
Cours
Intermediate Data Visualization with Seaborn
4 h
75K
La visualisation des données est un élément essentiel de l'interprétation d'ensembles de données complexes.
Dans le domaine de la programmation Python, Seaborn se distingue comme une bibliothèque puissante pour créer des graphiques statistiques visuellement attrayants et informatifs, comme des histogrammes et des tracés linéaires.
Il s'appuie sur les capacités de Matplotlib, en améliorant son interface et en offrant davantage d'options pour la visualisation des données, en particulier pour l'analyse statistique. L'intégration transparente de Seaborn avec Pandas DataFrames en fait l'un des favoris des data scientists et des analystes.
Dans ce guide détaillé, nous nous concentrerons sur l'un des graphiques les plus couramment utilisés dans Seaborn, l'histogramme.
sns.histplot functionLa fonction sns.histplot de Seaborn est conçue pour dessiner des histogrammes, qui sont essentiels pour examiner la distribution des données continues. Cette fonction est polyvalente et permet une personnalisation poussée, ce qui facilite l'extraction d'informations significatives à partir des données.
Cette fonction est l'une des nombreuses fonctions disponibles dans la bibliothèque Seaborn. Jetez un coup d'œil à l'aide-mémoire ci-dessous pour une vue d'ensemble rapide.
Seaborn pour la science des données - source
Avant de nous plonger dans la visualisation des données, nous devons mettre en place notre environnement. Il s'agit d'importer les bibliothèques nécessaires, en particulier Seaborn. Pour des raisons de commodité, le germon est généralement importé sous la forme de sns.
Outre Seaborn, les autres bibliothèques essentielles comprennent souvent NumPy pour les opérations numériques, pandas pour le traitement des données et Matplotlib pour des options de personnalisation supplémentaires.
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
Ce sont toutes des bibliothèques essentielles qui fournissent les outils nécessaires à la création et à la manipulation de visualisations de données en Python. Ce sont les bibliothèques les plus couramment utilisées par les analystes et les scientifiques des données.
Si vous vous lancez dans l'apprentissage de Python, je vous suggère d'essayer notre cours d'introduction à Python. Pour en savoir plus sur pandas, NumPy et Matplotlib, consultez nos cours Manipulation de données avec pandas, Introduction à NumPy et Introduction à la visualisation de données avec Matplotlib.
Nous utiliserons l'ensemble de données Boston Housing Prices, qui peut être chargé à partir de la bibliothèque Scikit-Learn. Cet ensemble de données fournit la valeur des logements dans différents quartiers de Boston, ainsi que plusieurs attributs tels que le taux de criminalité, le nombre moyen de pièces, etc.
from sklearn.datasets import load_boston
boston = load_boston()
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df['MEDV'] = boston.target
Le fait de disposer de données appropriées pour vos histogrammes est la clé de leur succès ou de leur échec. Dans ce cas, nous utilisons une variable continue, la valeur médiane des logements occupés par leur propriétaire (MEDV) à Boston.
Comme les histogrammes montrent généralement la distribution d'une seule variable, nous allons sélectionner une colonne de notre DataFrame.
Nouveau dans Scikit-Learn ? Consultez notre tutoriel sur l'apprentissage automatique en Python. Si vous souhaitez plus d'informations, notre cours Apprentissage supervisé avec scikit-learn vous aidera à couvrir les bases.
Avant de commencer, voici quelques pré-requis de base avant de commencer à construire votre histogramme Seaborn :
Nous allons commencer par passer en revue la syntaxe et les paramètres courants de la fonction `sns.histplot`.
La syntaxe de base pour créer un histogramme avec `sns.histplot` est simple.
Les principaux paramètres sont les suivants :
data: L'ensemble de données, qui est souvent un DataFrame Pandas.x: La variable pour laquelle l'histogramme est tracé.color: Pour spécifier la couleur des barres.alpha: Transparence des barres.bins: Le nombre de bins (groupes de barres) à utiliser.binwidth: La largeur de chaque case.kde: Un booléen pour ajouter un graphique d'estimation de la densité du noyau.hue: Différencier des sous-ensembles de données en fonction d'une autre variable.La fonction accepte de nombreux paramètres et arguments, mais nous nous concentrerons sur ceux qui sont nécessaires pour notre ensemble de données.
