Curso
Conceptos de MLOps
2 h
42.7K
Aprende a trabajar con LLMs en Python directamente en tu navegador

Con la introducción de GPT-4 y posteriormente GPT-4o, ha comenzado la carrera para producir grandes modelos lingüísticos y aprovechar todo el potencial de la IA moderna. Los LLM necesitan bases de datos vectoriales y marcos de integración para crear aplicaciones inteligentes de IA.
Qdrant es un motor de búsqueda de similitud vectorial y una base de datos vectorial de código abierto que proporciona un servicio listo para la producción con una cómoda API, que te permite almacenar, buscar y gestionar incrustaciones vectoriales.
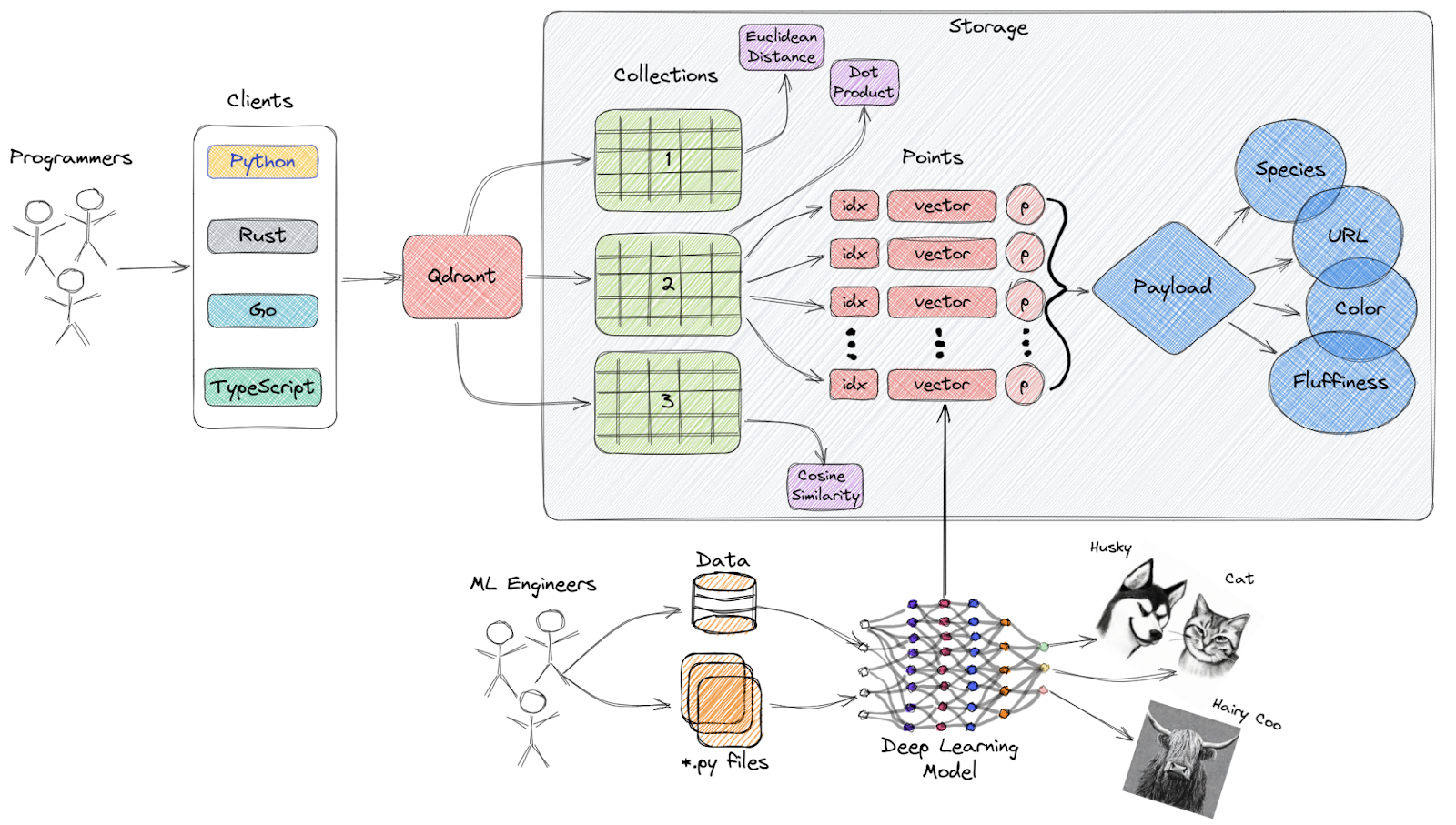
Visión general de alto nivel de la arquitectura de Qdrant
Características principales:
Descubre las mejores bases de datos vectoriales leyendo Las 5 mejores bases de datos vectoriales | Una lista con ejemplos.
LangChain es un marco versátil y potente para desarrollar aplicaciones basadas en modelos lingüísticos. Ofrece varios componentes que permiten a los desarrolladores crear, desplegar y supervisar aplicaciones basadas en el razonamiento y conscientes del contexto.
El marco consta de 4 componentes principales:
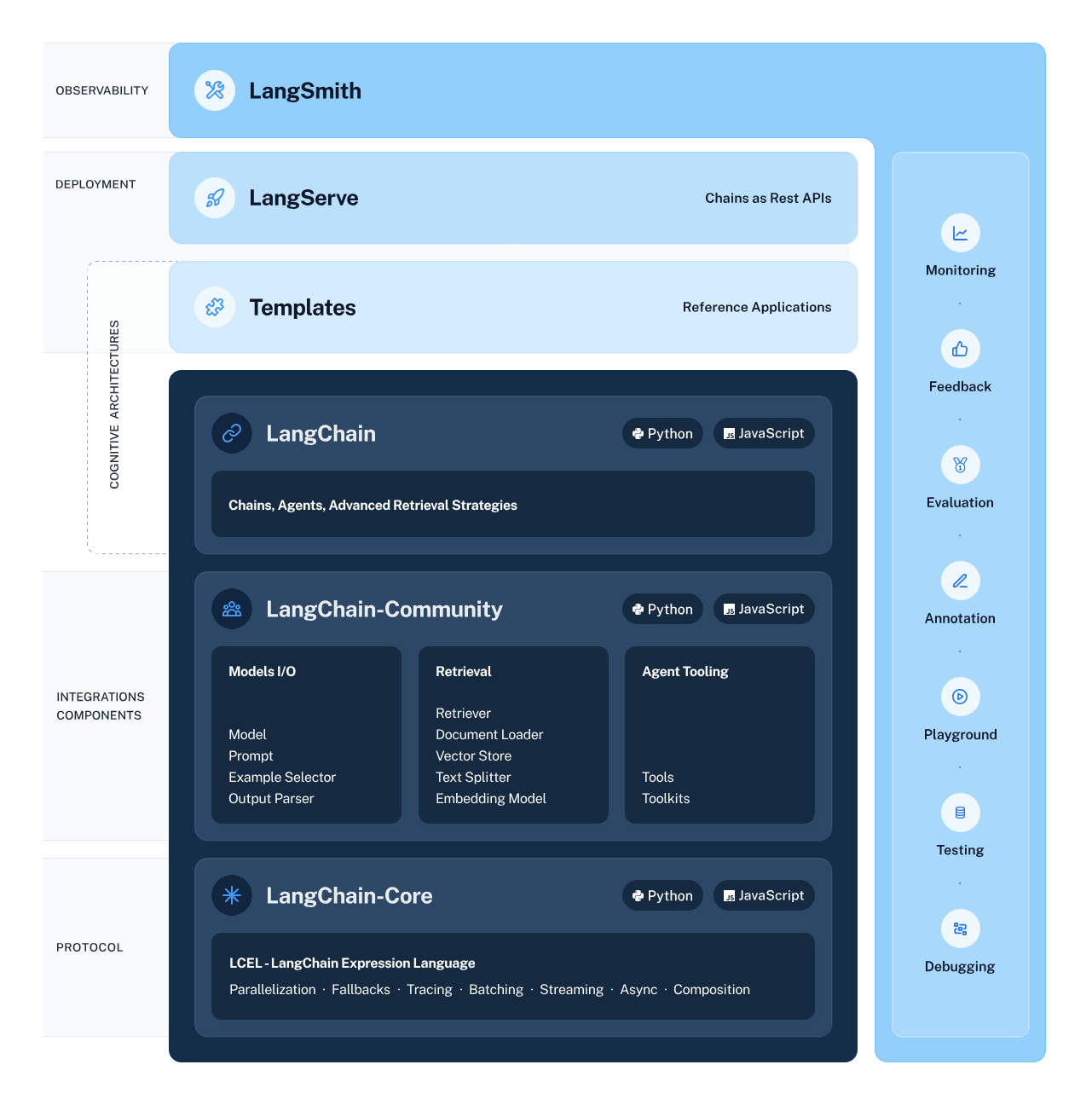
LangChain Ecosystem
Aprende a crear aplicaciones LLM con LangChain y explora el potencial sin explotar de los grandes modelos lingüísticos.
Estas herramientas te permiten gestionar los metadatos de los modelos y te ayudan con el seguimiento de los experimentos:
MLflow es una herramienta de código abierto que te ayuda a gestionar partes fundamentales del ciclo de vida del aprendizaje automático. Generalmente se utiliza para el seguimiento de experimentos, pero también puedes utilizarlo para la reproducibilidad, el despliegue y el registro de modelos. Puedes gestionar los experimentos de aprendizaje automático y los metadatos de los modelos mediante CLI, Python, R, Java y REST API.
MLflow tiene cuatro funciones básicas:
Imagen del autor
Comet ML es una plataforma para rastrear, comparar, explicar y optimizar modelos y experimentos de aprendizaje automático. Puedes utilizarlo con cualquier biblioteca de aprendizaje automático, como Scikit-learn, Pytorch, TensorFlow y HuggingFace.
Comet ML es para particulares, equipos, empresas y académicos. Permite a cualquiera visualizar y comparar fácilmente los experimentos. Además, te permite visualizar muestras de imágenes, audio, texto y datos tabulares.
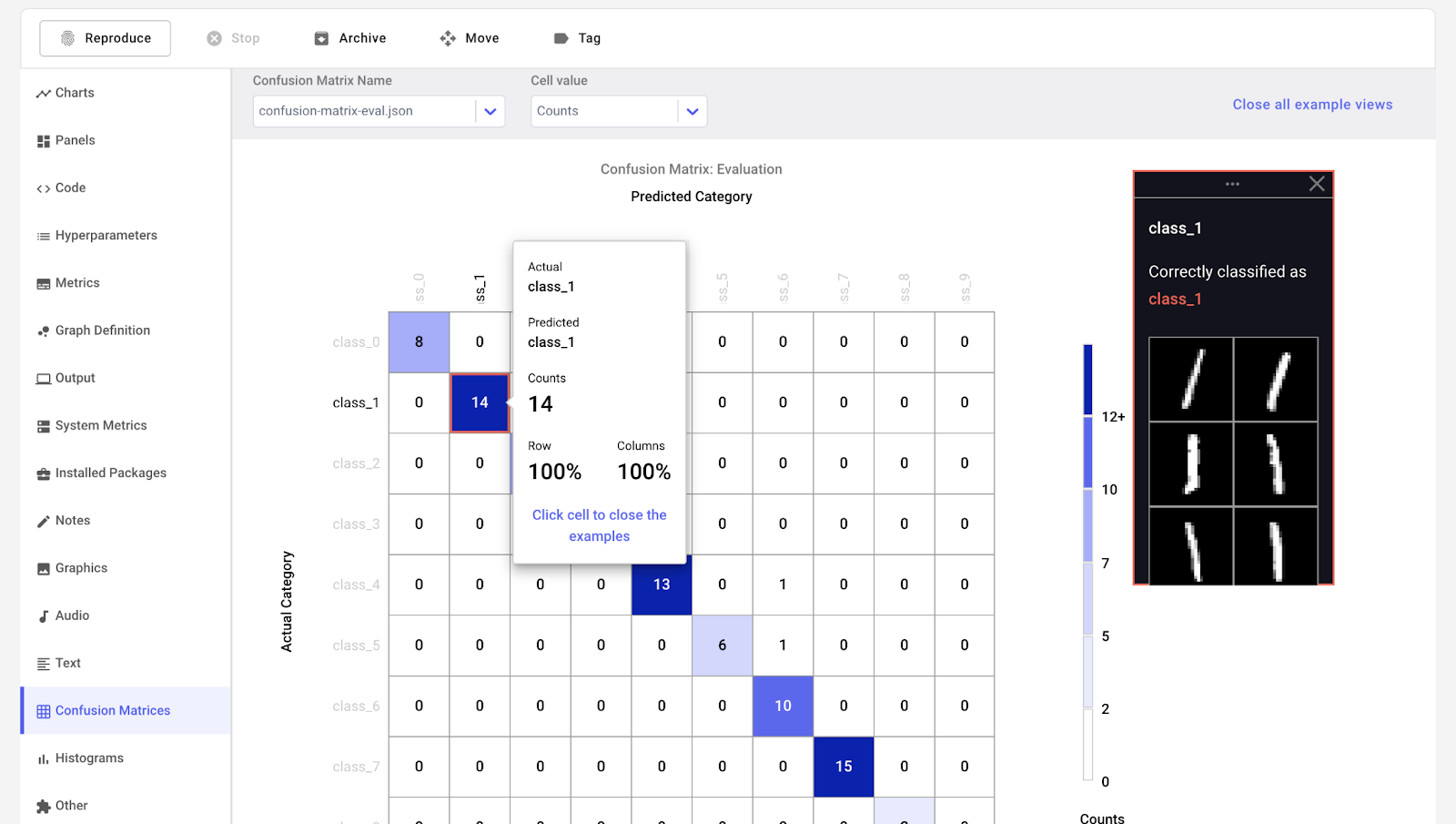
Imagen de Comet ML
Weights & Biases es una plataforma de ML para el seguimiento de experimentos, el versionado de datos y modelos, la optimización de hiperparámetros y la gestión de modelos. Además, puedes utilizarlo para registrar artefactos (conjuntos de datos, modelos, dependencias, canalizaciones y resultados) y visualizar los conjuntos de datos (audio, visual, texto y tabular).
