
programa
Contenedores y virtualización con Docker y Kubernetes
13 h
Acabas de detener el contenedor Docker para actualizar un archivo de configuración, pero al reiniciarlo, todos los datos habían desaparecido. He estado ahí.
Esto ocurre porque los contenedores son efímeros por defecto: cuando se eliminan, cualquier dato almacenado dentro de su capa grabable desaparece. Las aplicaciones reales no pueden funcionar así. Necesitas bases de datos que persistan, archivos de configuración que sobrevivan a los reinicios y registros a los que puedas acceder realmente.
Docker Mount resuelve este problema conectando el almacenamiento del contenedor a ubicaciones externas. Hay tres tipos: volúmenes para datos de producción, montajes vinculados para flujos de trabajo de desarrollo y tmpfs para archivos temporales almacenados en la memoria.
En este artículo, te explicaré cómo elegir el tipo de montaje adecuado para tu caso de uso y cómo implementarlo correctamente. Para comprender todo lo que se trata en este artículo, necesitarás tener un conocimiento básico sobre Docker y la contenedorización. Realiza nuestro curso de Docker de nivel intermedio « » para ponerte al día rápidamente.
Los contenedores Docker utilizan un sistema de archivos por capas que trata todo como temporal por defecto.
Cuando creas una imagen de Docker, cada instrucción de tu Dockerfile crea una nueva capa de solo lectura. Estas capas se apilan unas sobre otras como una baraja de cartas. Si descargas una imagen de Ubuntu con Python instalado, obtendrás una capa para el sistema operativo base y otra para Python.
El problema es que todas estas capas son de solo lectura. No puedes modificarlos.
Cuando inicias un contenedor, Docker añade una capa más encima: la capa de contenedor grabable.
Aquí es donde se producen todos los cambios. Todos los archivos que creas, las configuraciones que modificas y los registros de tablas que añades se almacenan aquí.
Suena muy bien, pero el problema es que esta capa está vinculada al ciclo de vida del contenedor.
Cuando detienes y eliminas el contenedor con docker rm, la capa grabable desaparece. Todo en lo que has trabajado se ha perdido. Docker no solicitará confirmación. Simplemente borra todo.
Este diseño tiene sentido para aplicaciones sin estado que no necesitan recordar nada entre ejecuciones. Pero las aplicaciones reales no son sin estado.
La capa grabable presenta dos problemas importantes para los entornos de producción.
En primer lugar, se pierden datos cuando los contenedores se detienen. ¿De qué sirve un contenedor de bases de datos que olvida todas las filas después de reiniciarse? No se me ocurre ninguna otra cosa aparte de ejecutar pruebas de integración para tu aplicación.
En segundo lugar, no puedes compartir datos entre contenedores. Supongamos que estás ejecutando una aplicación web y un trabajador en segundo plano que necesitan acceder a los mismos archivos. Si esos archivos se encuentran en la capa grabable de un contenedor, el otro contenedor no podrá verlos.
Los montajes de Docker resuelven ambos problemas conectando los contenedores al almacenamiento que existe fuera del ciclo de vida del contenedor. Puedes montar un directorio desde tu máquina host o un volumen gestionado por Docker. Tus datos persisten incluso cuando se eliminan los contenedores. Varios contenedores pueden montarse en la misma ubicación y compartir archivos en tiempo real.
Por eso es necesario utilizar soportes. A continuación, repasemos los tipos de montaje y luego te mostraré cómo funcionan.
Docker te ofrece tres formas de gestionar los datos persistentes, y cada una de ellas resuelve problemas diferentes. A continuación, se explica qué hace cada tipo y cuándo debes utilizarlo.
Los volúmenes son la respuesta predeterminada de Docker al almacenamiento persistente.
Docker crea y gestiona volúmenes por ti en un directorio dedicado en tu máquina host. No es necesario que sepas dónde está ese directorio, todo se gestiona automáticamente. Esto hace que los volúmenes sean portátiles entre diferentes sistemas y seguros de usar en producción.
Cuando eliminas un contenedor, el volumen permanece intacto. Si inicias un nuevo contenedor y conectas el mismo volumen, todos tus datos estarán exactamente donde los dejaste.
Los volúmenes funcionan mejor para bases de datos de producción, estado de aplicaciones y cualquier dato que no puedas perder.
Los montajes vinculados conectan un directorio específico de tu máquina host directamente a un contenedor.
Tú eliges la ruta exacta en tu host, como /home/user/project, y Docker la asigna al contenedor. Cuando cambias un archivo en tu host, el contenedor verá el cambio inmediatamente. Cambia un archivo en el contenedor y aparecerá en tu host.
Esta sincronización en tiempo real hace que los montajes vinculantes sean perfectos para el desarrollo.
Pero los montajes vinculantes conllevan riesgos. Exponen las rutas del host a los contenedores y dependen de estructuras de directorios específicas que podrían no existir en otras máquinas.
Los montajes tmpfs almacenan datos en la memoria de tu host en lugar de en el disco.
No se escribe nada en el sistema de archivos. Cuando el contenedor se detiene, los datos desaparecen por completo. Esto hace que los montajes tmpfs sean útiles paradatos temporales e es que no deseas conservar, como tokens de autenticación, datos de sesión o archivos de caché que vas a reconstruir de todos modos.
Dicho esto, los montajes tmpfs están limitados por la RAM disponible y solo funcionan en hosts Linux.
Los volúmenes son la solución de almacenamiento lista para producción de Docker, y deberías utilizarlos por defecto a menos que tengas una razón específica para no hacerlo.
Son gestionados íntegramente por Docker, funcionan de manera coherente en diferentes plataformas y, por su diseño, sobreviven a la eliminación de contenedores. Si gestionas bases de datos, almacenas el estado de aplicaciones o manejas datos que deben sobrevivir a un único contenedor, los volúmenes son la solución.
Docker almacena los volúmenes en un directorio específico de tu máquina host:
/var/lib/docker/volumes/~/Library/Containers/com.docker.docker/Data/vms/0/data/\\wsl$\docker-desktop-data\data\docker\volumes\, suponiendo que usas WSL2 como backend.No gestionas este directorio directamente. Docker gestiona la creación, los permisos y la limpieza a través de tu propia API. Esta separación significa que los volúmenes funcionan de la misma manera tanto si utilizas Linux, Mac o Windows, lo que a su vez hace que la configuración de tu contenedor sea portátil entre entornos de desarrollo y producción.
Lo que hay que recordar aquí es que los volúmenes existen independientemente de cualquier contenedor. Cuando creas un volumen, lo adjuntas a un contenedor, ejecutas tu aplicación y, a continuación, detienes y eliminas ese contenedor, el volumen permanece exactamente donde está, con todos tus datos intactos.
Si inicias un nuevo contenedor y adjuntas el mismo volumen, tus datos seguirán estando ahí.
