Curso
Python intermedio
4 h
1.4M

Los datos sintéticos son datos generados por ordenador que son similares a los datos del mundo real. El objetivo principal de los datos sintéticos es aumentar la privacidad e integridad de los sistemas. Por ejemplo, para proteger la Información Personal Identificable (IPI) o la Información Personal Sanitaria (IPS) de los usuarios, las empresas tienen que aplicar estrategias de protección de datos. Utilizar datos sintéticos puede ayudar a las empresas a probar nuevas aplicaciones y proteger la privacidad de los usuarios.
En el caso del aprendizaje automático, utilizamos datos sintéticos para mejorar el rendimiento del modelo. También es válido para situaciones en las que los datos son escasos y desequilibrados. El uso típico de los datos sintéticos en el aprendizaje automático es la conducción autónoma de vehículos, la seguridad, la robótica, la protección contra el fraude y la asistencia sanitaria.
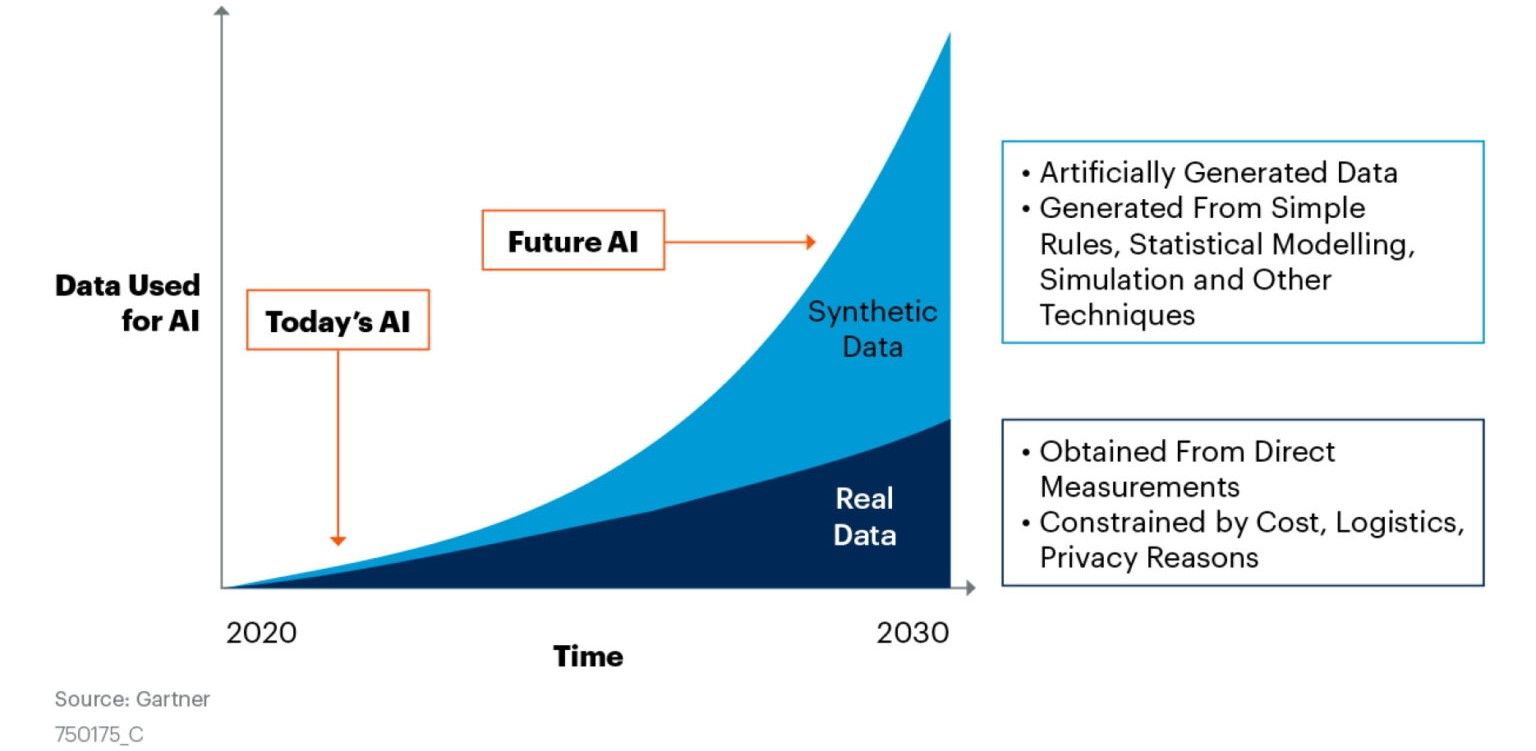
Imagen de Nvidia
Según datos de Gartner, en 2024, el 60% de los datos utilizados para desarrollar aplicaciones analíticas y de aprendizaje automático se generarán sintéticamente. Pero, ¿por qué vemos una tendencia al alza de los datos sintéticos?
