aunque el Dolly original proporciona capacidades operativas básicas, puedes modificar el modelo existente para crear aplicaciones como los chatbots.
Crear un chatbot
Puedes crear un chatbot personalizado utilizando databricks dolly en dos partes.
Preparación de datos y creación de bases de datos vectoriales
Para crear un chatbot, primero tienes que configurar la base de datos vectorial de Databricks (Chroma) para recopilar e ingerir datos mediante Databricks Lakehouse, Delta Lake y Delta Live Tables.
Primero, instala las bibliotecas necesarias.
%pip install -U chromadb==0.3.22 langchain==0.0.164 transformers==4.29.0 accelerate==0.19.0Ejecuta el siguiente comando en tu bloc de notas Databricks.
%run ./_resources/00-init $catalog=hive_metastore $db=dbdemos_llmAhora, supón que estás construyendo un chatbot de jardinería.
Nota: Si quieres probar tú mismo esta demostración, asegúrate de configurar las demostraciones db en el bloc de notas Databricks.
1. Como estamos trabajando con un conjunto de datos de jardinería de muestra de dbdemos, extrae el conjunto de datos utilizando el comando "sh".
%sh
#To keep it simple, we'll download and extract the dataset using standard bash commands
#Install 7zip to extract the file
apt-get install -y p7zip-full
rm -r /tmp/gardening
mkdir -p /tmp/gardening
cd /tmp/gardening
#Download & extract the gardening archive
curl -L https://archive.org/download/stackexchange/gardening.stackexchange.com.7z -o gardening.7z
7z x gardening.7z
#Move the dataset to our main bucket
mkdir -p /dbfs/dbdemos/product/llm/gardening/raw
cp -f Posts.xml /dbfs/dbdemos/product/llm/gardening/raw2. Ahora, puedes comprobar la información del conjunto de datos.
%fs ls /dbdemos/product/llm/gardening/raw
Limpieza y preparación de Q/As:
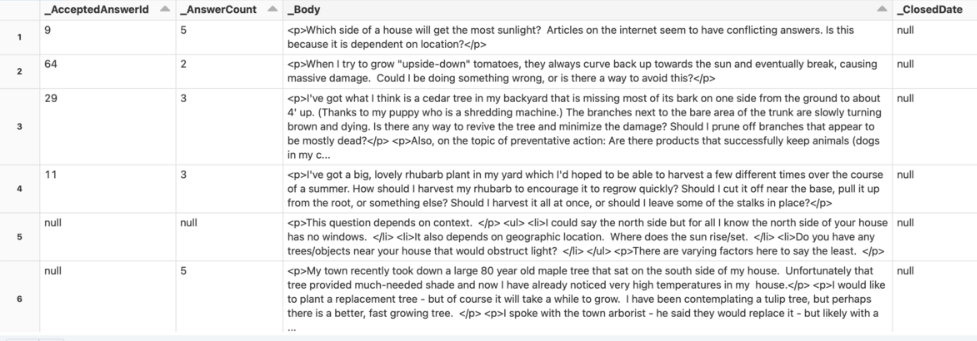
1. Revisa el conjunto de datos sin procesar.
gardening_raw_path = demo_path+"/gardening/raw"
print(f"loading raw xml dataset under {gardening_raw_path}")
raw_gardening = spark.read.format("xml").option("rowTag", "row").load(f"{gardening_raw_path}/Posts.xml")
display(raw_gardening)
2. El código siguiente convierte una cadena con formato HTML en texto y utiliza BeautifulSoup para analizar el HTML y extraer el texto.
from bs4 import BeautifulSoup
#UDF to transform html content as text
@pandas_udf("string")
def html_to_text(html):
return html.apply(lambda x: BeautifulSoup(x).get_text())
gardening_df =(raw_gardening
.filter("_Score >= 5") # keep only good answer/question
.filter(length("_Body") <= 1000) #remove too long questions
.withColumn("body", html_to_text("_Body"))
#Convert html to text
.withColumnsRenamed({"_Id": "id", "_ParentId": "parent_id"})
.select("id", "body", "parent_id"))
# Save 'raw' content for later loading of questions
gardening_df.write.mode("overwrite").saveAsTable(f"gardening_dataset")
display(spark.table("gardening_dataset"))
3. Ahora, empareja las preguntas y las respuestas.
gardening_df = spark.table("gardening_dataset")
# Self-join to assemble questions and answers
qa_df = gardening_df.alias("a").filter("parent_id IS NULL") \
.join(gardening_df.alias("b"), on=[col("a.id") == col("b.parent_id")]) \
.select("b.id", "a.body", "b.body") \
.toDF("answer_id", "question", "answer")
