
Curso
Visualização intermediária de dados com a Seaborn
4 h
75K
A visualização de dados é um componente essencial para a interpretação de conjuntos de dados complexos.
No âmbito da programação Python, a Seaborn se destaca como uma biblioteca avançada para a criação de gráficos estatísticos informativos e visualmente atraentes, como histogramas e gráficos de linhas.
Ele se baseia nos recursos do Matplotlib, aprimorando sua interface e oferecendo mais opções de visualização de dados, especialmente para análise estatística. A integração perfeita do Seaborn com o Pandas DataFrames o torna um dos favoritos entre os cientistas e analistas de dados.
Neste guia detalhado, vamos nos concentrar em um dos gráficos mais usados no Seaborn: o histograma.
sns.histplot funçãoA função sns.histplot do Seaborn foi projetada para desenhar histogramas, que são essenciais para examinar a distribuição de dados contínuos. Essa função é versátil e permite uma ampla personalização, facilitando a obtenção de percepções significativas dos dados.
Essa função é uma das muitas funções disponíveis na biblioteca do Seaborn. Dê uma olhada nesta folha de dicas abaixo para ter uma visão geral rápida.
Seaborn para a folha de dicas de ciência de dados - fonte
Antes de mergulhar na visualização de dados, precisamos configurar nosso ambiente. Isso envolve a importação das bibliotecas necessárias, sendo o Seaborn o foco principal. O Seaborn é normalmente importado como sns por conveniência.
Além do Seaborn, outras bibliotecas essenciais geralmente incluem o NumPy para operações numéricas, o pandas para manipulação de dados e o Matplotlib para opções adicionais de personalização.
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
Todas essas bibliotecas são essenciais e fornecem as ferramentas necessárias para criar e manipular visualizações de dados em Python. Elas são as bibliotecas mais comumente usadas por analistas e cientistas de dados.
Se você está começando a aprender Python, sugiro que experimente nosso curso Introduction to Python. Para que você possa aprender mais sobre pandas, NumPy e Matplotlib, faça nossos cursos Manipulação de dados com pandas, Introdução ao NumPy e Introdução à visualização de dados com Matplotlib.
Usaremos o conjunto de dados Boston Housing Prices, que pode ser carregado na biblioteca Scikit-Learn. Esse conjunto de dados fornece valores de moradia em diferentes áreas de Boston, juntamente com vários atributos, como taxa de criminalidade, número médio de quartos, etc.
from sklearn.datasets import load_boston
boston = load_boston()
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df['MEDV'] = boston.target
Ter dados adequados para seus histogramas é o que faz com que eles sejam bons ou ruins. Nesse caso, estamos usando uma variável contínua, o valor médio das residências ocupadas pelos proprietários (MEDV) em Boston.
Como os histogramas normalmente mostram a distribuição de uma única variável, selecionaremos uma coluna do nosso DataFrame.
Você é novo no Scikit-Learn? Dê uma olhada em nosso tutorial sobre aprendizado de máquina em Python. Se você quiser obter mais informações, nosso curso Aprendizado supervisionado com o scikit-learn ajudará a cobrir os conceitos básicos.
Antes de começar, aqui estão alguns pré-requisitos básicos para você começar a criar o histograma do Seaborn:
Começaremos analisando alguns dos parâmetros e sintaxe comuns da função `sns.histplot`.
A sintaxe básica para criar um histograma usando o `sns.histplot` é simples.
Os principais parâmetros incluem:
data: O conjunto de dados, que geralmente é um Pandas DataFrame.x: A variável para a qual o histograma é plotado.color: Para especificar a cor das barras.alpha: Transparência das barras.bins: O número de compartimentos (grupos de barras) a serem usados.binwidth: A largura de cada compartimento.kde: Um booleano para adicionar um gráfico de estimativa de densidade de kernel.hue: Para diferenciar subconjuntos de dados com base em outra variável.A função aceita muitos parâmetros e argumentos, mas vamos nos concentrar nos que são necessários para o nosso conjunto de dados.
Vamos criar um histograma básico para visualizar a distribuição dos preços médios de moradia (MEDV).
plt.figure(figsize=(10, 6))
sns.histplot(data=df, x='MEDV')
plt.title('Distribution of Median Housing Prices in Boston')
plt.xlabel('Median Value of Owner-Occupied Homes (in $1000)')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()
Esse comando exibirá o histograma da coluna MEDV.
