¿Qué es FLAN-T5?
FLAN-T5 es un modelo de lenguaje amplio, secuencia a secuencia y de código abierto que también puede utilizarse comercialmente. El modelo fue publicado por investigadores de Google a finales de 2022, y ha sido puesto a punto en múltiples tareas.
El modelo T5 reformula varias tareas en un formato de texto a texto, como la traducción, la aceptabilidad lingüística, la similitud de frases y el resumen de documentos, como se muestra a continuación:
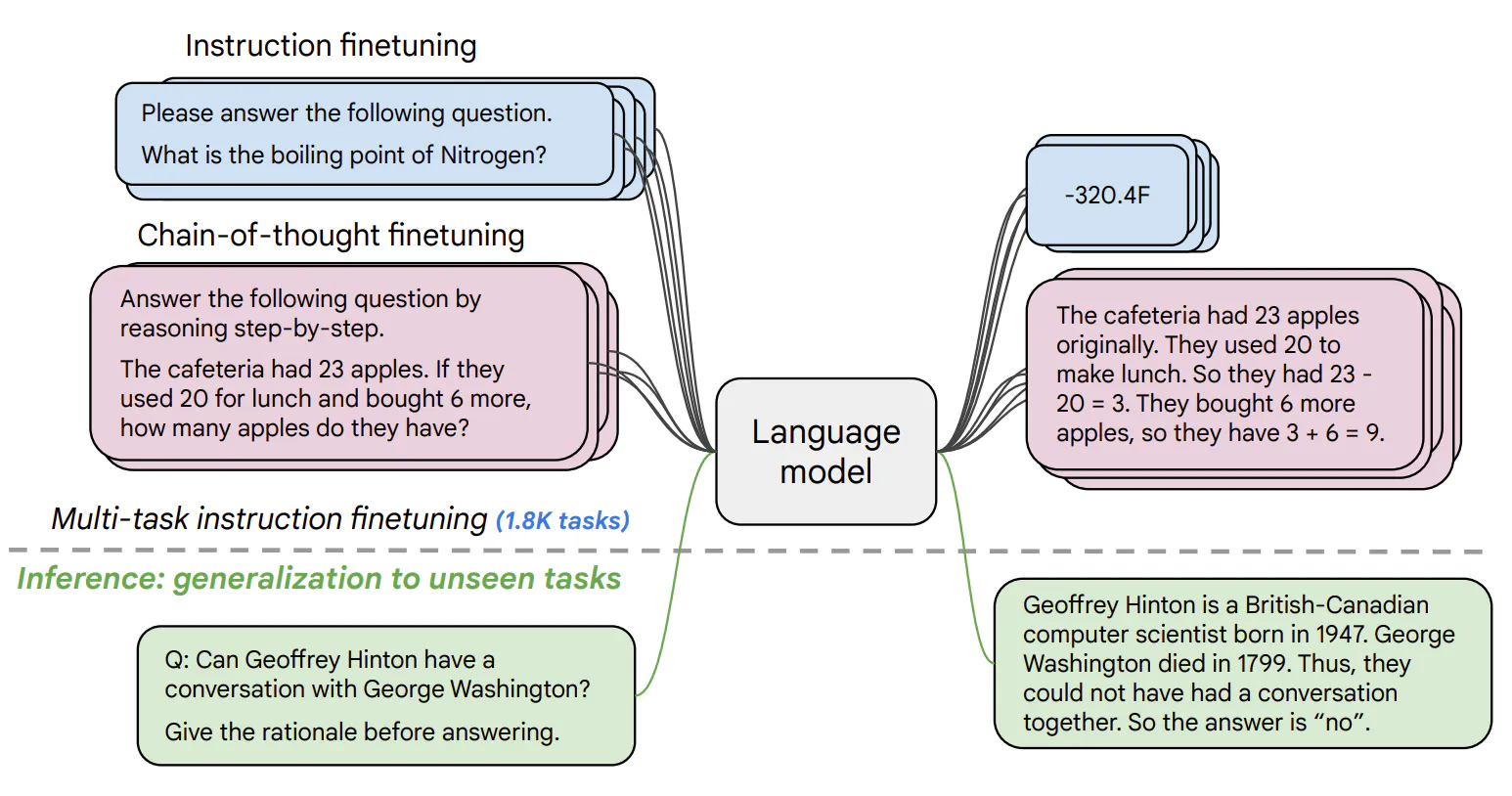
Ejemplos de cómo T5 reformula una serie de tareas en el marco de texto a texto(fuente)
Del mismo modo, la arquitectura del modelo T5 se asemeja mucho a la estructura codificador-decodificador utilizada en el documento original de Transformer. La principal diferencia radica en el tamaño y la naturaleza de los datos de entrenamiento: T5 se entrenó con un extenso corpus de texto de 750 GB conocido como Colossal Clean Crawled Corpus (C4).
En cambio, el Transformer original se diseñó específicamente para la traducción de idiomas y, por tanto, se entrenó con un conjunto de datos formado por 1,4 GB de pares de frases inglés-alemán.
Nuestro artículo An Introduction to Using Transformers and Hugging Face guía al lector en la comprensión de los transformadores y el aprovechamiento de su poder para resolver problemas de la vida real.
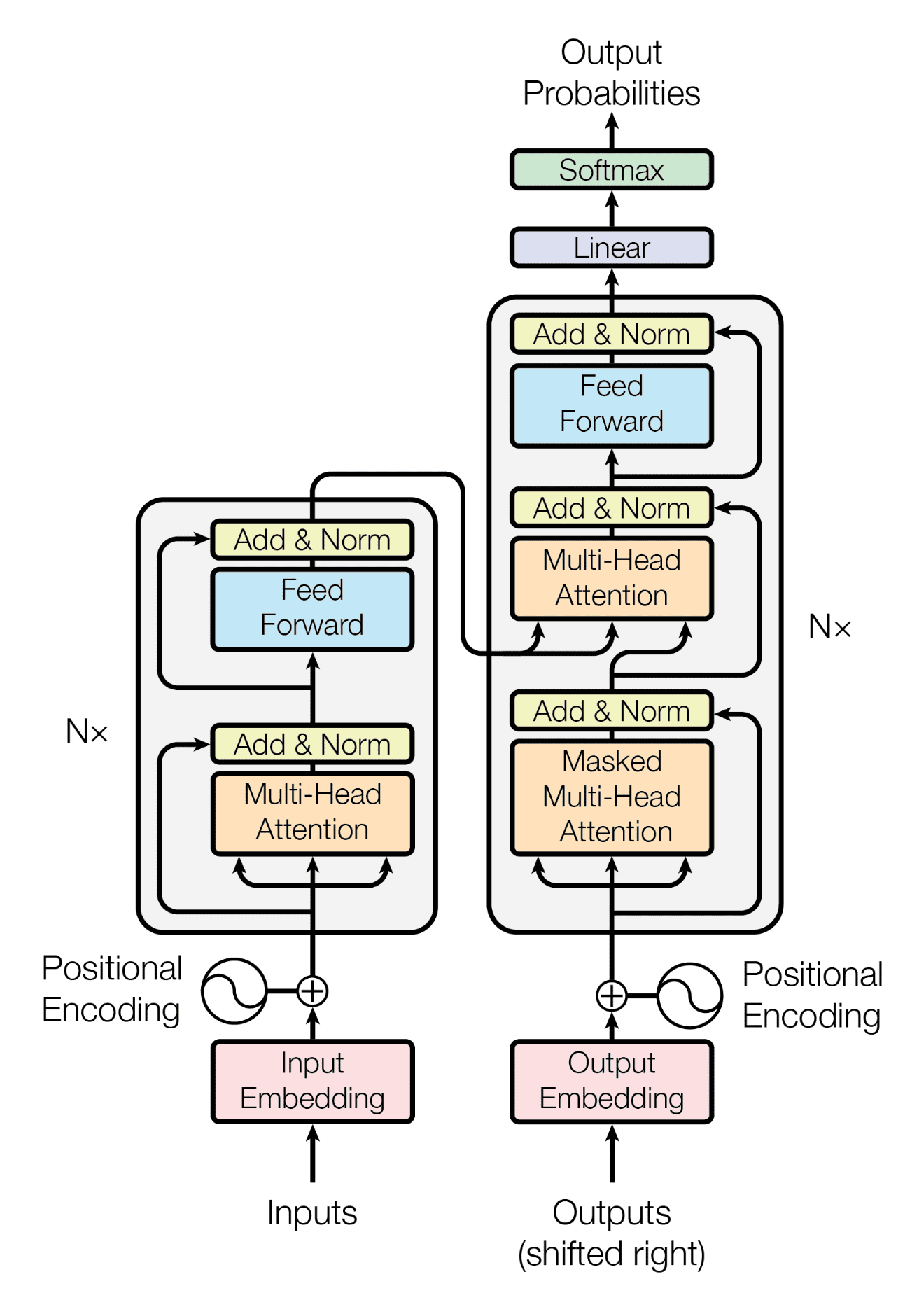
Arquitectura del modelo Transformer(fuente)
¿Qué importancia tiene la puesta a punto de FLAN-T5?
