Course
Intermediate Python
4 hr
1.4M

Synthetic data is computer-generated data that is similar to real-world data. The primary purpose of synthetics data is to increase the privacy and integrity of systems. For example, to protect the Personally Identifiable Information (PII) or Personal Health Information (PHI) of the users, companies have to implement data protection strategies. Using synthetic data can help companies test new applications and protect user privacy.
In the case of machine learning, we use synthetic data to improve model performance. It is also valid for situations where data is scarce and unbalanced. The typical use of synthetics data in machine learning is self-driving vehicles, security, robotics, fraud protection, and healthcare.
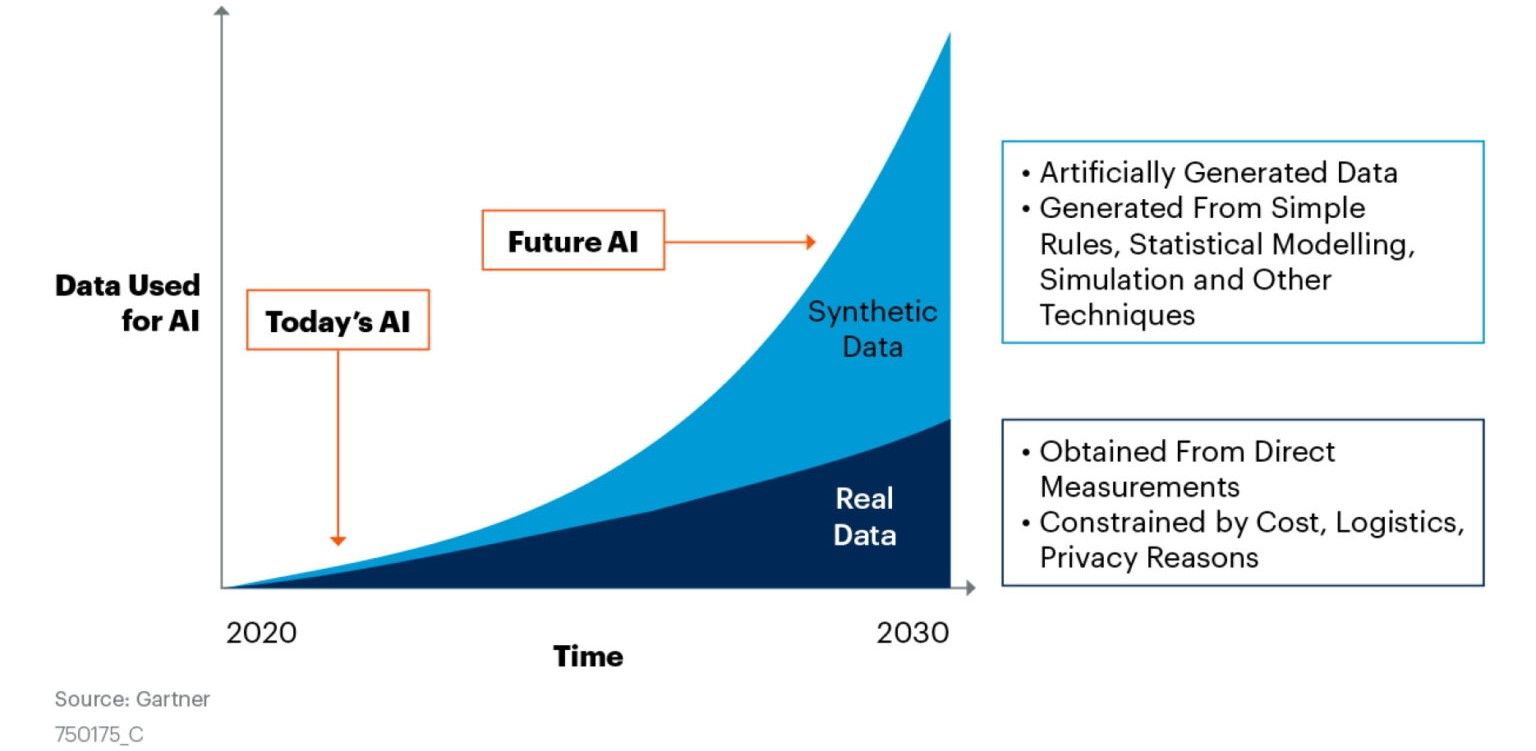
Image from Nvidia
According to data from Gartner, by 2024, 60% of data used to develop machine learning and analytical applications will be synthetically generated. But why are we seeing an upward trend of synthetics data?