Aqui está o gráfico gerado por esse código:
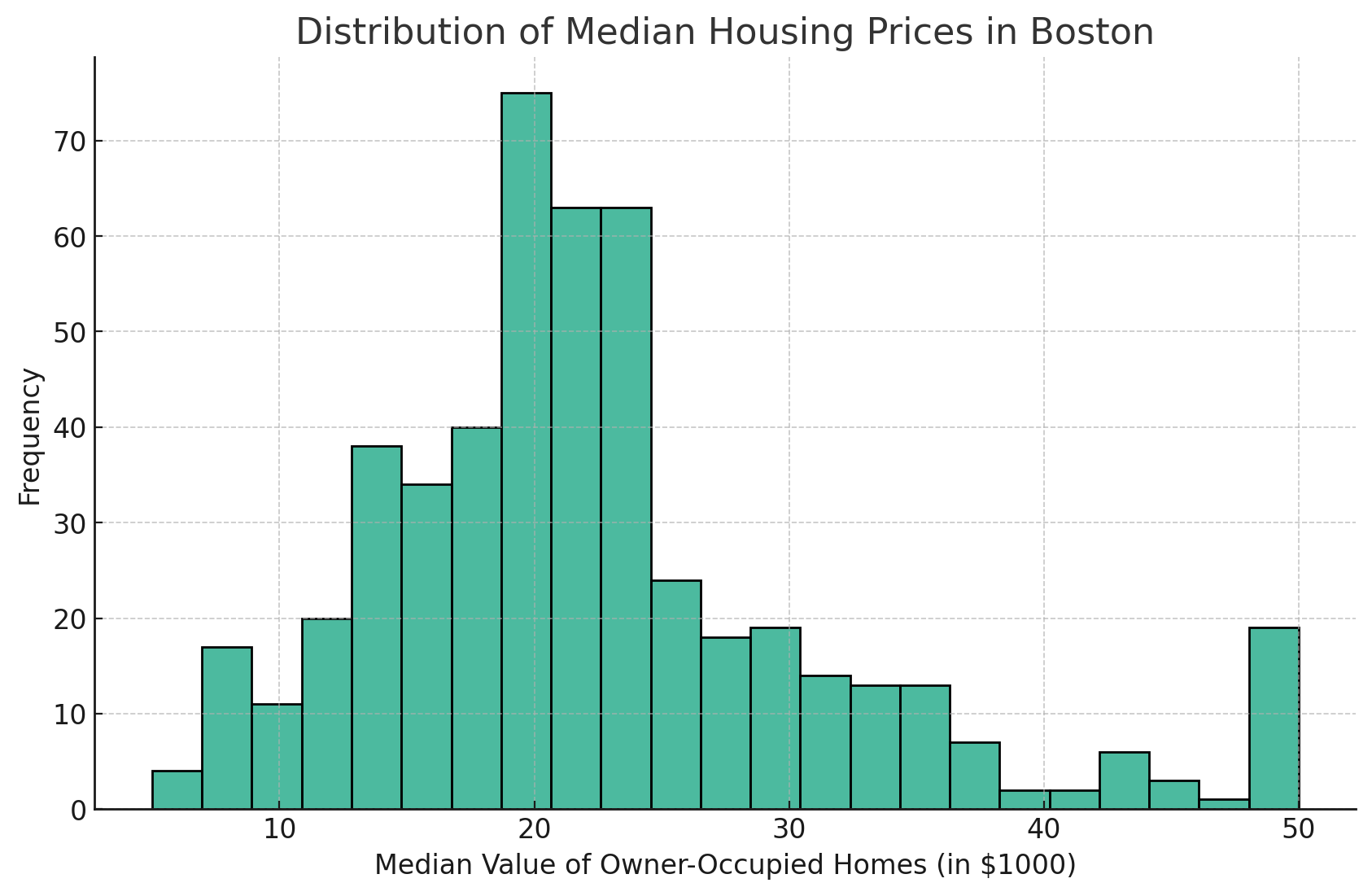
Aqui está o gráfico de histograma que mostra a distribuição dos preços médios de moradia (MEDV) no conjunto de dados de Boston. O histograma fornece uma representação visual da distribuição de frequência dos valores medianos de residências ocupadas por proprietários.
