
Curso
Visualización de datos intermedia con Seaborn
4 h
75K
La visualización de datos es un componente crítico en la interpretación de conjuntos de datos complejos.
En el ámbito de la programación en Python, Seaborn destaca como una potente biblioteca para crear gráficos estadísticos visualmente atractivos e informativos, como histogramas y gráficos de líneas.
Se basa en las capacidades de Matplotlib, mejorando su interfaz y ofreciendo más opciones para visualizar datos, especialmente para el análisis estadístico. La perfecta integración de Seaborn con Pandas DataFrames lo convierte en el favorito de los científicos y analistas de datos.
En esta guía detallada, nos centraremos en uno de los gráficos más utilizados en Seaborn: el histograma.
sns.histplot funciónLa función sns.histplot de Seaborn está diseñada para dibujar histogramas, que son esenciales para examinar la distribución de datos continuos. Esta función es versátil y permite una amplia personalización, lo que facilita la obtención de información significativa a partir de los datos.
Esta función es una de las muchas disponibles en la biblioteca Seaborn. Echa un vistazo a esta hoja de trucos para tener una visión general rápida.
Seaborn para la ciencia de datos - fuente
Antes de sumergirnos en la visualización de datos, tenemos que configurar nuestro entorno. Esto implica importar las bibliotecas necesarias, siendo Seaborn la principal. El seaborn suele importarse como sns por comodidad.
Junto a Seaborn, otras bibliotecas esenciales suelen ser NumPy para operaciones numéricas, pandas para el manejo de datos y Matplotlib para opciones de personalización adicionales.
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
Todas ellas son bibliotecas esenciales que proporcionan las herramientas necesarias para crear y manipular visualizaciones de datos en Python. Son las bibliotecas más utilizadas por los analistas y científicos de datos.
Si te estás iniciando en el aprendizaje de Python, te sugiero que pruebes nuestro curso Introducción a Python. Para aprender más sobre pandas, NumPy y Matplotlib, consulta nuestros cursos Manipulación de datos con pandas, Introducción a NumPy e Introducción a la visualización de datos con Matplotlib.
Utilizaremos el conjunto de datos Precios de la Vivienda en Boston, que puede cargarse desde la biblioteca Scikit-Learn. Este conjunto de datos proporciona los valores de la vivienda en distintas zonas de Boston, junto con varios atributos como el índice de delincuencia, el número medio de habitaciones, etc.
from sklearn.datasets import load_boston
boston = load_boston()
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df['MEDV'] = boston.target
Disponer de datos adecuados para tus histogramas es lo que los hace o los deshace. En este caso, utilizamos una variable continua, el valor medio de las viviendas ocupadas por sus propietarios (MEDV) en Boston.
Como los histogramas suelen mostrar la distribución de una sola variable, seleccionaremos una columna de nuestro DataFrame.
¿Eres nuevo en Scikit-Learn? Echa un vistazo a nuestro tutorial sobre Aprendizaje Automático en Python. Si quieres más información, nuestro curso Aprendizaje supervisado con scikit-learn te ayudará a cubrir los aspectos básicos.
Antes de ponerte manos a la obra, aquí tienes algunos requisitos previos básicos antes de empezar a construir tu histograma Seaborn:
Empezaremos repasando algunos de los parámetros y sintaxis habituales de la función `sns.histplot`.
La sintaxis básica para crear un histograma utilizando `sns.histplot` es sencilla.
Los parámetros clave son:
data: El conjunto de datos, que suele ser un Pandas DataFrame.x: La variable para la que se traza el histograma.color: Para especificar el color de las barras.alpha: Transparencia de las barras.bins: El número de bins (grupos de barras) que se van a utilizar.binwidth: La anchura de cada recipiente.kde: Un booleano para añadir un gráfico de Estimación de la Densidad del Núcleo.hue: Para diferenciar subconjuntos de datos en función de otra variable.La función acepta muchos parámetros y argumentos, pero nos centraremos en los necesarios para nuestro conjunto de datos.
Vamos a crear un histograma básico para visualizar la distribución de los precios medios de la vivienda (MEDV).
plt.figure(figsize=(10, 6))
sns.histplot(data=df, x='MEDV')
plt.title('Distribution of Median Housing Prices in Boston')
plt.xlabel('Median Value of Owner-Occupied Homes (in $1000)')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()
Este comando mostrará el histograma de la columna MEDV.
