Curso
Análisis de clústeres en R
4 h
44.1K

Imagina que eres un Científico de Datos que trabaja para una empresa minorista. Tu jefe te pide que segmentes a los clientes en los siguientes grupos: clientes bajos, medios, medianos o platino, basándote en el comportamiento de gasto para fines de marketing dirigido y recomendaciones de productos.
Sabiendo que no existe tal etiqueta histórica asociada a esos clientes, ¿cómo es posible categorizarlos?
Aquí es donde la agrupación puede ayudar. Es una técnica de aprendizaje automático no supervisado que se utiliza para agrupar datos no etiquetados en categorías similares.
Este tutorial se centrará más en el enfoque de agrupación jerárquica, una de las muchas técnicas del aprendizaje automático no supervisado. Comenzará ofreciendo una visión general de lo que es la agrupación jerárquica, antes de compararla con algunas técnicas existentes.
A continuación, te guiará paso a paso en la implementación en Python utilizando la popular biblioteca Scipy.
Un enfoque de agrupación jerárquica se basa en la determinación de agrupaciones sucesivas a partir de agrupaciones previamente definidas. Es una técnica más orientada a agrupar los datos en un árbol de conglomerados llamado dendrograma, que representa gráficamente la relación jerárquica entre los conglomerados subyacentes.
La agrupación jerárquica es un algoritmo potente, pero no es el único que existe, y cada tipo de agrupación tiene sus ventajas e inconvenientes.
Entendamos cómo se compara con otros tipos de agrupación, como K-means y la agrupación basada en modelos. Existen muchas más técnicas, pero estas dos, además de la agrupación jerárquica, se utilizan ampliamente y proporcionan un marco para ayudar a comprender mejor las demás.
Puedes obtener más información sobre la agrupación en el aprendizaje automático en nuestro artículo independiente, que abarca cinco algoritmos de agrupación esenciales.
A diferencia de la agrupación jerárquica, la agrupación de K-means trata de dividir los puntos de datos originales en "K" grupos o clusters, donde el usuario especifica "K" de antemano.
La idea general es buscar conglomerados que minimicen la distancia euclídea al cuadrado de todos los puntos respecto a los centros sobre todos los atributos (variables o características) y fusionar esos individuos de forma iterativa.
Nuestro tutorial Clustering de K-means en Python con Scikit-learn te ayudará a comprender el funcionamiento interno del clustering de K-means con un interesante caso práctico.
A pesar de sus limitaciones, la agrupación de k-means sigue siendo un método popular debido a su facilidad de uso y eficacia computacional. Se utiliza frecuentemente como punto de referencia para comparar el rendimiento de otras técnicas de agrupación.
Tanto las técnicas de K-means como las de agrupación jerárquica utilizan una matriz de distancias para representar las distancias entre todos los puntos del conjunto de datos. La agrupación basada en modelos, por otra parte, aplica técnicas estadísticas para identificar agrupaciones en los datos. A continuación se indica el proceso general:
La agrupación jerárquica tiene una gran variedad de aplicaciones en nuestra vida cotidiana, entre ellas (pero sin limitarse a ellas) la biología, el procesamiento de imágenes, el marketing, la economía y el análisis de redes sociales.
La agrupación de secuencias de ADN es uno de los mayores retos de la bioinformática.
Los biólogos pueden aprovechar la agrupación jerárquica para estudiar las relaciones genéticas entre organismos y clasificarlos en grupos taxonómicos. Esto es beneficioso para el análisis rápido y la visualización de las relaciones subyacentes.
La agrupación jerárquica puede realizarse en el tratamiento de imágenes para agrupar regiones o píxeles similares de una imagen en términos de color, intensidad u otras características. Esto puede ser útil para otras tareas como la segmentación de imágenes, la clasificación de imágenes y el reconocimiento de objetos.
Los especialistas en marketing pueden utilizar la agrupación jerárquica para establecer una jerarquía entre los distintos tipos de clientes basándose en sus hábitos de compra, con el fin de mejorar las estrategias de marketing y las recomendaciones de productos. Por ejemplo, se pueden recomendar distintos productos en los comercios minoristas a los clientes, independientemente de que gasten poco, medio o mucho.
Las redes sociales son una gran fuente de información valiosa cuando se explotan eficazmente. La agrupación jerárquica puede utilizarse para identificar grupos o comunidades y comprender sus relaciones entre sí y la estructura de la red en su conjunto.
En esta sección, examinaremos tres conceptos principales. Las etapas del algoritmo jerárquico, un resumen de los dos tipos de agrupación jerárquica (aglomerativa y divisiva) y, por último, algunas técnicas para elegir la medida de distancia adecuada.
El algoritmo de agrupación jerárquica emplea el uso de medidas de distancia para generar agrupaciones. Este proceso de generación implica los siguientes pasos principales:
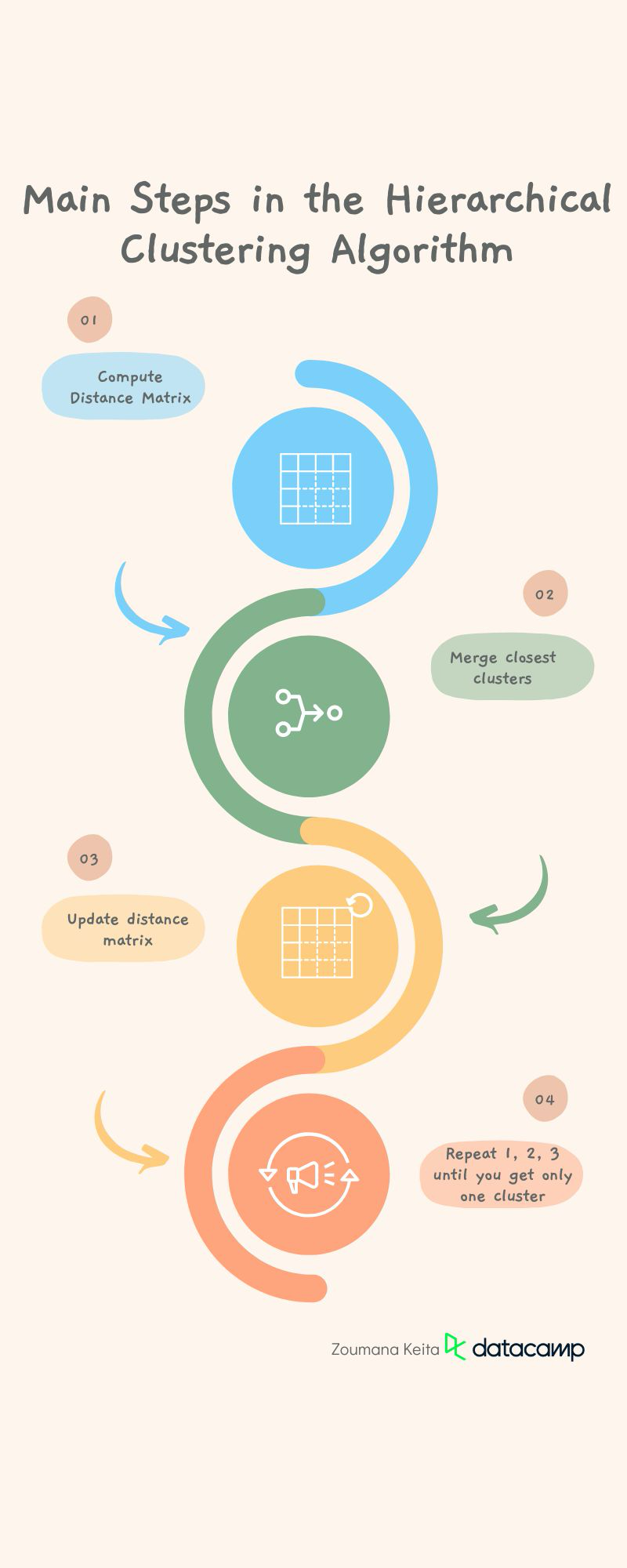
Preprocesa los datos eliminando los datos que falten y aplicando cualquier tarea adicional que haga que los datos estén lo más limpios posible. Este paso es más general para la mayoría de las tareas de aprendizaje automático.
