
Curso
Extreme Gradient Boosting con XGBoost
4 h
60.7K
Python es uno de los lenguajes de programación más populares utilizados en diversas disciplinas tecnológicas, especialmente en ciencia de datos y machine learning. Python ofrece un lenguaje de alto nivel, orientado a objetos y fácil de programar, con una amplia colección de bibliotecas para multitud de casos de uso. Cuenta con más de 200 000 bibliotecas.
Una de las razones por las que Python es tan valioso para la ciencia de datos es su amplia colección de bibliotecas de manipulación de datos, visualización de datos, machine learning y aprendizaje profundo. Dado que Python cuenta con un ecosistema tan rico en bibliotecas de ciencia de datos, es casi imposible abarcarlo todo en un solo artículo. La lista de las mejores bibliotecas aquí se centra solo en cinco áreas principales:
Hay muchas otras áreas que no se incluyen en esta lista; por ejemplo, MLOps, Big Data y visión artificial. La lista que aparece en este blog no sigue ningún orden en particular y no pretende ser en modo alguno una clasificación.
NumPy es una de las bibliotecas Python de código abierto más utilizadas y se emplea principalmente para cálculos científicos. Tus funciones matemáticas integradas permiten realizar cálculos a gran velocidad y son compatibles con datos multidimensionales y matrices de gran tamaño. También se utiliza en álgebra lineal. Los arreglos NumPy suelen utilizarse preferentemente en lugar de las listas, ya que consumen menos memoria y son más prácticas y eficientes.
Según el sitio web de NumPy, se trata de un proyecto de código abierto cuyo objetivo es permitir el cálculo numérico con Python. Se creó en 2005 y se basó en los primeros trabajos de las bibliotecas Numeric y Numarray. Una de las grandes ventajas de NumPy es que se ha publicado bajo la licencia BSD modificada, por lo que siempre será de uso gratuito para todos.
NumPy se desarrolla de forma abierta en GitHub con el consenso de la comunidad NumPy y de la comunidad científica Python en general. Puedes obtener más información al respecto en nuestro curso introductorio sobre Numpy.
⭐ Estrellas de GitHub: 25K | Descargas totales: 2400 millones
Pandas es una biblioteca de código abierto que se utiliza habitualmente en ciencia de datos. Se utiliza principalmente para el análisis, la manipulación y la limpieza de datos. Pandas permite realizar operaciones sencillas de modelado y análisis de datos sin necesidad de escribir mucho código. Tal y como se indica en su sitio web, pandas es una herramienta de análisis y manipulación de datos de código abierto rápida, potente, flexible y fácil de usar. Algunas de las características principales de esta biblioteca son:
Empezar a utilizar pandas es sencillo y directo. Puedes consultar el curso «Analizar la actividad policial con pandas» de DataCamp para aprender a utilizar pandas en conjuntos de datos del mundo real.
⭐ Estrellas de GitHub: 41K | Descargas totales: 1600 millones
Aunque Pandas sigue siendo la opción predeterminada para datos pequeños, Polars se ha convertido en el estándar para el procesamiento de datos de alto rendimiento. Escrito en Rust, utiliza un motor de «evaluación perezosa» para procesar conjuntos de datos (de 10 GB a más de 100 GB) que normalmente bloquearían las máquinas con memoria RAM limitada. A diferencia de Pandas, que ejecuta las operaciones de forma secuencial, Polars optimiza las consultas de principio a fin y las ejecuta en paralelo en todos los núcleos de CPU disponibles.
Está diseñado para ser una actualización inmediata para cargas de trabajo pesadas, ofreciendo una sintaxis que suele ser más legible y entre 10 y 50 veces más rápida que los DataFrame tradicionales.
A continuación se muestra un ejemplo de código para realizar una selección filtrada, agrupada y agregada a partir de un enorme conjunto de datos CSV:
import polars as pl
# Lazy evaluation: Nothing runs until .collect() is called
# allowing Polars to optimize the query plan beforehand
q = (
pl.scan_csv("massive_dataset.csv")
.filter(pl.col("category") == "Technology")
.group_by("region")
.agg(pl.col("sales").sum())
)
df = q.collect() # Executes in parallel⭐ Estrellas de GitHub: Más de 40 000 | Estado: Estándar de alto rendimiento
Matplotlib es una amplia biblioteca para crear visualizaciones fijas, interactivas y animadas en Python. Un gran número de paquetes de terceros amplían y desarrollan la funcionalidad de Matplotlib, incluyendo varias interfaces de gráficando de alto nivel (Seaborn, HoloViews, ggplot, etc.).