Puedes crear un volumen con nombre antes de iniciar cualquier contenedor:
docker volume create mydata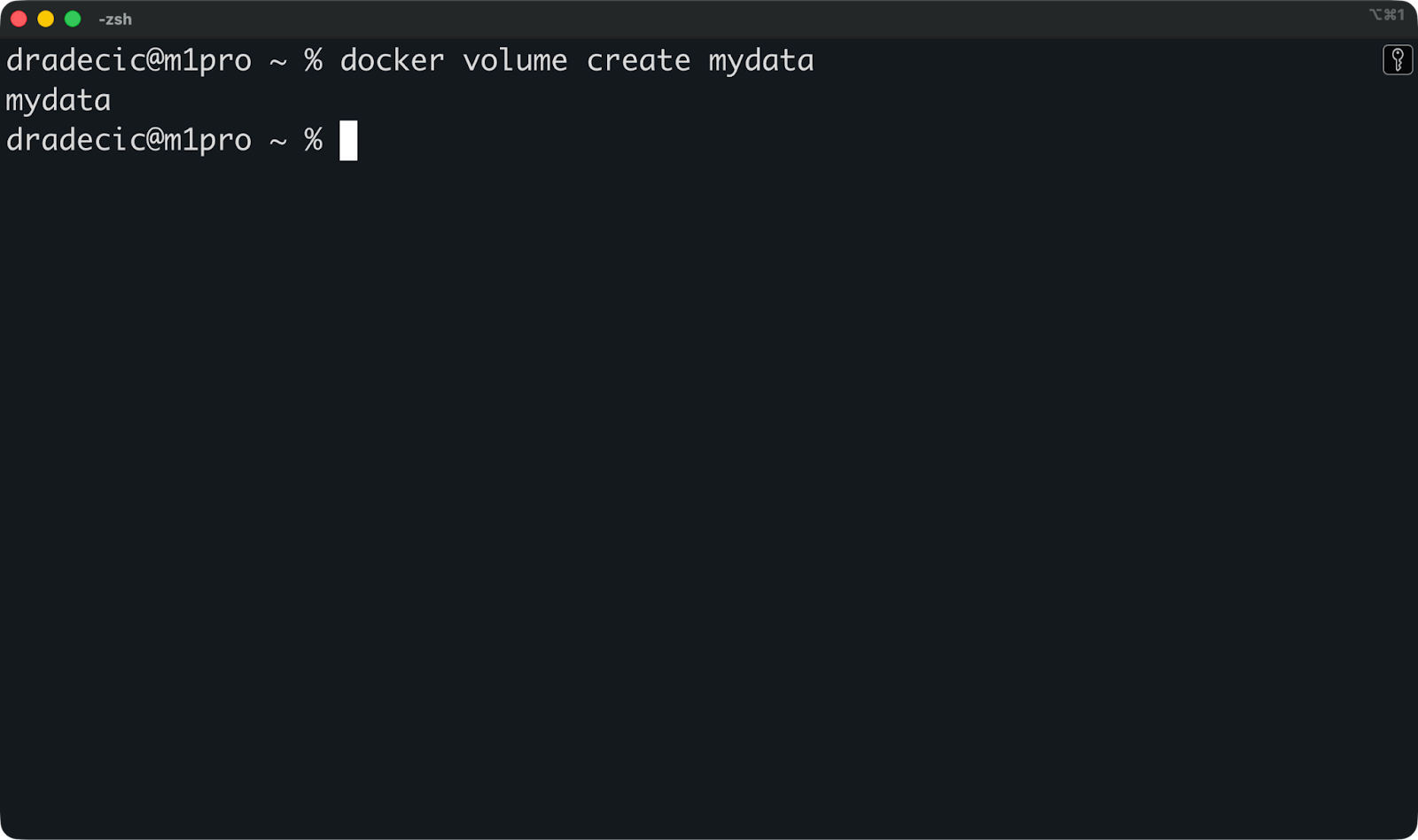
A continuación, adjúntalo cuando ejecutes un contenedor utilizando el indicador « --mount »:
docker run -d \
--name postgres-db \
--mount source=mydata,target=/var/lib/postgresql/data \
postgres:18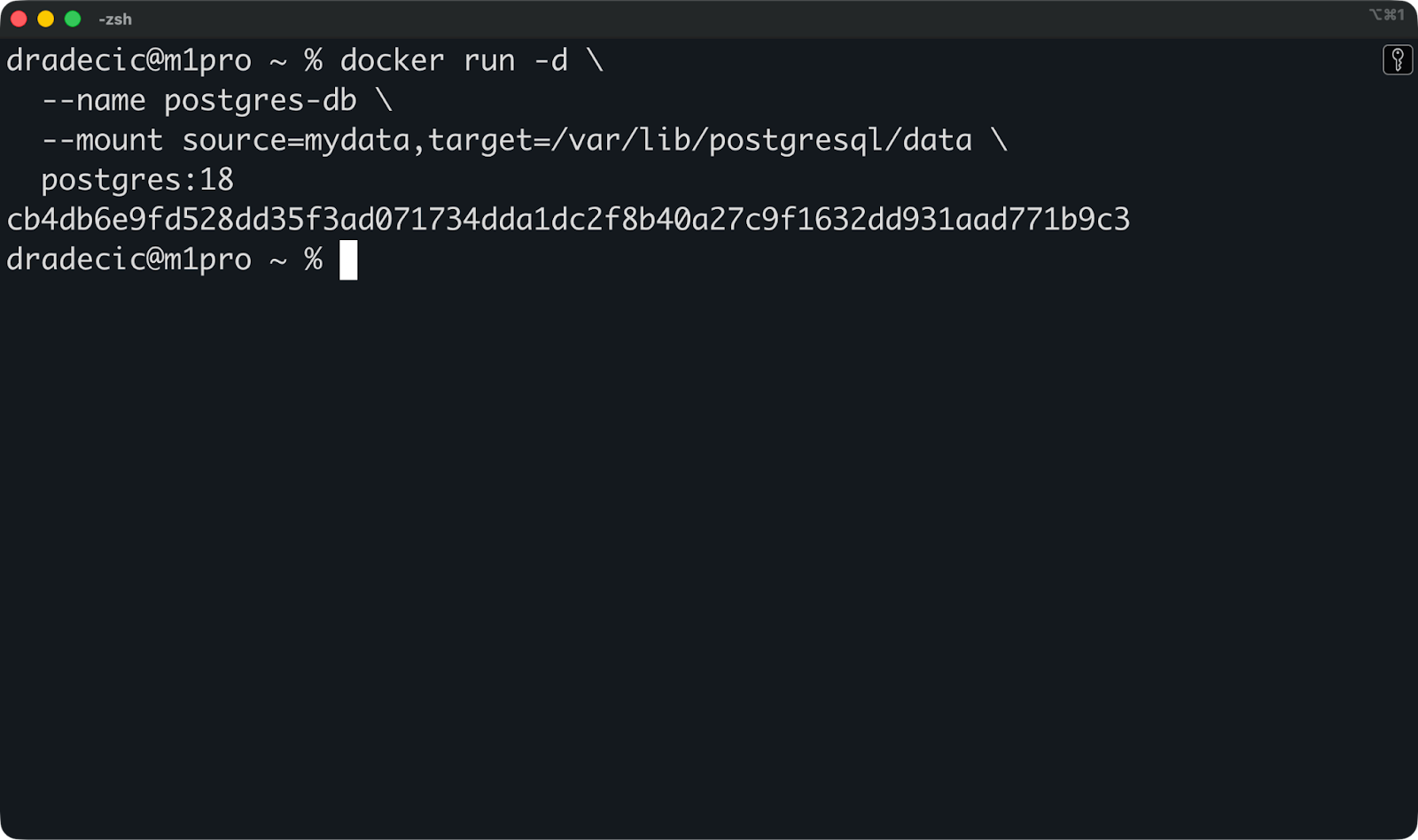
Esto monta el volumen mydata en /var/lib/postgresql/data dentro del contenedor, donde Postgres almacena sus archivos de base de datos.
