programa
Fundamentos de la IA
10 h
| Lee la versión en inglés 🇺🇲 de este artículo. |
Tras el lanzamiento de la primera versión de LLaMA por parte de Meta, se inició una nueva carrera para construir mejores modelos de lenguaje grandes (LLM) que pudieran rivalizar con modelos como GPT-3.5 (ChatGPT). La comunidad de código abierto publicó rápidamente modelos cada vez más potentes. Parecía Navidad para los entusiastas de la IA, con el anuncio frecuente de nuevos avances.
Sin embargo, estos avances tenían sus inconvenientes. La mayoría de los modelos de código abierto tienen una licencia restringida, lo que significa que solo pueden utilizarse con fines de investigación. En segundo lugar, solo las grandes empresas o institutos de investigación con presupuestos considerables podían permitirse ajustar o entrenar los modelos. Por último, implementar y mantener grandes modelos de última generación resultaba caro.
La nueva versión de los modelos LLaMA pretende resolver estos problemas. Cuenta con una licencia comercial, lo que lo hace accesible a más organizaciones. Además, las nuevas metodologías permiten el ajuste fino en GPU de consumo con memoria limitada.
Esta democratización de la IA es fundamental para su adopción generalizada. Al superar las barreras de entrada, incluso las pequeñas empresas pueden construir modelos personalizados adaptados a sus necesidades y presupuestos.
En este tutorial, exploraremos Llama-2 y demostraremos cómo ajustarlo en un nuevo conjunto de datos utilizando Google Colab. Además, veremos nuevas metodologías y técnicas de ajuste fino que pueden ayudar a reducir el uso de memoria y acelerar el proceso de entrenamiento.

Imagen generada por el autor con DALL-E 3
Llama 2 es una colección de LLM de código abierto de segunda generación de Meta que incluye una licencia comercial. Está diseñado para gestionar una amplia gama de tareas de procesamiento de lenguaje natural, con modelos cuya escala oscila entre 7000 millones y 70 000 millones de parámetros. Descubre más sobre los modelos LLaMA leyendo nuestro artículo Introducción a LLaMA de Meta AI: Potenciar la innovación en IA.
Llama-2-Chat, optimizado para el diálogo, ha mostrado un rendimiento similar al de modelos populares de código cerrado como ChatGPT y PaLM. Podemos incluso mejorar el rendimiento del modelo ajustándolo con un conjunto de datos conversacionales de alta calidad.
El ajuste fino en machine learning es el proceso de ajustar los pesos y los parámetros de un modelo preentrenado con nuevos datos para aumentar su rendimiento en una tarea específica. Consiste en entrenar el modelo con un nuevo conjunto de datos específico para una tarea concreta y actualizar los pesos del modelo para adaptarlos a los nuevos datos. Lee más sobre el ajuste fino en nuestra guía sobre el ajuste fino de GPT 3.5.
Es imposible ajustar los LLM en hardware de consumo debido a la inadecuación de las VRAM y la computación. Sin embargo, en este tutorial superaremos estos retos de memoria y computación y entrenaremos nuestro modelo utilizando una versión gratuita de Google Colab Notebook.
En esta parte, conoceremos todos los pasos necesarios para ajustar el modelo Llama 2 con 7000 millones de parámetros en una GPU T4. Tienes la opción de utilizar una GPU gratuita en Google Colab o Kaggle. El código funciona en ambas plataformas.
La GPU T4 Colab tiene una VRAM limitada de 16 GB, que apenas es suficiente para almacenar los pesos de Llama 2-7b, lo que significa que no es posible un ajuste fino completo, y tenemos que utilizar técnicas de ajuste fino eficientes en cuanto a parámetros, como LoRA o QLoRA.
Utilizaremos la técnica QLoRA para ajustar el modelo con una precisión de 4 bits y optimizar el uso de la VRAM. Para ello, utilizaremos el ecosistema Hugging Face de bibliotecas LLM: transformers, accelerate, peft, trl y bitsandbytes.
Empezaremos instalando las bibliotecas necesarias.
%%capture
%pip install accelerate peft bitsandbytes transformers trlDespués, cargaremos los módulos necesarios de estas bibliotecas.
import os
import torch
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline,
logging,
)
from peft import LoraConfig
from trl import SFTTrainerPuedes acceder al modelo oficial Llama-2 de Meta desde Hugging Face, pero tienes que solicitarlo y esperar un par de días para obtener la confirmación. En lugar de esperar, utilizaremos Llama-2-7b-chat-hf de NousResearch como modelo base. Es igual que el original, pero de fácil acceso.
Imagen de Hugging Face
Ajustaremos nuestro modelo base utilizando un conjunto de datos menor llamado mlabonne/guanaco-llama2-1k y escribiremos el nombre del modelo ajustado.
# Model from Hugging Face hub
base_model = "NousResearch/Llama-2-7b-chat-hf"
# New instruction dataset
guanaco_dataset = "mlabonne/guanaco-llama2-1k"
# Fine-tuned model
new_model = "llama-2-7b-chat-guanaco"
Conjunto de datos en Hugging Face
Cargaremos el conjunto de datos "guanaco-llama2-1k" del hub de Hugging Face. El conjunto de datos contiene 1000 muestras, se ha procesado para ajustarse al formato de prompt de Llama 2 y es un subconjunto del excelente conjunto de datos timdettmers/openassistant-guanaco.
dataset = load_dataset(guanaco_dataset, split="train")Dataset parquet downloaded and prepared to /root/.cache/huggingface/datasets/parquet/mlabonne--guanaco-llama2-1k-f1f1134768f90029/0.0.0/0b6d5799bb726b24ad7fc7be720c170d8e497f575d02d47537de9a5bac074901. Subsequent calls will reuse this data.La cuantificación de 4 bits mediante QLoRA permite un ajuste fino eficiente de modelos LLM enormes en hardware de consumo, manteniendo un alto rendimiento. Esto mejora mucho la accesibilidad y la usabilidad para las aplicaciones del mundo real.
QLoRA cuantifica un modelo lingüístico preentrenado con 4 bits y congela los parámetros. A continuación, se añade al modelo un pequeño número de capas de adaptador de bajo rango entrenables.
Durante el ajuste fino, los gradientes se retropropagan a través del modelo cuantificado congelado de 4 bits solo en las capas del adaptador de bajo rango. Así, todo el modelo preentrenado permanece fijo en 4 bits, mientras que solo se actualizan los adaptadores. Además, la cuantificación de 4 bits no perjudica al rendimiento del modelo.
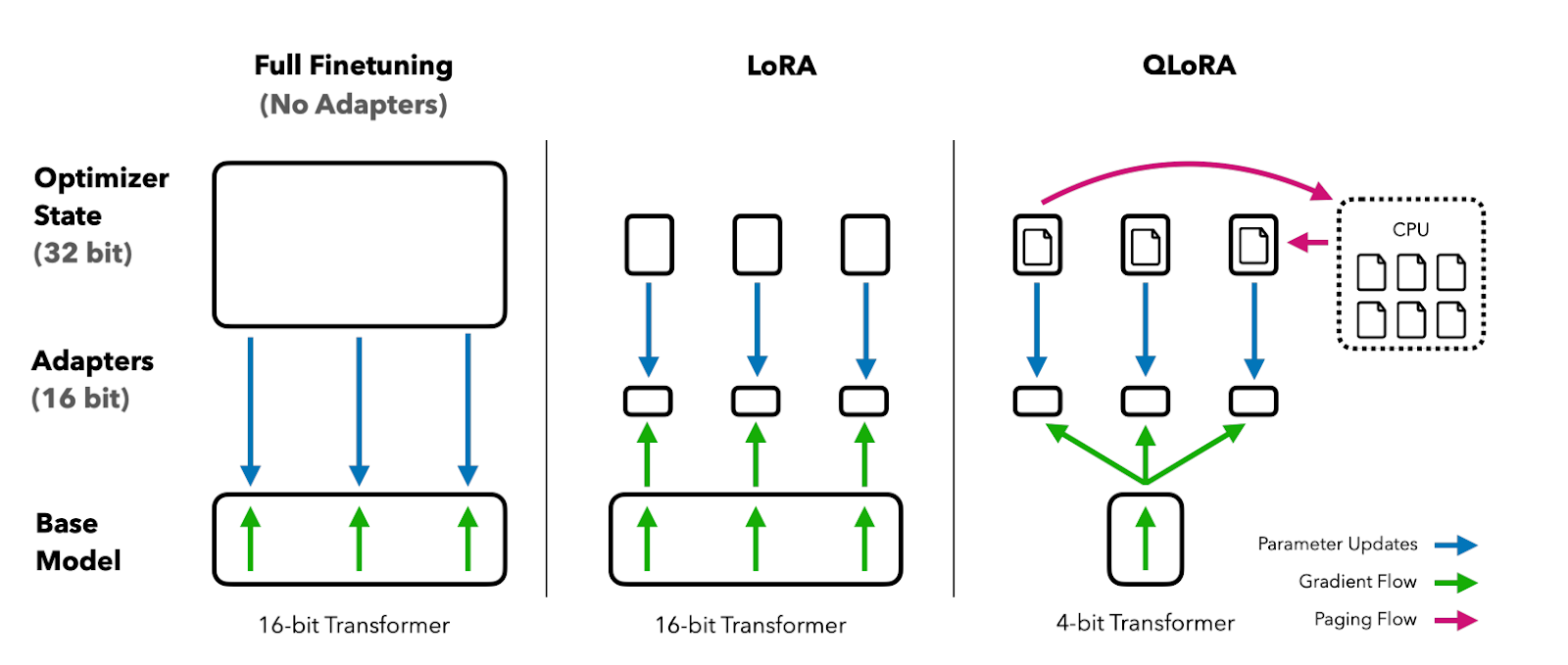
Imagen del documento QLoRA
Puedes leer el documento para entenderlo mejor.
En nuestro caso, creamos una cuantificación de 4 bits con una configuración de tipo NF4 utilizando BitsAndBytes.
compute_dtype = getattr(torch, "float16")
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=False,
)Ahora cargaremos un modelo utilizando precisión de 4 bits con compute-dtype "float16" de Hugging Face para un entrenamiento más rápido.
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=quant_config,
device_map={"": 0}
)
model.config.use_cache = False
model.config.pretraining_tp = 1A continuación, cargaremos el tokenizador de Hugging Face y pondremos padding_side a "derecha" para solucionar el problema con fp16.
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"El ajuste fino tradicional de los modelos lingüísticos preentrenados (PLM) requiere la actualización de todos los parámetros del modelo, lo que es caro desde el punto de vista informático y requiere cantidades ingentes de datos.
Parameter-Efficient Fine-Tuning (PEFT) funciona actualizando solo un pequeño subconjunto de los parámetros del modelo, lo que lo hace mucho más eficiente. Infórmate sobre los parámetros leyendo la documentación oficial de PEFT.
peft_params = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)A continuación se muestra una lista de hiperparámetros que pueden utilizarse para optimizar el proceso de entrenamiento:
training_params = TrainingArguments(
output_dir="./results",
num_train_epochs=1,
per_device_train_batch_size=4,
gradient_accumulation_steps=1,
optim="paged_adamw_32bit",
save_steps=25,
logging_steps=25,
learning_rate=2e-4,
weight_decay=0.001,
fp16=False,
bf16=False,
max_grad_norm=0.3,
max_steps=-1,
warmup_ratio=0.03,
group_by_length=True,
lr_scheduler_type="constant",
report_to="tensorboard"
)El ajuste fino supervisado (SFT) es un paso clave en el aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF). La biblioteca TRL de Hugging Face proporciona una API fácil de usar para crear modelos SFT y entrenarlos con tu conjunto de datos con solo unas líneas de código. Incluye herramientas para entrenar modelos lingüísticos mediante el aprendizaje por refuerzo, empezando por el ajuste fino supervisado, siguiendo por el modelado de recompensas y terminando con la optimización de políticas proximales (PPO).
Proporcionaremos a SFT Trainer el modelo, el conjunto de datos, la configuración de Lora, el tokenizador y los parámetros de entrenamiento.
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_params,
dataset_text_field="text",
max_seq_length=None,
tokenizer=tokenizer,
args=training_params,
packing=False,
)Utilizaremos .train() para ajustar el modelo Llama 2 con un nuevo conjunto de datos. El modelo tardó una hora y media en completar 1 época.

Después de entrenar el modelo, guardaremos los tokenizadores y el adaptador del modelo. También puedes cargar el modelo en Hugging Face utilizando una API similar.
trainer.model.save_pretrained(new_model)
trainer.tokenizer.save_pretrained(new_model)
Ahora podemos revisar los resultados del entrenamiento en la sesión interactiva de Tensorboard.
from tensorboard import notebook
log_dir = "results/runs"
notebook.start("--logdir {} --port 4000".format(log_dir))
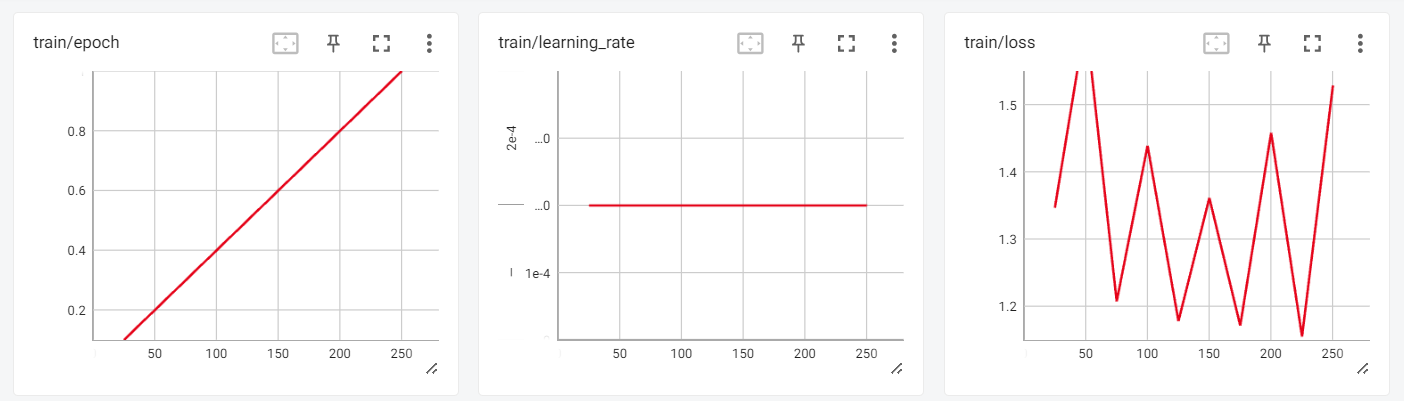
Para probar nuestro modelo ajustado, utilizaremos el pipeline de generación de texto de los transformadores y formularemos preguntas sencillas como "¿Quién es Leonardo da Vinci?".
logging.set_verbosity(logging.CRITICAL)
prompt = "Who is Leonardo Da Vinci?"
pipe = pipeline(task="text-generation", model=model, tokenizer=tokenizer, max_length=200)
result = pipe(f"<s>[INST] {prompt} [/INST]")
print(result[0]['generated_text'])Salida:
Como podemos ver, obtuvimos resultados sorprendentes.
<s>[INST] Who is Leonardo Da Vinci? [/INST] Leonardo da Vinci (1452-1519) was an Italian polymath, artist, inventor, and engineer.
Da Vinci is widely considered one of the greatest painters of all time, and his works include the famous Mona Lisa. He was also an accomplished engineer, inventor, and anatomist, and his designs for machines and flight were centuries ahead of his time.
Da Vinci was born in the town of Vinci, Italy, and he was the illegitimate son of a local notary. Despite his humble origins, he was able to study art and engineering in Florence, and he became a renowned artist and inventor.
Da Vinci's work had a profound impact on the Renaissance, and his legacy continues to inspire artists, engineers, and inventors to this day. He
Hagamos otra pregunta.
prompt = "What is Datacamp Career track?"
result = pipe(f"<s>[INST] {prompt} [/INST]")
print(result[0]['generated_text'])Salida:
Guanaco es un conjunto de datos de alta calidad que se ha utilizado para ajustar los LLM más avanzados en el pasado. Todo el conjunto de datos Guanaco está disponible en Hugging Face y tiene potencial para lograr un rendimiento aún mayor en diversas tareas de lenguaje natural.
<s>[INST] What is Datacamp Career track? [/INST] DataCamp Career Track is a program that offers a comprehensive learning experience to help you build your skills and prepare for a career in data science.
The program includes a range of courses, projects, and assessments that are designed to help you build your skills in data science. You will learn how to work with data, create visualizations, and build predictive models.
In addition to the technical skills, you will also learn how to communicate your findings to stakeholders and how to work with a team to solve complex problems.
The program is designed to be flexible, so you can learn at your own pace and on your own schedule. You will also have access to a community of learners and mentors who can provide support and guidance throughout the program.
Overall, DataCamp Career Track is a great way to build your skills and prepare for a career inAquí tienes el cuaderno de Colab con el código y las salidas para ayudarte en tu viaje de programación.
A continuación, puedes utilizar LlamaIndex y construir tu propia aplicación de IA utilizando tu nuevo modelo de entrenamiento siguiendo el tutorial LlamaIndex: Añadir datos personales a los LLM. Puedes inspirarte para tu proyecto echando un vistazo a 5 proyectos construidos con modelos generativos y herramientas de código abierto.
El tutorial proporcionó una guía completa sobre el ajuste fino del modelo LLaMA 2 utilizando técnicas como QLoRA, PEFT y SFT para superar las limitaciones de memoria y cálculo. Aprovechando bibliotecas de Hugging Face como transformers, accelerate, peft, trl y bitsandbytes, pudimos ajustar correctamente el modelo LLaMA 2 de 7000 millones de parámetros en una GPU de consumo.
En general, este tutorial ejemplificó cómo los avances recientes han permitido la democratización y accesibilidad de grandes modelos lingüísticos, permitiendo incluso a los aficionados construir IA de vanguardia con recursos limitados.
Si eres nuevo en los grandes modelos lingüísticos, considera la posibilidad de realizar el curso Dominar los conceptos de los LLM. Y, si quieres empezar tu carrera en inteligencia artificial, deberías matricularte en el programa de habilidades Fundamentos de la IA.
¡Comienza hoy tu viaje a la IA!
programa
Curso
Curso
blog
Ryan Ong
8 min
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita
Tutorial
Dimitri Didmanidze
