Curso
Introducción a Python
4 h
6.9M
El algoritmo de coincidencia difusa de cadenas busca determinar el grado de similitud entre dos cadenas diferentes. Esto se descubre utilizando una métrica de distancia conocida como «distancia de edición». La distancia de edición determina cuán cercanas son dos cadenas al encontrar el número mínimo de «ediciones» necesarias para transformar una cadena en otra.
Si la distancia de edición cuenta el número de operaciones de edición para indicarnos cuántas operaciones separan una cadena de otra, una edición es una operación realizada sobre una cadena para transformarla en otra cadena.
Hay cuatro tipos principales de ediciones:
| Editar operación | Descripción | Ejemplo |
|---|---|---|
| Insertar | Añadir una carta | «Londn» -> «Londres» |
| Eliminar | Eliminar una letra | «Londoon» -> «Londres» |
| Cambiar | Intercambia dos letras adyacentes. | «Lnodon» -> «Londres» |
| Reemplazar | Cambiar una letra por otra | «Londin» -> «Londres» |
Estas cuatro operaciones de edición permiten modificar cualquier cadena.
Al combinar las operaciones de edición, puedes descubrir la lista de cadenas posibles que están a N ediciones de distancia, donde N es el número de operaciones de edición. Por ejemplo, la distancia de edición entre «London» y «Londin» es uno, ya que sustituir la «i» por una «o» da como resultado una coincidencia exacta.
Pero, ¿cómo se calcula exactamente la distancia de edición?, te preguntarás.
Existen diferentes variaciones sobre cómo calcular la distancia de edición. Por ejemplo, existe la distancia de Levenshtein, la distancia de Hamming, la distancia de Jaro y otras.
En este tutorial, solo nos ocuparemos de la distancia de Levenshtein.
Es una métrica que lleva el nombre de Vladimir Levenshtein, quien la concibió originalmente en 1965 para medir la diferencia entre dos secuencias de palabras. Podemos utilizarlo para descubrir el número mínimo de ediciones que necesitas realizar para cambiar una secuencia de una palabra por otra.
Aquí está el cálculo formal:
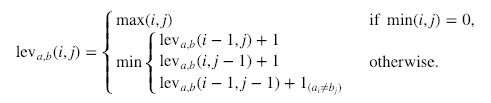
Donde 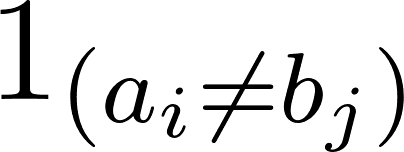 indica 0 cuando a=by 1 en caso contrario.
indica 0 cuando a=by 1 en caso contrario.
Es importante señalar que las filas del mínimo anterior corresponden a una eliminación, una inserción y una sustitución, en ese orden.
También es posible calcular el índice de similitud de Levenshtein basándose en la distancia de Levenshtein. Esto se puede hacer utilizando la siguiente fórmula:
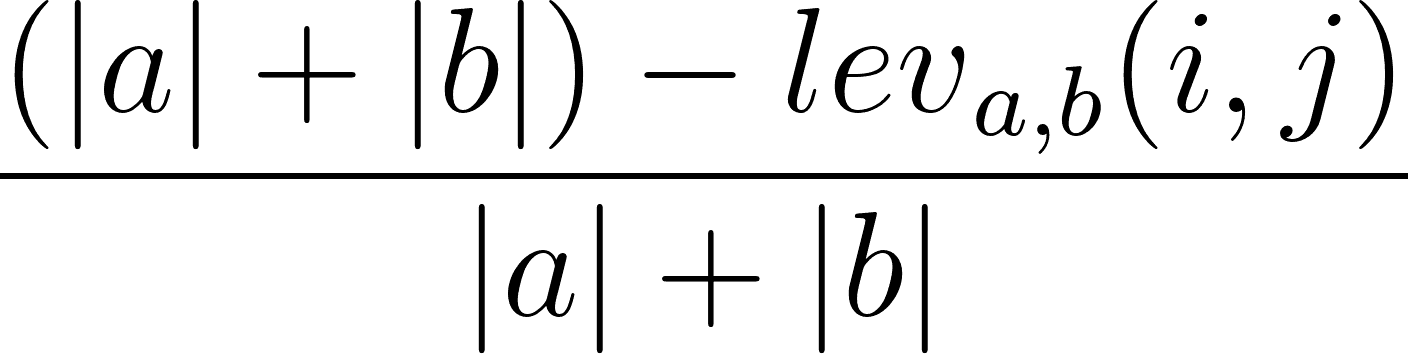
donde|a| y|b| son las longitudes de la secuencia a y la secuenciab, respectivamente.