It is costly to collect and clean real-world data, and in some cases, it is rare. For example, bank fraud, breast cancer, self-driving cars, and malware attack data are rare to find in the real world. Even if you get the data, it will take time and resources to clean and process it for machine learning tasks.
In the first part of the tutorial, we will learn about why we need synthetic data, its applications, and how to generate it. In the final part, we will explore the Python Faker library and use it to create synthetic data for testing and maintaining user privacy.

Image by Author
We need synthetic data for user privacy, application testing, improving model performance, representing rare cases, and reducing the cost of operation.
In this section, we will learn how companies use synthetics data to build cost-effective, privacy-friendly, high-performance applications.
We can use fake data generators, statistical tools, neural networks, and generative adversarial networks to generate synthetic data.
Generating fake databases using Faker library to test databases and systems. It can generate fake user profiles with addresses and all the essential information. You can also use it to generate random text and paragraphs. It helps companies protect users' privacy in the testing phase and save money in acquiring real-world datasets.
Understanding data distribution to generate a completely new dataset using statistical tools such as Gaussian, Exponential, Chi-square, t, lognormal, and Uniform. You must have subject knowledge to generate distribution-based synthetics data.
Variational Autoencoder is an unsupervised learning method that uses an encoder and decoder to compress the original dataset and generate a representation of the original dataset. It is designed to optimize the correlation between the input and output datasets.
Generative Adversarial Network is the most popular way of generating data. You can use it to render synthetic images, sound, tabular data, and simulation data. It uses generator and discriminator deep learning model architecture to generate synthetic data by comparing random samples with actual data. Read our Demystifying Generative Adversarial Nets tutorial to create your own synthetic data using Keras.
Python Faker is an open-source Python package used to create a fake dataset for application testing, bootstrapping the database, and maintaining user anonymity.

Image by Author
You can install Faker using:
pip install fakerFaker comes with command line support, Pytest fixtures, Localization (support different regions), reproducibility, and dynamic provider (customizing it to your needs).
You can also use Faker's basic functionalities to create a quick dataset and customize it to your needs. In the table below, you can check various Faker functions and the purpose.
|
Faker Function |
Purpose |
|
name() |
Generates fake full name |
|
credit_card_full() |
Generates credit card number with expiry and CVV |
|
email() |
Generates fake email address |
|
url() |
Generate fake URL |
|
phone_number() |
Generates fake phone number with country code |
|
address() |
Generates fake full address |
|
license_plate() |
Generates fake license plate |
|
currency() |
Generate tuple of currency code and full form |
|
color_name() |
Generate random color name |
|
local_latlng() |
Generate latitude, longitude, area, country, and states |
|
domain_name() |
Generate the fake website based fake person name |
|
text() |
Generate the fake small text |
|
company() |
Generate fake company name |
To learn about more advanced functions, check out the Faker documentation.
It is important to review these functions as we will use them to create various examples and dataframes.
In this section, we will use Python Faker to generate synthetics data. It consists of 5 examples of how you can use Faker for various tasks. The main goal is to develop a privacy-centric approach for testing systems. In the last part, we will generate fake data to complement the original data using Faker's localized provider.
You can find all the code for this tutorial in this DataLab workbook; you can easily create your own workbook copy to run all of the code in the browser, without installing anything on your computer.
First, we will initiate a fake generator using `Faker()`. By default, it is using the “en_US” locale.
from faker import Faker
fake = Faker()The “fake” object can generate data by using property names. For example, `fake.name()` is used for generating a random person's full name.
print(fake.name())
>>> Jessica RobinsonSimilarly, we can generate a fake email address, country name, text, geolocation, and URL, as shown below.
print(fake.email())
print(fake.country())
print(fake.name())
print(fake.text())
print(fake.latitude(), fake.longitude())
print(fake.url())Output
[email protected]
Mayotte
Mr. Jose Browning DDS
Dog might bank dog total life financial. Dark view doctor time just.
Stay second treatment language theory. Space seek adult create matter imagine lay.
51.7514185 -148.802970
http://fischer.info/You can use different locales to generate data in diverse languages and for distinct regions.
In the example below, we will generate data in Spanish and the region in Spain.
fake = Faker("es_ES")
print(fake.email())
print(fake.country())
print(fake.name())
print(fake.text())
print(fake.latitude(), fake.longitude())
print(fake.url())Output
As we can see, the name of the individual has changed, and the text is in Spanish.
[email protected]
Tonga
Juan Solera-Mancebo
Cumque adipisci eligendi aperiam. Quas laboriosam amet at dignissimos. Excepturi pariatur ipsam esse.
