Curso
Limpiar datos con PySpark
4 h
33.2K
Los datos que se pueden clasificar pero carecen de una jerarquía u orden inherente se conocen como datos categóricos. En otras palabras, no existe ninguna conexión matemática entre las categorías. El sexo de una persona (hombre/mujer), el color de sus ojos (azul, verde, marrón, etc.), el tipo de vehículo que conduce (turismo, todoterreno, camión, etc.) o el tipo de fruta que consume (manzana, plátano, naranja, etc.) son ejemplos de datos categóricos.
En este tutorial, describiremos los métodos de tratamiento y preprocesamiento de datos categóricos. Antes de hablar de la importancia de preparar los datos categóricos para los modelos de aprendizaje automático, definiremos los datos categóricos y sus tipos. Además, veremos varios métodos de codificación, análisis de datos categóricos y métodos de visualización en Python, e ideas más avanzadas como datos categóricos de gran cardinalidad y varios métodos de codificación.
La información se representa utilizando dos formas diferentes de datos: datos categóricos y datos numéricos. Los datos que se pueden clasificar o agrupar se denominan datos categóricos. Los hombres y las mujeres entran en la categoría de género, los colores rojo, verde y azul entran en la categoría de colores, y la categoría de países podría incluir EE.UU., Canadá, México, etc.
Los datos numéricos son aquellos que pueden expresarse como un número. Algunos ejemplos de datos numéricos son la altura, el peso y la temperatura.
En términos sencillos, los datos categóricos son información que puede clasificarse en categorías, mientras que los datos numéricos son información que puede expresarse como un número. Dado que la mayoría de los algoritmos de aprendizaje automático se crean para operar con datos numéricos, en este campo los datos categóricos se tratan de forma diferente a los numéricos. Antes de que los datos categóricos puedan utilizarse como entrada para un modelo de aprendizaje automático, primero deben transformarse en datos numéricos. Este proceso de conversión de datos categóricos en representación numérica se conoce como codificación.
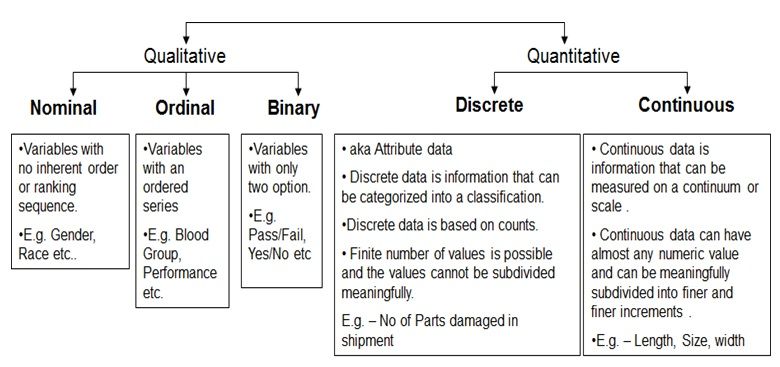
Datos cualitativos y cuantitativos - Fuente de imágenes
Existen dos tipos de datos categóricos: nominales y ordinales.
Los datos nominales son datos categóricos que pueden dividirse en grupos, pero estos grupos carecen de jerarquía u orden intrínsecos. Algunos ejemplos de datos nominales son las marcas (Coca-Cola, Pepsi, Sprite), las variedades de ingredientes de las pizzas (pepperoni, champiñones, cebolla) y el color del pelo (rubio, castaño, negro, etc.).
Los datos ordinales, por su parte, describen información que puede clasificarse y tiene un orden o clasificación distintos. Los niveles de estudios (bachillerato, licenciatura, máster), los niveles de satisfacción laboral (muy satisfecho, satisfecho, neutro, insatisfecho, muy insatisfecho) y las valoraciones por estrellas (1 estrella, 2 estrellas, 3 estrellas, 4 estrellas, 5 estrellas) son algunos ejemplos de datos ordinales.