No cabe duda de que FLAN-T5 puede utilizarse para diversas tareas de Procesamiento del Lenguaje Natural.
Sin embargo, para aprovechar todo su potencial y garantizar un rendimiento óptimo para aplicaciones específicas, la puesta a punto es un paso crucial. A continuación se exponen los puntos principales que destacan la importancia de la puesta a punto de FLAN-T5:
- El ajuste de FLAN-T5 es importante para adaptar el modelo a tareas específicas y mejorar su rendimiento en ellas.
- El ajuste fino permite personalizar el modelo para adaptarlo mejor a las necesidades y los datos del usuario.
- La posibilidad de ajustar FLAN-T5 en estaciones de trabajo locales con CPU lo hace accesible a un mayor número de usuarios.
- Esta accesibilidad es beneficiosa para las organizaciones más pequeñas o los investigadores individuales que pueden no tener acceso a los recursos de la GPU.
- En general, el ajuste de FLAN-T5 es un paso valioso para optimizar el modelo para casos de uso específicos y maximizar sus beneficios potenciales.
El objetivo de este tutorial es proporcionar una guía completa para la puesta a punto de FLAN-T5 en un escenario de respuesta de preguntas.
En este tutorial, trataremos una serie de temas que le ayudarán a comprender e implementar el ajuste fino para FLAN-T5. Empezaremos hablando de las bibliotecas y herramientas necesarias para este proceso, seguidas de los pasos para configurar el entorno para el ajuste fino.
A continuación, le guiaremos a través del proceso de carga del modelo FLAN-T5 y la preparación de sus datos para el ajuste fino. Una vez que los datos estén listos, le guiaremos por los pasos necesarios para entrenar y ajustar el modelo a sus necesidades específicas.
Por último, exploraremos algunas aplicaciones potenciales del modelo FLAN-T5 ajustado, demostrando cómo puede utilizarse en diversos escenarios para lograr un mejor rendimiento y resultados más precisos.
Posibles aplicaciones de FLAN-T5 optimizado
Antes de sumergirnos en la implementación técnica, vamos a explorar algunas de las aplicaciones potenciales de FLAN-T5 afinado, y a continuación se presentan algunos ejemplos para el resumen de chats y diálogos, la clasificación de textos y los Recursos de Interoperabilidad Sanitaria Rápida (FHIR).
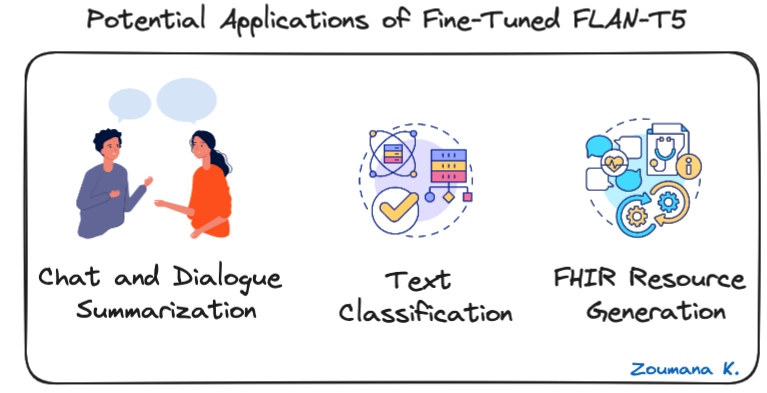
Tres posibles aplicaciones de FLAN-T5 optimizado
- Resumen de conversaciones y diálogos: FLAN-T5 puede condensar conversaciones, proporcionando un rápido resumen de las interacciones del servicio de atención al cliente o de las reuniones de negocios.
- Clasificación de textos: útil para automatizar la categorización de textos en clases predefinidas, como el análisis de sentimientos, la detección de spam o el modelado de temas.
- Generación de recursos FHIR: FLAN-T5 puede convertir texto clínico en FHIR (Fast Healthcare Interoperability Resources) estructurado para facilitar el intercambio y la integración en los sistemas sanitarios.
