In this article, I'll use the example of scaling numerical data (numerical data: data consisting of numbers, as opposed to categories/strings; scaling: using basic arithmetic to change the range of the data; more details to follow) to demonstrate the importance of considering preprocessing as part of a greater structure, the machine learning (ML) pipeline. To this end, we'll see a real-world example in which scaling can improve model performance.
I'll first introduce classification problems in ML and k-Nearest Neighbors, one of the simplest algorithms used in such settings. To appreciate the importance of scaling numerical data in such a setting, I'll need to introduce measures of model performance and the concepts of training and test sets. You'll see all these concepts and practices at play with a dataset in which I attempt to classify the quality of red wine. I'll also make sure that I put preprocessing in its most useful place, near the beginning of an iterative data science pipeline. All examples herein will be in Python. If you're not familiar with Python, you can check out our DataCamp courses here. I will make use of the libraries pandas for our dataframe needs and scikit-learn for our machine learning needs.
This is part one of a three part tutorial:
Part 2: Centering, Scaling and Logistic Regression
Part 3: Scaling Synthesized Data
A Brief Introduction to Classification Problems in Machine Learning
Classifying and labelling things in the phenomenal world is an ancient art. In the 4th century BC, Aristotle constructed a classification system of living things that was used for 2,000 years. In the modern world, classification is commonly framed as a machine learning task, in particular, a supervised learning task. The basic principle of supervised learning is straightforward: we have a bunch of data consisting of predictor variables and a target variable. The aim of supervised learning is to build a model that is 'good at' predicting the target variable, given the predictor variables. If the target variable consists of categories (e.g. 'click' or 'not', 'malignant' or 'benign' tumor), we call the learning task classification. Alternatively, if the target is a continuously varying variable (e.g. price of a house), it is a regression task.
An illustrative example will go a long way here: consider the heart disease dataset, in which there are 75 predictor variables, such as 'age', 'sex' and 'smoker or not' and the target variable refers to the presence of heart disease and ranges from 0 (no heart disease) to 4. Much work on this dataset has concentrated on attempts to distinguish the presence of heart disease from its absence. This is a classification task. If you were to attempt to predict the actual value (0 to 4) of the target variable, this would be a regression problem (because the target variable is ordered). I'll discuss regression in the next post. Here I'll look at one of the simplest algorithms for classification tasks, the k-Nearest Neighbors algorithm.
k-Nearest Neighbors for classification in machine learning
Let's say that we have some labeled data, for example, data that consists of characteristics of red wine (e.g. alcohol content, density, amount of citric acid, pH, etc...; these are the predictor variables) with target variable 'Quality' and labels 'good' & 'bad'. Then, given the characteristics of a new, unlabeled wine, the classification task is to predict its 'Quality'. When all the predictor variables are numerical (there are also ways to deal with the categorical case), we can consider each row/wine as a point in n-dimensional space and, in this case, k-Nearest Neighbors (k-NN) is a conceptually & computationally simple classification method: for each new, unlabeled wine, we calculate, for some integer k, its k nearest neighbors in the n-dimensional predictor variable space. Then we look at the labels of these k neighbors (i.e. 'good' or 'bad') & assign the label with the most hits to the new wine (e.g. if k = 5, 3 neighbors vote 'good' and 2 vote 'bad', then our model labels the new wine 'good'). Note that, here, training the model consists entirely in storing the data points: there are no parameters to fit!
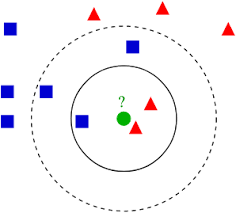
A visual description of k-Nearest Neighbors
In the image below, there's an example of k-NN in 2D: how do you classsify the data point in the middle? Well, if k=3, you would clasify it as red and, if k=5, as green.
k-NN implementation in Python (scikit-learn)
import pandas as pd%matplotlib inlineimport matplotlib.pyplot as pltplt.style.use('ggplot')df = pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv ' , sep = ';')X = df.drop('quality' , 1).values # drop target variabley1 = df['quality'].valuespd.DataFrame.hist(df, figsize = [15,15]);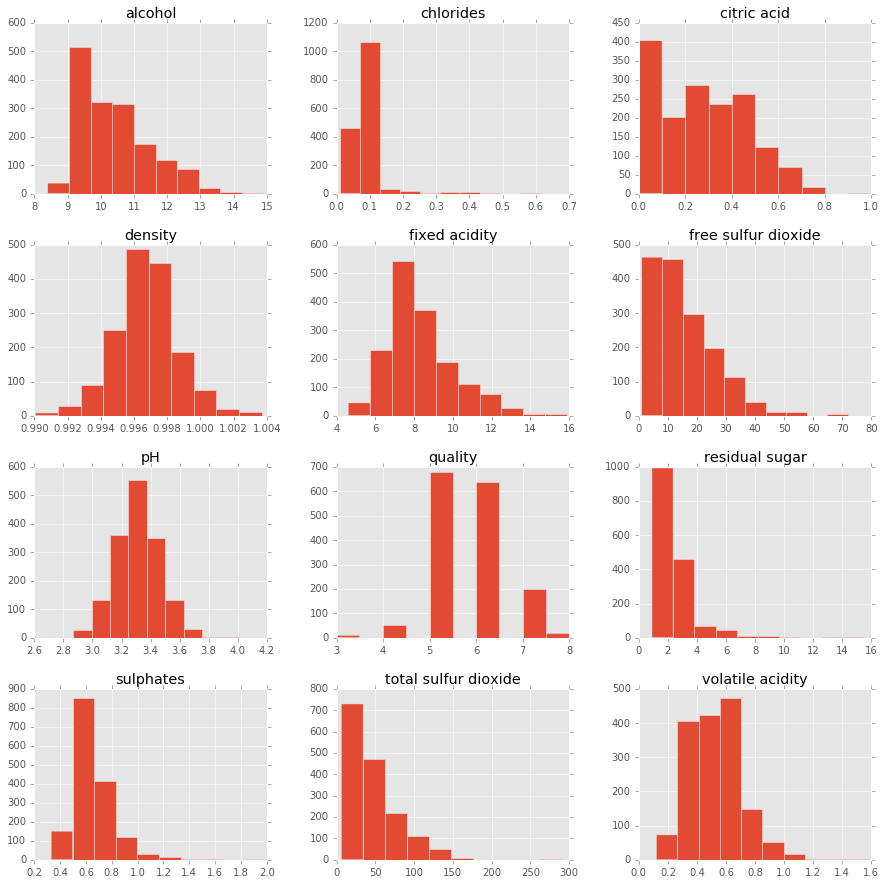
First notice the range of the predictor variables: 'free sulfur dioxide' ranges from 0 to ~70 and 'volatile acidity' from ~0 to ~1.2. More specifically, the former has a range 2 orders of magnitude larger than that of the latter. Any algorithm, such as k-NN, which cares about the distance between data points, may thus focus squarely and unfairly on variables with a larger range, such as 'free sulfur dioxide', a variable that may contain only noise, for all we know. This motivates scaling our data, which we'll get to soon enough.
Now the target variable is a 'Quality' rating of wine and ranges from 3 to 8. For the purpose of expositional ease, let's turn it into a two-category variable consisting of 'good' (rating > 5) & 'bad' (rating <= 5). We'll also plot histograms of both formulations of the target variable to get a sense of what's going on.
y = y1 <= 5 # is the rating <= 5?# plot histograms of original target variable# and aggregated target variableplt.figure(figsize=(20,5));plt.subplot(1, 2, 1 );plt.hist(y1);plt.xlabel('original target value')plt.ylabel('count')plt.subplot(1, 2, 2);plt.hist(y)plt.xlabel('aggregated target value')plt.show()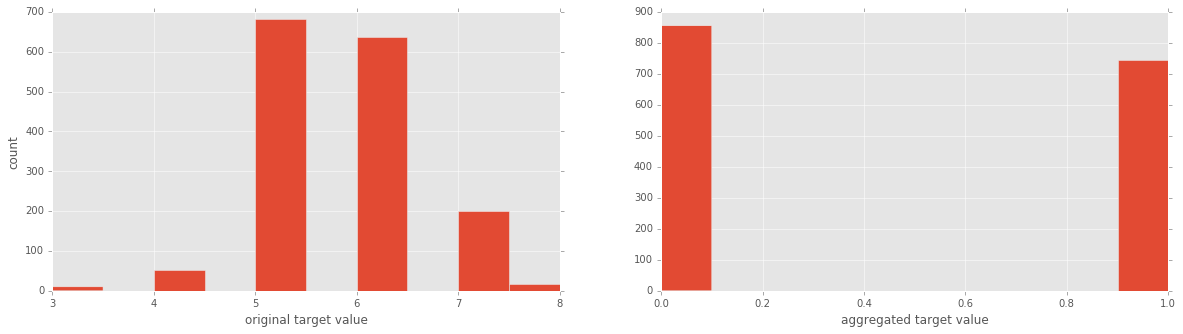
k-Nearest Neighbors: how well does it perform?
Note: accuracy can also be defined in terms of a confusion matrix and is commonly defined for binary classification problems in terms of true positives & false negatives; other common measures of model performance derivable from the confusion matrix are precision, the number of true positives divided by the number of true & false positives, and recall, the number of true positives divided by the number of true positives plus the number of false negatives; yet another measure, the F1-score is the harmonic mean of the precision and the recall. See machine learning mastery for a nice exposition of these measures; also check out the Wikipedia entries on the confusion matrix and the F1 score.
k-Nearest Neighbors: performance in practice and the train test split
from sklearn.cross_validation import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)We now build the k-NN model, make predictions on the test set and compare these predictions to the ground truth in order to get a measure of model performance:from sklearn import neighbors, linear_modelknn = neighbors.KNeighborsClassifier(n_neighbors = 5)knn_model_1 = knn.fit(X_train, y_train)print('k-NN accuracy for test set: %f' % knn_model_1.score(X_test, y_test))k-NN accuracy for test set: 0.612500
It is worth reiterating that the default scoring method for k-NN in scikit-learn is accuracy. An accuracy of 61% is not great but for an out of the box model without any preprocessing it's not horrible either. To check out a variety of other metrics, we can use scikit-learn's classification report also:
from sklearn.metrics import classification_reporty_true, y_pred = y_test, knn_model_1.predict(X_test)print(classification_report(y_true, y_pred))Now we're going to introduce scaling and centering, the most basic methods of preprocessing numerical data, and see if and how they effect our model performance.
The Mechanics of Preprocessing: Scaling and Centering
Before running a model, such as regression (predicting a continuous variable) or classification (predicting a discrete variable), on data, you almost always want to do some preprocessing. For numerical variables, it is common to either normalize or standardize your data. What do these terms mean?
All normalization means is scaling a dataset so that its minimum is 0 and its maximum 1. To achieve this we transform each data point $x$ to
$$x_{normalized} = \frac{x-x_{min}}{x_{max}-x_{min}}.$$Stardardization is slightly different; it's job is to center the data around 0 and to scale with respect to the standard deviation:
$$x_{standardized} = \frac{x-\mu}{\sigma},$$where $\mu$ and $\sigma$ are the mean and standard deviation of the dataset, respectively. First note that these transformations merely change the range of the data and not the distribution. You may later wish to use any other number of transforms, such as a log transform or a Box-Cox transform, to make your data look more Gaussian (like a bell-curve). But before we go further, it is important to ask the following questions: why do we scale our data? Are there times that it is more appropriate than others? For example, is it more important in classification problems than in regression?
Let's first delve into classification challenges and see how scaling affects the performance of k-Nearest Neighbors:
Preprocessing: scaling in practice
Here below I (i) scale the data, (ii) use k-Nearest Neighbors and (iii) check the model performance. I'll use scikit-learn's scale function, which standardizes all features (columns) in the array passed to it.
from sklearn.preprocessing import scaleXs = scale(X)from sklearn.cross_validation import train_test_splitXs_train, Xs_test, y_train, y_test = train_test_split(Xs, y, test_size=0.2, random_state=42)knn_model_2 = knn.fit(Xs_train, y_train)print('k-NN score for test set: %f' % knn_model_2.score(Xs_test, y_test))print('k-NN score for training set: %f' % knn_model_2.score(Xs_train, y_train))y_true, y_pred = y_test, knn_model_2.predict(Xs_test)print(classification_report(y_true, y_pred)) k-NN score for test set: 0.712500k-NN score for training set: 0.814699 precision recall f1-score support False 0.72 0.79 0.75 179 True 0.70 0.62 0.65 141avg / total 0.71 0.71 0.71 320All these measures improved by 0.1, which is a 16% improvement and significant! As hinted at above, before scaling there were a number of predictor variables with ranges of different order of magnitudes, meaning that one or two of them could dominate in the context of an algorithm such as k-NN. The two main reasons for scaling your data are
- Your predictor variables may have significantly different ranges and, in certain situations, such as when implementing k-NN, this needs to be mitigated so that certain features do not dominate the algorithm;
- You want your features to be unit-independent, that is, not reliant on the scale of the measurement involved: for example, you could have a measured feature expressed in meters and I could have the same feature expressed in centimeters. If we both scale our respective data, this feature will be the same for each of us.
We have seen the essential place occupied in the data scientific pipeline by preprocessing, in its scaling and centering form, and we have done so to promote a holistic approach to the challenges of machine learning. In future articles, I hope to extend this discussion to other types of preprocessing, such as transformations of numerical data and preprocessing of categorical data, both essential aspects of any data scientists's toolkit. Before moving onto this, in the next article I will explore the role of scaling in regression approaches to classification. In particular, I'll look at logistic regression and you'll see that the result is very different to the one you just saw in the context of k-Nearest Neighbors.
In the interactive window below, you can play with the data yourself. Start off by changing the variable n_neig, which is the number of neighbors to use in the k-NN algorithm. You can also scale the data by setting sc = True, if you desire. Then run the entire script to report the accuracy of the model, along with a classification report.
import pandas as pdimport matplotlib.pyplot as pltfrom sklearn.cross_validation import train_test_splitfrom sklearn import neighborsfrom sklearn.preprocessing import scalefrom sklearn.metrics import classification_report # Set the the number of neighbors for k-NNn_neig = 5# Set sc = True if you want to scale your featuressc = False# Load datadf = pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv ' , sep = ';')X = df.drop('quality' , 1).values# drop target variable# Here we scale, if desiredif sc == True: X = scale(X)# Target valuey1 = df['quality'].values# original target variabley = y1 <= 5# new target variable: is the rating <= 5?# Split the data into a test set and a training setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Train k-NN model and print performance on the test setknn = neighbors.KNeighborsClassifier(n_neighbors = n_neig)knn_model = knn.fit(X_train, y_train)y_true, y_pred = y_test, knn_model.predict(X_test)print('k-NN accuracy for test set: %f' % knn_model.score(X_test, y_test))print(classification_report(y_true, y_pred))Dictionary
Supervised learning: The task of inferring a target variable from predictor variables. For example, inferring the target variable 'presence of heart disease' from predictor variables such as 'age', 'sex', and 'smoker status'.
Classification task: A supervised learning task is a classification task if the target variable consists of categories (e.g. 'click' or 'not', 'malignant' or 'benign' tumour).
Regression task: A supervised learning task is a regression task if the target variable is a continuously varying variable (e.g. price of a house) or an ordered categorical variable such as 'quality rating of wine'.
k-Nearest Neighbors: An algorithm for classification tasks, in which a data point is assigned the label decided by a majority vote of its k nearest neighbors.
Preprocessing: Any number of operations data scientists will use to get their data into a form more appropriate for what they want to do with it. For example, before performing sentiment analysis of twitter data, you may want to strip out any html tags, white spaces, expand abbreviations and split the tweets into lists of the words they contain.
Centering and Scaling: These are both forms of preprocessing numerical data, that is, data consisting of numbers, as opposed to categories or strings, for example; centering a variable is subtracting the mean of the variable from each data point so that the new variable's mean is 0; scaling a variable is multiplying each data point by a constant in order to alter the range of the data. See the body of the article for the importance of these, along with examples.
This article was generated from a Jupyter notebook. You can download the notebook here.

