Introduction to Natural Language Processing in Python
BeginnerSkill Level
4 h
126.7K learners
Ejecuta y edita el código de este tutorial en línea
Ejecutar códigoMuchas veces habrás visto una nube llena de montones de palabras de distintos tamaños, que representan la frecuencia o la importancia de cada palabra. Esto se llama nube de etiquetas o nube de palabras. En este tutorial aprenderás a crear una nube de palabras en Python y a personalizarla como mejor te parezca. Esta herramienta te resultará útil para explorar datos de texto y dar más vida a tu informe.
Practica la generación de una WordCloud en Python con este ejercicio práctico.
En este tutorial, utilizaremos un conjunto de datos de reseñas de vinos del sitio web Wine Enthusiast para aprender:
Es importante recordar que, aunque las nubes de palabras son útiles para visualizar palabras comunes en un texto o conjunto de datos, normalmente sólo son útiles como visión general de alto nivel de los temas. Son similares a los gráficos de barras con colores, pero suelen ser más atractivas visualmente (aunque a veces más difíciles de interpretar). Las nubes de palabras pueden ser especialmente útiles cuando quieres
Sin embargo, es importante tener en cuenta que las nubes de palabras no proporcionan ningún contexto ni una comprensión más profunda de las palabras y frases que se utilizan. Por lo tanto, deben utilizarse junto con otros métodos de análisis e interpretación de datos textuales.
Para empezar a hacer una nube de palabras en Python, necesitarás instalar algunos paquetes que se indican a continuación:
La biblioteca numpy es una de las más populares y útiles que se utilizan para manejar matrices y arrays multidimensionales. También se utiliza en combinación con la biblioteca pandas para realizar análisis de datos.
El módulo os de Python es una biblioteca incorporada, por lo que no tienes que instalarlo. Para saber más sobre el manejo de archivos con el módulo os, te será útil este tutorial de DataCamp sobre lectura y escritura de archivos en Python.
Para la visualización, matplotlib es una biblioteca básica que permite que muchas otras bibliotecas se ejecuten y tracen sobre su base, incluyendo seaborn o wordcloud que utilizarás en este tutorial. La biblioteca pillow es un paquete que permite la lectura de imágenes. Pillow es una envoltura para PIL - Python Imaging Library. Necesitarás esta biblioteca para leer en imagen como la máscara de la nube de palabras.
wordcloud puede ser un poco difícil de instalar. Si sólo lo necesitas para trazar una nube de palabras básica, entonces pip install wordcloud o conda install -c conda-forge wordcloud serían suficientes. Sin embargo, la última versión, con la posibilidad de enmascarar la nube en cualquier forma que elijas, requiere un método de instalación diferente, como se indica a continuación:
git clone https://github.com/amueller/word_cloud.git
cd word_cloud
pip install .Este tutorial utiliza el conjunto de datos de reseñas de vinos de Kaggle. Esta colección es un gran conjunto de datos para el aprendizaje en el que no faltan valores (que llevará tiempo manejar) y que incluye muchos datos de texto (reseñas de vinos), categóricos y numéricos.
Lo primero es cargar todas las bibliotecas necesarias:
# Start with loading all necessary libraries
import numpy as np
import pandas as pd
from os import path
from PIL import Image
from wordcloud import WordCloud, STOPWORDS, ImageColorGeneratorimport matplotlib.pyplot as plt
% matplotlib inlinec:\intelpython3\lib\site-packages\matplotlib\__init__.py:
import warnings
warnings.filterwarnings("ignore")
Si tienes más de 10 bibliotecas, organízalas por secciones (como bibliotecas básicas, visualización, modelos, etc.). Utilizar comentarios en el código hará que éste sea limpio y fácil de seguir.
Ahora, utiliza pandas read_csv para cargar el dataframe. Fíjate en el uso de index_col=0, lo que significa que no leemos el nombre de la fila (índice) como una columna independiente.