Al dar a cada categoría un valor numérico que refleja su orden o clasificación, los datos ordinales pueden transformarse en datos numéricos y utilizarse en el aprendizaje automático. Para los algoritmos que son sensibles al tamaño de los datos de entrada, esto puede ser útil.
La distinción entre datos nominales y ordinales no siempre es obvia en la práctica y puede variar en función del caso de uso concreto. Por ejemplo, mientras que algunas personas pueden considerar la "clasificación por estrellas" como un dato ordinal, otras pueden considerarla un dato nominal. Lo más importante es ser consciente de la naturaleza de sus datos y seleccionar la estrategia de codificación que mejor capte las relaciones de sus datos.
La biblioteca de código abierto pandas de Python se utiliza ampliamente para el análisis y la manipulación de datos. Tiene grandes capacidades para tratar con datos estructurados, incluyendo como marcos de datos y series que pueden tratar con datos tabulares con filas y columnas etiquetadas.
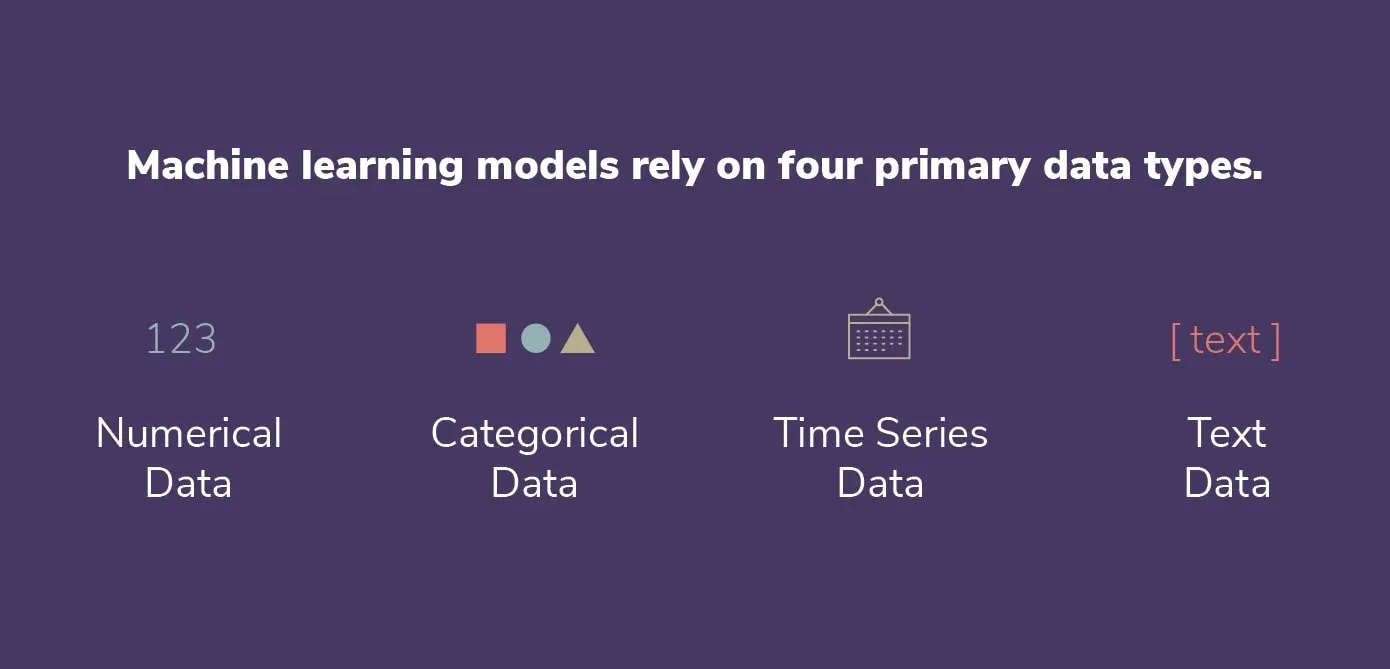
pandas también proporciona varias funciones para leer y escribir diferentes tipos de archivos (csv, parquet, base de datos, etc.). Cuando se lee un fichero utilizando pandas, a cada columna se le asigna un tipo de datos basado en la inferencia. Aquí están todos los tipos de datos que pandas puede asignar:
Los datos que no encajan en los otros tipos de datos, incluyendo cadenas, tipos mixtos u otros objetos, se representan mediante los tipos de datos categoría y objeto en pandas. Sin embargo, presentan algunas diferencias significativas que influyen en su funcionamiento y rendimiento.