Aquí tienes el gráfico generado a partir de este código:
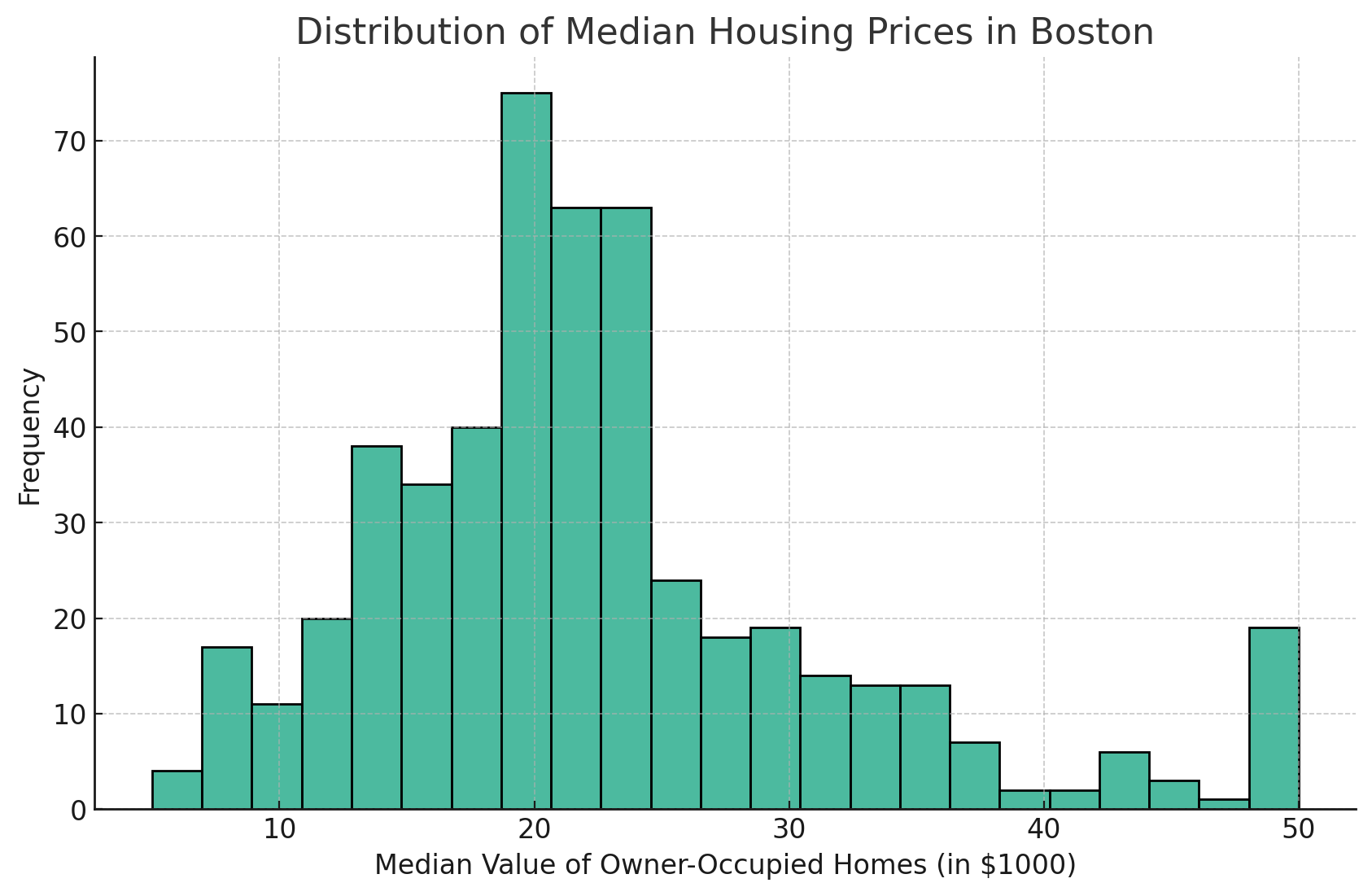
Este es el histograma que muestra la distribución de los precios medios de la vivienda (MEDV) en el conjunto de datos de Boston. El histograma proporciona una representación visual de la distribución de frecuencias de los valores medios de las viviendas ocupadas por sus propietarios.