Es costoso recopilar y limpiar datos del mundo real y, en algunos casos, son escasos. Por ejemplo, los datos sobre fraudes bancarios, cáncer de mama, coches autoconducidos y ataques de malware son raros de encontrar en el mundo real. Incluso si consigues los datos, te llevará tiempo y recursos limpiarlos y procesarlos para las tareas de aprendizaje automático.
En la primera parte del tutorial, aprenderemos por qué necesitamos datos sintéticos, sus aplicaciones y cómo generarlos. En la parte final, exploraremos la biblioteca Faker de Python y la utilizaremos para crear datos sintéticos para probar y mantener la privacidad de los usuarios.

Imagen del autor
Necesitamos datos sintéticos para la privacidad del usuario, probar aplicaciones, mejorar el rendimiento de los modelos, representar casos raros y reducir el coste de la operación.
En esta sección, aprenderemos cómo utilizan las empresas los datos sintéticos para crear aplicaciones rentables, respetuosas con la privacidad y de alto rendimiento.
Podemos utilizar generadores de datos falsos, herramientas estadísticas, redes neuronales y redes generativas adversariales para generar datos sintéticos.
Generar bases de datos falsas utilizando la biblioteca Faker para probar bases de datos y sistemas. Puede generar perfiles de usuario falsos con direcciones y toda la información esencial. También puedes utilizarlo para generar texto y párrafos aleatorios. Ayuda a las empresas a proteger la privacidad de los usuarios en la fase de prueba y a ahorrar dinero en la adquisición de conjuntos de datos del mundo real.
Comprender la distribución de los datos para generar un conjunto de datos completamente nuevo utilizando herramientas estadísticas como la Gaussiana, la Exponencial, la Chi-cuadrado, la t, la lognormal y la Uniforme. Debes tener conocimientos de la materia para generar datos sintéticos basados en la distribución.
El Autoencoder Variacional es un método de aprendizaje no supervisado que utiliza un codificador y un decodificador para comprimir el conjunto de datos original y generar una representación del mismo. Está diseñado para optimizar la correlación entre los conjuntos de datos de entrada y de salida.
La Red Adversarial Generativa es la forma más popular de generar datos. Puedes utilizarlo para representar imágenes sintéticas, sonido, datos tabulares y datos de simulación. Utiliza una arquitectura de modelo de aprendizaje profundo generador y discriminador para generar datos sintéticos comparando muestras aleatorias con datos reales. Lee nuestro tutorial Desmitificando las Redes Adversariales Generativas para crear tus propios datos sintéticos utilizando Keras.
Python Faker es un paquete Python de código abierto que se utiliza para crear un conjunto de datos falso para probar aplicaciones, arrancar la base de datos y mantener el anonimato del usuario.

Imagen del autor
Puedes instalar Faker utilizando:
pip install fakerFaker viene con soporte de línea de comandos, Pytest fixtures, Localización (soporta diferentes regiones), reproducibilidad y proveedor dinámico (personalizándolo según tus necesidades).
También puedes utilizar las funcionalidades básicas de Faker para crear un conjunto de datos rápido y personalizarlo según tus necesidades. En la tabla siguiente, puedes consultar varias funciones del Faker y su finalidad.
|
Función Farsante |
Propósito |
|
nombre() |
Genera un nombre completo falso |
|
credit_card_full() |
Genera un número de tarjeta de crédito con caducidad y CVV |
|
correo electrónico() |
Genera una dirección de correo electrónico falsa |
|
url() |
Generar URL falsa |
|
phone_number() |
Genera un número de teléfono falso con el prefijo del país |
|
address() |
Genera una dirección completa falsa |
|
license_plate() |
Genera matrículas falsas |
|
moneda() |
Generar tupla de código de moneda y forma completa |
|
color_name() |
Generar nombre de color aleatorio |
|
local_latlng() |
Generar latitud, longitud, zona, país y estados |
|
domain_name() |
Generar el sitio web falso basado en el nombre falso de la persona |
|
text() |
Generar el texto pequeño falso |
|
company() |
Generar nombre de empresa falso |
Para conocer funciones más avanzadas, consulta la documentación de Faker.
