
Lernpfad
Containerisierung und Virtualisierung mit Docker und Kubernetes
13 Std.
Du hast also den Docker-Container angehalten, um eine Konfigurationsdatei zu aktualisieren, aber als du ihn neu gestartet hast, waren alle Daten weg. Ich war schon mal da.
Das passiert, weil Container standardmäßig kurzlebig sind – wenn sie entfernt werden, verschwinden alle Daten, die in ihrer beschreibbaren Schicht gespeichert sind. Echte Anwendungen können so nicht funktionieren. Du brauchst Datenbanken, die dauerhaft sind, Konfigurationsdateien, die auch nach einem Neustart noch da sind, und Protokolle, auf die du wirklich zugreifen kannst.
Docker Mount löst dieses Problem, indem es den Containerspeicher mit externen Speicherorten verbindet. Es gibt drei Arten: Volumes für Produktionsdaten, Bind-Mounts für Entwicklungs-Workflows und tmpfs für temporäre Dateien, die im Speicher abgelegt werden.
In diesem Artikel zeige ich dir, wie du den richtigen Befestigungstyp für deinen Anwendungsfall auswählst und richtig einsetzt. Um alles in diesem Artikel zu verstehen, solltest du Docker und Containerisierung gut kennen. Mach unseren Docker- Kurs für Fortgeschrittene „ “, um dich schnell auf den neuesten Stand zu bringen.
Docker-Container nutzen ein mehrschichtiges Dateisystem, das standardmäßig alles als temporär behandelt.
Wenn du ein Docker-Image erstellst, macht jede Anweisung in deiner Dockerfile eine neue, schreibgeschützte Ebene. Diese Schichten stapeln sich wie ein Kartenspiel übereinander. Wenn du ein Ubuntu-Image mit Python runterlädst, kriegst du eine Ebene für das Basis-Betriebssystem und eine weitere für Python.
Der Haken ist, dass all diese Ebenen schreibgeschützt sind. Du kannst sie nicht ändern.
Wenn du einen Container startest, fügt Docker noch eine weitere Ebene hinzu – die beschreibbare Container-Schicht.
Hier passieren alle Veränderungen. Jede Datei, die du erstellst, jede Konfiguration, die du änderst, und jeder Eintrag einer Tabelle, den du hinzufügst, wird hier gespeichert.
Das klingt super, aber das Problem ist, dass diese Schicht mit dem Lebenszyklus des Containers verbunden ist.
Wenn du den Container mit „ docker rm “ stoppt und entfernst, ist die beschreibbare Schicht weg. Alles, woran du gearbeitet hast, ist weg. Docker fragt nicht nach einer Bestätigung. Es löscht einfach alles.
Dieses Design ist sinnvoll für zustandslose Apps, die zwischen den Ausführungen nichts speichern müssen. Aber echte Anwendungen sind nicht zustandslos.
Die beschreibbare Schicht hat zwei große Probleme für Produktionsumgebungen.
Erstens verliert man Daten, wenn Container stehen bleiben. Was bringt ein Datenbankcontainer, der nach einem Neustart alle Zeilen vergisst? Mir fällt nichts anderes ein, als Integrationstests für deine App durchzuführen.
Zweitens kannst du keine Daten zwischen Containern austauschen. Angenommen, du betreibst eine Web-App und einen Hintergrund-Worker, die beide Zugriff auf dieselben Dateien brauchen. Wenn diese Dateien in der beschreibbaren Ebene eines Containers liegen, kann der andere Container sie nicht sehen.
Docker-Mounts lösen beide Probleme, indem sie Container mit Speicher verbinden, der außerhalb des Container-Lebenszyklus existiert. Du kannst ein Verzeichnis von deinem Host-Rechner oder einem von Docker verwalteten Volume einbinden. Deine Daten bleiben auch dann erhalten, wenn Container entfernt werden. Mehrere Container können denselben Speicherort mounten und Dateien in Echtzeit teilen.
Deshalb musst du Halterungen benutzen. Lass uns als Nächstes die verschiedenen Arten von Halterungen anschauen, und dann zeig ich dir, wie sie funktionieren.
Docker bietet dir drei Möglichkeiten, persistente Daten zu verwalten, und jede davon löst unterschiedliche Probleme. Hier erfährst du, was die einzelnen Typen machen und wann du sie verwenden solltest.
Volumes sind Dockers Standardlösung für persistenten Speicher.
Docker erstellt und verwaltet Volumes für dich in einem speziellen Verzeichnis auf deinem Host-Rechner. Du musst nicht wissen, wo sich dieses Verzeichnis befindet, das wird alles für dich erledigt. Dadurch sind Volumes auf verschiedenen Systemen übertragbar und können sicher in der Produktion eingesetzt werden.
Wenn du einen Container entfernst, bleibt das Volumen gleich. Wenn du einen neuen Container startest und dasselbe Volume hinzufügst, sind alle deine Daten genau da, wo du sie gelassen hast.
Volumes eignen sich am besten für Produktionsdatenbanken, den Anwendungsstatus und alle Daten, die du nicht verlieren darfst.
Bind-Mounts verbinden ein bestimmtes Verzeichnis auf deinem Host-Rechner direkt mit einem Container.
Du suchst dir den genauen Pfad auf deinem Host aus – zum Beispiel /home/user/project – und Docker ordnet ihn dem Container zu. Wenn du eine Datei auf deinem Host änderst, sieht der Container die Änderung sofort. Ändere eine Datei im Container, und sie wird auf deinem Host angezeigt.
Diese Echtzeit-Synchronisierung macht Bind-Mounts super für die Entwicklung.
Aber Bind-Mounts haben auch ihre Risiken. Sie legen Host-Pfade für Container offen und sind von bestimmten Verzeichnisstrukturen abhängig, die auf anderen Rechnern vielleicht nicht vorhanden sind.
tmpfs speichert Daten im Speicher deines Hosts statt auf der Festplatte.
Es wird nichts ins Dateisystem geschrieben. Wenn der Container anhält, verschwinden die Daten komplett. Das macht tmpfs-Mounts super praktisch fürtemporäre Daten, die du nicht behalten willst – denk mal an Authentifizierungstoken, Sitzungsdaten oder Cache-Dateien, die du sowieso neu erstellen wirst.
Allerdings sind tmpfs-Mounts durch den verfügbaren Arbeitsspeicher eingeschränkt und funktionieren nur auf Linux-Hosts.
Volumes sind die produktionsreife Speicherlösung von Docker, und du solltest sie standardmäßig verwenden, es sei denn, du hast einen bestimmten Grund, das nicht zu tun.
Sie werden komplett von Docker verwaltet, funktionieren auf verschiedenen Plattformen gleich und überstehen das Entfernen von Containern ohne Probleme. Wenn du Datenbanken betreibst, den Status von Anwendungen speicherst oder Daten verarbeitest, die länger als ein einzelner Container bestehen bleiben müssen, sind Volumes die richtige Lösung.
Docker speichert Volumes in einem speziellen Verzeichnis auf deinem Host-Rechner:
/var/lib/docker/volumes/~/Library/Containers/com.docker.docker/Data/vms/0/data/\\wsl$\docker-desktop-data\data\docker\volumes\, mit WSL2 als BackendDu verwaltest dieses Verzeichnis nicht direkt. Docker kümmert sich über seine eigene API um die Erstellung, Berechtigungen und Bereinigung. Durch diese Trennung funktionieren Volumes auf Linux, Mac und Windows gleich, was wiederum deine Container-Einrichtung über Entwicklungs- und Produktionsumgebungen hinweg portabel macht.
Man muss sich merken, dass Volumes unabhängig von Containern existieren. Wenn du ein Volume erstellst, es an einen Container hängst, deine App startest und dann den Container stoppst und löschst, bleibt das Volume genau da, wo es ist, und alle deine Daten bleiben intakt.
Wenn du einen neuen Container startest und dasselbe Volume hinzufügst, sind deine Daten immer noch da.
Du kannst einen benannten Volume erstellen, bevor du einen Container startest:
docker volume create mydata
Dann häng es an, wenn du einen Container mit dem Flag „ --mount “ startest:
docker run -d \
--name postgres-db \
--mount source=mydata,target=/var/lib/postgresql/data \
postgres:18
Damit wird das Volume „ mydata “ unter „ /var/lib/postgresql/data “ im Container gemountet, wo Postgres seine Datenbankdateien speichert.
