Curso
Machine Learning para datos de series temporales en Python
4 h
53.2K
La agrupación es una técnica de aprendizaje automático no supervisado con muchas aplicaciones en las áreas de reconocimiento de patrones, análisis de imágenes, análisis de clientes, segmentación de mercados, análisis de redes sociales, etc. Una amplia gama de industrias utilizan la agrupación, desde las aerolíneas a la sanidad y más allá.
Es un tipo de aprendizaje no supervisado, lo que significa que no necesitamos datos etiquetados para los algoritmos de agrupación; ésta es una de las mayores ventajas de la agrupación frente a otros aprendizajes supervisados como la Clasificación. En este tutorial sobre clustering, aprenderás:
La agrupación es el proceso de ordenar un grupo de objetos de forma que los objetos de un mismo grupo (que se denomina clúster) sean más parecidos entre sí que a los objetos de cualquier otro grupo. Los profesionales de los datos suelen utilizar la agrupación en la fase de Análisis Exploratorio de Datos para descubrir nueva información y patrones en los datos. Como la agrupación es aprendizaje automático no supervisado, no requiere un conjunto de datos etiquetados.
La agrupación en sí no es un algoritmo específico, sino la tarea general que hay que resolver. Puedes lograr este objetivo utilizando varios algoritmos que difieren significativamente en su comprensión de lo que constituye un conglomerado y en cómo encontrarlos de forma eficiente.
Más adelante en este tutorial, compararemos los resultados de diferentes algoritmos de agrupación, seguidos de una discusión detallada de 5 algoritmos de agrupación esenciales y populares que se utilizan hoy en día en la industria. Aunque los algoritmos son esencialmente matemáticos, este tutorial de agrupación pretende construir una comprensión intuitiva de los algoritmos más que una formulación matemática.
La agrupación, a diferencia de los casos de uso del aprendizaje supervisado, como la clasificación o la regresión, no puede automatizarse completamente de principio a fin. Por el contrario, se trata de un proceso iterativo de descubrimiento de información que requiere experiencia en el dominio y un juicio humano utilizado con frecuencia para realizar ajustes en los datos y en los parámetros del modelo para lograr el resultado deseado.
Y lo que es más importante, como la agrupación es un aprendizaje no supervisado y no utiliza datos etiquetados, no podemos calcular métricas de rendimiento como la precisión, el AUC, el RMSE, etc., para comparar distintos algoritmos o técnicas de preprocesamiento de datos. Como resultado, esto hace que sea realmente difícil y subjetivo evaluar el rendimiento de los modelos de agrupación.
Los criterios clave del éxito en los modelos de agrupación giran en torno a:
Antes de entrar en detalles algorítmicos, vamos a construir una intuición sobre la agrupación utilizando un ejemplo de juguete de conjuntos de datos de frutas. Supongamos que tenemos una enorme colección de datos de imágenes que contienen tres frutas (i) fresas, (ii) peras y (iii) manzanas.
En el conjunto de datos todas las imágenes están mezcladas y tu caso de uso es agrupar frutas similares, es decir, crear tres grupos en los que cada uno contenga un tipo de fruta. Esto es exactamente lo que hará un algoritmo de agrupación.
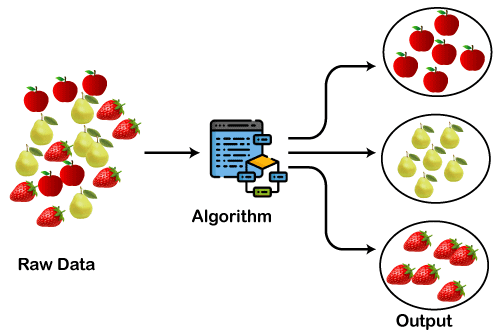
Fuente de la imagen: https://static.javatpoint.com/tutorial/machine-learning/images/clustering-in-machine-learning.png
La agrupación es una técnica muy potente y tiene amplias aplicaciones en diversos sectores, desde los medios de comunicación a la sanidad, pasando por la industria manufacturera y los servicios, y en cualquier lugar donde haya grandes cantidades de datos. Veamos algunos casos prácticos:
Los clientes se clasifican mediante algoritmos de agrupación según su comportamiento de compra o sus intereses para desarrollar campañas de marketing específicas.