Ajustar el número de bins puede ayudar a comprender mejor la distribución. Un mayor número de bins puede revelar más detalles, mientras que un número menor simplifica la visualización.
Para aumentar el número de bins, puedes modificar el parámetro bins.
He aquí un ejemplo:
plt.figure(figsize=(10, 6))
sns.histplot(data=df, x='MEDV', bins=30)
plt.title('Distribution of Median Housing Prices in Boston')
plt.xlabel('Median Value of Owner-Occupied Homes (in $1000)')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()
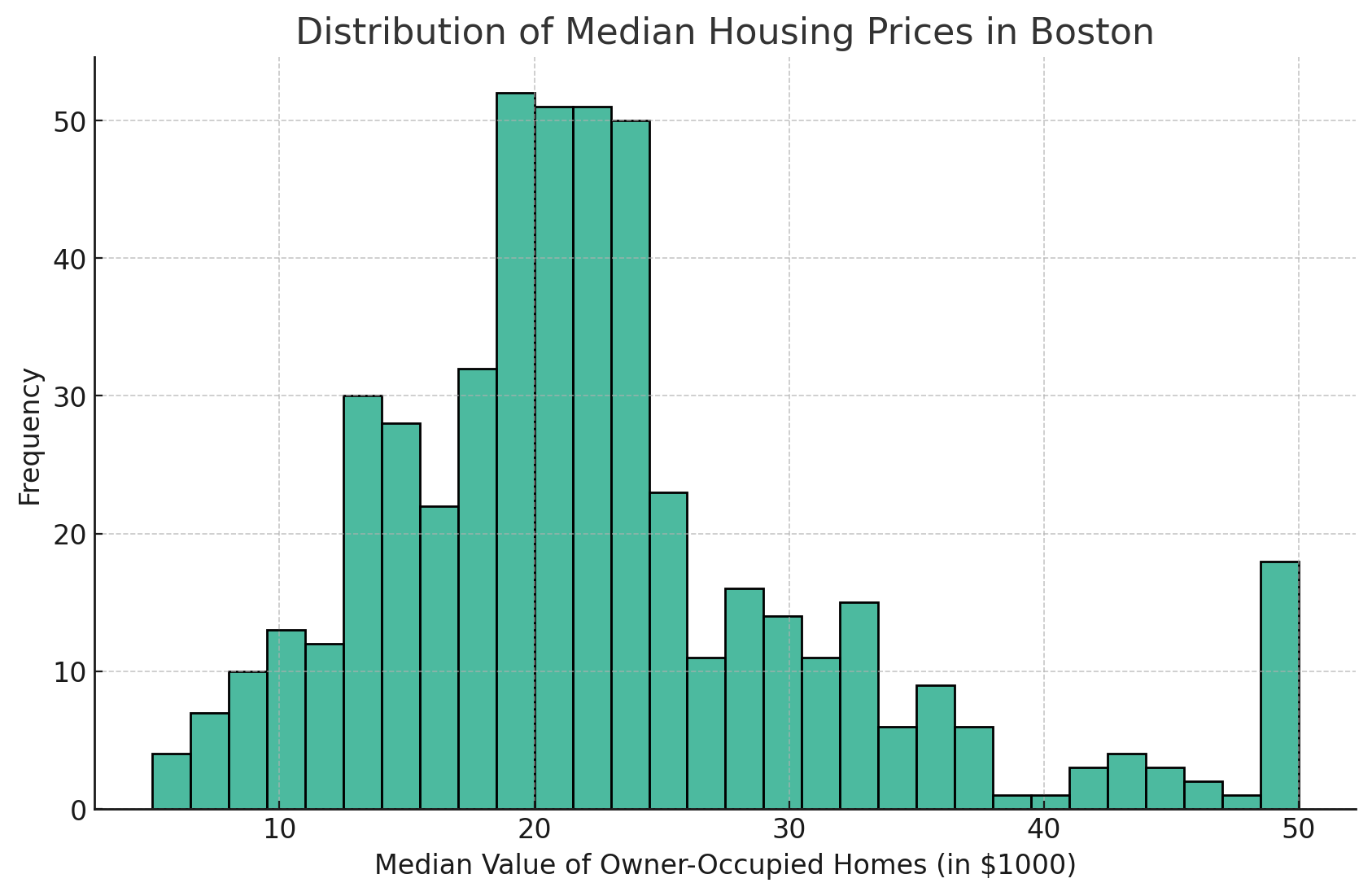
Como puedes ver en el histograma Seaborn anterior, el número de barras ha aumentado hasta la cantidad que he establecido, que, en este caso, es 30. Es una buena forma de profundizar en los detalles para obtener una mayor granularidad de tus datos.