Créons un histogramme de base pour visualiser la distribution des prix médians des logements (VLM).
plt.figure(figsize=(10, 6))
sns.histplot(data=df, x='MEDV')
plt.title('Distribution of Median Housing Prices in Boston')
plt.xlabel('Median Value of Owner-Occupied Homes (in $1000)')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()
Cette commande permet d'afficher l'histogramme de la colonne MEDV.
Voici le graphique généré à partir de ce code :
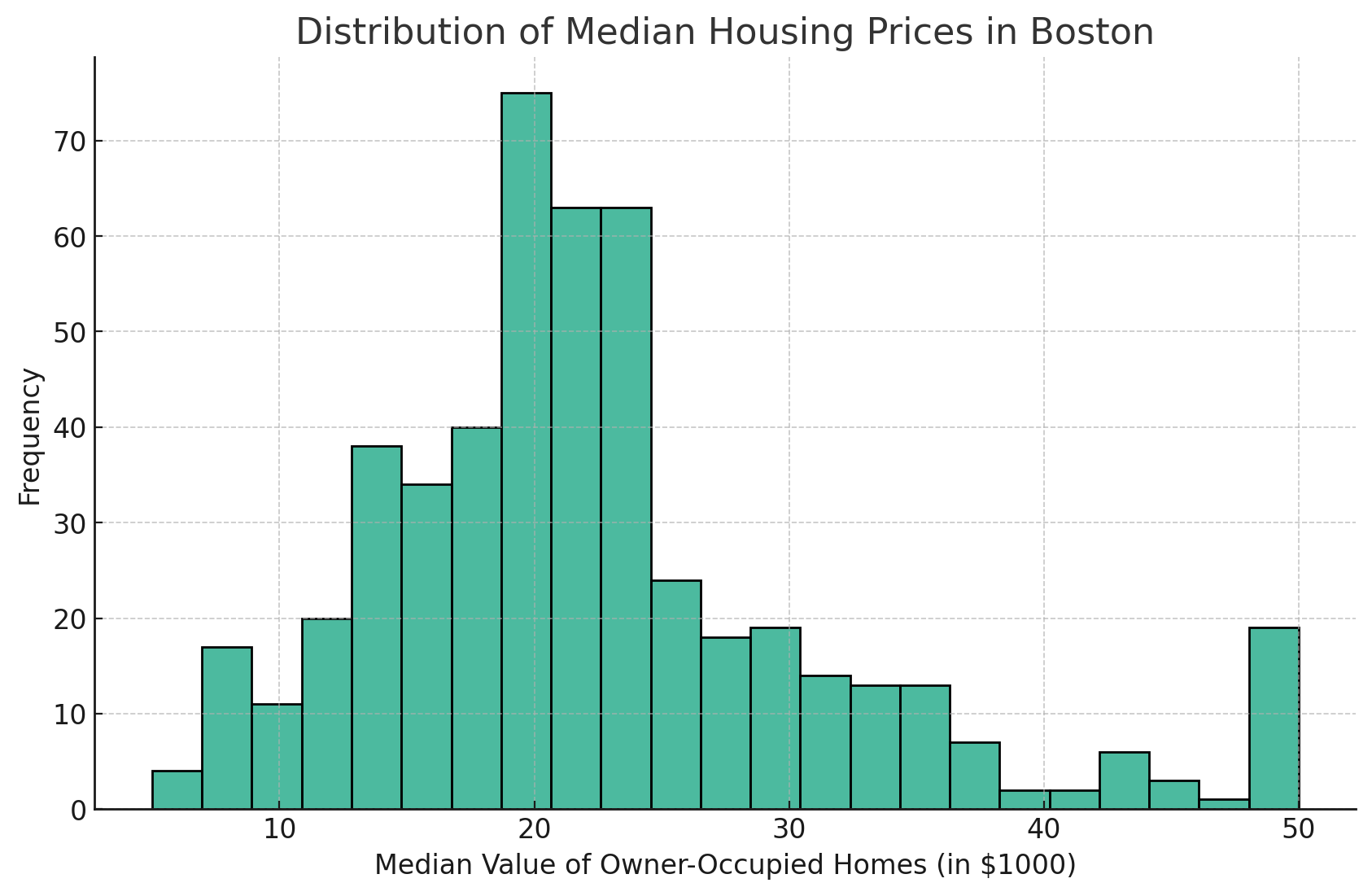
Voici l'histogramme montrant la distribution des prix médians des logements (MEDV) dans l'ensemble de données de Boston. L'histogramme fournit une représentation visuelle de la distribution de fréquence des valeurs médianes des logements occupés par leurs propriétaires.