Du kannst jetzt diesen Container stoppen und entfernen und dann einen neuen mit dem gleichen Volumen starten:
docker rm -f postgres-db
docker run -d \
--name postgres-db-new \
--mount source=mydata,target=/var/lib/postgresql/data \
postgres:18Deine Datenbank ist wieder da, mit allen Tabellen und Zeilen intakt.
Das ist der Sinn von Volumes – Daten bleiben über den ganzen Lebenszyklus von Containern hinweg erhalten.
Du kannst diesen Befehl ausführen, um zu checken, welche Volumes auf deinem System vorhanden sind:
docker volume ls
Dann kannst du diesen Befehl ausführen, um ein bestimmtes Volume zu checken und zu sehen, wo es gespeichert ist und welche Container es nutzen:
docker volume inspect mydata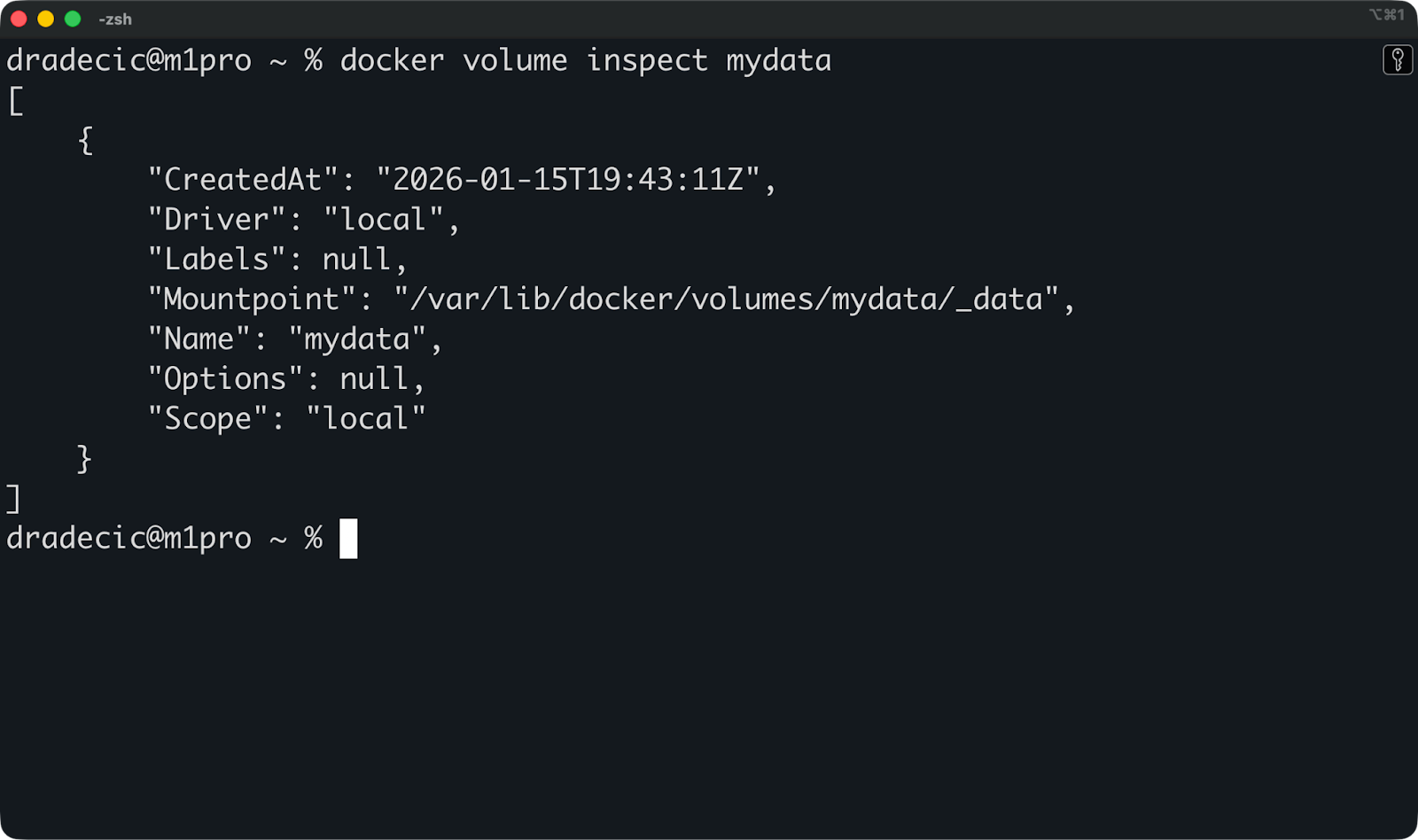
Hier siehst du den Mount-Punkt auf deinem Host und nützliche Metadaten. Aber du musst selten direkt auf dieses Verzeichnis zugreifen – das ist die Aufgabe von Docker.
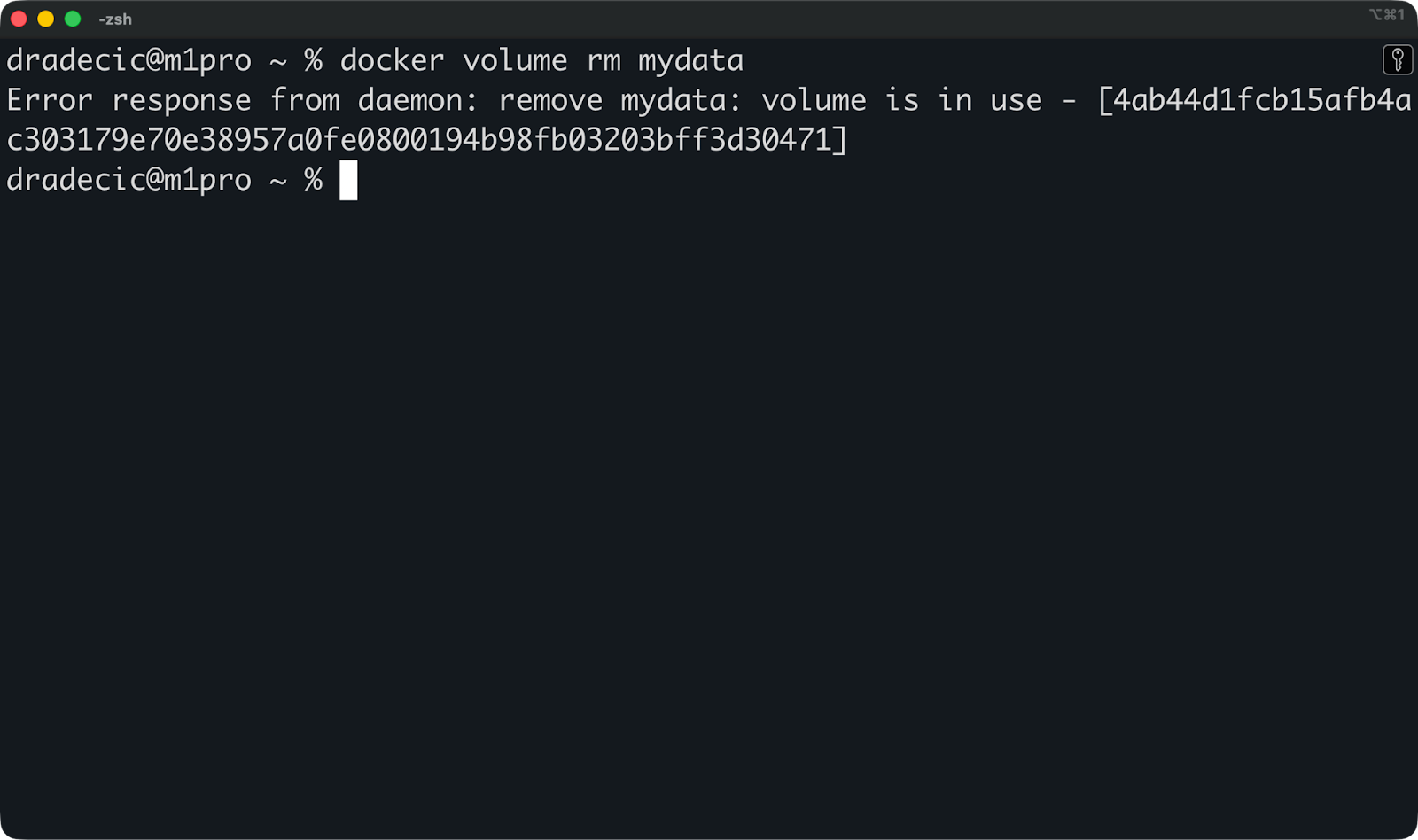
Wenn du mit dem Volume fertig bist und es entfernen willst, gib einfach diesen Befehl ein:
docker volume rm mydataMit Docker kannst du kein Volume löschen, das an einen laufenden Container angehängt ist. Halt zuerst den Container an und nimm dann das Volume raus.
