Lernpfad
GitHub-Grundlagen
10 Std.
Lokale Repositorys mit ihren Remote-Entsprechungen zu synchronisieren, ist ein wichtiger Teil der Arbeit mit Git.
Zwei Befehle, die beim Remote-Zugriff auf Code oft verwechselt werden, sind „ git fetch “ und „ git pull “. Auch wenn sie ähnlich aussehen, haben ihre Unterschiede wichtige Auswirkungen auf die Codeüberprüfung, das Branch-Management und die allgemeine Produktivität des Teams.
In diesem Artikel schauen wir uns an, was die einzelnen Funktionen machen, sehen uns ein paar Beispiele an und reden auch über ein paar bewährte Methoden, wie man sie am besten nutzt. Wenn du dich noch mit Git vertraut machst, schau dir doch mal unseren Lernpfad „Git-Grundlagen“ an.
Obwohl sie miteinander zusammenhängen, unterscheiden sich die Befehle sowohl in ihrem Verhalten als auch in ihrer Absicht.
Schauen wir uns mal die Unterschiede in der Tabelle unten an:
|
Unterschiede |
Git Fetch |
Git Pull |
|
Zweck |
Aktualisiert nur Remote-Tracking-Zweige |
Aktualisiert Remote-Tracking-Branches und integriert sie in den aktuellen Branch. |
|
Auswirkung auf das Arbeitsverzeichnis |
Keine Änderungen an Dateien |
Änderungen werden sofort auf Dateien im Arbeitszweig angewendet. |
|
Sicherheit |
Sicher; Änderungen werden nicht automatisch zusammengeführt |
Weniger sicher; kann sofort zu Zusammenführungskonflikten führen |
|
Kontrolle |
Gibt dem Benutzer die volle Kontrolle darüber, wann und wie die Zusammenführung passiert. |
Automatisiert die Integration; weniger manuelle Entscheidungen |
|
Auswirkungen auf die Geschichte |
Hält den Verlauf sauber, bis die Zusammenführung fertig ist. |
Du kannst Merge-Commits hinzufügen (mit „merge“) oder deine lokale Commit-Historie umschreiben (mit „rebase“). |
