Curso
Importación intermedia de datos en Python
2 h
210.9K

Pandas es un popular paquete de Python para la ciencia de datos, y con razón: ofrece estructuras de datos potentes, expresivas y flexibles que facilitan la manipulación y el análisis de datos, entre otras muchas cosas. El DataFrame es una de estas estructuras.
Este tutorial cubre los DataFrames de pandas, desde las manipulaciones básicas hasta las operaciones avanzadas, abordando 11 de las preguntas más populares para que entiendas -y evites- las dudas de los Pythonistas que te han precedido.
Para practicar más, ¡prueba gratis el primer capítulo de este curso sobre DataFrames de Pandas!
Antes de empezar, recapitulemos brevemente qué son los DataFrames.
Los que están familiarizados con R conocen el marco de datos como una forma de almacenar datos en cuadrículas rectangulares que pueden verse fácilmente. Cada fila de estas cuadrículas corresponde a medidas o valores de una instancia, mientras que cada columna es un vector que contiene datos de una variable concreta. Esto significa que las filas de un marco de datos no tienen por qué contener, sino que pueden contener, el mismo tipo de valores: pueden ser numéricos, de caracteres, lógicos, etc.
Ahora bien, los DataFrames en Python son muy similares: vienen con la biblioteca pandas, y se definen como estructuras de datos bidimensionales etiquetadas con columnas de tipos potencialmente diferentes.
En general, se podría decir que el DataFrame de pandas consta de tres componentes principales: los datos, el índice y las columnas.
DataFrame de PandasSeries de Pandas: una matriz unidimensional etiquetada capaz de contener cualquier tipo de datos con etiquetas de eje o índice. Un ejemplo de objeto Serie es una columna de un DataFrame.ndarray de NumPy, que puede ser un registro o estructuradondarray bidimensionalndarray de diccionarios unidimensionales, listas, diccionarios o Series.Observa la diferencia entre np.ndarray y np.array(). El primero es un tipo de datos real, mientras que el segundo es una función para hacer matrices a partir de otras estructuras de datos.
Las matrices estructuradas permiten a los usuarios manipular los datos por campos con nombre: en el ejemplo siguiente, se crea una matriz estructurada de tres tuplas. El primer elemento de cada tupla se llamará foo y será del tipo int, mientras que el segundo elemento se llamará bar y será un flotador.
En cambio, las matrices de registros amplían las propiedades de las matrices estructuradas. Permiten a los usuarios acceder a campos de matrices estructuradas por atributos, en lugar de por índices. A continuación verás que se accede a los valores de foo en la matriz de registros r2.
Un ejemplo:
import pandas as pd
import numpy as np
# A structured array
my_array = np.ones(3, dtype=([('foo', int), ('bar', float)]))
# Print the structured array
print(my_array['foo'])
# A record array
my_array2 = my_array.view(np.recarray)
# Print the record array
print(my_array2.foo)[1 1 1]
[1 1 1]Si aún tienes dudas sobre los DataFrames de Pandas y en qué se diferencian de otras estructuras de datos como una matriz NumPy o una Serie, puedes ver la pequeña presentación que aparece a continuación:
Ten en cuenta que en este post, la mayoría de las veces, ya se han cargado las librerías que necesitas. La biblioteca Pandas suele importarse con el alias pd, mientras que la biblioteca NumPy se carga como np. Recuerda que cuando codifiques en tu propio entorno de ciencia de datos, no debes olvidar este paso de importación, que se escribe así:
import numpy as np
import pandas as pdAhora que ya no te queda ninguna duda sobre qué son los DataFrames, qué pueden hacer y en qué se diferencian de otras estructuras, ¡es hora de abordar las preguntas más comunes que tienen los usuarios sobre cómo trabajar con ellos!
Ejecuta y edita el código de este tutorial en línea
Ejecutar códigoObviamente, crear tus DataFrames es el primer paso en casi todo lo que quieras hacer cuando se trata de manejar datos en Python. A veces, querrás empezar desde cero, pero también puedes convertir otras estructuras de datos, como listas o matrices NumPy, en DataFrames de Pandas. En esta sección, sólo cubrirás lo segundo. Sin embargo, si quieres leer más sobre cómo hacer DataFrames vacíos que puedas rellenar con datos más adelante, ve a la sección 7.
Entre las muchas cosas que pueden servir de entrada para hacer un "DataFrame", un NumPy ndarray es una de ellas. Para crear un marco de datos a partir de una matriz NumPy, basta con pasársela a la función DataFrame() en el argumento data.
data = np.array([['','Col1','Col2'],
['Row1',1,2],
['Row2',3,4]])
print(pd.DataFrame(data=data[1:,1:],
index=data[1:,0],
columns=data[0,1:]))
Col1 Col2
Row1 1 2
Row2 3 4
Presta atención a cómo los trozos de código anteriores seleccionan elementos de la matriz NumPy para construir el DataFrame: primero seleccionas los valores que contienen las listas que empiezan por Row1 y Row2, luego seleccionas los números de índice o fila Row1 y Row2 y después los nombres de columna Col1 y Col2.
A continuación, también verás que, en el ejemplo anterior, imprimimos una pequeña selección de los datos. Esto funciona igual que el subconjunto de matrices NumPy en 2D: primero indicas la fila en la que quieres buscar tus datos, y luego la columna. ¡No olvides que los índices empiezan en 0! En data, en el ejemplo anterior, vas y buscas en las filas desde el índice 1 hasta el final, y seleccionas todos los elementos que vienen después del índice 1. Como resultado, acabas seleccionando 1, 2, 3 y 4.
Este planteamiento de hacer DataFrames será el mismo para todas las estructuras que DataFrame() puede tomar como entrada.
Mira el ejemplo siguiente:
Recuerda que la biblioteca Pandas ya se ha importado como pd.
# Take a 2D array as input to your DataFrame
my_2darray = np.array([[1, 2, 3], [4, 5, 6]])
print(pd.DataFrame(my_2darray))
# Take a dictionary as input to your DataFrame
my_dict = {1: ['1', '3'], 2: ['1', '2'], 3: ['2', '4']}
print(pd.DataFrame(my_dict))
# Take a DataFrame as input to your DataFrame
my_df = pd.DataFrame(data=[4,5,6,7], index=range(0,4), columns=['A'])
print(pd.DataFrame(my_df))
# Take a Series as input to your DataFrame
my_series = pd.Series({"Belgium":"Brussels", "India":"New Delhi", "United Kingdom":"London", "United States":"Washington"})
print(pd.DataFrame(my_series))0 1 2
0 1 2 3
1 4 5 6
1 2 3
0 1 1 2
1 3 2 4
A
0 4
1 5Observa que el índice de tu Serie (y del DataFrame) contiene las claves del diccionario original, pero que están ordenadas: Belgium será el índice en 0, mientras que United States será el índice en 3.
Cuando hayas creado tu DataFrame, quizá quieras saber algo más sobre él. Puedes utilizar la propiedad shape o la función len() en combinación con la propiedad .index:
df = pd.DataFrame(np.array([[1, 2, 3], [4, 5, 6]]))
# Use the `shape` property
print(df.shape)
# Or use the `len()` function with the `index` property
print(len(df))(2, 3)
2Estas dos opciones te proporcionan información ligeramente distinta sobre tu DataFrame: la propiedad shape te proporcionará las dimensiones de tu DataFrame. Esto significa que conocerás la anchura y la altura de tu DataFrame. Por otra parte, la función len(), en combinación con la propiedad index, sólo te dará información sobre la altura de tu DataFrame.
Pero todo esto no tiene nada de extraordinario, ya que das explícitamente en la propiedad index.
También podrías utilizar df[0].count() para saber más sobre la altura de tu DataFrame, pero esto excluirá los valores de NaN (si los hay). Por eso, llamar a .count() en tu DataFrame no siempre es la mejor opción.
Si quieres más información sobre las columnas de tu DataFrame, siempre puedes ejecutar list(my_dataframe.columns.values).
Ahora que has colocado tus datos en una estructura DataFrame de Pandas más cómoda, ¡es hora de ponerse manos a la obra!
Esta primera sección te guiará a través de los primeros pasos para trabajar con DataFrames en Python. Cubrirá las operaciones básicas que puedes hacer en tu recién creado DataFrame: añadir, seleccionar, eliminar, renombrar y más.
Antes de empezar a añadir, eliminar y renombrar los componentes de tu DataFrame, primero tienes que saber cómo puedes seleccionar estos elementos. Entonces, ¿cómo lo haces?
Aunque aún recuerdes cómo hacerlo de la sección anterior: seleccionar un índice, una columna o un valor de tu DataFrame no es tan difícil, sino todo lo contrario. Es similar a lo que ves en otros lenguajes (¡o paquetes!) que se utilizan para el análisis de datos. Si no estás convencido, considera lo siguiente:
En R, utilizas la notación [,] para acceder a los valores del marco de datos.
Supongamos que tienes un DataFrame como éste:
A B C
0 1 2 3
1 4 5 6
2 7 8 9Y quieres acceder al valor que está en el índice 0, en la columna "A".
Existen varias opciones para recuperar tu valor 1:
df = pd.DataFrame({"A":[1,4,7], "B":[2,5,8], "C":[3,6,9]})
print(df) A B C
0 1 2 3
1 4 5 6
2 7 8 9# Using `iloc[]`
print(df.iloc[0][0])
# Using `loc[]`
print(df.loc[0]['A'])
# Using `at[]`
print(df.at[0,'A'])
# Using `iat[]`
print(df.iat[0,0])1
1
1
1Los más importantes que hay que recordar son, sin duda, .loc[] y .iloc[]. Las sutiles diferencias entre ambos se tratarán en los siguientes apartados.
Basta por ahora de seleccionar valores de tu DataFrame. ¿Qué pasa con la selección de filas y columnas? En ese caso, utilizarías:
# Use `iloc[]` to select row `0`
print(df.iloc[0])
# Use `loc[]` to select column `'A'`
print(df.loc[:,'A'])A 1
B 2
C 3
Name: 0, dtype: int64
0 1
1 4
2 7
Name: A, dtype: int64Por ahora, basta con saber que puedes acceder a los valores llamándolos por su etiqueta o por su posición en el índice o columna. Si no lo ves, fíjate de nuevo en las ligeras diferencias entre los comandos: una vez, ves [0][0], y otra vez, ves [0,'A'] para recuperar tu valor 1.
Ahora que has aprendido a seleccionar un valor de un DataFrame, ¡es hora de ponerse manos a la obra y añadirle un índice, una fila o una columna!
Cuando creas un DataFrame, tienes la opción de añadir una entrada al argumento "index" para asegurarte de que tienes el índice que deseas. Si no lo especificas, tu DataFrame tendrá, por defecto, un índice de valor numérico que empieza por 0 y continúa hasta la última fila de tu DataFrame.
Sin embargo, aunque tu índice se especifique automáticamente, puedes reutilizar una de tus columnas y convertirla en tu índice. Puedes hacerlo fácilmente llamando a set_index() en tu DataFrame. ¡Pruébalo a continuación!
# Print out your DataFrame `df` to check it out
print(df)
# Set 'C' as the index of your DataFrame
df.set_index('C') A B C
0 1 2 3
1 4 5 6
2 7 8 9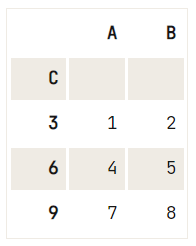
Antes de llegar a la solución, conviene que comprendas el concepto de loc y en qué se diferencia de otros atributos de indexación, como .iloc[] e .ix[]:
Todo esto puede parecer muy complicado. Vamos a ilustrar todo esto con un pequeño ejemplo:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), index= [2, 'A', 4], columns=[48, 49, 50])
# Pass `2` to `loc`
print(df.loc[2])
# Pass `2` to `iloc`
print(df.iloc[2])48 1
49 2
50 3
Name: 2, dtype: int64
48 7
49 8
50 9
Name: 4, dtype: int64Ten en cuenta que, en este caso, has utilizado un ejemplo de un DataFrame que no está basado únicamente en números enteros, para que te resulte más fácil comprender las diferencias. ¡Ves claramente que pasar 2 a .loc[] o .iloc[]/.ix[] no devuelve el mismo resultado!
48 1
49 2
50 3.iloc[] irá a ver las posiciones del índice. Cuando pases 2, volverás:48 7
49 8
50 9.ix[] tendrá el mismo comportamiento que iloc y mirará las posiciones del índice. Obtendrás el mismo resultado que en .iloc[].Ahora que la diferencia entre .iloc[], .loc[] y .ix[] está clara, ¡estás preparado para añadir filas a tu DataFrame!
Consejo: como consecuencia de lo que acabas de leer, ahora también entiendes que la recomendación general es que utilices .loc para insertar filas en tu DataFrame. Esto se debe a que si utilizaras df.ix[], podrías intentar hacer referencia a un índice de valor numérico con el valor del índice y sobrescribir accidentalmente una fila existente de tu DataFrame. ¡Deberías evitarlo!
Comprueba la diferencia una vez más en el DataFrame que aparece a continuación:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), index= [2.5, 12.6, 4.8], columns=[48, 49, 50])
# This will make an index labeled `2` and add the new values
df.loc[2] = [11, 12, 13]
print(df) 48 49 50
2.5 1 2 3
12.6 4 5 6
4.8 7 8 9
2.0 11 12 13Ya ves por qué todo esto puede resultar confuso, ¿verdad?
En algunos casos, querrás que el índice forme parte del DataFrame. Puedes hacerlo fácilmente tomando una columna del DataFrame o haciendo referencia a una columna que aún no hayas creado y asignándola a la propiedad .index, tal y como se indica a continuación:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Use `.index`
df['D'] = df.index
# Print `df`
print(df) A B C D
0 1 2 3 0
1 4 5 6 1
2 7 8 9 2En otras palabras, le dices al DataFrame que debe tomar la columna A como índice.
Sin embargo, si quieres añadir columnas al DataFrame, también puedes seguir el mismo método que cuando añades un índice a tu DataFrame: utilizas .loc[] o .iloc[]. En este caso, añades una Serie a un DataFrame existente con la ayuda de .loc[]:
# Study the DataFrame `df`
print(df)
# Append a column to `df`
df.loc[:, 4] = pd.Series(['5', '6', '7'], index=df.index)
# Print out `df` again to see the changes
print(df) A B C D
0 1 2 3 0
1 4 5 6 1
2 7 8 9 2
A B C D 4
0 1 2 3 0 5
1 4 5 6 1 6
2 7 8 9 2 7Recuerda que un objeto Serie es muy parecido a una columna de un DataFrame. Eso explica por qué puedes añadir fácilmente una Serie a un DataFrame existente. Ten en cuenta también que la observación que hicimos antes sobre .loc[] sigue siendo válida, ¡incluso cuando añades columnas al DataFrame!
Cuando el índice no tenga el aspecto que deseas, puedes optar por restablecerlo. Puedes hacerlo fácilmente con .reset_index(). Sin embargo, debes tener cuidado, ya que puedes pasar varios argumentos que pueden hacer o deshacer el éxito del reinicio:
# Check out the weird index of your dataframe
print(df)
# Use `reset_index()` to reset the values.
df_reset = df.reset_index(level=0, drop=True)
# Print `df_reset`
print(df_reset) A B C D 4
0 1 2 3 0 5
1 4 5 6 1 6
2 7 8 9 2 7
A B C D 4
0 1 2 3 0 5
1 4 5 6 1 6
2 7 8 9 2 7Puedes probar a sustituir el argumento drop por inplace en el ejemplo anterior ¡y ver qué pasa!
Observa cómo utilizas el argumento drop para indicar que quieres deshacerte del índice que había. Si hubieras utilizado inplace, el índice original con flotantes se añade como una columna más al DataFrame.
Ahora que has visto cómo seleccionar y añadir índices, filas y columnas al DataFrame, es hora de considerar otro caso de uso: eliminar estos tres de la estructura de datos.
Si quieres eliminar el índice del DataFrame, deberías reconsiderarlo, porque los Marcos de datos y las Series siempre tienen un índice.
Sin embargo, lo que *puedes* hacer es, por ejemplo:
del df.index.name,df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [40, 50, 60], [23, 35, 37]]),
index= [2.5, 12.6, 4.8, 4.8, 2.5],
columns=[48, 49, 50])
df.reset_index().drop_duplicates(subset='index', keep='last').set_index('index')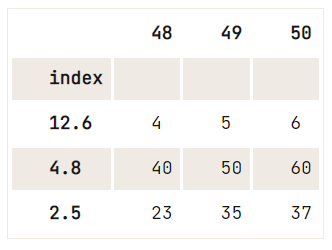
Ahora que ya sabes cómo eliminar un índice del DataFrame, ¡puedes pasar a eliminar columnas y filas!
Para deshacerte de (una selección de) columnas del DataFrame, puedes utilizar el método drop():
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Check out the DataFrame `df`
print(df)
# Drop the column with label 'A'
df.drop('A', axis=1, inplace=True)
# Drop the column at position 1
df.drop(df.columns[[1]], axis=1) A B C
0 1 2 3
1 4 5 6
2 7 8 9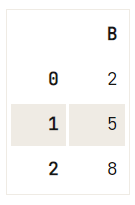
Puede que ahora pienses: bueno, esto no es tan sencillo; ¡hay algunos argumentos extra que se pasan al método drop()!
axis es 0 cuando indica filas y 1 cuando se utiliza para soltar columnas.inplace en True para eliminar la columna sin tener que reasignar el DataFrame.Puedes eliminar las filas duplicadas del DataFrame ejecutando df.drop_duplicates(). También puedes eliminar filas del DataFrame, teniendo en cuenta sólo los valores duplicados que existan en una columna.
Mira este ejemplo:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [40, 50, 60], [23, 35, 37]]),
index= [2.5, 12.6, 4.8, 4.8, 2.5],
columns=[48, 49, 50])
# Check out your DataFrame `df`
print(df)
# Drop the duplicates in `df`
df.drop_duplicates([48], keep='last') 48 49 50
2.5 1 2 3
12.6 4 5 6
4.8 7 8 9
4.8 40 50 60
2.5 23 35 37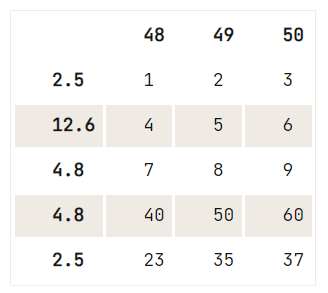
Si no existe un criterio de unicidad para el borrado que quieres realizar, puedes utilizar el método drop(), en el que utilizas la propiedad index para especificar el índice de las filas que quieres eliminar del DataFrame:
# Check out the DataFrame `df`
print(df)
# Drop the index at position 1
df.drop(df.index[1]) 48 49 50
2.5 1 2 3
12.6 4 5 6
4.8 7 8 9
4.8 40 50 60
2.5 23 35 37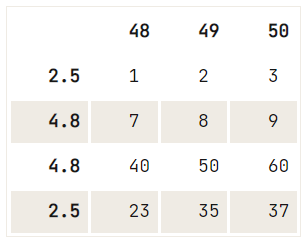
Después de este comando, puede que quieras restablecer el índice de nuevo.
Consejo: ¡prueba tú mismo a restablecer el índice del DataFrame resultante! No olvides utilizar el argumento drop si lo consideras necesario.
Para dar a las columnas o a los valores índice del DataFrame un valor diferente, lo mejor es utilizar el método .rename().
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Check out your DataFrame `df`
print(df)
# Define the new names of your columns
newcols = {
'A': 'new_column_1',
'B': 'new_column_2',
'C': 'new_column_3'
}
# Use `rename()` to rename your columns
df.rename(columns=newcols, inplace=True)
# Rename your index
df.rename(index={1: 'a'}) A B C
0 1 2 3
1 4 5 6
2 7 8 9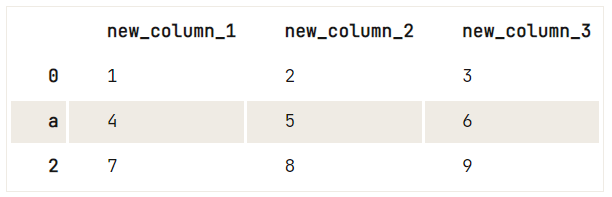
Consejo: prueba a cambiar el argumento inplace de la primera tarea (cambiar el nombre de tus columnas) por False y observa qué muestra ahora el script como resultado. Verás que ahora el DataFrame no se ha reasignado al renombrar las columnas. Como resultado, la segunda tarea toma como entrada el DataFrame original y no el que acabas de recuperar de la primera operación rename().
Ahora que has pasado por un primer conjunto de preguntas sobre los DataFrames de Pandas, es hora de ir más allá de lo básico y ensuciarte las manos de verdad, porque hay mucho más en los DataFrames que lo que has visto en la primera sección.
La mayoría de las veces, también querrás poder realizar algunas operaciones sobre los valores reales que contiene el DataFrame. En las siguientes secciones, verás varias formas de dar formato a los valores del DataFrame de pandas
Para sustituir determinadas cadenas en el DataFrame, puedes utilizar fácilmente replace(): pasa los valores que quieres cambiar, seguidos de los valores por los que quieres sustituirlos.
Así:
df = pd.DataFrame({"Student1":['OK','Awful','Acceptable'],
"Student2":['Perfect','Awful','OK'],
"Student3":['Acceptable','Perfect','Poor']})
# Study the DataFrame `df` first
print(df)
# Replace the strings by numerical values (0-4)
df.replace(['Awful', 'Poor', 'OK', 'Acceptable', 'Perfect'], [0, 1, 2, 3, 4]) Student1 Student2 Student3
0 OK Perfect Acceptable
1 Awful Awful Perfect
2 Acceptable OK Poor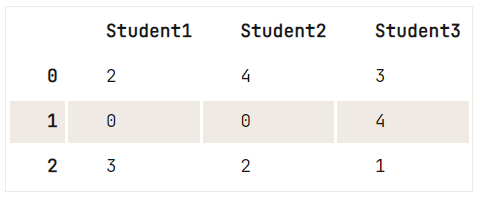
Ten en cuenta que también existe un argumento regex que puede ayudarte enormemente cuando te enfrentes a combinaciones de cadenas extrañas:
df = pd.DataFrame([["1\n", 2, "3\n"], [4, 5, "6\n"] ,[7, "8\n", 9]])
# Check out your DataFrame `df`
print(df)
# Replace strings by others with `regex`
df.replace({'\n': ''}, regex=True) 0 1 2
0 1\n 2 3\n
1 4 5 6\n
2 7 8\n 9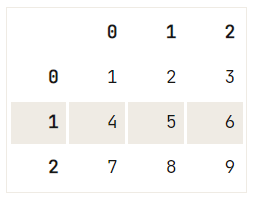
¡En resumen, replace() es sobre todo con lo que tienes que tratar cuando quieras sustituir valores o cadenas del DataFrame por otros!
Eliminar las partes no deseadas de las cadenas es un trabajo engorroso. Por suerte, ¡este problema tiene fácil solución!
df = pd.DataFrame([["+-1aAbBcC", "2", "+-3aAbBcC"], ["4", "5", "+-6aAbBcC"] ,["7", "+-8aAbBcC", "9"]])
# Check out your DataFrame
print(df)
# Delete unwanted parts from the strings in the first column
df[0] = df[0].map(lambda x: x.lstrip('+-').rstrip('aAbBcC'))
# Check out the result again
df 0 1 2
0 +-1aAbBcC 2 +-3aAbBcC
1 4 5 +-6aAbBcC
2 7 +-8aAbBcC 9
Utiliza map() en la columna result para aplicar la función lambda sobre cada elemento o elemento de la columna. La función en sí toma el valor de la cadena y le quita el + o - que se encuentra a la izquierda, y también le quita cualquiera de los seis aAbBcC de la derecha.
Esta es una tarea de formato algo más difícil. Sin embargo, el siguiente fragmento de código te guiará por los pasos:
df = pd.DataFrame({"Age": [34, 22, 19],
"PlusOne":[0,0,1],
"Ticket":["23:44:55", "66:77:88", "43:68:05 56:34:12"]})
# Inspect your DataFrame `df`
print(df)
# Split out the two values in the third row
# Make it a Series
# Stack the values
ticket_series = df['Ticket'].str.split(' ').apply(pd.Series, 1).stack()
# Get rid of the stack:
# Drop the level to line up with the DataFrame
ticket_series.index = ticket_series.index.droplevel(-1)
print(ticket_series) Age PlusOne Ticket
0 34 0 23:44:55
1 22 0 66:77:88
2 19 1 43:68:05 56:34:12
0 23:44:55
1 66:77:88
2 43:68:05
2 56:34:12
dtype: object
0
0 23:44:55
1 66:77:88
2 43:68:05
2 56:34:12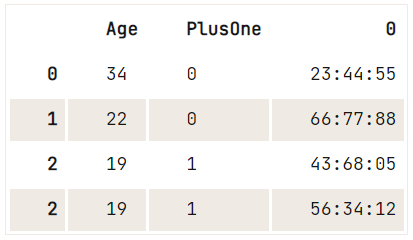
En resumen, lo que haces es:
Ticket del DataFrame df y la encadenas en un espacio. Así te asegurarás de que al final los dos billetes acaben en dos filas separadas. A continuación, coge estos cuatro valores (los cuatro números del ticket) y ponlos en un objeto Serie: 0 1
0 23:44:55 NaN
1 66:77:88 NaN
2 43:68:05 56:34:12NaN! Tienes que apilar las Series para asegurarte de que no tienes ningún valor NaN en la Serie resultante.0 0 23:44:55
1 0 66:77:88
2 0 43:68:05
1 56:34:120 23:44:55
1 66:77:88
2 43:68:05
2 56:34:12
dtype: objectTicket.Puede que quieras ajustar los datos del DataFrame aplicándoles una función. Empecemos a responder a esta pregunta creando tu propia función lambda:
doubler = lambda x: x*2Consejo: si quieres saber más sobre las funciones en Python, considera seguir este tutorial sobre funciones en Python.
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Study the `df` DataFrame
print(df)
# Apply the `doubler` function to the `A` DataFrame column
df['A'].apply(doubler)
A B C
0 1 2 3
1 4 5 6
2 7 8 9
0 2
1 8
2 14
Name: A, dtype: int64Ten en cuenta que también puedes seleccionar la fila del DataFrame y aplicarle la función lambda doubler. Recuerda que puedes seleccionar fácilmente una fila del DataFrame utilizando .loc[] o .iloc[].
Entonces, ejecutarías algo así, dependiendo de si quieres seleccionar el índice en función de su posición o en función de su etiqueta:
df.loc[0].apply(doubler)Ten en cuenta que la función apply() sólo aplica la función doubler a lo largo del eje del DataFrame. Eso significa que te diriges al índice o a las columnas. O, en otras palabras, una fila o una columna.
Sin embargo, si quieres aplicarlo a cada elemento o elemento por elemento, puedes utilizar la función map(). Puedes sustituir la función apply() del fragmento de código anterior por map(). No olvides pasarle aún la función doubler para asegurarte de que multiplicas los valores por 2.
Supongamos que quieres aplicar esta función de duplicación no sólo a la columna A del DataFrame, sino a toda ella. En este caso, puedes utilizar applymap() para aplicar la función doubler a cada uno de los elementos de todo el DataFrame:
doubled_df = df.applymap(doubler)
print(doubled_df) A B C
0 2 4 6
1 8 10 12
2 14 16 18Ten en cuenta que, en estos casos, hemos estado trabajando con funciones lambda o funciones anónimas que se crean en tiempo de ejecución. Sin embargo, también puedes escribir tu propia función. Por ejemplo:
def doubler(x):
if x % 2 == 0:
return x
else:
return x * 2
# Use `applymap()` to apply `doubler()` to your DataFrame
doubled_df = df.applymap(doubler)
# Check the DataFrame
print(doubled_df) A B C
0 2 2 6
1 4 10 6
2 14 8 18Si quieres más información sobre el flujo de control en Pythonsiempre puedes consultar nuestros otros recursos.
La función que utilizarás es la función Pandas Dataframe(): requiere que le pases los datos que quieres introducir, los índices y las columnas.
Recuerda que los datos contenidos en el marco de datos no tienen por qué ser homogéneos. ¡Puede ser de diferentes tipos de datos!
Puedes utilizar esta función de varias formas para crear un DataFrame vacío. En primer lugar, puedes utilizar numpy.nan para inicializar el DataFrame con NaNs. Observa que numpy.nan tiene el tipo float.
df = pd.DataFrame(np.nan, index=[0,1,2,3], columns=['A'])
print(df) A
0 NaN
1 NaN
2 NaN
3 NaNAhora mismo, el tipo de datos del marco de datos se infiere por defecto: como numpy.nan tiene tipo float, el marco de datos también contendrá valores de tipo float. Sin embargo, también puedes forzar que el DataFrame sea de un tipo determinado añadiendo el atributo dtype y rellenando el tipo deseado. Como en este ejemplo:
df = pd.DataFrame(index=range(0,4),columns=['A'], dtype='float')
print(df)
A
0 NaN
1 NaN
2 NaN
3 NaNTen en cuenta que si no especificas las etiquetas o el índice de los ejes, se construirán a partir de los datos de entrada basándose en reglas de sentido común.
Pandas puede reconocerlo, pero tienes que ayudarle un poquito: añade el argumento parse_dates cuandoleas datos de, digamos, un archivo de valores separados por comas (CSV):
import pandas as pd
pd.read_csv('yourFile', parse_dates=True)
# or this option:
pd.read_csv('yourFile', parse_dates=['columnName'])Sin embargo, siempre hay formatos de fecha-hora raros.
No te preocupes. En estos casos, puedes construir tu propio analizador sintáctico para solucionarlo. Podrías, por ejemplo, hacer una función lambda que tomara tu DateTime y la controlara con una cadena de formato.
import pandas as pd
dateparser = lambda x: pd.datetime.strptime(x, '%Y-%m-%d %H:%M:%S')
# Which makes your read command:
pd.read_csv(infile, parse_dates=['columnName'], date_parser=dateparse)
# Or combine two columns into a single DateTime column
pd.read_csv(infile, parse_dates={'datetime': ['date', 'time']}, date_parser=dateparse)Remodelar el DataFrame es transformarlo de modo que la estructura resultante lo haga más adecuado para tu análisis de datos. En otras palabras, la remodelación no se ocupa tanto de dar formato a los valores que contiene el DataFrame, sino más bien de transformar su forma.
Esto responde al cuándo y al por qué. Pero, ¿cómo remodelarías el DataFrame?
Hay tres formas de remodelar que suelen plantear dudas a los usuarios: dinamizar, apilar y desapilar y fundir.
Puedes utilizar la función pivot() para crear una nueva tabla derivada a partir de la original. Cuando utilices la función, puedes pasar tres argumentos:
values: este argumento te permite especificar qué valores de tu DataFrame original quieres ver en tu tabla dinámica.columns: lo que pases a este argumento se convertirá en una columna de la tabla resultante.index: lo que pases a este argumento se convertirá en un índice en la tabla resultante.# Import pandas
import pandas as pd
# Create your DataFrame
products = pd.DataFrame({'category': ['Cleaning', 'Cleaning', 'Entertainment', 'Entertainment', 'Tech', 'Tech'],
'store': ['Walmart', 'Dia', 'Walmart', 'Fnac', 'Dia','Walmart'],
'price':[11.42, 23.50, 19.99, 15.95, 55.75, 111.55],
'testscore': [4, 3, 5, 7, 5, 8]})
# Use `pivot()` to pivot the DataFrame
pivot_products = products.pivot(index='category', columns='store', values='price')
# Check out the result
print(pivot_products)store Dia Fnac Walmart
category
Cleaning 23.50 NaN 11.42
Entertainment NaN 15.95 19.99
Tech 55.75 NaN 111.55Cuando no rellenas específicamente qué valores esperas que estén presentes en tu tabla resultante, dinamizarás por varias columnas:
# Import the Pandas library
import pandas as pd
# Construct the DataFrame
products = pd.DataFrame({'category': ['Cleaning', 'Cleaning', 'Entertainment', 'Entertainment', 'Tech', 'Tech'],
'store': ['Walmart', 'Dia', 'Walmart', 'Fnac', 'Dia','Walmart'],
'price':[11.42, 23.50, 19.99, 15.95, 55.75, 111.55],
'testscore': [4, 3, 5, 7, 5, 8]})
# Use `pivot()` to pivot your DataFrame
pivot_products = products.pivot(index='category', columns='store')
# Check out the results
print(pivot_products)
price testscore
store Dia Fnac Walmart Dia Fnac Walmart
category
Cleaning 23.50 NaN 11.42 3.0 NaN 4.0
Entertainment NaN 15.95 19.99 NaN 7.0 5.0
Tech 55.75 NaN 111.55 5.0 NaN 8.0Ten en cuenta que tus datos no pueden tener filas con valores duplicados para las columnas que especifiques. Si no es así, aparecerá un mensaje de error. Si no puedes garantizar la unicidad de tus datos, te conviene utilizar en su lugar el método pivot_table:
# Import the Pandas library
import pandas as pd
# Your DataFrame
products = pd.DataFrame({'category': ['Cleaning', 'Cleaning', 'Entertainment', 'Entertainment', 'Tech', 'Tech'],
'store': ['Walmart', 'Dia', 'Walmart', 'Fnac', 'Dia','Walmart'],
'price':[11.42, 23.50, 19.99, 15.95, 19.99, 111.55],
'testscore': [4, 3, 5, 7, 5, 8]})
# Pivot your `products` DataFrame with `pivot_table()`
pivot_products = products.pivot_table(index='category', columns='store', values='price', aggfunc='mean')
# Check out the results
print(pivot_products)store Dia Fnac Walmart
category
Cleaning 23.50 NaN 11.42
Entertainment NaN 15.95 19.99
Tech 19.99 NaN 111.55Observa el argumento adicional aggfunc que se pasa al método pivot_table. Este argumento indica que utilizas una función de agregación que sirve para combinar varios valores. En este ejemplo, puedes ver claramente que se utiliza la función mean.
stack() y unstack() para remodelar el DataFrame PandasYa has visto un ejemplo de apilamiento en el apartado 5. En esencia, puede que aún recuerdes que cuando apilas un DataFrame, lo haces más alto. Mueves el índice de la columna más interior para que sea el índice de la fila más interior. Devuelve un DataFrame con un índice con un nuevo nivel más interno de etiquetas de fila.
Vuelve al recorrido completo de la sección 5 si no estás seguro del funcionamiento destack().
La inversa del apilamiento se llama desapilamiento. De forma parecida a stack(), utilizas unstack() para desplazar el índice de la fila más interna y convertirlo en el índice de la columna más interna.
Para una explicación de la dinamización, el apilamiento y en desapilamiento en pandas, consulta nuestro curso Dar forma a los datos con pandas.
melt()La fusión se considera útil en los casos en que tienes datos que tienen una o más columnas que son variables identificadoras, mientras que todas las demás columnas se consideran variables medidas.
Estas variables medidas están todas "unpivoted" del eje de filas. Es decir, mientras que las variables medidas que estaban repartidas por la anchura del DataFrame, el fundido se encargará de colocarlas en la altura del mismo. O, dicho de otro modo, el DataFrame ahora será más largo en lugar de más ancho.
Como resultado, tienes dos columnas no identificadoras, a saber, ‘variable’ y ‘value’.
Vamos a ilustrarlo con un ejemplo:
# The `people` DataFrame
people = pd.DataFrame({'FirstName' : ['John', 'Jane'],
'LastName' : ['Doe', 'Austen'],
'BloodType' : ['A-', 'B+'],
'Weight' : [90, 64]})
# Use `melt()` on the `people` DataFrame
print(pd.melt(people, id_vars=['FirstName', 'LastName'], var_name='measurements')) FirstName LastName measurements value
0 John Doe BloodType A-
1 Jane Austen BloodType B+
2 John Doe Weight 90
3 Jane Austen Weight 64Si buscas más formas de remodelar tus datos, consulta la documentación.
Puedes iterar sobre las filas del DataFrame con la ayuda de un bucle for en combinación con una llamada a iterrows() en el DataFrame:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
for index, row in df.iterrows() :
print(row['A'], row['B'])1 2
4 5
7 8iterrows() te permite recorrer eficazmente las filas del DataFrame como pares (índice, Serie). En otras palabras, te da como resultado tuplas (índice, fila).
Cuando hayas terminado de manipular los datos con Pandas, puede que quieras exportar el DataFrame a otro formato. En esta sección se describen dos formas de enviar el DataFrame de pandas a un archivo CSV o Excel.
Para escribir un DataFrame como un archivo CSV, puedes utilizar to_csv():
import pandas as pd
df.to_csv('myDataFrame.csv')Ese fragmento de código parece bastante sencillo, pero aquí es donde empiezan las dificultades para la mayoría de la gente, porque tendrás requisitos específicos para la salida de tus datos. Quizá no quieras una coma como delimitador, o quieras especificar una codificación concreta.
No te preocupes. Puedes pasar algunos argumentos adicionales a to_csv() para asegurarte de que tus datos salen como tú quieres.
sep:import pandas as pd
df.to_csv('myDataFrame.csv', sep='\t')encoding:import pandas as pd
df.to_csv('myDataFrame.csv', sep='\t', encoding='utf-8')NaN o los valores que faltan, si quieres que salga o no la cabecera, si quieres escribir o no los nombres de las filas, si quieres compresión, puedes leer las opciones.De forma similar a lo que hiciste para pasar el DataFrame a CSV, puedes utilizar to_excel() para escribir la tabla en Excel. Sin embargo, es un poco más complicado:
import pandas as pd
writer = pd.ExcelWriter('myDataFrame.xlsx')
df.to_excel(writer, 'DataFrame')
writer.save()Sin embargo, ten en cuenta que, al igual que con to_csv(), tienes un montón de argumentos extra como startcol, startrow, etc., para asegurarte de que das salida a tus datos correctamente. Puedes obtener más información sobre cómo importar datos desde y exportar datos a archivos CSV utilizando pandas en nuestro tutorial.
Sin embargo, si quieres más información sobre las herramientas IO en Pandas, consulta la documentación de Pandas de DataFrames a Excel.
Eso es. ¡Has completado con éxito el tutorial DataFrame de Pandas!
Las respuestas a las 11 preguntas frecuentes sobre Pandas representan funciones esenciales que necesitarás para importar, limpiar y manipular tus datos para tu trabajo de ciencia de datos. ¿No estás seguro de haber profundizado lo suficiente en este asunto? ¡Nuestro curso Importar datos en Python te ayudará! Si te has enterado de esto, quizá quieras ver a los pandas trabajando en un proyecto de la vida real. La serie de tutoriales Importancia del preprocesamiento en la ciencia de datos y la canalización en machine learning son de lectura obligada, y el curso abierto Introducción a Python y al machine learning es imprescindible.
Más información sobre Python y pandas
Curso
Curso
Curso
Tutorial
DataCamp Team
Tutorial
DataCamp Team
Tutorial
Vidhi Chugh
Tutorial
Kurtis Pykes
Tutorial
Abid Ali Awan
Tutorial
Aditya Sharma