Matplotlib está diseñado para ser tan funcional como MATLAB, con la ventaja adicional de poder utilizar Python. También tiene la ventaja de ser gratuito y de código abierto. Permite al usuario visualizar datos utilizando una variedad de tipos diferentes de gráficos, incluyendo, entre otros, diagramas de dispersión, histogramas, gráficos de barras, gráficos de errores y diagramas de caja. Además, todas las visualizaciones se pueden implementar con solo unas pocas líneas de código.
Ejemplos de gráficos desarrollados con Matplotlib
Empieza a utilizar Matplotlib con este tutorial paso a paso.
⭐ Estrellas de GitHub: 18,7 mil | Total de descargas: 653 millones
Seaborn, otro popular marco de visualización de datos de Python basado en Matplotlib, es una interfaz de alto nivel para crear imágenes estadísticas estéticamente atractivas y valiosas, que son fundamentales para estudiar y comprender los datos. Esta biblioteca de Python está estrechamente relacionada con las estructuras de datos NumPy y pandas. El principio fundamental de Seaborn es convertir la visualización en un componente esencial del análisis y la exploración de datos; por lo tanto, sus algoritmos de gráficando utilizan marcos de datos que abarcan conjuntos de datos completos.
Galería de ejemplos de Seaborn
Este tutorial de Seaborn para principiantes es un recurso excelente para familiarizarse con esta biblioteca de visualización dinámica.
⭐ Estrellas de GitHub: 11,6 K | Total de descargas: 180 millones
La popular biblioteca de gráficos de código abierto Plotly se puede utilizar para crear visualizaciones de datos interactivas. Plotly se basa en la biblioteca JavaScript Plotly (plotly.js) y se puede utilizar para crear visualizaciones de datos basadas en web que se pueden guardar como archivos HTML o mostrar en cuadernos Jupyter y aplicaciones web utilizando Dash.
Ofrece más de 40 tipos de gráficos únicos, como diagramas de dispersión, histogramas, gráficos de líneas, gráficos de barras, gráficos circulares, barras de error, diagramas de caja, ejes múltiples, minigráficos, dendrogramas y gráficos 3D. Plotly también ofrece gráficos de contorno, que no son tan comunes en otras bibliotecas de visualización de datos.
Si deseas visualizaciones interactivas o gráficos similares a paneles de control, Plotly es una buena alternativa a Matplotlib y Seaborn. Actualmente está disponible para su uso bajo la licencia MIT.
Puedes empezar a dominar Plotly hoy mismo con este curso de visualización de Plotly.
⭐ Estrellas de GitHub: 14,7 mil | Total de descargas: 190 millones
Los términos «machine learning» y «scikit-learn» son inseparables. Scikit-learn es una de las bibliotecas de machine learning más utilizadas en Python. Basada en NumPy, SciPy y Matplotlib, es una biblioteca Python de código abierto que se puede utilizar comercialmente bajo la licencia BSD. Es una herramienta sencilla y eficaz para tareas de análisis predictivo de datos.
Lanzado inicialmente en 2007 como un proyecto de Google Summer of Code, Scikit-learn es un proyecto impulsado por la comunidad; sin embargo, las subvenciones institucionales y privadas ayudan a garantizar su sostenibilidad.
Lo mejor de scikit-learn es que es muy fácil de usar.
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score
# Load the diabetes dataset
diabetes_X, diabetes_y = datasets.load_diabetes(return_X_y=True)
# Use only one feature
diabetes_X = diabetes_X[:, np.newaxis, 2]
# Split the data into training/testing sets
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
# Split the targets into training/testing sets
diabetes_y_train = diabetes_y[:-20]
diabetes_y_test = diabetes_y[-20:]
# Create linear regression object
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(diabetes_X_train, diabetes_y_train)
# Make predictions using the testing set
diabetes_y_pred = regr.predict(diabetes_X_test)Crédito: Código reproducido de la documentación oficial de scikit-learn.