L'ajustement du nombre de bacs peut aider à mieux comprendre la distribution. Un plus grand nombre de cases peut révéler plus de détails, tandis qu'un nombre plus faible simplifie la visualisation.
Pour augmenter le nombre de bins, vous pouvez modifier le paramètre bins.
En voici un exemple :
plt.figure(figsize=(10, 6))
sns.histplot(data=df, x='MEDV', bins=30)
plt.title('Distribution of Median Housing Prices in Boston')
plt.xlabel('Median Value of Owner-Occupied Homes (in $1000)')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()
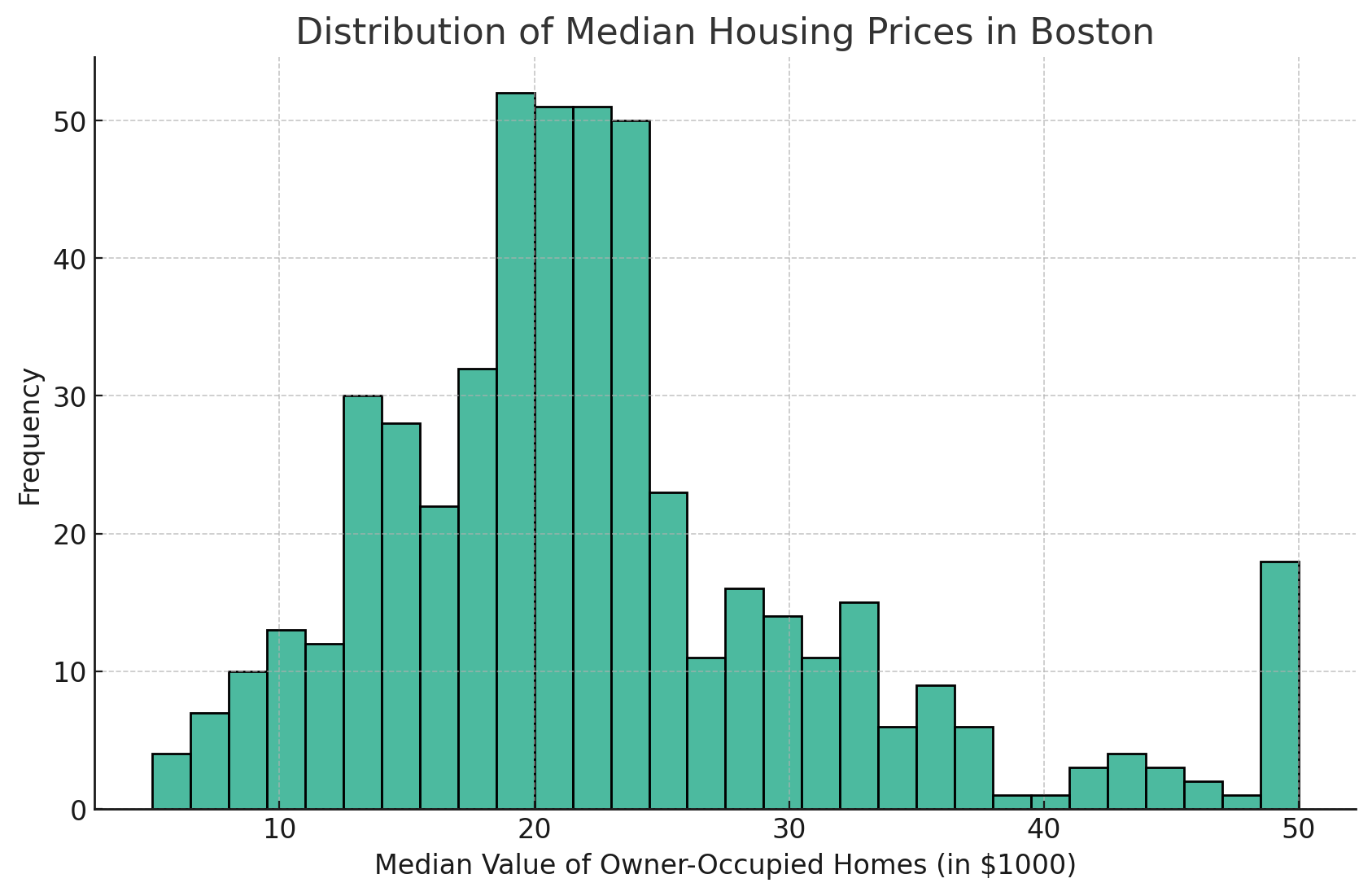
Comme vous pouvez le voir dans l'histogramme Seaborn ci-dessus, le nombre de barres a augmenté jusqu'au nombre que j'ai fixé, qui, dans ce cas, est de 30. C'est un bon moyen d'approfondir les détails pour obtenir une plus grande granularité de vos données.