Es importante repasar estas funciones, ya que las utilizaremos para crear varios ejemplos y marcos de datos.
En esta sección, utilizaremos Python Faker para generar datos sintéticos. Consta de 5 ejemplos de cómo puedes utilizar Faker para diversas tareas. El objetivo principal es desarrollar un enfoque centrado en la privacidad para probar sistemas. En la última parte, generaremos datos falsos para complementar los datos originales utilizando el proveedor localizado de Faker.
Puedes encontrar todo el código de este tutorial en este libro de trabajo de DataLab; puedes crear fácilmente tu propia copia del libro de trabajo para ejecutar todo el código en el navegador, sin instalar nada en tu ordenador.
En primer lugar, iniciaremos un generador falso utilizando `Faker()`. Por defecto, utiliza la configuración regional "en_US".
from faker import Faker
fake = Faker()El objeto "falso" puede generar datos utilizando nombres de propiedades. Por ejemplo, `fake.name()` se utiliza para generar el nombre completo de una persona al azar.
print(fake.name())
>>> Jessica RobinsonDel mismo modo, podemos generar una dirección de correo electrónico, un nombre de país, un texto, una geolocalización y una URL falsos, como se muestra a continuación.
print(fake.email())
print(fake.country())
print(fake.name())
print(fake.text())
print(fake.latitude(), fake.longitude())
print(fake.url())Salida
ybanks@example.com
Mayotte
Mr. Jose Browning DDS
Dog might bank dog total life financial. Dark view doctor time just.
Stay second treatment language theory. Space seek adult create matter imagine lay.
51.7514185 -148.802970
http://fischer.info/Puedes utilizar distintas localizaciones para generar datos en diversos idiomas y para distintas regiones.
En el ejemplo siguiente, generaremos los datos en español y la región en España.
fake = Faker("es_ES")
print(fake.email())
print(fake.country())
print(fake.name())
print(fake.text())
print(fake.latitude(), fake.longitude())
print(fake.url())Salida
Como podemos ver, el nombre del individuo ha cambiado, y el texto está en español.
casandrahierro@example.com
Tonga
Juan Solera-Mancebo
Cumque adipisci eligendi aperiam. Quas laboriosam amet at dignissimos. Excepturi pariatur ipsam esse.
89.180798 -2.274117
https://corbacho-galan.net/Intentémoslo de nuevo con la lengua alemana y Alemania como país. Para generar un perfil de usuario completo, utilizaremos la función `perfil()`.
fake = Faker("de_DE")
fake.profile()Salida
Está bastante claro cómo podemos utilizar Faker para generar datos en varios idiomas para varios países. Al cambiar la configuración regional, cambiarán el nombre, el trabajo, la dirección, la empresa y otros datos de identificación del usuario según el idioma y el país.
{'job': 'Erzieher',
'company': 'Stadelmann Thanel GmbH',
'ssn': '631-64-0521',
'residence': 'Leo-Schinke-Allee 298\n26224 Altötting',
'current_location': (Decimal('51.5788595'), Decimal('29.780659')),
'blood_group': 'B+',
'website': ['https://www.schmidtke.de/',
'https://roskoth.com/',
'http://www.textor.de/',
'https://www.zirme.com/'],
'username': 'vdoerr',
'name': 'Francesca Fröhlich',
'sex': 'F',
'address': 'Steinbergallee 13\n84765 Saarbrücken',
'mail': 'smuehle@gmail.com',
'birthdate': datetime.date(1998, 3, 19)}En este ejemplo, crearemos un marco de datos pandas utilizando Faker.
from random import randint
import pandas as pd
fake = Faker()
def input_data(x):
# pandas dataframe
data = pd.DataFrame()
for i in range(0, x):
data.loc[i,'id']= randint(1, 100)
data.loc[i,'name']= fake.name()
data.loc[i,'address']= fake.address()
data.loc[i,'latitude']= str(fake.latitude())
data.loc[i,'longitude']= str(fake.longitude())
return data
input_data(10)El resultado es increíble. Tenemos columnas id, nombre, dirección, latitud y longitud con datos únicos de usuario.