Puedes probar scikit-learn por ti mismo con este tutorial introductorio sobre scikit-learn.
⭐ Estrellas de GitHub: 57K | Descargas totales: 703 millones
Atrás quedaron los días en que los científicos de datos solo entregaban informes PDF estáticos. Streamlit convierte scripts de Python en aplicaciones web interactivas y compartibles en cuestión de minutos. No requiere conocimientos de HTML, CSS ni JavaScript. En 2025, se utiliza ampliamente para crear herramientas internas, prototipos de paneles de control y demostraciones de modelos interactivos para las partes interesadas.
Con simples llamadas a la API como st.write() y st.slider(), puedes crear una interfaz que reaccione a los cambios en los datos en tiempo real, salvando la distancia entre el análisis y la ingeniería.
⭐ Estrellas de GitHub: 42K+ | Estado: Esencial para la entrega
Originalmente una herramienta de desarrollo web, Pydantic es ahora una piedra angular de la pila de IA. Realiza la validación de datos y la gestión de configuraciones utilizando anotaciones de tipo Python. En la era de los LLM, es fundamental garantizar que los datos (y los resultados de los modelos) se ajusten estrictamente a un esquema específico.
Pydantic es el motor que impulsa bibliotecas como LangChain y Hugging Face, garantizando que los desordenados resultados JSON de los modelos de IA se conviertan en objetos Python estructurados y válidos que no dañen tu código descendente.
⭐ Estrellas de GitHub: Más de 26 000 | Estado: Infraestructura crítica
LightGBM es una biblioteca de código abierto muy popular que utiliza algoritmos basados en árboles para el refuerzo de gradientes. Ofrece las siguientes ventajas:
Se puede utilizar tanto para tareas de clasificación supervisada como de regresión. Puedes consultar la documentación oficial o su GitHub para obtener más información sobre este increíble marco de trabajo.
⭐ Estrellas de GitHub: 15,8 K | Total de descargas: 162 millones
XGBoost es otra biblioteca de refuerzo de gradiente distribuido muy utilizada, creada para ser portátil, flexible y eficiente. Permite la implementación de algoritmos de machine learning dentro del marco de refuerzo de gradientes. XGBoost ofrece árboles de decisión potenciados por gradientes (GBDT), un potenciamiento de árboles paralelo que ofrece soluciones a muchos problemas de ciencia de datos de forma rápida y precisa. El mismo código se ejecuta en los principales entornos distribuidos (Hadoop, SGE, MPI) y puede resolver innumerables problemas.
XGBoost ha ganado una gran popularidad en los últimos años gracias a que ha ayudado a personas y equipos a ganar prácticamente todas las competiciones de datos estructurados de Kaggle. Las ventajas de XGBoost incluyen:
XGBoost ha sido desarrollado y mantenido por miembros activos de la comunidad y su uso está autorizado bajo la licencia Apache. Este tutorial de XGBoost es un recurso excelente si deseas obtener más información.
⭐ Estrellas de GitHub: 25,2 K | Total de descargas: 179 millones
Catboost es una biblioteca rápida, escalable y de alto rendimiento para el refuerzo de gradientes en árboles de decisión que se utiliza para tareas de clasificación, regresión y otras tareas de machine learning en Python, R, Java y C++. Admite cálculos en CPU y GPU.
Como sucesor del algoritmo MatrixNet, se utiliza ampliamente para tareas de clasificación, previsión y recomendación. Gracias a su carácter universal, se puede aplicar en una amplia gama de áreas y a una gran variedad de problemas.
Las ventajas de CatBoost según su repositorio son:
⭐ Estrellas de GitHub: 7,5 K | Total de descargas: 53 millones
Statsmodels proporciona clases y funciones que permiten a los usuarios estimar diversos modelos estadísticos, realizar pruebas estadísticas y explorar datos estadísticos. A continuación, se proporciona una lista completa de estadísticas de resultados para cada estimador. La precisión de los resultados se puede comprobar con los paquetes estadísticos existentes.
La mayoría de los resultados de las pruebas de la biblioteca se han verificado con al menos otro paquete estadístico: R, Stata o SAS. Algunas características de statsmodels son:
Este curso introductorio sobre modelos estadísticos es un excelente punto de partida si deseas aprender más.
⭐ Estrellas de GitHub: 9,2 mil | Total de descargas: 161 millones
El conjunto de bibliotecas de software de código abierto RAPIDS ejecuta procesos completos de ciencia de datos y análisis íntegramente en GPU. Se adapta perfectamente desde estaciones de trabajo con GPU hasta servidores con múltiples GPU y clústeres de múltiples nodos con Dask. El proyecto cuenta con el apoyo de NVIDIA y también se basa en Numba, Apache Arrow y muchos otros proyectos de código abierto.
cuDF es una biblioteca de GPU DataFrame que se utiliza para cargar, unir, agregar, filtrar y manipular datos. Se desarrolló basándose en el formato de memoria columnar que se encuentra en Apache Arrow. Proporciona una API similar a pandas que resultará familiar a los ingenieros y científicos de datos, lo que les permitirá acelerar fácilmente sus flujos de trabajo sin entrar en los detalles de la programación CUDA.
cuML es un conjunto de bibliotecas que implementa algoritmos de machine learning y funciones matemáticas primitivas que comparten API compatibles con otros proyectos RAPIDS. Permite a los científicos de datos, investigadores e ingenieros de software ejecutar tareas tradicionales de aprendizaje automático tabular en GPU sin entrar en los detalles de la programación CUDA. La API de Python de cuML suele coincidir con la API de scikit-learn.
Este marco de optimización de hiperparámetros de código abierto se utiliza principalmente para automatizar búsquedas de hiperparámetros. Utiliza bucles, condicionales y sintaxis de Python para buscar automáticamente los hiperparámetros óptimos y puede buscar en grandes espacios y descartar ensayos poco prometedores para obtener resultados más rápidos. Lo mejor de todo es que es fácil de paralelizar y escalar en grandes conjuntos de datos.
Características principales según tu repositorio GitHub:
⭐ Estrellas de GitHub: 9,1 mil | Total de descargas: 18 millones