El tipo de datos categórico se creó para la información que sólo tiene unos pocos valores posibles, como las categorías o las etiquetas. Internamente, los datos categóricos se representan como una colección de números, lo que puede acelerar algunas operaciones y conservar memoria en comparación con el tipo de datos objeto correspondiente. Además, los datos categóricos pueden ordenarse de forma lógica y facilitan procedimientos eficaces de agrupación y agregación.
Por otro lado, el tipo de datos objeto sirve como cajón de sastre para la información que no cabe en los otros tipos de datos. Listas, diccionarios y otros objetos son sólo algunos ejemplos de los muchos tipos de datos que puede incluir. Aunque los datos de objetos tienen una gran flexibilidad, también pueden ser más lentos y consumir más memoria que los datos categóricos del mismo tamaño y no pueden someterse a algunas de las operaciones especializadas que son posibles con los datos de categorías.
En general, puede que le interese utilizar el tipo de datos categóricos si sus datos tienen un número reducido de valores posibles y pretende realizar muchas agrupaciones o agregaciones. El tipo de datos objeto suele ser una opción segura en todos los demás casos. El tipo de datos ideal, sin embargo, depende en última instancia de su caso de uso único y de las propiedades de sus datos.
Veamos un ejemplo leyendo un archivo csv de GitHub.
# read csv using pandas
data = pd.read_csv(‘https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv’)
# check the head of dataframe
data.head()Salida:
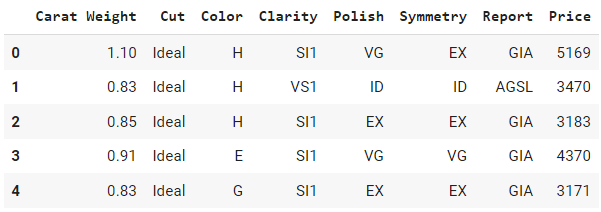
¿Puede identificar cuáles de estas columnas son categóricas y cuáles numéricas? Bien, todas las columnas de este ejemplo son categóricas excepto `Carat Weight` y `Price.` Veamos si estamos en lo cierto comprobando los tipos de datos por defecto.
# check the data types
data.dtypesSalida:

Fíjese cómo a `Price` se le asigna el tipo `int64`, a `Carat Weight` como `float64`, y el resto de las columnas son objetos, exactamente como esperábamos.
Hay algunas funciones en pandas, una popular biblioteca de análisis de datos en Python, que le permiten analizar rápidamente tipos de datos categóricos en su conjunto de datos. Examinémoslos uno por uno:
`value_counts()` es una función de la biblioteca pandas que devuelve la frecuencia de cada valor único en una columna de datos categóricos. Esta función es útil cuando se desea obtener una comprensión rápida de la distribución de una variable categórica, como las categorías más comunes y su frecuencia.