Wenn du Ressourcen bereinigen und Speicherplatz zurückgewinnen willst, kannst du diesen Befehl ausführen, um alle ungenutzten Volumes auf einmal zu entfernen:
docker volume prune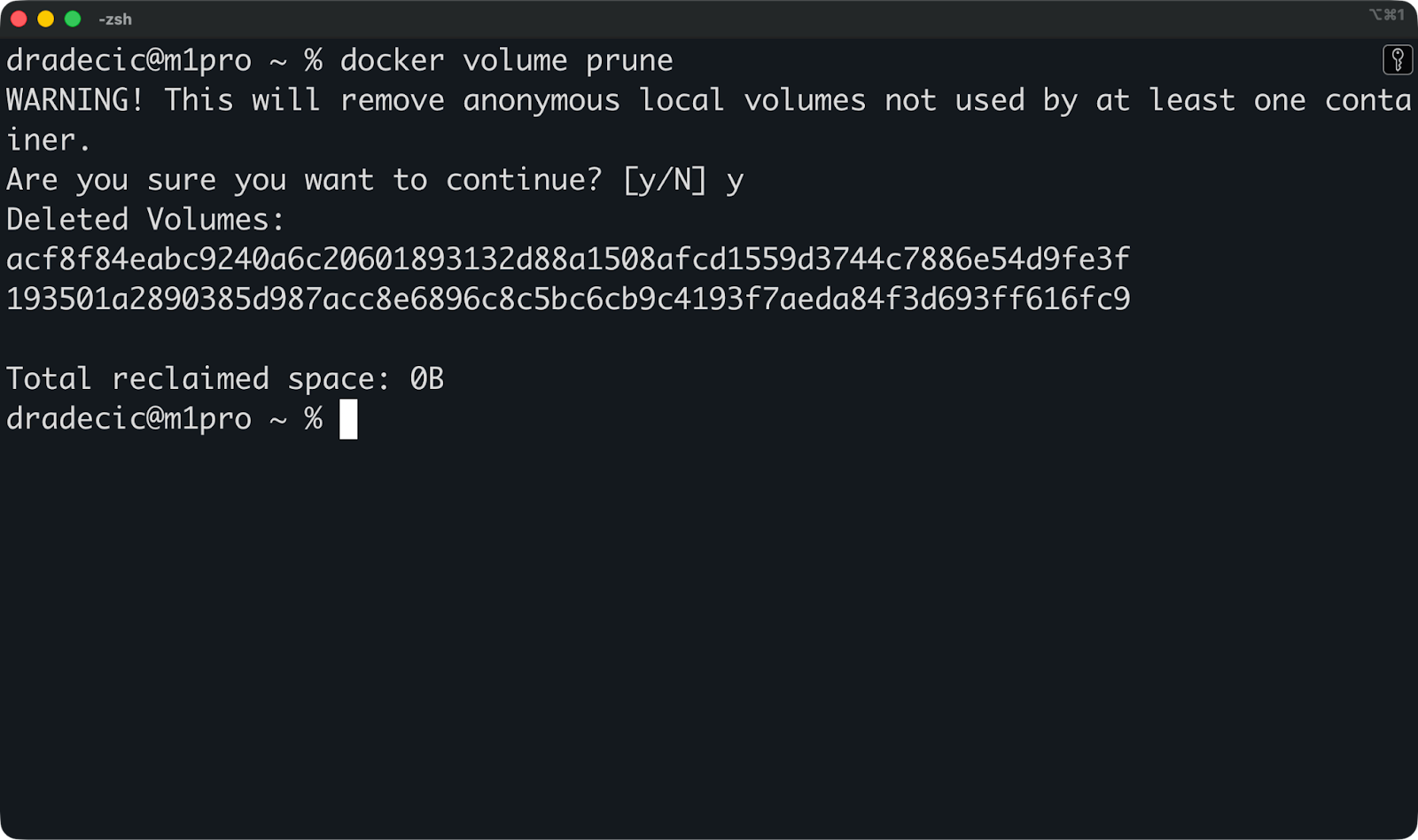
Für Produktionsumgebungen unterstützt Docker Volume-Treiber, die sich mit externen Speichersystemen wie NFS, AWS EFS oder Cloud-Blockspeichern verbinden. Du gibst den Treiber beim Erstellen des Volumes an, und Docker kümmert sich um den Rest. Damit kannst du Daten komplett außerhalb deines Host-Rechners speichern, was bei Hochverfügbarkeits-Setups wichtig ist, wo Container zwischen Servern hin und her wandern.
Als Nächstes reden wir über Bind-Mounts.
Mit Bind-Mounts kannst du direkt von einem Container aus auf dein Host-Dateisystem zugreifen, und genau deshalb sind sie bei Entwicklern so beliebt.
Sie sind super für die lokale Entwicklung, aber es gibt ein paar Nachteile, die sie für die Produktion riskant machen. Du bekommst Echtzeit-Dateisynchronisierung und musst keine Build-Schritte machen, aber du verlierst Portabilität und kannst Sicherheitslücken schaffen.
Ein Bind-Mount ordnet ein bestimmtes Verzeichnis auf deinem Host-Rechner direkt einem Container zu.
Du gibst den genauen Pfad an – zum Beispiel /home/user/myapp – und Docker macht ihn über einen Pfad im Container verfügbar. Es gibt kein Kopieren, keinen von Docker verwalteten Speicher und keine Abstraktionsschicht. Der Container sieht deine echten Host-Dateien.
Wenn du eine Datei auf deinem Host änderst, sieht der Container die Änderung sofort. Wenn du eine Datei im Container änderst, wird sie auch auf deinem Host aktualisiert. Beide Seiten arbeiten in Echtzeit mit denselben Dateien.