O ajuste do número de compartimentos pode ajudar você a entender melhor a distribuição. Um número maior de compartimentos pode revelar mais detalhes, enquanto um número menor simplifica a visualização.
Para aumentar o número de compartimentos, você pode modificar o parâmetro bins.
Aqui está um exemplo:
plt.figure(figsize=(10, 6))
sns.histplot(data=df, x='MEDV', bins=30)
plt.title('Distribution of Median Housing Prices in Boston')
plt.xlabel('Median Value of Owner-Occupied Homes (in $1000)')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()
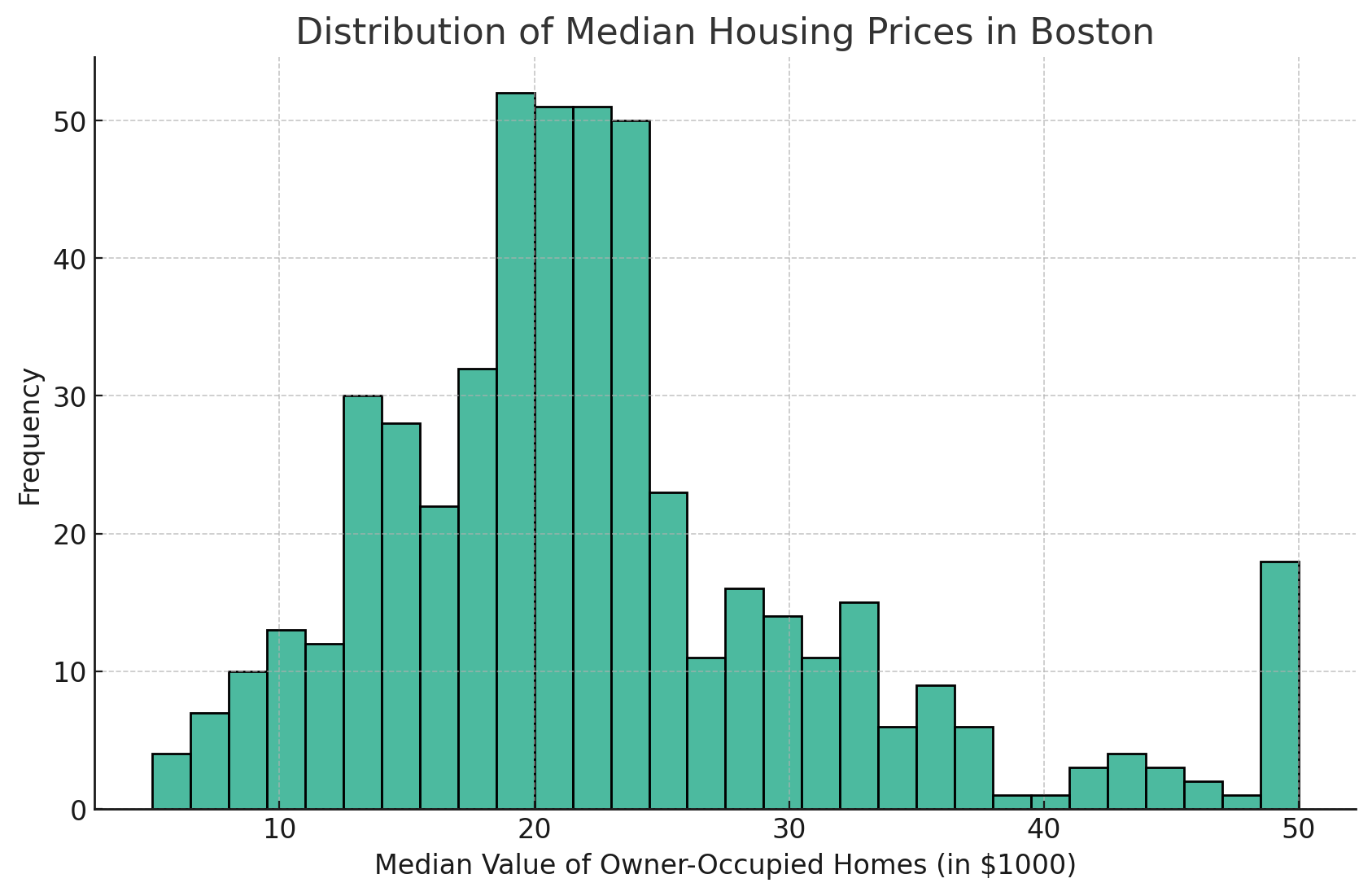
Como você pode ver no histograma do Seaborn acima, o número de barras aumentou até o valor que defini, que, nesse caso, é 30. Essa é uma boa maneira de se aprofundar nos detalhes para obter mais granularidade de seus dados.
