Curso
Trabalhar com a API da OpenAI
3 h
141.6K
No cenário em rápida mudança da IA, a chegada de grandes modelos de linguagem revolucionou a forma como interagimos e geramos conteúdo de texto. Desde o lançamento do ChatGPT da OpenAI em novembro de 2022, temos visto uma nova onda de grandes modelos de linguagem sendo lançados diariamente.
Entre esses modelos, o Cohere Command tornou-se uma das principais opções entre os profissionais. A Cohere oferece ferramentas de ponta para capacitar desenvolvedores e empresas a aproveitarem o poder dos modelos fundamentais em seus aplicativos e casos de uso.
Este guia para iniciantes tem como objetivo descrever as ofertas de API da Cohere, fornecendo uma exploração aprofundada de seus recursos, vantagens e estratégias práticas de implementação.
Começaremos com uma rápida visão geral dos modelos de linguagem grandes, mas se você estiver procurando uma abordagem mais abrangente, confira este curso sobre modelos de linguagem grandes (LLMs).
Os LLMs (Large Language Models) são sistemas avançados de IA que entendem e geram textos semelhantes aos humanos. Eles são treinados em grandes quantidades de dados para entender padrões complexos, compreender nuances de linguagem e gerar respostas coerentes.
Os LLMs podem executar várias tarefas relacionadas ao idioma, incluindo tradução, preenchimento de texto, resumo e interações de conversação.
O Cohere é um dos principais participantes nesse espaço, oferecendo uma API fácil de usar que concede aos cientistas de dados acesso a esses recursos de LLM, simplificando seus fluxos de trabalho.
