
programa
Associate AI Engineer para desarrolladores
26 h
Mientras tu script de Python espera pacientemente a que finalicen las respuestas de la API, las consultas a la base de datos o las operaciones con archivos, ese tiempo suele quedar sin utilizar. Con la programación asíncrona de Python, tu código puede manejar varias tareas a la vez. Así, mientras una operación espera, otras avanzan, convirtiendo los momentos de inactividad en trabajo productivo y, a menudo, reduciendo los minutos de espera a solo unos segundos.
En esta guía, te enseñaré los fundamentos de la programación asíncrona en Python mediante la realización de miniproyectos. Verás cómo las corrutinas, los bucles de eventos y la E/S asíncrona pueden hacer que tu código sea mucho más receptivo.
Si quieres aprender a crear API web asíncronas, no te pierdas este curso sobre FastAPI.
En Python síncrono tradicional, el código se ejecuta línea por línea. Por ejemplo, cuando llamas a una API, tu programa se detiene y espera la respuesta. Si eso lleva dos segundos, todo el programa permanecerá inactivo durante dos segundos. La programación asíncrona permite que tu código inicie una llamada a la API y luego continúe con otras tareas.
Cuando llega la respuesta, tu código continúa donde lo había dejado. En lugar de esperar a que se complete cada operación, puedes ejecutar varias operaciones al mismo tiempo. Esto es especialmente importante cuando tu código pasa tiempo esperando la respuesta de sistemas externos, como bases de datos, API o sistemas de archivos.
Para que esto funcione, el sistema asíncrono de Python utiliza algunos conceptos básicos:
Corrutinas: Funciones definidas con async def en lugar de def. Pueden pausar y reanudar la ejecución, lo que los hace perfectos para operaciones que implican espera.
await: Esta palabra clave le indica a Python: «Pausa esta corrutina hasta que se complete esta operación, pero deja que el resto del código se ejecute mientras tanto».
Bucle de eventos: El motor que gestiona todas tus corrutinas, decidiendo cuál ejecutar y cuándo cambiar entre ellas.
Tareas: Corrutinas envueltas para ejecución concurrente. Los creas con asyncio.create_task() para ejecutar varias operaciones a la vez.
Para evitar confusiones sobre lo que la programación asíncrona puede (y no puede) hacer, ten en cuenta lo siguiente:
Async funciona mejor con tareas relacionadas con E/S, como solicitudes HTTP, consultas a bases de datos y operaciones con archivos, en las que el código espera a sistemas externos.
Async no ayuda con tareas que dependen de la CPU, como cálculos complejos o procesamiento de datos, en las que el código realiza cálculos de forma activa en lugar de esperar.
La mejor manera de interiorizar estos conceptos es escribir código asíncrono real. En la siguiente sección, crearás tu primera función asíncrona y verás exactamente cómo funcionan conjuntamente las corrutinas y el bucle de eventos.
Antes de escribir código asíncrono, veamos una función síncrona normal que espera antes de hacer algo:
import time
def greet_after_delay():
print("Starting...")
time.sleep(2) # Blocks for 2 seconds
print("Hello!")
greet_after_delay()Starting...
Hello!La función funciona, pero time.sleep(2) bloquea todo el programa. Nada más puede ejecutarse durante esos dos segundos.
Ahora, aquí está la versión asíncrona:
import asyncio
async def greet_after_delay():
print("Starting...")
await asyncio.sleep(2) # Pauses, but doesn't block
print("Hello!")
asyncio.run(greet_after_delay())Starting...
Hello!El resultado parece idéntico, pero hay algo diferente bajo el capó. Tres cambios hicieron que esto fuera asíncrono:
async def En lugar de « def », declara esto como una corrutina.
await asyncio.sleep(2) en lugar de time.sleep(2) hace una pausa sin bloquear.
asyncio.run() inicia el bucle de eventos y ejecuta la corrutina.
Ten en cuenta que « asyncio.sleep() » es en sí misma una función asíncrona, por lo que necesita « await ». Esta es una regla clave: todas las funciones asíncronas deben llamarse con await. Tanto si se trata de una función integrada, como asyncio.sleep(), como de una que escribas tú mismo, si olvidas await, no se ejecutará.
Por ahora, la versión asíncrona no parece más rápida. Eso es porque solo tenemos una tarea. La ventaja real se aprecia cuando ejecutas varias corrutinas a la vez, lo que veremos en la siguiente sección.
Otra cosa importante que debes saber: no puedes llamar a una función asíncrona directamente como si fuera una función normal. Probémoslo:
result = greet_after_delay()
print(result)
print(type(result))<coroutine object greet_after_delay at 0x...>
<class 'coroutine'>Al llamar a greet_after_delay(), se devuelve un objeto de corrutina, no el resultado. La función no se ejecuta realmente. Necesitas asyncio.run() o await para ejecutarlo dentro de otra función.
El bucle de eventos es el motor que impulsa la programación asíncrona. Gestiona tus corrutinas y decide qué se ejecuta y cuándo. Esto es lo que ocurre paso a paso cuando ejecutas la función asíncrona greet_after_delay():
asyncio.run() crea un bucle de eventos.
El bucle de eventos se inicia greet_after_delay().
«Iniciando...» se imprime.
Los éxitos esperan asyncio.sleep(2) → pausas de corrutinas.
Comprobaciones del bucle de eventos: ¿Hay alguna otra tarea que ejecutar? (ninguna por ahora).
Transcurren 2 segundos, se completa el modo de suspensión.
El bucle de eventos se reanuda greet_after_delay().
Imprime «¡Hola!».
La función finaliza → el bucle de eventos se cierra.
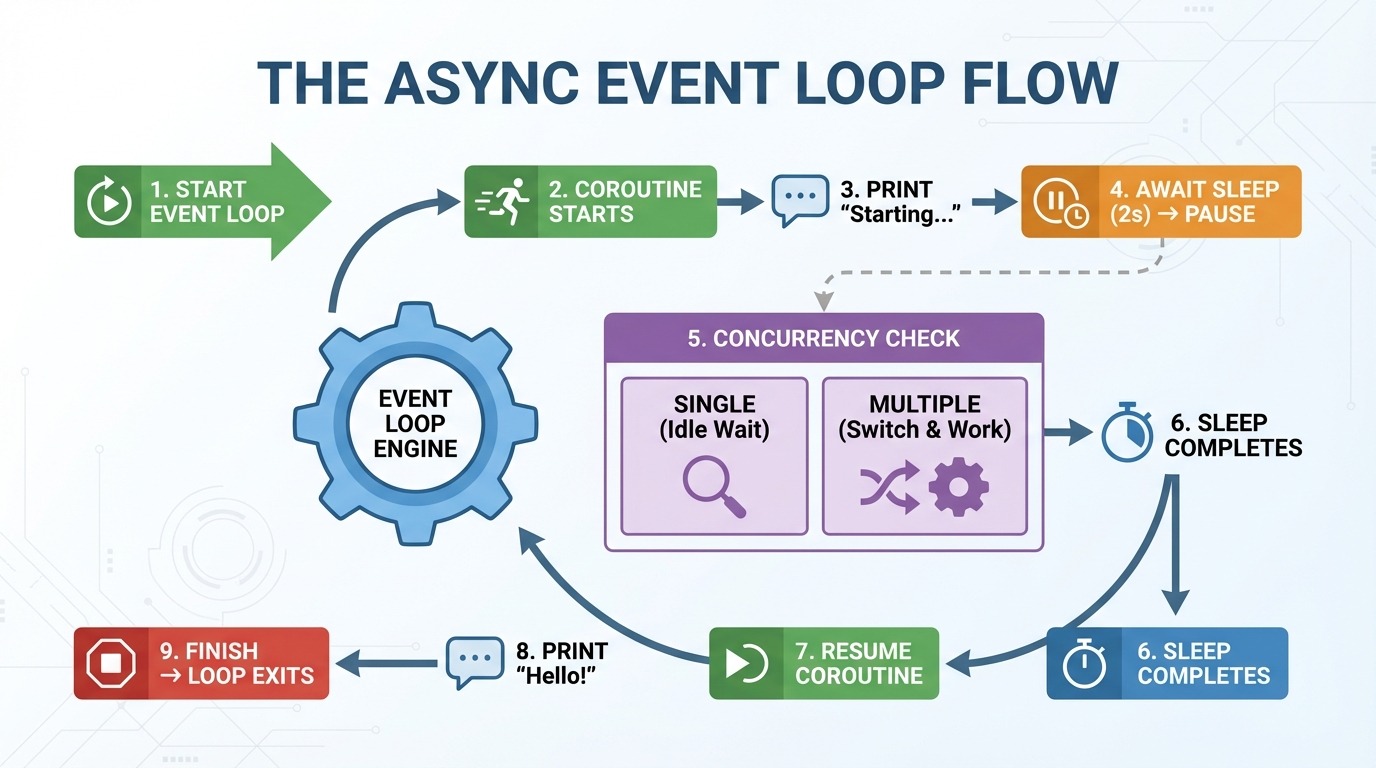
El paso 5 es donde async se vuelve interesante. Con una corrutina, no hay nada más que hacer. Pero cuando hay varias corrutinas, el bucle de eventos pasa a otra tarea mientras una espera. En lugar de permanecer inactivo durante un sueño de dos segundos, puede ejecutar otro código.
Piensa en el bucle de eventos como un controlador de tráfico. No hace que los coches individuales sean más rápidos. Mantiene el tráfico en movimiento al permitir que otros coches pasen mientras uno está parado.
Un error común entre los principiantes es olvidarse de await al llamar a una corrutina dentro de otra función asíncrona:
import asyncio
async def get_message():
await asyncio.sleep(1)
return "Hello!"
async def main():
message = get_message() # Missing await!
print(message)
asyncio.run(main())<coroutine object get_message at 0x...>
RuntimeWarning: coroutine 'get_message' was never awaitedSin await, obtienes el objeto corrutina en lugar del valor de retorno. Python también te advierte de que la corrutina nunca se ejecutó.
La solución es sencilla:
async def main():
message = await get_message() # Added await
print(message)
asyncio.run(main())Hello!Cuando veas un error « RuntimeWarning » (corrutina no esperada) sobre una corrutina no esperada, comprueba que has utilizado « await » (corrutina no esperada) en cada llamada a una función asíncrona.
En la sección anterior, convertimos una función síncrona en asíncrona. Pero no era más rápido. Eso es porque solo ejecutamos una corrutina. El verdadero poder de async se manifiesta cuando ejecutas varias corrutinas al mismo tiempo.
Podrías pensar que llamar a varias funciones asíncronas las ejecutaría automáticamente de forma simultánea. Pero mira lo que pasa cuando llamamos tres veces a greet_after_delay():
import asyncio
import time
async def greet_after_delay(name):
print(f"Starting {name}...")
await asyncio.sleep(2)
print(f"Hello, {name}!")
async def main():
start = time.perf_counter()
await greet_after_delay("Alice")
await greet_after_delay("Bob")
await greet_after_delay("Charlie")
elapsed = time.perf_counter() - start
print(f"Total time: {elapsed:.2f} seconds")
asyncio.run(main())Starting Alice...
Hello, Alice!
Starting Bob...
Hello, Bob!
Starting Charlie...
Hello, Charlie!
Total time: 6.01 secondsSeis segundos para tres tareas de dos segundos. Cada await espera a que tu corrutina termine antes de pasar a la siguiente línea. El código es asíncrono, pero se ejecuta de forma secuencial.
Para ejecutar corrutinas al mismo tiempo, utiliza asyncio.gather(). Toma múltiples corrutinas y las ejecuta simultáneamente:
async def main():
start = time.perf_counter()
await asyncio.gather(
greet_after_delay("Alice"),
greet_after_delay("Bob"),
greet_after_delay("Charlie"),
)
elapsed = time.perf_counter() - start
print(f"Total time: {elapsed:.2f} seconds")
asyncio.run(main())Starting Alice...
Starting Bob...
Starting Charlie...
Hello, Alice!
Hello, Bob!
Hello, Charlie!
Total time: 2.00 secondsDos segundos en lugar de seis. Las tres corrutinas se iniciaron inmediatamente, se suspendieron simultáneamente y finalizaron juntas. Eso supone una aceleración de 3 veces con un solo cambio.
Fíjate en el orden de salida: los tres mensajes «Starting...» se imprimen antes que cualquier mensaje «Hello...». Esto muestra que todas las corrutinas se ejecutan durante el mismo intervalo de dos segundos, en lugar de esperar unas a otras.
asyncio.gather() devuelve una lista de resultados en el mismo orden en que pasaste las corrutinas. Si tus corrutinas devuelven valores, puedes capturarlos:
async def fetch_number(n):
await asyncio.sleep(1)
return n * 10
async def main():
results = await asyncio.gather(
fetch_number(1),
fetch_number(2),
fetch_number(3),
)
print(results)
asyncio.run(main())[10, 20, 30]Los resultados se devuelven en orden [10, 20, 30], coincidiendo con el orden de las corrutinas pasadas a gather().
Hasta ahora, hemos utilizado asyncio.sleep() para simular retrasos. Ahora hagamos solicitudes HTTP reales. Podrías recurrir a la biblioteca requests, pero no funcionará en este caso. requests es sincrónico y bloquea el bucle de eventos, lo que frustra el propósito de la asincronía.
En su lugar, utiliza aiohttp, un cliente HTTP asíncrono creado para este fin.
A continuación se explica cómo obtener una URL con aiohttp:
import aiohttp
import asyncio
async def fetch(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
return await response.text()
async def main():
html = await fetch("https://example.com")
print(f"Fetched {len(html)} characters")
asyncio.run(main())Fetched 513 charactersObserva los dos bloques anidados « async with ». Cada uno gestiona un recurso diferente, y comprender lo que hacen es clave para utilizar correctamente aiohttp.
Esto es lo que ocurre paso a paso cuando realizas solicitudes con aiohttp:
aiohttp.ClientSession() crea un grupo de conexiones (vacío al principio).
session.get(url) comprueba la piscina: ¿Alguna conexión abierta con este host (el servidor del sitio web)?
Si no existe ninguna conexión, se crea una nueva conexión TCP (el protocolo básico para enviar datos a través de Internet) y un protocolo de enlace SSL (la configuración de cifrado para HTTPS).
Se envía una solicitud HTTP y esperamos los encabezados de respuesta.
El objeto de respuesta mantiene la conexión.
await response.text() lee los datos del cuerpo desde la red.
Salida del bucle interno async with: La conexión vuelve al grupo (¡permanece abierta!).
Se realiza la siguiente solicitud al mismo host, reutilizando la conexión del grupo (se omite el paso 3).
Salir del bucle externo async with: Se cierran todas las conexiones agrupadas.
Los pasos 7 y 8 son las ideas clave. El grupo de conexiones mantiene activas las conexiones entre solicitudes. Cuando realizas otra solicitud al mismo host, se omite por completo el protocolo TCP y el protocolo SSL.
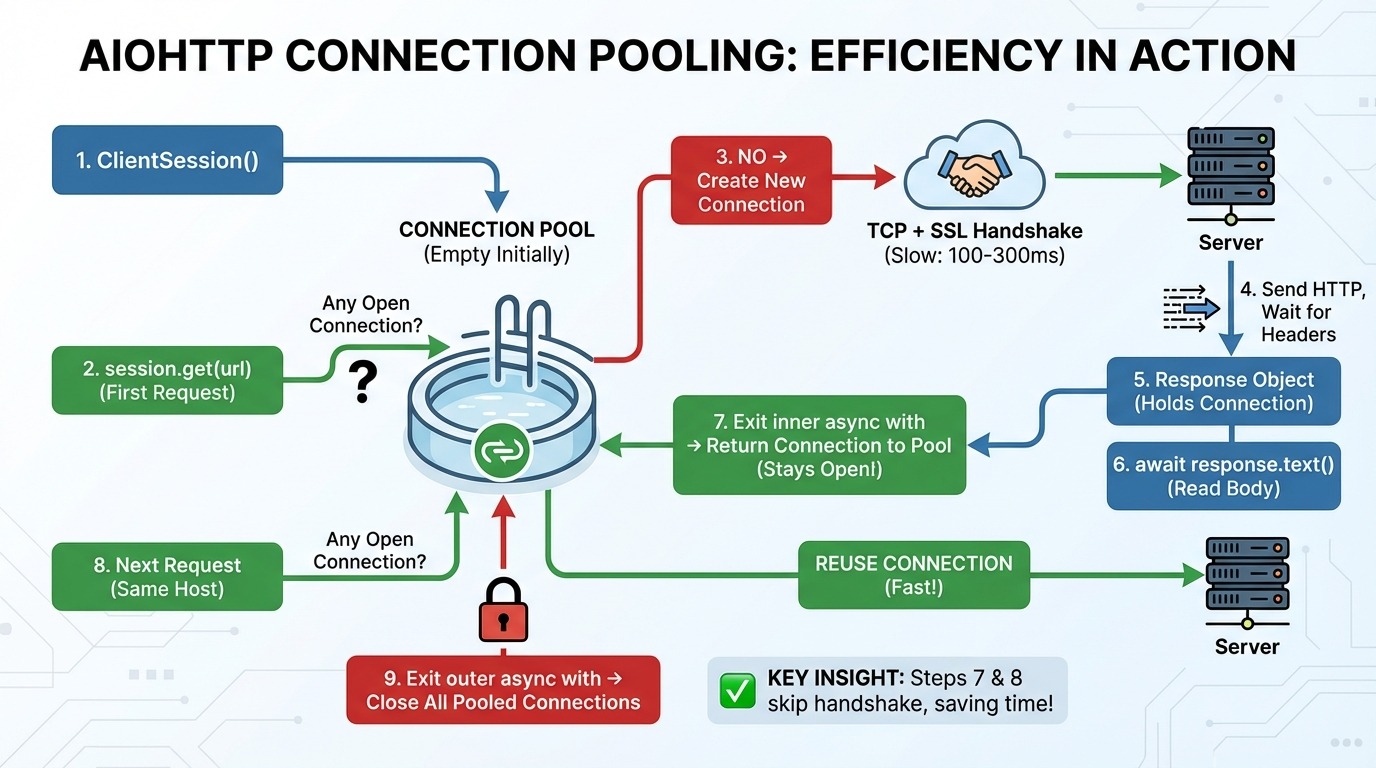
Esto es importante porque establecer una nueva conexión es lento. Un protocolo de enlace TCP requiere un viaje de ida y vuelta al servidor. Un protocolo de enlace SSL tarda dos más. Dependiendo de la latencia, eso supone entre 100 y 300 ms antes incluso de enviar tu primer byte de datos.
Ahora puedes ver por qué crear una nueva sesión para cada solicitud es un problema:
# Wrong: new session for each request
async def fetch_bad(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
return await response.text()
async def main():
urls = ["https://example.com"] * 10
results = await asyncio.gather(*[fetch_bad(url) for url in urls])Cada llamada a fetch_bad() crea una nueva sesión con un grupo vacío. Cada solicitud paga el coste total del protocolo de enlace, aunque todas vayan al mismo host.
La solución es crear una sesión y pasarla a la función fetch:
# Right: reuse a single session
async def fetch_good(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
urls = ["https://example.com"] * 10
async with aiohttp.ClientSession() as session:
results = await asyncio.gather(*[fetch_good(session, url) for url in urls])Con una sesión compartida, la primera solicitud establece la conexión y las nueve solicitudes restantes la reutilizan. Un apretón de manos en lugar de diez.
Pongamos esto en práctica con la API de Hacker News. Esta API es perfecta para demostrar el comportamiento asíncrono, ya que la recuperación de historias requiere múltiples solicitudes. Si eres nuevo en el uso de API REST en Python, consulta API de Python de : Guía para crear y utilizar API para conocer los conceptos básicos.
Estructura de la API de Hacker News:
https://hacker-news.firebaseio.com/v0/topstories.json devuelve una lista de ID de historias (solo números)
https://hacker-news.firebaseio.com/v0/item/{id}.json devuelve los detalles de una historia
Para obtener 10 historias, necesitas 11 solicitudes: una para la lista de ID y otra para cada historia. Ahí es precisamente donde destaca la programación asíncrona.