Pesos y Sesgos dispone de un panel central de fácil manejo para los experimentos de aprendizaje automático. Al igual que Comet ML, puedes integrarla con otras bibliotecas de aprendizaje automático, como Fastai, Keras, PyTorch, Hugging face, Yolov5, Spacy y muchas más. Puedes consultar nuestra introducción a Pesos y BIases en otro artículo.
Gif de Pesos y prejuicios
Nota: También puedes utilizar TensorBoard, Pachyderm, DagsHub y DVC Studio para el seguimiento de experimentos y la gestión de metadatos de ML.
Estas herramientas te ayudan a crear proyectos de ciencia de datos y a gestionar flujos de trabajo de aprendizaje automático:
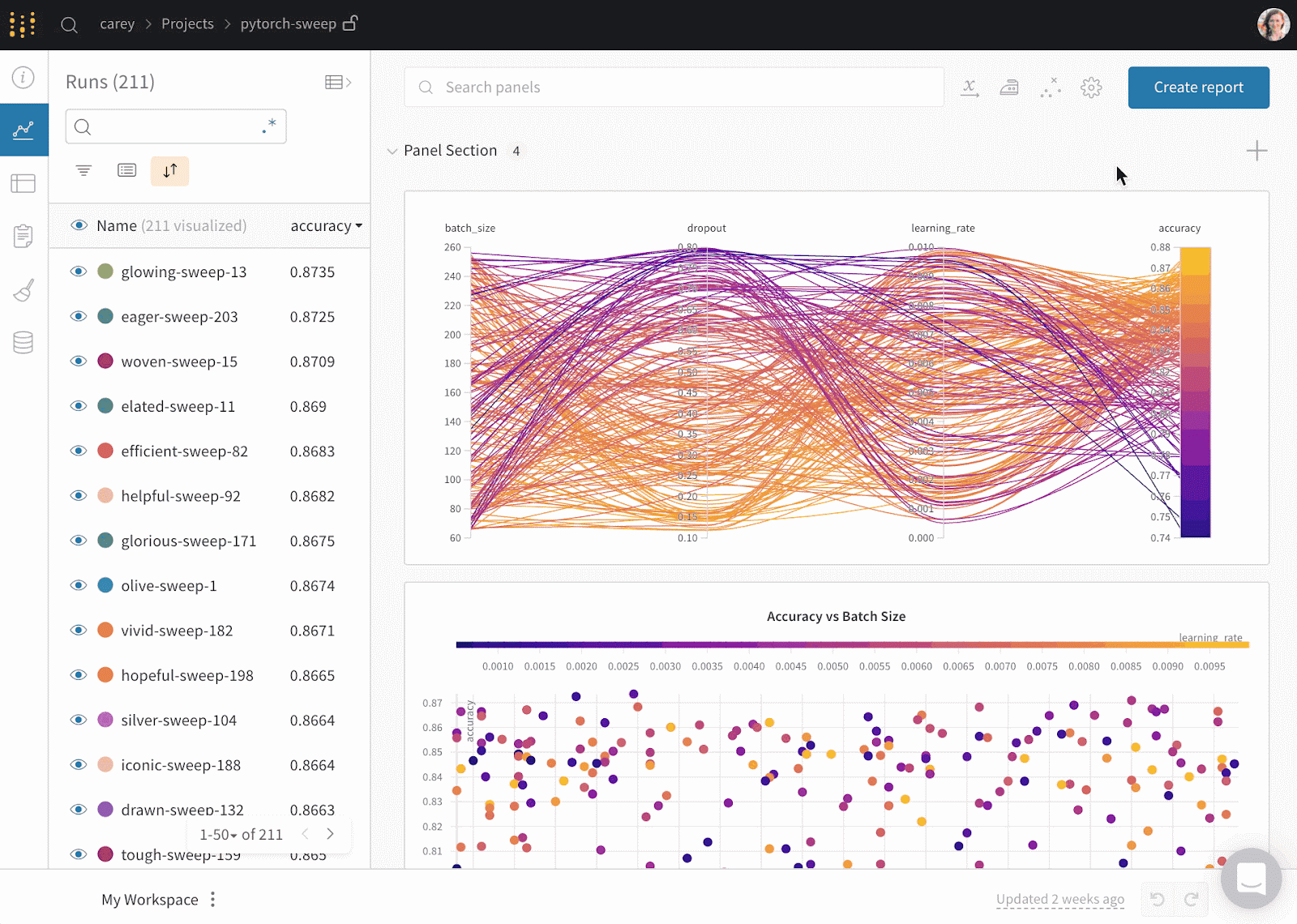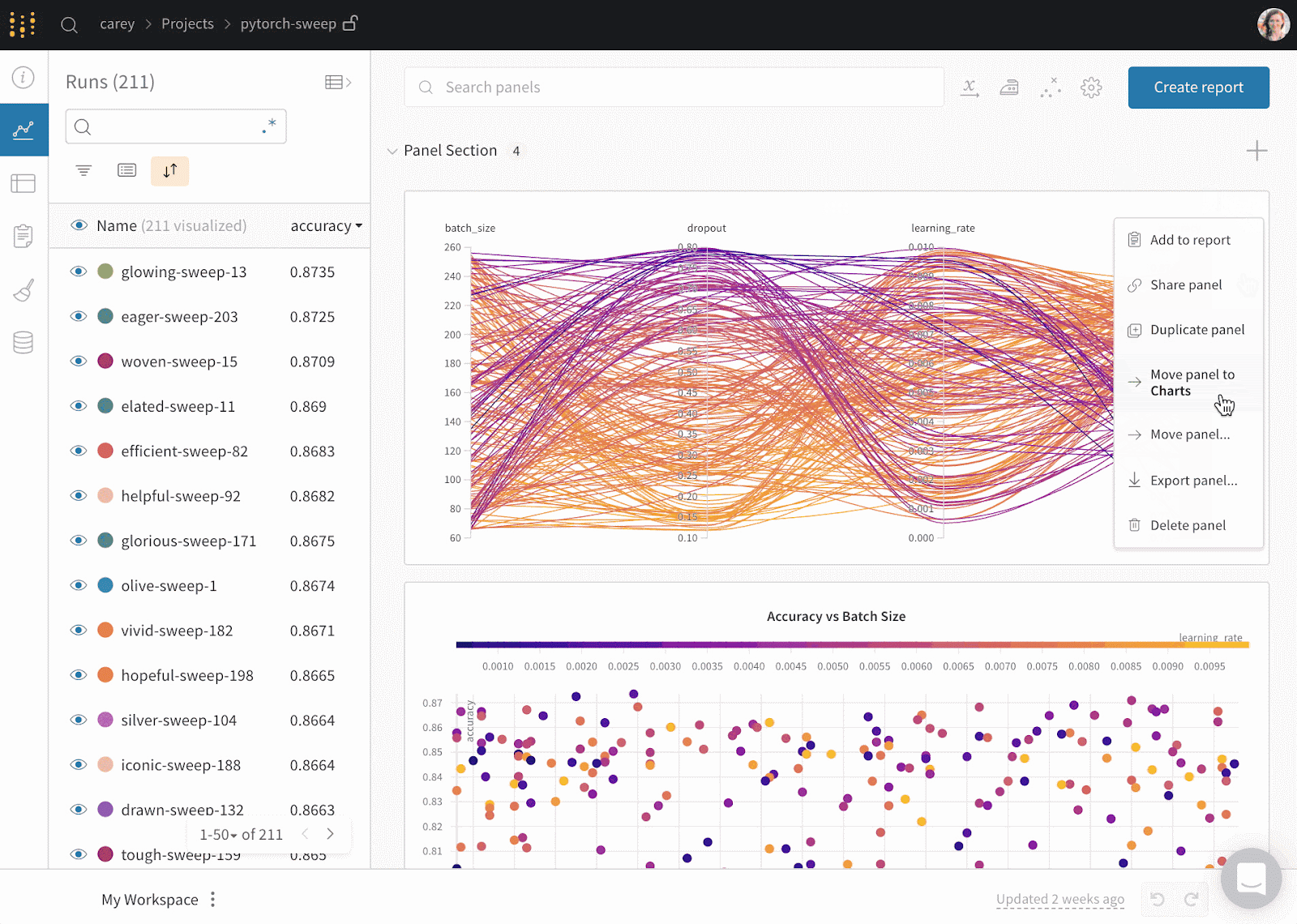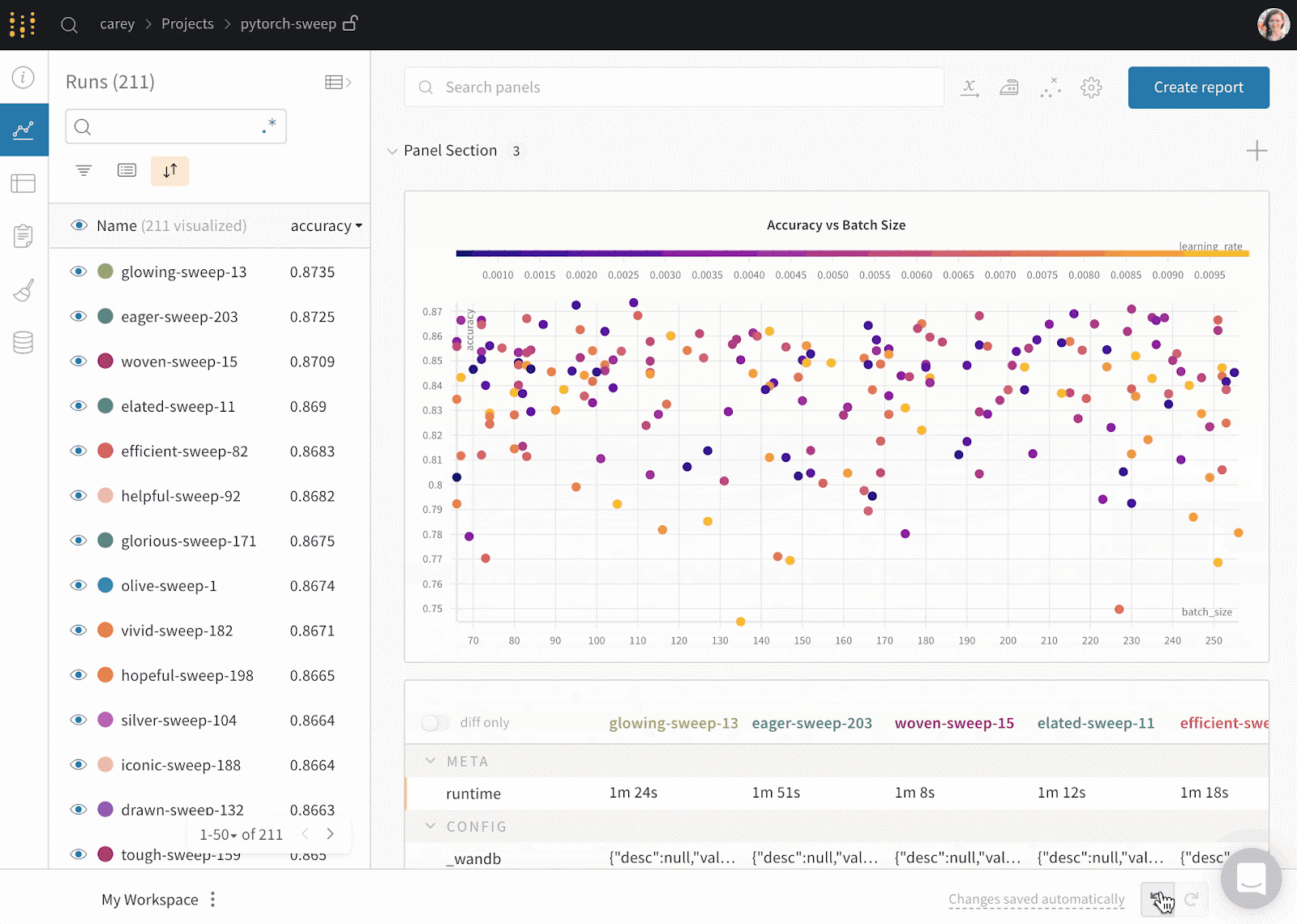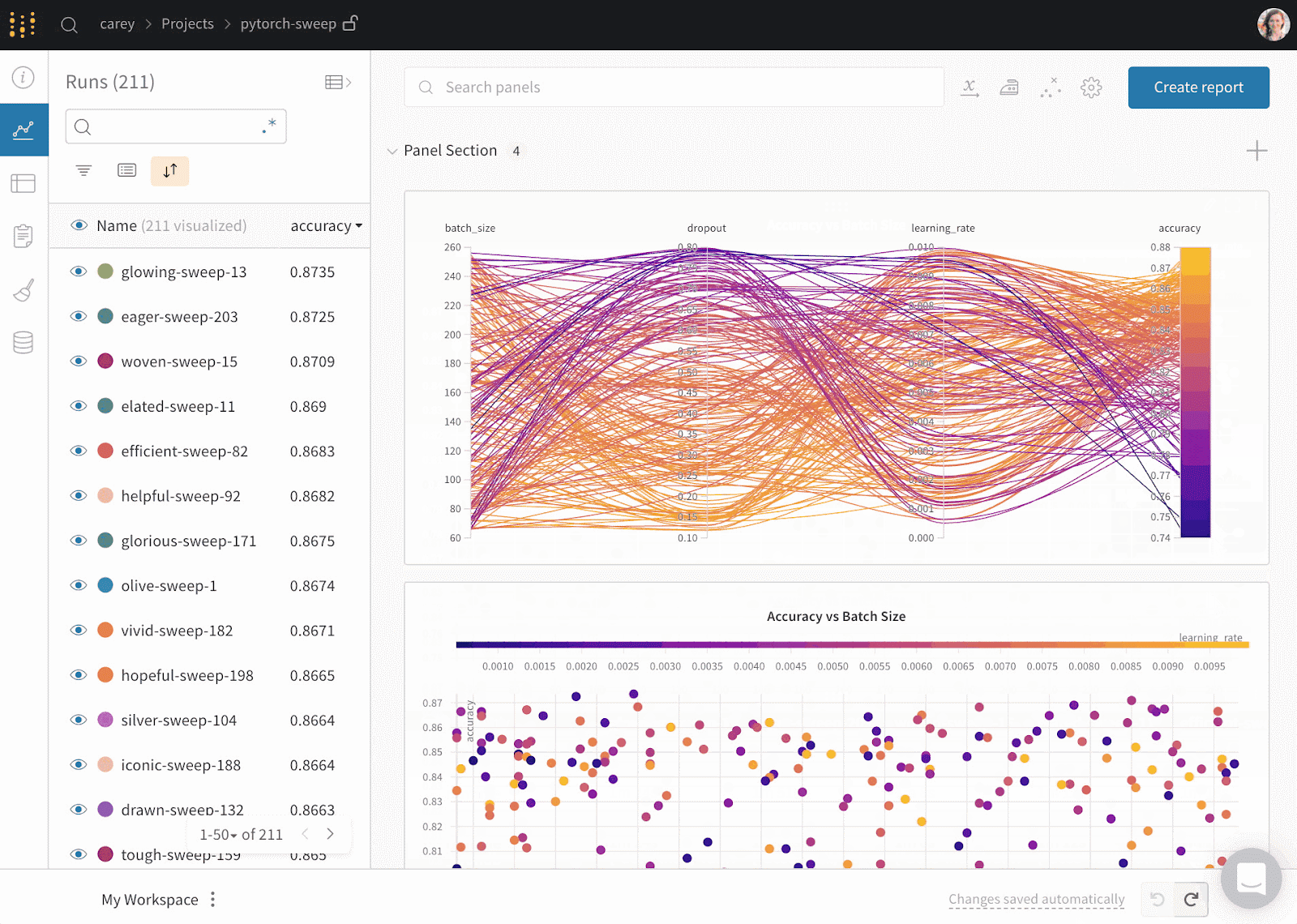
El Prefect es una moderna pila de datos para supervisar, coordinar y orquestar flujos de trabajo entre y a través de aplicaciones. Se trata de una herramienta ligera y de código abierto creada para canalizar el aprendizaje automático de extremo a extremo.
Puedes utilizar Prefect Orion UI o Prefect Cloud para las bases de datos.
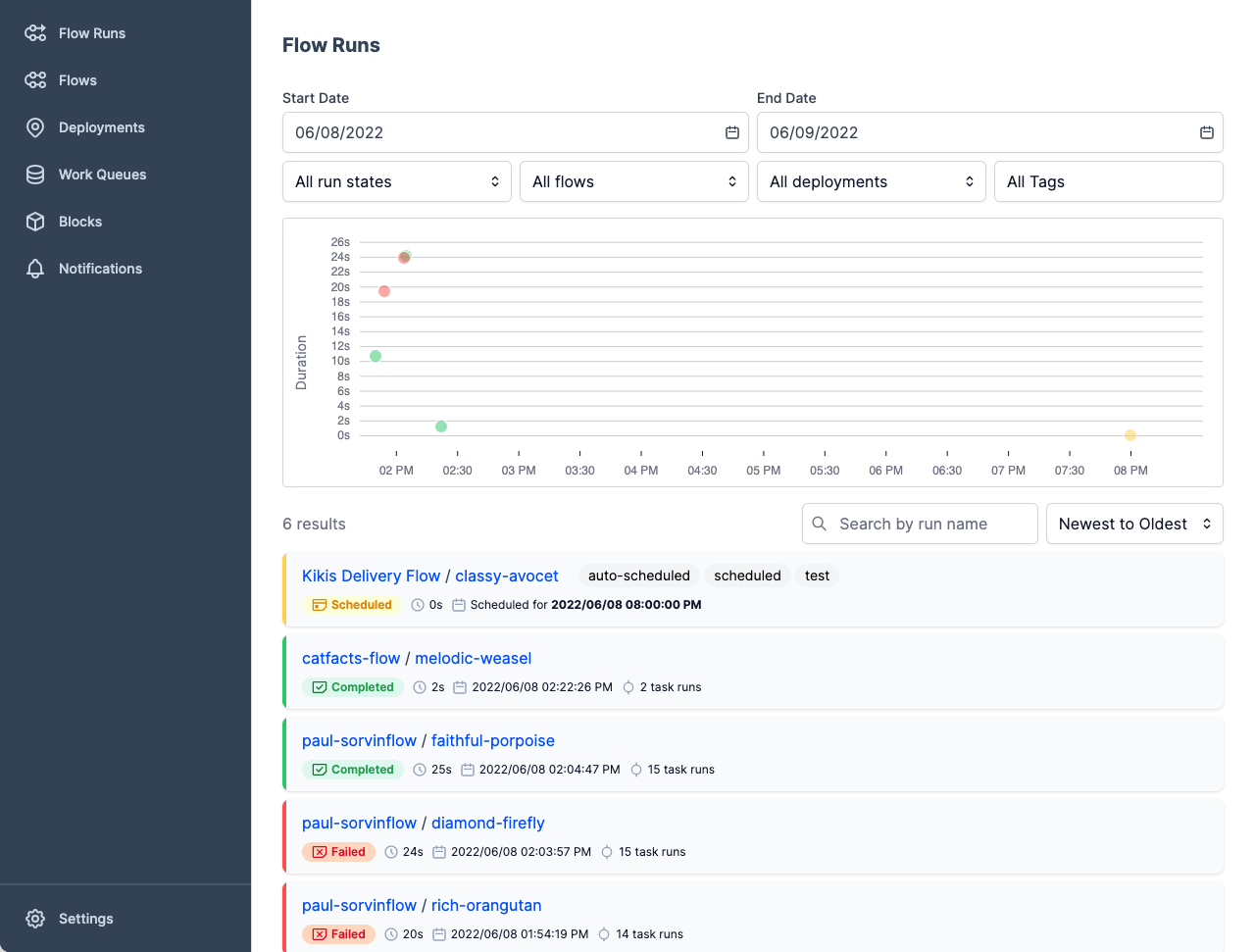
Imagen de Prefect
Metaflow es una potente herramienta de gestión de flujos de trabajo para proyectos de ciencia de datos y aprendizaje automático. Se ha creado para que los científicos de datos puedan centrarse en crear modelos en lugar de preocuparse por la ingeniería de MLOps.
Con Metaflow, puedes diseñar el flujo de trabajo, ejecutarlo a escala y desplegar el modelo en producción. Rastrea y versiona automáticamente los experimentos y datos de aprendizaje automático. Además, puedes visualizar los resultados en el cuaderno.
Metaflow funciona con múltiples nubes (incluidas AWS, GCP y Azure) y varios paquetes Python de aprendizaje automático (como Scikit-learn y Tensorflow), y la API también está disponible para el lenguaje R.
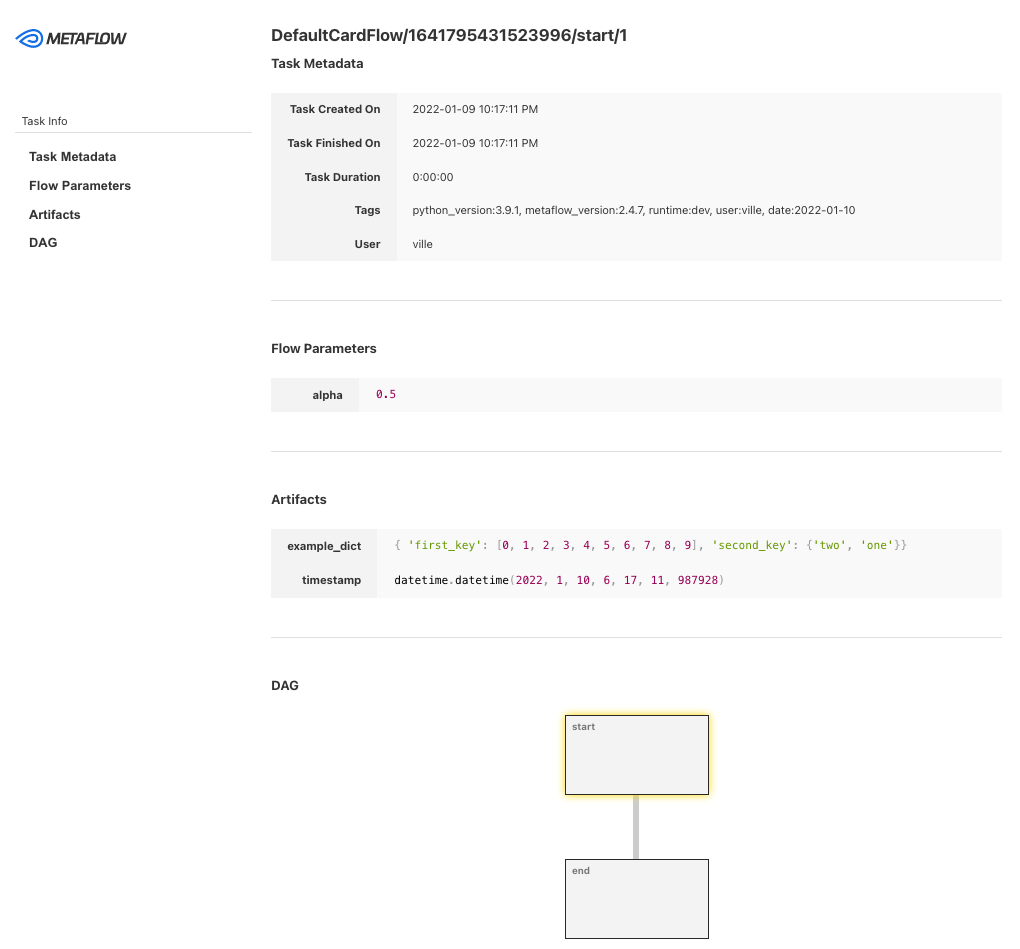
Imagen de Metaflow
Kedro es una herramienta de orquestación de flujos de trabajo basada en Python. Puedes utilizarlo para crear proyectos de ciencia de datos reproducibles, mantenibles y modulares. Integra los conceptos de la ingeniería del software en el aprendizaje automático, como la modularidad, la separación de preocupaciones y el versionado.
Con Kedro, puedes:
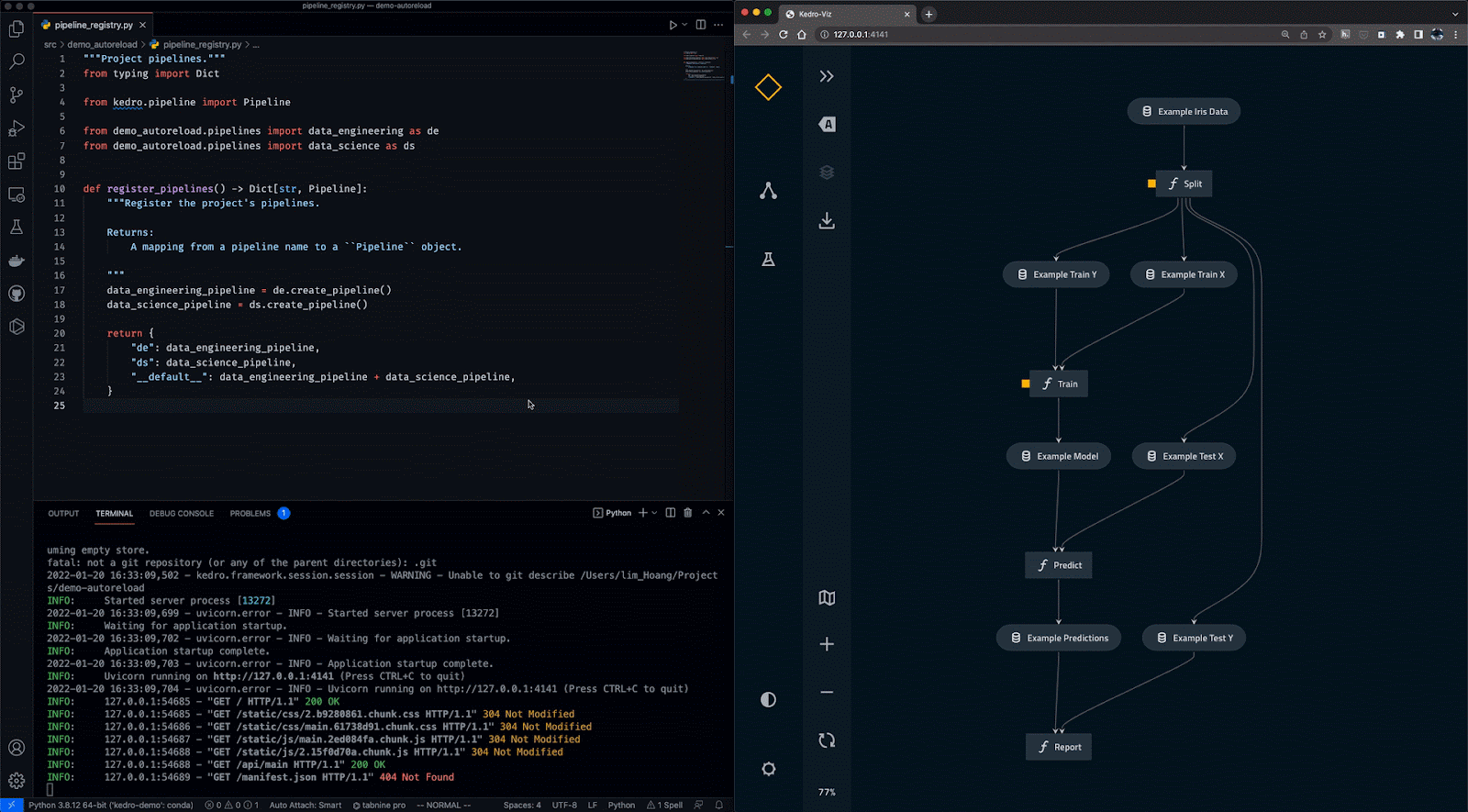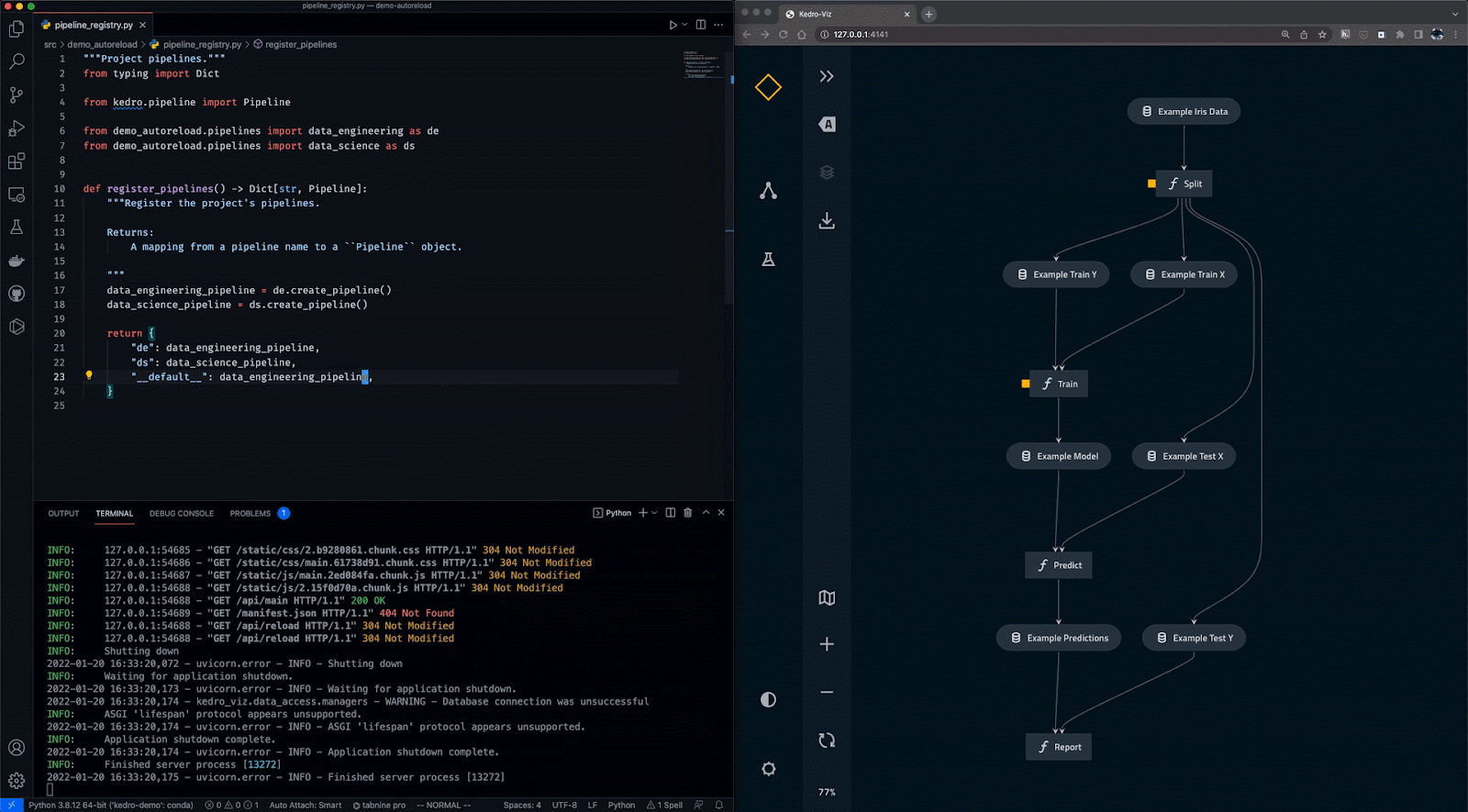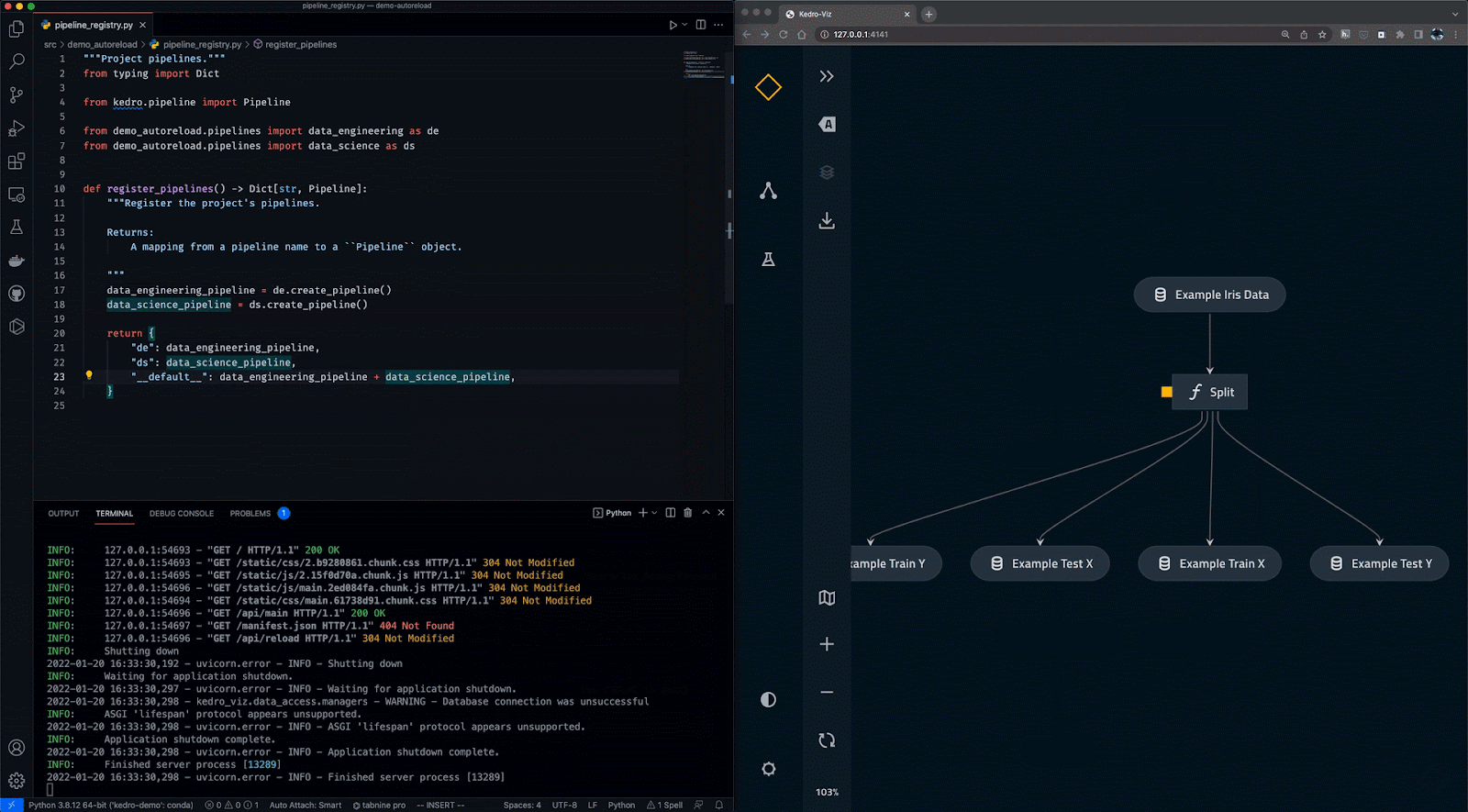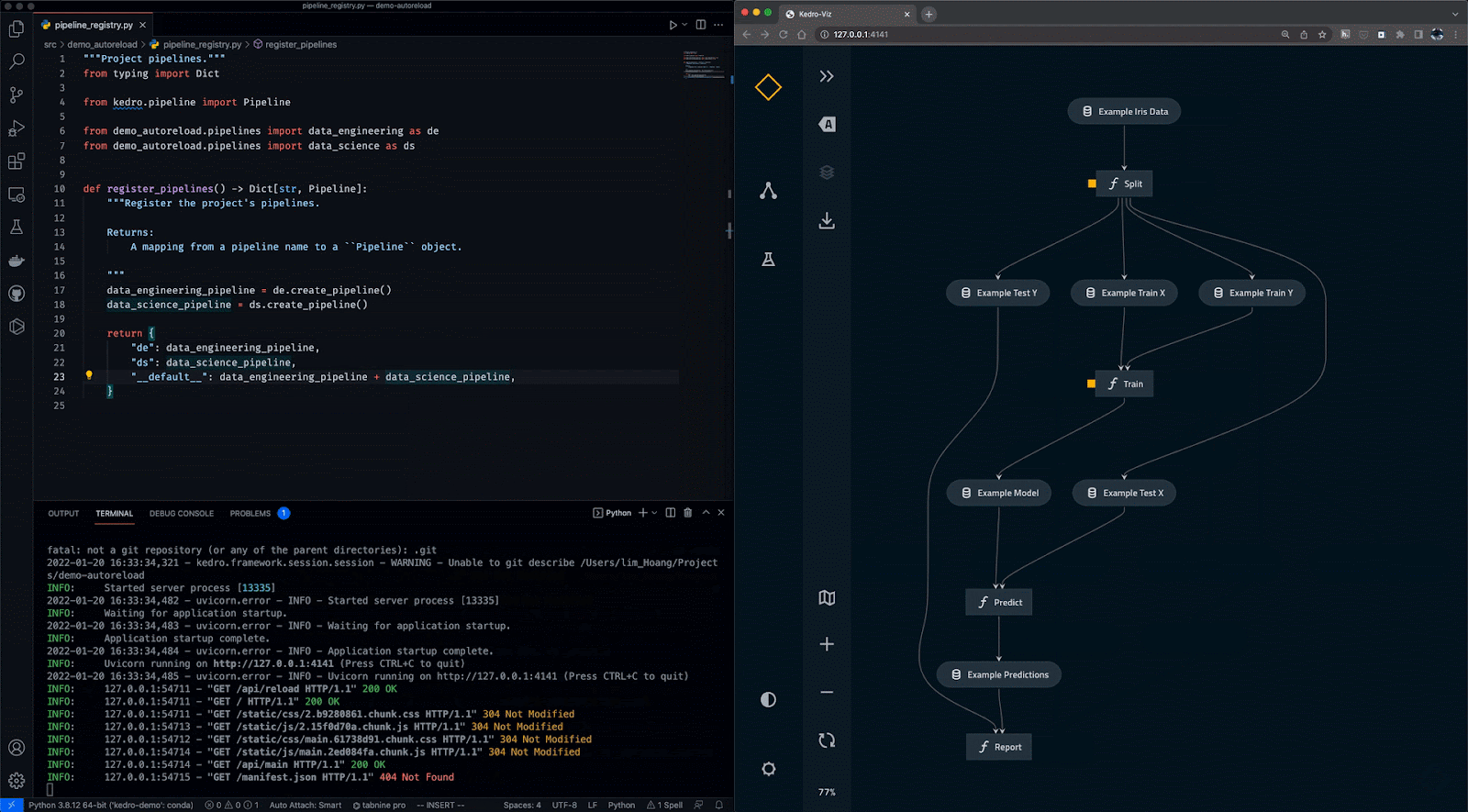
Gif de Kedro
Nota: también puedes utilizar Kubeflow y DVC para la orquestación y las canalizaciones del flujo de trabajo.
Con estas herramientas de MLOps, puedes gestionar las tareas relacionadas con los datos y el versionado de las canalizaciones:
Pachyderm automatiza la transformación de datos con versionado de datos, linaje y canalizaciones de extremo a extremo en Kubernetes. Puedes integrarte con cualquier dato (imágenes, registros, vídeo, CSV), cualquier lenguaje (Python, R, SQL, C/C++) y a cualquier escala (Petabytes de datos, miles de trabajos).
La edición comunitaria es de código abierto y para un equipo pequeño. Las organizaciones y equipos que deseen funciones avanzadas pueden optar por la edición Enterprise.
Al igual que Git, puedes versionar tus datos utilizando una sintaxis similar. En Pachyderm, el nivel más alto del objeto es Repositorio, y puedes utilizar Commit, Ramas, Archivo, Historial y Procedencia para rastrear y versionar el conjunto de datos.
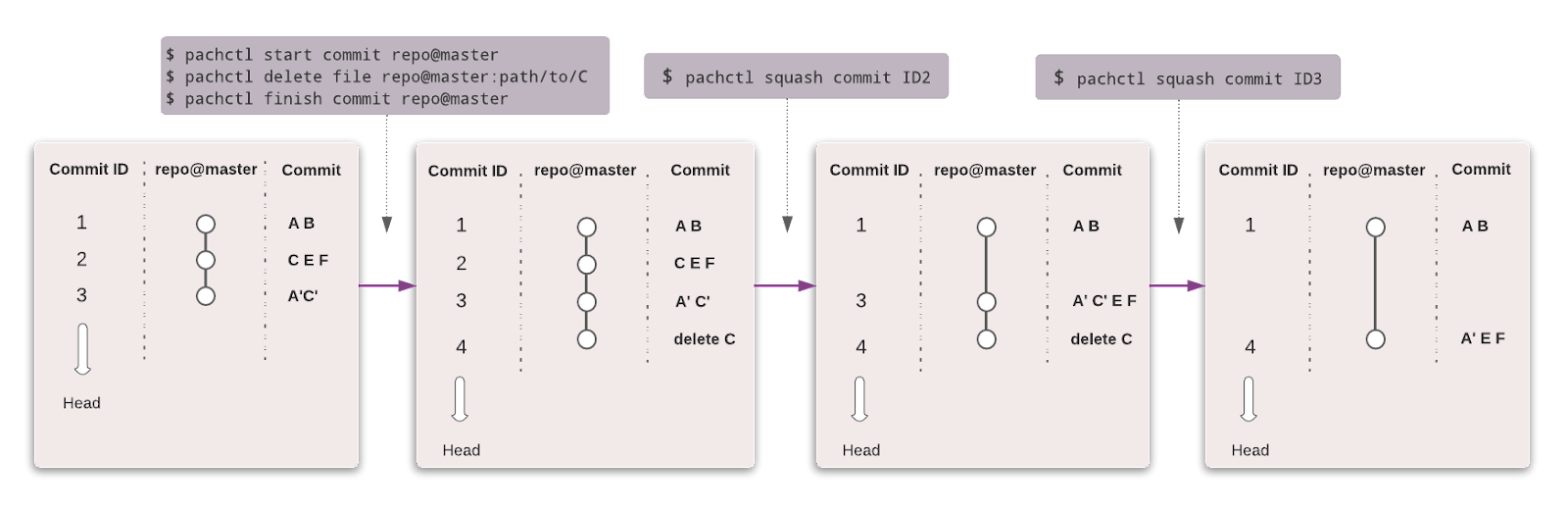
Imagen de Pachyderm
El Control de Versiones de Datos es una herramienta popular y de código abierto para proyectos de aprendizaje automático. Funciona a la perfección con Git para proporcionarte versiones de código, datos, modelos, metadatos y canalizaciones.
DVC es algo más que una herramienta de seguimiento y versionado de datos.
Puedes utilizarlo para:
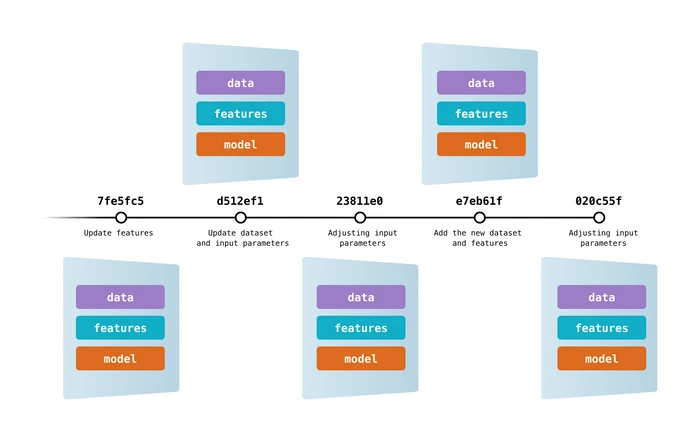
Imagen de DVC
Nota: DagsHub también puede utilizarse para versionar datos y tuberías.
LakeFS es una herramienta de control de versiones de datos escalable y de código abierto que proporciona una interfaz de control de versiones similar a Git para el almacenamiento de objetos, permitiendo a los usuarios gestionar sus lagos de datos como lo harían con su código. Con LakeFS, los usuarios pueden controlar las versiones de los datos a escala de exabytes, lo que la convierte en una solución altamente escalable para gestionar grandes lagos de datos.
Capacidades adicionales:
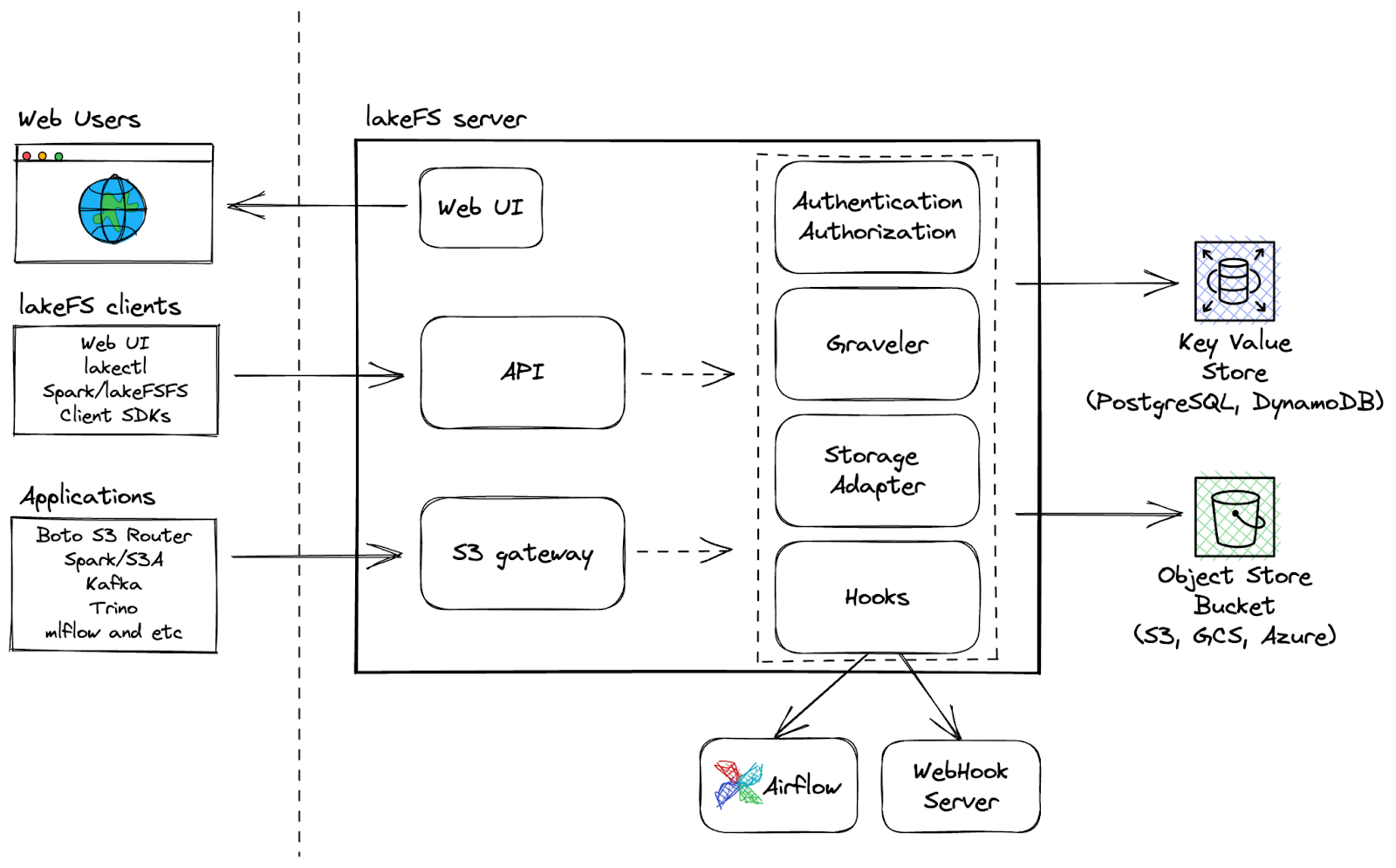
LakeFS Architecture
Los almacenes de características son depósitos centralizados para almacenar, versionar, gestionar y servir características (atributos de datos procesados utilizados para entrenar modelos de aprendizaje automático) para modelos de aprendizaje automático tanto en producción como con fines de entrenamiento.
Feast es un almacén de funciones de código abierto que ayuda a los equipos de aprendizaje automático a producir modelos en tiempo real y a construir una plataforma de funciones que fomente la colaboración entre ingenieros y científicos de datos.
Características principales:
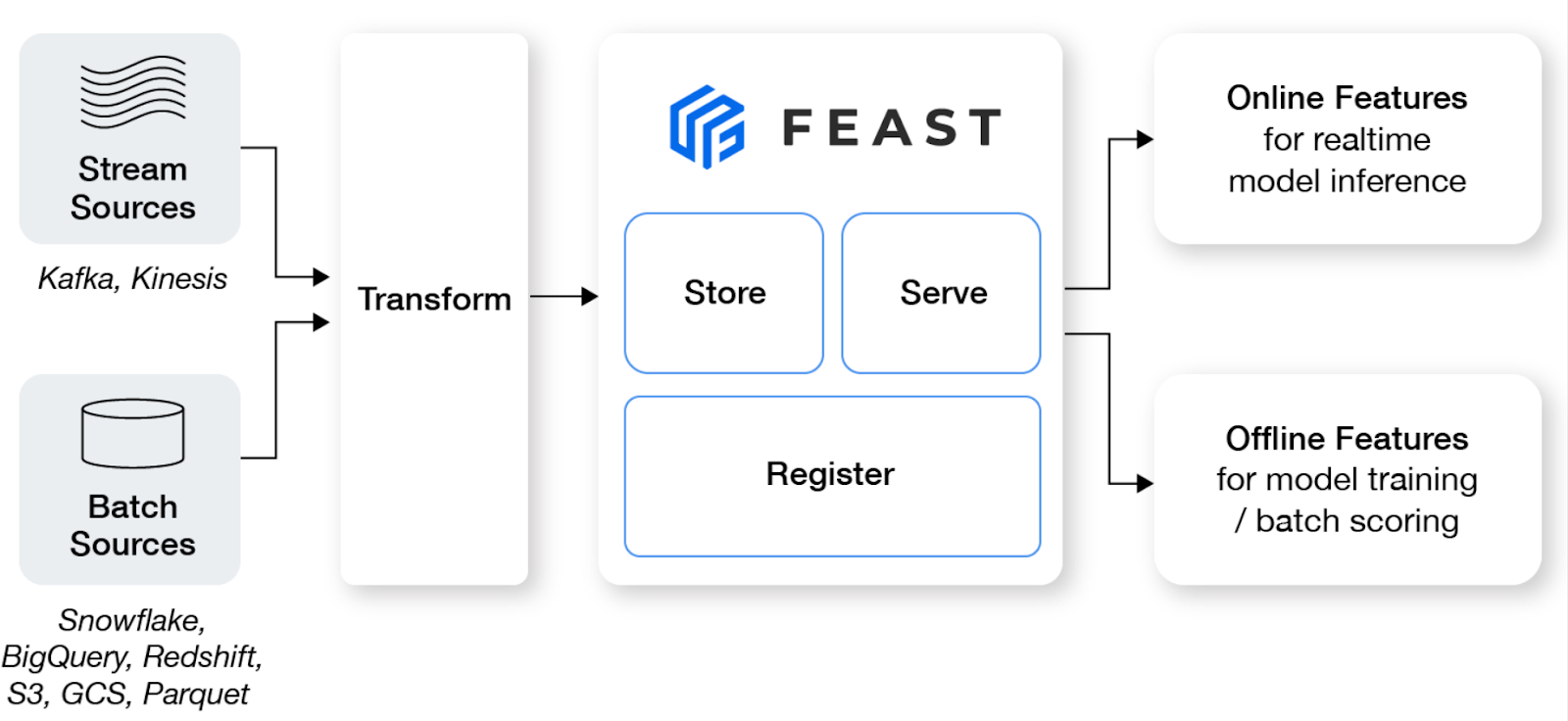
Imagen de Fiesta
Featureform es un almacén virtual de características que permite a los científicos de datos definir, gestionar y servir las características de su modelo ML. Puede ayudar a los equipos de ciencia de datos a mejorar la colaboración, organizar la experimentación, facilitar el despliegue, aumentar la fiabilidad y preservar el cumplimiento.