Antes de profundizar en los aspectos técnicos centrales del artículo, nuestro tutorial, Cómo crear aplicaciones LLM con LangChain, guía al lector para explorar el potencial sin explotar de los grandes modelos lingüísticos con LangChain, un marco Python de código abierto para crear aplicaciones avanzadas de IA.
Requisitos previos
Ahora que tenemos una mejor comprensión de FLAN-T5, vamos a ver cómo ponerlo a punto para un caso de uso de respuesta a preguntas, y el cuaderno completo está disponible en GitHub.
Para empezar, se necesitan las siguientes bibliotecas y herramientas:
- Cara de abrazo: Una plataforma que proporciona acceso al modelo FLAN-T5, facilitando su descarga y uso para su puesta a punto.
- Transformers: Se utiliza para simplificar el proceso de carga del modelo FLAN-T5 preentrenado y proporciona funciones útiles para el ajuste fino.
- Conjuntos de datos: una colección de conjuntos de datos listos para usar, cruciales para obtener datos relevantes para el ajuste.
- Sentencepiece: herramienta de tokenización utilizada principalmente para manejar datos de texto extensos y multilingües.
- Tokenizers: una biblioteca de tokenización para convertir texto a un formato adecuado para el caso de uso.
- Evalúa: Esta biblioteca ofrece una amplia gama de métricas para la evaluación de modelos, lo que garantiza que el modelo ajustado cumpla la norma de rendimiento deseada.
- Puntuación Rouge: métrica específica utilizada para evaluar la calidad del texto generado por grandes modelos lingüísticos.
- NLTK: útil para pasos de preprocesamiento de datos como la tokenización y el stemming.
Instalación de las bibliotecas
La instalación se puede realizar de la siguiente manera, utilizando pip, el gestor de paquetes Python del cuaderno Jupyter.
%%bash
pip install nltk
pip install datasets
pip install transformers[torch]
pip install tokenizers
pip install evaluate
pip install rouge_score
pip install sentencepiece
pip install huggingface_hubEl comando %%bash se utiliza en el cuaderno para ejecutar la celda correspondiente como un script bash en lugar de ejecutar cada comando individualmente.
Importar bibliotecas
Una vez instaladas todas las bibliotecas, podemos importar cada una de ellas de la siguiente manera:
import nltk
import evaluate
import numpy as np
from datasets import load_dataset
from transformers import T5Tokenizer, DataCollatorForSeq2Seq
from transformers import T5ForConditionalGeneration, Seq2SeqTrainingArguments, Seq2SeqTrainerCarga del modelo FLAN-T5
En Hugging Face hay disponibles varios formatos de modelos FLAN-T5, desde modelos pequeños hasta extragrandes, y cuanto más grande es el modelo, más parámetros tiene.
A continuación se muestran los diferentes tamaños de modelo disponibles en la tarjeta de modelo Hugging Face:
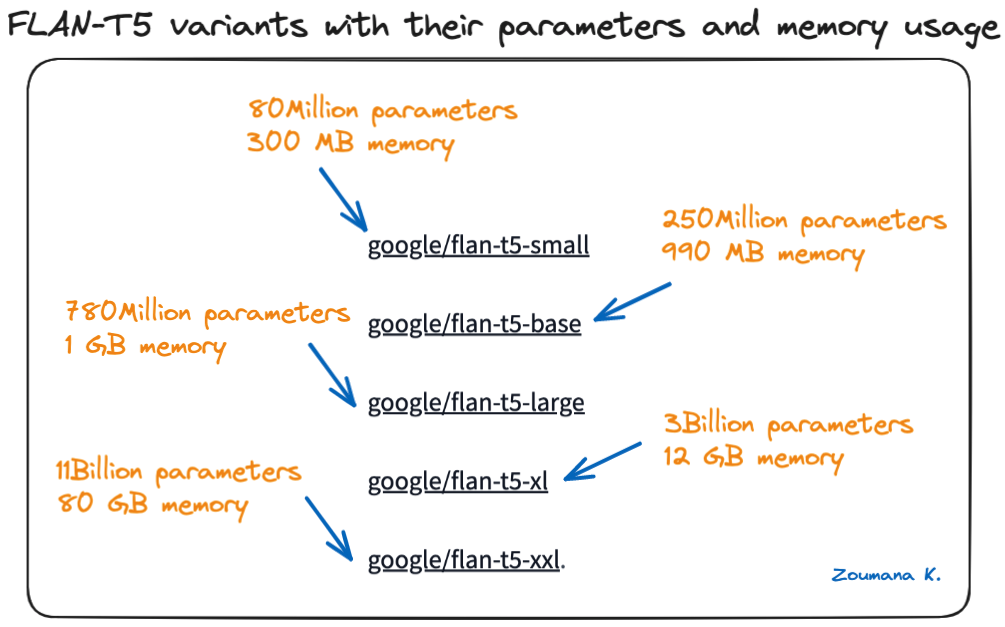
Variantes de FLAN-T5 con sus parámetros y uso de memoria
Elegir bien el tamaño del modelo
La elección del tamaño de modelo adecuado entre las variantes de FLAN-T5 depende en gran medida de los siguientes criterios:
- Los requisitos específicos del proyecto
- Los recursos informáticos disponibles
- El nivel de rendimiento esperado
Para esta experimentación se está utilizando una GPU NVIDIA A100 y el modelo google/flan-t5-base buscará un equilibrio entre la eficiencia computacional y la compatibilidad de rendimiento.