89.180798 -2.274117
https://corbacho-galan.net/Let’s try again with the German language and Germany as the country. To generate a full user profile, we will use the `profile()` function.
fake = Faker("de_DE")
fake.profile()Output
It is quite clear how we can use Faker to generate data in various languages for various countries. Changing locale will change name, job, address, company, and other user identification data based on language and country.
{'job': 'Erzieher',
'company': 'Stadelmann Thanel GmbH',
'ssn': '631-64-0521',
'residence': 'Leo-Schinke-Allee 298\n26224 Altötting',
'current_location': (Decimal('51.5788595'), Decimal('29.780659')),
'blood_group': 'B+',
'website': ['https://www.schmidtke.de/',
'https://roskoth.com/',
'http://www.textor.de/',
'https://www.zirme.com/'],
'username': 'vdoerr',
'name': 'Francesca Fröhlich',
'sex': 'F',
'address': 'Steinbergallee 13\n84765 Saarbrücken',
'mail': '[email protected]',
'birthdate': datetime.date(1998, 3, 19)}In this example, we will create a pandas dataframe using Faker.
from random import randint
import pandas as pd
fake = Faker()
def input_data(x):
# pandas dataframe
data = pd.DataFrame()
for i in range(0, x):
data.loc[i,'id']= randint(1, 100)
data.loc[i,'name']= fake.name()
data.loc[i,'address']= fake.address()
data.loc[i,'latitude']= str(fake.latitude())
data.loc[i,'longitude']= str(fake.longitude())
return data
input_data(10)The output looks incredible. We have id, name, address, latitude, and longitude columns with unique user data.

To reproduce the result, we have to set the seed. So whenever we run the code cell again, we will get similar results.
Faker.seed(2)
input_data(10)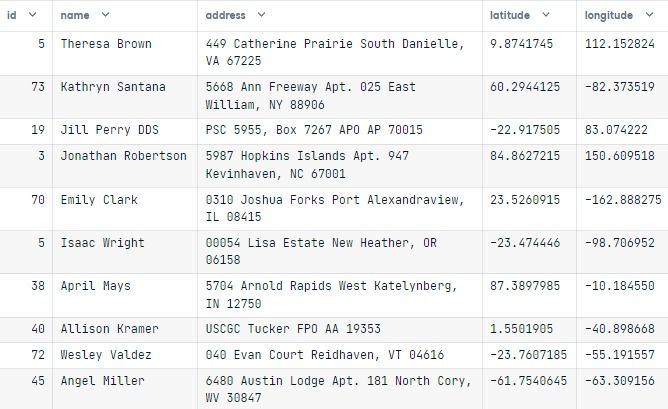
We can also generate a sentence that contains keywords of our choice. Similar to `text(), texts(), paragraph(), word(), and words()`. You can increase the number of words in a sentence by setting the nb_words argument.
In the example below, we generate five sentences using a word list. It is not perfect, but it can help us test applications that require tons of text data.
word_list = ["DataCamp", "says", "great", "loves", "tutorial", "workplace"]
for i in range(0, 5):
print(fake.sentence(ext_word_list=word_list))Output
Loves great says.
Says workplace workplace tutorial great loves.
Loves workplace workplace loves workplace loves great DataCamp.
Loves says workplace great.
Workplace great DataCamp.In this part, we will use E-Commerce Data from DataCamp’s dataset repository and add fake user data using CustomerID and Country columns. It will help us maintain user privacy and test the system on additional parameters.
To load CSV file, we will use and pandas `read_csv()` function and display top five rows using `head()`
# Loading CSV file
Ecommerce = pd.read_csv("e-commerce.csv")
Ecommerce.head()The dataset consists of InvoiceNo, StockCode (product ID), Description, Product (item) name, Quantity (per transaction), InvoiceDate, UnitPrice (in Pounds), CustomerID, and Country columns.
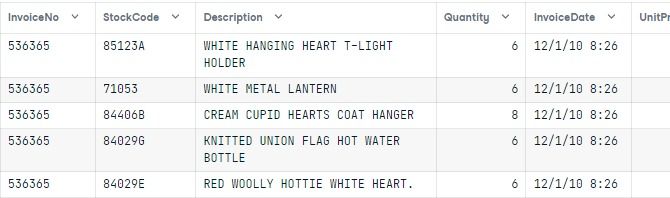
To create a localized faker object, we will display unique country names and use them to create a dictionary. As we can observe, we have seven countries, and we will be creating seven faker localized generators in the next part.