Esta biblioteca de machine learning de código abierto, muy popular, automatiza los flujos de trabajo de machine learning en Python utilizando muy poco código. Es una herramienta integral para la gestión de modelos y machine learning que puede acelerar considerablemente el ciclo experimental.
En comparación con otras bibliotecas de machine learning de código abierto, PyCaret ofrece una solución de bajo código que puede sustituir cientos de líneas de código por unas pocas. Esto hace que los experimentos sean exponencialmente rápidos y eficientes.
PyCaret está actualmente disponible para su uso bajo la licencia MIT. Para obtener más información sobre PyCaret, puedes consultar la documentación oficial o su repositorio GitHub, o echar un vistazo a este tutorial introductorio sobre PyCaret.
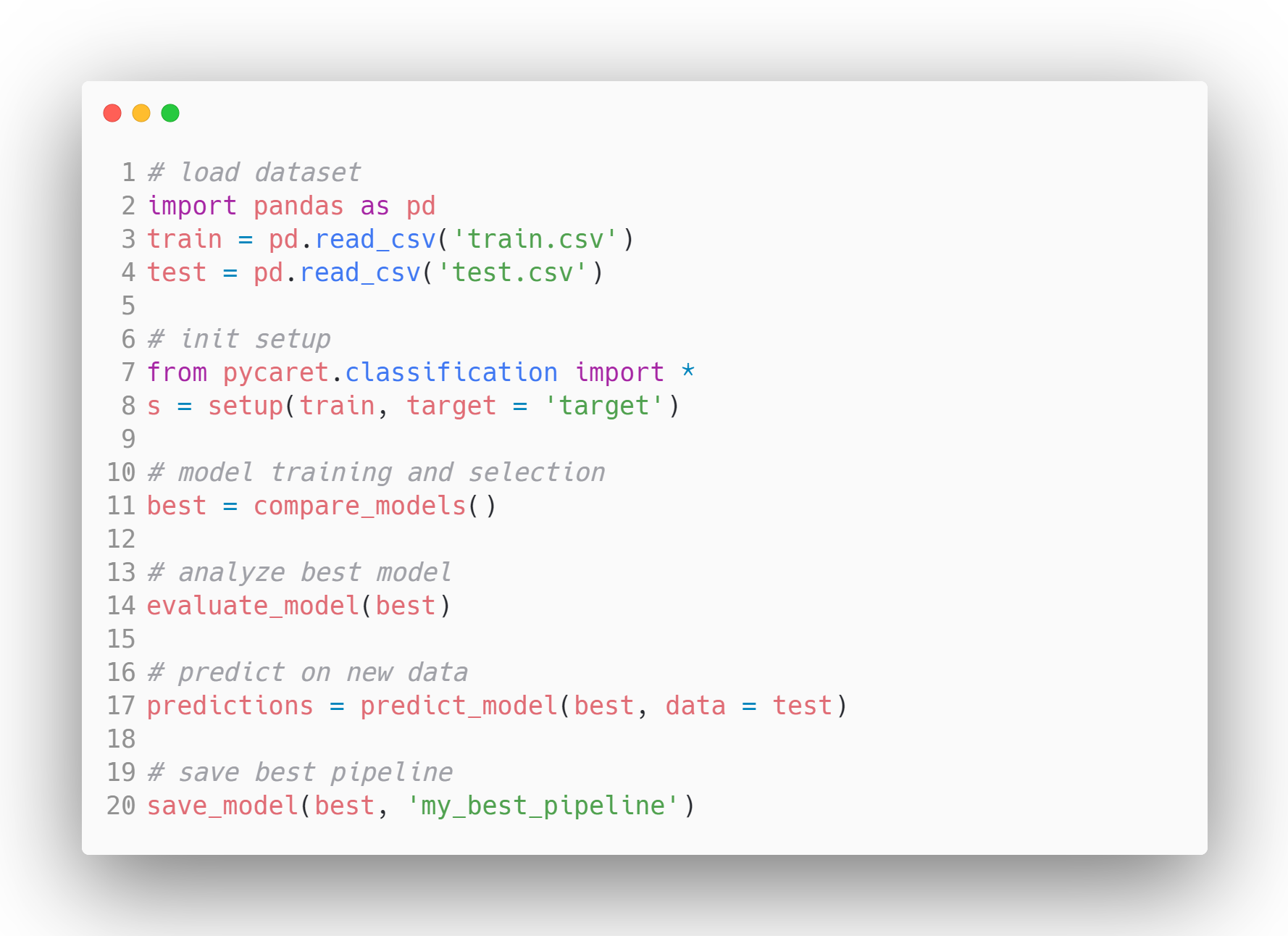
Ejemplo de flujo de trabajo del modelo en PyCaret - Fuente
⭐ Estrellas de GitHub: 8,1 mil | Total de descargas: 3,9 millones
H2O es una plataforma de machine learning y análisis predictivo que permite la construcción de modelos de machine learning sobre big data. También facilita la producción de esos modelos en un entorno empresarial.
El código principal de H2O está escrito en Java. Los algoritmos utilizan el marco Java Fork/Join para el multihilo y se implementan sobre el marco distribuido Map/Reduce de H2O.
H2O está licenciado bajo la licencia Apache, versión 2.0, y está disponible para los lenguajes Python, R y Java. Para obtener más información sobre H2O AutoML, consulta tu documentación oficial.
⭐ Estrellas de GitHub: 10,6 K | Total de descargas: 15,1 millones
Auto-sklearn es un conjunto de herramientas de machine learning automatizado y un sustituto adecuado del modelo scikit-learn. Realiza el ajuste de hiperparámetros y la selección de algoritmos de forma automática, lo que supone un ahorro considerable de tiempo para los profesionales del machine learning. Tu diseño refleja los últimos avances en metaaprendizaje, construcción de conjuntos y optimización bayesiana.
Creado como complemento de scikit-learn, auto-sklearn utiliza un procedimiento de búsqueda de optimización bayesiana para identificar el modelo de canalización con mejor rendimiento para un conjunto de datos determinado.