Inicialización del modelo y del tokenizador
Para crear el modelo se necesitan las tres instrucciones siguientes.
# Load the tokenizer, model, and data collator
MODEL_NAME = "google/flan-t5-base"
tokenizer = T5Tokenizer.from_pretrained(MODEL_NAME)
model = T5ForConditionalGeneration.from_pretrained(MODEL_NAME)
data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=model)- El tokenizador se instanciará utilizando el módulo T5Tokenizer y el nombre del modelo
- Utilizando la función from_pretrained de T5ForConditionalGeneration, se carga el modelo
- Con DataCollectorForSeq2Seq, se crea un recopilador de datos que se utilizará para la tarea de respuesta a preguntas
Preparar los datos para el ajuste
Con el modelo, el tokenizador y el recopilador de datos disponibles, el siguiente paso es cargar la experimentación para el ajuste fino, y los datos que se utilizan son los datos de discusión de Yahoo disponibles en Hugging Face.
El proceso de carga de los datos es sencillo y puede realizarse mediante la función load_dataset, que toma como parámetro el nombre del conjunto de datos. En este caso concreto, la atención se centra en los datos de formación.
# Acquire the training data from Hugging Face
DATA_NAME = "yahoo_answers_qa"
yahoo_answers_qa = load_dataset(DATA_NAME)Una vez adquiridos los datos, se dividen en conjuntos de datos de entrenamiento y de prueba, respectivamente, en una proporción del 70% y el 30%, y esto se consigue utilizando la función train_test_split.
yahoo_answers_qa = yahoo_answers_qa["train"].train_test_split(test_size=0.3)El siguiente enunciado muestra el número total de observaciones tanto en los datos de entrenamiento como en los de prueba.
# Check the length of the data and its structure
yahoo_answers_qa
Número total de observaciones para los conjuntos de datos de entrenamiento y validación
Formateo de datos y tokenización
Disponemos de una cantidad significativa de datos, tanto de entrenamiento como de prueba, para el proceso de ajuste. Pero antes tenemos que procesar los datos para que se ajusten al formato de ajuste.
La mayoría de las funciones utilizadas para el siguiente paso se inspiran en el artículo de Toughdata.
Durante el modo de inferencia, el proceso de llamada al modelo tendrá este formato:
"Por favor, responda a esta pregunta: <USER_QUESTION>"
Donde <USER_QUESTION> es la pregunta sobre la que el usuario desea una respuesta. Para lograr esa funcionalidad, necesitamos formatear los datos de entrenamiento anteponiendo a la tarea la cadena "Por favor, responda a esta pregunta", y esto se hace con la función preprocess_function que se muestra a continuación.
Además del formateo, la función también aplica la tokenización de las entradas y salidas utilizando la función tokenizer.
# We prefix our tasks with "answer the question"
prefix = "Please answer this question: "
# Define the preprocessing function
def preprocess_function(examples):
"""Add prefix to the sentences, tokenize the text, and set the labels"""
# The "inputs" are the tokenized answer:
inputs = [prefix + doc for doc in examples["question"]]
model_inputs = tokenizer(inputs, max_length=128, truncation=True)
# The "labels" are the tokenized outputs:
labels = tokenizer(text_target=examples["answer"],
max_length=512,
truncation=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputsA continuación, la función se aplica a todo el conjunto de datos mediante la función map que figura a continuación:
# Map the preprocessing function across our dataset
tokenized_dataset = yahoo_answers_qa.map(preprocess_function, batched=True)Formación y puesta a punto de FLAN-T5
Antes de sumergirse en el proceso de formación, es mejor identificar las métricas para evaluar el rendimiento general del ajuste.
