
Course
Working with the OpenAI API
3 hr
143.4K
In the fast-changing landscape of AI, the arrival of large language models has revolutionized how we interact with and generate text content. Since the release of OpenAI’s ChatGPT in November 2022, we’ve seen a fresh wave of large language models being released daily.
Among these models, Cohere Command has become a top choice among practitioners. Cohere offers cutting-edge tools to empower developers and businesses to harness foundational models' power in their applications and use cases.
This beginner's guide aims to describe Cohere's API offerings, providing an in-depth exploration of its capabilities, advantages, and practical implementation strategies.
We’ll begin with a quick overview of large language models, but if you’re looking for a more comprehensive approach, check out this course on Large Language Models (LLMs).
Large Language Models (LLMs) are advanced AI systems that understand and generate human-like text. They are trained on vast amounts of data to grasp complex patterns, comprehend language nuances, and generate coherent responses.
LLMs can perform various language-related tasks, including translation, text completion, summarization, and conversational interactions.
Cohere is a key player in this space, offering a user-friendly API that grants data scientists access to these LLM capabilities, streamlining their workflows.
Established in 2019, Cohere is a Canadian enterprise dedicated to creating artificial intelligence solutions for businesses. It has rapidly become a significant figure in the large language model (LLM) industry, frequently mentioned alongside competitors like OpenAI GPT and Anthropic Claude.
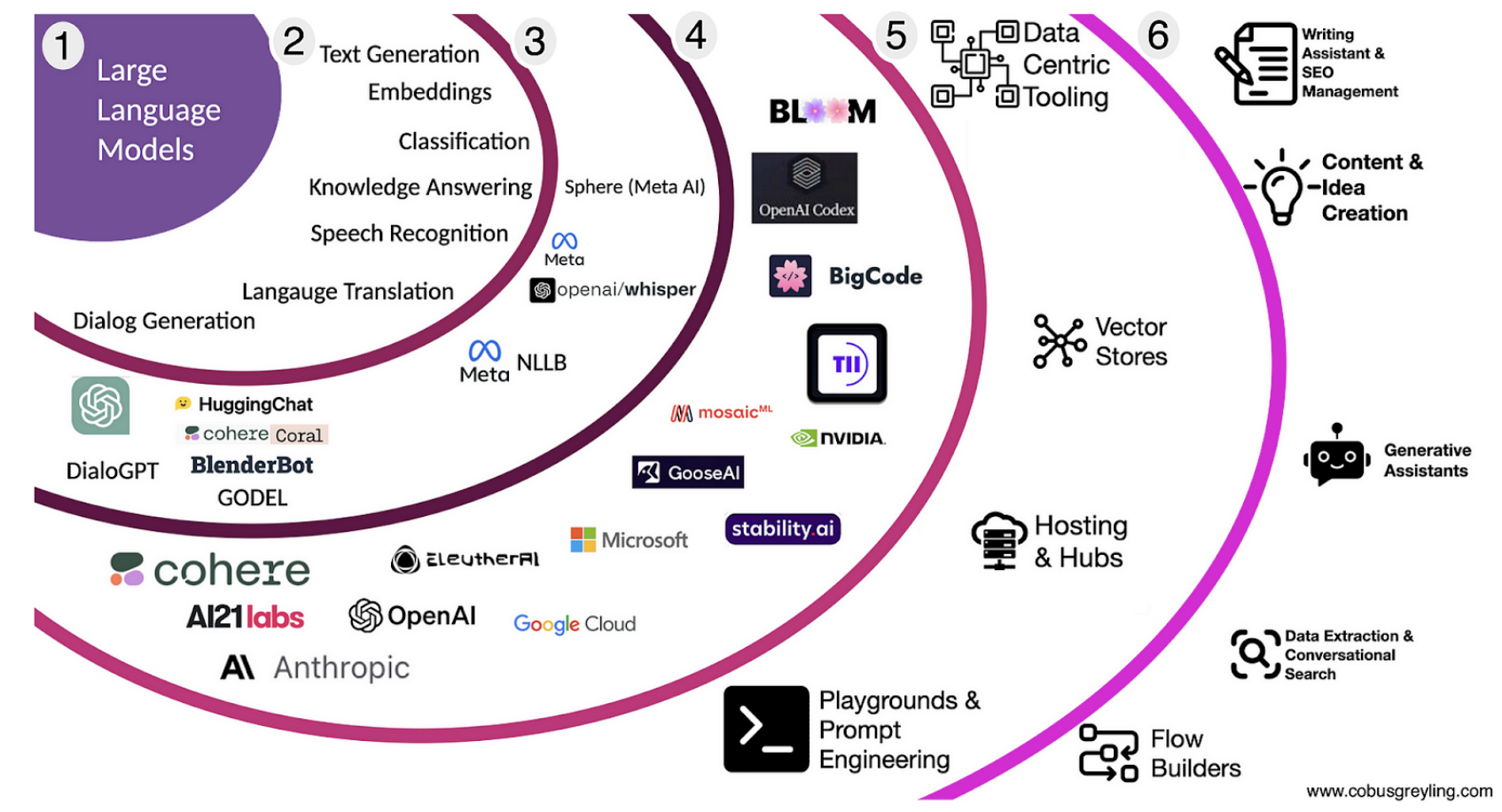
Source: Cobus Greyling, Large Language Model Landscape, Medium
Primarily, Cohere develops and provides foundational models for language generation, which are accessible to developers and businesses mainly through its API service.