Auto-sklearn es extremadamente fácil de usar y se puede emplear tanto para tareas de clasificación supervisada como de regresión.
import autosklearn.classification
cls = autosklearn.classification.AutoSklearnClassifier()
cls.fit(X_train, y_train)
predictions = cls.predict(X_test)Fuente: Ejemplo reproducido de la documentación oficial de auto-sklearn.
Para obtener más información sobre auto-sklearn, consulta su repositorio GitHub.
⭐ Estrellas de GitHub: 7,3 mil | Total de descargas: 675K
FLAML es una biblioteca ligera de Python que identifica automáticamente modelos precisos de machine learning. Selecciona automáticamente los alumnos y los hiperparámetros, lo que ahorra a los profesionales del machine learning una cantidad considerable de tiempo y esfuerzo. Según vuestro repositorio GitHub, algunas de las características de FLAML son:
Con solo tres líneas de código, puedes obtener un estimador al estilo scikit-learn con este rápido motor AutoML.
from flaml import AutoML
automl = AutoML()
automl.fit(X_train, y_train, task="classification")Fuente: Ejemplo reproducido del repositorio oficial de GitHub.
⭐ Estrellas de GitHub: 3,5 K | Descargas totales: 456K
Mientras que otras bibliotecas AutoML se centran en la velocidad, AutoGluon (desarrollada por Amazon) se centra en la solidez y la precisión de vanguardia. Es famoso por su estrategia de «ensamblaje de capas múltiples», que a menudo te permite superar a los modelos ajustados por humanos en pruebas comparativas de datos tabulares.
No solo admite datos tabulares, sino también problemas multimodales. Esto significa que te permite entrenar un único predictor en un conjunto de datos que contiene columnas de texto, imágenes y números simultáneamente sin necesidad de realizar complejas operaciones de ingeniería de características.
El siguiente fragmento de código muestra la sintaxis de AutoGluon:
from autogluon.tabular import TabularPredictor
predictor = TabularPredictor(label='class').fit(train_data)
# AutoGluon automatically trains, tunes, and ensembles multiple models⭐ Estrellas de GitHub: Más de 10 000 | Estado: La mejor precisión de su clase
TensorFlow es una popular biblioteca de código abierto para cálculos numéricos de alto rendimiento desarrollada por el equipo Google Brain de Google, y un pilar fundamental en el campo de la investigación sobre aprendizaje profundo.
Tal y como se indica en la página web oficial, TensorFlow es una plataforma integral de código abierto para machine learning. Ofrece una amplia y versátil variedad de herramientas, bibliotecas y recursos comunitarios para investigadores y programadores de machine learning.
Algunas de las características de TensorFlow que lo convirtieron en una biblioteca de aprendizaje profundo popular y ampliamente utilizada:
Para obtener más información sobre TensorFlow, consulta su guía oficial o el repositorio GitHub, o prueba a utilizarlo tú mismo siguiendo este tutorial paso a paso de TensorFlow.
⭐ Estrellas de GitHub: 180 000 | Total de descargas: 384 millones
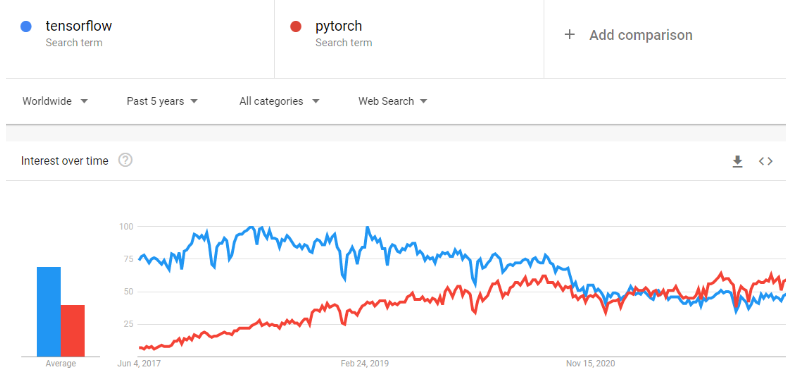
PyTorch es un marco de machine learning que acelera considerablemente el proceso desde la creación de prototipos de investigación hasta la implementación en producción. Es una biblioteca tensorial optimizada para el aprendizaje profundo que utiliza GPU y CPU, y se considera una alternativa a TensorFlow. Con el tiempo, la popularidad de PyTorch ha crecido hasta superar a TensorFlow en las tendencias de Google.
