programa
Fundamentos de GitHub
10 h
Sincronizar los repositorios locales con sus homólogos remotos es un aspecto fundamental del trabajo con Git.
Dos comandos que suelen confundirse al acceder al código de forma remota son « git fetch » y « git pull ». Aunque parecen similares, sus diferencias tienen implicaciones significativas para la revisión del código, la gestión de ramas y la productividad general del equipo.
En este artículo, explicaremos qué hace cada una de las funciones, veremos algunos ejemplos y también algunas prácticas recomendadas para utilizarlas. Si todavía estás aprendiendo sobre Git, te recomiendo que eches un vistazo a nuestro programa de Git Fundamentals.
Aunque están relacionados, los comandos difieren tanto en su comportamiento como en su intención.
Comparémoslos en la siguiente tabla:
|
Diferencias |
Git Fetch |
Git Pull |
|
Objetivo |
Actualiza solo las ramas de seguimiento remoto. |
Actualiza las ramas de seguimiento remoto y las integra en la rama actual. |
|
Efecto sobre el directorio de trabajo |
No hay cambios en los archivos. |
Los cambios se aplican inmediatamente a los archivos de la rama de trabajo. |
|
Seguridad |
Seguro; los cambios no se fusionan automáticamente. |
Menos seguro; puede provocar conflictos de fusión de inmediato. |
|
Control |
Te da control total sobre cuándo y cómo fusionar. |
Automatiza la integración; menos toma de decisiones manuales. |
|
Impacto histórico |
Mantiene el historial limpio hasta que se realiza la fusión. |
Puedes añadir confirmaciones de fusión (con merge) o reescribir tu historial de confirmaciones local (con rebase). |
|
Casos de uso comunes |
Revisión de código, integración de planificación, sincronización segura |
Actualizaciones rápidas, procesos de CI/CD, entornos de confianza. |
Como puedes ver, los comandos difieren tanto en su comportamiento como en su intención:
git fetch Solo actualiza las referencias de seguimiento remoto, dejando tu rama de trabajo intacta.git pull Actualiza las referencias de seguimiento remoto y las integra inmediatamente en tu rama actual.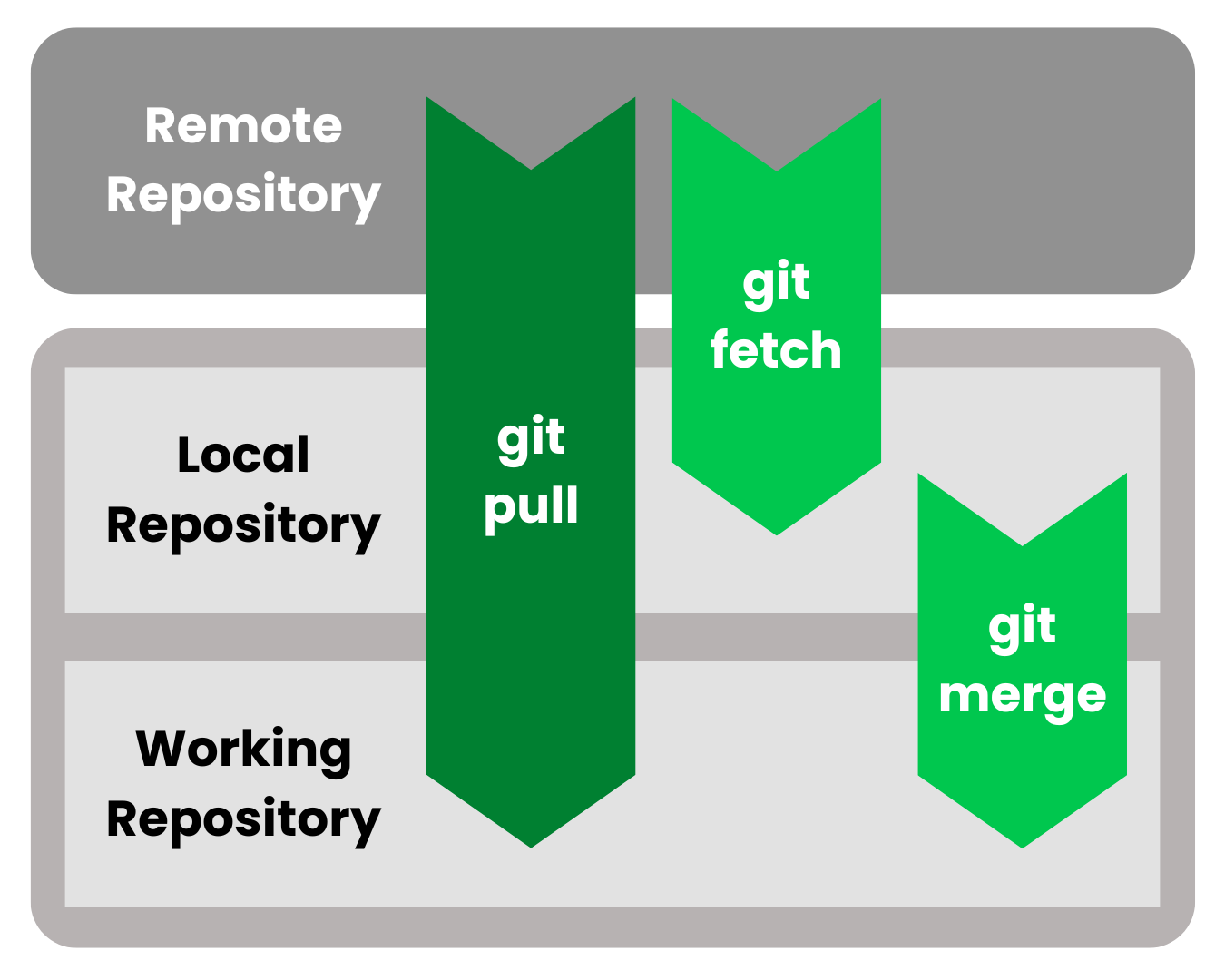
Como se muestra en el flujo visual anterior, las diferencias entre fetch y pull radican en el destino al que fluye el código.
En resumen:
origin/main). Tu main local permanece sin cambios, lo que te permite ver las actualizaciones sin interrupciones.Para apreciar plenamente git fetch y git pull, tendremos que comprender la estructura interna de Git y las capas que intervienen.
Git es fundamentalmente un sistema de control de versiones distribuido, lo que significa que cada programador tiene una copia completa del repositorio, incluyendo el historial, las ramas y las etiquetas.
Esta arquitectura permite que el trabajo continúe independientemente de un servidor central, haciendo que comandos como fetch y pull sean los puentes que mantienen sincronizados los entornos distribuidos.