La personnalisation de l'esthétique, comme la modification de la couleur des barres et de la transparence, peut rendre l'histogramme plus informatif et plus attrayant visuellement.
Dans l'exemple ci-dessous, j'ai recréé notre histogramme original en utilisant du violet au lieu de la couleur par défaut.
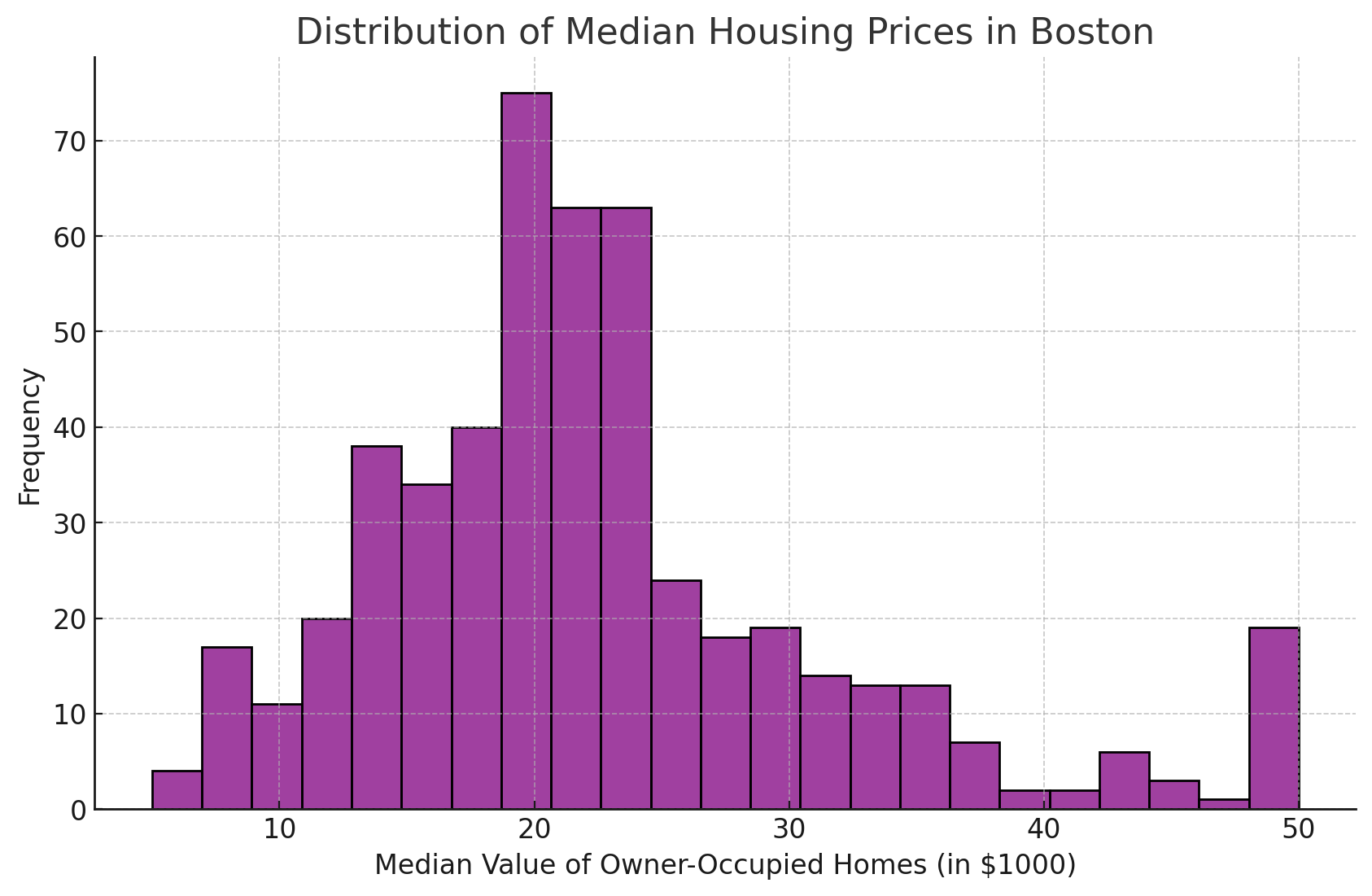
Voici le code que j'ai utilisé pour créer le graphique ci-dessus.