Personalizar la estética, como cambiar el color y la transparencia de la barra, puede hacer que el histograma sea más informativo y visualmente atractivo.
En el ejemplo siguiente, he recreado nuestro histograma original utilizando el color morado en lugar del color por defecto.
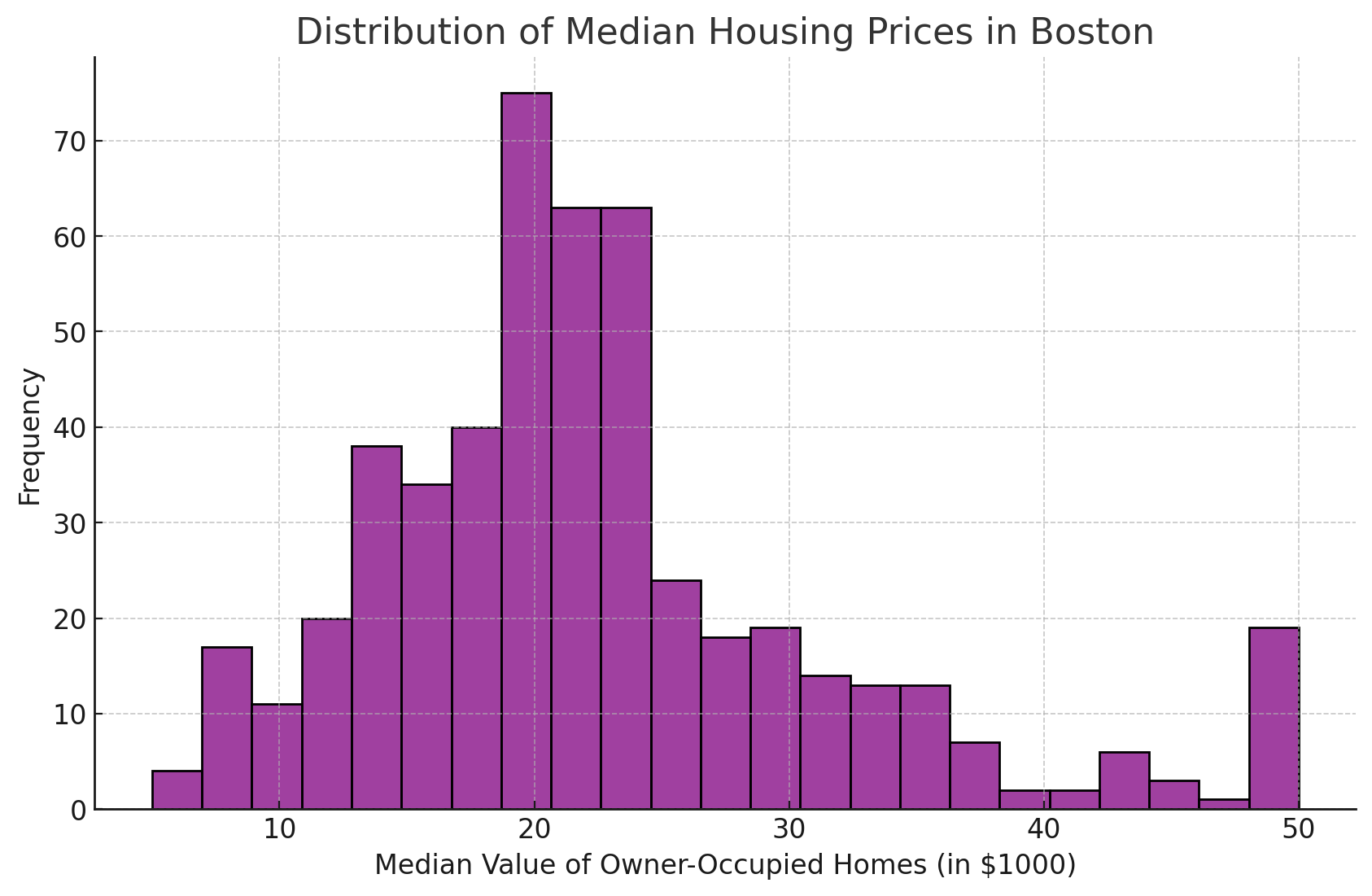
Este es el código que he utilizado para crear el gráfico anterior.
plt.figure(figsize=(10, 6))
sns.histplot(data=df, x='MEDV', color='purple')
plt.title('Distribution of Median Housing Prices in Boston')
plt.xlabel('Median Value of Owner-Occupied Homes (in $1000)')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()
KDE proporciona una estimación suave de la distribución de los datos. Puede ser especialmente útil para identificar patrones en los datos.
Esto crea una curva lineal suave que puede ayudar a visualizar las tendencias generales.
Para ello, utilizamos el parámetro kde en esta función:
plt.figure(figsize=(10, 6))
sns.histplot(data=df, x='MEDV', kde=True)
plt.title('Distribution of Median Housing Prices in Boston')
plt.xlabel('Median Value of Owner-Occupied Homes (in $1000)')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()
Esto producirá una bonita curva en nuestro histograma, como se muestra a continuación.
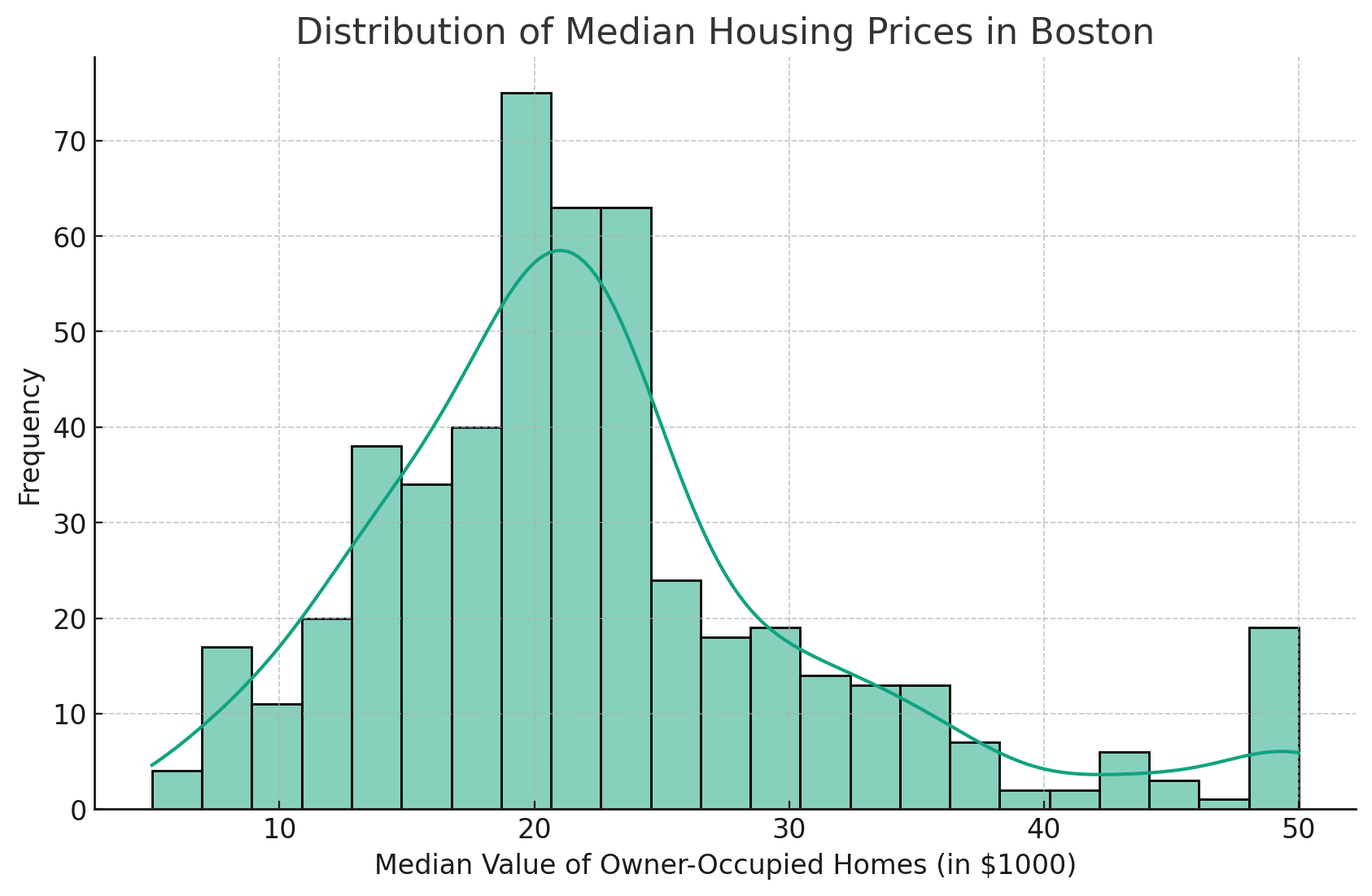
La adición de la línea de Estimación de la Densidad del Núcleo (KDE) proporciona una estimación más suave de la distribución.