1. Calcula la matriz de distancia que contiene la distancia entre cada par de puntos de datos utilizando una métrica de distancia determinada, como la distancia euclídea, la distancia de Manhattan o la similitud del coseno. Pero la métrica de distancia por defecto es la euclídea.
2.Fusiona los dos conglomerados que estén más próximos en distancia.
3. Actualiza la matriz de distancias con respecto a los nuevos conglomerados.
4. Repite los pasos 1, 2 y 3 hasta que todos los clusters estén fusionados para crear un único cluster.
Podemos considerar la agrupación aglomerativa y la divisiva como espejos la una de la otra. Veamos mejor cómo funciona cada uno de ellos, junto con un ejemplo de agrupación jerárquica y una visualización gráfica.
Este primer escenario corresponde al planteamiento explicado anteriormente. Comienza considerando cada observación como un conglomerado singleton (conglomerado con un solo punto de datos). A continuación, fusiona iterativamente los conglomerados hasta obtener un único conglomerado. Este proceso también se conoce como enfoque ascendente.
Como se muestra en la siguiente ilustración:
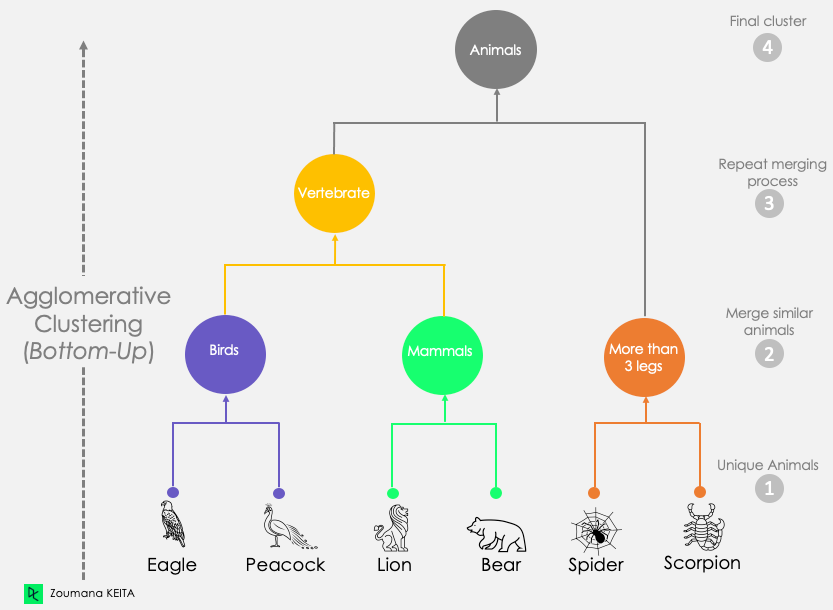
Dendrograma del método de agrupación aglomerativa
Por otra parte, la agrupación divisiva es descendente porque empieza considerando todos los puntos de datos como un único conglomerado. Después, sepáralos hasta que todos los puntos de datos sean únicos.
De este enfoque divisivo gráfico:
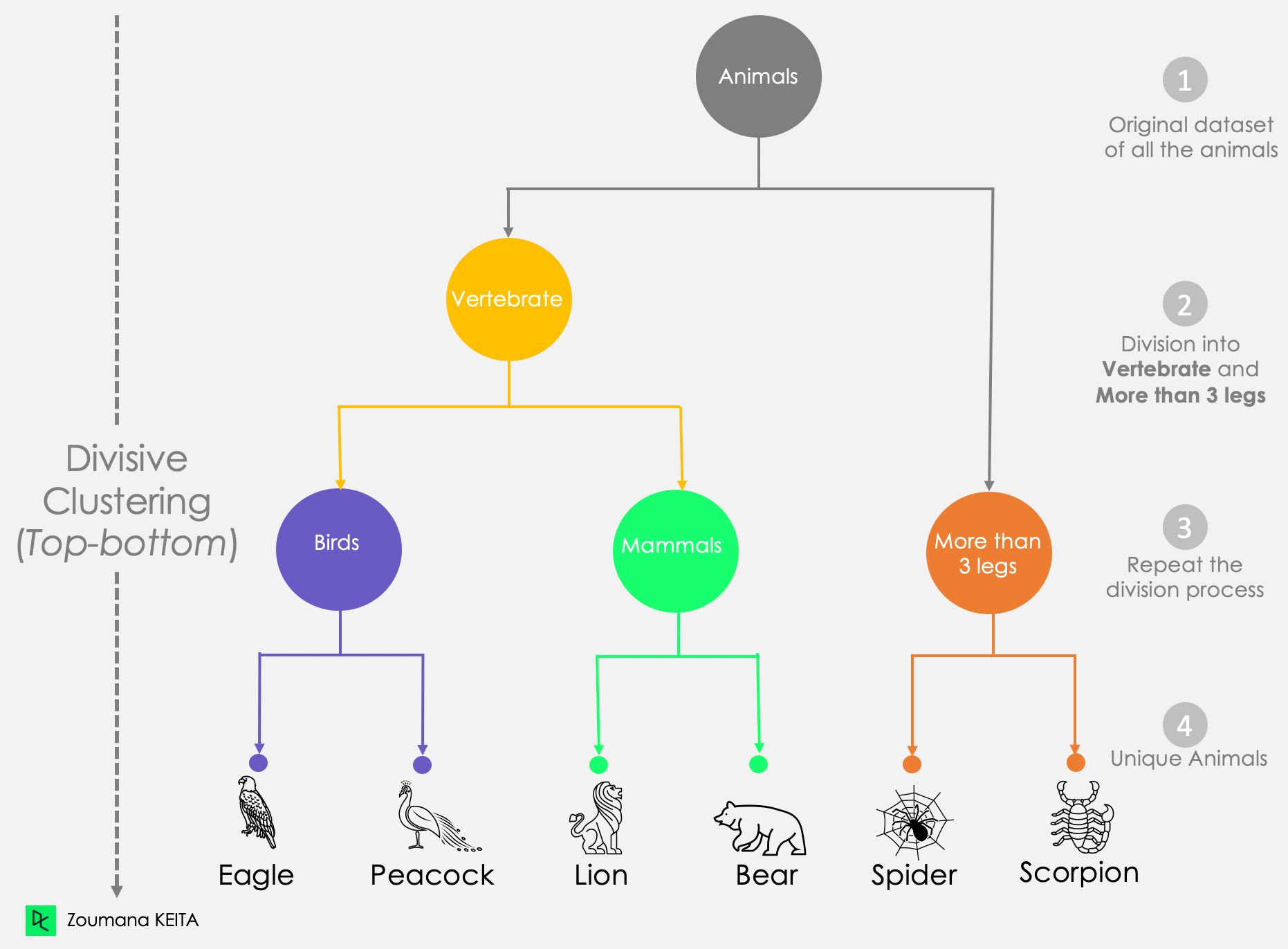
Dendrograma del enfoque de agrupación divisiva
La elección de la medida de distancia es un paso fundamental en la agrupación, y depende del problema que intentes resolver. Considerando el siguiente escenario, podríamos agrupar a los alumnos basándonos en cualquier número de enfoques, como su:
Todas ellas son agrupaciones válidas, pero difieren en su significado.