A personalização da estética, como a alteração da cor e da transparência da barra, pode tornar o histograma mais informativo e visualmente atraente.
No exemplo abaixo, recriei nosso histograma original usando roxo em vez da cor padrão.
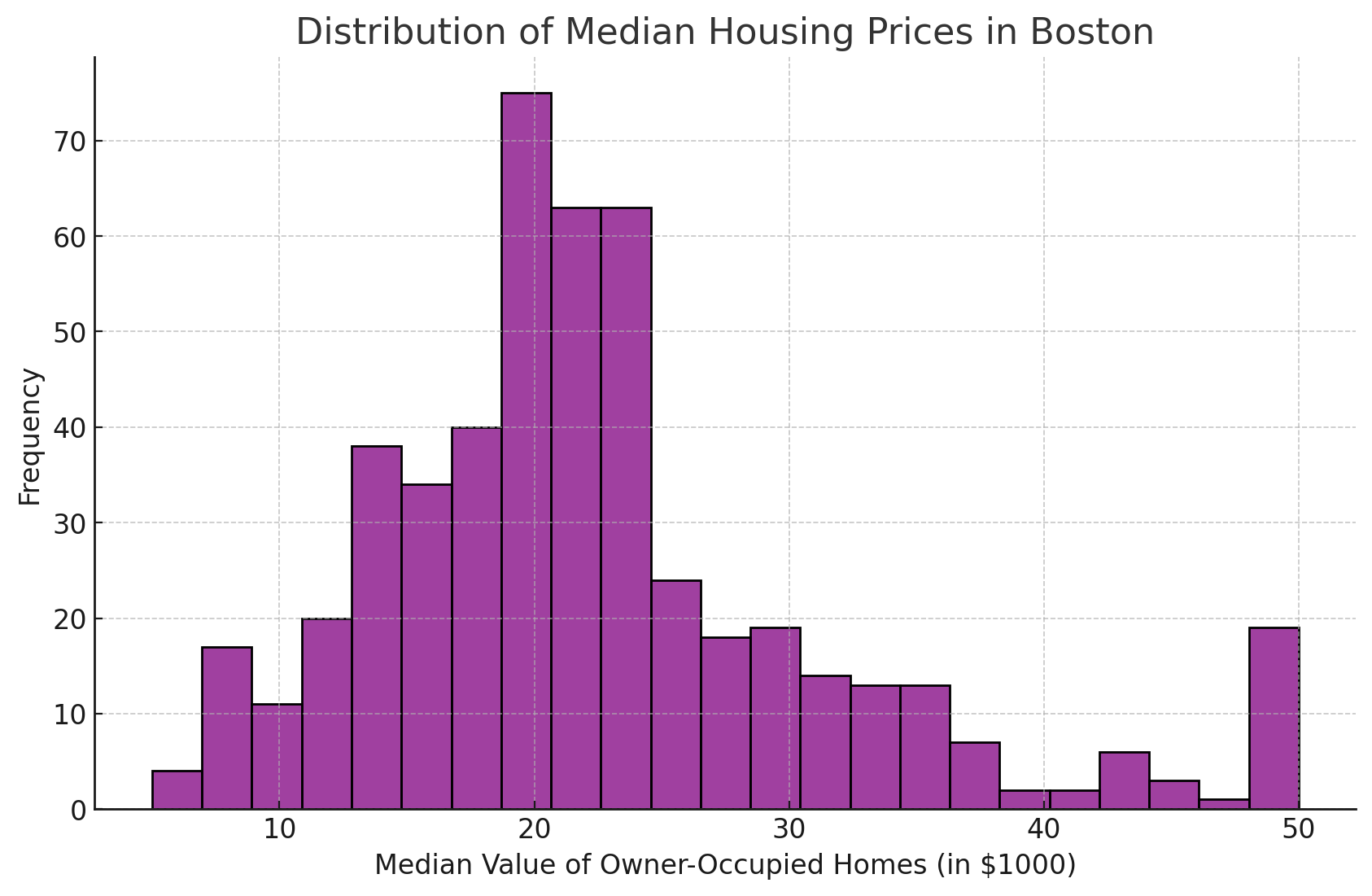
Aqui está o código que usei para criar o gráfico acima.