El parámetro matiz permite comparar diferentes categorías dentro del histograma.
Este parámetro nos permite distinguir entre diferentes categorías dentro del mismo histograma, proporcionando una comparación visual de las distribuciones.
En pocas palabras, toma una columna categórica del Marco de datos y diferencia los datos utilizando diferentes colores.
Por ejemplo, si tenemos una columna llamada "CHAS" en nuestro DataFrame, que indica si una casa está junto al río Charles (1) o no (0), podemos utilizar el parámetro "hue" para comparar la distribución de los precios medios de la vivienda de las casas que están cerca del río frente a las que no lo están.
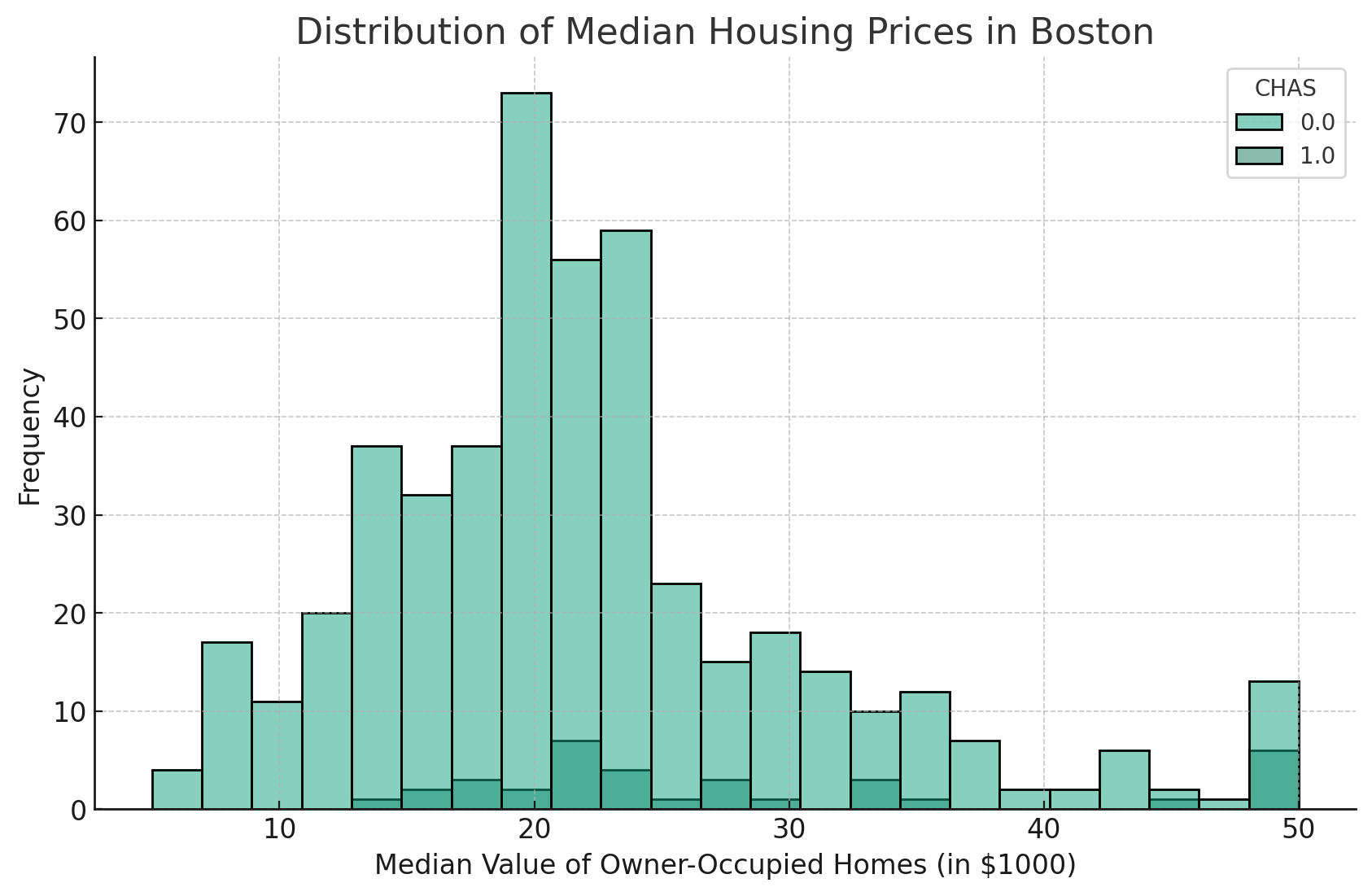
El código tendrá el siguiente aspecto:
plt.figure(figsize=(10, 6))
sns.histplot(data=df, x='MEDV', hue='CHAS')
plt.title('Distribution of Median Housing Prices in Boston')
plt.xlabel('Median Value of Owner-Occupied Homes (in $1000)')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()
Esto generará un histograma en el que se diferenciará la distribución de MEDV de las viviendas que bordean el río Charles (CHAS=1) de las que no lo bordean (CHAS=0), cada una representada por un color distinto.
Cuando construyas histogramas Seaborn, hay varios aspectos que debes tener en cuenta, como se indica a continuación:
Seleccionar el número óptimo de bins es clave para crear un histograma informativo. Aunque un mayor número de intervalos puede proporcionar más detalles, también puede llevar a un ajuste excesivo y a una representación errónea de los datos.
Por otra parte, un número demasiado reducido de intervalos puede simplificar en exceso la distribución.
Una forma de elegir el número adecuado de recipientes es utilizar una regla empírica llamada Regla de Scott. Esta regla calcula el tamaño ideal del recipiente en función del número de puntos de datos del conjunto de datos.