Cohere primarily offers three different types of models:
We can access Cohere models in two ways:
Cohere also offers an exclusive chat interface similar to ChatGPT—powered by Command R+ under the hood.
Cohere Playground provides a user-friendly interface for interacting with Cohere Models, offering an intuitive experience similar to working with GPT.
Users can explore and experiment with various model capabilities, generating text and gaining insights into its behavior. With a sleek and accessible design, Cohere Playground enables users to quickly prototype and test Cohere’s model offerings quickly.
Cohere Playground is free for users to explore and experiment with models (it’s free until you go into production).
To use Cohere Playground, we first need to sign up on Cohere’s website.
Then, we can sign in, and we’ll land on the page we see below—which is pretty similar to a playground in the OpenAI platform. Using the dropdown on the right-hand side, we can choose different Cohere models.
The Playground has slightly different interfaces for different tasks. Towards the top, you have four options to choose from: Chat, Classify, Embed, and Generate.
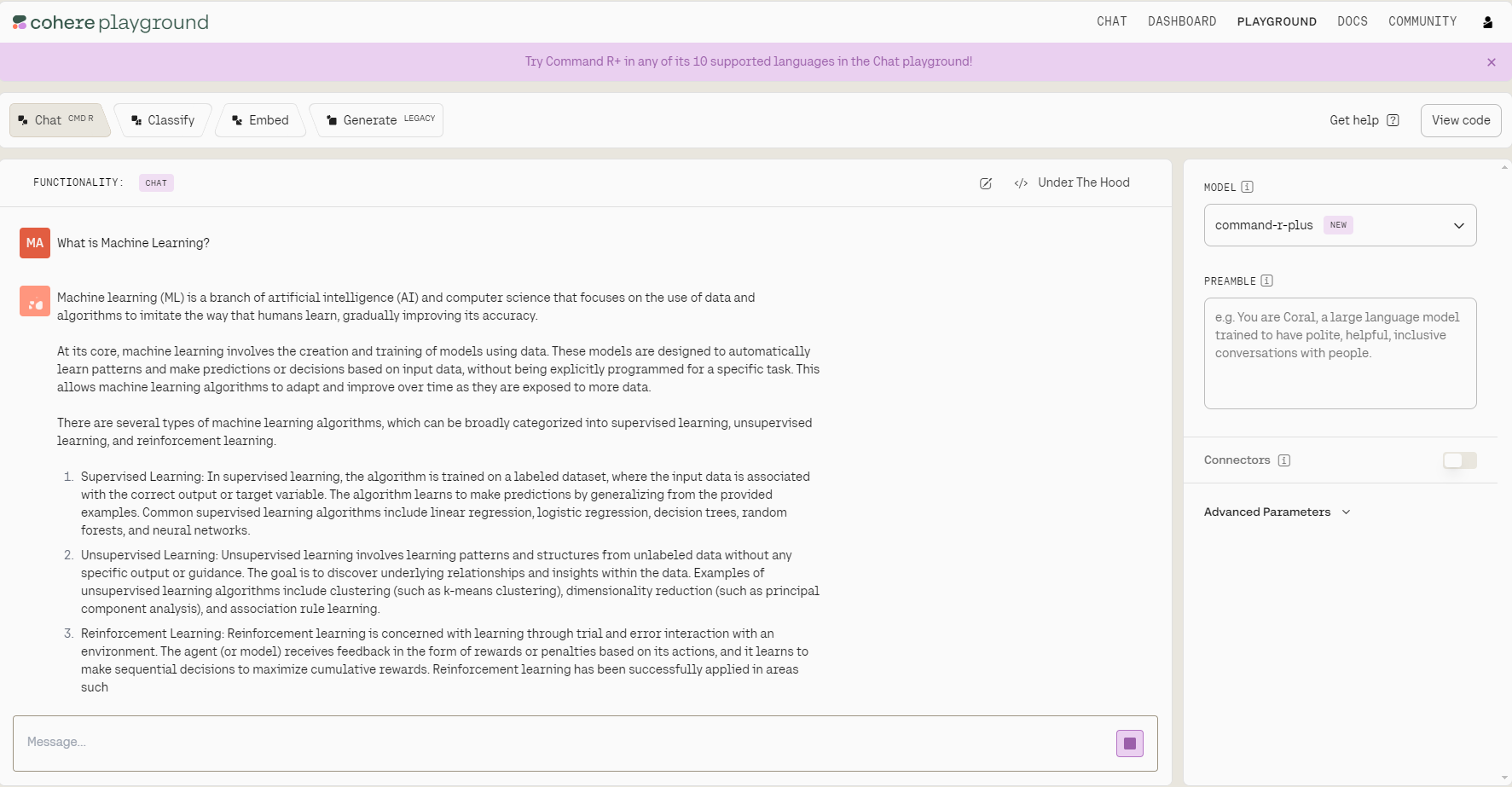
Cohere Playground’s dashboard
Cohere Playground is great for quickly testing the capabilities of Cohere models, but if you are building an application or workflow, you need a programmatic way to access these models. That’s where Cohere’s API comes in!
Accessing Cohere’s API is pretty straightforward. In a nutshell, we’ll need to:
Let’s discuss these steps one by one.
We can install the cohere client using pip.
!pip install cohereNow, we need an API key.
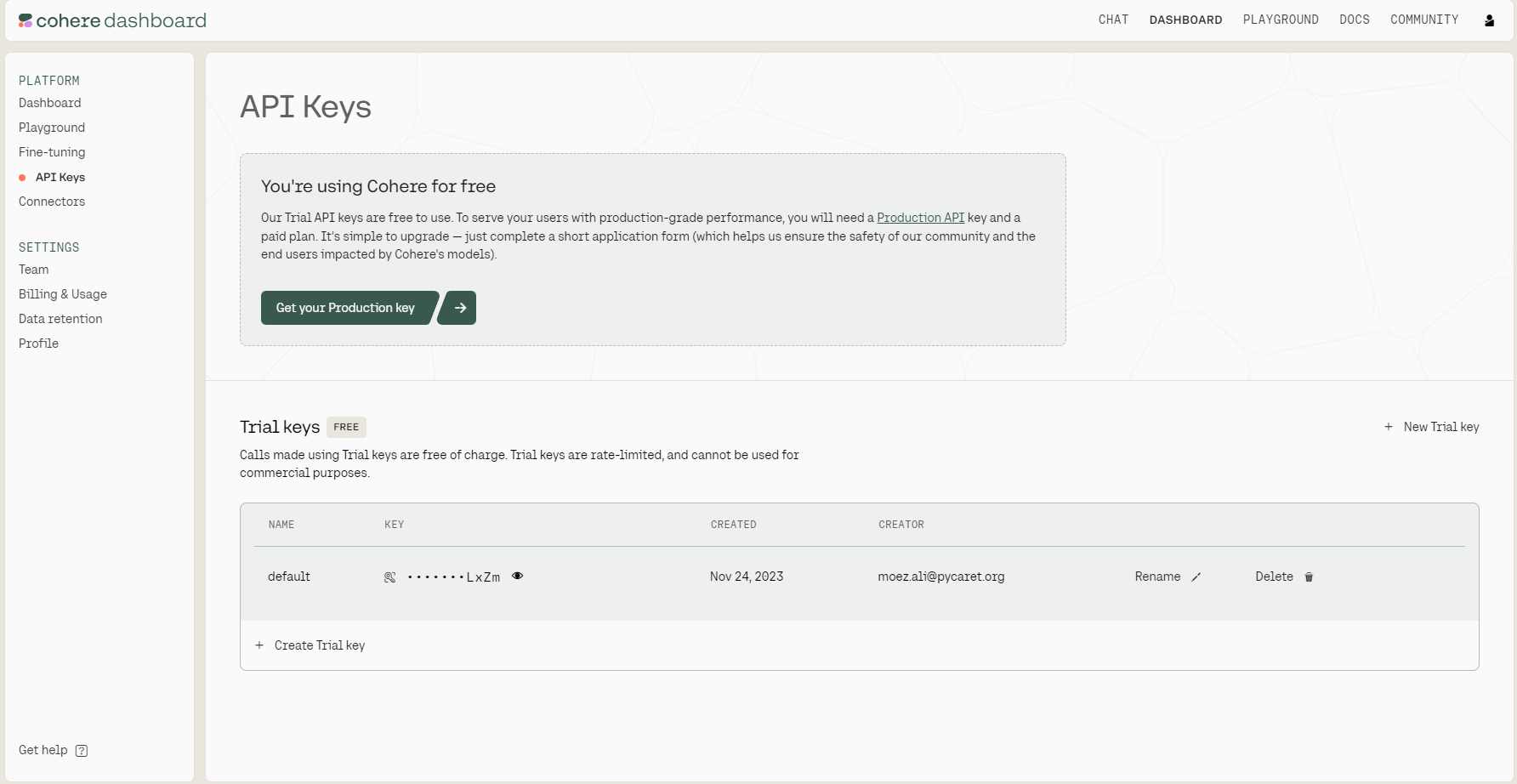
As we can see in the image below, there are two kinds of API keys: production and trial. For this tutorial’s purposes, we only need a trial key. We can copy it by clicking the copy icon next to the key.