# Prepare the training dataset: question following with the best answers.
docs_df = qa_df.select(col("answer_id"), F.concat(col("question"), F.lit("\n\n"), col("answer"))).toDF("source", "text")
display(docs_df)
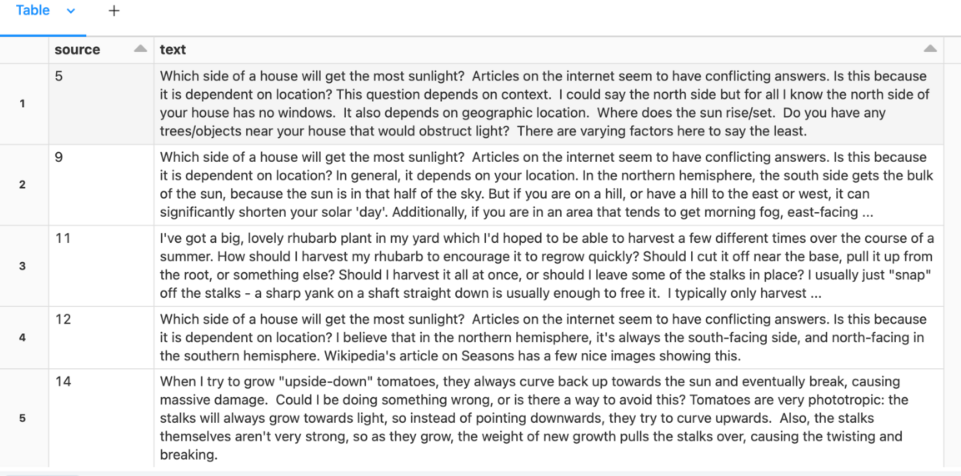
Convierte documentos a representación vectorial:
from langchain.embeddings import HuggingFaceEmbeddings
# Download model from Hugging face
hf_embed = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")Indexa documentos en la base de datos vectorial Databricks para mejorar la búsqueda:
dbutils.widgets.dropdown("reset_vector_database", "false", ["false", "true"], "Recompute embeddings for chromadb")
gardening_vector_db_path = demo_path+"/vector_db"
# Don't recompute the embeddings if they're already available
compute_embeddings = dbutils.widgets.get("reset_vector_database") == "true" or is_folder_empty(gardening_vector_db_path)
if compute_embeddings:
print(f"creating folder {gardening_vector_db_path} under our blob storage (dbfs)")
dbutils.fs.rm(gardening_vector_db_path, True)
dbutils.fs.mkdirs(gardening_vector_db_path)4. Ahora, crea la base de datos de documentos almacenando tu conjunto de datos dentro de la BD vectorial.
from langchain.docstore.document import Document
from langchain.vectorstores import Chroma
# Import if you want to divide Chunk.
# from langchain.text_splitter import CharacterTextSplitter
all_texts = spark.table("gardening_training_dataset")
print(f"Saving document embeddings under /dbfs{gardening_vector_db_path}")
if compute_embeddings:
# Convert lines as langchain Documents.
# If you want to index for shorter time periods, use the text_short field instead.
documents = [Document(page_content=r["text"], metadata={"source": r["source"]}) for r in all_texts.collect()]
# Long sentences may need to be split. But it's best to summarize as above.
# text_splitter = CharacterTextSplitter(separator="\n", chunk_size=1000, chunk_overlap=100)
# documents = text_splitter.split_documents(documents)
# Initialize chromadb with sentence-transformers/all-mpnet-base-v2 model loaded from hugging face (hf_embed).
db = Chroma.from_documents(collection_name="gardening_docs", documents=documents, embedding=hf_embed, persist_directory="/dbfs"+gardening_vector_db_path)
db.similarity_search("dummy") # tickle it to persist metadata (?)
db.persist()Esto guardará las incrustaciones del documento en /dbfs/dbdemos/product/llm/vector_db
Y ya está: tu conjunto de datos Q/A está listo.
Sin embargo, una vez que hayas terminado, reinicia tu núcleo Python para liberar la memoria.
Ingeniería rápida para preguntas y respuestas
En este paso, haces una pregunta y el sistema obtiene contenido similar del conjunto de datos de Preguntas y Respuestas. A continuación, elabora una consulta con el contenido y la envía a Dolly, que genera una respuesta para mostrársela al cliente.