Uno de los paquetes más populares para la coincidencia difusa de cadenas en Python era, históricamente, FuzzyWuzzy. Sin embargo, para resolver problemas relacionados con las licencias y actualizar el código base, el proyecto pasó a llamarse en 2021 TheFuzz. Sigue siendo una biblioteca muy utilizada por los principiantes debido a su simplicidad y es la biblioteca que utilizaremos en este tutorial.
Fue desarrollado originalmente por SeatGeek para distinguir si dos anuncios de entradas con nombres similares correspondían al mismo evento. Al igual que su predecesor, TheFuzz utiliza la distancia de edición de Levenshtein para calcular el grado de similitud entre dos cadenas.
Consejo profesional: Para la producción, utiliza RapidFuzz. Aunque TheFuzz es excelente para el aprendizaje y los conjuntos de datos más pequeños, puede resultar lento para el procesamiento de datos a gran escala. La industria ha avanzado en gran medida hacia una nueva biblioteca llamada RapidFuzz.
fuzz.ratio), por lo que puedes cambiar fácilmente más adelante.Para esta guía, utilizaremos TheFuzz, ya que viene preinstalado en muchos entornos y es perfecto para comprender los conceptos básicos.
Primero, debemos instalar el paquet TheFuzz. Puedes hacerlo con pip utilizando el siguiente comando:
!pip install thefuzzNota: Esta biblioteca viene preinstalada en el cuaderno de trabajo de DataLab.
Ahora, echemos un vistazo a algunas de las cosas que podemos hacer con thefuzz.
Sigue el código de este cuaderno de trabajo de DataLab.
Podemos determinar la relación simple entre dos cadenas utilizando el método ratio() en el objeto fuzz. Esto simplemente calcula la distancia de edición basándose en el orden de ambas cadenas de entrada difflib.ratio(). Para obtener más información, consulta la documentación de difflib.
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Similarity score: {fuzz.ratio(name, full_name)}")
"""
Similarity Score: 86
"""En el código, utilizamos dos variaciones de mi nombre para comparar la puntuación de similitud, que fue de 86.
Comparémoslo con la razón parcial.
Para comprobar la proporción parcial, todo lo que debemos hacer con el código anterior es llamar a partial_ratio() en nuestro objeto fuzz en lugar de ratio().
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Similarity score: {fuzz.partial_ratio(name, full_name)}")
"""
Similarity Score: 67
"""Observamos una disminución. ¿Qué está pasando?
Bueno, la función « partial_ratio() » busca determinar en qué medida dos cadenas son parcialmente similares. Dos cadenas son parcialmente similares si tienen algunas de las palabras en un orden común.
El algoritmo de búsqueda de coincidencias de cadenas ( partial_ratio() ) calcula la similitud tomando la cadena más corta, que en este caso se almacena en la variable name, y luego la compara con las subcadenas de la misma longitud en la cadena más larga, que se almacena en full_name.
Dado que el orden importa en proporción parcial, nuestra puntuación bajó en este caso. Por lo tanto, para obtener una coincidencia del 100 %, tendrías que mover la parte «K D» (que significa mi segundo nombre) al final de la cadena. Por ejemplo:
# Order matters with partial ratio
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis Pykes K D"
print(f"Partial ratio similarity score: {fuzz.partial_ratio(name, full_name)}")
# But order will not effect simple ratio if strings do not match
print(f"Simple ratio similarity score: {fuzz.ratio(name, full_name)}")
"""
Partial ratio similarity score: 100
Simple ratio similarity score: 86
"""¿Qué pasa si queremos que nuestro comparador de cadenas difusas ignore el orden?
Entonces es posible que quieras utilizar la «proporción de clasificación de tokens».
Bien, queremos ignorar el orden de las palabras en las cadenas, pero seguir determinando su grado de similitud. La clasificación por tokens te ayuda precisamente a hacer eso. La clasificación por tokens no tiene en cuenta el orden en que aparecen las palabras. Tiene en cuenta cadenas similares que no están en orden, tal y como se ha indicado anteriormente.
Por lo tanto, deberíamos obtener una puntuación del 100 % utilizando la proporción de clasificación de tokens con el ejemplo más reciente:
# Check the similarity score
full_name = "Kurtis K D Pykes"
full_name_reordered = "Kurtis Pykes K D"
# Order does not matter for token sort ratio
print(f"Token sort ratio similarity score: {fuzz.token_sort_ratio(full_name_reordered, full_name)}")
# Order matters for partial ratio
print(f"Partial ratio similarity score: {fuzz.partial_ratio(full_name, full_name_reordered)}")
# Order will not effect simple ratio if strings do not match
print(f"Simple ratio similarity score: {fuzz.ratio(name, full_name)}")
"""
Token sort ratio similarity score: 100
Partial ratio similarity score: 75
Simple ratio similarity score: 86
"""... y, como era de esperar, lo hicimos.
Volvamos a las variables original_name y full_name. ¿Qué crees que pasará si utilizamos ahora la clasificación por tokens?
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Token sort ratio similarity score: {fuzz.token_sort_ratio(name, full_name)}")
"""
Token sort ratio similarity score: 86
"""La puntuación baja.
Esto se debe a que la clasificación por tokens solo ignora el orden. Si hay palabras que son diferentes en las cadenas, esto afectará negativamente al índice de similitud, como hemos visto anteriormente.
Pero hay una solución alternativa.
El método « token_set_ratio() » es muy similar al « token_sort_ratio() », salvo que elimina los tokens comunes antes de calcular el grado de similitud entre las cadenas: esto resulta extremadamente útil cuando las cadenas tienen una longitud muy diferente.
Dado que las variables name y full_name contienen «Kurtis Pykes», podemos esperar que la similitud del conjunto de tokens sea del 100 %.
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Token sort ratio similarity score: {fuzz.token_set_ratio(name, full_name)}")
"""
Token sort ratio similarity score: 100
"""El módulo de proceso permite a los usuarios extraer texto de una colección mediante la coincidencia de cadenas difusas. Al llamar al método extract() en el módulo de proceso, se devuelven las cadenas con una puntuación de similitud en un vector. Por ejemplo:
from thefuzz import process
collection = ["AFC Barcelona", "Barcelona AFC", "barcelona fc", "afc barcalona"]
print(process.extract("barcelona", collection, scorer=fuzz.ratio))
"""
[('barcelona fc', 86), ('AFC Barcelona', 82), ('Barcelona AFC', 82), ('afc barcalona', 73)]
"""Podemos controlar la longitud del vector devuelto por el método extract() estableciendo el parámetro límite en la longitud deseada.
print(process.extract("barcelona", collection, scorer=fuzz.ratio))
"""
[('barcelona fc', 86), ('AFC Barcelona', 82), ('Barcelona AFC', 82)]
"""En este caso, extract() devuelve las tres cadenas más parecidas según el puntuador que hemos definido.
En la siguiente tabla, puedes ver una comparación rápida de los diferentes tipos de técnicas disponibles en TheFuzz:
| Técnica | Descripción | Ejemplo de código |
|---|---|---|
| Relación simple | Calcula la similitud teniendo en cuenta el orden de las cadenas de entrada. | fuzz.ratio(name, full_name) |
| Ratio parcial | Encuentra similitudes parciales comparando la cadena más corta con subcadenas. | fuzz.partial_ratio(name, full_name) |
| Proporción de clasificación de tokens | Ignora el orden de las palabras en las cadenas. | fuzz.token_sort_ratio(full_name_reordered, full_name) |
| Proporción del conjunto de tokens | Elimina los tokens comunes antes de calcular la similitud. | fuzz.token_set_ratio(name, full_name) |
En esta sección, veremos cómo realizar coincidencias de cadenas difusas en un DataFrame de pandas.
Supongamos que tienes algunos datos que has exportado a un DataFrame de pandas y deseas unirlos a los datos que ya tienes.
import pandas as pd
# Creating a dataframe
dict_one = {
"country": ["England", "Scotland", "Wales", "United Kingdom", "Northern Ireland"],
"population_in_millions": [55.98, 5.45, 3.14, 67.33, 1.89]
}
dict_two = {
"country": ["Northern Iland", "Wles", "Scotlnd", "Englnd", "United K."],
"GDP_per_capita": [24900, 23882, 37460, 45101, 46510.28]
}
existing_data = pd.DataFrame(dict_one)
exported_data = pd.DataFrame(dict_two)
print(existing_data, exported_data, sep="\n\n")
"""
country population_in_millions
0 England 55.98
1 Scotland 5.45
2 Wales 3.14
3 United Kingdom 67.33
4 Northern Ireland 1.89
country GDP_per_capita
0 Northern Iland 24900.00
1 Wles 23882.00
2 Scotlnd 37460.00
3 Englnd 45101.00
4 United K. 46510.28
"""Hay un problema grave.
Los datos existentes tienen la ortografía correcta de los países, pero los datos exportados no. Si intentamos unir los dos DataFrames en la columna «país», pandas no reconocería las palabras mal escritas como equivalentes a las palabras escritas correctamente. Por lo tanto, el resultado devuelto por la función merge no será el esperado.
Esto es lo que pasaría si lo intentáramos:
# Attempt to join the two dataframe
data = pd.merge(existing_data, exported_data, on="country", how="left")
print(data.head())
"""
country population_in_millions GDP_per_capita
0 England 55.98 NaN
1 Scotland 5.45 NaN
2 Wales 3.14 NaN
3 United Kingdom 67.33 NaN
4 Northern Ireland 1.89 NaN
"""Esto frustra el propósito de intentar fusionar estos DataFrames.
Sin embargo, podemos solucionar este problema con la coincidencia difusa de cadenas.
Veamos cómo queda en el código:
# Rename the misspelled columns
exported_data["country"] = exported_data["country"].apply(
lambda x: process.extractOne(x, existing_data["country"], scorer=fuzz.partial_ratio)[0]
)
# Attempt to join the two dataframe
data = pd.merge(existing_data, exported_data, on="country", how="left")
print(data.head())
"""
country population_in_millions GDP_per_capita
0 England 55.98 45101.00
1 Scotland 5.45 37460.00
2 Wales 3.14 23882.00
3 United Kingdom 67.33 46510.28
4 Northern Ireland 1.89 24900.00
"""En este código, hemos renombrado los valores mal escritos en la columna «country» de los datos exportados utilizando una elegante función lambda en asociación con el método « process.extractOne() ». Ten en cuenta que utilizamos un índice de 0 en el resultado de extractOne() para devolver en línea la cadena similar en lugar de una lista que contenga la cadena y el valor de similitud.
A continuación, fusionamos los DataFrames en la columna «país» utilizando una unión izquierda. El resultado es un único DataFrame que contiene los países escritos correctamente (incluida la unión política del Reino Unido).
Aunque la solución anterior es perfecta para este tutorial y para conjuntos de datos pequeños, hay que tener cuidado al aplicarla a «Big Data».
Cuando utilizas .apply() con coincidencia aproximada, el ordenador debe comparar cada fila del DataFrame A con cada fila del DataFrame B (un producto cartesiano).
Para conjuntos de datos de más de unos pocos miles de filas, considera la posibilidad de utilizar RapidFuzz (que utiliza C++ para aumentar la velocidad) o Splink (que utiliza el «bloqueo» para reducir las comparaciones).
Si necesitas un resumen rápido de las técnicas mencionadas anteriormente, puedes encontrarlas en la siguiente tabla:
| Paso | Descripción | Fragmento de código |
|---|---|---|
| Crear DataFrames | Define datos con posibles errores ortográficos. | existing_data = pd.DataFrame(dict_one), exported_data = pd.DataFrame(dict_two) |
| Intentar fusionar con errores | La fusión inicial falla debido a cadenas que no coinciden. | data = pd.merge(existing_data, exported_data, on="country", how="left") |
| Corregir errores ortográficos | Utiliza la coincidencia aproximada para corregir los nombres de países mal escritos. | exported_data["country"] = exported_data["country"].apply(lambda x: process.extractOne(x, existing_data["country"], scorer=fuzz.partial_ratio)[0]) |
| Fusión exitosa | Combina los DataFrames después de corregir los errores ortográficos utilizando la coincidencia de cadenas difusas. | data = pd.merge(existing_data, exported_data, on="country", how="left") |
En este tutorial, has aprendido:
Los ejemplos aquí presentados pueden ser sencillos, pero bastan para ilustrar cómo manejar diversos casos de lo que un ordenador considera cadenas no coincidentes. Existen varias aplicaciones de la coincidencia difusa en áreas como la revisión ortográfica y la bioinformática, donde se utiliza la lógica difusa para hacer coincidir secuencias de ADN.
Cursos de Python
Curso
Curso
Curso
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal
Tutorial
Adel Nehme
Tutorial
Satyabrata Pal
Tutorial
Duong Vu