Fundada em 2019, a Cohere é uma empresa canadense dedicada a criar soluções de inteligência artificial para empresas. Ele se tornou rapidamente uma figura importante no setor de modelos de linguagem grande (LLM), sendo frequentemente mencionado ao lado de concorrentes como OpenAI GPT e Anthropic Claude.
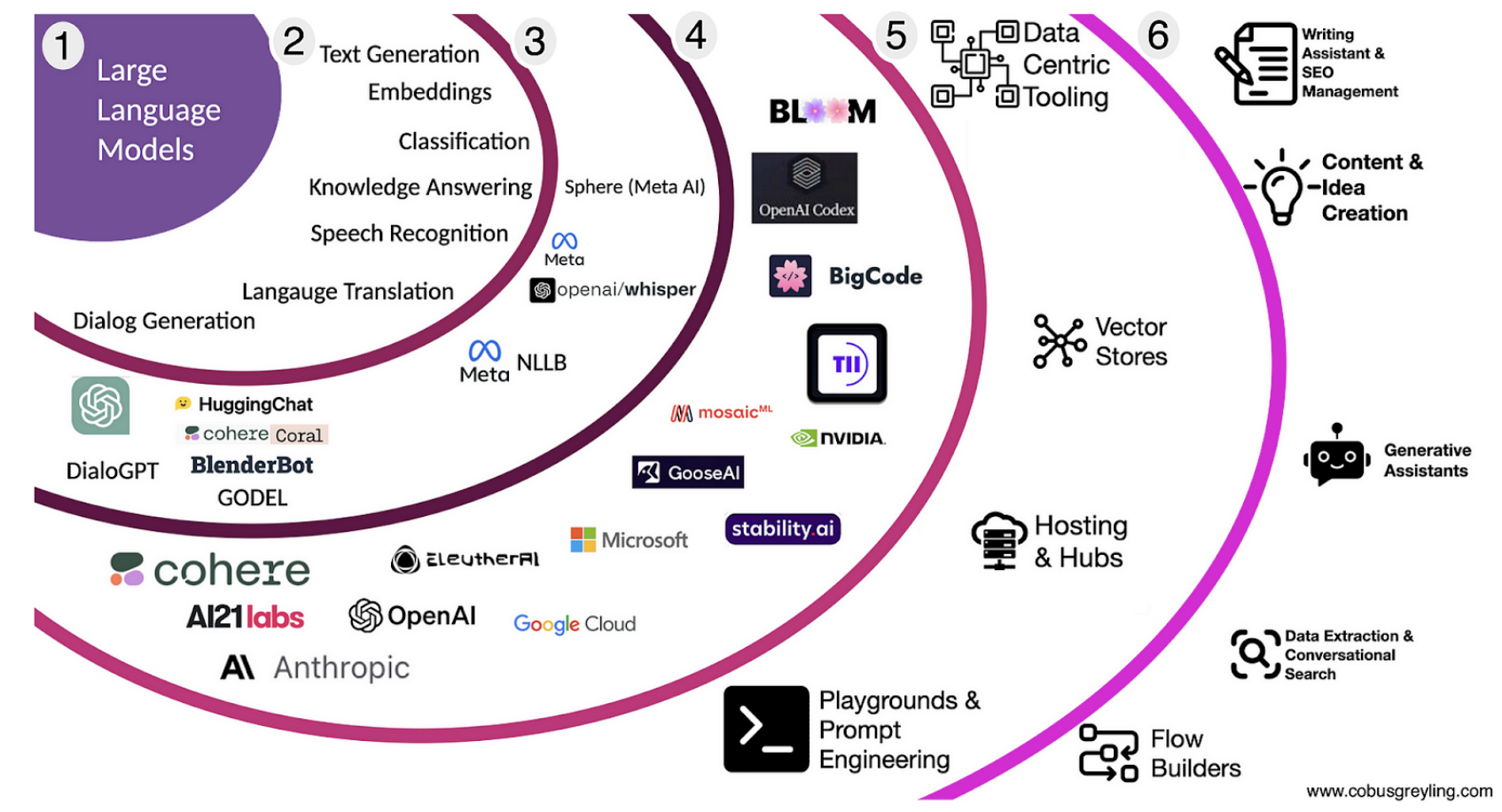
Fonte: Cobus Greyling, modelo de idioma grande Paisagem, médio
Principalmente, a Cohere desenvolve e fornece modelos básicos para a geração de linguagem, que são acessíveis a desenvolvedores e empresas principalmente por meio de seu serviço de API.
A Cohere oferece principalmente três tipos diferentes de modelos:
Você pode acessar os modelos Cohere de duas maneiras:
O Cohere também oferece uma interface de bate-papo exclusiva, semelhante ao ChatGPT, alimentada pelo Command R+.
O Cohere Playground fornece uma interface amigável para a interação com os modelos Cohere, oferecendo uma experiência intuitiva semelhante ao trabalho com o GPT.
Os usuários podem explorar e experimentar vários recursos do modelo, gerando texto e obtendo insights sobre seu comportamento. Com um design elegante e acessível, o Cohere Playground permite que os usuários criem protótipos e testem rapidamente as ofertas de modelos da Cohere.
O Cohere Playground é gratuito para os usuários explorarem e experimentarem modelos (é gratuito até que você entre em produção).
Para usar o Cohere Playground, primeiro você precisa se registrar no site do Cohere.
Em seguida, podemos fazer login e chegaremos à página que vemos abaixo, que é muito semelhante a um playground na plataforma OpenAI. Usando o menu suspenso no lado direito, podemos escolher diferentes modelos Cohere.
O Playground tem interfaces ligeiramente diferentes para tarefas diferentes. Na parte superior, você tem quatro opções para escolher: Você pode conversar, classificar, incorporar e gerar.