plt.figure(figsize=(10, 6))
sns.histplot(data=df, x='MEDV', color='purple')
plt.title('Distribution of Median Housing Prices in Boston')
plt.xlabel('Median Value of Owner-Occupied Homes (in $1000)')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()
KDE fournit une estimation lisse de la distribution des données. Elle peut être particulièrement utile pour identifier des schémas dans les données.
Cela crée une courbe lisse qui peut aider à visualiser les tendances générales.
Pour ce faire, nous utilisons le paramètre kde dans cette fonction :
plt.figure(figsize=(10, 6))
sns.histplot(data=df, x='MEDV', kde=True)
plt.title('Distribution of Median Housing Prices in Boston')
plt.xlabel('Median Value of Owner-Occupied Homes (in $1000)')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()
Cela permet d'obtenir une belle courbe pour notre histogramme, comme indiqué ci-dessous.
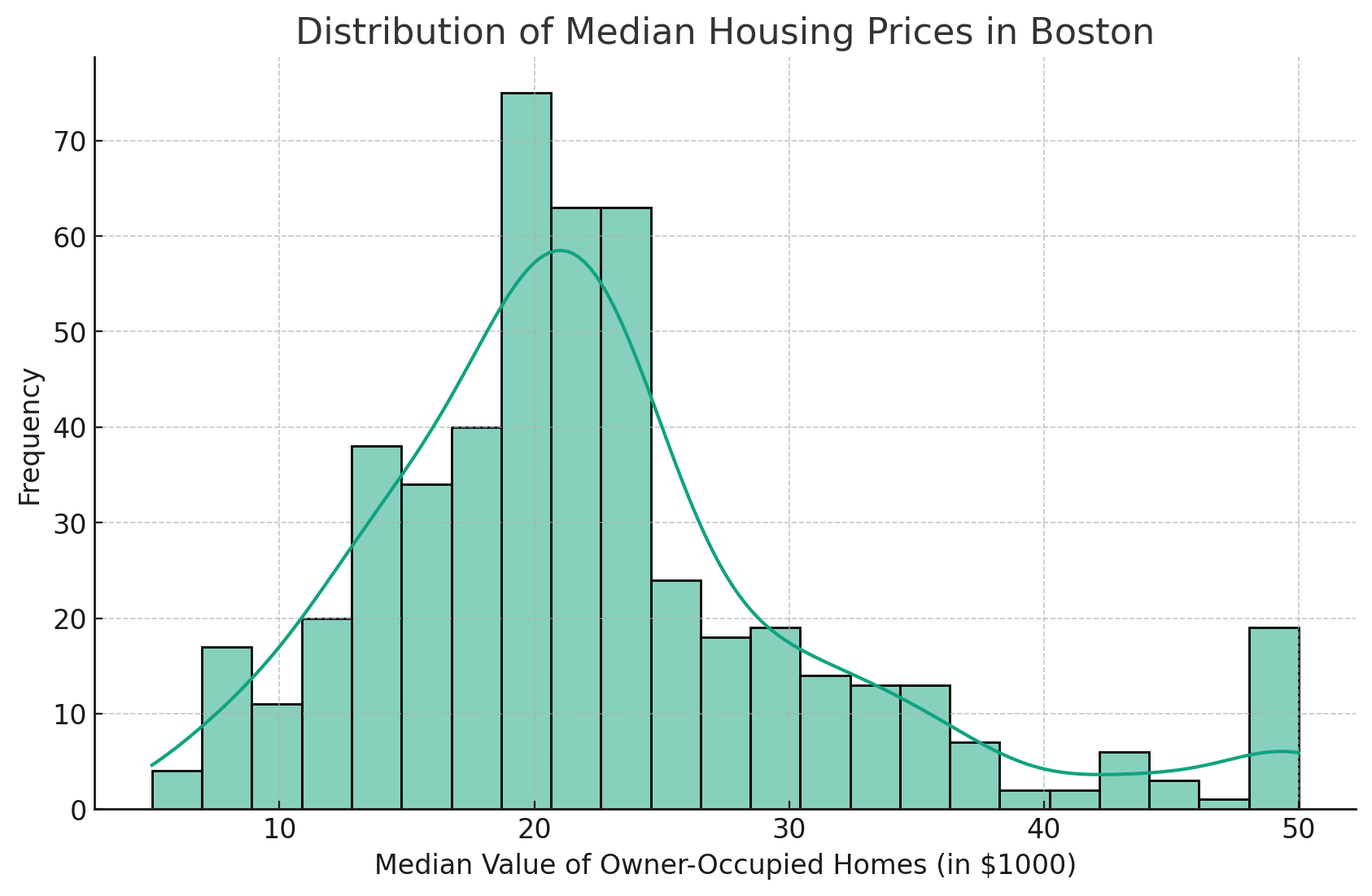
L'ajout de la ligne Kernel Density Estimate (KDE) permet d'obtenir une estimation plus lisse de la distribution.