Aunque es importante proporcionar suficientes detalles en un histograma, también es crucial garantizar que la visualización siga siendo clara y fácil de interpretar.
Añadir demasiados elementos, como líneas KDE o demasiados colores, puede dar lugar a visuales desordenados y difíciles de entender.
Lo mejor es encontrar un equilibrio entre añadir elementos informativos y mantener la sencillez.
El tipo de datos que se visualizan también influye en la selección de los parámetros adecuados del histograma.
Por ejemplo, las variables continuas requerirán tamaños de recipiente diferentes en comparación con las variables categóricas.
Es importante tener en cuenta la naturaleza de los datos al crear histogramas, para garantizar que representan con precisión la distribución.
Sin embargo, Seaborn es sólo una de las bibliotecas disponibles para la visualización de datos en Python. Si lo prefieres, también puedes crear tus histogramas en Matplotlib.
Seaborn es una potente biblioteca para crear visualizaciones en Python, y la función `histplot` permite crear histogramas fácilmente. Con sólo cambiar los parámetros dentro de la función, puedes modificar el aspecto de tu gráfico para conseguir el nivel de detalle y la estética que desees.
Recuerda todos los consejos sobre histogramas de Seaborn mencionados anteriormente: ten siempre en cuenta el tipo de datos, elige tamaños de recipiente adecuados y equilibra el detalle con la claridad al crear histogramas con Seaborn.
¿Te interesa saber más sobre Seaborn y sus otras potentes funciones de visualización de datos? Nuestro curso Introducción a la visualización de datos con Seaborn es un curso excelente para principiantes.
¡Comienza hoy tu viaje a Seaborn!
Curso
Curso
Curso