Imagina que tienes 10M de clientes, y quieres desarrollar campañas de marketing personalizadas o enfocadas. Es poco probable que desarrolles campañas de marketing de 10M, así que ¿qué hacemos? Podríamos utilizar el clustering para agrupar 10M de clientes en 25 clusters y luego diseñar 25 campañas de marketing en lugar de 10M.
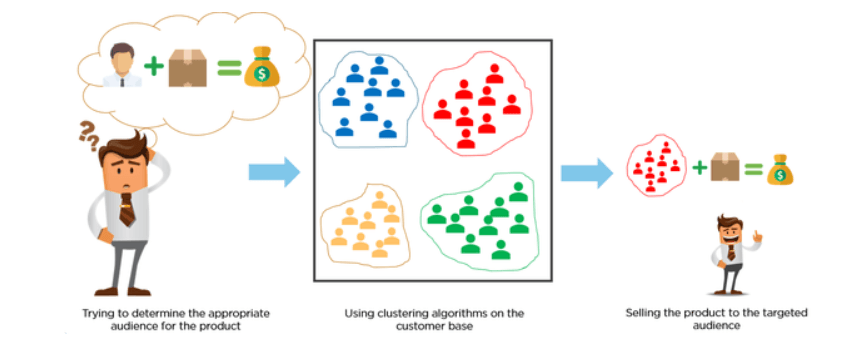
Image Source: https://miro.medium.com/max/845/1*rFATWK6tWBrDJ1o1rzEZ8w.png
Hay muchas oportunidades de agrupación en los comercios minoristas. Por ejemplo, puedes recopilar datos sobre cada tienda y agruparlos a nivel de tienda para generar perspectivas que te indiquen qué ubicaciones son similares entre sí en función de atributos como el tráfico peatonal, las ventas medias de la tienda, el número de SKU, etc.
Otro ejemplo podría ser la agrupación a nivel de categoría. En el diagrama siguiente, tenemos ocho tiendas. Los distintos colores representan agrupaciones diferentes. En este ejemplo hay cuatro grupos.
Observa que la categoría de desodorantes de la Tienda 1 está representada por el grupo rojo, mientras que la categoría de desodorantes de la Tienda 2 está representada por el grupo azul. Esto demuestra que la Tienda 1 y la Tienda 2 tienen mercados objetivo completamente distintos para la categoría de desodorantes.
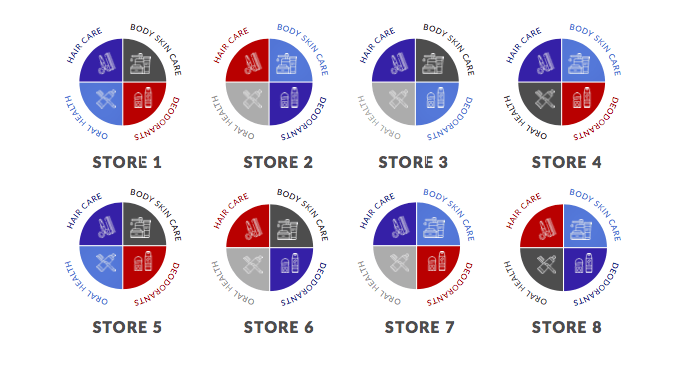
Fuente de la imagen:https://www.dotactiv.com/hs-fs/hubfs/Category-based%20clustering.png?width=1038&height=557&name=Category-based%20clustering.png
La Sanidad y las Ciencias Clínicas vuelven a ser una de esas áreas repletas de oportunidades para la agrupación que, de hecho, tienen un gran impacto en el campo. Un ejemplo de ello es la investigación publicada por Komaru & Yoshida et al. 2020, donde recogieron datos demográficos y de laboratorio de 101 pacientes y luego los segmentaron en 3 grupos.
Cada grupo estaba representado por condiciones diferentes. Por ejemplo, el grupo 1 tiene pacientes con CMB y PCR bajos. El Grupo 2 tiene pacientes con BMP y Suero elevados, y el Grupo 3 tiene pacientes con Suero bajo. Cada grupo representa una trayectoria de supervivencia diferente dada la mortalidad a 1 año tras la hemodiálisis.
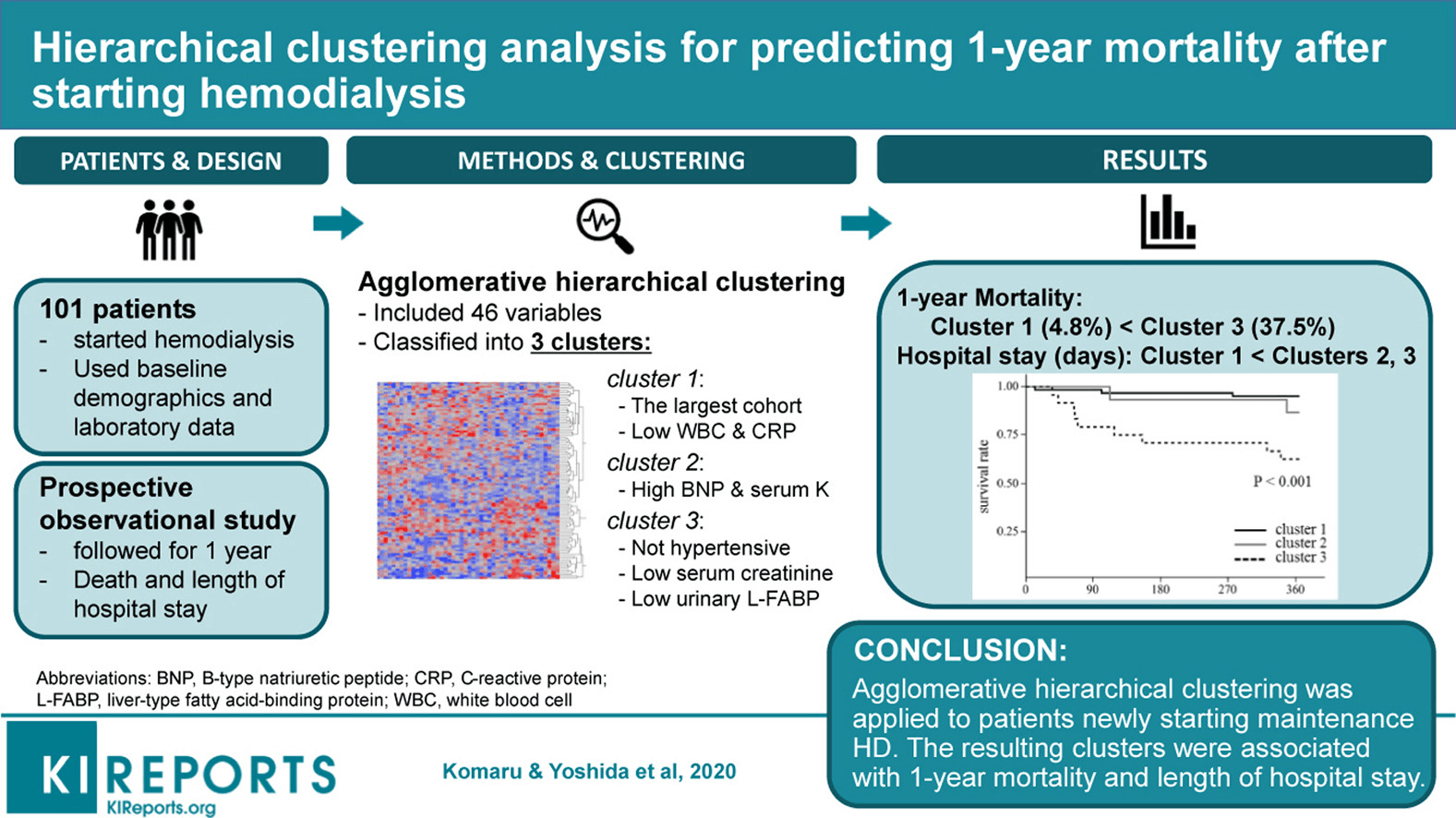
Fuente de la imagen: https://els-jbs-prod-cdn.jbs.elsevierhealth.com/cms/attachment/da4cb0c9-0a86-4702-8a78-80ffffcf1f9c/fx1_lrg.jpg
La segmentación de imágenes es la clasificación de una imagen en diferentes grupos. Se ha investigado mucho en el área de la segmentación de imágenes mediante agrupación. Este tipo de agrupación es útil si quieres aislar objetos en una imagen para analizar cada objeto individualmente y comprobar de qué se trata.
En el ejemplo siguiente, el lado izquierdo representa la imagen original, y el lado derecho es el resultado del algoritmo de agrupación. Puedes ver claramente que hay 4 conglomerados que son 4 objetos diferentes de la imagen determinados en función de los píxeles (tigre, hierba, agua y arena).
|
¿Quieres poner en marcha tu carrera Domina las habilidades esenciales para conseguir un trabajo como científico de aprendizaje automático? Echa un vistazo a estos increíbles cursos de DataCamp Científico de Aprendizaje Automático con Python y Científico de Aprendizaje Automático con R. |
Hay 10 algoritmos de agrupación no supervisada implementados en scikit-learn, una popular biblioteca de aprendizaje automático en Python. Existen diferencias subyacentes fundamentales en la forma en que cada algoritmo determina y asigna los conglomerados en el conjunto de datos.
Las diferencias subyacentes en la modalidad matemática de estos algoritmos se reducen a cuatro aspectos en los que podemos comparar y contrastar estos algoritmos:
Centrémonos en el resultado de estos algoritmos. En el diagrama siguiente, cada columna representa una salida de un algoritmo de agrupación diferente, como KMeans, Propagación de afinidad, MeanShift, etc. Hay un total de 10 algoritmos que se entrenan con el mismo conjunto de datos.
Algunos algoritmos han dado el mismo resultado. Observa que la Agrupación Aglomerativa, DBSCAN, OPTICS y la Agrupación Espectral han dado como resultado los mismos conglomerados.
Sin embargo, si observas y comparas el resultado del algoritmo KMeans con el del algoritmo MeanShift, te darás cuenta de que ambos algoritmos dieron resultados diferentes. En el caso de KMeans, sólo hay dos grupos (clusters: azul y naranja), mientras que, en el caso de MeanShift, hay tres, es decir, azul, verde y naranja.

Image Source: https://scikit-learn.org/stable/_images/sphx_glr_plot_cluster_comparison_001.png
Por desgracia (o por suerte), no hay una respuesta correcta o incorrecta en la Agrupación. Habría sido tan sencillo determinarlo y hacer una afirmación como "X Algoritmo funciona mejor aquí".
Esto no es posible y por ello la agrupación es una tarea muy difícil.
En última instancia, qué algoritmo funciona mejor no depende de ninguna métrica fácilmente medible, sino de la interpretación y de lo útil que sea el resultado para el caso de uso en cuestión.
El algoritmo de agrupación K-Means es fácilmente el algoritmo más popular y utilizado para tareas de agrupación. Se debe principalmente a la intuición y a la facilidad de aplicación. Es un algoritmo basado en el centroide, en el que el usuario debe definir el número de conglomerados que desea crear.
Normalmente se obtiene a partir de un caso de uso empresarial o probando distintos valores para el número de conglomerados y evaluando después el resultado.
La agrupación de K-Means es un algoritmo iterativo que crea clusters no solapados, lo que significa que cada instancia de tu conjunto de datos sólo puede pertenecer a un cluster exclusivamente. La forma más fácil de intuir el algoritmo K-Means es entender los pasos junto con el diagrama de ejemplo que aparece a continuación. También puedes obtener una descripción detallada del proceso en nuestros tutoriales Clustering de K-Means en Python y Clustering de K-Means en R.
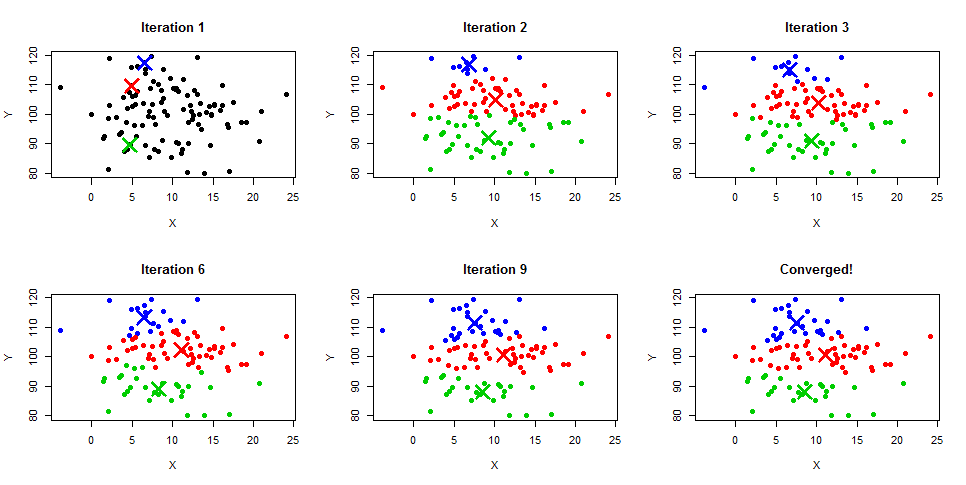
Fuente de la imagen: https://www.learnbymarketing.com/wp-content/uploads/2015/01/method-k-means-steps-example.png
A diferencia del algoritmo K-Means, el algoritmo MeanShift no requiere especificar el número de conglomerados. El propio algoritmo determina automáticamente el número de conglomerados, lo que supone una gran ventaja sobre K-Means si no estás seguro de los patrones de los datos.
MeanShift también se basa en centroides y asigna iterativamente cada punto de datos a clusters. El caso de uso más habitual de la agrupación MeanShift son las tareas de segmentación de imágenes.
El algoritmo MeanShift se basa en la estimación de la densidad del núcleo. De forma similar al algoritmo K-Means, los algoritmos MeanShift asignan iterativamente cada punto de datos hacia el centroide del clúster más cercano, que se inicializan aleatoriamente, y cada punto se desplaza iterativamente en el espacio en función de dónde se encuentre la mayor cantidad de puntos, es decir, el Modo (el modo es la mayor densidad de puntos de datos en la región, en el contexto del MeanShift).
Por eso el algoritmo MeanShift también se conoce como algoritmo de búsqueda de modo. Los pasos del algoritmo MeanShift son los siguientes:
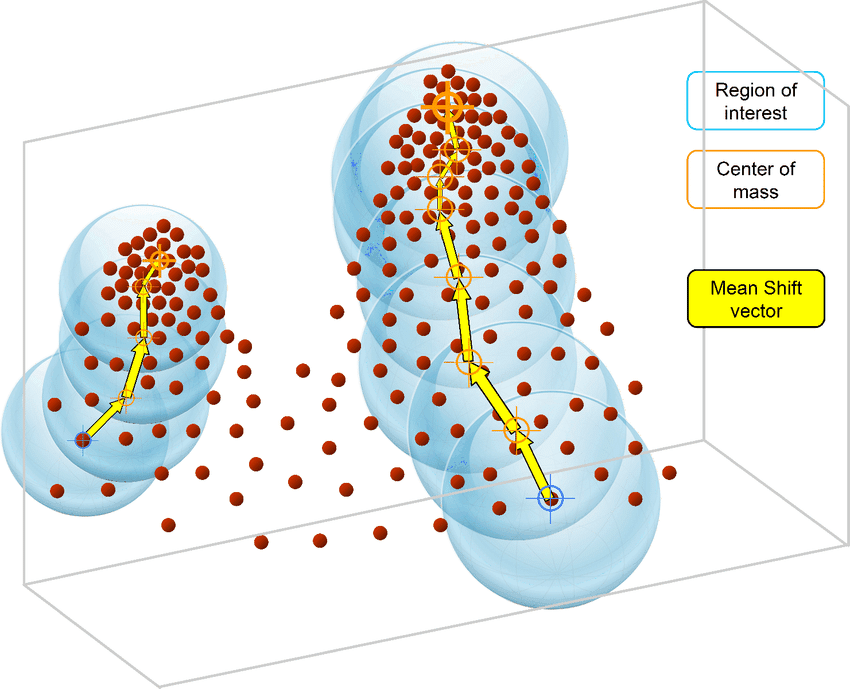
Fuente de la imagen: https://www.researchgate.net/publication/326242239/figure/fig3/AS:645578044231681@1530929208053/Intuitive-description-of-the-mean-shift-procedure-find-the-densest-regions-in-the.png
DBSCAN o Agrupación Espacialde Aplicacionescon RuidoBasada en la Densidades un algoritmo de agrupación no supervisado que funciona sobre la premisa de que los clusters son espacios densos en la región separados por regiones de menor densidad.
La mayor ventaja de este algoritmo sobre K-Means y MeanShift es que es robusto frente a los valores atípicos, lo que significa que no incluirá puntos de datos atípicos en ningún conglomerado.
Los algoritmos DBSCAN sólo requieren dos parámetros del usuario:
Cada punto de datos está rodeado por un círculo de radio épsilon, y DBSCAN los identifica como punto Núcleo, punto Frontera o punto Ruido. Se considera que un punto de datos es un punto Central si el círculo que lo rodea tiene un número mínimo de puntos especificado por el parámetro minPuntos.
Se considera Punto Límite si el número de puntos es inferior al mínimo requerido, y se considera Ruido si no hay puntos de datos adicionales situados en un radio épsilon de cualquier punto de datos. Los puntos de datos con ruido no se clasifican en ningún conglomerado (básicamente, son valores atípicos).
Algunos de los casos de uso habituales del algoritmo de agrupación DBSCAN son:
Comparando los algoritmos DBSCAN con los K-Means, las diferencias más comunes son:
Puedes aprender más sobre DBSCAN en Python en nuestro tutorial.
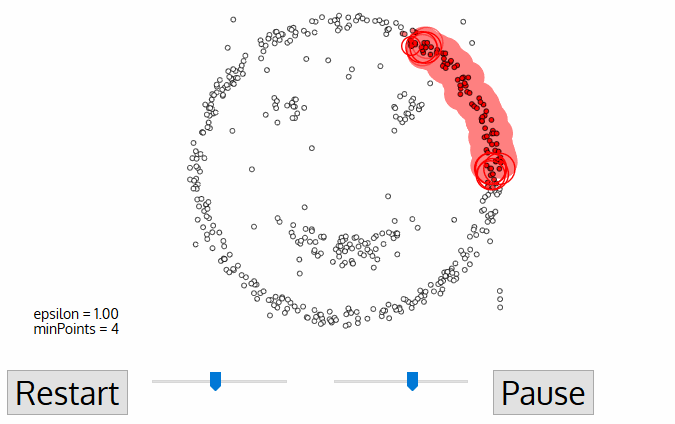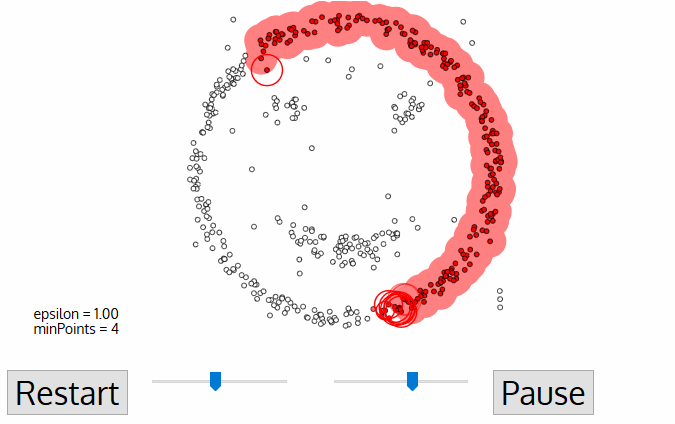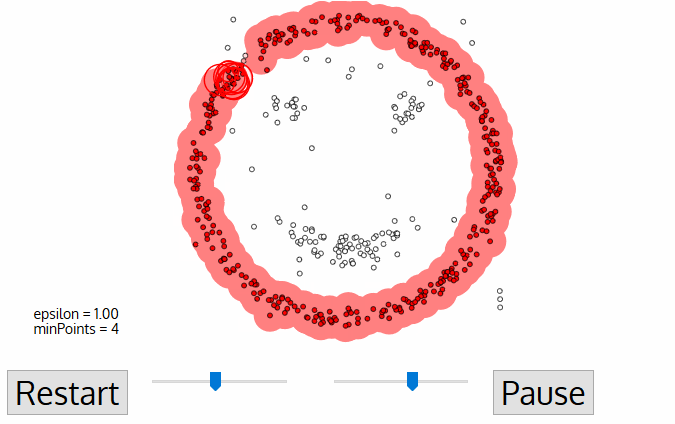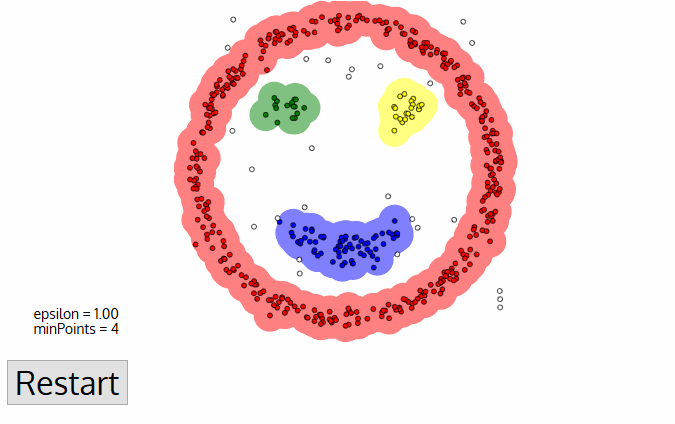
Fuente de la imagen: https://miro.medium.com/proxy/1*tc8UF-h0nQqUfLC8-0uInQ.gif
La agrupación jerárquica es un método de agrupación que construye una jerarquía de conglomerados. Hay dos tipos de este método.
Cuando se trata de analizar datos de redes sociales, la agrupación jerárquica es, con diferencia, el método de agrupación más común y popular. Los nodos (ramas) del grafo se comparan entre sí en función del grado de similitud que exista entre ellos. Uniendo grupos más pequeños de nodos relacionados entre sí, se pueden crear agrupaciones mayores.
La mayor ventaja de la agrupación jerárquica es que es fácil de entender y aplicar. Normalmente, el resultado de este método de agrupación se analiza en una imagen como la siguiente. Se llama Dendrograma.
Puedes obtener más información sobre la agrupación jerárquica y la agrupación de K-Means en nuestro tutorial sobre agrupación jerárquica en Python.
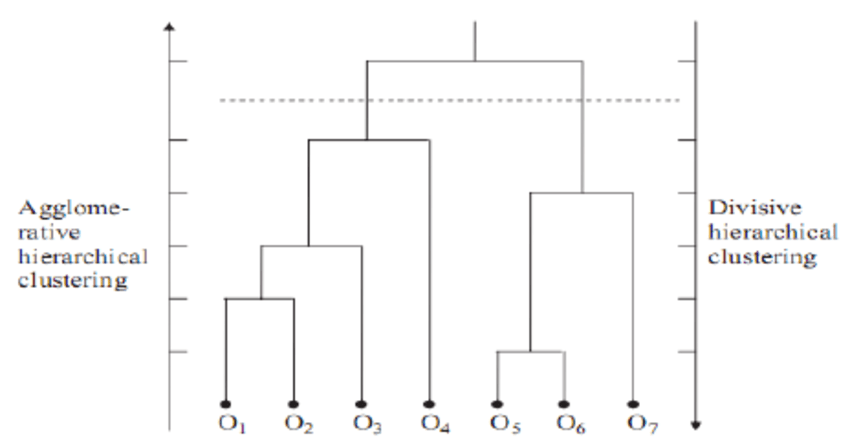
Fuente de la imagen: https://www.researchgate.net/profile/Rahmat-Widia-Sembiring/publication/48194320/figure/fig1/AS:307395533262848@1450300214331/Example-of-a-dendrogram-from-hierarchical-clustering.png
BIRCH son las siglas en inglés de Agrupación Jerárquica Iterativa Equilibrada. Se utiliza en conjuntos de datos muy grandes en los que K-Means no puede escalar prácticamente. El algoritmo BIRCH divide los datos grandes en clusters pequeños e intenta retener la máxima cantidad de información posible. A continuación, se agrupan los grupos más pequeños para obtener un resultado final, en lugar de agrupar directamente los grandes conjuntos de datos.
BIRCH se utiliza a menudo para complementar otros algoritmos de agrupación, generando un resumen de la información que los otros algoritmos de agrupación pueden utilizar. Los usuarios tienen que definir el número de conglomerados para entrenar el algoritmo BIRCH, de forma similar a como lo definimos en K-Means.
Una de las ventajas de utilizar BIRCH es que puede agrupar progresiva y dinámicamente puntos de datos multidimensionales. Esto se hace para crear clusters de la máxima calidad con unas limitaciones de memoria y tiempo dadas. En la mayoría de los casos, BIRCH sólo necesita hacer una búsqueda en toda la base de datos, lo que hace que BIRCH sea escalable.
El caso de uso más común del algoritmo de agrupación BIRCH es que se trata de una alternativa a KMeans eficiente en memoria que puede utilizarse para agrupar grandes conjuntos de datos que no pueden manejarse mediante KMeans debido a limitaciones de memoria o computación.
La agrupación es una técnica de aprendizaje automático muy útil, pero no es tan sencilla como algunos de los casos de uso del aprendizaje supervisado, como la clasificación y la regresión. Esto se debe principalmente a que la evaluación del rendimiento y la valoración de la calidad del modelo son difíciles, ya que existen algunos parámetros críticos, como el número de conglomerados, que el usuario debe definir correctamente para obtener resultados significativos.
Sin embargo, hay montones de casos de uso de la agrupación en una amplia gama de industrias, y es una habilidad importante incluso para los científicos de datos, los ingenieros de aprendizaje automático y los analistas de datos.
Si quieres saber más sobre Clustering y aprendizaje automático no supervisado y aprender su implementación utilizando el lenguaje Python y R, los cursos que se indican a continuación pueden ayudarte a progresar:
Cursos de Aprendizaje Automático
Curso
Curso
Curso
blog
Zoumana Keita
14 min
blog
Kurtis Pykes
9 min
blog
Moez Ali
8 min
blog
DataCamp Team
11 min
Tutorial
DataCamp Team
Tutorial
Eugenia Anello