# Load in the dataframe
df = pd.read_csv("data/winemag-data-130k-v2.csv", index_col=0)# Looking at first 5 rows of the dataset
df.head()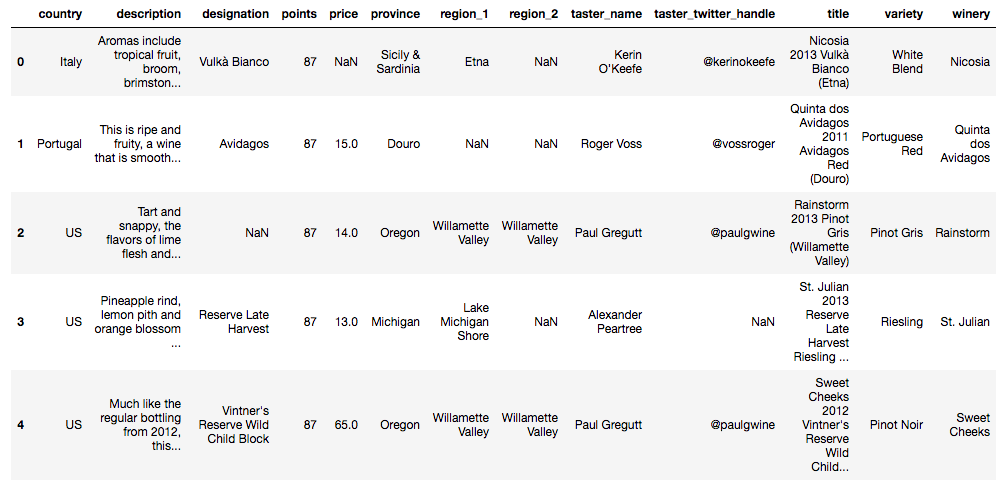
Puedes imprimir alguna información básica sobre el conjunto de datos utilizando print() combinado con .format() para tener una impresión agradable.
print("There are {} observations and {} features in this dataset. \n".format(df.shape[0],df.shape[1]))
print("There are {} types of wine in this dataset such as {}... \n".format(len(df.variety.unique()),
", ".join(df.variety.unique()[0:5])))
print("There are {} countries producing wine in this dataset such as {}... \n".format(len(df.country.unique()),
", ".join(df.country.unique()[0:5])))There are 129971 observations and 13 features in this dataset.
There are 708 types of wine in this dataset such as White Blend, Portuguese Red, Pinot Gris, Riesling, Pinot Noir...
There are 44 countries producing wine in this dataset such as Italy, Portugal, US, Spain, France...df[["country", "description","points"]].head()| country | description | points | |
|---|---|---|---|
| 0 | Italy | Aromas include tropical fruit, broom, brimston... | 87 |
| 1 | Portugal | This is ripe and fruity, a wine that is smooth... | 87 |
| 2 | US | Tart and snappy, the flavors of lime flesh and... | 87 |
| 3 | US | Pineapple rind, lemon pith and orange blossom ... | 87 |
| 4 | US | Much like the regular bottling from 2012, this... | 87 |
Para hacer comparaciones entre grupos de una característica, puedes utilizar groupby() y calcular estadísticas de resumen.
Con el conjunto de datos de vinos, puedes agrupar por países y consultar las estadísticas resumidas de puntos y precios de todos los países o seleccionar los más populares y caros.
# Groupby by country
country = df.groupby("country")
# Summary statistic of all countries
country.describe().head()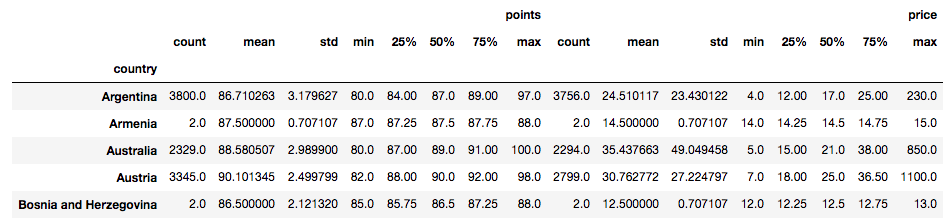
Así se seleccionan los 5 puntos medios más altos de los 44 países:
country.mean().sort_values(by="points",ascending=False).head()| country | points | price |
|---|---|---|
| England | 91.581081 | 51.681159 |
| India | 90.222222 | 13.333333 |
| Austria | 90.101345 | 30.762772 |
| Germany | 89.851732 | 42.257547 |
| Canada | 89.369650 | 35.712598 |
Puedes trazar el número de vinos por país utilizando el método plot de Pandas DataFrame y Matplotlib. Si no estás familiarizado con Matplotlib, echa un vistazo a nuestro tutorial sobre Matplotlib.