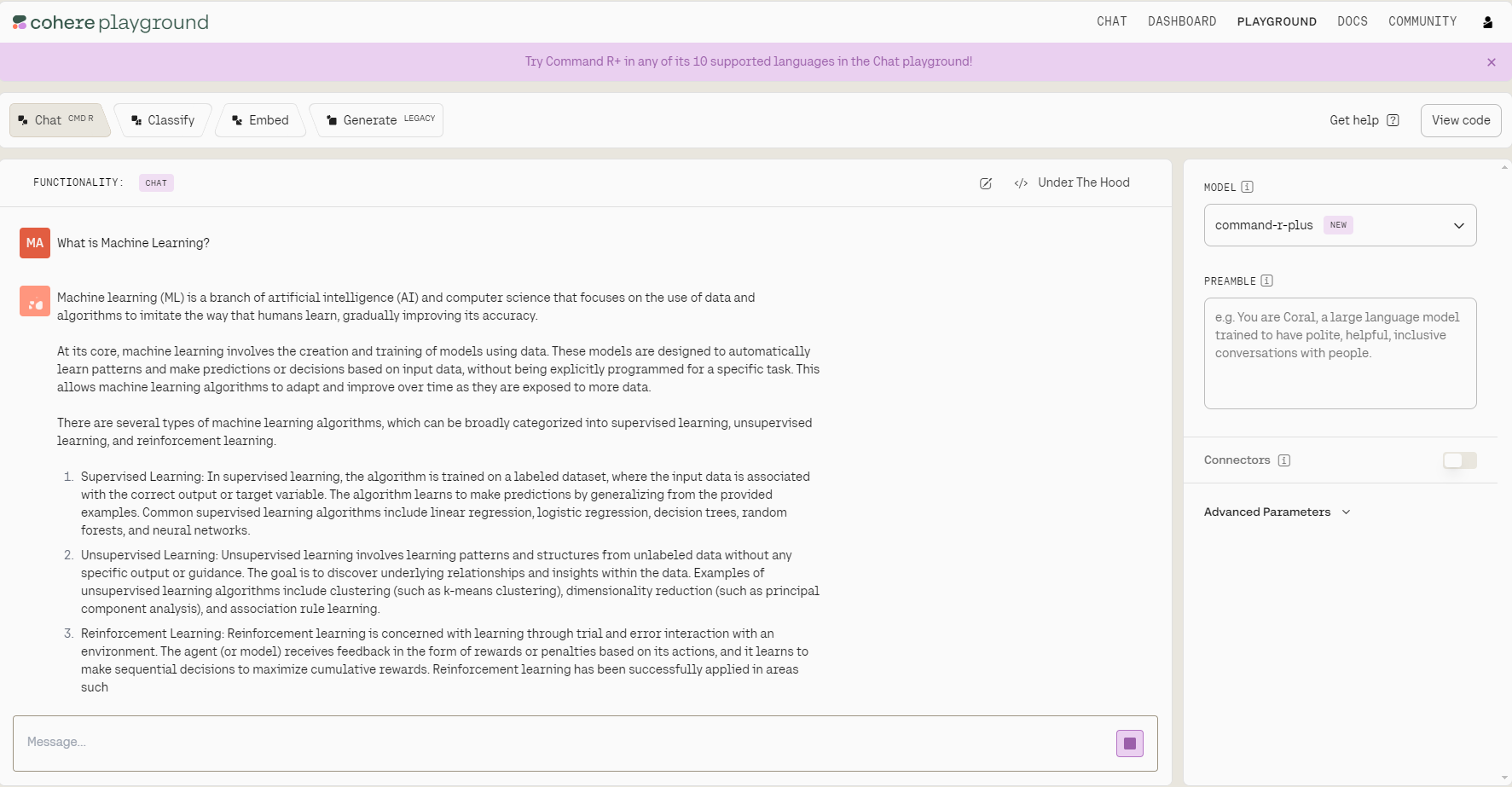
Painel de controle do Cohere Playground
O Cohere Playground é excelente para testar rapidamente os recursos dos modelos Cohere, mas se você estiver criando um aplicativo ou fluxo de trabalho, precisará de uma forma programática para acessar esses modelos. É aí que entra a API da Cohere!
O acesso à API do Cohere é bastante simples. Em resumo, precisaremos de:
Vamos discutir essas etapas uma a uma.
Você pode instalar o cliente cohere usando pip.
!pip install cohereAgora, precisamos de uma chave de API.