Ahora puedes detener y eliminar este contenedor, y luego iniciar uno nuevo con el mismo volumen:
docker rm -f postgres-db
docker run -d \
--name postgres-db-new \
--mount source=mydata,target=/var/lib/postgresql/data \
postgres:18Tu base de datos ha vuelto con todas las tablas y filas intactas.
Ese es el objetivo de los volúmenes: la persistencia de los datos a lo largo del ciclo de vida de los contenedores.
Puedes ejecutar este comando para comprobar qué volúmenes existen en tu sistema:
docker volume ls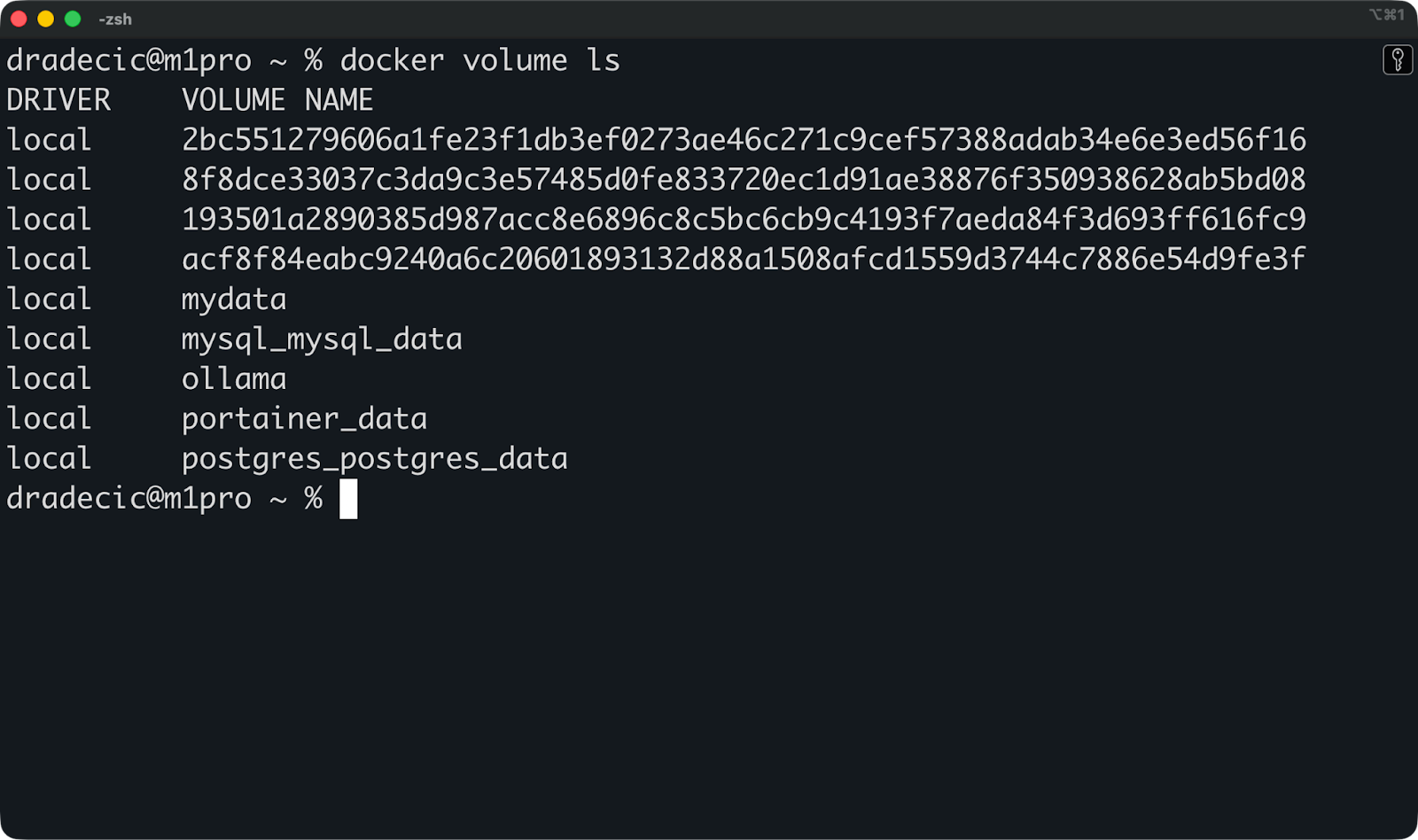
A continuación, puedes ejecutar este comando para inspeccionar un volumen específico y ver dónde está almacenado y qué contenedores lo utilizan:
docker volume inspect mydata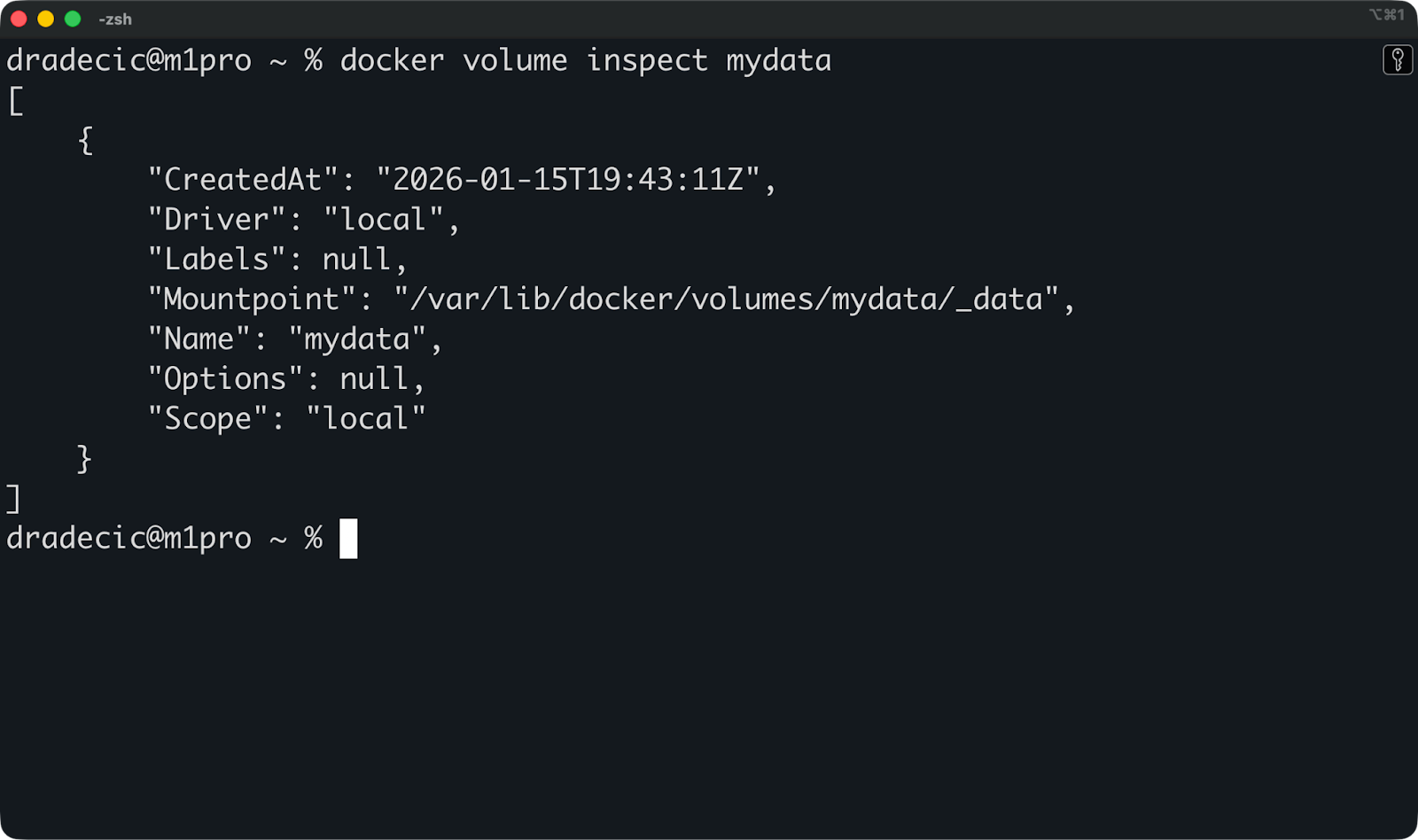
Esto muestra el punto de montaje en tu host y metadatos útiles. Pero rara vez necesitas acceder a este directorio directamente, esa es la función de Docker.