Para reproducir el resultado, tenemos que fijar la semilla. Así, cada vez que volvamos a ejecutar la célula de código, obtendremos resultados similares.
Faker.seed(2)
input_data(10)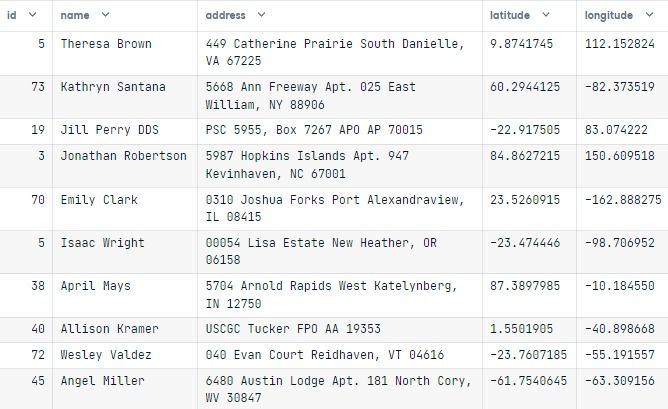
También podemos generar una frase que contenga las palabras clave que elijamos. Similar a `text(), texts(), paragraph(), word() y words()`. Puedes aumentar el número de palabras de una frase estableciendo el argumento nb_palabras.
En el ejemplo siguiente, generamos cinco frases utilizando una lista de palabras. No es perfecto, pero puede ayudarnos a probar aplicaciones que requieren toneladas de datos de texto.
word_list = ["DataCamp", "says", "great", "loves", "tutorial", "workplace"]
for i in range(0, 5):
print(fake.sentence(ext_word_list=word_list))Salida
Loves great says.
Says workplace workplace tutorial great loves.
Loves workplace workplace loves workplace loves great DataCamp.
Loves says workplace great.
Workplace great DataCamp.En esta parte, utilizaremos los Datos de Comercio Electrónico del repositorio de conjuntos de datos de DataCamp y añadiremos datos de usuario falsos utilizando las columnas CustomerID y Country. Nos ayudará a mantener la privacidad del usuario y a probar el sistema con parámetros adicionales.
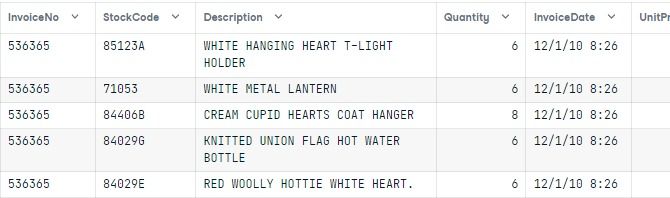
Para cargar el archivo CSV, utilizaremos la función `read_csv()` de pandas y mostraremos las cinco primeras filas con `head()`.
# Loading CSV file
Ecommerce = pd.read_csv("e-commerce.csv")
Ecommerce.head()El conjunto de datos consta de las columnas Número de factura, Código de inventario (ID de producto), Descripción, Nombre del producto (artículo), Cantidad (por transacción), Fecha de factura, Precio unitario (en libras), ID de cliente y País.
Para crear un objeto falsificador localizado, mostraremos nombres de países únicos y los utilizaremos para crear un diccionario. Como podemos observar, tenemos siete países, y en la siguiente parte crearemos siete generadores localizados falsos.
Ecommerce.Country.dropna().unique()
>>> array(['United Kingdom', 'France', 'Australia', 'Netherlands', 'Germany',
'Norway', 'EIRE'], dtype=object)En la función `anónimo`, tenemos:
La función siguiente utiliza el marco de datos y añade cuatro nuevas columnas con datos de usuario basados en las columnas CustomerID y Country.
def anonymous(df):
# Extracting unique CustomerID
unique_id = df.CustomerID.dropna().unique()
# Creating the dictionary for Faker localized providers
local = {
"United Kingdom": "en_GB",
"France": "fr_FR",
"Australia": "en_AU",
"Netherlands": "nl_NL",
"Germany": "de_DE",
"Norway": "no_NO",
"EIRE": "ga_IE",
}
for i in unique_id:
# Extracting row index
row_id = df[df["CustomerID"] == i].index
# Extracting country name for faker locale
CountryName = Ecommerce.loc[
Ecommerce["CustomerID"] == i, "Country"
].to_numpy()[0]
# Using locale dictionary to create faker locale generator
code = local[CountryName]
fake = Faker(code)
# Generating fake data and adding it to dataframe
CustomerName = fake.name()
Address = fake.address()
Latitude = str(fake.latitude())
Longitude = str(fake.longitude())
for x in row_id:
df.loc[x, "CustomerName"] = CustomerName
df.loc[x, "Address"] = Address
df.loc[x, "Latitude"] = Latitude
df.loc[x, "Longitude"] = Longitude
return dfUtilizaremos semilla(5) para la reproducibilidad y ejecutaremos una función `anónima` en el marco de datos de Comercio Electrónico.
# Using seed for reproducibility
Faker.seed(5)
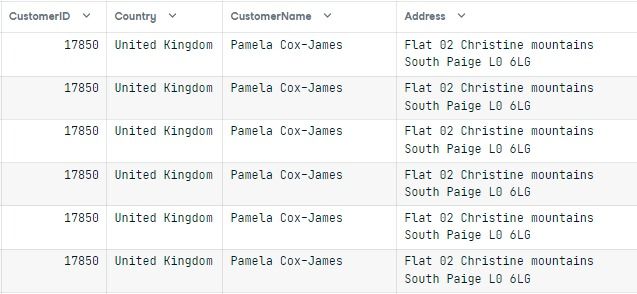
secure_db = anonymous(Ecommerce)
secure_dbLos primeros resultados muestran los datos de 17850, Reino Unido, y Pamela Cox-James.
Para visualizar los resultados localizados de la función, necesitamos ver los datos de una única columna País.
display_db = []
for i in Ecommerce.Country.dropna().unique():
display_db.append(secure_db[secure_db["Country"] == i].to_numpy()[0])
pd.DataFrame(display_db, columns=Ecommerce.columns)El resultado es prometedor. Puedes ver diferentes nombres por región y lengua. Las direcciones se emparejan con el país. Con este método, puedes eliminar los datos de identificación personal y crear datos localizados utilizando Faker para proteger la privacidad del usuario y ahorrar dinero.
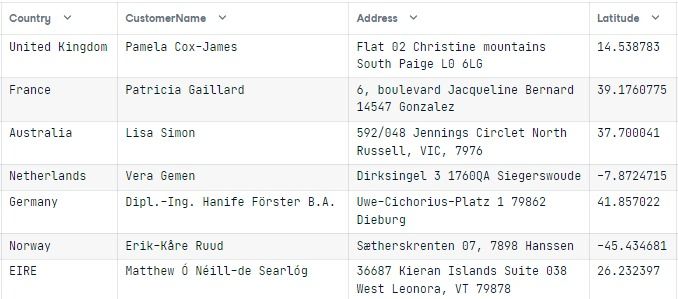
El código fuente está disponible en este libro de trabajo de DataLab.
Uno de los inconvenientes de utilizar Python Faker es que proporciona datos de baja calidad. Puede funcionar para probar aplicaciones, pero carece de precisión de datos. Por ejemplo, los nombres no coinciden con el correo electrónico, el nombre de dominio o el nombre de usuario.
Puedes personalizar el proveedor o crear uno nuevo según tus preferencias, pero te llevará más tiempo perfeccionar el sistema. En ese momento, puedes crear tu paquete Python utilizando `random.choice()`.
En big tech, los científicos de datos utilizan diversas herramientas para procesar datos sensibles y mantener la privacidad de los datos. También están utilizando datos sintéticos para mejorar el rendimiento de los modelos, reducir la base, probar aplicaciones y ahorrar costes en el desarrollo de soluciones de IA de vanguardia.
Si estás interesado en saber más, echa un vistazo a la trayectoria profesional de Científico de Datos con Python para comenzar tu viaje de convertirte en un científico de datos seguro de ti mismo.
En este tutorial, hemos aprendido la importancia de los datos sintéticos y sus aplicaciones. También hemos generado datos falsos desde cero utilizando Python Faker para probar los sistemas de datos y mantener la privacidad de los usuarios.
Cursos para Python
Curso
Curso
Curso
Tutorial
Duong Vu
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Kurtis Pykes
Tutorial
Abid Ali Awan