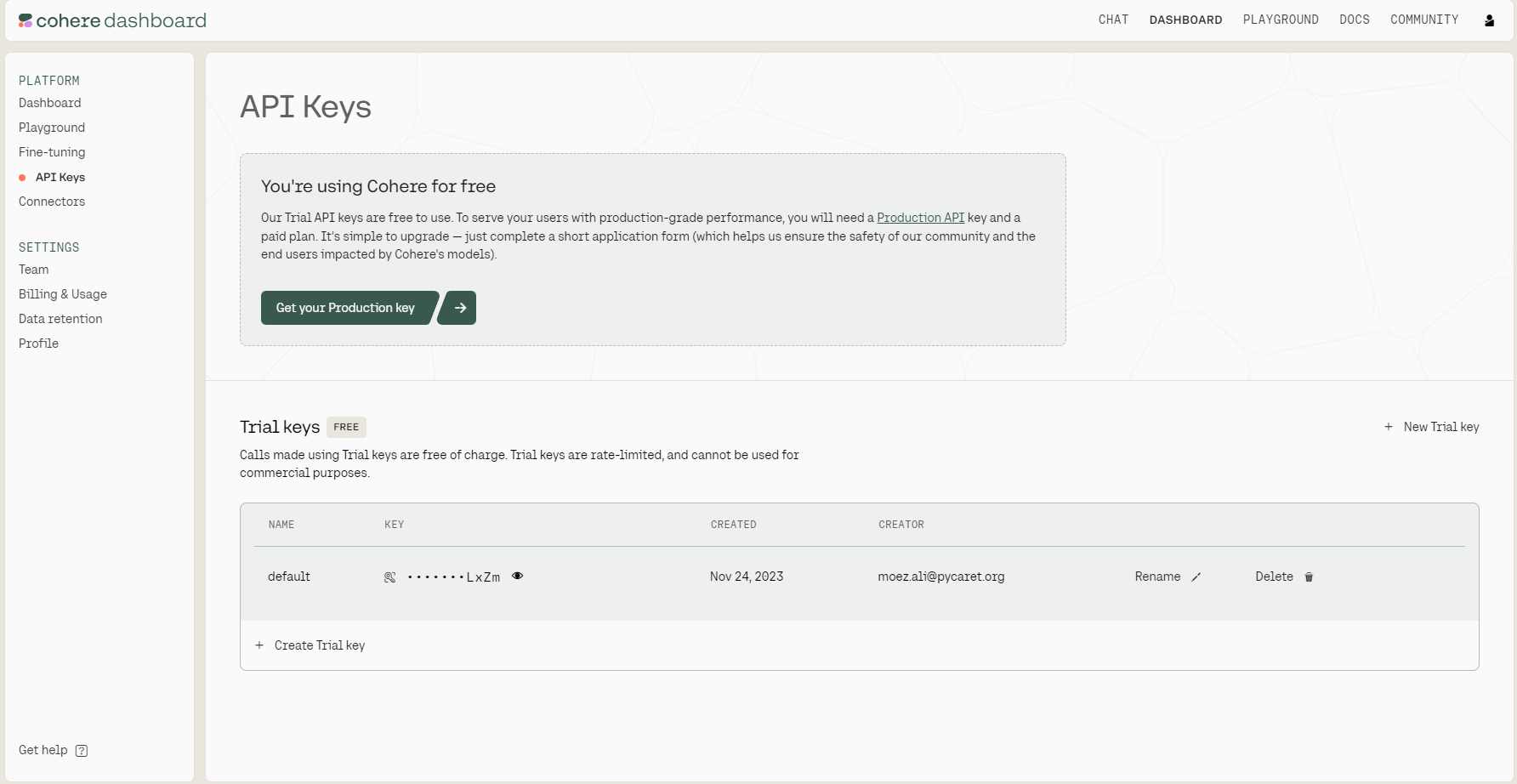
Como podemos ver na imagem abaixo, há dois tipos de chaves de API: produção e teste. Para os fins deste tutorial, precisamos apenas de uma chave de avaliação. Você pode copiá-la clicando no ícone de cópia ao lado da chave.
Agora que temos a biblioteca cohere instalada e nossa chave de API, podemos fazer uma chamada de API. No código abaixo, você:
cohere para interagir com sua API.Client usando nossa chave de API.co.chat().import cohere
co = cohere.Client('your_token_here')
message = "What is Machine Learning?"
response = co.chat(
message=message,
model="command",
temperature=0.3
)
answer = response.text
print(answer)Machine learning is a branch of computer science that focuses on developing algorithms and models that enable computers to learn and make predictions or decisions without being explicitly programmed. It is a key component of artificial intelligence (AI).