Si ya has terminado con el volumen y deseas eliminarlo, simplemente ejecuta este comando:
docker volume rm mydataDocker no te permite eliminar un volumen que esté asociado a un contenedor en ejecución. Primero detén el contenedor y luego elimina el volumen.
Por último, si deseas limpiar recursos y recuperar espacio en disco, puedes ejecutar este comando para eliminar todos los volúmenes no utilizados de una sola vez:
docker volume prune
Para configuraciones de producción, Docker admite controladores de volumen que se conectan a sistemas de almacenamiento externos como NFS, AWS EFS o almacenamiento en bloque en la nube. Tú especificas el controlador al crear el volumen y Docker se encarga del resto. Esto te permite almacenar datos completamente fuera de tu máquina host, lo cual es importante para configuraciones de alta disponibilidad en las que los contenedores se mueven entre servidores.
A continuación, hablemos de los montajes vinculados.
Los montajes vinculados te permiten acceder directamente al sistema de archivos del host desde dentro de un contenedor, y esa es precisamente la razón por la que a los programadores les encantan.
Son perfectos para el desarrollo local, pero tienen algunas desventajas que los hacen arriesgados para la producción. Obtienes sincronización de archivos en tiempo real y cero pasos de compilación, pero pierdes portabilidad y puedes abrir agujeros de seguridad.
Un montaje vinculante asigna un directorio específico de tu máquina host directamente a un contenedor.
Tú especificas la ruta exacta, como /home/user/myapp, y Docker la pone a disposición en una ruta dentro del contenedor. No hay copias, ni almacenamiento gestionado por Docker, ni capa de abstracción. El contenedor ve tus archivos de host reales.
Si cambias un archivo en tu host, el contenedor ve el cambio inmediatamente. Del mismo modo, si modificas un archivo dentro del contenedor, se actualizará en tu host. Ambas partes están trabajando con los mismos archivos en tiempo real.
Aquí tienes un montaje fijo en acción:
docker run -d \
--name dev-app \
--mount type=bind,source=/Users/dradecic/Desktop/app,target=/app \
python:3.14
Esto monta /Users/dradecic/Desktop/app desde tu host a /app dentro del contenedor. Cuando edito un archivo Python en /Users/dradecic/Desktop/app utilizando tu editor de texto, la aplicación contenedorizada ve el cambio al instante.
También puedes utilizar la sintaxis más corta:
El caso de uso más común es montar tu código fuente durante el desarrollo.
Supongamos que estás creando una aplicación FastAPI. Puedes montar el directorio de tu proyecto en el contenedor, habilitar la recarga en caliente y tendrás un entorno de desarrollo completo:
docker run -d \
--name fastapi-dev \
--mount type=bind,source=/Users/dradecic/Desktop/app,target=/app \
-w /app \
-p 8000:8000 \
python:3.14 \
sh -c "pip install fastapi uvicorn && uvicorn main:app --reload --host 0.0.0.0"
A modo de referencia, este es mi archivo main.py:
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI(
title="FastAPI Docker Demo",
description="A minimal FastAPI app running inside Docker",
version="1.0.0",
)
class Item(BaseModel):
name: str
price: float
in_stock: bool = True
@app.get("/")
def read_root():
return {
"message": "FastAPI is running",
"docs": "/docs",
"redoc": "/redoc",
}
@app.get("/health")
def health_check():
return {"status": "ok"}
@app.post("/items")
def create_item(item: Item):
return {
"message": "Item received",
"item": item,
}Después de ejecutar el comando Docker, la aplicación está disponible desde tu máquina host en el puerto 8000:
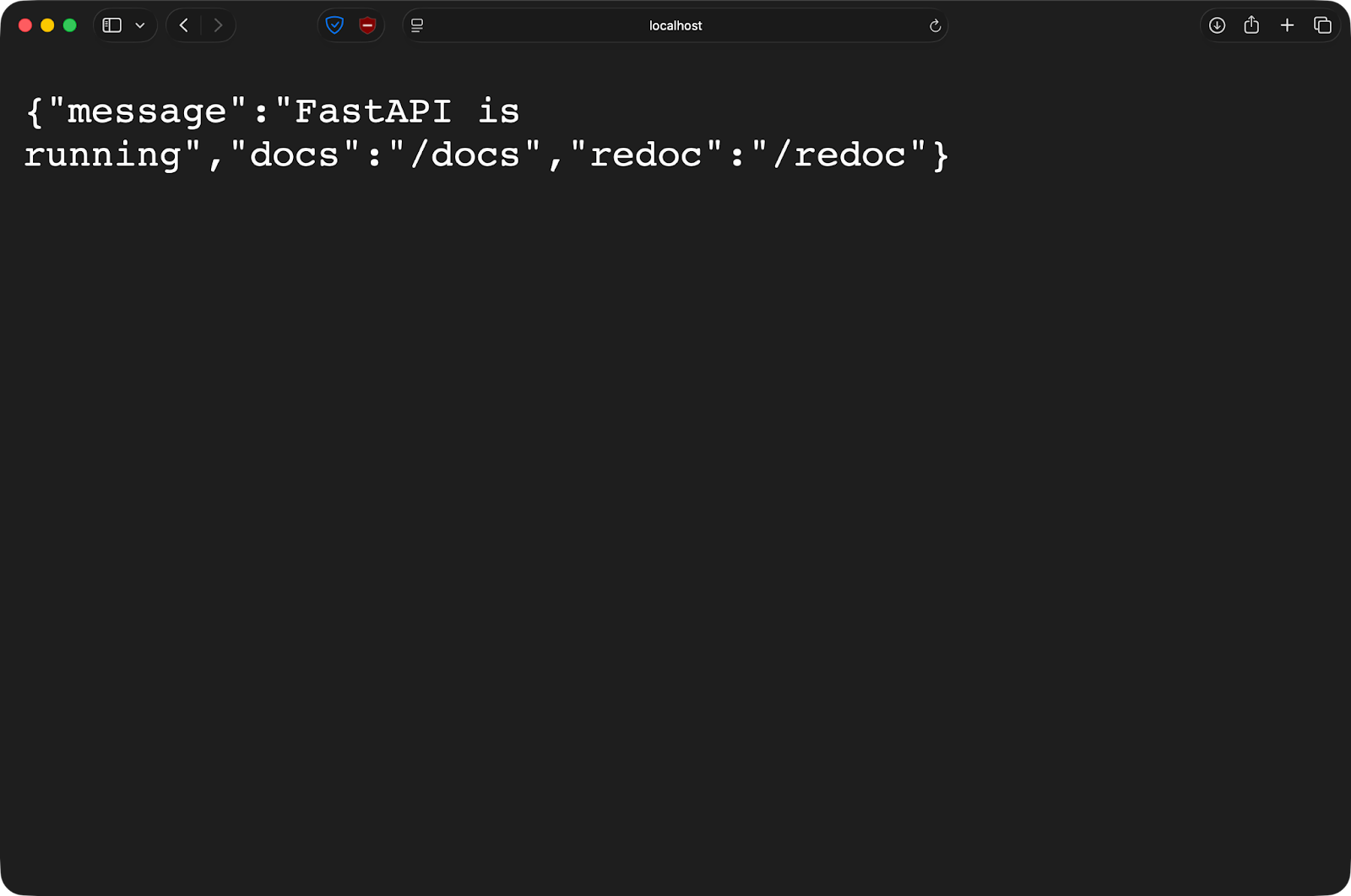
Si editas main.py en tu editor, guarda el archivo y FastAPI se recargará automáticamente. Sin necesidad de reconstruir imágenes ni reiniciar contenedores. Escribes código como lo harías localmente, pero tu aplicación se ejecuta en un entorno de contenedor coherente.
Los montajes vinculados exponen el sistema de archivos del host a los contenedores, lo que puede crear problemas de seguridad.
Un contenedor con un montaje vinculante puede leer y escribir archivos en tu host. Ejecuta un contenedor como root (que es la configuración predeterminada) y tendrás acceso root a esos archivos montados. El código malicioso o un contenedor comprometido pueden modificar o eliminar cualquier elemento del directorio montado.
La portabilidad es otro problema.