Características principales:
Imagen de Featureform
Con estas herramientas de MLOps, puedes probar la calidad del modelo y garantizar la fiabilidad, solidez y precisión de los modelos de aprendizaje automático:
Deepchecks es una solución de código abierto que satisface todas tus necesidades de validación de ML, garantizando que tus datos y modelos se comprueban a fondo desde la investigación hasta la producción. Ofrece un enfoque holístico para validar tus datos y modelos a través de sus diversos componentes.
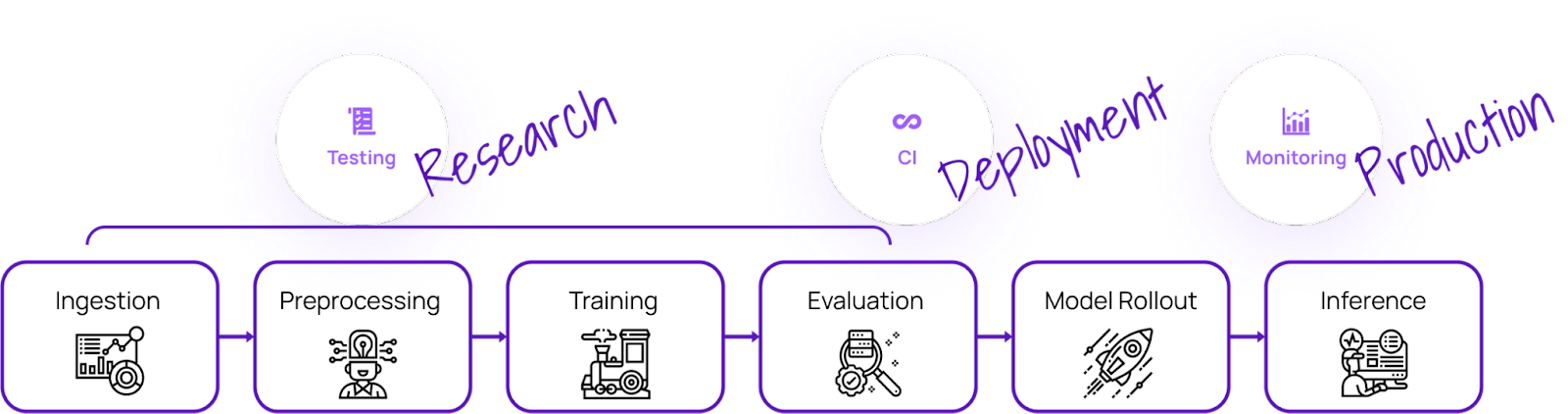
Imagen de Deepchecks
Las comprobaciones profundas constan de tres componentes:
TruEra es una plataforma avanzada diseñada para impulsar la calidad y el rendimiento de los modelos mediante pruebas automatizadas, capacidad de explicación y análisis de las causas raíz. Ofrece varias funciones para ayudar a optimizar y depurar modelos, lograr la mejor explicabilidad de su clase e integrarse fácilmente en tu pila tecnológica de ML.
Características principales:
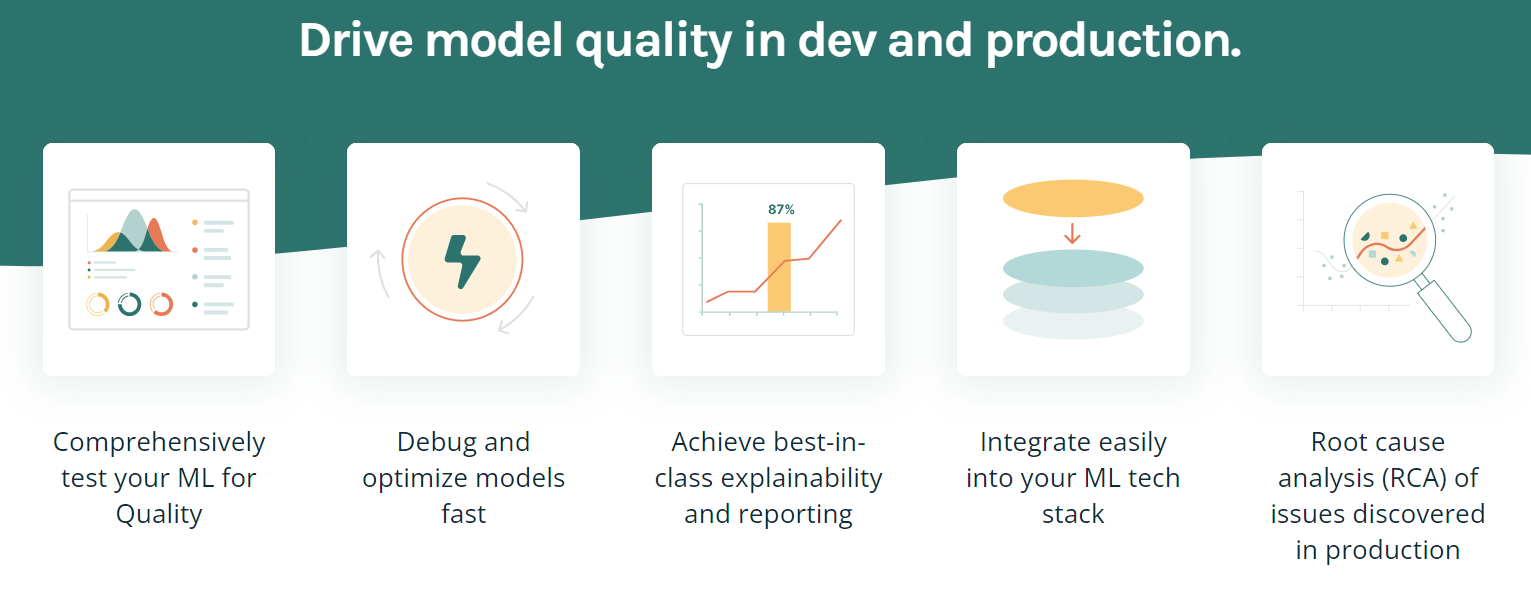
Imagen de TruEra
A la hora de desplegar modelos, estas herramientas MLOps pueden ser de gran ayuda:
Kubeflow hace que el despliegue de modelos de aprendizaje automático en Kubernetes sea sencillo, portátil y escalable. Puedes utilizarlo para preparar datos, entrenar modelos, optimizar modelos, servir predicciones y motorizar el rendimiento del modelo en producción. Puedes desplegar el flujo de trabajo de aprendizaje automático localmente, en las instalaciones o en la nube. En resumen, facilita Kubernetes a los equipos de ciencia de datos.
Características principales:
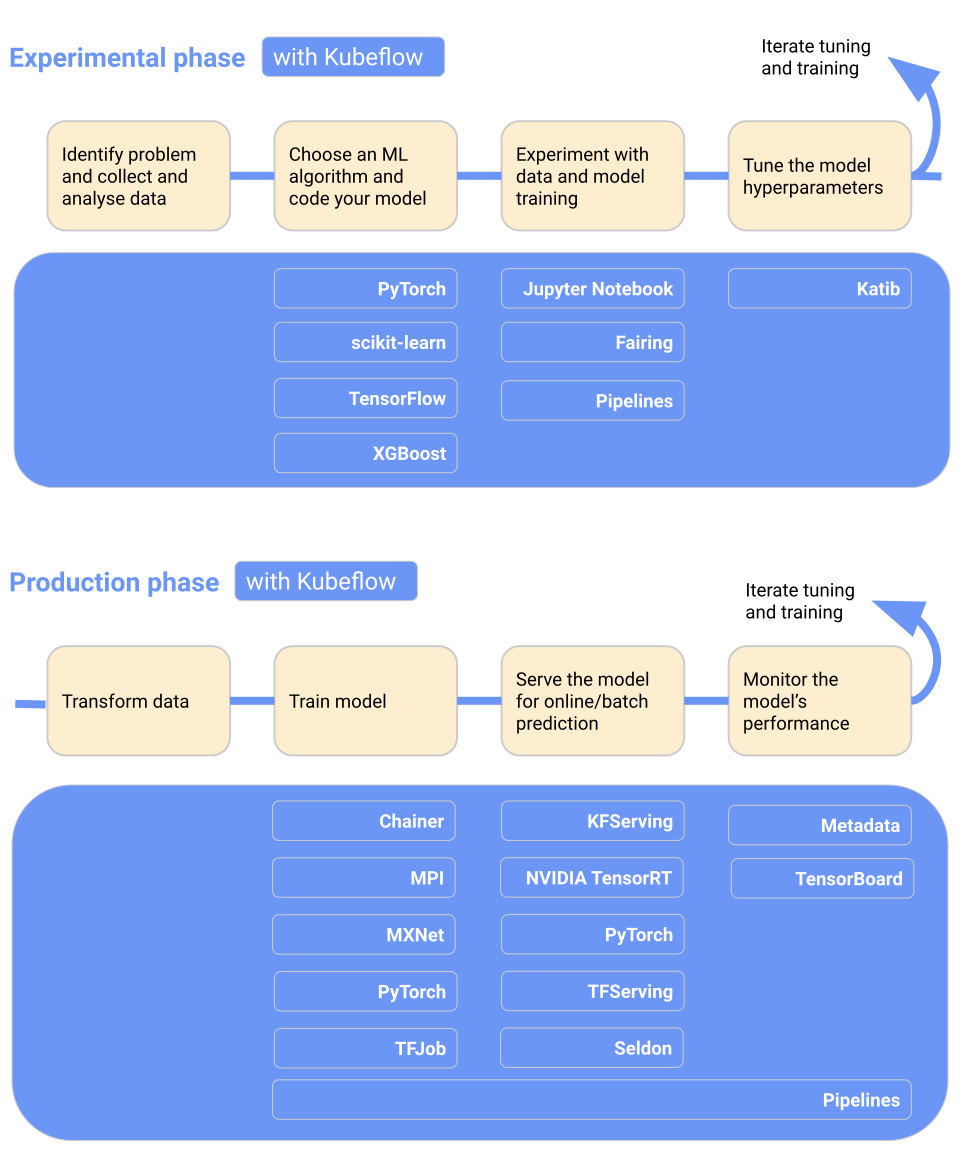
Imagen de Kubeflow
BentoML facilita y agiliza la distribución de aplicaciones de aprendizaje automático. Es una herramienta basada en Python para desplegar y mantener APIs en producción. Se escala con potentes optimizaciones mediante la inferencia paralela y la dosificación adaptativa, y proporciona aceleración por hardware.
El panel de control centralizado e interactivo de BentoML facilita la organización y la supervisión al desplegar modelos de aprendizaje automático. Lo mejor es que funciona con todo tipo de marcos de aprendizaje automático, como Keras, ONNX, LightGBM, Pytorch y Scikit-learn. En resumen, BentoML proporciona una solución completa para el despliegue, el servicio y la supervisión de modelos.
Imagen de BentoML
Hugging Face Inference Endpoints es un servicio basado en la nube ofrecido por Hugging Face, una plataforma de ML todo en uno que permite a los usuarios entrenar, alojar y compartir modelos, conjuntos de datos y demostraciones. Estos puntos finales están diseñados para ayudar a los usuarios a desplegar sus modelos de aprendizaje automático entrenados para la inferencia sin necesidad de configurar y gestionar la infraestructura necesaria.
Características principales:
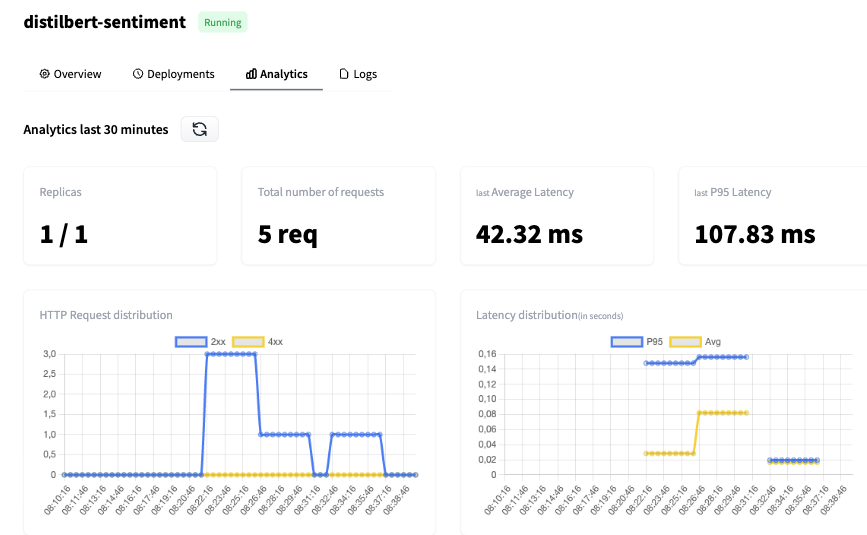
Imagen de Cara de abrazo
Nota: También puedes utilizar MLflow y AWS sagemaker para desplegar y servir modelos.