Aunque la distancia euclidiana es la más utilizada en la mayoría de los programas informáticos de agrupación, existen otras medidas de distancia, como la distancia Manhattan, la distancia Canberra, la correlación de Pearson o Spearman y la distancia de Minkowski.
Las distancias mencionadas anteriormente están relacionadas con los elementos. En esta sección, trataremos tres formas estándar (no exhaustivas) de medir el par de conglomerados más cercano antes de fusionarlos: (1) Enlace simple, (2) Enlace completo y (3) Enlace medio.
De todas las distancias por pares entre los elementos de los dos conglomerados C1 y C2, el enlace único toma la distancia entre los conglomerados como distancia mínima.
Distancia (C1, C2) = Mín { d(i, j), donde el elemento i está dentro de C1, y el elemento j está dentro de C2}
De todos los pares de elementos de los dos conglomerados, los resaltados en verde tienen la distancia mínima.
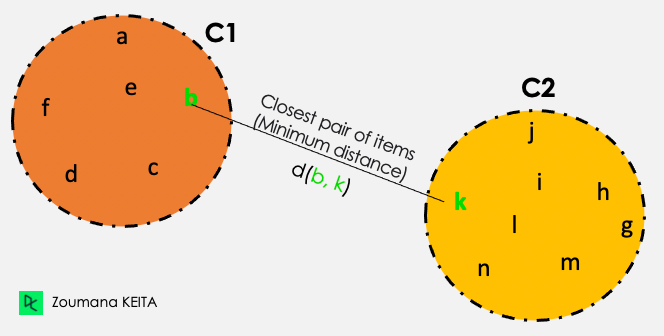
Ilustración de enlace simple
De todas las distancias por pares entre los elementos de los dos conglomerados C1 y C2, el enlace único toma la distancia entre los conglomerados como distancia máxima.
Distancia (C1, C2) = Máx { d(i, j), donde el elemento i está dentro de C1, y el elemento j está dentro de C2}
De todos los pares de elementos de los dos conglomerados, los resaltados en verde tienen la distancia máxima.
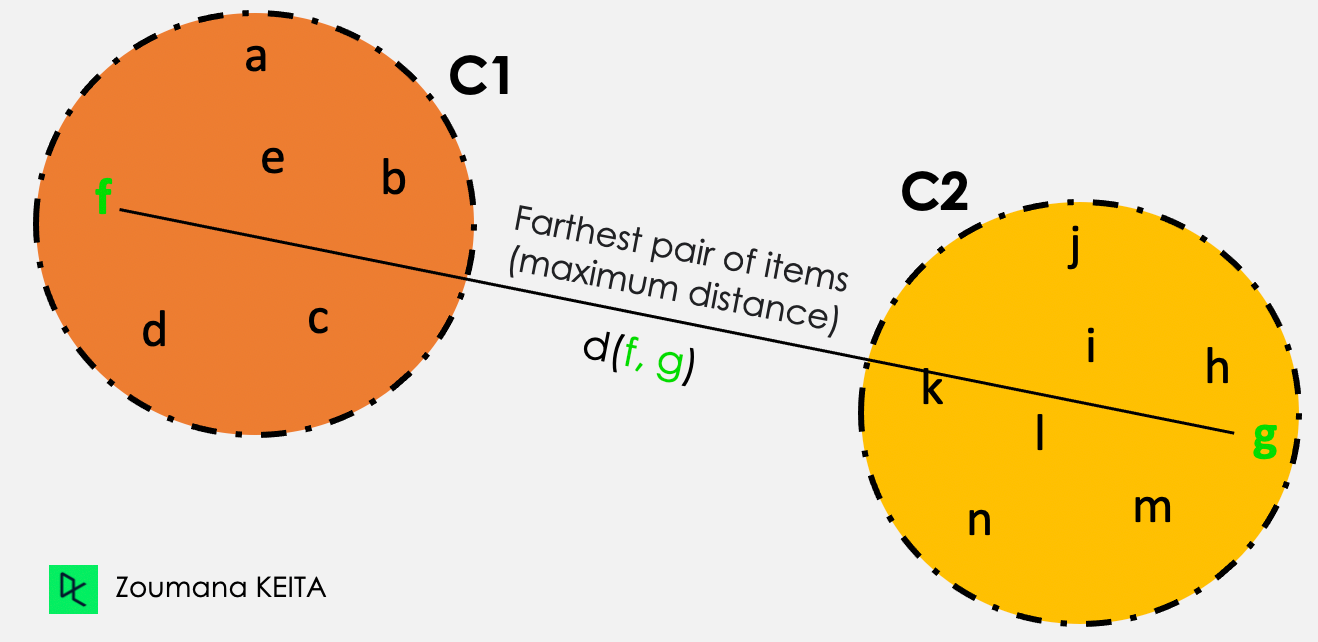
Ilustración del enganche completo
En la agrupación de vinculación media, la distancia entre dos conglomerados dados C1 y C2 corresponde a las distancias medias entre todos los pares de elementos de los dos conglomerados.
Distancia (C1, C2) = Suma{ d(i, j) } / Número total de distancias
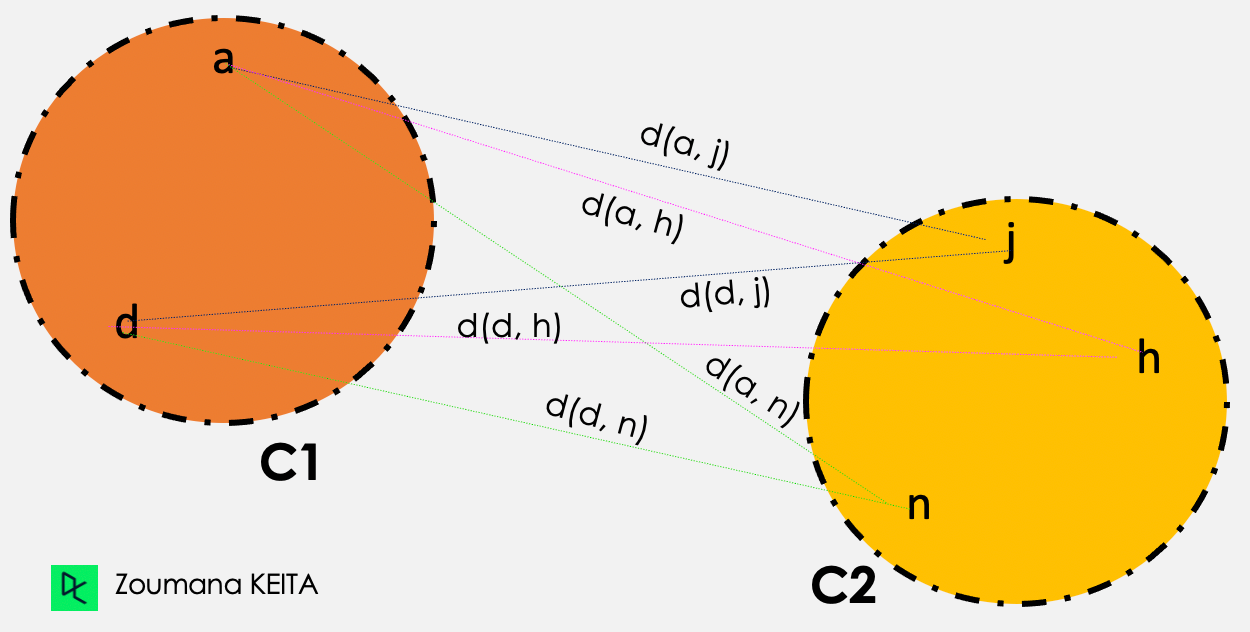
Ilustración del enlace medio
A continuación, la agrupación de enlace medio se realiza del siguiente modo
d(a,j) + d(a,h) + d(a,n) + d(d,j) + d(d,h) + d(d,n)
------------------------------------------------------------, donde Número total de distancias = 6
Número total de distancias
Ahora ya sabes cómo funciona la agrupación jerárquica. En esta sección, nos centraremos en la implementación técnica utilizando Python.
Si estás más interesado en realizar la implementación con el lenguaje de programación R, nuestro tutorial Clusterización jerárquica en R es por donde debes empezar.
Para empezar, necesitarás tener instalado Python en tu ordenador, junto con las siguientes bibliotecas:
Puedes instalar estas bibliotecas utilizando pip, el gestor de paquetes de Python, de la siguiente manera:
pip install scikit-learn
pip install pandas
pip install matplotlib seaborn
pip install scipyA continuación, vamos a importar los módulos necesarios y a cargar el conjunto de datos. Utilizaremos el conjunto de datos de iris incorporado de scikit-learn, que contiene información sobre distintos tipos de flores de iris.
Para ilustrar mejor el caso práctico, utilizaremos los Datos de Préstamos disponibles en DataLab. Todo el código de este tutorial está disponible en este libro de trabajo de DataLab; puedes crear fácilmente una copia para ejecutar el código en el navegador, sin tener que instalar ningún programa en tu ordenador.
El conjunto de datos tiene 9.500 préstamos con información sobre la estructura del préstamo, el prestatario y si el préstamo se devolvió en su totalidad. Nos desharemos de la columna objetivo no.totalmente.pagada para cumplir el aspecto no supervisado.
import pandas as pd
loan_data = pd.read_csv("loan_data.csv")
loan_data.head()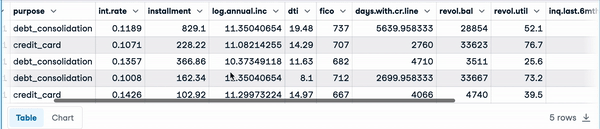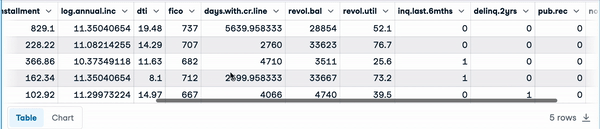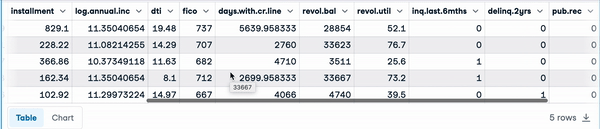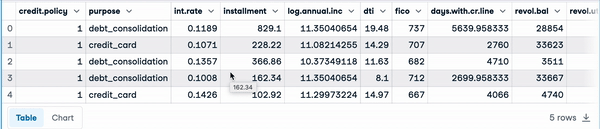 Cinco primeras filas de los datos de carga
Cinco primeras filas de los datos de carga
La siguiente instrucción muestra que los datos tienen 9.578 filas y 14 columnas de tipo numérico, excepto la finalidad, que es objeto y da la descripción textual de la finalidad de la carga.
loan_data.info()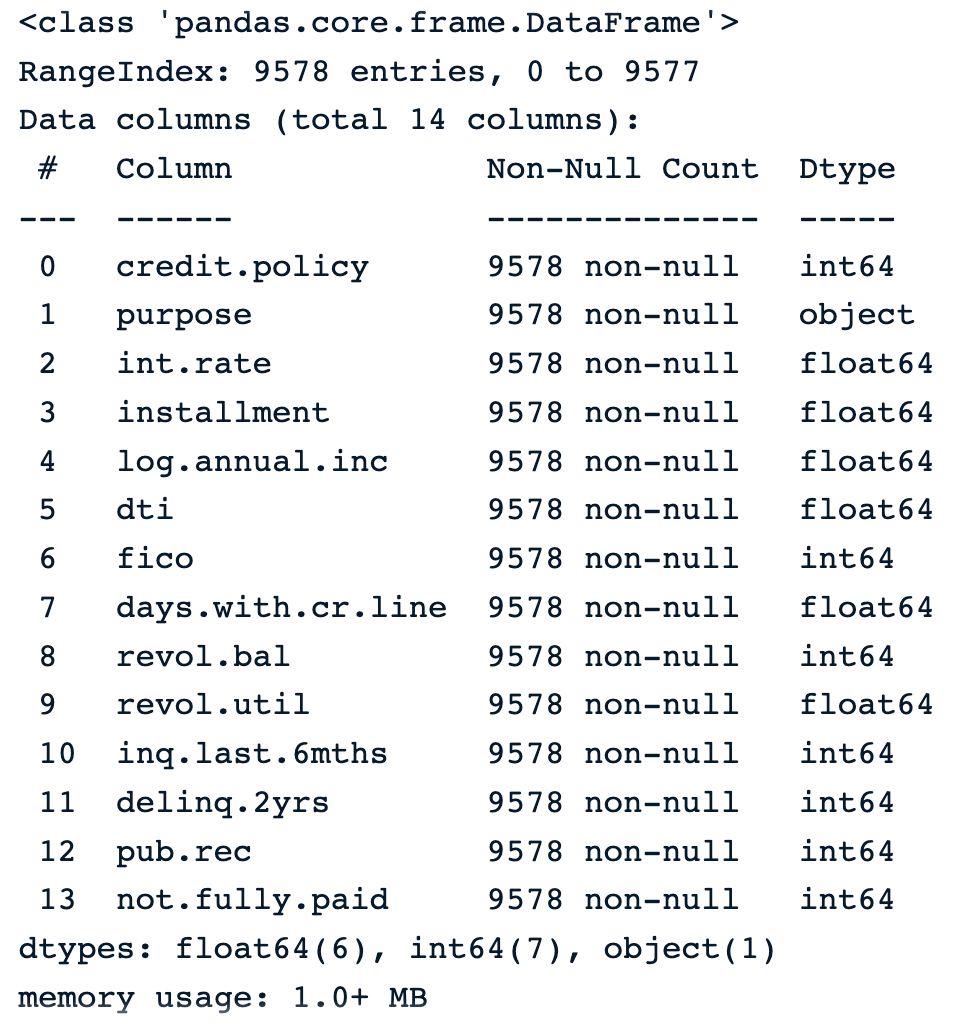 Información sobre los datos
Información sobre los datos
Antes de aplicar la agrupación, hay que preprocesar los datos para tratar la información que falta, normalizar los valores de las columnas y eliminar las columnas irrelevantes.
En el resultado que aparece a continuación, observamos que no hay ningún valor omitido en los datos.
percent_missing =round(100*(loan_data.isnull().sum())/len(loan_data),2)
percent_missing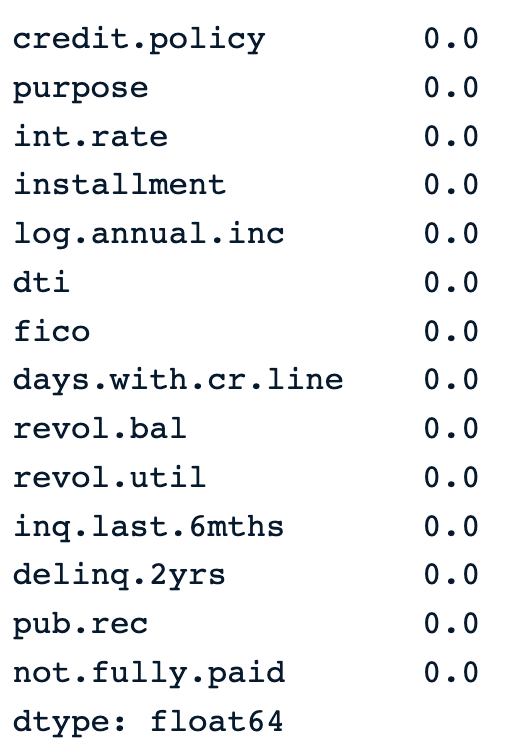 Porcentaje de valores omitidos en los datos
Porcentaje de valores omitidos en los datos
Vamos a analizar los datos del préstamo utilizando todas las columnas excepto la siguiente:
Los datos_limpiados corresponden a los datos sin las columnas anteriores.
cleaned_data = loan_data.drop(['purpose', 'not.fully.paid'], axis=1)
cleaned_data.info()La imagen siguiente muestra la información de los nuevos datos.
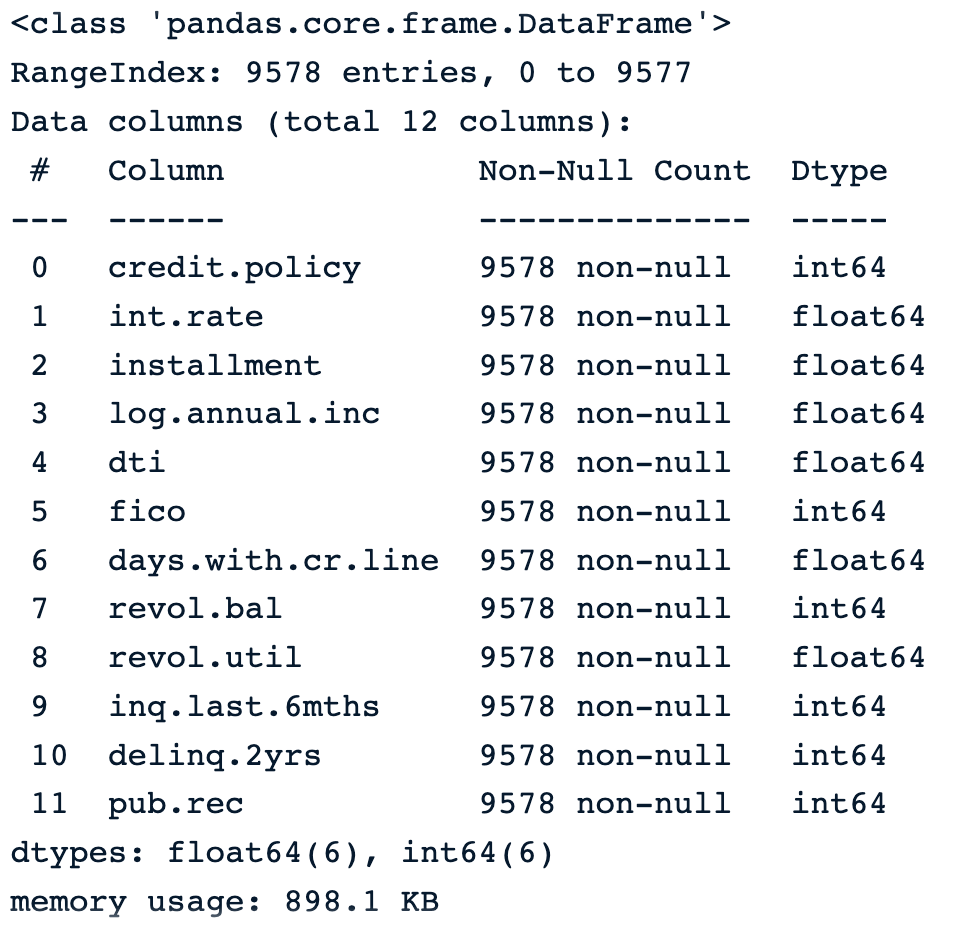
Nuevos datos sin las columnas no deseadas
Uno de los puntos débiles de la agrupación jerárquica es que es sensible a los valores atípicos. La distribución de cada variable viene dada por el diagrama de caja.
def show_boxplot(df):
plt.rcParams['figure.figsize'] = [14,6]
sns.boxplot(data = df, orient="v")
plt.title("Outliers Distribution", fontsize = 16)
plt.ylabel("Range", fontweight = 'bold')
plt.xlabel("Attributes", fontweight = 'bold')
show_boxplot(cleaned_data)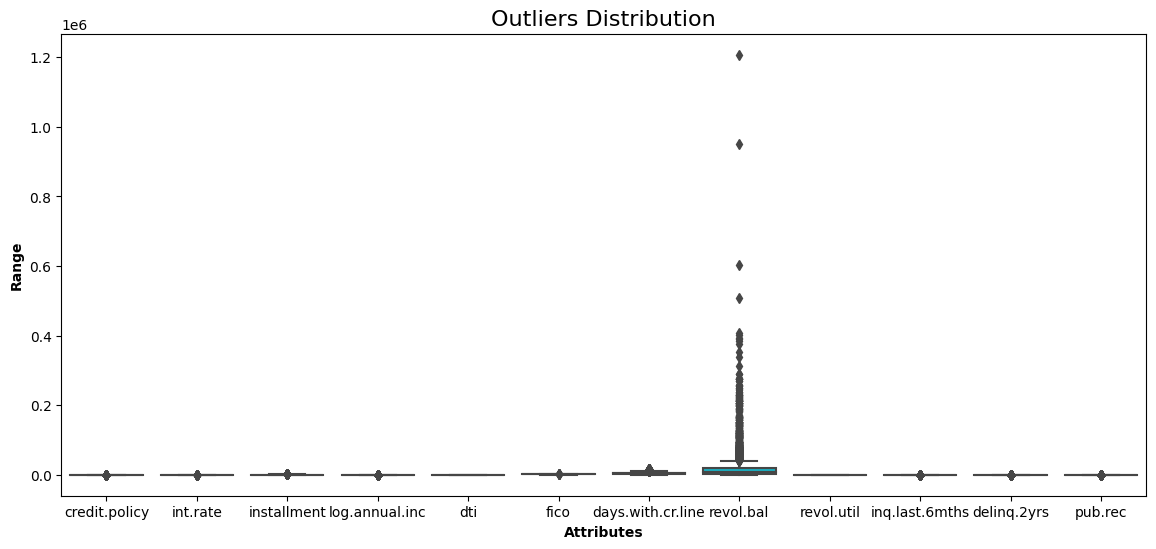
Diagrama de caja de todas las variables de los datos
El saldo renovable del prestatario (revol_bal) es el único atributo con puntos de datos alejados del resto.
Utilizando el enfoque del rango intercuartílico, podemos eliminar todos los puntos que se encuentren fuera del rango definido por los cuartiles +/-1,5 * IQR, donde IQR es el Rango Intercuartílico.
Esto se consigue con la siguiente función de ayuda.
def remove_outliers(data):
df = data.copy()
for col in list(df.columns):
Q1 = df[str(col)].quantile(0.05)
Q3 = df[str(col)].quantile(0.95)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5*IQR
upper_bound = Q3 + 1.5*IQR
df = df[(df[str(col)] >= lower_bound) &
(df[str(col)] <= upper_bound)]
return df
A continuación, podemos aplicar la función al conjunto de datos.
without_outliers = remove_outliers(cleaned_data)Ahora podemos comprobar el nuevo boxplot y compararlo con el anterior a la eliminación de los valores atípicos.
show_boxplot(without_outliers)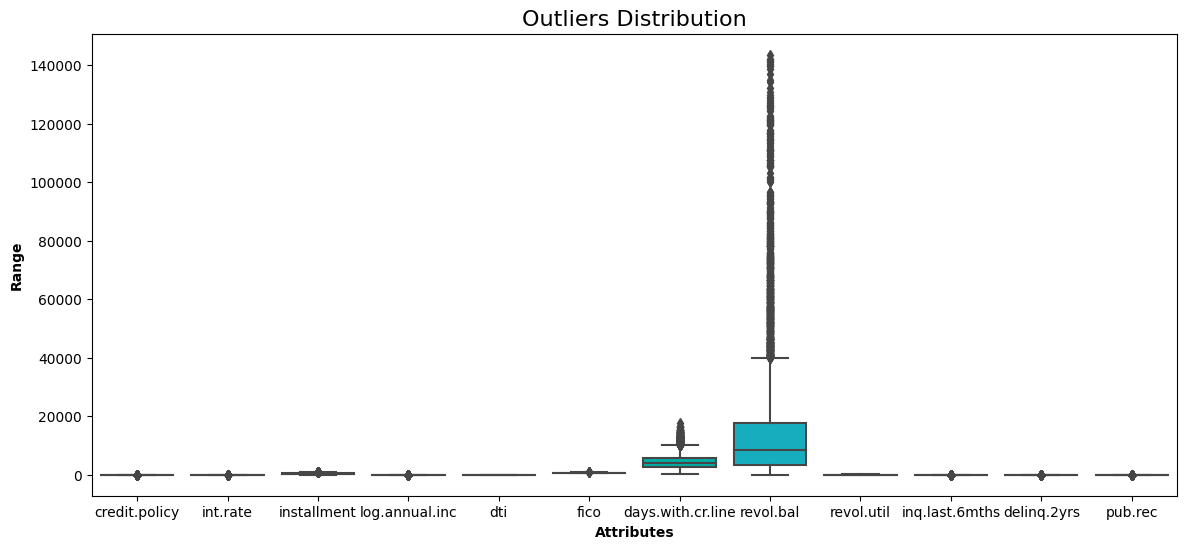
No hay más puntos de datos fuera del rango intercuartílico.
without_outliers.shapeLa forma de los datos es ahora de 9.319 filas y 12 columnas. Esto significa que 259 observaciones eran valores atípicos, que se han eliminado.
Como la agrupación jerárquica utiliza la distancia euclídea, que es muy sensible al tratar con variables con escalas diferentes, es conveniente reescalar todas las variables antes de calcular la distancia.
Esto se hace utilizando la clase StandardScaler de sklearn.
from sklearn.preprocessing import StandardScaler
data_scaler = StandardScaler()
scaled_data = data_scaler.fit_transform(without_outliers)
scaled_data.shapeLa forma de los datos sigue siendo la misma (9.319 filas, 12 columnas) porque la normalización no afecta a la misma de los datos.
Se cumplen todos los requisitos para profundizar en la implementación del algoritmo de agrupación.
Llegados a este punto, podemos decidir qué enfoque de vinculación adoptar para la agrupación en el atributo method del método linkage(). En esta sección, trataremos las tres técnicas de enlace utilizando la distancia euclídea.
Esto se consigue con los códigos que aparecen a continuación, tras importar las bibliotecas correspondientes.
from scipy.cluster.hierarchy import linkage, dendrogram
complete_clustering = linkage(scaled_data, method="complete", metric="euclidean")
average_clustering = linkage(scaled_data, method="average", metric="euclidean")
single_clustering = linkage(scaled_data, method="single", metric="euclidean")Una vez que hemos calculado las tres agrupaciones, los dendrogramas correspondientes se muestran como sigue, empezando por la agrupación completa
dendrogram(complete_clustering)
plt.show()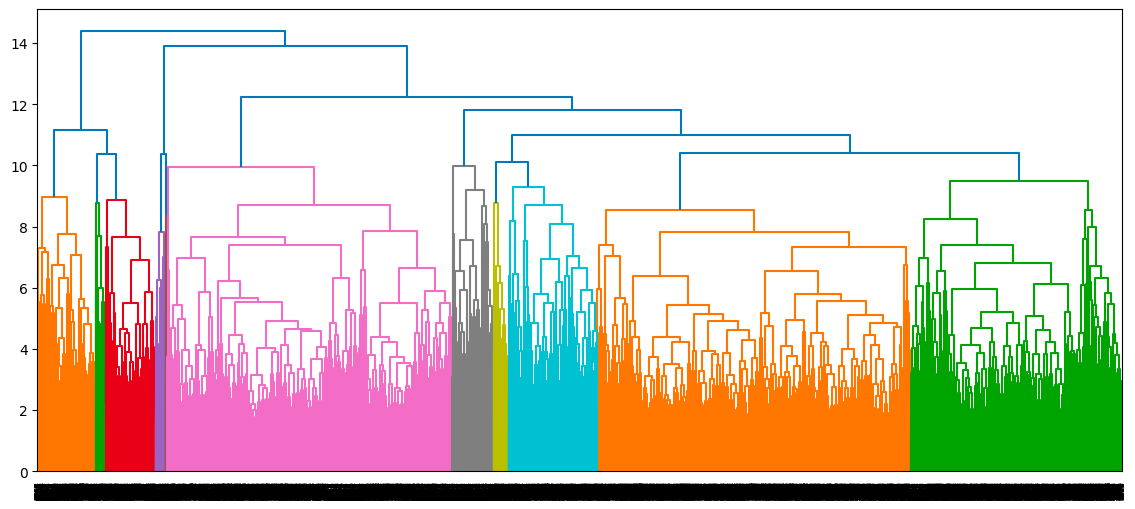
Dendrograma del enfoque de agrupación completo
dendrogram(average_clustering)
plt.show()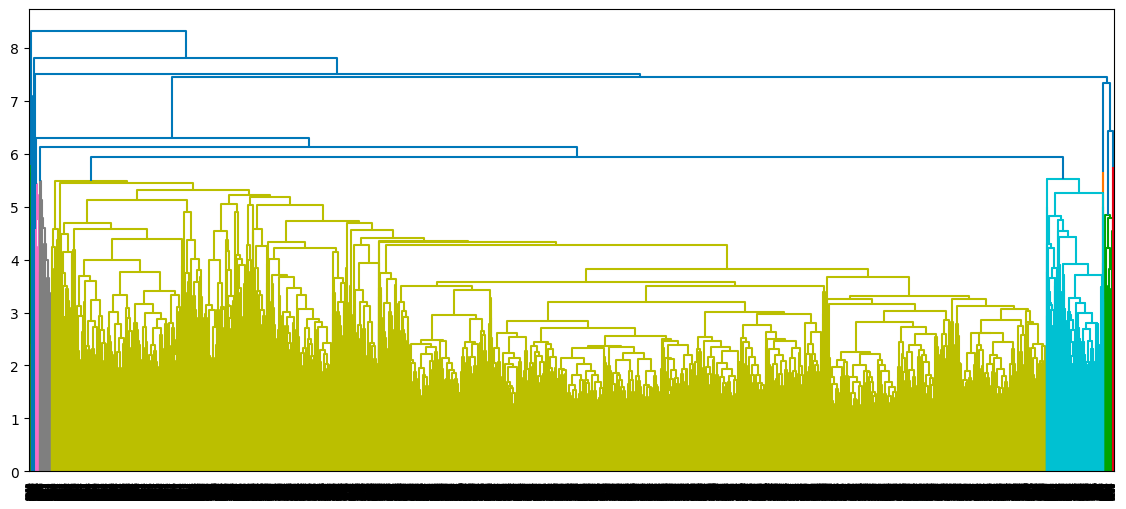
Dendrograma del enfoque de agrupación media
dendrogram(single_clustering)
plt.show()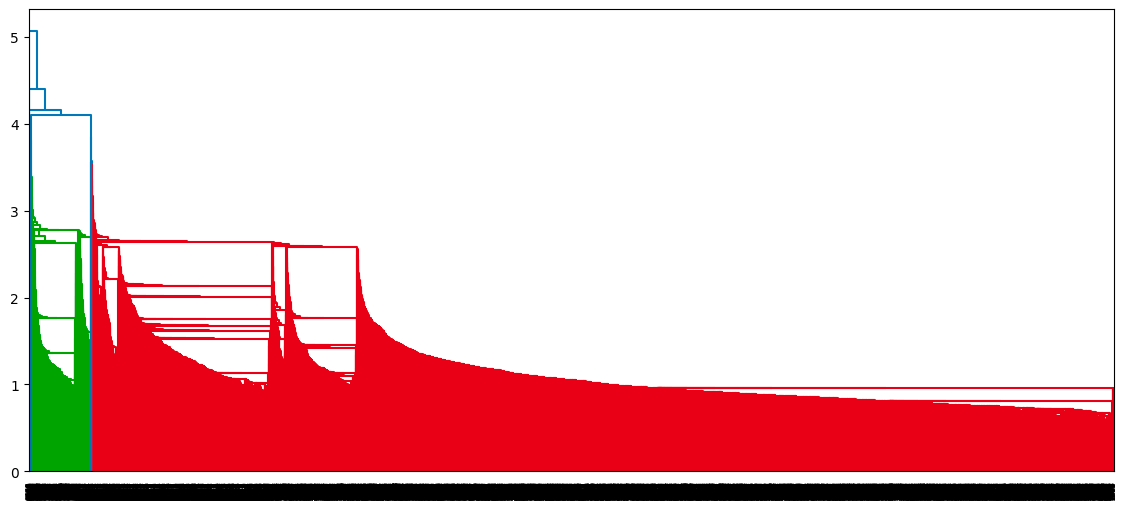
Dendrograma del enfoque de agrupación única
Para cada enfoque de vinculación, cómo se construye el dendrograma y cada punto de datos acaba en un único conglomerado.
El número óptimo de conglomerados puede obtenerse identificando la línea vertical más alta que no se cruce con ningún otro conglomerado (línea horizontal). Dicha línea se encuentra a continuación con un círculo rojo y una marca de verificación verde.
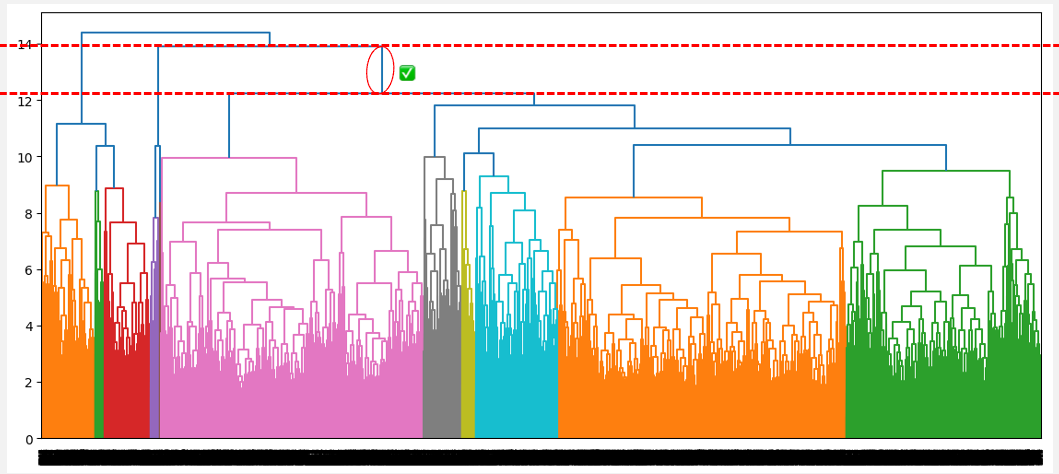
Número óptimo de conglomerados a partir de la distancia más alta sin intersección (vinculación completa)
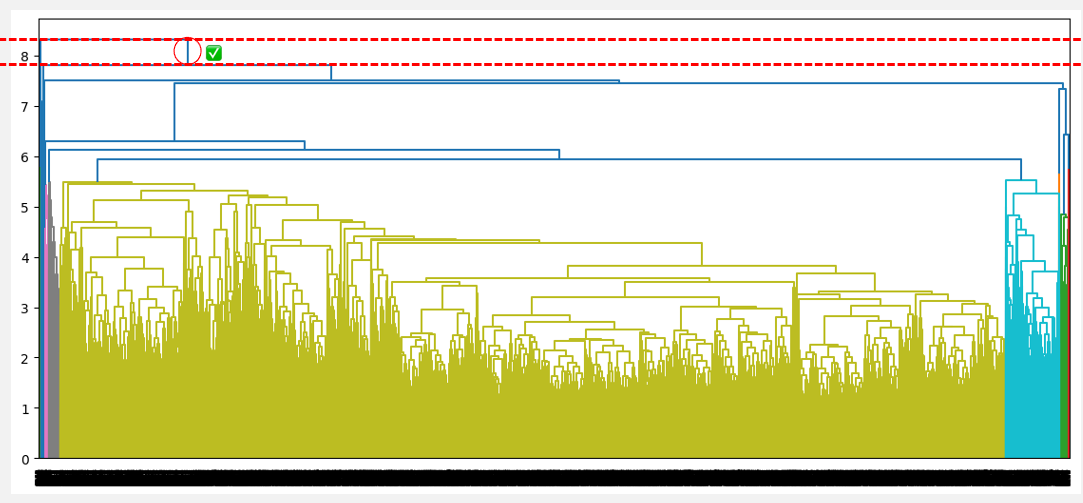
Número óptimo de conglomerados a partir de la mayor distancia sin intersección (enlace medio)
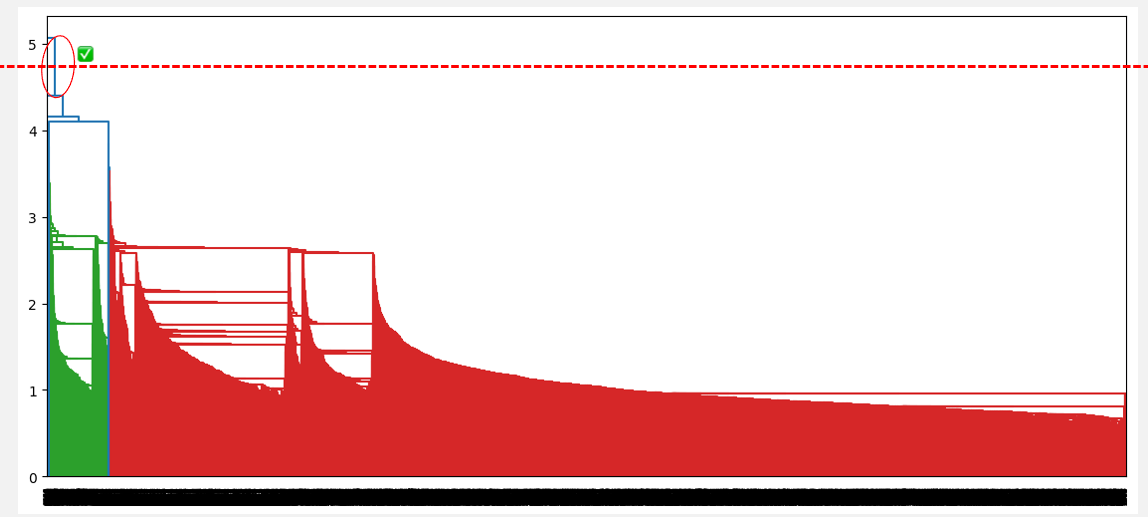
Número óptimo de conglomerados a partir de la mayor distancia sin intersección (enlace único)
A partir de las observaciones anteriores, la vinculación media parece ser la que proporciona la mejor agrupación, a diferencia de la vinculación simple y la completa, que sugieren, respectivamente, considerar un conglomerado y tres conglomerados. Además, el número óptimo de conglomerados de dos corresponde a nuestro conocimiento previo sobre el conjunto de datos, que son los dos tipos de prestatarios.
Ahora que hemos encontrado el número óptimo de conglomerados, veamos qué significan esos conglomerados en función de la puntuación crediticia del prestatario.
cluster_labels = cut_tree(average_clustering, n_clusters=2).reshape(-1, )
without_outliers["Cluster"] = cluster_labels
sns.boxplot(x='Cluster', y='fico', data=without_outliers)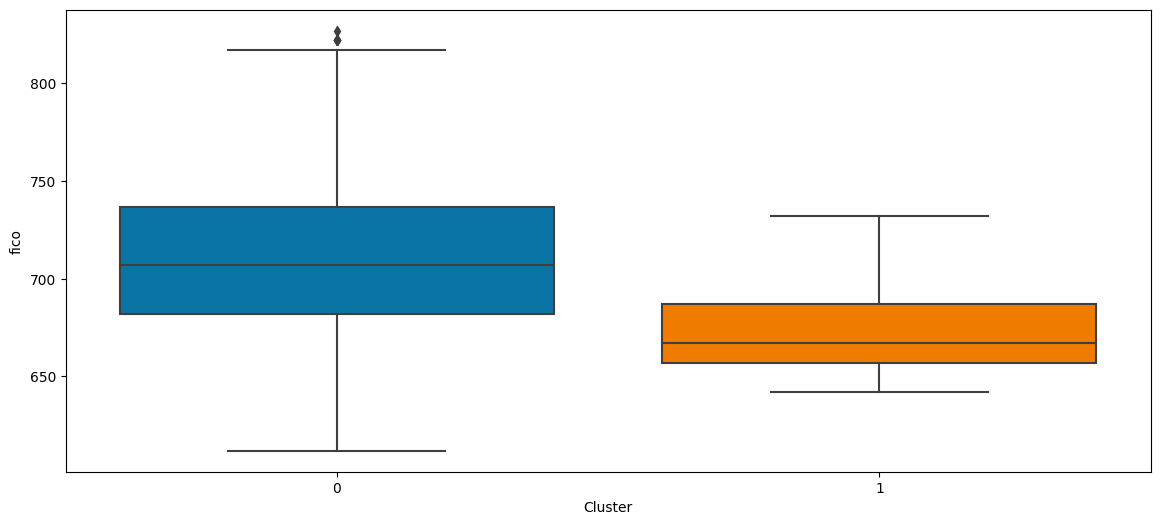
Del diagrama de caja anterior, podemos observar que:
Análisis de conglomerados en Python puede ser un buen paso siguiente para profundizar en K-means y la agrupación jerárquica utilizando la biblioteca Scipy.
En este artículo se ha tratado qué es la agrupación jerárquica, sus ventajas y desventajas, y cómo se compara con k-means y la agrupación basada en modelos.
Esperamos que el artículo te proporcione los conocimientos necesarios para agrupar eficazmente tus datos no etiquetados para una toma de decisiones procesable.
Agrupación de cursos
Curso
Curso