plt.figure(figsize=(10, 6))
sns.histplot(data=df, x='MEDV', color='purple')
plt.title('Distribution of Median Housing Prices in Boston')
plt.xlabel('Median Value of Owner-Occupied Homes (in $1000)')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()
O KDE fornece uma estimativa suave da distribuição de dados. Isso pode ser particularmente útil para identificar padrões nos dados.
Isso cria uma curva de linha suave que pode ajudar a visualizar as tendências gerais.
Para isso, usamos o parâmetro kde nessa função:
plt.figure(figsize=(10, 6))
sns.histplot(data=df, x='MEDV', kde=True)
plt.title('Distribution of Median Housing Prices in Boston')
plt.xlabel('Median Value of Owner-Occupied Homes (in $1000)')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()
Isso produzirá uma boa curva em nosso histograma, conforme mostrado abaixo.
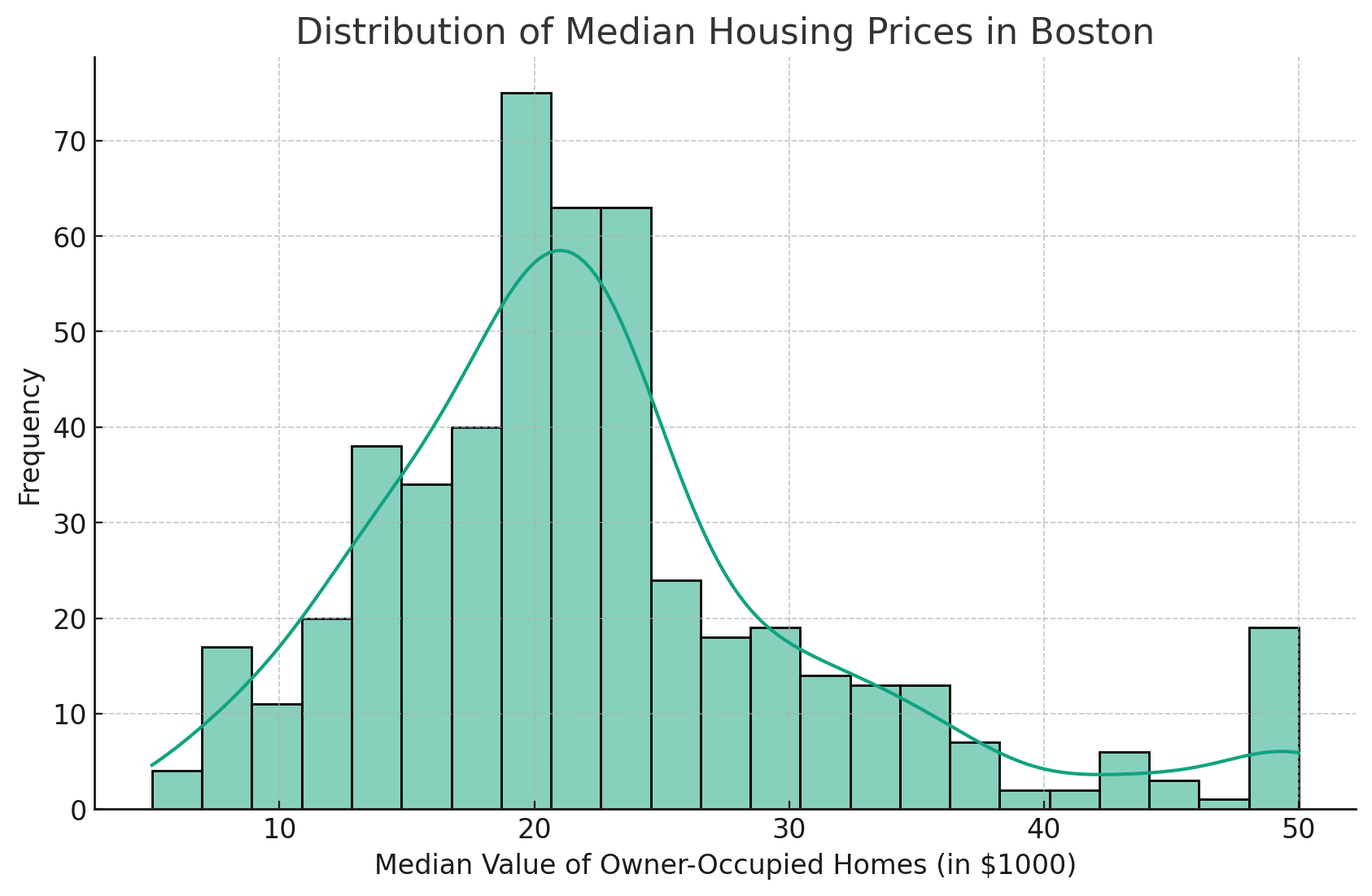
A adição da linha KDE (Kernel Density Estimate, estimativa de densidade do núcleo) fornece uma estimativa mais suave da distribuição.