Now that we have the cohere library installed and our API key, we can make an API call. In the code below, we:
cohere library to interact with their API.Client object using our API key.co.chat().import cohere
co = cohere.Client('your_token_here')
message = "What is Machine Learning?"
response = co.chat(
message=message,
model="command",
temperature=0.3
)
answer = response.text
print(answer)Machine learning is a branch of computer science that focuses on developing algorithms and models that enable computers to learn and make predictions or decisions without being explicitly programmed. It is a key component of artificial intelligence (AI).
Machine Learning allows systems to identify patterns in data, uncover insights, and improve processes through iterative learning. Instead of writing explicit programs, ML enables the creation of models that can analyze data, identify patterns, and predict outcomes. These models are refined and optimized through a process known as training, which involves feeding the models annotated examples or real-world data.
(...)Earlier, we accessed the answer using response.text. But the response object contains more information, and we can access it using response.dict()—this will return a JSON file containing all the metadata including the response message:
response.dict()
{
"text":"Machine Learning (ML) is a ....",
"generation_id":"cebf4874-1e3d-429a-8699-8b9639b943dd",
"finish_reason":"COMPLETE",
"chat_history":[
{
"message":"What is Machine Learning?",
"role":"USER"
},
{
"message":"Machine Learning (ML) is a ....",
"role":"CHATBOT"
}
],
"meta":{
"api_version":{
"version":"1"
},
"billed_units":{
"input_tokens":56,
"output_tokens":252
},
"tokens":{
"input_tokens":67,
"output_tokens":252
}
},
"response_id":"df34a5f8-f1cd-407f-b1b5-5971aa12ae2a"
}Let’s break down each field of the response object:
text: Contains the message generated by the model.generation_id: Contains the ID associated with the generated answer, which can be used with the Feedback API endpoint to highlight good responses and report poor ones.finish_reason: Indicates why the generation ended and can be one of the following:COMPLETE: The model successfully finished generating the message.MAX_TOKENS: The model's context limit was reached before the generation could be completed.chat_history: Contains the conversation presented in a chat log format.meta: Contains information about token counts, billing, etc.response_id: While generation_id focuses on a single attempt at text generation, response_id identifies the entire response object containing that generated text and other relevant data.Imagine you are developing a chatbot designed to answer user queries. Having context from previous conversations can enable the language model to provide more relevant answers.
In multi-turn conversations, retaining the context of previous interactions is essential for generating coherent and pertinent responses. Cohere’s API facilitates this by allowing us to include the chat history through the chat_history parameter.
This helps the model comprehend the conversation flow and respond appropriately based on earlier exchanges. Let’s see an example.
message = "How is this related to Artificial Intelligence?"
response = co.chat(
model="command-r-plus",
chat_history=[
{"role": "USER", "text": "What is Large Language Model?"},
{"role": "CHATBOT", "text": "Large Language Model is a type ..."},
],
message="How is this related to Artificial Intelligence?"
)
print(response.text)Large language models (LLMs) are a key component of artificial intelligence (AI), and their development has played a significant role in advancing the field of AI. Here's how they are related:
1. Language Understanding and Generation: AI aims to create intelligent systems that can understand and respond to human language. LLMs are designed to process and generate human-like language, which is a fundamental aspect of human intelligence. By training on vast amounts of text data, LLMs learn to recognize patterns, syntax, semantics, and context, enabling them to interpret and generate language in a way that is similar to how humans do.
2. Machine Learning and Neural Networks: LLMs are typically built using machine learning techniques, particularly deep learning and neural networks. These are core areas of AI research. Neural networks, inspired by the structure of the human brain, enable LLMs to learn and make connections between different pieces of information. By training on large datasets, LLMs can identify patterns, relationships, and meanings in the data, which is a fundamental aspect of AI.
3. (...)When the user asked "How is this related to Artificial Intelligence?," the model understood that "this" referred to large language models (LLMs). This is thanks to the chat_history parameter, which provided the necessary context from the previous interactions. Maintaining context in multi-turn conversations is crucial for generating relevant and coherent responses.
This works great but it’s not realistic to manually pass the chat_history to the API like we did in the above example. Instead of hardcoding the chat_history, we can build it dynamically as we have a conversation.
There are multiple ways to achieve this. The simplest one is using conversation_id in the API. Let’s see an example:
# First message
response = co.chat(
model="command-r-plus",
message="What is Large Language Models?",
conversation_id='newuser1',
)
print(response.text)Large Language Models (LLMs) are a type of artificial intelligence model specifically designed to process and generate human language. These models are typically based on deep learning and neural network architectures and are trained on vast amounts of text data. Here's an overview of LLMs and their key characteristics:
1. Definition:
- Large Language Models are machine learning models that are trained on large-scale textual data to understand, generate, and manipulate human language. They aim to capture the complexities of language, including syntax, semantics, and context.
2. Training Data:
- LLMs are trained on massive amounts of text data, often consisting of billions or even trillions of words. This training data can come from various sources such as books, articles, websites, social media, and other text-based documents.
3. (...)And now let’s prompt the model with another message—notice how conversation_id is kept consistent with the first message. As long as conversation_id is kept consistent, the API will automatically use previous messages as context.
# Second message
response = co.chat(
model="command-r-plus",
message="How is it related to Artificial Intelligence?",
conversation_id='newuser1',
)
print(response.text)Large Language Models (LLMs) are a crucial component and a powerful manifestation of Artificial Intelligence (AI). Here's how LLMs are closely related to AI:
1. AI Foundation:
- Artificial Intelligence is a broad field that encompasses the development of computer systems capable of performing tasks typically associated with human intelligence. This includes areas like machine learning, natural language processing, computer vision, robotics, and decision-making.
- LLMs fall under the umbrella of AI as they are designed to understand, generate, and respond to human language, which is a fundamental aspect of human intelligence.
2. Machine Learning:
- Machine learning is a subset of AI that focuses on the development of algorithms and models that enable computers to learn and improve over time, based on data and experience, without being explicitly programmed.
- LLMs are built using machine learning techniques, particularly deep learning and neural networks. They are trained on large datasets to identify patterns, understand context, and generate responses, demonstrating their ability to learn and improve from data.
3. (...)If you want to continue the conversation, we need to keep the conversation_id consistent, and it’ll automatically remember all previous conversations. The conversation_id should not be used in conjunction with the chat_history. They are mutually exclusive.
If you want to learn more, check out Cohere’s documentation.
Let's examine the pricing of Cohere's most advanced model and compare it with the top proprietary language models from OpenAI and Anthropic (we’ll focus on each company's most powerful model). As of May 2024, these are the prices:
|
Model |
$ / million input token |
$ / million output token |
|
Cohere Command R+ |
$3.00 |
$15.00 |
|
Anthropic Claude Opus |
$15.00 |
$75.00 |
|
OpenAI GPT-4 Turbo |
$10.00 |
$30.00 |
While Cohere Command R+ offers an attractive cost advantage, it's important to consider the broader performance spectrum of these models. Anthropic Claude Opus and GPT-4 turbo have consistently demonstrated stronger performance in benchmarks.
Whether you're a developer looking to enhance your applications or a business aiming to incorporate cutting-edge AI, Cohere offers large models that are competitive with other foundational models, like GPT and Claude—but at a significantly lower price.
In this blog, we’ve learned what Cohere is and how to access it using either the Playground or the API.
If you want to explore the topic further, I recommend this code-along on Using Large Language Models with the Cohere API.
If you feel like going even deeper and learn how to develop end-to-end AI applications, check out Developing LLM Applications with LangChain.
Learn more about APIs and LLMs with these courses!
Course
Course
Course
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Arunn Thevapalan
code-along
Rishit Dholakia
code-along
Korey Stegared-Pace
code-along
Richie Cotton