Hier siehst du ein Bind Mount in Aktion:
docker run -d \
--name dev-app \
--mount type=bind,source=/Users/dradecic/Desktop/app,target=/app \
python:3.14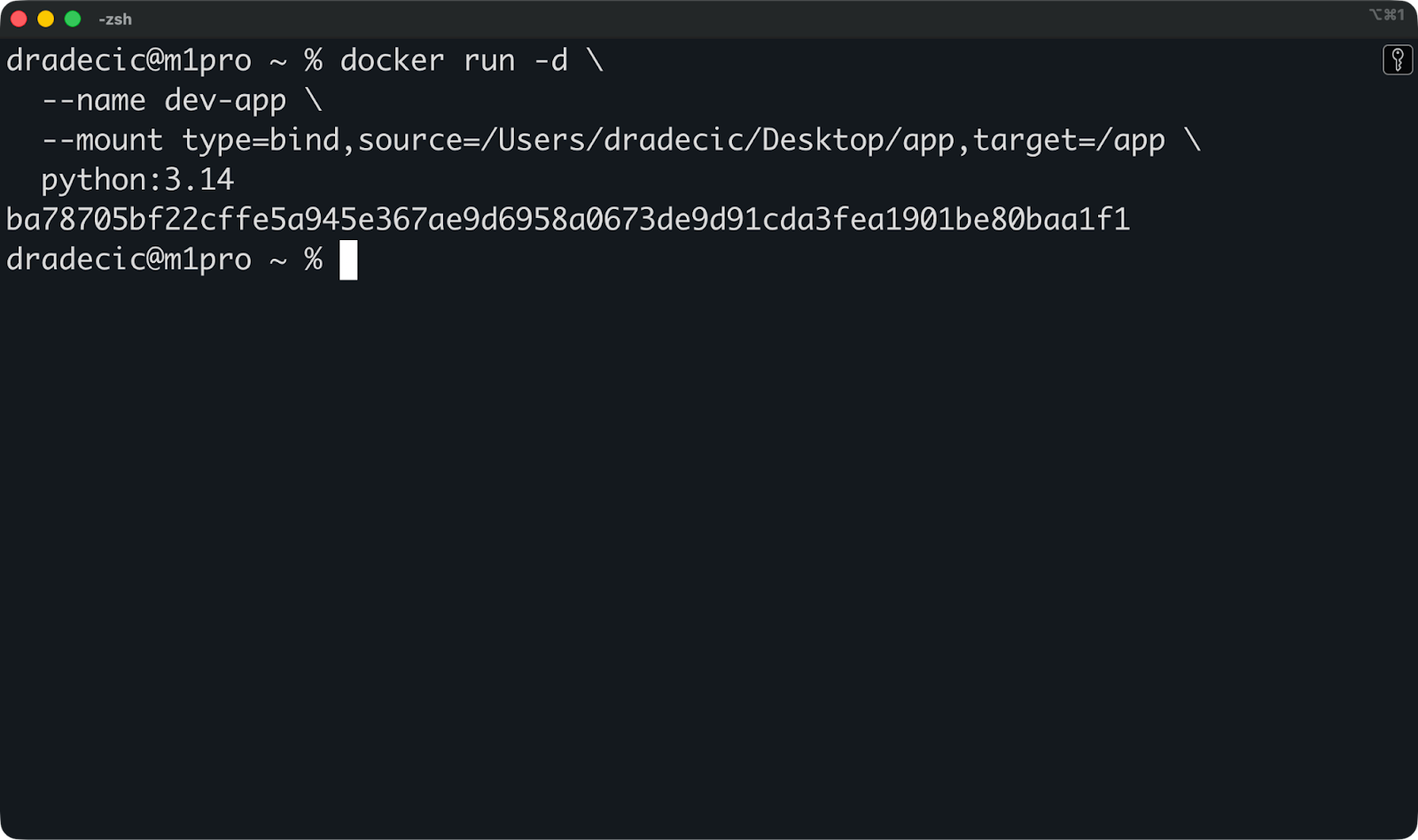
Damit wird „ /Users/dradecic/Desktop/app “ von meinem Host auf „ /app “ im Container gemountet. Wenn ich eine Python-Datei in „ /Users/dradecic/Desktop/app ” mit deinem Texteditor bearbeite, sieht die containerisierte App die Änderung sofort.
Du kannst auch die kürzere Syntax verwenden:
Der häufigste Anwendungsfall ist das Einbinden deines Quellcodes während der Entwicklung.
Angenommen, du entwickelst eine FastAPI-Anwendung. Du kannst dein Projektverzeichnis im Container einbinden, Hot Reload aktivieren und schon hast du eine komplette Entwicklungsumgebung:
docker run -d \
--name fastapi-dev \
--mount type=bind,source=/Users/dradecic/Desktop/app,target=/app \
-w /app \
-p 8000:8000 \
python:3.14 \
sh -c "pip install fastapi uvicorn && uvicorn main:app --reload --host 0.0.0.0"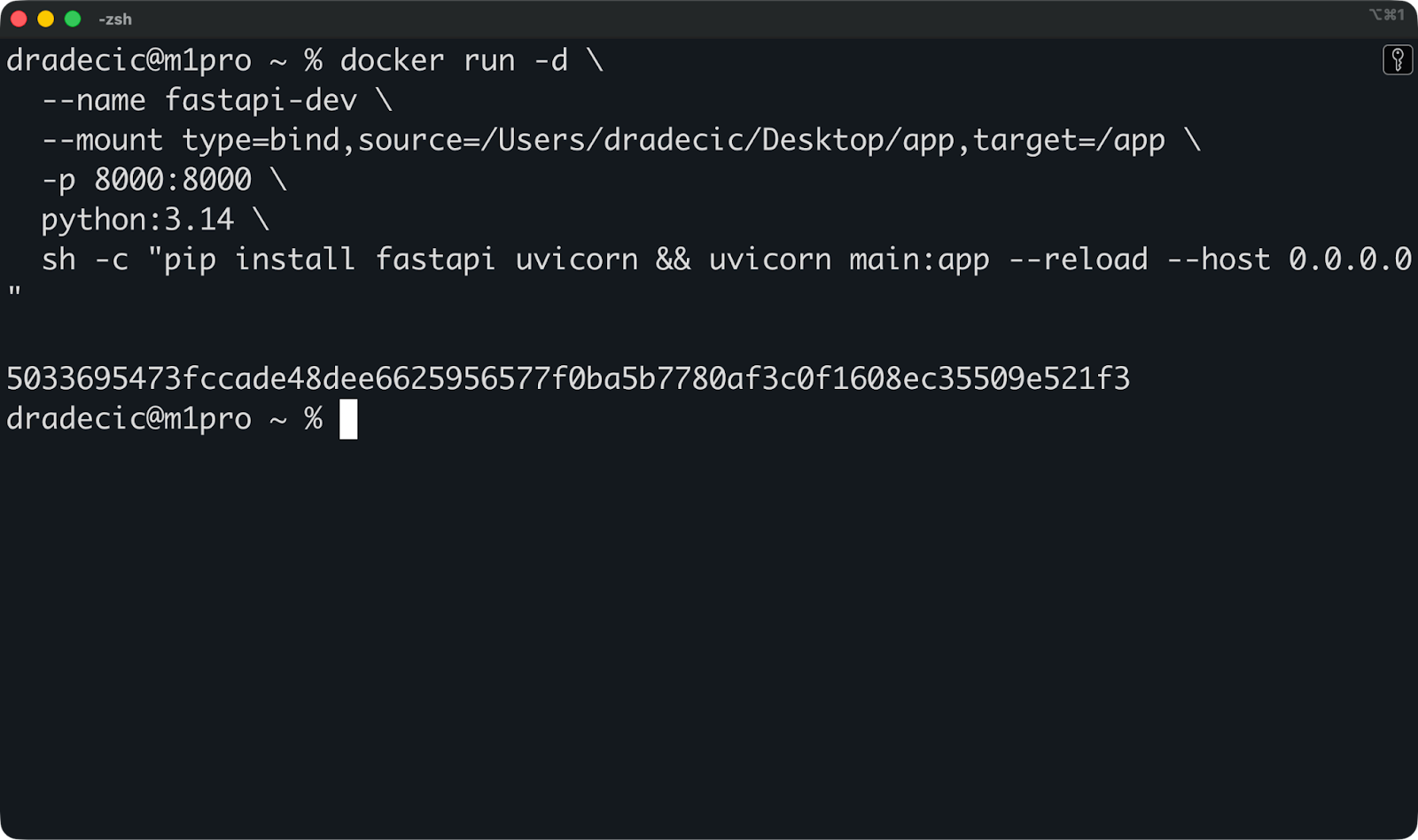
Nur zur Info, das ist meine Datei „ main.py “:
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI(
title="FastAPI Docker Demo",
description="A minimal FastAPI app running inside Docker",
version="1.0.0",
)
class Item(BaseModel):
name: str
price: float
in_stock: bool = True
@app.get("/")
def read_root():
return {
"message": "FastAPI is running",
"docs": "/docs",
"redoc": "/redoc",
}
@app.get("/health")
def health_check():
return {"status": "ok"}
@app.post("/items")
def create_item(item: Item):
return {
"message": "Item received",
"item": item,
}Nachdem ich den Docker-Befehl ausgeführt habe, ist die App auf meinem Host-Rechner über Port 8000 erreichbar:
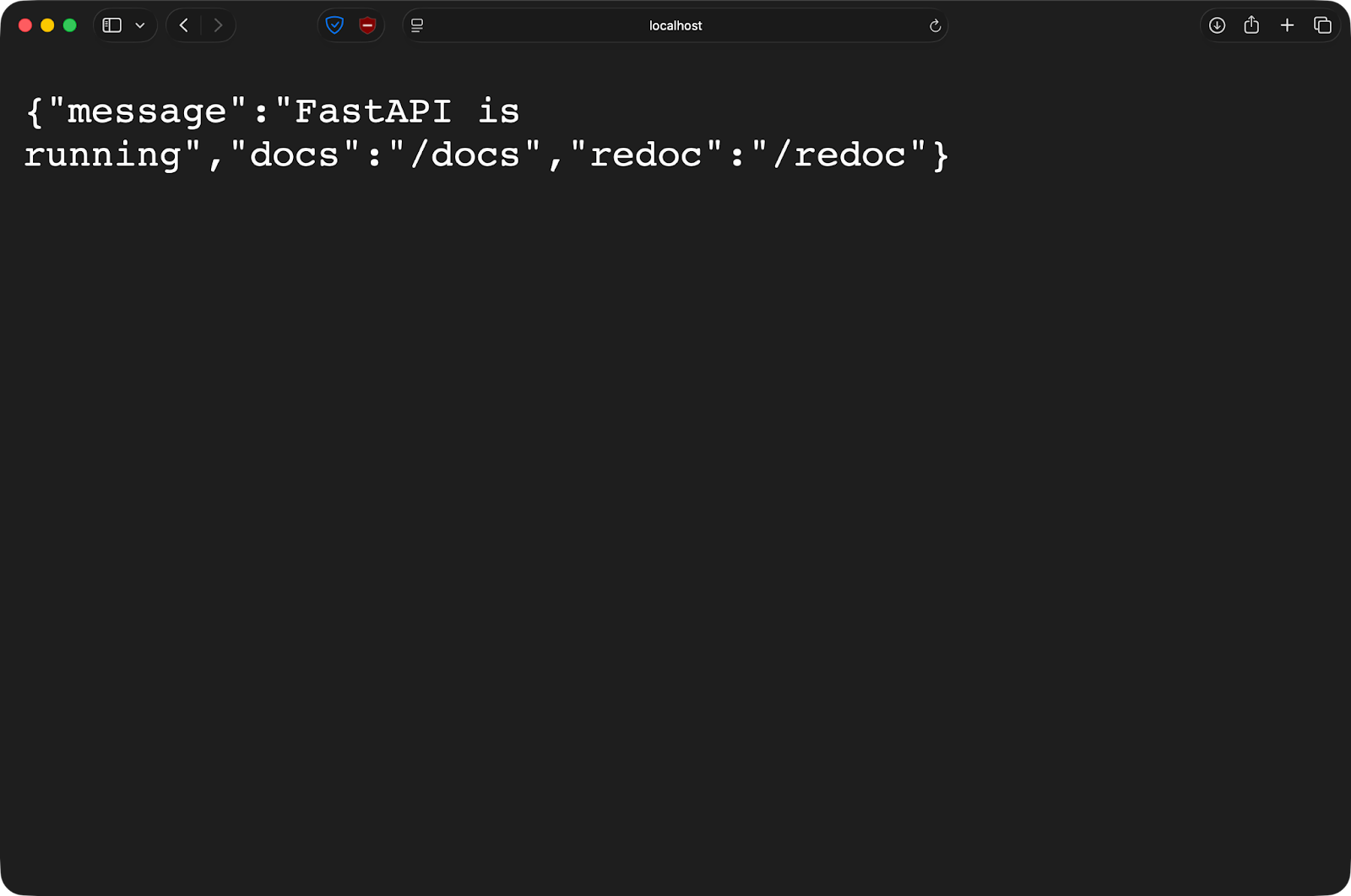
Wenn du die Datei „ main.py “ in deinem Editor bearbeitest und speicherst, wird FastAPI automatisch neu geladen. Keine Bilder neu erstellen, keine Container neu starten. Du schreibst Code wie lokal, aber deine App läuft in einer einheitlichen Containerumgebung.
Bind-Mounts machen dein Host-Dateisystem für Container zugänglich, was zu Sicherheitsproblemen führen kann.
Ein Container mit einem Bind-Mount kann Dateien auf deinem Host lesen und schreiben. Wenn du einen Container als Root ausführst – das ist die Standardeinstellung –, hat er Root-Zugriff auf die eingebundenen Dateien. Bösartiger Code oder ein geknackter Container kann alles im gemounteten Verzeichnis ändern oder löschen.
Die Tragbarkeit ist ein weiteres Problem.
Bind-Mounts brauchen bestimmte Pfade auf dem Host. Die Datei „ /Users/dradecic/Desktop/app “ ist weder auf deinem Rechner noch auf einem Produktionsserver vorhanden. Das macht die „überall funktionierende“ Versprechung von Containern zunichte.
Plattformunterschiede sind auch ein Thema. Windows und Mac nutzen eine VM, um Docker zu starten, also müssen Bind-Mounts eine zusätzliche Übersetzungsschicht durchlaufen. Das macht Dateioperationen langsamer und kann zu kleinen Fehlern bei der Dateiüberwachung und bei Symlinks führen.
In Produktionsumgebungen sollte man niemals Bind-Mounts verwenden.
Sie hängen zu sehr von hostspezifischen Pfaden ab, sind aus Sicherheitsgründen zu riskant und lassen sich nicht versionieren. Volumes lösen all diese Probleme, deshalb sind sie der Standard in der Produktion.
Betrachte Bind-Mounts als Entwicklungswerkzeug – schnell, praktisch und leistungsstark, aber nichts, was du in der Produktion einsetzen solltest.
tmpfs speichert Daten im RAM deines Hosts statt auf der Festplatte. Das macht sie super für Daten, die du nicht dauerhaft speichern willst.
Ein tmpfs-Mount ist komplett im Speicher.
Docker teilt RAM auf deinem Host-Rechner zu und macht ihn als Dateisystem im Container verfügbar. Eine Datei, die in ein tmpfs-Mount geschrieben wird, landet nie auf deiner Festplatte. Die Daten bleiben im Speicher, bis der Container angehalten wird.
Wenn du den Container stoppst, wird alles im tmpfs-Mount gelöscht. Es ist keine Bereinigung nötig, es gibt keine Dateireste und keine Spuren von dem, was da war. Jedes Mal, wenn du den Container neu startest, bekommst du einen neuen, leeren tmpfs-Mount.
Kurz gesagt, tmpfs-Mounts sind für Daten gedacht, die du nicht behalten willst – wie temporäre Berechnungen, Sitzungstoken oder sensible Infos, die nach der Nutzung nicht mehr da sein sollen.
Der häufigste Anwendungsfall ist das Speichern von Geheimnissen oder sensiblen Daten.
Angenommen, du betreibst einen Container, der einen API-Schlüssel oder ein Datenbankpasswort braucht. Speichere es in einem tmpfs-Mount, dann landet das Geheimnis nie auf der Festplatte. Wenn der Container anhält, verschwindet das Geheimnis aus dem Speicher. Es gibt keine Datei, die man aus Versehen in die Versionskontrolle einchecken oder im Dateisystem offen lassen könnte.
Caches passen auch super dazu. Artefakte, kompilierter Code oder heruntergeladene Abhängigkeiten, die du sowieso neu erstellen wirst, müssen nicht gespeichert werden. Speichere sie in tmpfs, um während der Laufzeit des Containers schneller draufzugreifen, und lösche sie dann, wenn du fertig bist.
Auch temporäre Dateien funktionieren hier gut – denk an Sitzungsdaten, Sperrdateien oder Zwischenergebnisse der Verarbeitung, die nur wichtig sind, solange der Container läuft.
Führ diesen Befehl aus, um ein tmpfs-Mount mit dem Flag „ --tmpfs “ zu erstellen:
docker run -d \
--name temp-app \
--tmpfs /tmp:rw,size=100m \
python:3.14Dadurch wird ein 100 MB großes tmpfs-Mount unter /tmp im Container erstellt. Die Option „ size “ legt fest, wie viel RAM das Mount verwenden darf.
Du kannst auch die Syntax „ --mount “ verwenden:
docker run -d \
--name temp-app \
--mount type=tmpfs,destination=/tmp,tmpfs-size=104857600 \
python:3.14Der Wert „ tmpfs-size “ wird in Bytes angegeben – 104857600 Bytes sind 100 MB.
Wenn du keine Größenbeschränkung angibst, nutzt tmpfs bis zur Hälfte des Arbeitsspeichers deines Systems. Das ist gefährlich – aus offensichtlichen Gründen. Leg immer klare Größenbeschränkungen fest.
Der einzige große Nachteil ist, dass tmpfs-Mounts nur unter Linux funktionieren.
Mac und Windows Docker Desktop können das nicht, weil sie Docker in einer Linux-VM laufen lassen und tmpfs direkte Kernel-Unterstützung braucht.
Docker bietet dir zwei Möglichkeiten, Mounts zu definieren. Wenn du die richtige Syntax wählst, sind deine Befehle leichter zu lesen und zu debuggen.
Beide Methoden funktionieren, aber eine ist besser, wenn du erweiterte Optionen oder mehrere Mounts in einem einzigen Container brauchst.
Die Option „ --mount “ nutzt eindeutige Schlüssel-Wert-Paare, während „ -v “ oder „ --volume “ eine durch Doppelpunkte getrennte Zeichenfolge verwenden.
Hier ist dieselbe Volume-Einbindung mit beiden Syntaxen:
# Using --mount
docker run -d \
--mount type=volume,source=mydata,target=/app/data \
python:3.14
# Using -v
docker run -d \
-v mydata:/app/data \
python:3.14Beide erstellen ein Volume namens „ mydata “ und hängen es im Container unter „ /app/data “ ein.
Benutz --mount für alles, was über die Grundeinstellungen hinausgeht. Es ist ausführlicher, aber die expliziten Schlüssel machen klar, was jeder Teil macht. Wenn du Optionen wie schreibgeschützten Zugriff oder benutzerdefinierte Volume-Treiber hinzufügst, bleibt es lesbar, während „ -v“ wie eine kryptische Zeichenfolge aussehen kann.
Die Syntax „ -v “ ist super für einfache Entwicklungsabläufe, bei denen du Befehle von Hand eingibst.
Die Option „ readonly ” verhindert, dass Container gemountete Daten ändern:
docker run -d \
--mount type=volume,source=mydata,target=/app/data,readonly \
python:3.14Das ist praktisch für Konfigurationsdateien oder Referenzdaten, die Container lesen, aber nie ändern sollten. Ein Container, der versucht, auf ein schreibgeschütztes Mount zu schreiben, kriegt 'ne Berechtigungsfehlermeldung.
Für Volumes überspringt die Option „ volume-nocopy “ das Kopieren vorhandener Daten aus dem Container-Image in das Volume:
docker run -d \
--mount type=volume,source=mydata,target=/app/data,volume-nocopy \
python:3.14Standardmäßig kopiert Docker alles, was am Einhängepunkt im Image vorhanden ist, in ein neues Volume. Wenn du` volume-nocopy ` einstellst, bekommst du ein leeres Volume, egal was im Image drin ist.
Für tmpfs-Mounts legt die Option „ tmpfs-size “ ein Speicherlimit fest:
docker run -d \
--mount type=tmpfs,target=/tmp,tmpfs-size=104857600 \
python:3.14Damit wird die Größe des tmpfs-Mounts auf 100 MB begrenzt. Ohne diese Option kann ein tmpfs-Mount den gesamten verfügbaren Arbeitsspeicher belegen.
Wenn du ein Verzeichnis einbindest, das schon im Container-Image da ist, wird alles, was vorher drin war, komplett ausgeblendet.
Angenommen, dein Image hat ein Verzeichnis „ /app/data “ mit integrierten Konfigurationsdateien. Wenn du ein Volume unter /app/data einbindest, verschwinden diese Konfigurationsdateien. Der Container sieht nur, was im Volume ist.
Das passiert bei allen Mount-Typen – Volumes, Bind-Mounts und tmpfs. Der gemountete Inhalt hat Vorrang, und das ursprüngliche Verzeichnis ist nicht mehr zugänglich, solange der Mount aktiv ist.
Mit Docker Compose kannst du ganz einfach Mounts für mehrere Container in deinem Anwendungsstack definieren und freigeben.
Anstatt lange Befehle wie „ docker run “ mit Mount-Flags zu tippen, legst du einfach alles in einer Datei namens „ docker-compose.yml “ fest. Ich zeig dir, wie das geht.
Hier ist eine Compose-Datei mit Beispielen für Volume und Bind-Mount:
services:
service-1:
image: ubuntu:latest
command: sleep infinity
volumes:
- ./code:/app # Bind mount for development
- shared:/data # Named volume shared with worker
service-2:
image: ubuntu:latest
command: sleep infinity
volumes:
- shared:/data # Same volume as service-1
volumes:
shared:Der Schlüssel „ volumes “ unter jedem Dienst legt fest, was eingebunden wird. Relative Pfade wie ./code erstellen Bind-Mounts, während Namen wie shared auf benannte Volumes verweisen.
Der Abschnitt „ volumes “ auf oberster Ebene sagt, welche benannten Volumes Compose erstellt und verwaltet. Sowohl service-1 als auch service-2 hängen dasselbe Volume shared ein, sodass sie die gleichen Dateien sehen. Schreib eine Datei aus einem Container, und der andere Container kann sie sofort lesen.
Der Befehl „ sleep infinity “ hält Container am Laufen, damit du sie ausführen kannst – nur zur Demo.
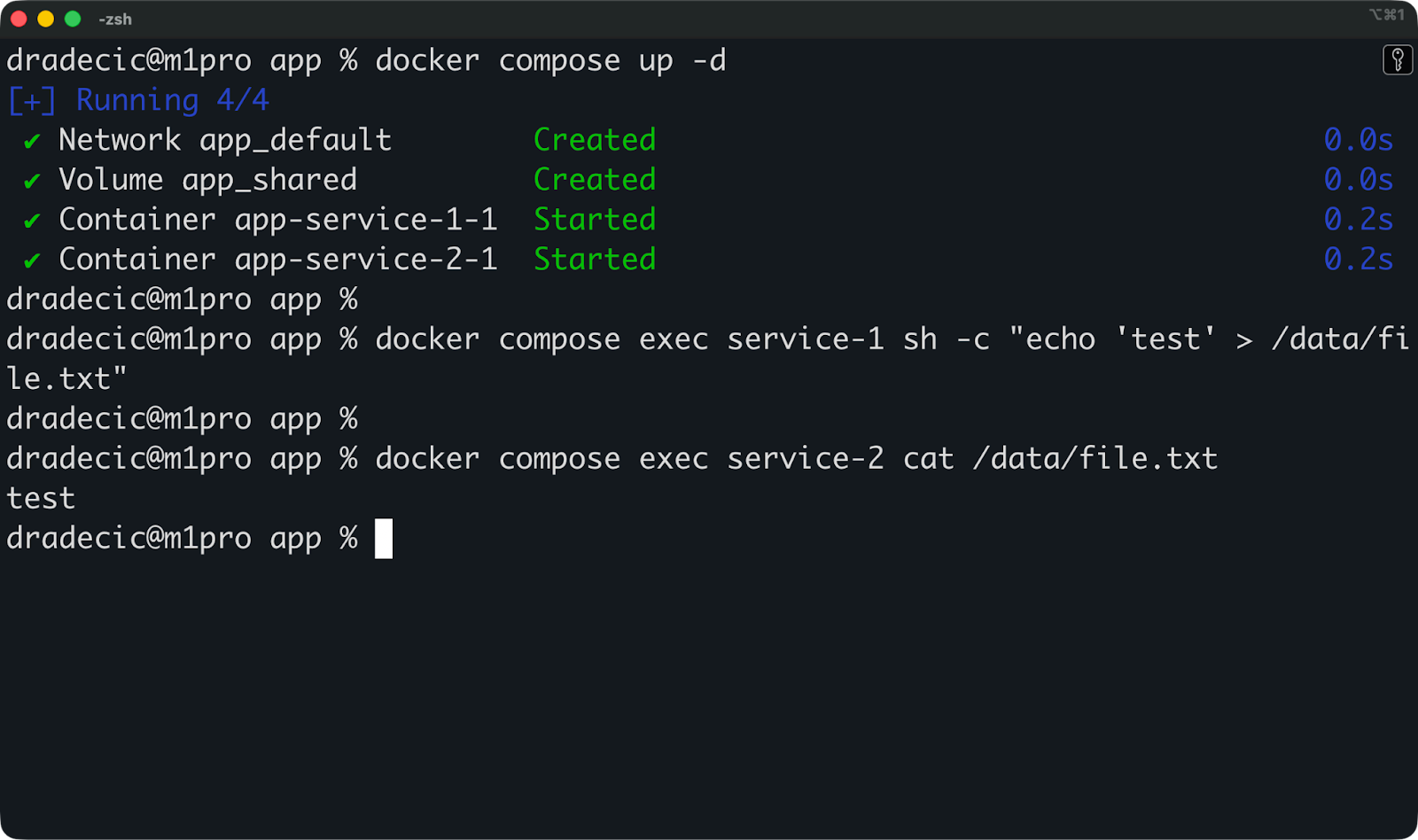
Mach mal mit „ docker compose up -d “ los und schau dann, ob die Mounts funktionieren:
# Write data to the shared volume from app
docker compose exec service-1 sh -c "echo 'test' > /data/file.txt"
# Read it from worker
docker compose exec service-2 cat /data/file.txtWenn beide Befehle funktionieren, sind deine Volumes richtig eingerichtet.
Jetzt kannst du diesen Befehl ausführen, um alles zu stoppen und zu entfernen:
docker compose downDeine benannten Volumes sind weiterhin vorhanden. Wenn du den Stack mit „ docker compose up -d “ neu startest, sind die Daten, die du vorher geschrieben hast, immer noch da. So bleiben Datenbanken über verschiedene Bereitstellungen hinweg erhalten – das Volume bleibt länger bestehen als der Container.
Um Volumes zu löschen, wenn du den Stack stoppst, füge das -v hinzu:
docker compose down -vDamit werden alle in deiner Compose-Datei definierten Volumes gelöscht. Benutz es, wenn du einen Neuanfang machen willst.
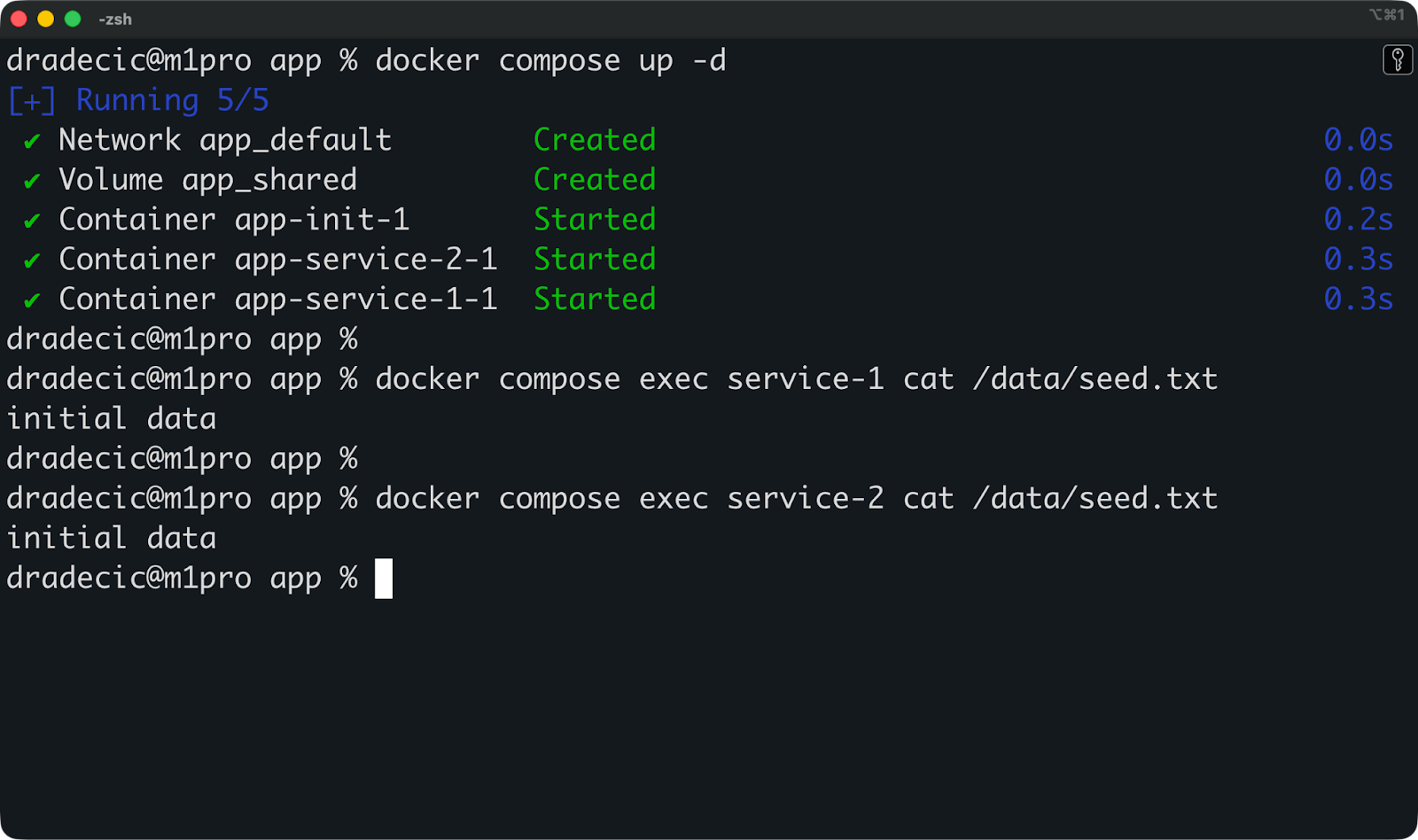
Das häufigste Muster ist, einen separaten Init-Container zu verwenden, um das gemeinsam genutzte Volume zu initialisieren:
services:
init:
image: ubuntu:latest
command: sh -c "mkdir -p /source && echo 'initial data' > /source/seed.txt && cp /source/* /dest/"
volumes:
- shared:/dest
service-1:
image: ubuntu:latest
command: sleep infinity
depends_on:
- init
volumes:
- shared:/data
service-2:
image: ubuntu:latest
command: sleep infinity
depends_on:
- init
volumes:
- shared:/data
volumes:
shared:Der Container „ init “ erstellt Startdaten, kopiert sie in das freigegebene Volume „ “ und beendet dann den Vorgang. Sowohl service-1 als auch service-2 starten danach und finden die gesäten Daten einsatzbereit vor.
Compose kümmert sich um die ganze Koordination mehrerer Container und ihres gemeinsamen Speichers in einer einzigen Datei, die nach Versionen verwaltet wird.
Wenn du den falschen Mount-Typ wählst, kann das deine Container verlangsamen oder Sicherheitslücken schaffen, von denen du gar nicht wusstest, dass sie existieren. Lies diesen Abschnitt, wenn du das nicht willst.
Volumes laufen unter Linux am besten, weil sie direkt im Dateisystem des Hosts gespeichert werden, ohne dass eine Übersetzungsschicht dazwischen ist.
Auf Mac und Windows läuft Docker in einer Linux-VM. Die Volumes funktionieren immer noch gut, weil sie in dieser VM bleiben. Andererseits müssen Bind-Mounts Dateien zwischen deinem Host-Betriebssystem und der Linux-VM synchronisieren, was zusätzlichen Aufwand bedeutet. Dateioperationen auf Bind-Mounts können auf Mac und Windows im Vergleich zu nativem Linux deutlich langsamer sein.
tmpfs ist die schnellste Option für Lese- und Schreibvorgänge, weil alles im RAM passiert. Keine Festplatten-E/A, kein Dateisystem-Overhead. Aber du bist durch den verfügbaren Speicher begrenzt, und die Daten verschwinden, wenn der Container angehalten wird.
Wenn du Linux nutzt und volle Leistung brauchst, solltest du Volumes verwenden. Wenn du einen Mac oder Windows-PC benutzt und während der Entwicklung langsame Dateioperationen feststellst, hast du wahrscheinlich mit Bind-Mount-Overhead zu kämpfen. Wechsel zu Volumes für Produktions-Workloads.
Jedes Mount gibt Containern Zugriff auf etwas außerhalb ihres isolierten Dateisystems, und das ist ein Risiko.
Bind-Mounts sind das größte Problem. Wenn du /home/user in einen Container einbindest, kann ein gehackter Container deine SSH-Schlüssel lesen, deine shell-Konfiguration ändern oder Dateien in deinem gesamten Home-Verzeichnis löschen. Starte diesen Container als Root – das ist die Standardeinstellung – und er hat Root-Zugriff auf diese Dateien.
Volumes machen das Risiko kleiner, weil sie im Speicherverzeichnis von Docker isoliert sind. Ein Container kann nicht einfach irgendwelche Host-Pfade über Volumes einbinden. Aber Volumes können trotzdem Daten zwischen Containern verlieren, wenn du sie einfach so freigibst.
tmpfs-Mounts machen das Risiko von Datenverlusten kleiner – im Speicher abgelegte Geheimnisse verschwinden, wenn die Container beendet werden. Aber sie schützen nicht vor Laufzeitangriffen, bei denen ein kompromittierter Container Geheimnisse aus dem Speicher liest.
Die Regel ist, dass Mounts die Isolation von Containern aufheben, also sei vorsichtig damit.
Montiere nur die Container, die du brauchst, und nicht mehr.
Anstatt dein ganzes Projektverzeichnis zu mounten, mount einfach nur das Unterverzeichnis, das der Container nutzt. Wenn der Container nur Logs lesen muss, häng ' /var/log ' nicht mit Schreibzugriff ein, sondern nur mit Lesezugriff.
Benutz die Option „ readonly “, wann immer du kannst:
docker run -d \
--mount type=bind,source=/app/config,target=/config,readonly \
ubuntu:latestDas verhindert, dass Container gemountete Daten verändern, und begrenzt den Schaden, wenn sie kompromittiert werden.
Lass Container als Nicht-Root-Benutzer laufen, um die Auswirkungen von Bind-Mount-Schwachstellen zu verringern. Erstell einen Benutzer in deiner Dockerfile und wechsel zu ihm, bevor der Container startet:
RUN useradd -m appuser
USER appuserRäum regelmäßig nicht genutzte Volumes auf mit „ docker volume prune “. Alte Volumes stapeln sich mit der Zeit, nehmen Speicherplatz weg und können sensible Daten aus gelöschten Containern enthalten.
Häng niemals sensible Host-Verzeichnisse wie /, /etc oder /var ein, es sei denn, du hast einen bestimmten Grund dafür und bist dir der Risiken bewusst. Jede Halterung sollte einen klaren Zweck haben und möglichst klein sein.
Mount-Probleme zeigen sich meistens als Berechtigungsfehler, fehlende Dateien oder Container, die nicht starten – und sie werden fast immer durch die gleichen Probleme verursacht.
Hier erfährst du, wie du die häufigsten Probleme, die auftreten können, findest und behebst.
Berechtigungsfehler treten auf, wenn der Benutzer im Container keinen Zugriff auf gemountete Dateien hat.
Docker-Container laufen standardmäßig als Root. Wenn root eine Datei in einem Bind-Mount erstellt, gehört diese Datei root auf deinem Host. Wenn du versuchst, es mit deinem normalen Benutzerkonto zu bearbeiten, bekommst du eine Fehlermeldung, dass die Berechtigung verweigert wurde.
Das Gegenteil passiert auch. Wenn du ein Verzeichnis, das dir gehört, in einem Container einbindest, der als Nicht-Root-Benutzer läuft, kann der Container möglicherweise nicht in dieses Verzeichnis schreiben.
Du kannst die Dateibesitzrechte mit „ ls -la “ im gemounteten Verzeichnis überprüfen:
ls -la /path/to/mounted/directoryWenn die Dateien Root gehören, dein Container aber mit einem anderen Benutzer läuft, hast du ein Problem. Behebe das Problem, indem du den Container mit demselben Benutzer ausführst, dem die Dateien gehören:
docker run -d \
--user $(id -u):$(id -g) \
-v ./data:/app/data \
ubuntu:latestDamit wird der Container als dein aktueller Benutzer statt als root ausgeführt, passend zur Eigentümerschaft der Dateien im Bind-Mount.
Bei Volumes kümmert sich Docker automatisch um die Berechtigungen, wenn Container Dateien erstellen. Wenn du aber Fehler siehst, check mal, unter welchem Benutzer die containerisierte App läuft und ob sie Schreibzugriff auf den Mountpunkt hat.
Der häufigste Fehler ist, einen Pfad einzubinden, der auf dem Host gar nicht existiert.
Versuch mal, /home/user/project zu mounten, wenn das Verzeichnis nicht da ist, und Docker macht ein leeres Verzeichnis, das root gehört. Dein Container startet, aber er mountet das Falsche – ein leeres Verzeichnis statt deines eigentlichen Projekts.
Überprüfe immer, ob die Pfade da sind, bevor du sie einbindest:
ls /home/user/projectWenn das Verzeichnis nicht da ist, leg es erst an oder korrigier den Pfad in deinem Mount-Befehl.
In Docker Compose werden relative Pfade aus dem Verzeichnis aufgelöst, in dem sich deine Datei „ docker-compose.yml “ befindet. Wenn deine Datei im Verzeichnis „ /home/user/app/ ” liegt und du „ ./data ” benutzt, sucht Docker nach „ /home/user/app/data ”.
Verschieb die Compose-Datei, und die Einbindung wird unterbrochen.
Ein weiterer häufiger Fehler ist das Mounten auf den falschen Zielpfad im Container. Wenn du deine App auf /app/data installierst, obwohl sie eigentlich /data braucht, wird sie ihre Dateien nicht finden können. Schau in der Dokumentation deiner Anwendung oder in der Dockerfile nach, wo die Daten sein sollen.
Unter Linux funktionieren Bind-Mounts direkt mit dem Dateisystem des Hosts.
Auf Mac und Windows läuft Docker in einer Linux-VM. Bind-Mounts synchronisieren Dateien zwischen deinem Host-Betriebssystem und dieser VM, was zu Timing-Problemen führt. Dateiüberwacher – Tools, die deine App neu laden, wenn sich Dateien ändern – verpassen manchmal Updates wegen Synchronisierungsverzögerungen.
Mac und Windows gehen auch unterschiedlich mit Dateiberechtigungen um. Die VM übersetzt Berechtigungen zwischen dem Host-Betriebssystem und Linux, was dazu führen kann, dass Dateien innerhalb von Containern mit falschen Eigentumsrechten angezeigt werden.
Symlinks funktionieren nicht zuverlässig in Bind-Mounts auf Mac und Windows. Die VM kann nicht immer Symlinks auflösen, die außerhalb des gemounteten Verzeichnisses liegen, sodass Dateien in Containern als fehlend oder beschädigt angezeigt werden.
tmpfs-Mounts funktionieren auf Mac und Windows überhaupt nicht, weil die VM tmpfs nicht für den Host freigibt. Wenn du versuchst, ein tmpfs-Mount zu verwenden, wird Docker es je nach Version entweder stillschweigend ignorieren oder eine Fehlermeldung ausgeben.
Wenn du auf Mac oder Windows entwickelst und komische Probleme mit der Dateisynchronisierung hast, wechsel zu benannten Volumes, um die Leistung und Zuverlässigkeit zu verbessern. Benutz Bind-Mounts für Entwicklungs-Workflows, bei denen Echtzeit-Synchronisierung wichtiger ist als perfekte Konsistenz.
Zum Schluss: Nutzt Volumes für Produktionsdaten, die dauerhaft gespeichert werden müssen, wie Datenbanken, hochgeladene Dateien, Anwendungsstatus – alles, was ihr nicht verlieren dürft. Sie werden von Docker verwaltet, sind plattformübergreifend und die sicherste Wahl für wichtige Daten.
Bind-Mounts sind super für Entwicklungsabläufe, wo du eine Echtzeit-Dateisynchronisierung zwischen deinem Host und Containern brauchst. Wenn du Code in deinem Editor bearbeitest, siehst du die Änderungen sofort in deiner containerisierten App. Aber lass sie aus der Produktion raus, weil sie zu sehr von hostspezifischen Pfaden abhängig sind und unnötige Sicherheitsrisiken mit sich bringen.
Wenn du bereit bist, dich näher mit Containerisierung und Virtualisierung zu beschäftigen, schau dir unseren Kurs an: Containerisierung und Virtualisierung mit Docker und Kubernetes.
Lerne Docker mit DataCamp
Lernpfad
Kurs
Kurs
Blog
Tutorial
Matt Crabtree
Tutorial
Javier Canales Luna
Tutorial
Stephen Gruppetta
Tutorial
Moez Ali