Unas buenas métricas de evaluación son importantes en cualquier proyecto de aprendizaje profundo y aprendizaje automático para evaluar el rendimiento de los modelos, no solo durante el entrenamiento, sino también posteriormente en producción.
Dos de las métricas más comunes para evaluar el rendimiento de un modelo de generación de texto son BLEU y ROUGE, y en este caso, para evaluar la calidad de una respuesta comparándola con una respuesta de referencia.
Este tutorial se centra en ROUGE, pero este artículo de wikipedia proporciona más información sobre la puntuación BLEU.
¿Qué es la puntuación ROUGE?
ROUGE son las siglas de Recall-Oriented Understudy for Gisting Evaluation. Algunos componentes clave de ROUGE para responder preguntas son:
- ROUGE-L: Mide la subsecuencia común más larga entre las respuestas del candidato y de referencia. Se centra en el recuerdo del texto completo.
- ROUGE-1, ROUGE-2, ROUGE-SU4: Compare los solapamientos de unigramas, bigramas y 4gramas entre el candidato y la referencia. Centrarse en el recuerdo de partes o fragmentos clave
- Las puntuaciones ROUGE más altas suelen indicar un mejor rendimiento a la hora de responder a las preguntas. Las puntuaciones cercanas o superiores a 0,70 se consideran altas.
- Cuando se utiliza esta métrica, tratamientos como el stemming y la eliminación de stopwords pueden ayudar a mejorar el rendimiento global.
Entendiendo esto, la siguiente función de ayuda compute_metrics puede ayudar a calcular la puntuación ROUGE subyacente. Antes de implementar la función, es necesario configurar ROUGE y NLTK.
nltk.download("punkt", quiet=True)
metric = evaluate.load("rouge")A continuación se muestra la implementación de la función.
def compute_metrics(eval_preds):
preds, labels = eval_preds
# decode preds and labels
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# rougeLSum expects newline after each sentence
decoded_preds = ["\n".join(nltk.sent_tokenize(pred.strip())) for pred in decoded_preds]
decoded_labels = ["\n".join(nltk.sent_tokenize(label.strip())) for label in decoded_labels]
result = metric.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True)
return resultProceso de formación
Para activar el ajuste fino, necesitamos establecer algunos hiperparámetros, los principales de los cuales se indican a continuación:
- Tasa de aprendizaje: para controlar la rapidez con la que el modelo aprende de los datos y los valores típicos son de 1e-5 a 5e-5, y para este caso de uso, el valor se establece en 3e-4.
- Tamaño del lote: número total de muestras procesadas antes de la actualización de los pesos del modelo. Utilizar lotes más grandes puede acelerar el proceso, pero el inconveniente es que puede dar lugar a un rendimiento deficiente. Utilizamos 8 para este caso
- Tamaño de lote de tren por dispositivo: es similar al tamaño de lote, pero se especifica por cada dispositivo (GPU).
- Decaimiento del peso: el objetivo es evitar que el modelo se ajuste en exceso. 0,01 es un valor aceptable para el tamaño del peso
- Guardar límite total: es el número total de puntos de control que se guardarán durante el entrenamiento. Cuantos más saves haya, más posibilidades hay de retroceder, pero utiliza más disco. En este caso, realizaremos 3 guardados
- Número de épocas: número total de pasadas por el conjunto de datos de entrenamiento. Cuantas más épocas, mayor será el tiempo de entrenamiento, pero también podría mejorar el rendimiento del modelo. Normalmente, se elige un valor de 3 a 10, y para este caso de uso se utiliza 3.