Ha sido desarrollado y es mantenido por Facebook, y actualmente está disponible para su uso bajo licencia BSD.
Según el sitio web oficial, las características principales de PyTorch son:
⭐ Estrellas de GitHub: 74K | Total de descargas: 119 millones
FastAI es una biblioteca de aprendizaje profundo que ofrece a los usuarios componentes de alto nivel que pueden generar resultados de vanguardia sin esfuerzo. También incluye componentes de bajo nivel que pueden intercambiarse para desarrollar nuevos enfoques. Su objetivo es hacer ambas cosas sin comprometer sustancialmente tu facilidad de uso, flexibilidad o rendimiento.
Características:
Para obtener más información sobre el proyecto, consulta tu documentación oficial.
⭐ Estrellas de GitHub: 25,1 mil | Total de descargas: 6,1 millones
Keras es una API de aprendizaje profundo diseñada para seres humanos, no para máquinas. Keras sigue las mejores prácticas para reducir la carga cognitiva: ofrece API coherentes y sencillas, minimiza el número de acciones que deben realizar los usuarios en los casos de uso más habituales y proporciona mensajes de error claros y prácticos. Keras es tan intuitivo que TensorFlow lo adoptó como su API predeterminada en la versión TF 2.0.
Keras ofrece un mecanismo más sencillo para expresar redes neuronales y también incluye algunas de las mejores herramientas para desarrollar modelos, procesar conjuntos de datos, visualizar gráficos y mucho más.
Características:
Para obtener más información sobre Keras, consulta tu documentación oficial o realiza este curso introductorio: Aprendizaje profundo con Keras.
⭐ Estrellas de GitHub: 60,2 K | Total de descargas: 163 millones
PyTorch Lightning ofrece una interfaz de alto nivel para PyTorch. Tu marco ligero y de alto rendimiento puede organizar el código PyTorch para separar la investigación de la ingeniería, lo que facilita la comprensión y reproducción de los experimentos de aprendizaje profundo. Se desarrolló para crear modelos de aprendizaje profundo escalables que puedan ejecutarse sin problemas en hardware distribuido.
Según el sitio web oficial, PyTorch Lightning está diseñado para que puedas dedicar más tiempo a la investigación y menos a la ingeniería. Una rápida refactorización te permitirá:
Para obtener más información sobre esta biblioteca, visita su sitio web oficial.
⭐ Estrellas de GitHub: 25,6 K | Total de descargas: 18,2 millones
JAX es una biblioteca de computación numérica de alto rendimiento desarrollada por Google. Mientras que PyTorch es el estándar fácil de usar, JAX es el «coche de Fórmula 1» utilizado por los investigadores (incluido DeepMind) que necesitan una velocidad extrema. Permite compilar automáticamente el código NumPy para ejecutarlo en aceleradores (GPU/TPU) a través de XLA (álgebra lineal acelerada).
Su capacidad para realizar diferenciaciones automáticas en funciones nativas de Python lo convierte en uno de los favoritos para desarrollar nuevos algoritmos desde cero, especialmente en el modelado generativo y las simulaciones físicas.
⭐ Estrellas de GitHub: Más de 35 000 | Estado: Norma de investigación
spaCy es una biblioteca de procesamiento del lenguaje natural de código abierto y potencia industrial en Python. spaCy destaca en tareas de extracción de información a gran escala. Está escrito desde cero en Cython, con una gestión cuidadosa de la memoria. spaCy es la biblioteca ideal si tu aplicación necesita procesar grandes volúmenes de datos web.
Características:
Para obtener más información sobre spaCy, visita su sitio web oficial o el repositorio GitHub. También puedes familiarizarte rápidamente con sus funcionalidades utilizando esta práctica hoja de referencia de spaCY.
⭐ Estrellas de GitHub: 28K | Total de descargas: 81 millones
Hugging Face Transformers es una biblioteca de código abierto creada por Hugging Face. Los transformadores permiten a las API descargar y entrenar fácilmente modelos preentrenados de última generación. El uso de modelos preentrenados puede reducir tus costes informáticos y tu huella de carbono, además de ahorrarte tiempo al no tener que entrenar un modelo desde cero. Los modelos son adecuados para una variedad de modalidades, entre las que se incluyen:
La biblioteca de transformadores admite una integración perfecta entre tres de las bibliotecas de aprendizaje profundo más populares: PyTorch, TensorFlow y JAX. Puedes entrenar tu modelo en tres líneas de código en un marco y cargarlo para la inferencia con otro. La arquitectura de cada transformador se define dentro de un módulo Python independiente, lo que los hace fácilmente personalizables para experimentos e investigaciones.
La biblioteca está actualmente disponible para su uso bajo la licencia Apache 2.0.
Para obtener más información sobre los transformadores, visita su sitio web oficial o el repositorio GitHub y consulta nuestro tutorial sobre el uso de Transformers y Hugging Face.
⭐ Estrellas de GitHub: 119K | Total de descargas: 62 millones
LangChain es el marco de coordinación estándar del sector para los modelos de lenguaje grandes (LLM). Permite a los programadores «encadenar» diferentes componentes, por ejemplo, conectando un LLM (como GPT 5.2) a otras fuentes de computación o conocimiento.
Abstrae la complejidad de trabajar con indicaciones, lo que te permite crear fácilmente «agentes» que pueden utilizar herramientas (como una calculadora, la búsqueda de Google o un REPL de Python) para resolver problemas de razonamiento de varios pasos.
from langchain.chains import LLMChain
# Example: Creating a chain that takes user input and formats it
# before sending to an LLM
chain = prompt | llm | output_parser
result = chain.invoke({"topic": "Data Science"})⭐ Estrellas de GitHub: 123 000+ | Estado: GenAI Essential
Mientras que LangChain se encarga del razonamiento, LlamaIndex se encarga de los datos. Es el marco líder para RAG (generación aumentada por recuperación). Se especializa en la ingesta, indexación y recuperación de tus datos privados (PDF, bases de datos SQL, hojas de Excel) para que los LLM puedan responder con precisión a preguntas sobre ellos.
En 2025, «chatear con tus documentos» es un requisito empresarial estándar, y LlamaIndex proporciona las estructuras de datos optimizadas para que eso sea eficiente y sin alucinaciones.
⭐ Estrellas de GitHub: Más de 35 000 | Estado: Norma RAG
Para que los LLM «recuerden» la información, necesitas una base de datos vectorial. ChromaDB es la base de datos vectorial de código abierto y nativa de IA que se ha convertido en la opción predeterminada para los programadores de Python. Gestiona la complejidad de incrustar texto (convertir palabras en listas de números) y almacenarlo para la búsqueda semántica.
A diferencia de las bases de datos SQL tradicionales, que buscan coincidencias exactas de palabras clave, ChromaDB permite realizar consultas por significado, lo que la convierte en el backend de memoria a largo plazo para las aplicaciones de IA modernas.
⭐ Estrellas de GitHub: Más de 25 000 | Estado: Tienda Vector Estándar
Seleccionar la biblioteca Python adecuada para tus tareas de ciencia de datos, machine learning o procesamiento del lenguaje natural es una decisión crucial que puede influir significativamente en el éxito de tus proyectos. Con un arreglo de bibliotecas disponibles, es fundamental tener en cuenta varios factores para tomar una decisión informada. A continuación, te presentamos algunas consideraciones clave que te servirán de guía:
Al evaluar cuidadosamente estos factores, podrás tomar una decisión informada a la hora de seleccionar bibliotecas de Python para tus proyectos de ciencia de datos o machine learning. Recuerda que la mejor biblioteca para tu proyecto depende de los requisitos específicos y los objetivos que quieras alcanzar.
Para impulsar tu carrera en ciencia de datos, sigue el programa de científico de datos en Python.
Cursos sobre bibliotecas Python en DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
15 min
blog
Javier Canales Luna
8 min
blog
Javier Canales Luna
13 min
blog
Yuliya Melnik
15 min
Tutorial
Adel Nehme
Tutorial
Abid Ali Awan