Machine Learning allows systems to identify patterns in data, uncover insights, and improve processes through iterative learning. Instead of writing explicit programs, ML enables the creation of models that can analyze data, identify patterns, and predict outcomes. These models are refined and optimized through a process known as training, which involves feeding the models annotated examples or real-world data.
(...)Anteriormente, acessamos a resposta usando response.text. Mas o objeto de resposta contém mais informações e podemos acessá-lo usando response.dict()- isso retornará um arquivo JSON que contém todos os metadados, inclusive a mensagem de resposta:
response.dict()
{
"text":"Machine Learning (ML) is a ....",
"generation_id":"cebf4874-1e3d-429a-8699-8b9639b943dd",
"finish_reason":"COMPLETE",
"chat_history":[
{
"message":"What is Machine Learning?",
"role":"USER"
},
{
"message":"Machine Learning (ML) is a ....",
"role":"CHATBOT"
}
],
"meta":{
"api_version":{
"version":"1"
},
"billed_units":{
"input_tokens":56,
"output_tokens":252
},
"tokens":{
"input_tokens":67,
"output_tokens":252
}
},
"response_id":"df34a5f8-f1cd-407f-b1b5-5971aa12ae2a"
}Vamos detalhar cada campo do objeto response:
text: Contém a mensagem gerada pelo modelo.generation_id: Contém a ID associada à resposta gerada, que pode ser usada com o ponto de extremidade da API de feedback para destacar boas respostas e relatar as ruins.finish_reason: Indica por que a geração terminou e pode ser uma das seguintes opções:COMPLETE: O modelo concluiu com êxito a geração da mensagem.MAX_TOKENS: O limite de contexto do modelo foi atingido antes que a geração pudesse ser concluída.chat_history: Contém a conversa apresentada em um formato de registro de bate-papo.meta: Contém informações sobre contagens de tokens, faturamento, etc.response_id: Enquanto o site generation_id se concentra em uma única tentativa de geração de texto, o site response_id identifica todo o objeto de resposta que contém o texto gerado e outros dados relevantes.Imagine que você está desenvolvendo um chatbot projetado para responder a consultas de usuários. Ter o contexto de conversas anteriores pode permitir que o modelo de linguagem forneça respostas mais relevantes.
Em conversas com vários turnos, manter o contexto de interações anteriores é essencial para gerar respostas coerentes e pertinentes. A API do Cohere facilita isso, permitindo que você inclua o histórico do bate-papo por meio do parâmetro chat_history.
Isso ajuda o modelo a compreender o fluxo da conversa e a responder adequadamente com base em trocas anteriores. Vamos ver um exemplo.
message = "How is this related to Artificial Intelligence?"
response = co.chat(
model="command-r-plus",
chat_history=[
{"role": "USER", "text": "What is Large Language Model?"},
{"role": "CHATBOT", "text": "Large Language Model is a type ..."},
],
message="How is this related to Artificial Intelligence?"
)
print(response.text)Large language models (LLMs) are a key component of artificial intelligence (AI), and their development has played a significant role in advancing the field of AI. Here's how they are related:
1. Language Understanding and Generation: AI aims to create intelligent systems that can understand and respond to human language. LLMs are designed to process and generate human-like language, which is a fundamental aspect of human intelligence. By training on vast amounts of text data, LLMs learn to recognize patterns, syntax, semantics, and context, enabling them to interpret and generate language in a way that is similar to how humans do.
2. Machine Learning and Neural Networks: LLMs are typically built using machine learning techniques, particularly deep learning and neural networks. These are core areas of AI research. Neural networks, inspired by the structure of the human brain, enable LLMs to learn and make connections between different pieces of information. By training on large datasets, LLMs can identify patterns, relationships, and meanings in the data, which is a fundamental aspect of AI.
3. (...)Quando o usuário perguntou "Como isso está relacionado à Inteligência Artificial?", o modelo entendeu que "isso" se referia a modelos de linguagem grandes (LLMs). Isso se deve ao parâmetro chat_history, que forneceu o contexto necessário das interações anteriores. Manter o contexto em conversas com vários turnos é fundamental para gerar respostas relevantes e coerentes.
Isso funciona muito bem, mas não é realista passar manualmente o endereço chat_history para a API, como fizemos no exemplo acima. Em vez de codificar o chat_history, podemos criá-lo dinamicamente à medida que temos uma conversa.