Ecommerce.Country.dropna().unique()
>>> array(['United Kingdom', 'France', 'Australia', 'Netherlands', 'Germany',
'Norway', 'EIRE'], dtype=object)In the `anonymous` function, we have:
The function below uses the dataframe and adds four new columns with user data based on CustomerID and Country columns.
def anonymous(df):
# Extracting unique CustomerID
unique_id = df.CustomerID.dropna().unique()
# Creating the dictionary for Faker localized providers
local = {
"United Kingdom": "en_GB",
"France": "fr_FR",
"Australia": "en_AU",
"Netherlands": "nl_NL",
"Germany": "de_DE",
"Norway": "no_NO",
"EIRE": "ga_IE",
}
for i in unique_id:
# Extracting row index
row_id = df[df["CustomerID"] == i].index
# Extracting country name for faker locale
CountryName = Ecommerce.loc[
Ecommerce["CustomerID"] == i, "Country"
].to_numpy()[0]
# Using locale dictionary to create faker locale generator
code = local[CountryName]
fake = Faker(code)
# Generating fake data and adding it to dataframe
CustomerName = fake.name()
Address = fake.address()
Latitude = str(fake.latitude())
Longitude = str(fake.longitude())
for x in row_id:
df.loc[x, "CustomerName"] = CustomerName
df.loc[x, "Address"] = Address
df.loc[x, "Latitude"] = Latitude
df.loc[x, "Longitude"] = Longitude
return dfWe will use seed(5) for reproducibility and run an `anonymous` function on the Ecommerce dataframe.
# Using seed for reproducibility
Faker.seed(5)
secure_db = anonymous(Ecommerce)
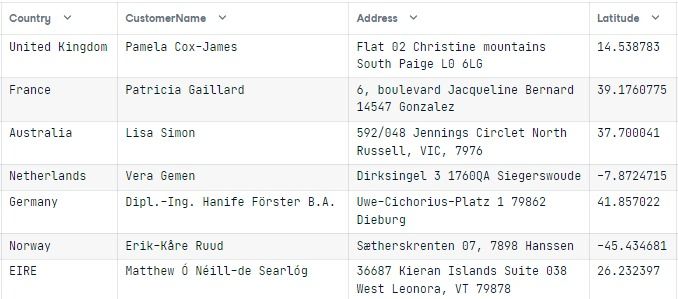
secure_dbThe first few results show the data of 17850, United Kingdom, and Pamela Cox-James.
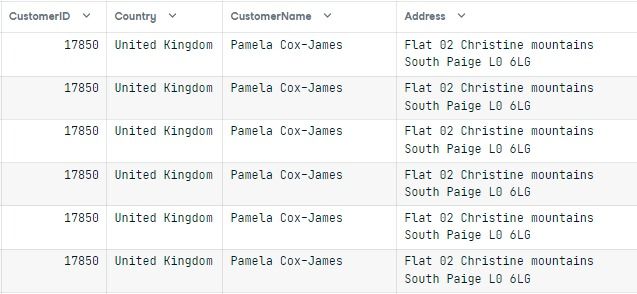
To visualize the localized results of the function, we need to view data for a unique Country column.
display_db = []
for i in Ecommerce.Country.dropna().unique():
display_db.append(secure_db[secure_db["Country"] == i].to_numpy()[0])
pd.DataFrame(display_db, columns=Ecommerce.columns)The result is promising. You can see different names per region and language. The addresses are matched with the country. With this method, you can drop personal identification data and create localized data using Faker to protect user privacy and save money.
The code source is available in this DataLab workbook.
One of the drawbacks of using Python Faker is that it provides poor data quality. It can work for application testing, but it lacks data accuracy. For example, names do not match email, domain name, or username.
You can customize the provider or create a new one based on your preference, but it will take you extra time to perfect the system. In that time, you can create your Python package using `random.choice()`.
In big tech, data scientists are using various tools to process sensitive data and maintain data privacy. They are also using synthetics data to improve model performance, reduce basis, test applications, and save cost in developing cutting-edge AI solutions.
If you are interested in learning more, check out the Data Scientist with Python career track to begin your journey of becoming a confident data scientist.
In this tutorial, we have learned the importance of synthetics data and its applications. We have also generated fake data from scratch using Python Faker to test data systems and maintain users' privacy.
Courses for Python
Course
Course
Course
blog
Abid Ali Awan
6 min
Tutorial
DataCamp Team
Tutorial
Abid Ali Awan
Tutorial
Matthew Przybyla
Tutorial
Katharine Jarmul
code-along
Alexandra Ebert