Los repositorios Git funcionan en varias capas:
.git que contiene la base de datos de todas las confirmaciones, ramas, etiquetas y configuraciones. Esto es totalmente local y no cambia a menos que lo confirmes o lo sincronices explícitamente.Estas capas funcionan de forma independiente, lo que significa que la sincronización con un control remoto no afecta inmediatamente a tu directorio de trabajo.
En cambio, los cambios se propagan gradualmente en este orden:
remoto → ramas de seguimiento remoto → repositorio local → directorio de trabajo.
Las ramas de seguimiento remoto son referencias especiales que representan el estado de las ramas en el repositorio remoto.
Por ejemplo, origin/main te indica dónde estaba la rama main en el control remoto origin la última vez que la recuperaste.
Actúan como marcadores, lo que te permite:
git fetch, Git actualiza estas ramas de seguimiento remoto.Esta separación significa que puedes observar y analizar las actualizaciones antes de que afecten a tu trabajo de desarrollo real. Puedes obtener más información en nuestro tutorial sobre Git remoto.
git fetch Recupera confirmaciones, ramas y etiquetas de un repositorio remoto y actualiza tus ramas de seguimiento remoto sin alterar tu rama actual ni tus archivos de trabajo.
Intenta pensar en ello como «descargar el último mapa del repositorio remoto» sin adentrarte en el nuevo territorio.
Es especialmente útil para programadores que desean tener visibilidad de la actividad remota sin correr el riesgo de que se produzcan cambios no deseados en su propio trabajo.
El comando se utiliza en la terminal bash o en la interfaz de línea de comandos (CLI). Aquí tienes algunos detalles sintácticos que debes tener en cuenta:
Comandos comunes de recuperación:
# Fetch all remotes
git fetch --all
# Fetch only one branch
git fetch origin main
# Fetch and prune stale references
git fetch --prune
# Fetch a specific tag
git fetch origin tag v1.2.0A continuación se explica cada comando y sus respectivas opciones:
--all garantiza que todos los mandos a distancia configurados se actualicen, lo cual resulta útil en configuraciones con varios mandos a distancia.git fetch origin main es eficaz si solo te interesa una línea de trabajo.--prune Elimina las ramas de seguimiento remoto obsoletas que ya no existen en el servidor, manteniendo tu entorno limpio.git fetch origin tag resulta útil en los flujos de trabajo de lanzamiento, donde las confirmaciones etiquetadas son más importantes que las ramas completas.Los programadores utilizan git fetch en diversos escenarios en los que la visibilidad y el control son importantes. Por ejemplo:
origin/main con tu rama local para preparar la fusión o el rebase.git pull es más agresivo que fetch porque descarga los cambios e intenta integrarlos inmediatamente en la rama actual.
Esto significa que el comando « git pull » es una combinación de los comandos « git fetch » y « git merge ».
De forma predeterminada, esta integración es una fusión, pero se puede configurar para utilizar rebase. Aunque es muy práctico, este comando asume que deseas que las actualizaciones remotas se apliquen de inmediato.
Es el comando ideal para los programadores que priorizan la velocidad y la sincronización inmediata.
Ahora, veamos la sintaxis para usar este comando.
Aquí hay algunos ejemplos:
# Default fetch + merge
git pull origin main
# Fetch + rebase for cleaner history
git pull --rebase origin main
# Pull all changes from default remote
git pull
# Pull with fast-forward only (avoids merge commits)
git pull --ff-onlyA continuación se explica el código anterior:
--rebase, Git vuelve a aplicar tus confirmaciones locales sobre la rama remota, creando un historial más limpio y lineal.--ff-only » garantiza que la rama se avance rápidamente sin fusiones innecesarias, lo que suele ser deseable para obtener flujos de trabajo limpios.En Git, «avance rápido» se refiere a un tipo específico de operación de fusión que se produce cuando la rama en la que estás fusionando no se ha desviado de la rama desde la que estás fusionando.
Esto significa que no hay nuevas confirmaciones en la rama de destino (en la que te encuentras actualmente) que no estén también presentes en la rama de origen (la que estás fusionando).
En esencia, el avance rápido es un proceso de fusión optimizado que simplifica el historial cuando se mantiene una progresión lineal de confirmaciones entre ramas.
Este comando se puede utilizar en diversos casos para controlar el código de desarrollo, como por ejemplo:
El comando « git pull » puede plantear algunas preocupaciones. A continuación, se indican algunos aspectos de seguridad que debes tener en cuenta:
La elección entre fetch y pull depende del flujo de trabajo y los requisitos del proyecto.
A la hora de decidir qué enfoque adoptar, hay que tener en cuenta la cultura del equipo y el tipo de proyecto.
En general, puedes adoptar dos estrategias diferentes.
Al trabajar con los dos comandos, los programadores suelen aplicar algunas prácticas recomendadas para evitar cambios inesperados en el código.
Aquí tienes algunos consejos que debes tener en cuenta:
git pull --rebase ayuda a evitar historiales desordenados.Más allá del simple acceso a repositorios remotos, Git también se puede utilizar para otros fines con el fin de garantizar un buen control de versiones.
A continuación se muestran algunos comandos relacionados comunes:
git diff HEAD..origin/main: Compara lo local y lo remoto.git branch -a: Inspecciona todas las sucursales, tanto locales como remotas.git clone: El punto de partida para la sincronización es crear una copia del repositorio remoto en tu máquina local.Más información sobre los comandos de Git en la hoja de referencia que aparece a continuación.

Fuente: Hoja de referencia rápida de Git de DataCamp
En entornos CI/CD, es habitual utilizar fetch y pull.
La automatización se puede habilitar mediante estos ejemplos:
Los comandos Git son muy útiles cuando se utilizan para gestionar flujos de trabajo de desarrollo.
Por lo tanto, pueden utilizarse adecuadamente en los siguientes casos de uso:
Ambos comandos son esenciales, pero tienen fines diferentes. git fetch hace hincapié en la seguridad, la visibilidad y la integración controlada, mientras que git pull destaca la rapidez y la comodidad. La elección entre uno u otro depende del contexto: el tamaño del proyecto, la cultura del equipo y el equilibrio entre estabilidad y agilidad.
Los equipos deben encontrar el equilibrio adecuado entre usar fetch para revisiones minuciosas y pull para actualizaciones rápidas. Podrás evitar conflictos innecesarios, optimizar la colaboración y mantener repositorios más saludables.
¿Quieres aprender más sobre cómo usar Git para el control de versiones? Echa un vistazo a nuestras GitHub Foundations o nuestro programa curso GitHub Concepts. ¿Quieres leer más sobre Git? Luego, nuestro Git Push y Pull y tutoriales de Git Remote pueden resultar útiles.
Los mejores cursos de DataCamp
programa
programa
Curso
Tutorial
Olivia Smith
Tutorial
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Tutorial