Tanto si tu modelo ML está en desarrollo, validación o desplegado en producción, estas herramientas pueden ayudarte a controlar una serie de factores:
Evidentemente, AI es una biblioteca Python de código abierto para monitorizar modelos ML durante el desarrollo, la validación y en producción. Comprueba la calidad de los datos y del modelo, la deriva de los datos, la deriva del objetivo y el rendimiento de la regresión y la clasificación.
Evidentemente tiene tres componentes principales:
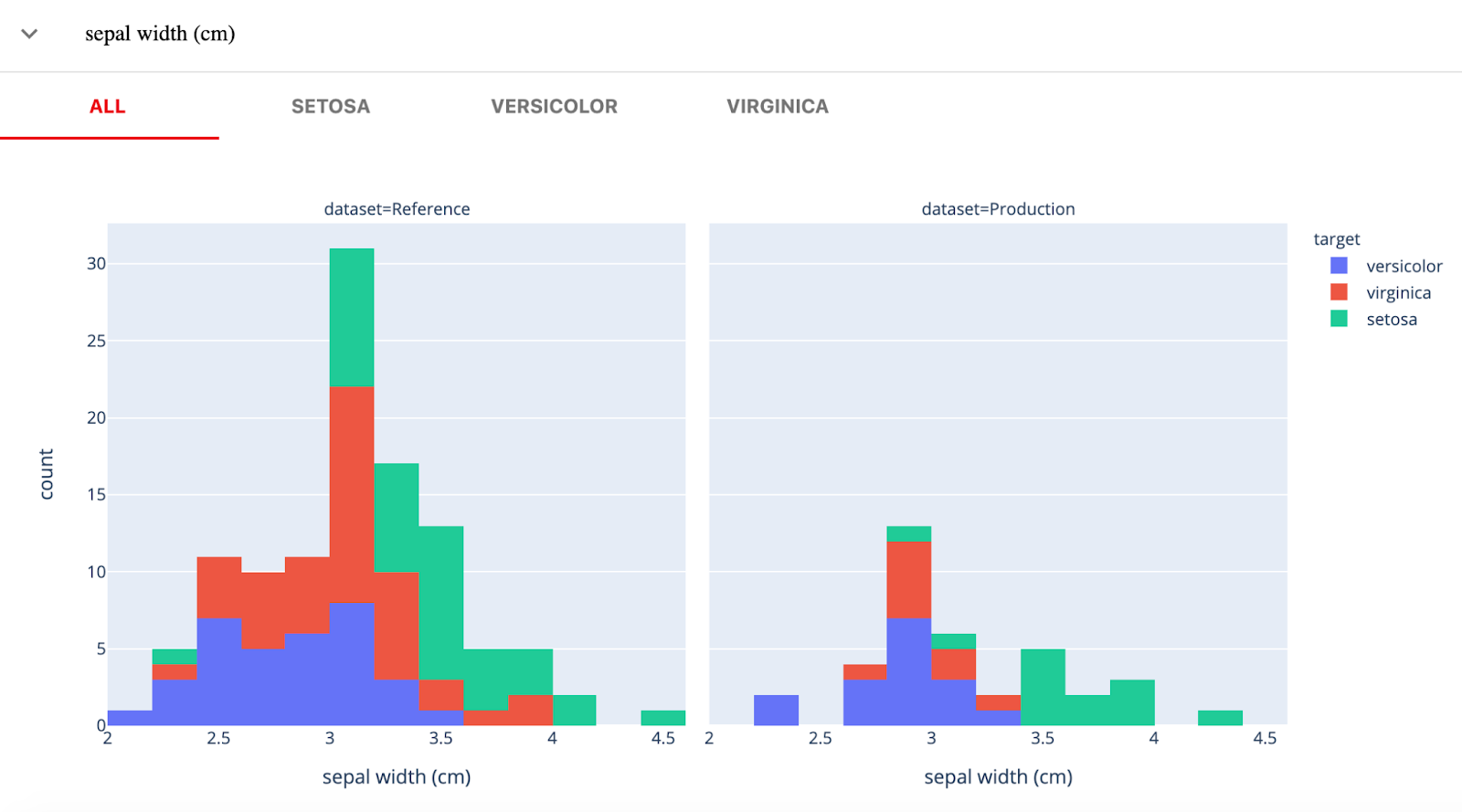
Imagen de Evidentemente
Fiddler AI es una herramienta de monitorización de modelos ML con una interfaz de usuario clara y fácil de usar. Te permite explicar y depurar predicciones, analizar el comportamiento del modo para todo el conjunto de datos, desplegar modelos de aprendizaje automático a escala y supervisar el rendimiento del modelo.
Veamos las principales funciones de la IA de Fiddler para la monitorización ML:
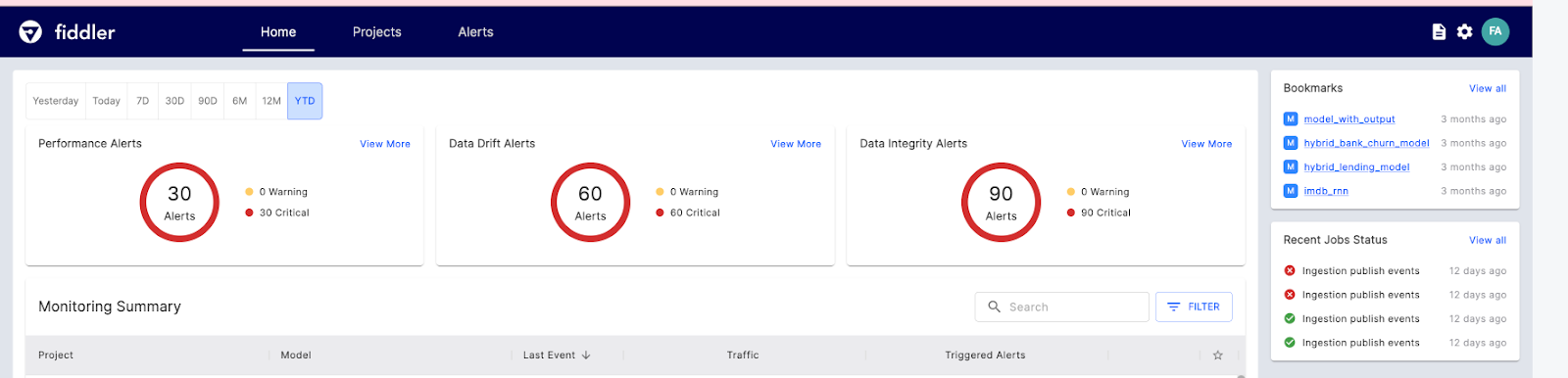
Imagen de El violinista
El motor de ejecución se encarga de cargar el modelo, preprocesar los datos de entrada, ejecutar la inferencia y devolver los resultados a la aplicación cliente.
Ray es un marco versátil diseñado para escalar aplicaciones de IA y Python, facilitando a los desarrolladores la gestión y optimización de sus proyectos de aprendizaje automático.
La plataforma consta de dos componentes principales: un núcleo de tiempo de ejecución distribuido y un conjunto de bibliotecas de IA adaptadas para simplificar la computación ML.
Ray Core ofrece un conjunto limitado de elementos fundamentales que pueden utilizarse para construir y ampliar aplicaciones distribuidas.
Ray también proporciona bibliotecas de IA para conjuntos de datos escalables para ML, formación distribuida, ajuste de hiperparámetros, aprendizaje por refuerzo y servicio escalable y programable.
El siguiente ejemplo muestra el entrenamiento y el servicio de un modelo Clasificador de Impulso Gradiente.
import requests
from starlette.requests import Request
from typing import Dict
from sklearn.datasets import load_iris
from sklearn.ensemble import GradientBoostingClassifier
from ray import serve
# Train model.
iris_dataset = load_iris()
model = GradientBoostingClassifier()
model.fit(iris_dataset["data"], iris_dataset["target"])
@serve.deployment
class BoostingModel:
def __init__(self, model):
self.model = model
self.label_list = iris_dataset["target_names"].tolist()
async def __call__(self, request: Request) -> Dict:
payload = (await request.json())["vector"]
print(f"Received http request with data {payload}")
prediction = self.model.predict([payload])[0]
human_name = self.label_list[prediction]
return {"result": human_name}
# Deploy model.
serve.run(BoostingModel.bind(model), route_prefix="/iris")Nuclio es un potente marco centrado en cargas de trabajo intensivas en datos, E/S y cálculo. Está diseñado para funcionar sin servidor, lo que significa que no tienes que preocuparte de gestionar servidores. Nuclio está bien integrado con herramientas populares de ciencia de datos, como Jupyter y Kubeflow. También admite una amplia variedad de fuentes de datos y streaming y puede ejecutarse en CPU y GPU.
Características principales:
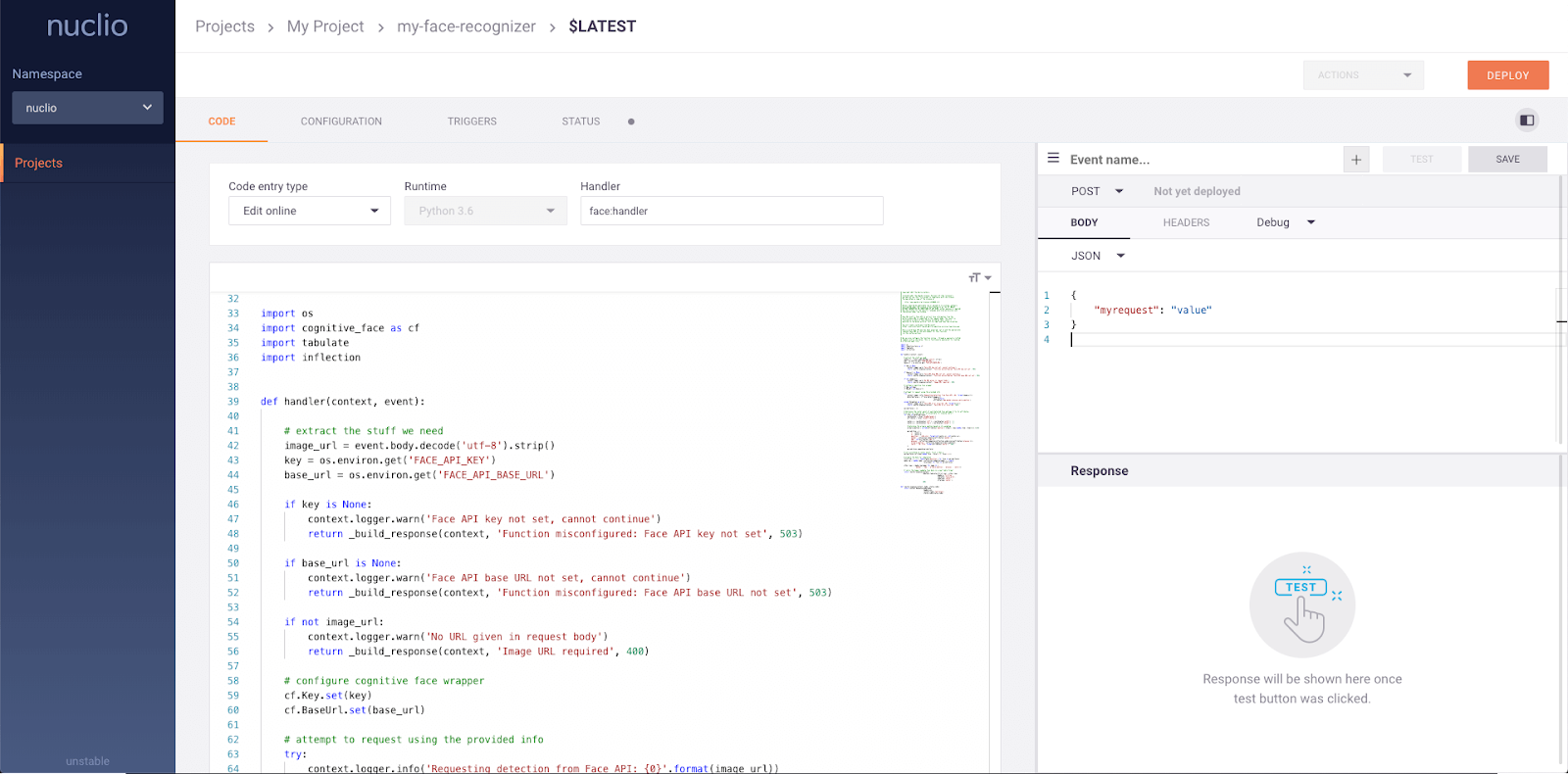
Imagen de Nuclio
Si buscas una herramienta MLOps completa que te ayude durante todo el proceso, aquí tienes algunas de las mejores:
Amazon Web Services SageMaker es una solución integral para MLOps. Puedes entrenar y acelerar el desarrollo de modelos, seguir y versionar experimentos, catalogar artefactos de ML, integrar conductos de CI/CD ML, y desplegar, servir y supervisar modelos en producción sin problemas.
Características principales:
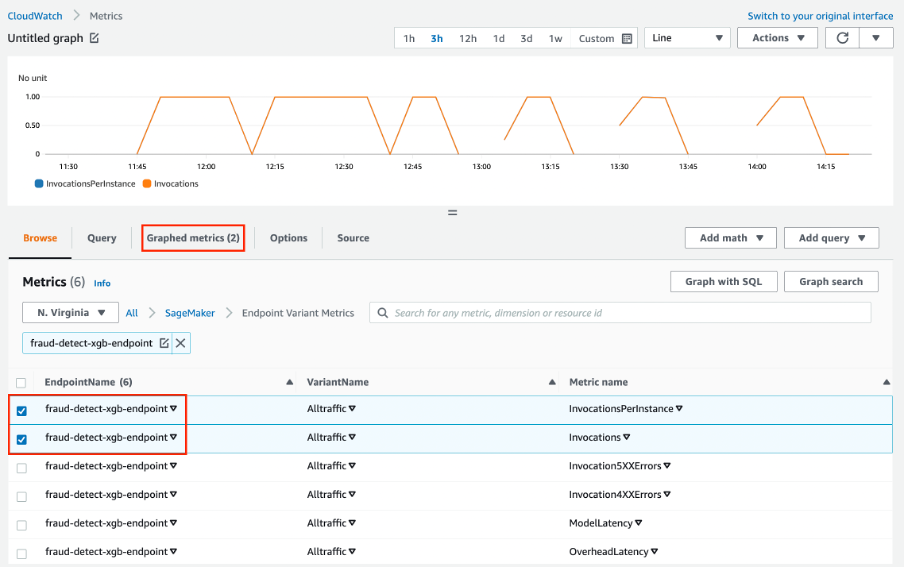
Imagen de Amazon SageMaker
DagsHub es una plataforma hecha para que la comunidad del aprendizaje automático rastree y versione los datos, modelos, experimentos, tuberías de ML y código. Permite a tu equipo construir, revisar y compartir proyectos de aprendizaje automático.
En pocas palabras, es un GitHub para el aprendizaje automático, y dispones de varias herramientas para optimizar el proceso de aprendizaje automático de principio a fin.
Características principales:
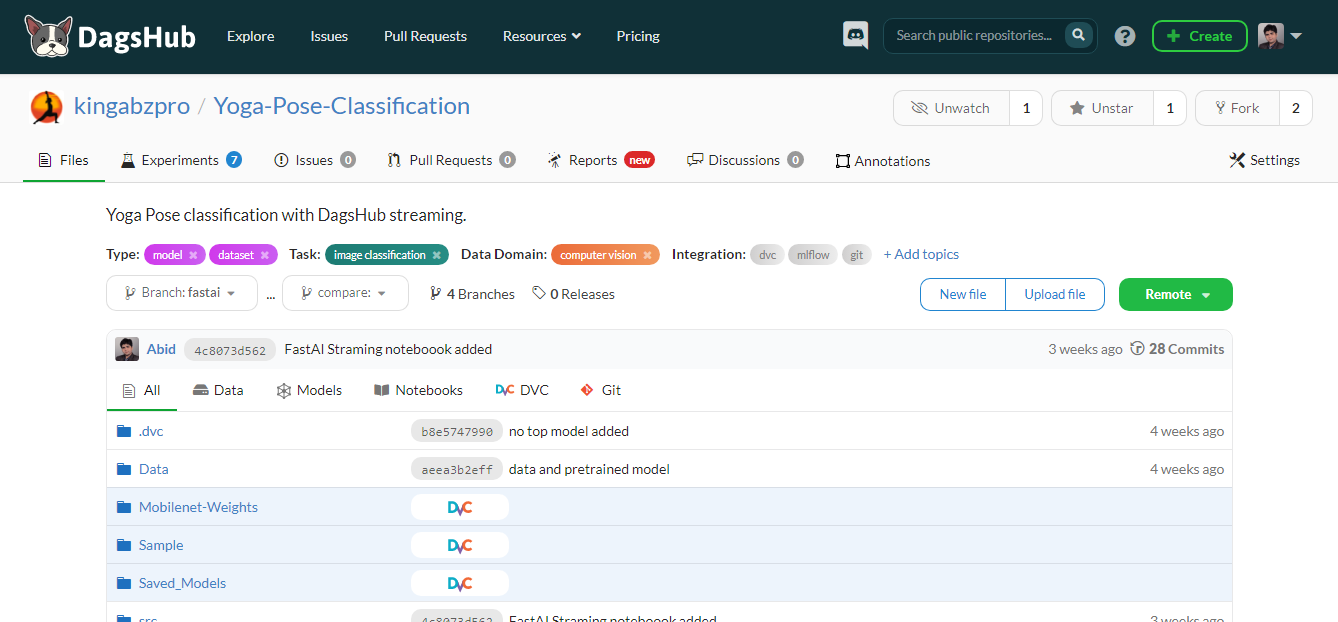
Imagen del autor
La Plataforma MLOps de Iguazio es una plataforma MLOps integral que permite a las organizaciones automatizar el proceso de aprendizaje automático, desde la recopilación y preparación de datos hasta la formación, despliegue y supervisión en producción. Proporciona una plataforma abierta(MLRun) y gestionada.
Un diferenciador clave de la Plataforma MLOps de Iguazio es su flexibilidad en las opciones de despliegue. Los usuarios pueden desplegar aplicaciones de IA en cualquier lugar, incluidos entornos en la nube, híbridos o locales. Esto es especialmente importante para sectores como la sanidad y las finanzas, en los que la privacidad de los datos puede hacer necesaria la implantación local.
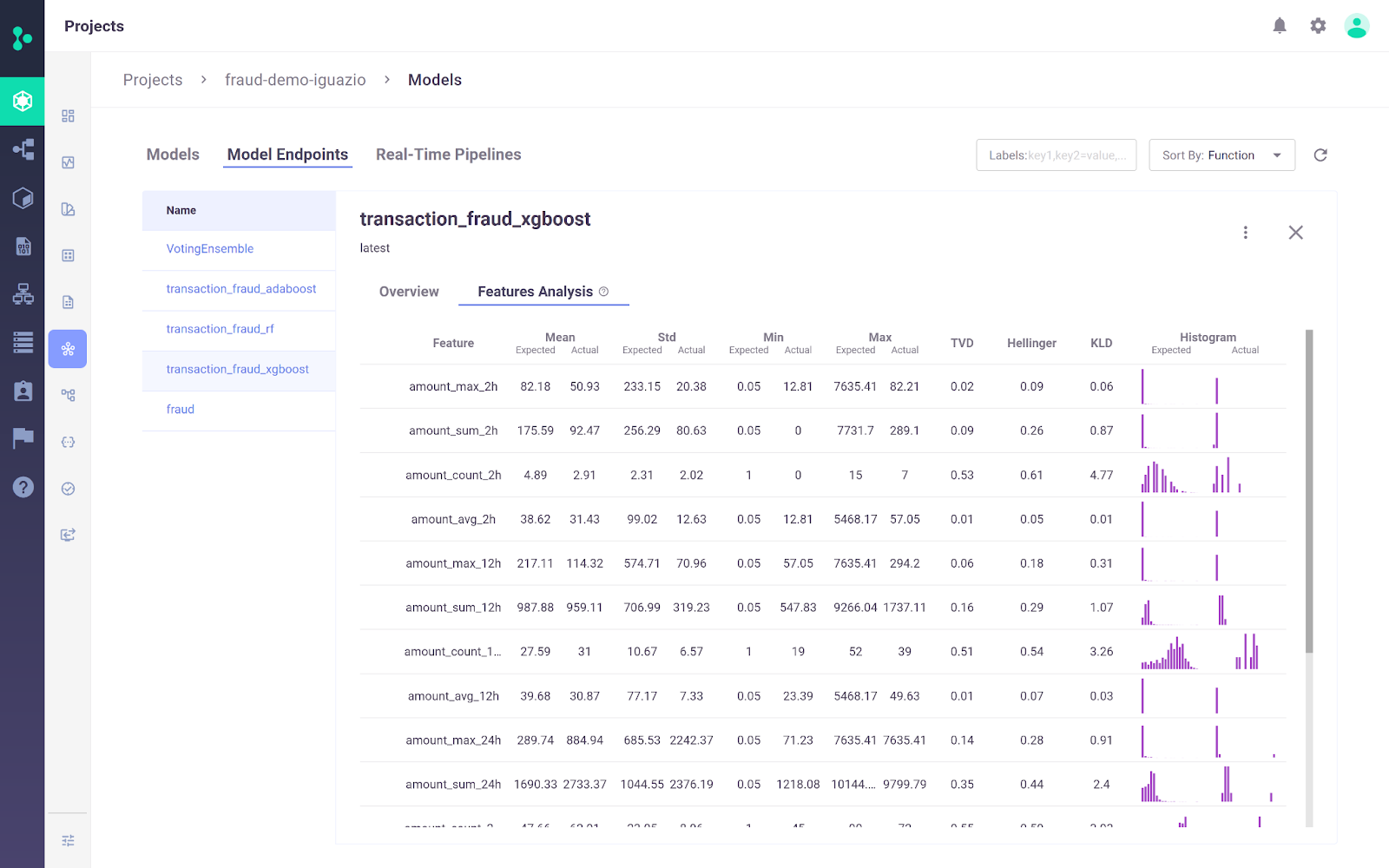
Imagen de la Plataforma MLOps de Iguazio
Características principales:
Aquí tienes una tabla comparativa para que puedas evaluar estas herramientas una al lado de la otra y decidir cuáles son las mejores para tus proyectos:
| Herramienta | Funcionalidad principal | Marcos compatibles | Opciones de despliegue |
|---|---|---|---|
| Qdrant | Búsqueda de similitudes vectoriales y gestión de bases de datos | Python, varios idiomas | Nube nativa, escalable horizontalmente |
| LangChain | Desarrollar aplicaciones con modelos lingüísticos | Python, JavaScript | API REST, plantillas |
| MLFlow | Seguimiento de experimentos, registro de modelos, despliegue | Python, R, Java, API REST | Local, nube |
| Cometa ML | Seguimiento y optimización de experimentos | Scikit-learn, PyTorch, TensorFlow, HuggingFace | Local, nube |
| Pesos y sesgos | Seguimiento de experimentos, versionado de datos y modelos | Fastai, Keras, PyTorch, HuggingFace, Yolov5, Spacy | Local, nube |
| Prefecto | Orquestación y supervisión del flujo de trabajo | Python | Local (Orion UI), Nube |
| Metaflow | Gestión del flujo de trabajo para la ciencia de datos | Scikit-learn, TensorFlow, Python, R | AWS, GCP, Azure, local |
| Kedro | Orquestación del flujo de trabajo, reproducibilidad | Python | Local, distribuido |
| Paquidermo | Transformación, versionado y linaje de datos | Cualquier idioma | Kubernetes |
| DVC | Versionado de datos y canalizaciones | Git, Python | Local, nube |
| LakeFS | Control de versiones tipo Git para lagos de datos | Cualquier servicio de almacenamiento | Local, nube |
| Fiesta | Almacén centralizado de características para modelos ML | Python | Local, nube |
| Featureform | Almacén virtual de características para modelos ML | Python | Local, nube |
| Comprobaciones profundas | Prueba y validación del modelo ML | Python | Local, nube |
| TruEra | Pruebas de calidad y rendimiento del modelo | Python | Local, nube |
| Kubeflow | Despliegue y orquestación de modelos ML | TensorFlow, PyTorch, PaddlePaddle, MXNet, XGboost | Kubernetes, cloud |
| BentoML | Despliegue de modelos y gestión de API | Keras, ONNX, LightGBM, PyTorch, Scikit-learn | Local, nube |
| Cara de abrazo | Inferencia y despliegue del modelo | Cualquier modelo | Nube |
| Evidentemente | Supervisión de los modelos ML para la deriva de datos y objetivos | Python | Local, nube |
| Violinista | Supervisión y depuración de modelos ML | Python | Local, nube |
| Ray | Escalar aplicaciones de IA y Python | Python | Local, nube |
| Nuclio | Marco sin servidor para cargas de trabajo intensivas en datos y cálculo | Jupyter, Kubeflow | Nube, local |
| AWS SageMaker | Gestión integral del ciclo de vida del LD | Python, R, Java, TensorFlow, PyTorch | Nube AWS |
| DagsHub | Versionado y colaboración para proyectos de ML | Git, DVC, MLflow | Local, nube |
| Iguazio | Automatización de extremo a extremo de los procesos de ML | Python, MLRun | Nube, híbrido, local |
Nos encontramos en un momento de auge del sector de las MLOps. Cada semana se ven nuevos desarrollos, nuevas startups y nuevas herramientas que se lanzan para resolver el problema básico de convertir los portátiles en aplicaciones listas para la producción. Incluso las herramientas existentes están ampliando el horizonte e integrando nuevas funciones para convertirse en súper herramientas MLOps.
En este blog, hemos aprendido cuáles son las mejores herramientas de MLOps para los distintos pasos del proceso de MLOps. Estas herramientas te ayudarán durante las fases de experimentación, desarrollo, despliegue y supervisión.
Si eres nuevo en el aprendizaje automático y quieres dominar las habilidades esenciales para conseguir un trabajo como científico de aprendizaje automático, prueba a seguir nuestro itinerario profesional de Científico de Aprendizaje Automático con Python.
Si eres un profesional y quieres saber más sobre las Prácticas MLOps estándar, lee nuestro artículo sobre las Mejores Prácticas MLOps y Cómo Aplicarlas y consulta nuestra pista de habilidades Fundamentos MLOps .
¡Aprende más sobre MLOps con estos cursos!
Curso
Curso
Curso
blog
Matt Crabtree
14 min
blog
Natassha Selvaraj
15 min
blog
Joleen Bothma
12 min
blog
Javier Canales Luna
8 min
blog
Abid Ali Awan
15 min
blog
Javier Canales Luna
8 min