Los montajes vinculantes dependen de rutas específicas existentes en el host. El servicio « /Users/dradecic/Desktop/app » no existe en tu equipo ni en ningún servidor de producción. Esto rompe la promesa de que los contenedores «funcionan en todas partes».
Las diferencias entre plataformas también son importantes. Windows y Mac utilizan una máquina virtual para ejecutar Docker, por lo que los montajes vinculados pasan por una capa de traducción adicional. Esto ralentiza las operaciones con archivos y puede provocar errores sutiles con la supervisión de archivos y los enlaces simbólicos.
Los entornos de producción nunca deben utilizar montajes vinculantes.
Dependen demasiado de rutas específicas del host, son demasiado arriesgadas desde el punto de vista de la seguridad y es imposible controlar sus versiones. Los volúmenes resuelven todos estos problemas, por lo que son el estándar de producción.
Considera los bind mounts como una herramienta de desarrollo: rápidos, prácticos y potentes, pero no algo que quieras tener cerca de la producción.
Los montajes tmpfs almacenan datos en la RAM de tu host en lugar de en el disco. Esto los hace perfectos para datos que no deseas conservar.
Un montaje tmpfs existe íntegramente en la memoria.
Docker asigna RAM en tu máquina host y la pone a disposición como un sistema de archivos dentro del contenedor. Un archivo escrito en un montaje tmpfs nunca llega a tocar tu disco. Los datos permanecen en la memoria hasta que el contenedor se detiene.
Cuando detienes el contenedor, se elimina todo lo que hay en el montaje tmpfs. No es necesario realizar ninguna limpieza, no quedan archivos residuales ni rastro alguno de lo que había allí. Cada vez que reinicias el contenedor, obtienes un montaje tmpfs nuevo y vacío.
En pocas palabras, los montajes tmpfs son para datos que no deseas conservar explícitamente: cálculos temporales, tokens de sesión o información confidencial que no debe permanecer después de su uso.
El caso de uso más común es el almacenamiento de secretos o datos confidenciales.
Supongamos que estás ejecutando un contenedor que necesita una clave API o una contraseña de base de datos. Guárdalo en un montaje tmpfs y el secreto nunca se almacenará en el disco. Cuando el contenedor se detiene, el secreto desaparece de la memoria. No hay ningún archivo que se pueda enviar accidentalmente al control de versiones o dejar expuesto en el sistema de archivos.
Las cachés también son una buena opción. Los artefactos de compilación, el código compilado o las dependencias descargadas que vas a regenerar de todos modos no necesitan conservarse. Colócalos en tmpfs para acceder más rápidamente a ellos durante la vida útil del contenedor y, luego, haz que desaparezcan cuando hayas terminado.
Los archivos temporales también funcionan bien aquí: piensa en datos de sesión, archivos de bloqueo o resultados de procesamiento intermedios que solo son importantes mientras se ejecuta el contenedor.
Ejecuta este comando para crear un montaje tmpfs utilizando el indicador ` --tmpfs `:
docker run -d \
--name temp-app \
--tmpfs /tmp:rw,size=100m \
python:3.14Esto crea un montaje tmpfs de 100 MB en /tmp dentro del contenedor. La opción ` size ` limita la cantidad de RAM que puede utilizar el montaje.
También puedes utilizar la sintaxis --mount:
docker run -d \
--name temp-app \
--mount type=tmpfs,destination=/tmp,tmpfs-size=104857600 \
python:3.14El valor « tmpfs-size » se expresa en bytes: 104857600 bytes equivalen a 100 MB.
Si no especificas un límite de tamaño, tmpfs utiliza hasta la mitad de la RAM de tu sistema. Eso es peligroso, por razones obvias. Establece siempre límites de tamaño explícitos.
La única gran desventaja es que los montajes tmpfs solo funcionan en Linux.
Mac y Windows Docker Desktop no los admiten porque ejecutan Docker dentro de una máquina virtual Linux, y tmpfs requiere compatibilidad directa con el kernel.
Docker te ofrece dos formas de definir montajes, y elegir la sintaxis adecuada hace que tus comandos sean más fáciles de leer y depurar.
Ambos enfoques funcionan, pero uno se adapta mejor cuando necesitas opciones avanzadas o múltiples montajes en un solo contenedor.
La bandera ` --mount ` utiliza pares clave-valor explícitos, mientras que ` -v ` o ` --volume ` utilizan una cadena separada por dos puntos.
Aquí tienes el mismo montaje de volumen con ambas sintaxis:
# Using --mount
docker run -d \
--mount type=volume,source=mydata,target=/app/data \
python:3.14
# Using -v
docker run -d \
-v mydata:/app/data \
python:3.14Ambos crean un volumen llamado mydata y lo montan en /app/data en el contenedor.