plt.figure(figsize=(15,10))
country.size().sort_values(ascending=False).plot.bar()
plt.xticks(rotation=50)
plt.xlabel("Country of Origin")
plt.ylabel("Number of Wines")
plt.show()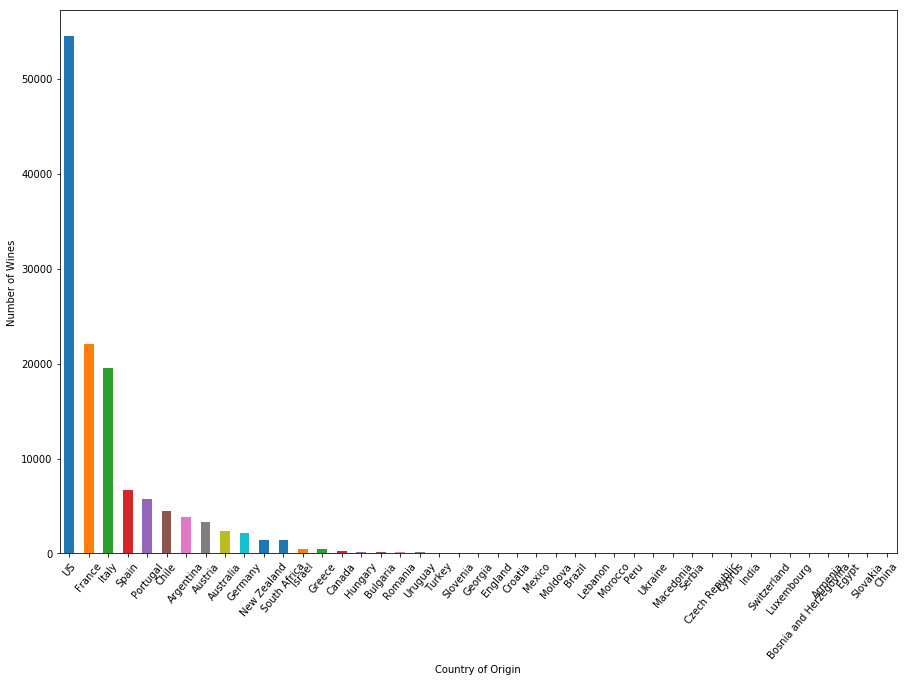
Entre los 44 países productores de vino, EE. UU. tiene más de 50 000 tipos en el conjunto de datos de revisión de vinos, el doble que el siguiente en la clasificación, Francia, país famoso por su vino. Italia también produce mucho vino de calidad, con casi 20 000 vinos abiertos a revisión.
Veamos ahora el gráfico de los 44 países según su vino mejor valorado, utilizando la misma técnica de trazado anterior:
plt.figure(figsize=(15,10))
country.max().sort_values(by="points",ascending=False)["points"].plot.bar()
plt.xticks(rotation=50)
plt.xlabel("Country of Origin")
plt.ylabel("Highest point of Wines")
plt.show()
Australia, EE. UU., Portugal, Italia y Francia tienen vinos de 100 puntos. Si te fijas, Portugal ocupa el 5.º lugar y Australia el 9º. en número de vinos producidos en el conjunto de datos, y ambos países tienen menos de 8000 tipos de vino.
Eso es un poco de exploración de datos para conocer el conjunto de datos que estás utilizando hoy. Ahora empezarás a sumergirte en el plato principal de la comida: la nube de palabras.
Una nube de palabras es una técnica para mostrar qué palabras son las más frecuentes en un texto dado. Podemos utilizar una biblioteca de Python para ayudarnos con esto. Lo primero que debes hacer antes de utilizar cualquier función es consultar el docstring de la función y ver todos los argumentos obligatorios y opcionales. Para ello, escribe ?function y ejecútalo para obtener toda la información.