A continuación se definen los parámetros anteriores, que se utilizan para configurar los argumentos de entrenamiento del modelo, y los artefactos de entrenamiento globales se guardan en la carpeta results :
# Global Parameters
L_RATE = 3e-4
BATCH_SIZE = 8
PER_DEVICE_EVAL_BATCH = 4
WEIGHT_DECAY = 0.01
SAVE_TOTAL_LIM = 3
NUM_EPOCHS = 3
# Set up training arguments
training_args = Seq2SeqTrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=L_RATE,
per_device_train_batch_size=BATCH_SIZE,
per_device_eval_batch_size=PER_DEVICE_EVAL_BATCH,
weight_decay=WEIGHT_DECAY,
save_total_limit=SAVE_TOTAL_LIM,
num_train_epochs=NUM_EPOCHS,
predict_with_generate=True,
push_to_hub=False
)A continuación, se configura el entrenador para activar el proceso de entrenamiento del modelo.
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["test"],
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics
)Por último, el entrenamiento del modelo se activa mediante la función train de la siguiente manera:
trainer.train()Tras casi cuatro horas, a continuación se muestra el rendimiento global del proceso de entrenamiento para cada época.

Épocas de entrenamiento y resultados correspondientes
Entendamos el tablero de indicadores de rendimiento anterior.
- Pérdida de formación y pérdida de validación: Los valores más bajos de estas métricas son preferibles, ya que indican un mejor ajuste del modelo a los datos. La pérdida de entrenamiento y validación ha disminuido a lo largo de las épocas, registrándose los valores más bajos en la época 3.
- Métricas Rouge (Rouge1, Rouge2, Rougel y Rougelsum): Los valores más altos de estas métricas son preferibles, ya que indican un mejor rendimiento en el resumen de textos. En las cuatro métricas Rouge, los valores han aumentado a lo largo de las épocas, registrándose los valores más altos en la época 3.
En general, el modelo funcionó bien durante la tercera época, ya que muestra la pérdida de entrenamiento y la pérdida de validación más bajas, junto con los valores más altos en todas las métricas ROUGE. A continuación se muestra el contenido de la carpeta de resultados con todos los puntos de control:

Contenido de la carpeta "resultados
Inferencia de modelos
Ahora que el modelo se ha puesto a punto, ¿no estaría bien aplicarlo a un escenario de la vida real?
En eso consiste la inferencia del modelo. Utilizar un modelo existente para resolver un problema del mundo real, y esto es lo que se está utilizando con el modelo afinado.
Antes de eso, tenemos que realizar algunos pasos:
- Cargar el modelo ajustado para el último punto de control
last_checkpoint = "./results/checkpoint-22500"
finetuned_model = T5ForConditionalGeneration.from_pretrained(last_checkpoint)
tokenizer = T5Tokenizer.from_pretrained(last_checkpoint)- Definir una pregunta concreta a la que responder
my_question = "What do you think about the benefit of Artificial Intelligence?"
inputs = "Please answer to this question: " + my_question- Ejecutar la predicción
inputs = tokenizer(inputs, return_tensors="pt")
outputs = finetuned_model.generate(**inputs)
answer = tokenizer.decode(outputs[0])
from textwrap import fill
print(fill(res, width=80))A continuación se muestra el resultado del modelo afinado, y tiene muy buena pinta. Y el método fill de textwrap se utiliza para limitar el número máximo de caracteres a 80 por línea, en lugar de tener toda la cadena en una sola línea.

Modelo de respuesta afinada a la pregunta
Conclusión y próximos pasos
Este artículo ha proporcionado una guía completa para la puesta a punto de un modelo FLAN-T5. En primer lugar, introduce al lector en una mejor comprensión del modelo y sus posibles casos de uso, antes de recorrer la implementación técnica general, desde la carga de los datos de experimentación y el modelo de cara abrazada hasta el entrenamiento del modelo en una GPU. El mejor modelo, según las puntuaciones ROUGE, se prueba en un escenario real
¿Qué hacer a partir de ahora?
Nuestros artículos 12 GPT-4 Open-Source Alternatives, y How to Train a LLM with PyTorch podrían ser un gran paso siguiente para fines de actualización. El primero destaca las alternativas de código abierto GPT-4 que pueden ofrecer un rendimiento similar y requieren menos recursos computacionales para ejecutarse. Estos proyectos vienen con instrucciones, fuentes de código, pesos del modelo, conjuntos de datos e interfaz de usuario del chatbot.
El segundo artículo ayuda al lector a dominar el proceso de entrenamiento de grandes modelos lingüísticos utilizando PyTorch, desde la configuración inicial hasta la implementación final. También puede eMejorar sus habilidades con el potente marco de aprendizaje profundo utilizado por los profesionales de la IA. Únase hoy mismo al curso Deep Learning with PyTorch.