Le paramètre de teinte permet de comparer les différentes catégories de l'histogramme.
Ce paramètre nous permet de distinguer différentes catégories au sein d'un même histogramme, ce qui permet de comparer visuellement les distributions.
En d'autres termes, elle prend une colonne catégorielle du DataFrame et différencie les données à l'aide de différentes couleurs.
Par exemple, si nous avons une colonne nommée "CHAS" dans notre DataFrame, qui indique si une maison se trouve le long de la Charles River (1) ou non (0), nous pouvons utiliser le paramètre "hue" pour comparer la distribution des prix médians des maisons qui se trouvent près de la rivière par rapport à celles qui n'y sont pas.
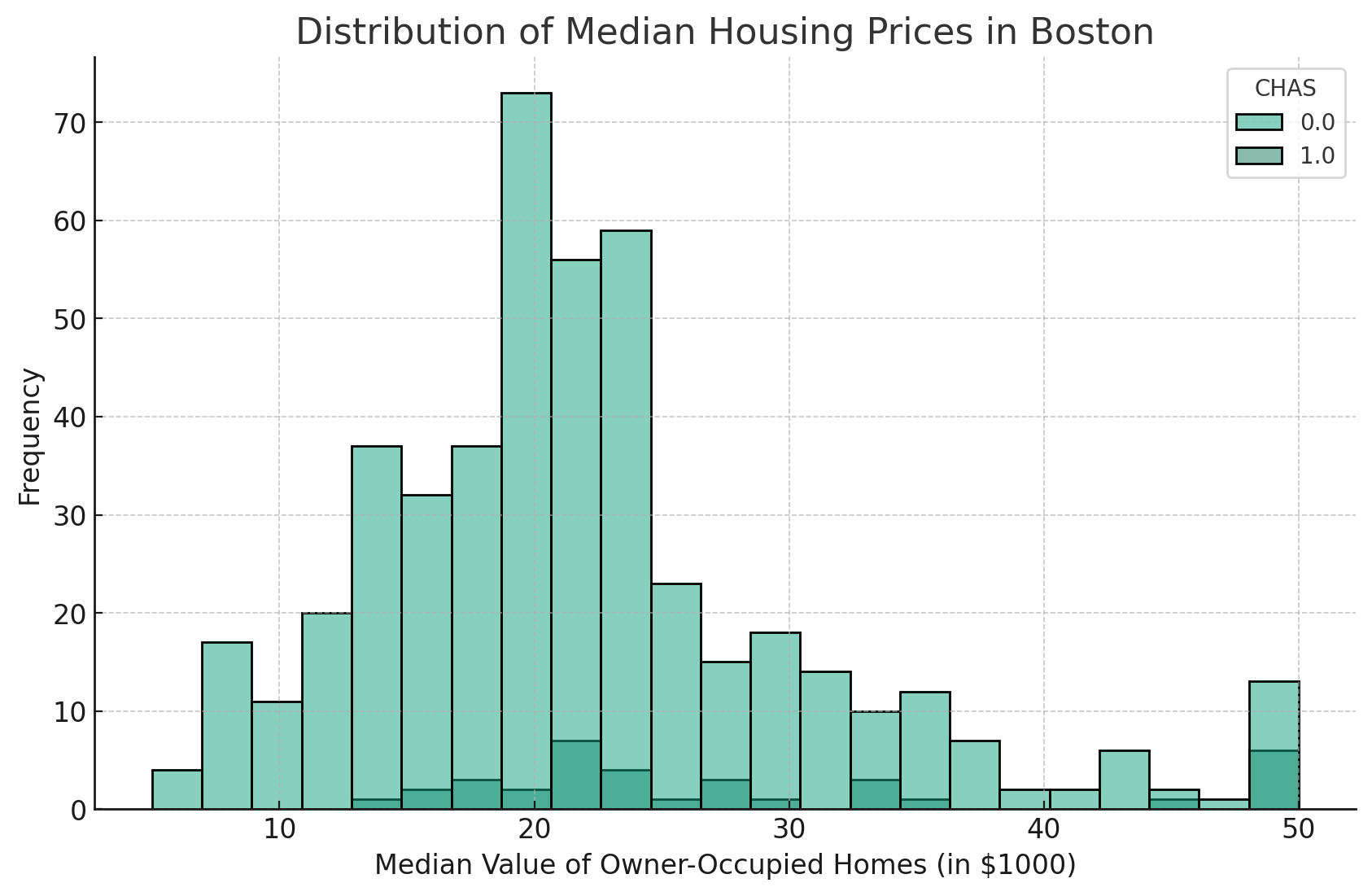
Le code se présente comme suit :
plt.figure(figsize=(10, 6))
sns.histplot(data=df, x='MEDV', hue='CHAS')
plt.title('Distribution of Median Housing Prices in Boston')
plt.xlabel('Median Value of Owner-Occupied Homes (in $1000)')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()
Vous obtiendrez ainsi un histogramme dans lequel la distribution de MEDV pour les maisons bordant Charles River (CHAS=1) est différenciée de celle des maisons ne bordant pas la rivière (CHAS=0), chacune étant représentée par une couleur différente.
Lorsque vous construisez des histogrammes Seaborn, plusieurs aspects doivent être pris en compte, comme indiqué ci-dessous :
La sélection du nombre optimal de cellules est essentielle à la création d'un histogramme informatif. Si un plus grand nombre de bacs permet d'obtenir plus de détails, il peut également conduire à un surajustement et à une représentation erronée des données.
D'autre part, un trop petit nombre de cases peut simplifier à l'excès la distribution.
Une façon de choisir le bon nombre de bacs est d'utiliser une règle empirique appelée règle de Scott. Cette règle calcule la taille idéale des cases en fonction du nombre de points de données dans l'ensemble de données.