# read csv using pandas
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# check value counts of Cut column
data['Cut'].value_counts()Salida:

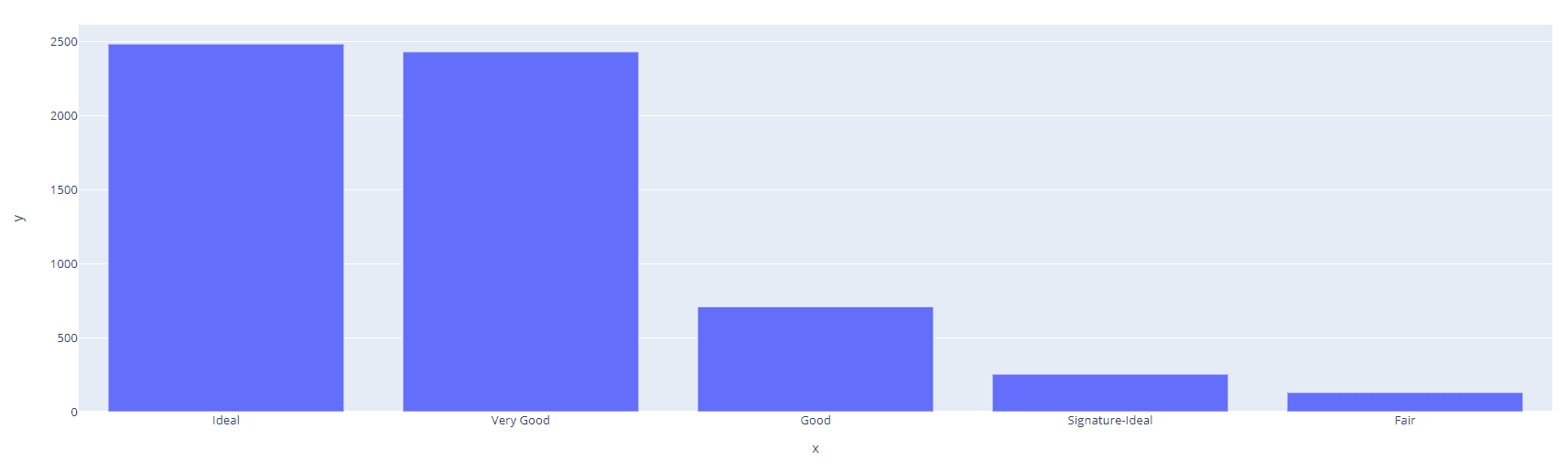
Si desea visualizar la distribución, puede utilizar la biblioteca `plotly` para dibujar un gráfico de barras interactivo.
import plotly.express as px
cut_counts = data['Cut'].value_counts()
fig = px.bar(x=cut_counts.index, y=cut_counts.values)
fig.show()Salida:
`groupby()` es una función de Pandas que permite agrupar datos por una o más columnas y aplicar funciones agregadas como suma, media y recuento. Esta función es útil cuando se desea realizar un análisis más complejo de datos categóricos, como calcular la media de una variable numérica para cada categoría. Veamos un ejemplo:
# read csv using pandas
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# average carat weight and price by Cut
data.groupby(by = 'Cut').mean()Salida:
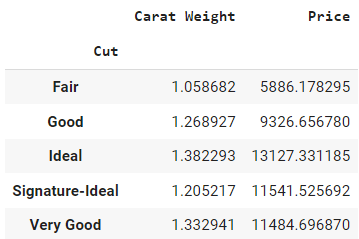
Sólo devolverá un marco de datos con columnas numéricas únicamente. El parámetro `by` dentro del método `groupby` define la columna sobre la que se desea realizar la operación de agrupar por, y a continuación `mean()` fuera de los paréntesis es el método de agregación.
El resultado puede interpretarse como que el precio medio de un diamante con talla justa es de 5.886, y el peso medio es de 1,05, frente al precio medio de 11.485 de un diamante con talla muy buena.
`crosstab()` es una función de pandas que crea una tabla de tabulación cruzada, que muestra la distribución de frecuencias de dos o más variables categóricas. Esta función es útil cuando se desea ver la relación entre dos o más variables categóricas, como por ejemplo cómo se relaciona la frecuencia de una variable con otra variable.
# read csv using pandas
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# cross tab of Cut and Color
pd.crosstab(index=data['Cut'], columns=data['Color'])
Salida:
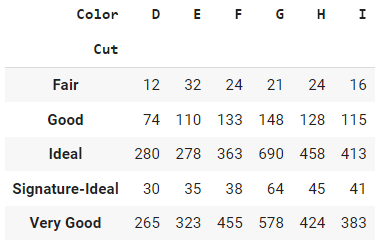
La salida de la función crosstab en pandas es una tabla que muestra la distribución de frecuencias de dos o más variables categóricas. Cada fila de la tabla representa una categoría única en una de las variables, y cada columna representa una categoría única en la otra variable. Las entradas de la tabla son los recuentos de frecuencia de las combinaciones de categorías en las dos variables.
pivot_table()` es una función de Pandas que crea tablas dinámicas, que son similares a las tablas de tabulación cruzada pero con más flexibilidad. Esta función es útil cuando se desea analizar múltiples variables categóricas y su relación con una o más variables numéricas. Las tablas dinámicas permiten agregar datos de múltiples maneras y mostrar los resultados de forma compacta.
# read csv using pandas
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# create pivot table
pd.pivot_table(data, values='Price', index='Cut', columns='Color', aggfunc=np.mean)
Salida:
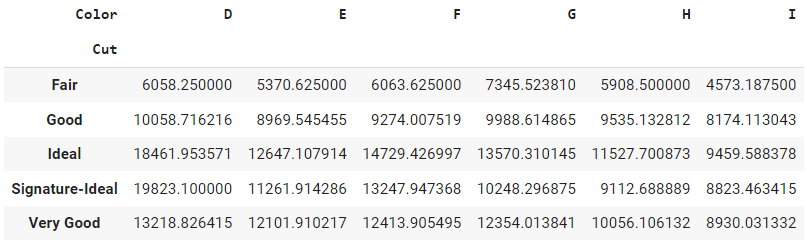
Esta tabla muestra el precio medio de cada talla de diamante para cada color. Las filas representan las distintas tallas de diamante, las columnas los distintos colores de diamante y las entradas de la tabla son el precio medio del diamante.
La función tabla_pivotante es útil cuando se desea resumir y comparar los datos numéricos a través de múltiples variables en un formato de tabla. La función permite agregar los datos utilizando diversas funciones (como media, suma, recuento, etc.) y organizarlos en un formato fácil de leer y analizar.
Los algoritmos de aprendizaje automático no suelen tratar directamente los datos categóricos, ya que la mayoría de los algoritmos están diseñados principalmente para trabajar sólo con datos numéricos. Por lo tanto, antes de que las características categóricas puedan utilizarse como entradas para los algoritmos de aprendizaje automático, deben codificarse como valores numéricos.
Existen varias técnicas para codificar rasgos categóricos, como la codificación de un punto, la codificación ordinal y la codificación de objetivos. La elección de la técnica de codificación depende de las características específicas de los datos y de los requisitos del algoritmo de aprendizaje automático que se utilice.
Una codificación en caliente es un proceso de representación de datos categóricos como un conjunto de valores binarios, donde cada categoría se asigna a un único valor binario. En esta representación, sólo un bit se pone a 1, y el resto a 0, de ahí el nombre de "uno caliente". Se utiliza habitualmente en el aprendizaje automático para convertir datos categóricos en un formato que los algoritmos puedan procesar.
