Curso
Trabajar con la API de OpenAI
3 h
142.5K
En el cambiante panorama de la IA, la llegada de grandes modelos lingüísticos ha revolucionado la forma en que interactuamos con el contenido textual y lo generamos. Desde el lanzamiento de ChatGPT de OpenAI en noviembre de 2022, hemos visto una nueva oleada de grandes modelos lingüísticos que se publican a diario.
Entre estos modelos, el Mando Cohere se ha convertido en la primera opción entre los profesionales. Cohere ofrece herramientas de vanguardia para que los desarrolladores y las empresas puedan aprovechar la potencia de los modelos fundacionales en sus aplicaciones y casos de uso.
Esta guía para principiantes pretende describir las ofertas de API de Cohere, proporcionando una exploración en profundidad de sus capacidades, ventajas y estrategias prácticas de implementación.
Comenzaremos con una rápida visión general de los grandes modelos lingüísticos, pero si buscas un enfoque más exhaustivo, consulta este curso sobre Grandes Modelos Lingüísticos (LLM).
Los Grandes Modelos Lingüísticos (LLM) son sistemas avanzados de IA que comprenden y generan textos similares a los humanos. Se les entrena con grandes cantidades de datos para que capten patrones complejos, comprendan los matices del lenguaje y generen respuestas coherentes.
Los LLM pueden realizar varias tareas relacionadas con el lenguaje, como traducir, completar textos, resumir e interactuar en conversaciones.
Cohere es un actor clave en este espacio, ya que ofrece una API fácil de usar que permite a los científicos de datos acceder a estas capacidades LLM, agilizando sus flujos de trabajo.
Fundada en 2019, Cohere es una empresa canadiense dedicada a crear soluciones de inteligencia artificial para empresas. Se ha convertido rápidamente en una figura importante en la industria de los grandes modelos lingüísticos (LLM), mencionada con frecuencia junto a competidores como OpenAI GPT y Anthropic Claude.