?WordCloud[1;31mInit signature:[0m [0mWordCloud[0m[1;33m([0m[0mfont_path[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mwidth[0m[1;33m=[0m[1;36m400[0m[1;33m,[0m [0mheight[0m[1;33m=[0m[1;36m200[0m[1;33m,[0m [0mmargin[0m[1;33m=[0m[1;36m2[0m[1;33m,[0m [0mranks_only[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mprefer_horizontal[0m[1;33m=[0m[1;36m0.9[0m[1;33m,[0m [0mmask[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mscale[0m[1;33m=[0m[1;36m1[0m[1;33m,[0m [0mcolor_func[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mmax_words[0m[1;33m=[0m[1;36m200[0m[1;33m,[0m [0mmin_font_size[0m[1;33m=[0m[1;36m4[0m[1;33m,[0m [0mstopwords[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mrandom_state[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mbackground_color[0m[1;33m=[0m[1;34m'black'[0m[1;33m,[0m [0mmax_font_size[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mfont_step[0m[1;33m=[0m[1;36m1[0m[1;33m,[0m [0mmode[0m[1;33m=[0m[1;34m'RGB'[0m[1;33m,[0m [0mrelative_scaling[0m[1;33m=[0m[1;36m0.5[0m[1;33m,[0m [0mregexp[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mcollocations[0m[1;33m=[0m[1;32mTrue[0m[1;33m,[0m [0mcolormap[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mnormalize_plurals[0m[1;33m=[0m[1;32mTrue[0m[1;33m,[0m [0mcontour_width[0m[1;33m=[0m[1;36m0[0m[1;33m,[0m [0mcontour_color[0m[1;33m=[0m[1;34m'black'[0m[1;33m)[0m[1;33m[0m[0m
[1;31mDocstring:[0m
Word cloud object for generating and drawing.
Parameters
----------
font_path : string
Font path to the font that will be used (OTF or TTF).
Defaults to DroidSansMono path on a Linux machine. If you are on
another OS or don't have this font; you need to adjust this path.
width : int (default=400)
Width of the canvas.
height : int (default=200)
Height of the canvas.
prefer_horizontal : float (default=0.90)
The ratio of times to try horizontal fitting as opposed to vertical.
If prefer_horizontal < 1, the algorithm will try rotating the word
if it doesn't fit. (There is currently no built-in way to get only
vertical words.)
mask : nd-array or None (default=None)
If not None, gives a binary mask on where to draw words. If mask is not
None, width and height will be ignored, and the shape of mask will be
used instead. All white (#FF or #FFFFFF) entries will be considered
"masked out" while other entries will be free to draw on. [This
changed in the most recent version!]
contour_width: float (default=0)
If mask is not None and contour_width > 0, draw the mask contour.
contour_color: color value (default="black")
Mask contour color.
scale : float (default=1)
Scaling between computation and drawing. For large word-cloud images,
using scale instead of larger canvas size is significantly faster, but
might lead to a coarser fit for the words.
min_font_size : int (default=4)
Smallest font size to use. Will stop when there is no more room in this
size.
font_step : int (default=1)
Step size for the font. font_step > 1 might speed up computation but
give a worse fit.
max_words : number (default=200)
The maximum number of words.
stopwords : set of strings or None
The words that will be eliminated. If None, the build-in STOPWORDS
list will be used.
background_color : color value (default="black")
Background color for the word cloud image.
max_font_size : int or None (default=None)
Maximum font size for the largest word. If None, the height of the image is
used.
mode : string (default="RGB")
Transparent background will be generated when mode is "RGBA" and
background_color is None.
relative_scaling : float (default=.5)
Importance of relative word frequencies for font-size. With
relative_scaling=0, only word-ranks are considered. With
relative_scaling=1, a word that is twice as frequent will have twice
the size. If you want to consider the word frequencies and not only
their rank, relative_scaling around .5 often looks good.
.. versionchanged: 2.0
Default is now 0.5.
color_func : callable, default=None
Callable with parameters word, font_size, position, orientation,
font_path, random_state that returns a PIL color for each word.
Overwrites "colormap".
See colormap for specifying a matplotlib colormap instead.
regexp : string or None (optional)
Regular expression to split the input text into tokens in process_text.
If None is specified, ``r"\w[\w']+"`` is used.
collocations : bool, default=True
Whether to include collocations (bigrams) of two words.
.. versionadded: 2.0
colormap : string or matplotlib colormap, default="viridis"
Matplotlib colormap to randomly draw colors from for each word.
Ignored if "color_func" is specified.
.. versionadded: 2.0
normalize_plurals : bool, default=True
Whether to remove trailing 's' from words. If True and a word
appears with and without a trailing 's', the one with trailing 's'
is removed and its counts are added to the version without
trailing 's' -- unless the word ends with 'ss'.