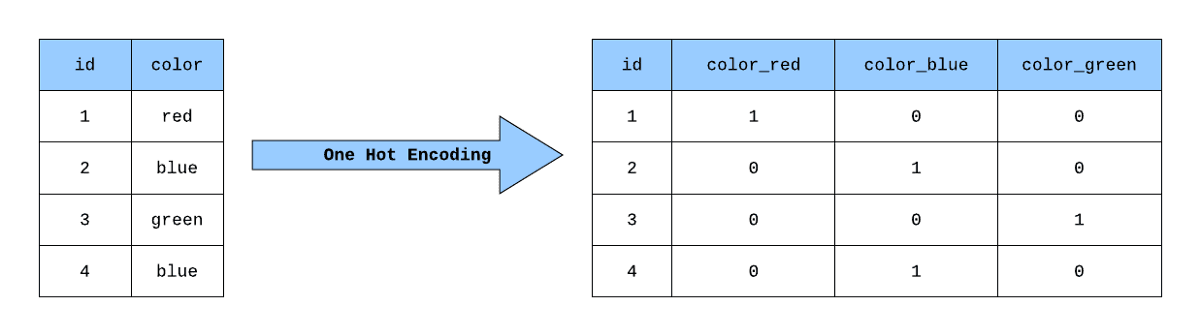
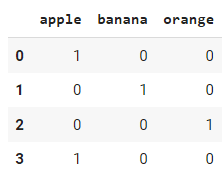
Una forma de conseguirlo en pandas es utilizando el método `pd.get_dummies()`. Es una función de la librería Pandas que se puede utilizar para realizar una codificación one-hot sobre variables categóricas en un DataFrame. Toma un DataFrame y devuelve un nuevo DataFrame con columnas binarias para cada categoría. Aquí tienes un ejemplo de cómo utilizarlo:
Supongamos que tenemos un marco de datos con una columna "fruta" que contiene datos categóricos:
import pandas as pd
# generate df with 1 col and 4 rows
data = {
"fruit": ["apple", "banana", "orange", "apple"]
}
# show head
df = pd.DataFrame(data)
df.head()
Salida:

# apply get_dummies function
df_encoded = pd.get_dummies(df["fruit"])
df_encoded .head()
Salida:
Aunque `pandas.get_dummies` es fácil de usar, un enfoque más común es utilizar `OneHotEncoder` de la biblioteca sklearn, especialmente cuando se realizan tareas de aprendizaje automático. La principal diferencia es que `pandas.get_dummies` no puede aprender codificaciones; sólo puede realizar una codificación en caliente en el conjunto de datos que le pases como entrada. Por otro lado, `sklearn.OneHotEncoder` es una clase que puede guardarse y utilizarse para transformar otros conjuntos de datos entrantes en el futuro.
import pandas as pd
# generate df with 1 col and 4 rows
data = {
"fruit": ["apple", "banana", "orange", "apple"]
}
# one-hot-encode using sklearn
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder()
encoded_results = encoder.fit_transform(df).toarray()
Salida:
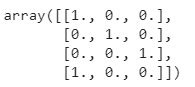
La codificación de etiquetas es una técnica para codificar variables categóricas como valores numéricos, asignando a cada categoría un número entero único. Por ejemplo, supongamos que tenemos una variable categórica "color" con tres categorías: "rojo", "verde" y "azul". Podemos codificar estas categorías utilizando la codificación de etiquetas de la siguiente manera (rojo: 0, verde: 1, azul: 2).
La codificación de etiquetas puede ser útil para algunos algoritmos de aprendizaje automático que requieren entradas numéricas, ya que permite representar datos categóricos de forma que los algoritmos puedan entenderlos. Sin embargo, es importante tener en cuenta que la codificación de etiquetas introduce una ordenación arbitraria de las categorías, que puede no reflejar necesariamente ninguna relación significativa entre ellas. En algunos casos, esto puede dar lugar a problemas en el análisis, especialmente si se interpreta que la ordenación tiene algún tipo de relación ordinal.