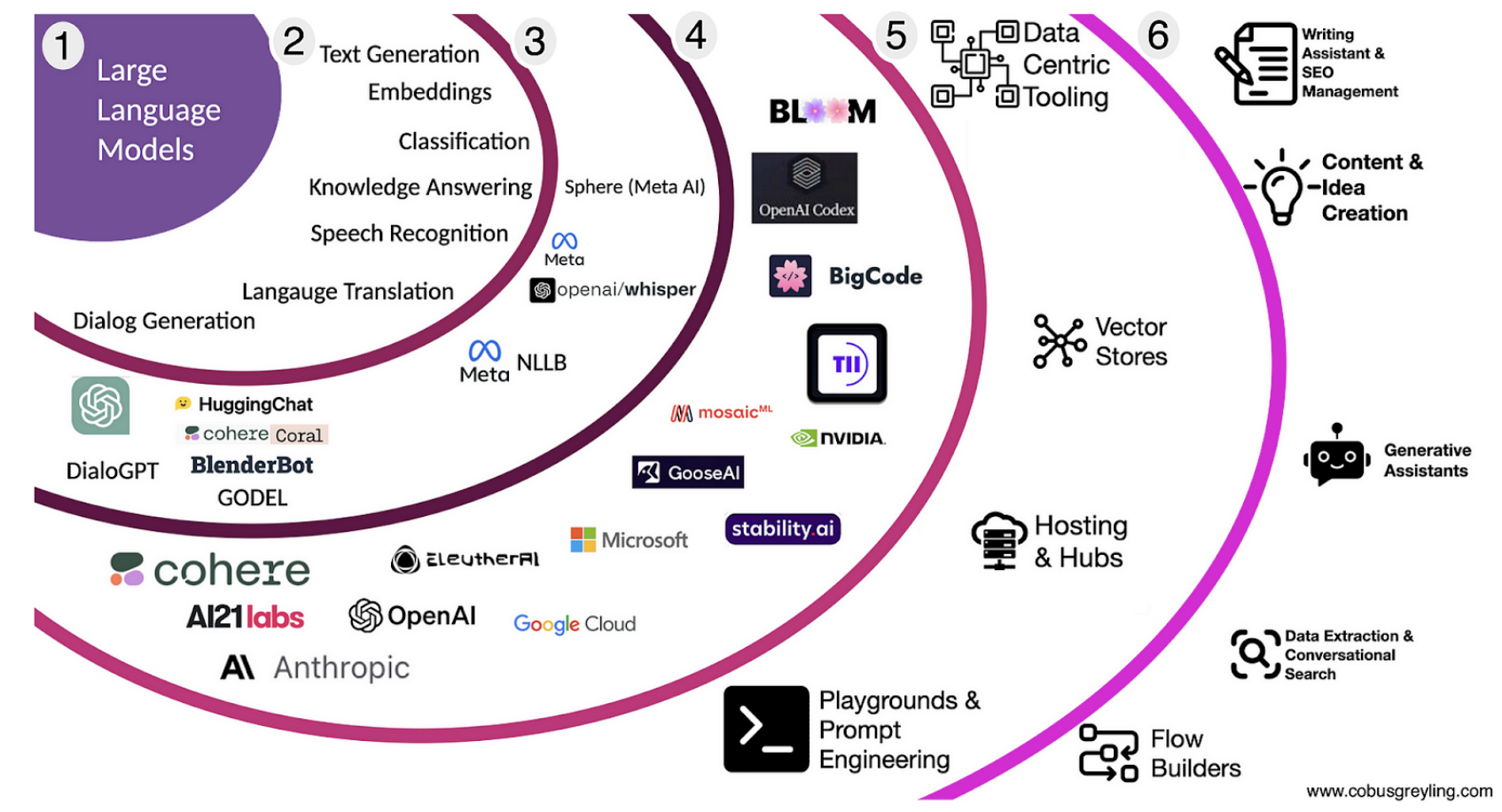
Fuente: Cobus Greyling, Modelo lingüístico grande Paisaje, Mediano
Principalmente, Cohere desarrolla y proporciona modelos fundacionales para la generación de lenguajes, accesibles a desarrolladores y empresas principalmente a través de su servicio API.
Cohere ofrece principalmente tres tipos diferentes de modelos:
Podemos acceder a los modelos Cohere de dos formas:
Cohere también ofrece una interfaz de chat exclusiva similar a ChatGPT, potenciada por Command R+ bajo el capó.
Cohere Playground proporciona una interfaz fácil de usar para interactuar con los Modelos Cohere, ofreciendo una experiencia intuitiva similar a trabajar con GPT.
Los usuarios pueden explorar y experimentar con diversas capacidades del modelo, generando texto y obteniendo información sobre su comportamiento. Con un diseño elegante y accesible, Cohere Playground permite a los usuarios crear prototipos y probar rápidamente las ofertas de modelos de Cohere.
Cohere Playground es gratuito para que los usuarios exploren y experimenten con modelos (es gratuito hasta que pasas a producción).
Para utilizar Cohere Playground, primero tenemos que registrarnos en el sitio web de Cohere.
A continuación, podemos iniciar sesión y aterrizaremos en la página que vemos a continuación, que es bastante similar a una zona de juegos de la plataforma OpenAI. Utilizando el desplegable de la derecha, podemos elegir diferentes modelos de Cohere.
El Patio de recreo tiene interfaces ligeramente diferentes para las distintas tareas. Hacia la parte superior, tienes cuatro opciones para elegir: Chatear, Clasificar, Incrustar y Generar.