Utiliza --mount para cualquier cosa que vaya más allá de las configuraciones básicas. Es más prolijo, pero las claves explícitas dejan claro qué hace cada parte. Cuando añades opciones como el acceso de solo lectura o controladores de volumen personalizados, sigue siendo legible, mientras que -v puede parecer una cadena críptica.
La sintaxis -v es adecuada para flujos de trabajo de desarrollo sencillos en los que escribes los comandos a mano.
La opción « readonly » impide que los contenedores modifiquen los datos montados:
docker run -d \
--mount type=volume,source=mydata,target=/app/data,readonly \
python:3.14Esto resulta útil para los archivos de configuración o los datos de referencia que los contenedores deben leer, pero nunca modificar. Un contenedor que intenta escribir en un montaje de solo lectura obtiene un error de permiso.
Para los volúmenes, la opción ` volume-nocopy ` omite la copia de los datos existentes de la imagen del contenedor al volumen:
docker run -d \
--mount type=volume,source=mydata,target=/app/data,volume-nocopy \
python:3.14De forma predeterminada, Docker copia todo lo que existe en el punto de montaje de la imagen a un nuevo volumen. Cuando estableces volume-nocopy, obtienes un volumen vacío independientemente de lo que haya en la imagen.
Para los montajes tmpfs, la opción ` tmpfs-size ` establece un límite de memoria:
docker run -d \
--mount type=tmpfs,target=/tmp,tmpfs-size=104857600 \
python:3.14Esto limita el montaje de tmpfs a 100 MB. Sin él, un montaje tmpfs puede consumir toda la RAM disponible.
Cuando montas un directorio que ya existe en la imagen del contenedor, el montaje oculta por completo todo lo que había allí.
Supongamos que tu imagen tiene un directorio /app/data con archivos de configuración integrados. Cuando montas un volumen en /app/data, esos archivos de configuración desaparecerán. El contenedor solo ve lo que hay en el volumen.
Esto ocurre con todos los tipos de montaje: volúmenes, montajes vinculados y tmpfs. El contenido montado tiene prioridad y no se puede acceder al directorio original mientras el montaje está activo.
Docker Compose facilita la definición y el intercambio de montajes entre varios contenedores en la pila de aplicaciones.
En lugar de escribir largos comandos docker run con indicadores de montaje, declaras todo en un archivo docker-compose.yml. Déjame mostrarte cómo.
Aquí tienes un archivo Compose con ejemplos de volumen y montaje vinculado:
services:
service-1:
image: ubuntu:latest
command: sleep infinity
volumes:
- ./code:/app # Bind mount for development
- shared:/data # Named volume shared with worker
service-2:
image: ubuntu:latest
command: sleep infinity
volumes:
- shared:/data # Same volume as service-1
volumes:
shared:La clave « volumes » (montaje) debajo de cada servicio define lo que se monta. Las rutas relativas como ./code crean montajes vinculados, mientras que nombres como shared hacen referencia a volúmenes con nombre.
La sección de nivel superior volumes declara los volúmenes con nombre que Compose crea y gestiona. Tanto service-1 como service-2 montan el mismo volumen shared, por lo que ven los mismos archivos. Escribe un archivo desde un contenedor y el otro contenedor podrá leerlo inmediatamente.
El comando « sleep infinity » mantiene los contenedores en ejecución para que puedas ejecutarlos, solo con fines de demostración.
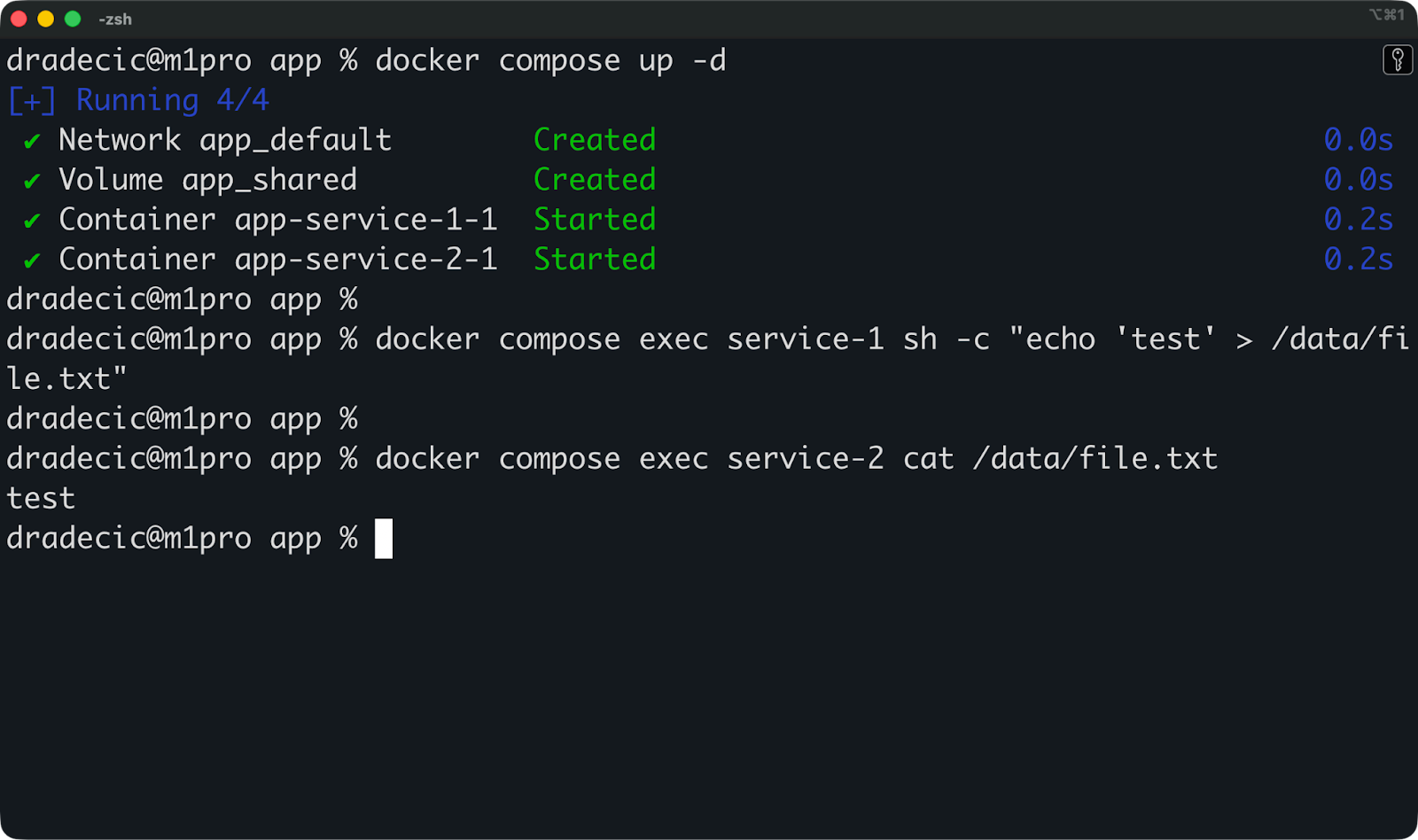
Inicia tu pila con docker compose up -d y, a continuación, comprueba si los montajes funcionan:
# Write data to the shared volume from app
docker compose exec service-1 sh -c "echo 'test' > /data/file.txt"
# Read it from worker
docker compose exec service-2 cat /data/file.txtSi ambos comandos funcionan, tus volúmenes están configurados correctamente.
Ahora puedes ejecutar este comando para detener y eliminar todo:
docker compose downTus volúmenes con nombre seguirán estando presentes. Si reinicias la pila con docker compose up -d, los datos que escribiste anteriormente seguirán ahí. Así es como las bases de datos persisten a través de las implementaciones : el volumen sobrevive al contenedor.
Para eliminar volúmenes al detener la pila, agrega el -v :
docker compose down -vEsto elimina todos los volúmenes definidos en tu archivo Compose. Úsalo cuando quieras empezar de cero.
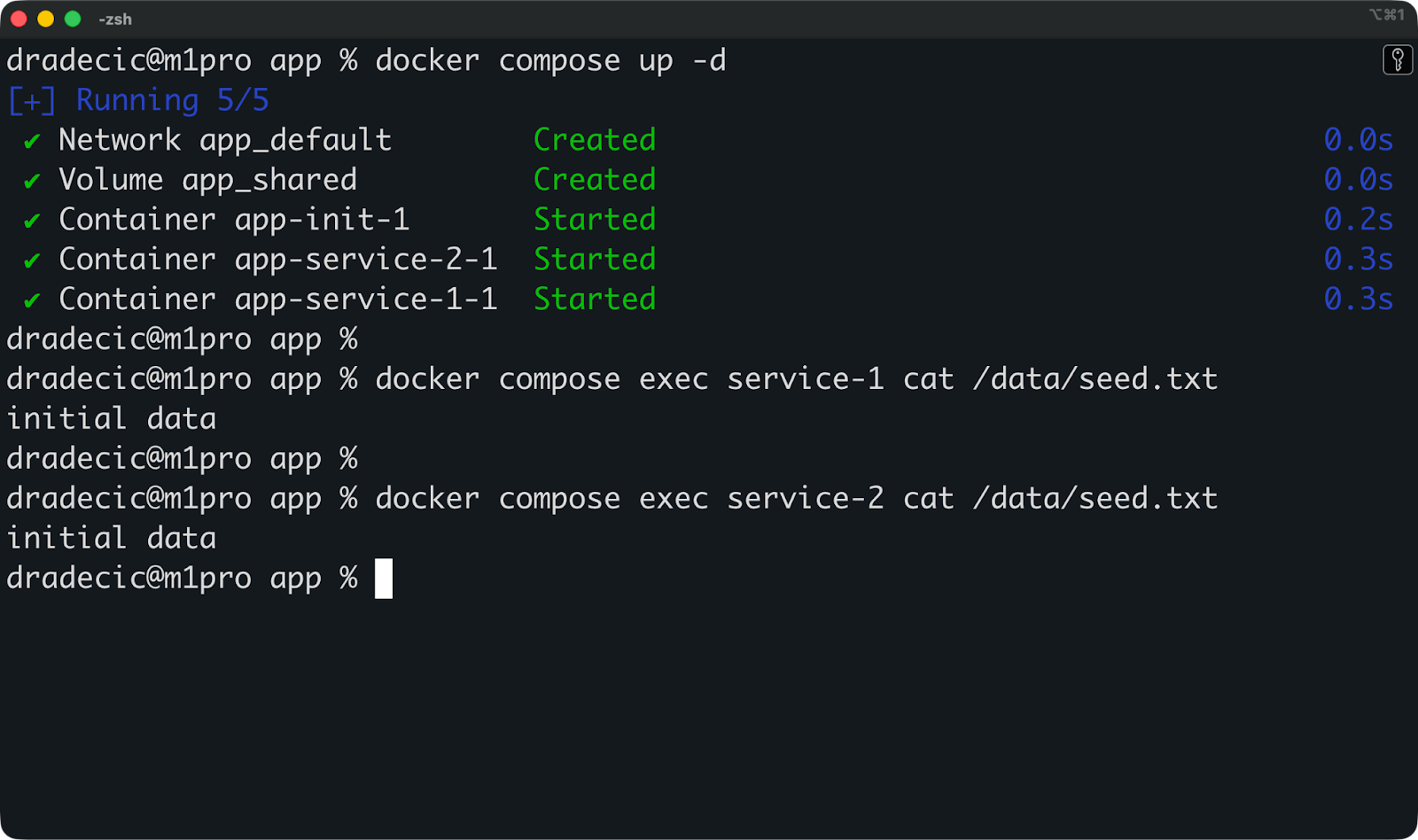
El patrón más común es utilizar un contenedor init independiente para inicializar el volumen compartido:
services:
init:
image: ubuntu:latest
command: sh -c "mkdir -p /source && echo 'initial data' > /source/seed.txt && cp /source/* /dest/"
volumes:
- shared:/dest
service-1:
image: ubuntu:latest
command: sleep infinity
depends_on:
- init
volumes:
- shared:/data
service-2:
image: ubuntu:latest
command: sleep infinity
depends_on:
- init
volumes:
- shared:/data
volumes:
shared:El contenedor ` init ` crea datos iniciales y los copia en el volumencompartido ` `, y luego se cierra. Tanto service-1 como service-2 se inician después y encuentran los datos inicializados listos para usar.
Compose gestiona la complejidad de coordinar múltiples contenedores y su almacenamiento compartido en un único archivo controlado por versiones.
Elegir el tipo de montaje incorrecto puede ralentizar tus contenedores o crear agujeros de seguridad que no sabías que existían. Lee esta sección si no quieres que eso suceda.
Los volúmenes ofrecen el mejor rendimiento en Linux porque se almacenan directamente en el sistema de archivos del host sin capa de traducción.
En Mac y Windows, Docker se ejecuta dentro de una máquina virtual Linux. Los volúmenes siguen funcionando bien porque permanecen dentro de esa máquina virtual. Por otro lado, los montajes vinculados tienen que sincronizar los archivos entre el sistema operativo host y la máquina virtual Linux, lo que añade una sobrecarga. Las operaciones con archivos en montajes vinculados pueden ser significativamente más lentas en Mac y Windows en comparación con Linux nativo.
tmpfs es la opción más rápida para operaciones de lectura y escritura, ya que todo se realiza en la RAM. Sin E/S de disco, sin sobrecarga del sistema de archivos. Pero estás limitado por la memoria disponible, y los datos desaparecen cuando el contenedor se detiene.
Si utilizas Linux y necesitas el máximo rendimiento, utiliza volúmenes. Si utilizas Mac o Windows y notas que las operaciones con archivos son lentas durante el desarrollo, es probable que estés sufriendo la sobrecarga del montaje vinculado. Cambia a volúmenes para cargas de trabajo de producción.
Cada montaje da acceso a los contenedores a algo fuera de su sistema de archivos aislado, y eso crea un riesgo.
Los soportes de fijación son la mayor preocupación. Si montas /home/user en un contenedor, un contenedor comprometido puede leer tus claves SSH, modificar la configuración de tu terminal o eliminar archivos de todo tu directorio de inicio. Ejecuta ese contenedor como root (el valor predeterminado) y tendrás acceso de nivel root a esos archivos.
Los volúmenes reducen este riesgo porque están aislados en el directorio de almacenamiento de Docker. Un contenedor no puede montar rutas de host arbitrarias a través de volúmenes. Sin embargo, los volúmenes pueden seguir filtrando datos entre contenedores si los compartes sin cuidado.
Los montajes tmpfs minimizan el riesgo de persistencia: los secretos almacenados en la memoria desaparecen cuando los contenedores se detienen. Pero no protegen contra ataques en tiempo de ejecución en los que un contenedor comprometido lee secretos de la memoria.
La regla general es que los montajes rompen el aislamiento de los contenedores, así que úsalos con cuidado.
Monta solo lo que necesiten los contenedores y nada más.
En lugar de montar todo el directorio del proyecto, monta solo el subdirectorio que utiliza el contenedor. En lugar de montar /var/log con acceso de escritura, móntalo como de solo lectura si el contenedor solo necesita leer registros.
Utiliza la opción « readonly » siempre que sea posible:
docker run -d \
--mount type=bind,source=/app/config,target=/config,readonly \
ubuntu:latestEsto evita que los contenedores modifiquen los datos montados, lo que limita los daños si se ven comprometidos.
Ejecuta los contenedores como usuarios no root para reducir el impacto de las vulnerabilidades de montaje vinculado. Crea un usuario en tu Dockerfile y cambia a él antes de que se inicie el contenedor:
RUN useradd -m appuser
USER appuserLimpia regularmente los volúmenes que no utilices con docker volume prune. Los volúmenes antiguos se acumulan con el tiempo, consumen espacio en disco y pueden contener datos confidenciales de contenedores eliminados.
Nunca montes directorios sensibles del host como /, /etc o /var a menos que tengas una razón específica y comprendas los riesgos. Cada montaje debe tener un propósito claro y un alcance mínimo.
Los problemas de montaje suelen manifestarse como errores de permiso, archivos que faltan o contenedores que no se inician, y casi siempre están causados por el mismo conjunto de problemas.
A continuación te explicamos cómo diagnosticar y solucionar los problemas más comunes con los que te encontrarás.
Los errores de permiso se producen cuando el usuario dentro del contenedor no tiene acceso a los archivos montados.
Los contenedores Docker se ejecutan como root de forma predeterminada. Cuando root crea un archivo en un montaje vinculado, ese archivo es propiedad de root en tu host. Si intentas editarlo con tu cuenta de usuario habitual, aparecerá un error de permiso denegado.
Lo contrario también ocurre. Monta un directorio de tu propiedad en un contenedor que se ejecute como usuario no root, y es posible que el contenedor no pueda escribir en él.
Puedes comprobar la propiedad de los archivos con « ls -la » en el directorio montado:
ls -la /path/to/mounted/directorySi los archivos son propiedad de root, pero tu contenedor se ejecuta como un usuario diferente, se produce una discrepancia. Soluciona el problema ejecutando el contenedor como el mismo usuario propietario de los archivos:
docker run -d \
--user $(id -u):$(id -g) \
-v ./data:/app/data \
ubuntu:latestEsto ejecuta el contenedor como tu usuario actual en lugar de como root, coincidiendo con la propiedad de los archivos en el montaje vinculado.
En cuanto a los volúmenes, Docker gestiona automáticamente los permisos cuando los contenedores crean archivos. Pero si ves errores, comprueba con qué usuario se ejecuta la aplicación en contenedor y si tiene acceso de escritura al punto de montaje.
El error más común es montar una ruta que no existe en el host.
Intenta montar /home/user/project cuando ese directorio no exista y Docker creará un directorio vacío propiedad de root. Tu contenedor se inicia, pero está montando algo incorrecto: un directorio vacío en lugar de tu proyecto real.
Siempre verifica que las rutas existan antes de montarlas:
ls /home/user/projectSi el directorio no existe, créalo primero o corrige la ruta en tu comando de montaje.
En Docker Compose, las rutas relativas se resuelven desde el directorio que contiene tu archivo docker-compose.yml. Si tu archivo está en /home/user/app/ y utilizas ./data, Docker buscará /home/user/app/data.
Si mueves el archivo Compose, el montaje se rompe.
Otro error común es montar en la ruta de destino incorrecta dentro del contenedor. Monta /app/data cuando tu aplicación espere /data, ya que de lo contrario la aplicación no podrá encontrar sus archivos. Consulta la documentación de tu aplicación o el archivo Dockerfile para confirmar dónde se espera que estén los datos.
En Linux, los montajes vinculados funcionan directamente con el sistema de archivos del host.
En Mac y Windows, Docker se ejecuta dentro de una máquina virtual Linux. Los montajes vinculados sincronizan los archivos entre tu sistema operativo host y esa máquina virtual, lo que crea problemas de sincronización. Los observadores de archivos, herramientas que recargan tu aplicación cuando cambian los archivos, a veces no detectan las actualizaciones debido a retrasos en la sincronización.
Mac y Windows también gestionan los permisos de los archivos de forma diferente. La máquina virtual traduce los permisos entre el sistema operativo host y Linux, lo que puede provocar que los archivos aparezcan con una propiedad incorrecta dentro de los contenedores.
Los enlaces simbólicos no funcionan de forma fiable en los montajes vinculados en Mac y Windows. La máquina virtual no siempre puede resolver los enlaces simbólicos que apuntan fuera del directorio montado, por lo que los archivos parecen estar perdidos o dañados dentro de los contenedores.
Los montajes tmpfs no funcionan en absoluto en Mac y Windows porque la máquina virtual no expone tmpfs al host. Si intentas utilizar un montaje tmpfs, Docker lo ignorará silenciosamente o generará un error, dependiendo de la versión.
Si estás desarrollando en Mac o Windows y te encuentras con problemas extraños de sincronización de archivos, cambia a volúmenes con nombre para obtener un mejor rendimiento y fiabilidad. Guarda los montajes vinculados para los flujos de trabajo de desarrollo en los que la sincronización en tiempo real es más importante que la consistencia perfecta.
Para terminar, utiliza volúmenes para los datos de producción que deben conservarse, como bases de datos, archivos cargados, estado de las aplicaciones... cualquier cosa que no puedas permitirte perder. Están gestionados por Docker, son portátiles entre plataformas y constituyen la opción más segura para los datos importantes.
Los montajes vinculados pertenecen a los flujos de trabajo de desarrollo en los que necesitas sincronización de archivos en tiempo real entre tu host y los contenedores. Cuando edites código en tu editor, verás los cambios al instante en tu aplicación contenedorizada. Pero manténlos fuera de la producción, ya que dependen demasiado de rutas específicas del host y crean riesgos de seguridad que no necesitas.
Cuando estés listo para profundizar en la contenedorización y la virtualización, consulta nuestro curso: Contenedorización y virtualización con Docker y Kubernetes.
Aprende Docker con DataCamp
programa
Curso
Curso
blog
Tim Lu
11 min
blog
Abid Ali Awan
15 min
Tutorial
Bex Tuychiev
Tutorial
Nic Raboy
Tutorial
Abid Ali Awan
Tutorial
Adam Shafi