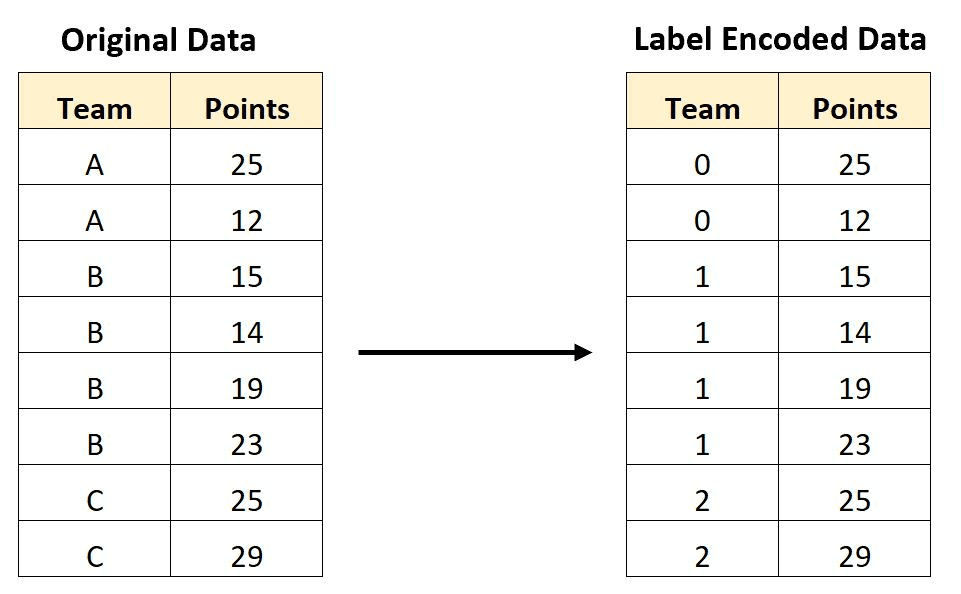
Etiqueta de datos codificados. Fuente de la imagen
Tanto la codificación de una sola vez como la codificación de etiquetas son técnicas para codificar variables categóricas como valores numéricos, pero tienen propiedades diferentes y son apropiadas para casos de uso distintos.
La codificación de una sola categoría representa cada categoría como una columna binaria, con un 1 que indica la presencia de la categoría y un 0 que indica su ausencia. Por ejemplo, supongamos que tenemos una variable categórica "color" con tres categorías: "rojo", "verde" y "azul". Una codificación en caliente representaría esta variable como tres columnas binarias:
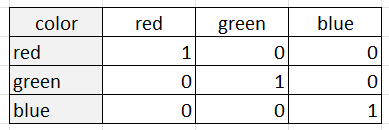
La codificación de una sola categoría es adecuada cuando las categorías no tienen un orden o una relación intrínseca entre sí. Esto se debe a que la codificación one-hot trata cada categoría como una entidad separada sin relación con las demás categorías. La codificación en una sola columna también es útil cuando el número de categorías es relativamente pequeño, ya que el número de columnas puede resultar difícil de manejar para un número muy elevado de categorías.
En cambio, la codificación de etiquetas representa cada categoría como un número entero único. Por ejemplo, la variable "color" con tres categorías podría codificarse como:
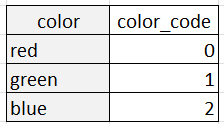
La codificación de etiquetas es adecuada cuando las categorías tienen un orden natural o una relación entre sí, como en el caso de variables ordinales como "pequeño", "mediano" y "grande". En estos casos, los valores enteros asignados a las categorías deben reflejar el orden de las categorías. La codificación de etiquetas también puede ser útil cuando el número de categorías es muy grande, ya que reduce la dimensionalidad de los datos.
En general, la codificación one-hot se utiliza más comúnmente en aplicaciones de aprendizaje automático, ya que es más flexible y evita los problemas de ambigüedad y ordenación arbitraria que pueden surgir con la codificación de etiquetas. Sin embargo, la codificación de etiquetas puede ser útil en determinados contextos en los que las categorías tienen un orden natural o cuando se trata de un número muy elevado de categorías.
La cardinalidad alta se refiere a un gran número de categorías únicas en una característica categórica. Hacer frente a una cardinalidad elevada es un reto habitual en la codificación de datos categóricos para modelos de aprendizaje automático. Una cardinalidad elevada puede dar lugar a una representación dispersa de los datos y repercutir negativamente en el rendimiento de algunos modelos de aprendizaje automático. A continuación se indican algunas técnicas que pueden utilizarse para tratar la cardinalidad alta en características categóricas:
Se trata de combinar categorías poco frecuentes en una única categoría. Esto reduce el número de categorías únicas y también la dispersión en la representación de los datos.
La codificación del objetivo sustituye los valores categóricos por el valor objetivo medio de esa categoría. Proporciona una representación más continua de los datos categóricos y puede ayudar a captar la relación entre la característica categórica y la variable objetivo.
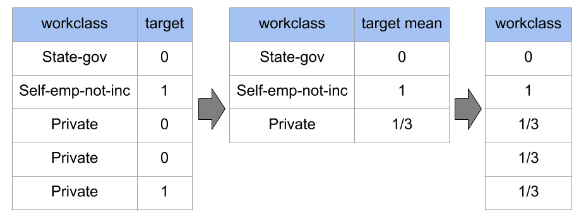
La codificación del peso de la evidencia es similar a la codificación del objetivo, pero tiene en cuenta la distribución de la variable objetivo para cada categoría. La WOE de una categoría se calcula como el logaritmo del cociente de la media del objetivo para la categoría sobre la media de toda la población.
La ingeniería de características es un paso importante en la preparación de los datos para los modelos de aprendizaje automático. Consiste en crear nuevas características a partir de las existentes para mejorar el rendimiento de los modelos. A continuación se indican algunas formas de realizar ingeniería de características en datos categóricos:
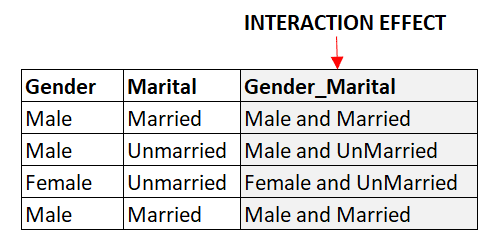
Las variables de interacción son nuevas características creadas mediante la combinación de dos o más características existentes. Por ejemplo, si tenemos dos características categóricas, "Sexo" y "Estado civil", podemos crear una nueva característica, "Sexo-Estado civil", para capturar la interacción entre las dos características. Esto puede ayudar a captar relaciones no lineales entre las características y la variable objetivo.
El binning es el proceso de dividir variables numéricas continuas en intervalos discretos. Esto puede ayudar a reducir el número de valores únicos en la característica, lo que puede ser beneficioso para codificar datos categóricos. El binning también puede ayudar a captar las relaciones no lineales entre las características y la variable objetivo.
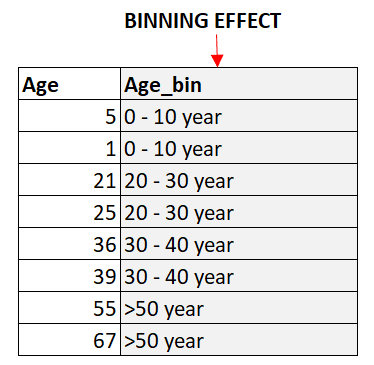
Las variables cíclicas son variables que se repiten a lo largo de un periodo determinado. Por ejemplo, la hora del día es una variable cíclica, ya que se repite cada 24 horas. La codificación de variables cíclicas puede ayudar a captar los patrones periódicos de los datos. Un enfoque habitual para codificar variables cíclicas consiste en crear dos nuevos rasgos, uno que represente el seno de la variable y otro que represente el coseno de la variable.
El tratamiento de datos categóricos es un aspecto importante de muchos proyectos de aprendizaje automático. En este tutorial, hemos explorado varias técnicas para analizar y codificar variables categóricas en Python, incluyendo la codificación one-hot y la codificación label, que son dos técnicas comúnmente utilizadas.
Empezamos introduciendo el concepto de datos categóricos y por qué es importante manejarlos adecuadamente en los modelos de aprendizaje automático. A continuación, proporcionamos una guía paso a paso sobre cómo realizar la codificación one-hot utilizando tanto pandas como scikit-learn, junto con ejemplos de código para ilustrar el proceso.
En este tutorial también se tratan algunos conceptos avanzados, como el tratamiento de datos categóricos de alta cardinalidad, la ingeniería de características, la codificación WOE, etc. Si desea profundizar en este tema, consulte nuestro curso Trabajar con datos categóricos en Python.
Si prefiere el lenguaje R, puede que le interesen nuestros cursos Datos categóricos en el Tidyverse o Inferencia para datos categóricos en R. Ambos son cursos increíbles para usuarios de R.
Más información sobre Python
Curso
Curso
Curso
Tutorial
Avinash Navlani
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