|
Häufige Anwendungsfälle |
Code-Review, Planungsintegration, sichere Synchronisierung |
Schnelle Updates, CI/CD-Pipelines, vertrauenswürdige Umgebungen |
Wie du siehst, unterscheiden sich die Befehle sowohl in ihrer Funktionsweise als auch in ihrer Absicht:
git fetch aktualisiert nur Remote-Tracking-Referenzen und lässt deinen Arbeitszweig unberührt.git pull Aktualisiert Remote-Tracking-Referenzen und integriert sie sofort in deinen aktuellen Branch.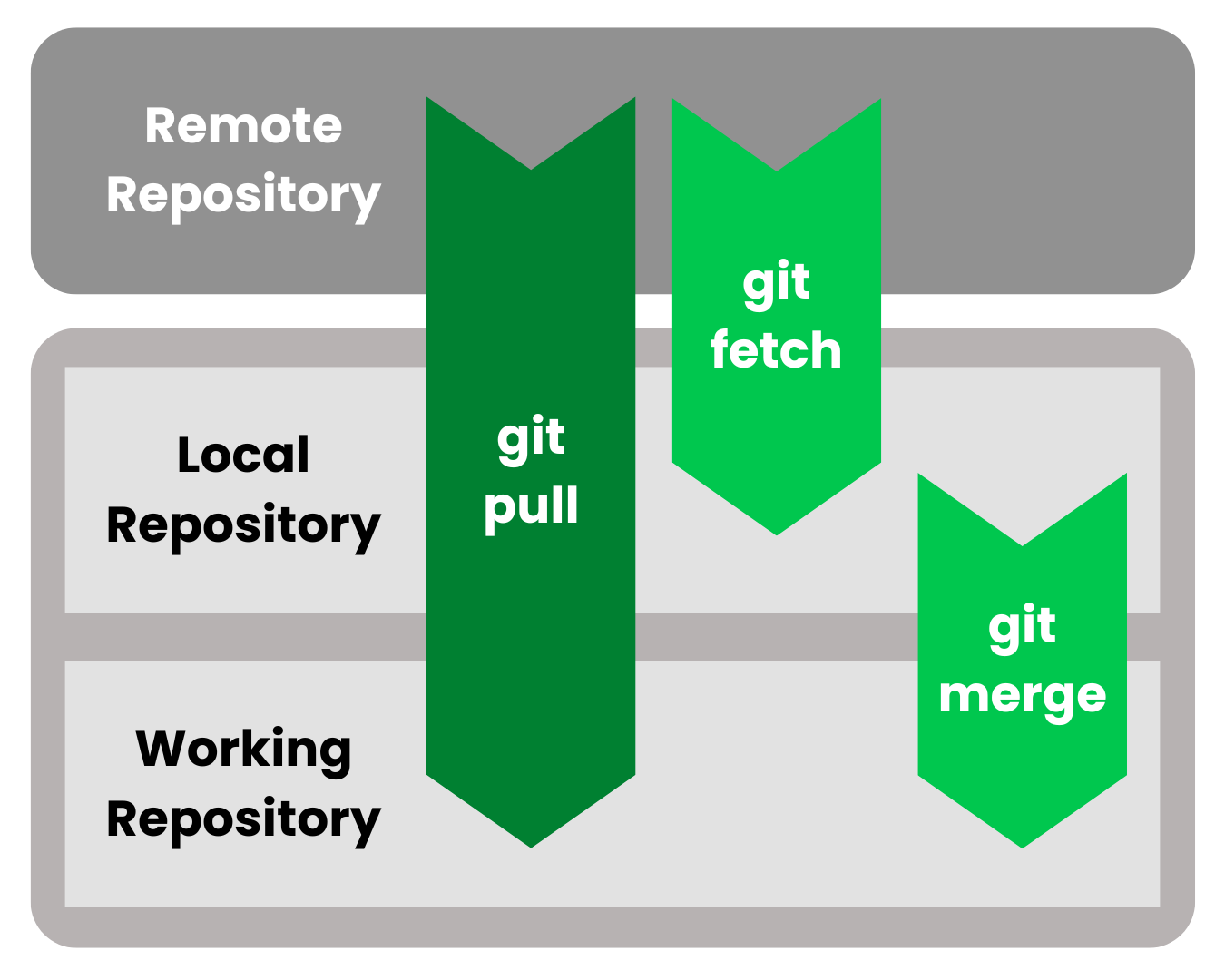
Wie du im obigen Flussdiagramm sehen kannst, geht es bei den Unterschieden zwischen Fetch und Pull darum, wohin dein Code fließt.
Zusammengefasst:
origin/main). Deine lokale main bleibt wie bisher, sodass du Updates ohne Probleme sehen kannst.Um git fetch und git pull richtig zu verstehen, müssen wir uns mit der internen Struktur von Git und den beteiligten Ebenen beschäftigen.
Git ist im Grunde ein verteiltes Versionskontrollsystem, was bedeutet, dass jeder Entwickler eine komplette Kopie des Repositorys hat, einschließlich Historie, Branches und Tags.
Mit dieser Architektur kann man unabhängig von einem zentralen Server weiterarbeiten, sodass Befehle wie „fetch“ und „pull“ die Brücken sind, die verteilte Umgebungen synchron halten.
Git-Repositorys funktionieren in mehreren Ebenen:
.git “, das die Datenbank mit allen Commits, Branches, Tags und Konfigurationen enthält. Das ist komplett lokal und ändert sich nur, wenn du was festschreibst oder explizit synchronisierst.Diese Ebenen funktionieren unabhängig voneinander, was bedeutet, dass die Synchronisierung mit einem Remote-Server nicht sofort Auswirkungen auf dein Arbeitsverzeichnis hat.