Attributes
----------
``words_`` : dict of string to float
Word tokens with associated frequency.
.. versionchanged: 2.0
``words_`` is now a dictionary
``layout_`` : list of tuples (string, int, (int, int), int, color))
Encodes the fitted word cloud. Encodes for each word the string, font
size, position, orientation, and color.
Notes
-----
Larger canvases will make the code significantly slower. If you need a
large word cloud, try a lower canvas size, and set the scale parameter.
The algorithm might give more weight to the ranking of the words
then their actual frequencies, depending on the ``max_font_size`` and the
scaling heuristic.
[1;31mFile:[0m c:\intelpython3\lib\site-packages\wordcloud\wordcloud.py
[1;31mType:[0m typePuedes ver que el único argumento necesario para un objeto WordCloud es el textomientras que todos los demás son opcionales.
Empecemos con un ejemplo sencillo: utilizar la descripción de la primera observación como entrada para la nube de palabras. Los tres pasos son:
# Start with one review:
text = df.description[0]
# Create and generate a word cloud image:
wordcloud = WordCloud().generate(text)
# Display the generated image:
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
¡Estupendo! Puedes ver que la primera reseña mencionaba mucho los sabores secos (dried) y los aromas del vino (Aromas).
Ahora, cambia algunos argumentos opcionales de la nube de palabras como max_font_size, max_word, y background_color.
# lower max_font_size, change the maximum number of word and lighten the background:
wordcloud = WordCloud(max_font_size=50, max_words=100, background_color="white").generate(text)
plt.figure()
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
Parece que utilizar max_font_size aquí podría no ser una buena idea. Hace más difícil ver las diferencias entre las frecuencias de las palabras. Sin embargo, aclarar el fondo hace que la nube sea más fácil de leer.
Si quieres guardar la imagen, WordCloud proporciona la función to_file
# Save the image in the img folder:
wordcloud.to_file("img/first_review.png")<wordcloud.wordcloud.WordCloud at 0x16f1d704978>El resultado será así cuando los cargues:
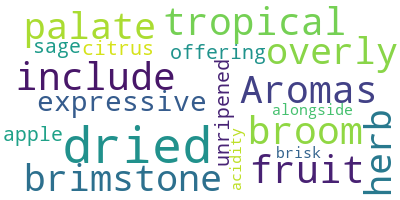
Seguramente te habrás fijado en el argumento interpolation="bilinear" en plt.imshow(). Esto se hace para que la imagen mostrada aparezca más limpia. Para más información sobre la elección, este tutorial sobre métodos de interpolación para imshow es un recurso útil.
Así que ahora combinarás todas las reseñas de vinos en un gran texto y crearás una gran nube para ver qué características son las más comunes en estos vinos.
text = " ".join(review for review in df.description)
print ("There are {} words in the combination of all review.".format(len(text)))
There are 31661073 words in the combination of all review.
# Create stopword list:
stopwords = set(STOPWORDS)
stopwords.update(["drink", "now", "wine", "flavor", "flavors"])
# Generate a word cloud image
wordcloud = WordCloud(stopwords=stopwords, background_color="white").generate(text)
# Display the generated image:
# the matplotlib way:
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()

Parece que la cereza negra (black cherry) y el cuerpo (full bodied) son las características más mencionadas, y el Cabernet Sauvignon es la más popular de todas. Esto concuerda con el hecho de que el Cabernet Sauvignon "es una de las variedades de uva tinta más reconocidas del mundo". Se cultiva en casi todos los principales países productores de vino, en un variado espectro de climas, desde el valle canadiense de Okanagan hasta el valle libanés de Beqaa".[1]
Ahora, ¡vertamos estas palabras en una copa (o incluso en una botella) de vino!
Para crear una forma para tu nube de palabras, primero tienes que encontrar un archivo PNG que se convierta en la máscara. A continuación encontrarás uno muy bonito que está disponible en Internet:

No todas las imágenes de máscara tienen el mismo formato, lo que da lugar a resultados diferentes, por lo que la función WordCloud no funciona correctamente. Para asegurarte de que tu máscara funciona, echémosle un vistazo en forma de matriz numpy:
wine_mask = np.array(Image.open("img/wine_mask.png"))
wine_mask
array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]], dtype=uint8)
El funcionamiento de las funciones de enmascaramiento requiere que toda la parte blanca de la máscara sea 255 y no 0 (tipo entero). Este valor representa la "intensity" del píxel. Los valores de 255 son blanco puro, mientras que los valores de 1 son negro. Aquí, puedes utilizar la función proporcionada a continuación para transformar tu máscara si ésta tiene el mismo formato que la anterior. Fíjate si tienes una máscara cuyo fondo no sea 0, sino 1 ó 2, ajusta la función para que coincida con tu máscara.