O parâmetro de matiz permite a comparação de diferentes categorias dentro do histograma.
Esse parâmetro nos permite distinguir entre diferentes categorias dentro do mesmo histograma, proporcionando uma comparação visual das distribuições.
Simplificando, ele pega uma coluna categórica do DataFrame e diferencia os dados usando cores diferentes.
Por exemplo, se tivermos uma coluna chamada "CHAS" em nosso DataFrame, que indica se uma casa está ao longo do Charles River (1) ou não (0), podemos usar o parâmetro "hue" para comparar a distribuição dos preços medianos de moradias para casas que estão perto do rio e aquelas que não estão.
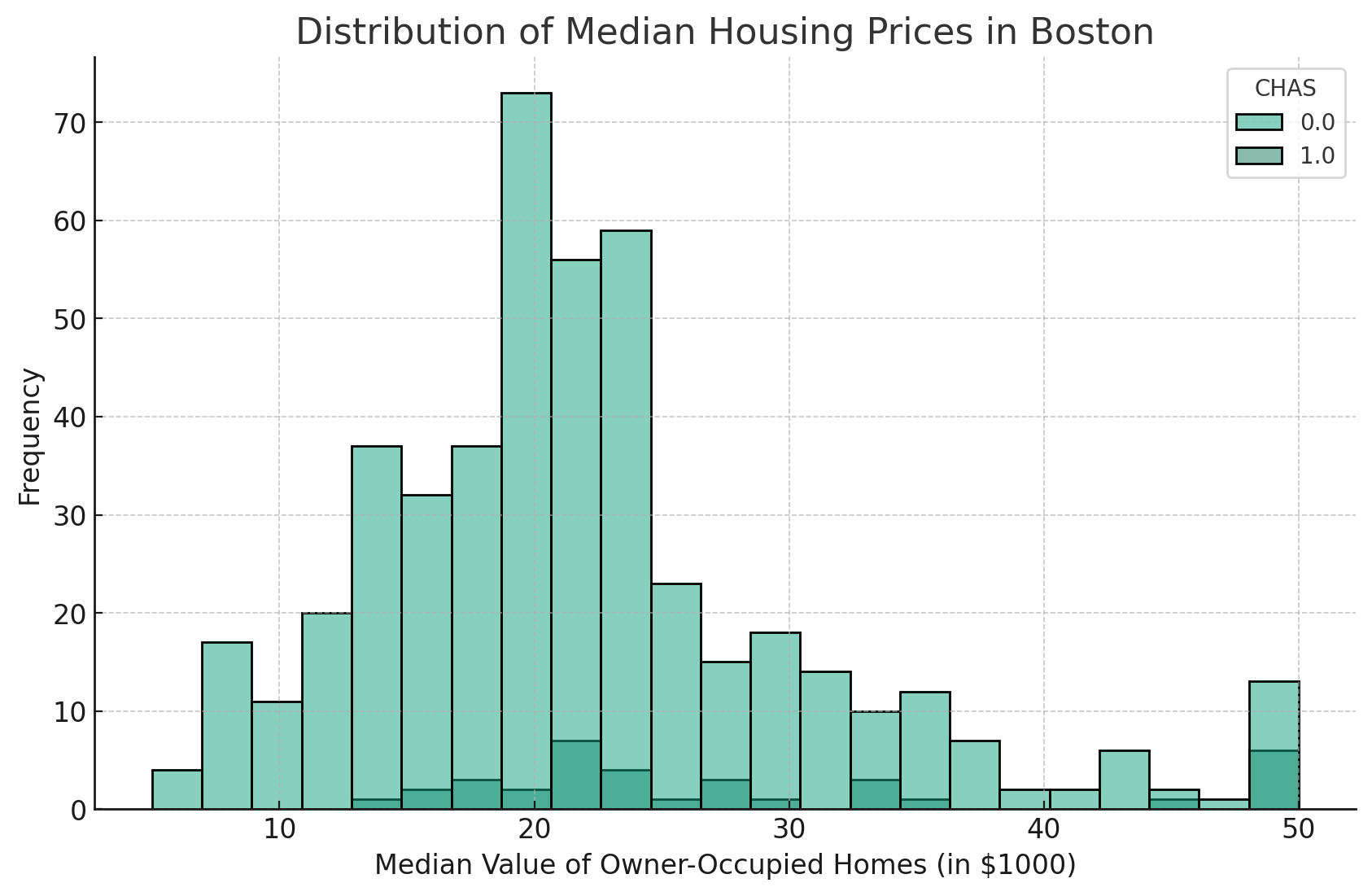
O código terá a seguinte aparência:
plt.figure(figsize=(10, 6))
sns.histplot(data=df, x='MEDV', hue='CHAS')
plt.title('Distribution of Median Housing Prices in Boston')
plt.xlabel('Median Value of Owner-Occupied Homes (in $1000)')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()
Isso gerará um histograma em que a distribuição de MEDV para residências que margeiam o Charles River (CHAS=1) é diferenciada daquelas que não margeiam o rio (CHAS=0), cada uma representada por uma cor diferente.
Quando você estiver criando histogramas do Seaborn, há vários aspectos que devem ser levados em conta, conforme descrito abaixo:
Selecionar o número ideal de compartimentos é fundamental para criar um histograma informativo. Embora um número maior de compartimentos possa fornecer mais detalhes, ele também pode levar a um ajuste excessivo e a uma representação incorreta dos dados.
Por outro lado, um número muito pequeno de compartimentos pode simplificar demais a distribuição.
Uma maneira de escolher o número certo de compartimentos é usar uma regra prática chamada Regra de Scott. Essa regra calcula o tamanho ideal do compartimento com base no número de pontos de dados no conjunto de dados.
Embora seja importante fornecer detalhes suficientes em um histograma, também é fundamental garantir que a visualização permaneça clara e fácil de interpretar.
A adição de muitos elementos, como linhas do KDE ou muitas cores, pode resultar em visuais desordenados e difíceis de entender.
É melhor você encontrar um equilíbrio entre adicionar elementos informativos e manter a simplicidade.
O tipo de dados que está sendo visualizado também desempenha um papel importante na seleção dos parâmetros apropriados do histograma.
Por exemplo, variáveis contínuas exigirão tamanhos de compartimento diferentes em comparação com variáveis categóricas.
É importante considerar a natureza dos dados ao criar histogramas para garantir que eles representem a distribuição com precisão.
No entanto, o Seaborn é apenas uma das bibliotecas disponíveis para visualização de dados em Python. Você também pode considerar a possibilidade de criar seus histogramas no Matplotlib, se preferir.
Seaborn é uma biblioteca avançada para criar visualizações em Python, e a função `histplot` permite que você crie histogramas facilmente. Apenas alterando os parâmetros da função, você pode modificar a aparência do gráfico para obter o nível de detalhe e a estética que deseja.
Lembre-se de todas as dicas de histograma do Seaborn mencionadas acima: sempre considere o tipo de dados, escolha tamanhos de compartimento apropriados e equilibre detalhes e clareza ao criar histogramas usando o Seaborn.
Você tem interesse em saber mais sobre o Seaborn e seus outros recursos avançados de visualização de dados? Nosso curso Introdução à visualização de dados com o Seaborn é um excelente curso para iniciantes.
Comece sua jornada na Seaborn hoje mesmo!
Curso
Curso
Curso
Tutorial
Elena Kosourova
Tutorial
Aditya Sharma
Tutorial
Arunn Thevapalan
Tutorial
Elena Kosourova
Tutorial
Kevin Babitz
Tutorial
Moez Ali