Stattdessen breiten sich die Änderungen nach und nach in dieser Reihenfolge aus:
Remote → Remote-Tracking-Zweige → lokales Repository → Arbeitsverzeichnis.
Remote-Tracking-Branches sind spezielle Referenzen, die den Status von Branches im Remote-Repository zeigen.
Zum Beispiel zeigt dir „ origin/main “ an, wo sich der Branch „ main “ auf dem Remote „ origin “ beim letzten Abruf befand.
Sie funktionieren wie Lesezeichen und ermöglichen dir Folgendes:
git fetch “ ausführst, aktualisiert Git diese Remote-Tracking-Zweige.Durch diese Trennung kannst du Updates checken und analysieren, bevor sie deine eigentliche Entwicklungsarbeit beeinflussen. Mehr Infos findest du in unserem Git-Remote-Tutorial.
git fetch Holst Commits, Branches und Tags aus einem Remote-Repository und aktualisiert deine Remote-Tracking-Branches, ohne deinen aktuellen Branch oder deine Arbeitsdateien zu verändern.
Stell dir das so vor, als würdest du „die neueste Karte des Remote-Repositorys runterladen“, ohne das neue Gebiet zu betreten.
Das ist besonders praktisch für Entwickler, die einen Überblick über Remote-Aktivitäten haben wollen, ohne dass ihre eigene Arbeit versehentlich verändert wird.
Der Befehl wird im Bash-Terminal oder in der Befehlszeilenschnittstelle (CLI) benutzt. Hier sind ein paar Details zur Syntax, die du beachten solltest:
Häufige Befehle zum Abrufen:
# Fetch all remotes
git fetch --all
# Fetch only one branch
git fetch origin main
# Fetch and prune stale references
git fetch --prune
# Fetch a specific tag
git fetch origin tag v1.2.0Hier ist eine Erklärung für jeden Befehl und seine Optionen:
--all sorgt dafür, dass alle eingestellten Fernbedienungen auf dem neuesten Stand sind, was bei Setups mit mehreren Fernbedienungen echt praktisch ist.git fetch origin main “ ist super, wenn du dich nur für einen Arbeitsablauf interessierst.--prune Entfernt veraltete Remote-Tracking-Zweige, die auf dem Server nicht mehr vorhanden sind, und sorgt so für eine saubere Umgebung.git fetch origin tag “ ist super in Release-Workflows, wo getaggte Commits wichtiger sind als ganze Branches.Entwickler nutzen „ git fetch “ in vielen Situationen, wo es auf Transparenz und Kontrolle ankommt. Zum Beispiel:
origin/main “ mit deinem lokalen Branch, um das Zusammenführen oder Rebasen vorzubereiten.git pull ist aggressiver als fetch, weil es sowohl Änderungen runterlädt als auch sofort versucht, sie in deinen aktuellen Branch zu integrieren.
Das heißt, der Befehl „ git pull “ ist eine Mischung aus den Befehlen „ git fetch “ und „ git merge “.
Standardmäßig ist diese Integration eine Zusammenführung, kann aber auch für die Verwendung von Rebase konfiguriert werden. Dieser Befehl ist zwar praktisch, setzt aber voraus, dass du Remote-Updates sofort installieren willst.
Das ist der Befehl, den Entwickler nutzen, wenn sie Wert auf Geschwindigkeit und sofortige Synchronisierung legen.
Schauen wir uns jetzt mal die Syntax für die Verwendung dieses Befehls an.
Hier sind ein paar Beispiele:
# Default fetch + merge
git pull origin main
# Fetch + rebase for cleaner history
git pull --rebase origin main
# Pull all changes from default remote
git pull
# Pull with fast-forward only (avoids merge commits)
git pull --ff-onlyHier ist eine Erklärung des obigen Codes:
--rebase “ macht Git deine lokalen Commits wieder auf dem Remote-Branch, was zu einer übersichtlicheren, linearen Historie führt.--ff-only “ wird sichergestellt, dass der Branch ohne unnötige Merges vorwärts verschoben wird, was für saubere Arbeitsabläufe oft wünschenswert ist.In Git ist „Fast-Forwarding“ eine spezielle Art von Merge-Vorgang, der passiert, wenn der Branch, in den du mergst, sich nicht von dem Branch, aus dem du mergst, unterscheidet.
Das heißt, es gibt keine neuen Commits auf dem Zielzweig (dem, auf dem du gerade bist), die nicht auch im Quellzweig (dem, den du zusammenführst) vorhanden sind.
Eigentlich ist Fast-Forwarding ein optimierter Merge-Prozess, der die Historie vereinfacht, wenn zwischen den Branches eine lineare Abfolge von Commits beibehalten wird.
Dieser Befehl kann in verschiedenen Situationen zum Steuern von Entwicklungscode verwendet werden, zum Beispiel:
Der Befehl „ git pull “ kann ein paar Probleme mit sich bringen. Hier sind ein paar Sicherheitsaspekte, die du beachten solltest:
Die Entscheidung zwischen Fetch und Pull hängt vom Arbeitsablauf und den Projektanforderungen ab.
Bei der Entscheidung, welchen Ansatz man wählen soll, muss man die Teamkultur und die Art des Projekts berücksichtigen.
Im Allgemeinen kannst du zwei verschiedene Strategien verfolgen.
Bei der Arbeit mit den beiden Befehlen haben Entwickler oft bewährte Vorgehensweisen, um unerwartete Änderungen am Code zu vermeiden.
Hier sind ein paar Tipps, die du beachten solltest:
git pull --rebase “ kannst du unübersichtliche Historiensätze vermeiden.Git kann nicht nur für den Zugriff auf Remote-Repositorys genutzt werden, sondern auch für andere Zwecke, um eine gute Versionskontrolle zu gewährleisten.
Hier sind ein paar häufig verwendete Befehle:
git diff HEAD..origin/main: Vergleich mal lokal und remote.git branch -a: Schau dir alle Zweigstellen an, egal ob vor Ort oder weit weg.git clone: Als Startpunkt für die Synchronisierung wird eine Kopie des Remote-Repositorys auf deinem lokalen Rechner erstellt.Mehr zu Git-Befehlen findest du im folgenden Spickzettel.

Quelle: DataCamp Git-Spickzettel
In CI/CD-Umgebungen ist es üblich, fetch und pull zu benutzen.
Automatisierung kann durch diese Beispiele aktiviert werden:
Git-Befehle sind echt nützlich, wenn man sie für die Verwaltung von Entwicklungsabläufen nutzt.
Deshalb passen sie super für die folgenden Anwendungsfälle:
Beide Befehle sind wichtig, haben aber unterschiedliche Zwecke. „ git fetch “ (Sicherheitsüberprüfung) legt Wert auf Sicherheit, Transparenz und kontrollierte Integration, während „ git pull “ (Schnellzugriff) auf Geschwindigkeit und Komfort setzt. Die Entscheidung zwischen den beiden hängt vom Kontext ab: Projektgröße, Teamkultur und das Gleichgewicht zwischen Stabilität und Flexibilität.
Teams sollten die richtige Balance finden zwischen dem Einsatz von „fetch“ für sorgfältige Überprüfungen und „pull“ für schnelle Updates. Du kannst unnötige Konflikte vermeiden, die Zusammenarbeit optimieren und gesündere Repositorys pflegen.
Willst du mehr über die Verwendung von Git für die Versionskontrolle erfahren? Schau dir unsere GitHub Foundations oder unseren Lernpfad GitHub-Konzepte Kurs an. Willst du mehr über Git erfahren? Dann unser Git Push und Pull und Git Remote könnten dir weiterhelfen.
Die besten DataCamp-Kurse
Lernpfad
Lernpfad
Kurs
Blog
Nathaniel Taylor-Leach
Tutorial
Sejal Jaiswal
Tutorial
Matt Crabtree
Tutorial
DataCamp Team
Tutorial
Laiba Siddiqui
Tutorial
Mark Pedigo