Há várias maneiras de conseguir isso. O mais simples é usar conversation_id na API. Vamos ver um exemplo:
# First message
response = co.chat(
model="command-r-plus",
message="What is Large Language Models?",
conversation_id='newuser1',
)
print(response.text)Large Language Models (LLMs) are a type of artificial intelligence model specifically designed to process and generate human language. These models are typically based on deep learning and neural network architectures and are trained on vast amounts of text data. Here's an overview of LLMs and their key characteristics:
1. Definition:
- Large Language Models are machine learning models that are trained on large-scale textual data to understand, generate, and manipulate human language. They aim to capture the complexities of language, including syntax, semantics, and context.
2. Training Data:
- LLMs are trained on massive amounts of text data, often consisting of billions or even trillions of words. This training data can come from various sources such as books, articles, websites, social media, and other text-based documents.
3. (...)E agora vamos solicitar ao modelo outra mensagem - observe como conversation_id é mantido consistente com a primeira mensagem. Desde que o site conversation_id seja mantido consistente, a API usará automaticamente as mensagens anteriores como contexto.
# Second message
response = co.chat(
model="command-r-plus",
message="How is it related to Artificial Intelligence?",
conversation_id='newuser1',
)
print(response.text)Large Language Models (LLMs) are a crucial component and a powerful manifestation of Artificial Intelligence (AI). Here's how LLMs are closely related to AI:
1. AI Foundation:
- Artificial Intelligence is a broad field that encompasses the development of computer systems capable of performing tasks typically associated with human intelligence. This includes areas like machine learning, natural language processing, computer vision, robotics, and decision-making.
- LLMs fall under the umbrella of AI as they are designed to understand, generate, and respond to human language, which is a fundamental aspect of human intelligence.
2. Machine Learning:
- Machine learning is a subset of AI that focuses on the development of algorithms and models that enable computers to learn and improve over time, based on data and experience, without being explicitly programmed.
- LLMs are built using machine learning techniques, particularly deep learning and neural networks. They are trained on large datasets to identify patterns, understand context, and generate responses, demonstrating their ability to learn and improve from data.
3. (...)Se você quiser continuar a conversa, precisamos manter o conversation_id consistente, e ele se lembrará automaticamente de todas as conversas anteriores. O conversation_id não deve ser usado em conjunto com o chat_history. Eles são mutuamente exclusivos.
Se você quiser saber mais, consulte a documentação do Cohere.
Vamos examinar o preço do modelo mais avançado da Cohere e compará-lo com os principais modelos de linguagem proprietários da OpenAI e da Anthropic (vamos nos concentrar no modelo mais avançado de cada empresa). A partir de maio de 2024, esses são os preços:
|
Modelo |
$ / milhão de token de entrada |
$ / milhão de tokens de saída |
|
Comando Cohere R+ |
$3.00 |
$15.00 |
|
Opus Claude Antrópico |
$15.00 |
$75.00 |
|
OpenAI GPT-4 Turbo |
$10.00 |
$30.00 |
Embora o Cohere Command R+ ofereça uma vantagem de custo atraente, é importante considerar o espectro de desempenho mais amplo desses modelos. O Anthropic Claude Opus e o GPT-4 turbo têm demonstrado consistentemente um melhor desempenho em benchmarks.
Se você é um desenvolvedor que deseja aprimorar seus aplicativos ou uma empresa que deseja incorporar IA de ponta, o Cohere oferece modelos grandes que são competitivos com outros modelos básicos, como GPT e Claude, mas a um preço significativamente menor.
Neste blog, você aprendeu o que é o Cohere e como acessá-lo usando o Playground ou a API.
Se você quiser explorar mais o tópico, recomendo este code-along sobre o uso de modelos de linguagem grandes com a API Cohere.
Se você quiser se aprofundar ainda mais e aprender a desenvolver aplicativos de IA de ponta a ponta, confira o artigo Developing LLM Applications with LangChain.
Saiba mais sobre APIs e LLMs com estes cursos!
Curso
Curso
Curso
Tutorial
Zoumana Keita
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Kurtis Pykes
Tutorial
Zoumana Keita