Primero, utiliza la función transform_format() para intercambiar el número 0 por el 255.
def transform_format(val):
if val == 0:
return 255
else:
return val
A continuación, crea una nueva máscara con la misma forma que la máscara que tienes entre manos y aplica la función transform_format() a cada valor de cada fila de la máscara anterior.
# Transform your mask into a new one that will work with the function:
transformed_wine_mask = np.ndarray((wine_mask.shape[0],wine_mask.shape[1]), np.int32)
for i in range(len(wine_mask)):
transformed_wine_mask[i] = list(map(transform_format, wine_mask[i]))
Ahora tienes una nueva máscara con la forma correcta. Imprimir la máscara transformada es la mejor forma de comprobar si la función actúa correctamente.
# Check the expected result of your mask
transformed_wine_mask
array([[255, 255, 255, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255],
...,
[255, 255, 255, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255]])
Con la máscara adecuada, puedes empezar a hacer la nube de palabras con la forma seleccionada. Observa que en la función WordCloud hay un argumento mask que toma la máscara transformada que creaste anteriormente. contour_width y contour_color son, como su nombre indica, argumentos para ajustar las características del contorno de la nube. La botella de vino que tienes aquí es una botella de vino tinto, así que firebrick parece una buena elección para el color del contorno. Para más opciones de color, puedes echar un vistazo a esta tabla de códigos de color.
# Create a word cloud image
wc = WordCloud(background_color="white", max_words=1000, mask=transformed_wine_mask,
stopwords=stopwords, contour_width=3, contour_color='firebrick')
# Generate a wordcloud
wc.generate(text)
# store to file
wc.to_file("img/wine.png")
# show
plt.figure(figsize=[20,10])
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()

¡Voilà! ¡Has creado una nube de palabras con forma de botella de vino! Parece que las descripciones de los vinos mencionan con más frecuencia la cereza negra, los sabores frutales y las características de gran cuerpo del vino. Ahora veamos más detenidamente las reseñas de cada país y tracemos la nube de palabras utilizando la bandera de cada país. A continuación se muestra un ejemplo que crearás en breve:

Puedes combinar todas las opiniones de los cinco países que tienen más vinos. Para encontrar esos países, puedes mirar el gráfico país vs. número de vinos de arriba o utilizar el grupo que obtuviste antes para encontrar el número de observaciones de cada país (cada grupo) y sort_values() con el argumento ascending=False para ordenar de forma descendente.
country.size().sort_values(ascending=False).head()
country
US 54504
France 22093
Italy 19540
Spain 6645
Portugal 5691
dtype: int64
Así que ahora tienes 5 países principales: EE. UU., Francia, Italia, España y Portugal. Puedes cambiar el número de países poniendo el número que quieras dentro de head() como se indica a continuación
country.size().sort_values(ascending=False).head(10)
country
US 54504
France 22093
Italy 19540
Spain 6645
Portugal 5691
Chile 4472
Argentina 3800
Austria 3345
Australia 2329
Germany 2165
dtype: int64
Por ahora, cinco países deberían ser suficientes.
Para obtener todas las opiniones de cada país, puedes concatenar todas las opiniones utilizando la sintaxis " ".join(list), que une todos los elementos de una lista, separándolos por espacios en blanco.
# Join all reviews of each country:
usa = " ".join(review for review in df[df["country"]=="US"].description)
fra = " ".join(review for review in df[df["country"]=="France"].description)
ita = " ".join(review for review in df[df["country"]=="Italy"].description)
spa = " ".join(review for review in df[df["country"]=="Spain"].description)
por = " ".join(review for review in df[df["country"]=="Portugal"].description)
A continuación, puedes crear la nube de palabras como se ha indicado anteriormente. Puedes combinar los dos pasos de crear y generar en uno, como se indica a continuación. La asignación de colores se realiza justo antes de trazar la nube utilizando la función ImageColorGenerator de la biblioteca WordCloud.
# Generate a word cloud image
mask = np.array(Image.open("img/us.png"))
wordcloud_usa = WordCloud(stopwords=stopwords, background_color="white", mode="RGBA", max_words=1000, mask=mask).generate(usa)
# create coloring from image
image_colors = ImageColorGenerator(mask)
plt.figure(figsize=[7,7])
plt.imshow(wordcloud_usa.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
# store to file
plt.savefig("img/us_wine.png", format="png")
plt.show()

¡Tiene buena pinta! Ahora repitamos con una reseña de Francia.
# Generate a word cloud image
mask = np.array(Image.open("img/france.png"))
wordcloud_fra = WordCloud(stopwords=stopwords, background_color="white", mode="RGBA", max_words=1000, mask=mask).generate(fra)
# create coloring from image
image_colors = ImageColorGenerator(mask)
plt.figure(figsize=[7,7])
plt.imshow(wordcloud_fra.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
# store to file
plt.savefig("img/fra_wine.png", format="png")
#plt.show()
Ten en cuenta que debes guardar la imagen después de trazarla para tener la nube de palabras con el patrón de colores deseado.

# Generate a word cloud image
mask = np.array(Image.open("img/italy.png"))
wordcloud_ita = WordCloud(stopwords=stopwords, background_color="white", max_words=1000, mask=mask).generate(ita)
# create coloring from image
image_colors = ImageColorGenerator(mask)
plt.figure(figsize=[7,7])
plt.imshow(wordcloud_ita.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
# store to file
plt.savefig("img/ita_wine.png", format="png")
#plt.show()

Después de Italia está España:
# Generate a word cloud image
mask = np.array(Image.open("img/spain.png"))
wordcloud_spa = WordCloud(stopwords=stopwords, background_color="white", max_words=1000, mask=mask).generate(spa)
# create coloring from image
image_colors = ImageColorGenerator(mask)
plt.figure(figsize=[7,7])
plt.imshow(wordcloud_spa.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
# store to file
plt.savefig("img/spa_wine.png", format="png")
#plt.show()

Por último, Portugal:
# Generate a word cloud image
mask = np.array(Image.open("img/portugal.png"))
wordcloud_por = WordCloud(stopwords=stopwords, background_color="white", max_words=1000, mask=mask).generate(por)
# create coloring from image
image_colors = ImageColorGenerator(mask)
plt.figure(figsize=[7,7])
plt.imshow(wordcloud_por.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
# store to file
plt.savefig("img/por_wine.png", format="png")
#plt.show()

El resultado final está en la siguiente tabla para comparar las máscaras y las nubes de palabras. ¿Cuál es tu favorito?
Ya hemos visto varios ejemplos de nubes de palabras y cómo crearlas en Python. Sin embargo, merece la pena explorar cómo interpretar estas visualizaciones de datos. En general, el tamaño de cada palabra en la nube representa su frecuencia o importancia en el texto. Normalmente, cuanto más frecuentemente aparezca una palabra en el texto, más grande aparecerá en la nube de palabras.
Hay varias cosas que debes tener en cuenta al interpretar las nubes de palabras:
En general, una nube de palabras puede ser una herramienta útil para visualizar rápidamente los temas e ideas clave de un texto. Sin embargo, es importante tener en cuenta que es sólo una herramienta entre muchas otras para analizar datos de texto, y que debe utilizarse junto con otros métodos para un análisis y una comprensión más profundos.
¡Lo has conseguido! Has aprendido varias formas de dibujar una nube de palabras en Python utilizando la biblioteca WordCloud, que sería útil para la visualización de cualquier análisis de texto. También aprenderás a enmascarar la nube en cualquier forma, utilizando cualquier color de tu elección. Si quieres practicar tus habilidades, considera el proyecto del DataCamp: Los temas más candentes del machine learning
Si te interesa aprender más sobre el Procesamiento del lenguaje natural, sigue nuestro curso Fundamentos del Procesamiento del lenguaje natural en Python.
Cursos de Python
Curso
Curso
Curso
Tutorial
Moez Ali
Tutorial
Moez Ali
Tutorial
Kurtis Pykes
Tutorial
Abid Ali Awan
Tutorial
Bekhruz Tuychiev