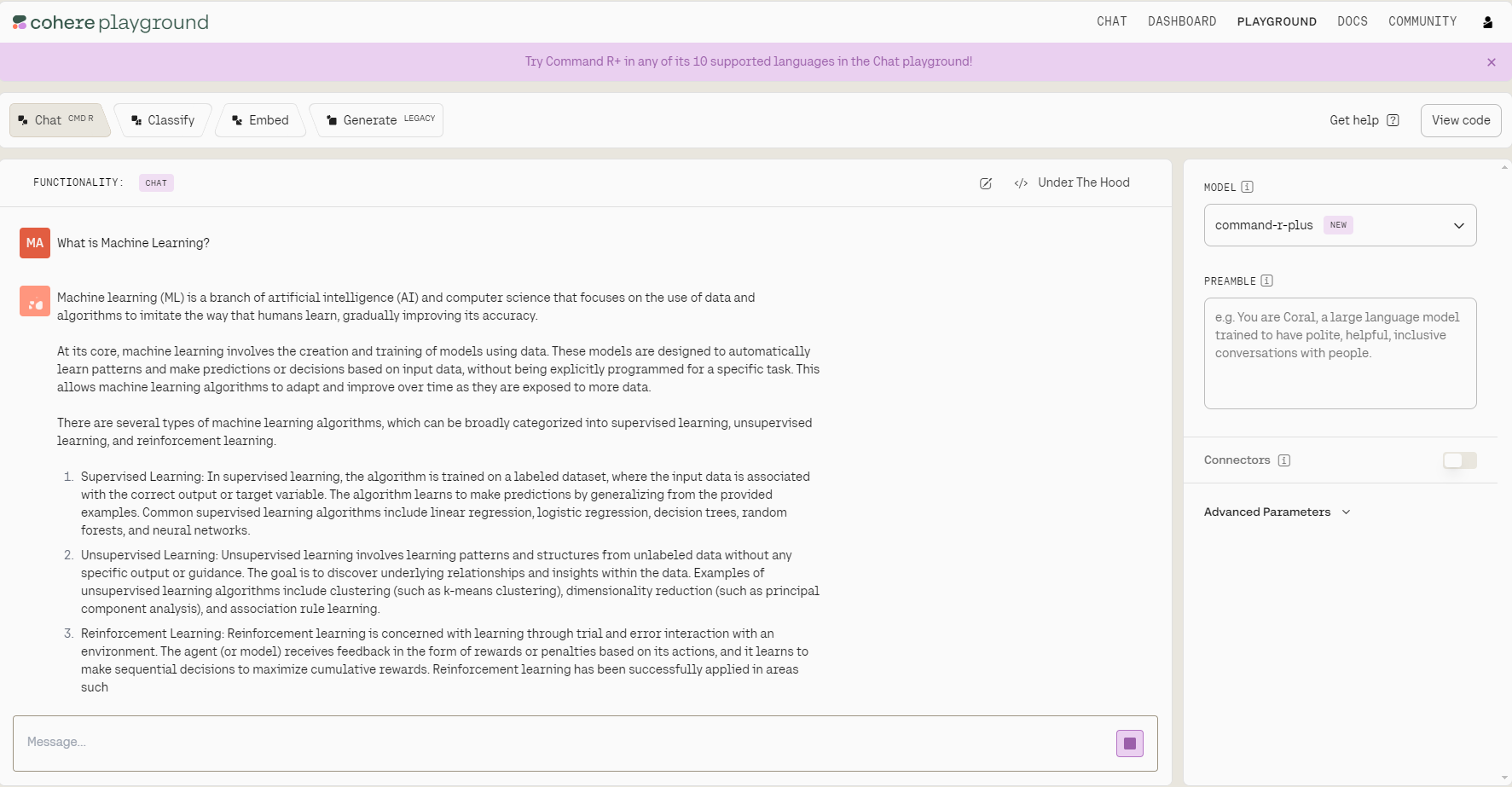
Panel de control de Cohere Playground
Cohere Playground es estupendo para probar rápidamente las capacidades de los modelos Cohere, pero si estás construyendo una aplicación o un flujo de trabajo, necesitas una forma programática de acceder a estos modelos. ¡Ahí es donde entra la API de Cohere!
Acceder a la API de Cohere es bastante sencillo. En pocas palabras, necesitaremos
Analicemos estos pasos uno por uno.
Podemos instalar el cliente cohere utilizando pip.
!pip install cohereAhora, necesitamos una clave API.