He aquí cómo puedes hacerlo:
- Descarga 2 incrustaciones de cara abrazada:
# Start here to load a previously-saved DB
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
if len(get_available_gpus()) == 0:
Exception("Running dolly without GPU will be slow. We recommend you switch to a Single Node cluster with at least 1 GPU to properly run this demo.")
gardening_vector_db_path = "/dbfs"+demo_path+"/vector_db"
hf_embed = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")
db = Chroma(collection_name="gardening_docs", embedding_function=hf_embed, persist_directory=gardening_vector_db_path)2. Ahora, realiza una comprobación de similitud entre las preguntas.
def get_similar_docs(question, similar_doc_count):
return db.similarity_search(question, k=similar_doc_count)
# Let's test it with blackberries:
for doc in get_similar_docs("how to grow blackberry?", 2):
print(doc.page_content)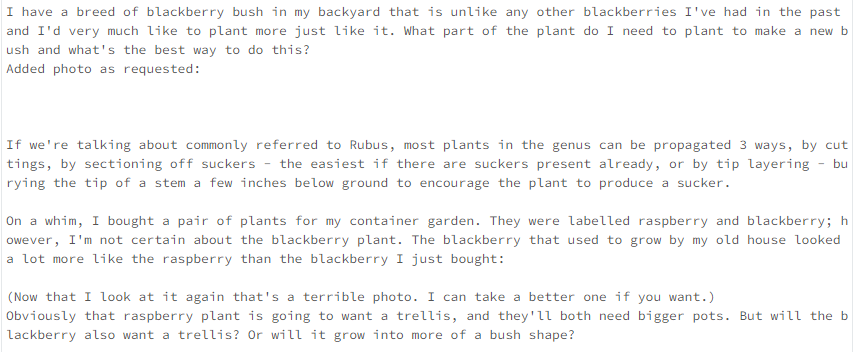
3. Utiliza un modelo lingüístico y pídele que construya un sistema que responda a preguntas utilizando LangChain.
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
import torch
from langchain import PromptTemplate
from langchain.llms import HuggingFacePipeline
from langchain.chains.question_answering import load_qa_chain
def build_qa_chain():
torch.cuda.empty_cache()
model_name = "databricks/dolly-v2-7b" # can use dolly-v2-3b or dolly-v2-7b for smaller models and faster inferences.
# Increase max_new_tokens for a longer response
# Other settings might give better results! Play around
instruct_pipeline = pipeline(model=model_name, torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto",
return_full_text=True, max_new_tokens=256, top_p=0.95, top_k=50)
# Note: if you use dolly 12B or smaller model but a GPU with less than 24GB RAM, use 8bit. This requires %pip install bitsandbytes
# Defining our prompt content.
# langchain will load our similar documents as {context}
template = """Below is an instruction that describes a task. Write a response that appropriately completes the request.
Instruction:
You are a gardener and your job is to help provide the best gardening answer.
Use only information in the following paragraphs to answer the question at the end. Explain the answer with reference to these paragraphs. If you don't know, say that you do not know.
{context}
Question: {question}
Response:
"""
prompt = PromptTemplate(input_variables=['context', 'question'], template=template)
hf_pipe = HuggingFacePipeline(pipeline=instruct_pipeline)
# Set verbose=True to see the full prompt:
return load_qa_chain(llm=hf_pipe, chain_type="stuff", prompt=prompt, verbose=True)# Building the chain will load Dolly and can take several minutes depending on the model size
qa_chain = build_qa_chain()Los ajustes clave que influyen en el rendimiento son:
- ‘Max_new_tokens’ : Reduce para obtener resultados más rápidos y concisos.
- ‘Num_beams’ : Con la búsqueda de haces, más haces aumentan el tiempo de ejecución de forma aproximadamente lineal.
4. Ya está. Ahora, puedes definir la función para responder preguntas sencillas.
def answer_question(question):
similar_docs = get_similar_docs(question, similar_doc_count=2)
result = qa_chain({"input_documents": similar_docs, "question": question})
result_html = f"<p><blockquote style=\"font-size:24\">{question}</blockquote></p>"
result_html += f"<p><blockquote style=\"font-size:18px\">{result['output_text']}</blockquote></p>"
result_html += "<p><hr/></p>"
for d in result["input_documents"]:
source_id = d.metadata["source"]
result_html += f"<p><blockquote>{d.page_content}<br/>(Source: <a href=\"https://gardening.stackexchange.com/a/{source_id}\">{source_id}</a>)</blockquote></p>"
displayHTML(result_html)Ahora puedes hacerle una pregunta relacionada con la jardinería.