S'il est important de fournir suffisamment de détails dans un histogramme, il est également essentiel de veiller à ce que la visualisation reste claire et facile à interpréter.
L'ajout d'un trop grand nombre d'éléments, tels que des lignes KDE ou un trop grand nombre de couleurs, peut conduire à des visuels encombrés et difficiles à comprendre.
Il est préférable de trouver un équilibre entre l'ajout d'éléments informatifs et le maintien de la simplicité.
Le type de données visualisées joue également un rôle dans la sélection des paramètres appropriés de l'histogramme.
Par exemple, les variables continues nécessiteront des tailles de cases différentes de celles des variables catégorielles.
Il est important de tenir compte de la nature des données lors de la création des histogrammes afin de s'assurer qu'ils représentent correctement la distribution.
Cependant, Seaborn n'est qu'une des bibliothèques disponibles pour la visualisation de données en Python. Vous pouvez également envisager de créer vos histogrammes dans Matplotlib si vous préférez.
Seaborn est une bibliothèque puissante pour créer des visualisations en Python, et la fonction `histplot` permet de créer facilement des histogrammes. En changeant simplement les paramètres de la fonction, vous pouvez modifier l'aspect de votre graphique afin d'obtenir le niveau de détail et l'esthétique que vous souhaitez.
N'oubliez pas tous les conseils relatifs aux histogrammes Seaborn mentionnés ci-dessus : tenez toujours compte du type de données, choisissez des tailles de cellules appropriées et équilibrez les détails avec la clarté lorsque vous créez des histogrammes à l'aide de Seaborn.
Vous souhaitez en savoir plus sur Seaborn et ses autres puissantes fonctionnalités de visualisation de données ? Notre cours Introduction à la visualisation de données avec Seaborn est un excellent cours pour les débutants.
Commencez votre voyage Seaborn dès aujourd'hui !
Cours
Cours
Cours
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach