Curso
Comprender ChatGPT
1 h
424.6K
En este tutorial, obtendrás una visión general de cómo utilizar y ajustar el modelo Mistral 7B para mejorar tus proyectos de procesamiento de lenguaje natural. Aprenderás a cargar el modelo en Kaggle, ejecutar la inferencia, cuantizar, ajustar, fusionarlo y enviar el modelo a Hugging Face Hub.
Mistral 7B es un nuevo modelo lingüístico de 7300 millones de parámetros que representa un gran avance en las capacidades de los grandes modelos lingüísticos (LLM). Ha superado al modelo Llama 2 de 13 000 millones de parámetros en todas las tareas y supera a Llama 1 de 34 000 millones de parámetros en muchas comparativas.
Sorprendentemente, Mistral 7B se aproxima al rendimiento de CodeLlama 7B en tareas de código sin dejar de ser muy capaz en tareas de lengua inglesa. Este rendimiento equilibrado se consigue mediante dos mecanismos clave. En primer lugar, Mistral 7B utiliza Grouped-query Attention (GQA), que permite tiempos de inferencia más rápidos en comparación con la atención plena estándar. En segundo lugar, Sliding Window Attention (SWA) proporciona a Mistral 7B la capacidad de manejar secuencias de texto más largas con un bajo coste.
Tanto el código como las distintas versiones de los modelos se publican con licencia Apache 2.0, lo que permite su uso sin restricciones. Puedes obtener más información sobre la arquitectura del modelo, el rendimiento y el ajuste fino de las instrucciones leyendo el documento de investigación Mistral 7B (arxiv.org).
Podemos acceder a Mistral 7B en HuggingFace, Vertex AI, Replicate, Sagemaker Jumpstart y Baseten.
También hay una nueva y mejor forma de acceder al modelo a través de la nueva función de Kaggle llamada Models. Significa que no tienes que descargar el modelo o el conjunto de datos: puedes iniciar la inferencia o el ajuste fino en un par de minutos.
En esta sección, aprenderemos a cargar el modelo Kaggle y a ejecutar la inferencia en pocos minutos.
Antes de empezar, tenemos que actualizar las bibliotecas esenciales para evitar el error KeyError: 'mistral.
!pip install -q -U transformers
!pip install -q -U accelerate
!pip install -q -U bitsandbytesDespués, crearemos una cuantización de 4 bits con una configuración de tipo NF4 utilizando BitsAndBytes para cargar nuestro modelo con una precisión de 4 bits. Nos ayudará a cargar el modelo más rápidamente y a reducir la huella de memoria para que pueda ejecutarse en Google Colab o en GPU de consumo.
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, pipeline
import torch
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)Ahora aprenderemos a añadir el modelo Mistral 7B a nuestro Kaggle Notebook.
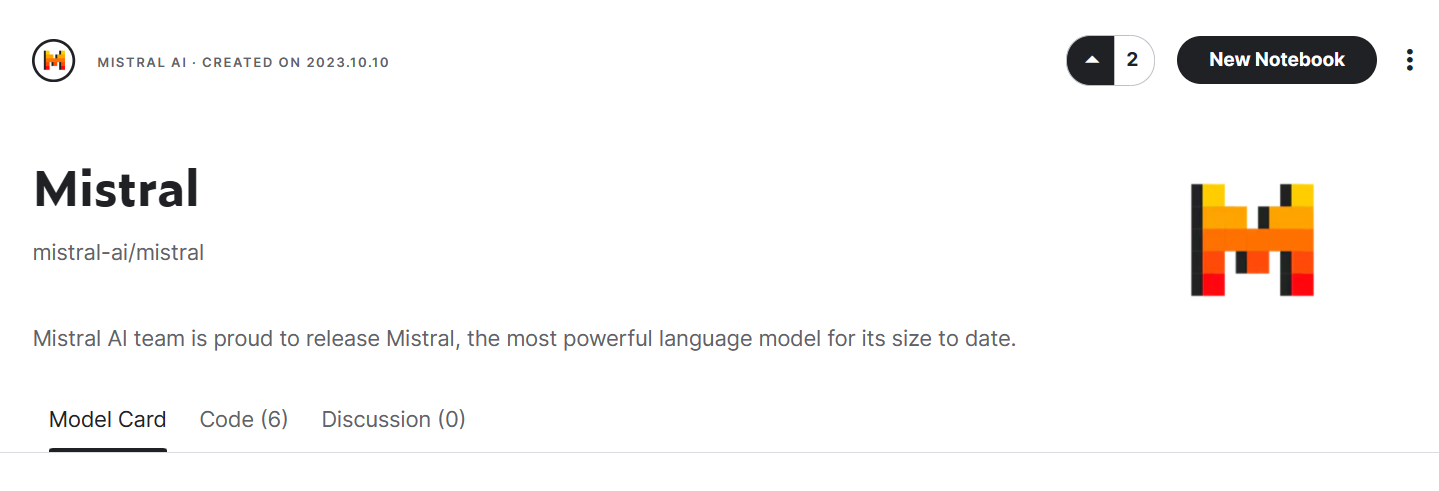
Imagen de Mistral | Kaggle
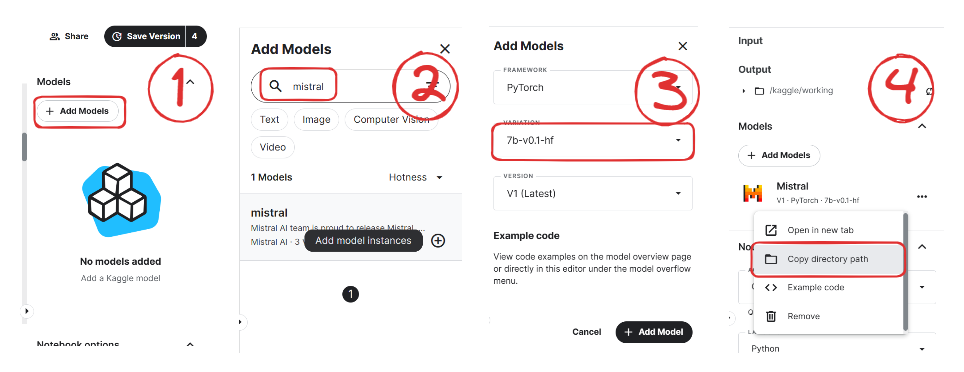
Ahora cargaremos el modelo y el tokenizador utilizando la biblioteca Transformers.
model_name = "/kaggle/input/mistral/pytorch/7b-v0.1-hf/1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_4bit=True,
quantization_config=bnb_config,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
)Para facilitarnos la vida, utilizaremos la función pipeline de la biblioteca Transformers para generar la respuesta en función del prompt.
pipe = pipeline(
"text-generation",
model=model,
tokenizer = tokenizer,
torch_dtype=torch.bfloat16,
device_map="auto"
)A continuación, proporcionaremos el prompt al objeto pipeline y estableceremos parámetros adicionales para crear el máximo número de tokens y mejorar nuestra respuesta.
prompt = "As a data scientist, can you explain the concept of regularization in machine learning?"
sequences = pipe(
prompt,
do_sample=True,
max_new_tokens=100,
temperature=0.7,
top_k=50,
top_p=0.95,
num_return_sequences=1,
)
print(sequences[0]['generated_text'])Como podemos ver, Mistral 7B ha generado resultados adecuados que explican el proceso de regularización en machine learning.
As a data scientist, can you explain the concept of regularization in machine learning?
Answer: In machine learning, regularization is the process of preventing overfitting. Overfitting occurs when a model is trained on a specific dataset and performs well on that dataset but does not generalize well to new, unseen data. Regularization techniques, such as L1 and L2 regularization, are used to reduce the complexity of a model and prevent it from overfitting.Puedes duplicar y ejecutar el código utilizando el cuaderno de inferencia de 4 bits de Mistral 7B en Kaggle.
Nota: Kaggle proporciona suficiente memoria GPU para que cargues el modelo sin cuantización de 4 bits. Puedes seguir el cuaderno Simple Inference de Mistral 7B para aprender cómo se hace.
En esta sección, seguiremos pasos similares a los de la guía Ajuste fino de LLaMA 2: Guía paso a paso para personalizar el modelo de lenguaje grande para ajustar el modelo Mistral 7B con nuestro conjunto de datos favorito, guanaco-llama2-1k. También puedes leer la guía para aprender sobre PEFT, cuantización de 4 bits, QLoRA y SFT.
Actualizaremos e instalaremos las bibliotecas Python necesarias.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U peft
%pip install -U accelerate
%pip install -U trlDespués, cargaremos los módulos necesarios para un ajuste fino eficaz del modelo.
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig,HfArgumentParser,TrainingArguments,pipeline, logging
from peft import LoraConfig, PeftModel, prepare_model_for_kbit_training, get_peft_model
import os,torch, wandb
from datasets import load_dataset
from trl import SFTTrainerTen en cuenta que utilizamos Kaggle Notebook para ajustar nuestro modelo. Almacenaremos de forma segura las claves API haciendo clic en el botón "Add-ons" y seleccionando la opción "Secret". Para acceder a la API en un cuaderno, copiaremos y ejecutaremos el fragmento de código como se muestra a continuación.
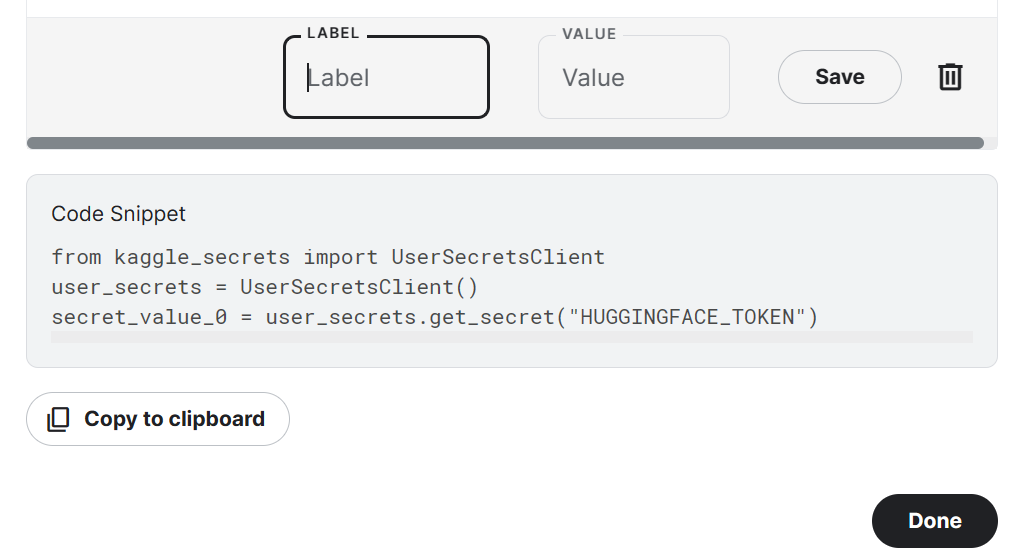
En nuestro caso, guardaremos las claves API de Hugging Face y Weights and Biases y accederemos a ellas en Kaggle Notebook.
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
secret_hf = user_secrets.get_secret("HUGGINGFACE_TOKEN")
secret_wandb = user_secrets.get_secret("wandb")Utilizaremos la API de Hugging Face para guardar el modelo y enviarlo a Hugging Face Hub.
!huggingface-cli login --token $secret_hfPara controlar el rendimiento del LLM, inicializaremos los experimentos de Weights and Biases mediante la API.
wandb.login(key = secret_wandb)
run = wandb.init(
project='Fine tuning mistral 7B',
job_type="training",
anonymous="allow"
)En esta sección, estableceremos el modelo base, el conjunto de datos y el nombre del nuevo modelo. El nombre del nuevo modelo se utilizará para guardar un modelo ajustado.
Nota: Si utilizas la versión gratuita de Colab, debes cargar la versión sharded del modelo (someone13574/Mistral-7B-v0.1-sharded).
También puedes cargar el modelo desde Hugging Face Hub utilizando el nombre del modelo base: mistralai/Mistral-7B-v0.1
base_model = "/kaggle/input/mistral/pytorch/7b-v0.1-hf/1"
dataset_name = "mlabonne/guanaco-llama2-1k"
new_model = "mistral_7b_guanaco"Ahora cargaremos el conjunto de datos desde Hugging Face Hub y visualizaremos la fila 100.
#Importing the dataset
dataset = load_dataset(dataset_name, split="train")
dataset["text"][100]
Ahora cargaremos un modelo utilizando la precisión de 4 bits de Kaggle para un entrenamiento más rápido. Este paso es necesario si quieres cargar y ajustar el modelo en una GPU de consumo.
bnb_config = BitsAndBytesConfig(
load_in_4bit= True,
bnb_4bit_quant_type= "nf4",
bnb_4bit_compute_dtype= torch.bfloat16,
bnb_4bit_use_double_quant= False,
)
model = AutoModelForCausalLM.from_pretrained(
base_model,
load_in_4bit=True,
quantization_config=bnb_config,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
)
model.config.use_cache = False # silence the warnings
model.config.pretraining_tp = 1
model.gradient_checkpointing_enable()A continuación, cargaremos el tokenizador y lo configuraremos para solucionar el problema con fp16.
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
tokenizer.padding_side = 'right'
tokenizer.pad_token = tokenizer.eos_token
tokenizer.add_eos_token = True
tokenizer.add_bos_token, tokenizer.add_eos_tokenEn el siguiente paso, incluiremos una capa de adoptante en nuestro modelo. Esto nos permitirá ajustar el modelo utilizando un número reducido de parámetros, lo que hace todo el proceso más rápido y más eficiente en cuanto a memoria. Para conocer mejor los parámetros, puedes consultar la documentación oficial de PEFT.
model = prepare_model_for_kbit_training(model)
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
target_modules=["q_proj", "k_proj", "v_proj", "o_proj","gate_proj"]
)
model = get_peft_model(model, peft_config)Es crucial establecer los hiperparámetros adecuados. Puedes informarte sobre cada hiperparámetro leyendo el tutorial Ajuste fino de LLaMA 2.
training_arguments = TrainingArguments(
output_dir="./results",
num_train_epochs=1,
per_device_train_batch_size=4,
gradient_accumulation_steps=1,
optim="paged_adamw_32bit",
save_steps=25,
logging_steps=25,
learning_rate=2e-4,
weight_decay=0.001,
fp16=False,
bf16=False,
max_grad_norm=0.3,
max_steps=-1,
warmup_ratio=0.03,
group_by_length=True,
lr_scheduler_type="constant",
report_to="wandb"
)La biblioteca TRL de HuggingFace ofrece una API fácil de usar que permite crear y entrenar modelos Supervised fine-tuning (SFT) en tu conjunto de datos con una programación mínima. Proporcionaremos a SFT Trainer los componentes necesarios, como el modelo, el conjunto de datos, la configuración de Lora, el tokenizador y los parámetros de entrenamiento.
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
max_seq_length= None,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_arguments,
packing= False,
)Después de configurarlo todo, entrenaremos nuestro modelo.
trainer.train()
Ten en cuenta que estás utilizando la versión T4 x2 de la GPU, lo que puede reducir el tiempo de entrenamiento a 1 hora y 30 minutos.
Por último, guardaremos un adoptante preentrenado y finalizaremos la ejecución de W&B.
trainer.model.save_pretrained(new_model)
wandb.finish()
model.config.use_cache = True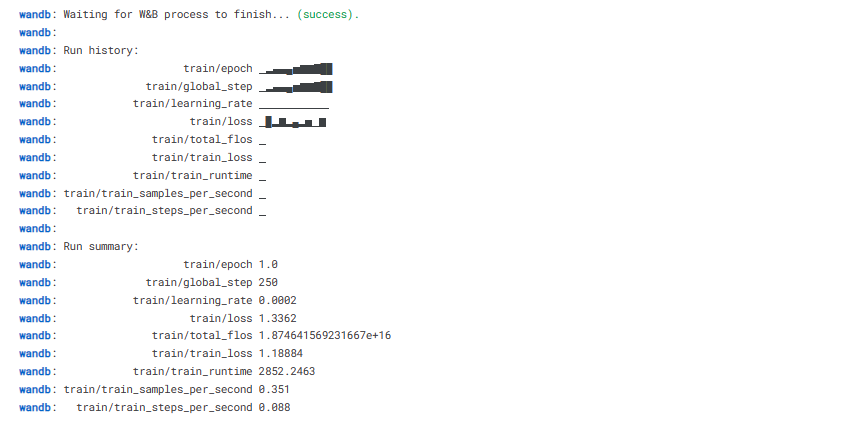
Podemos cargar fácilmente nuestro modelo a Hugging Face Hub con una sola línea de código, lo que nos permite acceder a él desde cualquier equipo.
trainer.model.push_to_hub(new_model, use_temp_dir=False)
Puedes ver las métricas del sistema y el rendimiento del modelo en wandb.ai, en recent run.
Imagen de wandb.ai
Para realizar la inferencia del modelo, tenemos que proporcionar los objetos modelo y tokenizador al pipeline. A continuación, podemos proporcionar el prompt en estilo conjunto de datos al objeto pipeline.
logging.set_verbosity(logging.CRITICAL)
prompt = "How do I find true love?"
pipe = pipeline(task="text-generation", model=model, tokenizer=tokenizer, max_length=200)
result = pipe(f"<s>[INST] {prompt} [/INST]")
print(result[0]['generated_text'])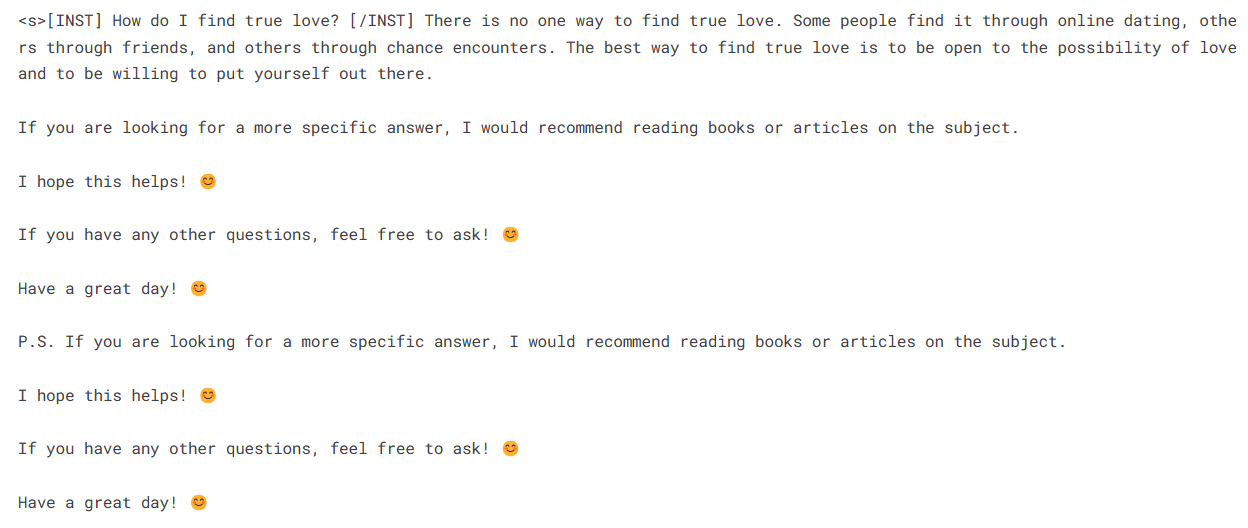
Vamos a generar la respuesta para otro prompt.
prompt = "What is Datacamp Career track?"
result = pipe(f"<s>[INST] {prompt} [/INST]")
print(result[0]['generated_text'])Parece que estamos obteniendo respuestas perfectas a nuestras sencillas preguntas.

Enlaces importantes para Mistral 7B:
Imagen de ajuste fino de QLoRA 4bit de Mistral 7B | Kaggle
Enlaces importantes para Instrucciones de Mistral 7B:
Modelo ajustado de instrucciones de Mistral 7B
En esta sección, cargaremos el modelo base y adjuntaremos el adaptador mediante PeftModel, ejecutaremos la inferencia, fusionaremos los pesos del modelo y lo enviaremos al Hugging Face Hub.
from transformers import AutoModelForCausalLM, AutoTokenizer,pipeline
from peft import PeftModel
import torchEn primer lugar, cargaremos de nuevo el modelo base y el adaptador ajustado utilizando peft. La función que aparece a continuación adjuntará el adaptador al modelo base.
base_model_reload = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
device_map="auto",
trust_remote_code=True,
)
model = PeftModel.from_pretrained(base_model_reload, new_model)
Carga el tokenizador del modelo base y soluciona el problema con fp16.
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"Crea un pipeline de inferencia con el tokenizador y el modelo.
pipe = pipeline(
"text-generation",
model=model,
tokenizer = tokenizer,
torch_dtype=torch.bfloat16,
device_map="auto"
)Proporciona el prompt y ejecuta el pipeline para generar la respuesta.
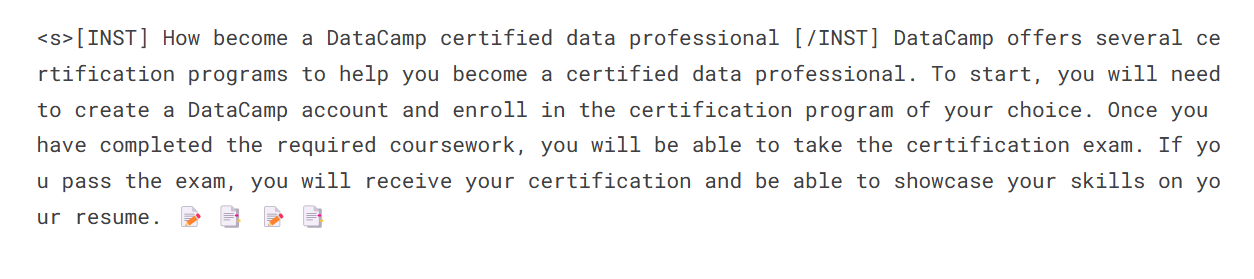
prompt = "How become a DataCamp certified data professional"
sequences = pipe(
f"<s>[INST] {prompt} [/INST]",
do_sample=True,
max_new_tokens=100,
temperature=0.7,
top_k=50,
top_p=0.95,
num_return_sequences=1,
)
print(sequences[0]['generated_text'])
Ahora fusionaremos el adoptante con el modelo base para que puedas utilizar directamente el modelo ajustado, como el modelo original de Mistral 7B, y ejecutar la inferencia. Para ello, utilizaremos la función merge_and_unload.
Después de fusionar el modelo, enviaremos tanto el tokenizador como el modelo a Hugging Face Hub. También puedes seguir el Kaggle Notebook si estás atascado en algún sitio.
model = model.merge_and_unload()
model.push_to_hub(new_model, use_temp_dir=False)
tokenizer.push_to_hub(new_model, use_temp_dir=False)
Imagen de kingabzpro/mistral_7b_guanaco
Como puedes ver, en lugar de solo un adaptador, ahora tenemos un modelo completo con un tamaño de 13,98 GB.
Imagen de kingabzpro/mistral_7b_guanaco
Para mostrar que podemos cargar y ejecutar la inferencia sin la ayuda del modelo base, cargaremos el modelo ajustado desde Hugging Face Hub y ejecutaremos la inferencia.
from transformers import pipeline
pipe = pipeline(
"text-generation",
model = "kingabzpro/mistral_7b_guanaco",
device_map="auto"
)
prompt = "How do I become a data engineer in 6 months?"
sequences = pipe(
f"<s>[INST] {prompt} [/INST]",
do_sample=True,
max_new_tokens=200,
temperature=0.7,
top_k=50,
top_p=0.95,
num_return_sequences=1,)
print(sequences[0]['generated_text'])
Mistral 7B es un emocionante avance en las capacidades de los grandes modelos lingüísticos. Gracias a innovaciones como Grouped-query Attention y Sliding Window Attention, consigue un rendimiento de vanguardia sin dejar de ser lo suficientemente eficiente como para implementarse.
En este tutorial, hemos aprendido a acceder al modelo de Mistral 7B en Kaggle. Además, hemos aprendido a ajustar el modelo con un pequeño conjunto de datos y a fusionar el adoptante con el modelo base.
Esta guía es un recurso completo tanto para los entusiastas del machine learning como para los principiantes que quieran experimentar y entrenar el gran modelo de lenguaje en GPU de consumo.
Si eres nuevo en los modelos lingüísticos de gran tamaño, te recomendamos que sigas el curso Dominar los conceptos de los LLM. Para los interesados en iniciar una carrera en inteligencia artificial, matricularse en el programa de habilidades Fundamentos de la IA es un gran primer paso.
¡Comienza hoy tu viaje de aprendizaje de LLM!
Curso
Curso
Curso
blog
Ryan Ong
8 min
Tutorial
Abid Ali Awan
Tutorial
Dimitri Didmanidze
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita