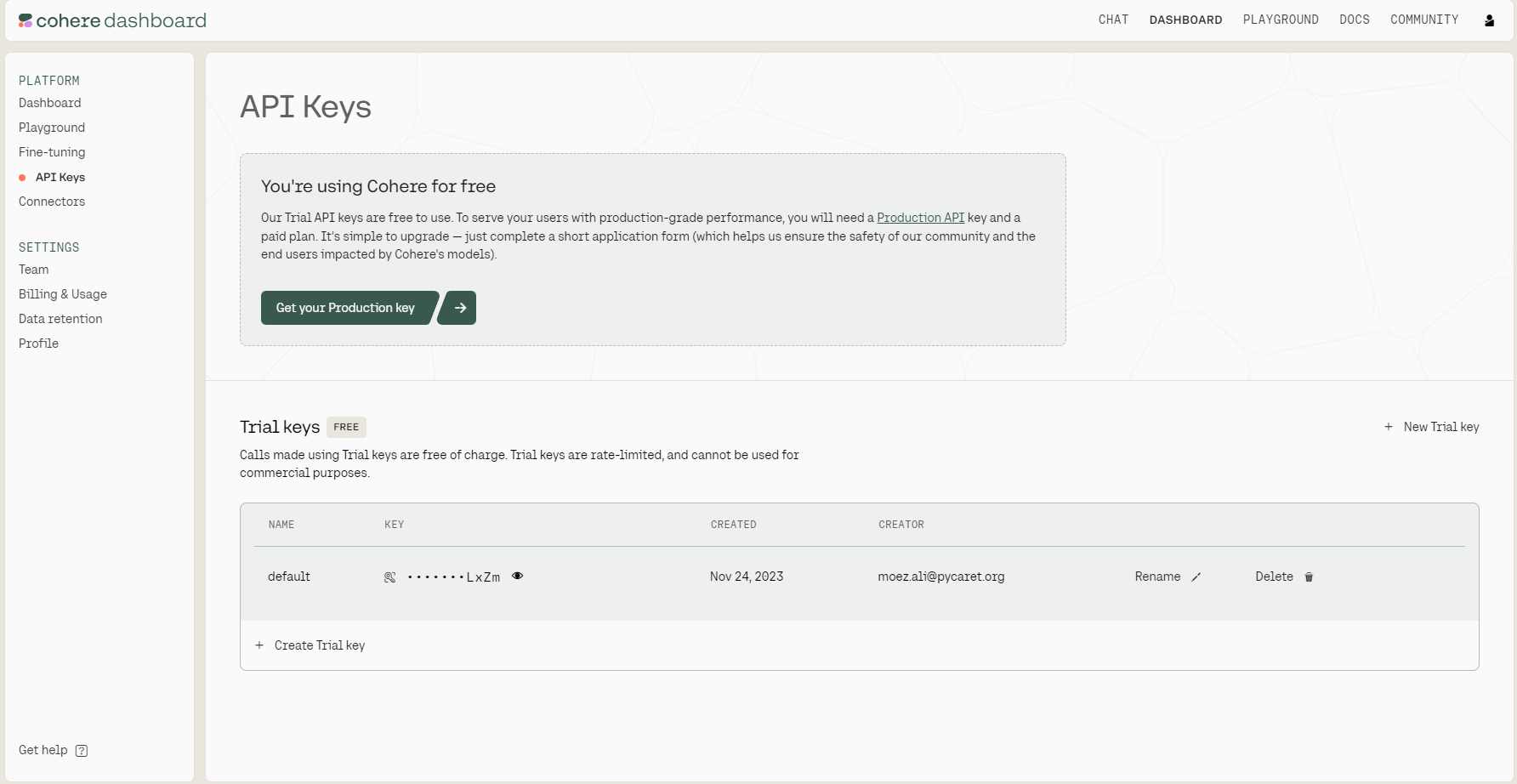
Como podemos ver en la imagen de abajo, hay dos tipos de claves API: de producción y de prueba. Para los fines de este tutorial, sólo necesitamos una clave de prueba. Podemos copiarla haciendo clic en el icono de copia situado junto a la clave.
Ahora que tenemos la biblioteca cohere instalada y nuestra clave API, podemos hacer una llamada a la API. En el código siguiente
cohere para interactuar con su API.Client utilizando nuestra clave API.co.chat().import cohere
co = cohere.Client('your_token_here')
message = "What is Machine Learning?"
response = co.chat(
message=message,
model="command",
temperature=0.3
)
answer = response.text
print(answer)Machine learning is a branch of computer science that focuses on developing algorithms and models that enable computers to learn and make predictions or decisions without being explicitly programmed. It is a key component of artificial intelligence (AI).
Machine Learning allows systems to identify patterns in data, uncover insights, and improve processes through iterative learning. Instead of writing explicit programs, ML enables the creation of models that can analyze data, identify patterns, and predict outcomes. These models are refined and optimized through a process known as training, which involves feeding the models annotated examples or real-world data.
(...)Anteriormente, accedimos a la respuesta utilizando response.text. Pero el objeto respuesta contiene más información, y podemos acceder a él utilizando response.dict()-esto devolverá un archivo JSON que contiene todos los metadatos, incluido el mensaje de respuesta:
response.dict()
{
"text":"Machine Learning (ML) is a ....",
"generation_id":"cebf4874-1e3d-429a-8699-8b9639b943dd",
"finish_reason":"COMPLETE",
"chat_history":[
{
"message":"What is Machine Learning?",
"role":"USER"
},
{
"message":"Machine Learning (ML) is a ....",
"role":"CHATBOT"
}
],
"meta":{
"api_version":{
"version":"1"
},
"billed_units":{
"input_tokens":56,
"output_tokens":252
},
"tokens":{
"input_tokens":67,
"output_tokens":252
}
},
"response_id":"df34a5f8-f1cd-407f-b1b5-5971aa12ae2a"
}Vamos a desglosar cada campo del objeto response:
text: Contiene el mensaje generado por el modelo.generation_id: Contiene el ID asociado a la respuesta generada, que puede utilizarse con el punto final de la API de retroalimentación para resaltar las buenas respuestas e informar de las malas.finish_reason: Indica por qué terminó la generación y puede ser una de las siguientes:COMPLETE: El modelo ha terminado correctamente de generar el mensaje.MAX_TOKENS: Se alcanzó el límite de contexto del modelo antes de que pudiera completarse la generación.chat_history: Contiene la conversación presentada en formato de registro de chat.meta: Contiene información sobre recuentos de fichas, facturación, etc.response_id: Mientras que generation_id se centra en un único intento de generación de texto, response_id identifica todo el objeto de respuesta que contiene ese texto generado y otros datos relevantes.Imagina que estás desarrollando un chatbot diseñado para responder a las consultas de los usuarios. Disponer del contexto de conversaciones anteriores puede permitir que el modelo lingüístico proporcione respuestas más pertinentes.
En las conversaciones multiturno, conservar el contexto de las interacciones anteriores es esencial para generar respuestas coherentes y pertinentes. La API de Cohere facilita esto permitiéndonos incluir el historial de chat a través del parámetro chat_history.
Esto ayuda al modelo a comprender el flujo de la conversación y a responder adecuadamente basándose en los intercambios anteriores. Veamos un ejemplo.
message = "How is this related to Artificial Intelligence?"
response = co.chat(
model="command-r-plus",
chat_history=[
{"role": "USER", "text": "What is Large Language Model?"},
{"role": "CHATBOT", "text": "Large Language Model is a type ..."},
],
message="How is this related to Artificial Intelligence?"
)
print(response.text)Large language models (LLMs) are a key component of artificial intelligence (AI), and their development has played a significant role in advancing the field of AI. Here's how they are related:
1. Language Understanding and Generation: AI aims to create intelligent systems that can understand and respond to human language. LLMs are designed to process and generate human-like language, which is a fundamental aspect of human intelligence. By training on vast amounts of text data, LLMs learn to recognize patterns, syntax, semantics, and context, enabling them to interpret and generate language in a way that is similar to how humans do.
2. Machine Learning and Neural Networks: LLMs are typically built using machine learning techniques, particularly deep learning and neural networks. These are core areas of AI research. Neural networks, inspired by the structure of the human brain, enable LLMs to learn and make connections between different pieces of information. By training on large datasets, LLMs can identify patterns, relationships, and meanings in the data, which is a fundamental aspect of AI.
3. (...)Cuando el usuario preguntó "¿Qué relación tiene esto con la Inteligencia Artificial?", el modelo entendió que "esto" se refería a los grandes modelos lingüísticos (LLM). Esto es gracias al parámetro chat_history, que proporcionó el contexto necesario de las interacciones anteriores. Mantener el contexto en conversaciones de varios turnos es crucial para generar respuestas pertinentes y coherentes.
Esto funciona muy bien, pero no es realista pasar manualmente el chat_history a la API como hicimos en el ejemplo anterior. En lugar de codificar el chat_history, podemos construirlo dinámicamente a medida que mantenemos una conversación.
Hay múltiples formas de conseguirlo. La más sencilla es utilizar conversation_id en la API. Veamos un ejemplo:
# First message
response = co.chat(
model="command-r-plus",
message="What is Large Language Models?",
conversation_id='newuser1',
)
print(response.text)Large Language Models (LLMs) are a type of artificial intelligence model specifically designed to process and generate human language. These models are typically based on deep learning and neural network architectures and are trained on vast amounts of text data. Here's an overview of LLMs and their key characteristics:
1. Definition:
- Large Language Models are machine learning models that are trained on large-scale textual data to understand, generate, and manipulate human language. They aim to capture the complexities of language, including syntax, semantics, and context.
2. Training Data:
- LLMs are trained on massive amounts of text data, often consisting of billions or even trillions of words. This training data can come from various sources such as books, articles, websites, social media, and other text-based documents.
3. (...)Y ahora incitemos al modelo con otro mensaje; fíjate en que conversation_id es coherente con el primer mensaje. Mientras conversation_id se mantenga coherente, la API utilizará automáticamente los mensajes anteriores como contexto.
# Second message
response = co.chat(
model="command-r-plus",
message="How is it related to Artificial Intelligence?",
conversation_id='newuser1',
)
print(response.text)Large Language Models (LLMs) are a crucial component and a powerful manifestation of Artificial Intelligence (AI). Here's how LLMs are closely related to AI:
1. AI Foundation:
- Artificial Intelligence is a broad field that encompasses the development of computer systems capable of performing tasks typically associated with human intelligence. This includes areas like machine learning, natural language processing, computer vision, robotics, and decision-making.
- LLMs fall under the umbrella of AI as they are designed to understand, generate, and respond to human language, which is a fundamental aspect of human intelligence.
2. Machine Learning:
- Machine learning is a subset of AI that focuses on the development of algorithms and models that enable computers to learn and improve over time, based on data and experience, without being explicitly programmed.
- LLMs are built using machine learning techniques, particularly deep learning and neural networks. They are trained on large datasets to identify patterns, understand context, and generate responses, demonstrating their ability to learn and improve from data.
3. (...)Si quieres continuar la conversación, tenemos que mantener el conversation_id coherente, y recordará automáticamente todas las conversaciones anteriores. El conversation_id no debe utilizarse junto con el chat_history. Son mutuamente excluyentes.
Si quieres saber más, consulta la documentación de Cohere.
Examinemos el precio del modelo más avanzado de Cohere y comparémoslo con los mejores modelos lingüísticos patentados de OpenAI y Anthropic (nos centraremos en el modelo más potente de cada empresa). En mayo de 2024, estos son los precios:
|
Modelo |
$ / millón token de entrada |
$ / millón de fichas de salida |
|
Comando Cohere R+ |
$3.00 |
$15.00 |
|
Claude Opus Antrópico |
$15.00 |
$75.00 |
|
OpenAI GPT-4 Turbo |
$10.00 |
$30.00 |
Aunque Cohere Command R+ ofrece una atractiva ventaja de costes, es importante tener en cuenta el espectro de prestaciones más amplio de estos modelos. Anthropic Claude Opus y GPT-4 turbo han demostrado sistemáticamente un mayor rendimiento en las pruebas comparativas.
Tanto si eres un desarrollador que busca mejorar sus aplicaciones como si eres una empresa que pretende incorporar IA de vanguardia, Cohere ofrece grandes modelos que son competitivos con otros modelos fundacionales, como GPT y Claude, pero a un precio significativamente inferior.
En este blog, hemos aprendido qué es Cohere y cómo acceder a él utilizando el Playground o la API.
Si quieres profundizar en el tema, te recomiendo este code-along sobre Utilización de grandes modelos lingüísticos con la API Cohere.
Si te apetece profundizar aún más y aprender a desarrollar aplicaciones de IA de extremo a extremo, consulta Desarrollo de aplicaciones LLM con LangChain.
¡Aprende más sobre APIs y LLMs con estos cursos!
Curso
Curso
Curso