answer_question("What is the best kind of soil to grow blueberries in?")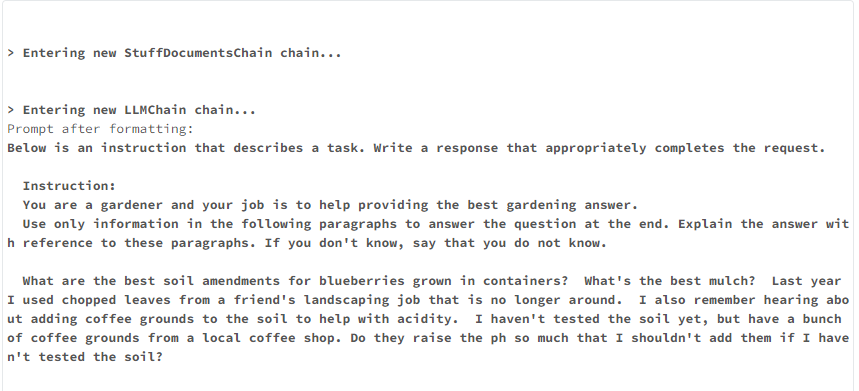

Consulta dbdemo para construir un chatbot aquí.
Casos prácticos reales
Con sus avanzadas capacidades de PNL, los LLM personalizados hechos con Dolly pueden utilizarse en muchos casos del mundo real, y aquí tienes algunos de los ejemplos más comunes:
1. Resumen automatizado de datos para analistas financieros
Dolly puede procesar grandes conjuntos de datos y generar resúmenes concisos para ayudar a los analistas a comprender más rápidamente las ideas clave.
Por ejemplo, un investigador financiero puede necesitar comprender rápidamente las tendencias históricas de los precios de las acciones. Dolly podía analizar los datos y proporcionar una visión clara, ahorrando al investigador un tiempo valioso.
2. Limpieza y preprocesamiento de datos en industrias minoristas
En las empresas minoristas, los analistas de datos trabajan con conjuntos de datos masivos que contienen registros de transacciones de miles de tiendas de todo el país. Sin embargo, los datos brutos de las tiendas individuales a menudo contienen incoherencias, valores que faltan, entradas duplicadas y otros errores.
Dolly puede identificar incoherencias, valores perdidos y errores potenciales en los datos, de modo que los científicos de datos puedan utilizar datos limpios para extraer perspectivas significativas y crear visualizaciones.
3. Estar al día de las últimas investigaciones en las industrias farmacéuticas
En las empresas farmacéuticas, los científicos se mantienen al día de las últimas investigaciones publicadas en múltiples disciplinas. Sin embargo, revisar manualmente cientos de nuevos artículos de investigación cada semana consume tiempo.
En su lugar, pueden utilizar Dolly LLM de Databricks para analizar artículos de investigación y extraer elementos clave como objetivos, métodos, resultados y conclusiones. Puede combinar resúmenes de varias páginas y destacar las ideas más destacadas de cada artículo.
Retos y limitaciones
Como cualquier otra tecnología LLM pionera, Dolly tiene algunas limitaciones y retos. Así pues, he aquí tres defectos principales de Dolly:
- Alucina o genera respuestas objetivamente incorrectas, ya que está entrenado con un conjunto de datos mucho menor que ChatGPT.
- Es difícil ajustarlo y adaptarlo a tus necesidades, ya que requiere un cierto nivel de aprendizaje automático y conocimientos de PNL.
- Tiene dificultades para resolver cuestiones matemáticas, programar problemas y añadir sentido del humor en las respuestas.
Mitigar las deficiencias de Dolly LLM
Aunque no existen técnicas confirmadas para mitigar las limitaciones actuales de Dolly, Databricks investiga continuamente y pretende encontrar formas de mejorar sus modelos de IA existentes. Dolly es un ejemplo de ello, actualmente en la versión 2, pero es posible que veamos nuevas mejoras en los próximos años.
Conclusión y próximos pasos
Databricks Dolly es un modelo de IA de código abierto disponible para uso comercial. Puedes utilizar su código de entrenamiento y sus conjuntos de datos para crear LLM específicos que se ajusten a tus necesidades.
Si estás preparado para ir más allá de este tutorial sobre Dolly de Databricks y pulir tus conocimientos actuales, empieza con los siguientes recursos:
- Desarrollar grandes modelos lingüísticos
- Introducción a Databricks
- Seminario en línea: Primeros pasos con Databricks
¡Feliz aprendizaje!