Primero, veamos qué devuelve la API si intentamos recuperar la primera historia:
import aiohttp
import asyncio
HN_API = "https://hacker-news.firebaseio.com/v0"
async def main():
async with aiohttp.ClientSession() as session:
# Get top story IDs
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
print(f"Found {len(story_ids)} stories")
print(f"First 5 IDs: {story_ids[:5]}")
# Fetch first story details
first_id = story_ids[0]
async with session.get(f"{HN_API}/item/{first_id}.json") as response:
story = await response.json()
print(f"\nStory structure:")
for key, value in story.items():
print(f" {key}: {repr(value)[:50]}")
asyncio.run(main())Found 500 stories
First 5 IDs: [46051449, 46055298, 46021577, 46053566, 45984864]
Story structure:
by: 'mikeayles'
descendants: 22
id: 46051449
kids: [46054027, 46053889, 46053275, 46053515, 46053002,
score: 217
text: 'I got DOOM running in KiCad by rendering it with
time: 1764108815
title: 'Show HN: KiDoom – Running DOOM on PCB Traces'
type: 'story'
url: 'https://www.mikeayles.com/#kidoom'La API devuelve 500 ID de historias, y cada historia tiene campos como title, url, score y by (el autor).
Ahora vamos a recuperar 10 historias de forma secuencial:
import aiohttp
import asyncio
import time
HN_API = "https://hacker-news.firebaseio.com/v0"
async def fetch_story(session, story_id):
async with session.get(f"{HN_API}/item/{story_id}.json") as response:
return await response.json()
async def main():
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
start = time.perf_counter()
stories = []
for story_id in story_ids[:10]:
story = await fetch_story(session, story_id)
stories.append(story)
elapsed = time.perf_counter() - start
print(f"Sequential: Fetched {len(stories)} stories in {elapsed:.2f} seconds")
asyncio.run(main())Sequential: Fetched 10 stories in 2.41 secondsAhora vamos a recuperar las mismas historias simultáneamente:
async def main():
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
start = time.perf_counter()
tasks = [fetch_story(session, story_id) for story_id in story_ids[:10]]
stories = await asyncio.gather(*tasks)
elapsed = time.perf_counter() - start
print(f"Concurrent: Fetched {len(stories)} stories in {elapsed:.2f} seconds")
print("\nTop 3 stories:")
for story in stories[:3]:
print(f" - {story.get('title', 'No title')}")
asyncio.run(main())Concurrent: Fetched 10 stories in 0.69 seconds
Top 3 stories:
- Show HN: KiDoom – Running DOOM on PCB Traces
- AWS is 10x slower than a dedicated server for the same price [video]
- Surprisingly, Emacs on Android is pretty goodLa versión concurrente es 3,5 veces más rápida. En lugar de esperar a que se complete cada solicitud antes de iniciar la siguiente, las 10 solicitudes se ejecutan al mismo tiempo. Aquí es donde la programación asíncrona da sus frutos con la E/S de red real.
Al recuperar datos de forma simultánea, pueden surgir varios problemas. Podrías saturar el servidor con demasiadas solicitudes. Algunas solicitudes pueden quedarse bloqueadas indefinidamente. Otros pueden fracasar rotundamente. Y cuando se producen fallos, necesitas una estrategia de recuperación.
En esta sección se analizan cada una de las cuestiones por orden de aparición: controlar el número de solicitudes que se envían, establecer límites de tiempo, gestionar los fallos y volver a intentarlo cuando sea conveniente. Si necesitas refrescar tus conocimientos sobre los fundamentos del manejo de excepciones en Python, consulta Manejo de excepciones y errores en Python. Utilizaremos esta configuración básica en todo momento:
import aiohttp
import asyncio
import time
HN_API = "https://hacker-news.firebaseio.com/v0"
async def fetch_story(session, story_id):
async with session.get(f"{HN_API}/item/{story_id}.json") as response:
return await response.json()En la sección anterior, enviamos 10 solicitudes a la vez. Funcionó bien. Pero, ¿qué ocurre cuando necesitas recuperar 500 historias? ¿O rascar 10 000 páginas?
La mayoría de las API imponen límites de velocidad. Podrían permitir 10 solicitudes por segundo o 100 conexiones simultáneas. Si superas esos límites, te bloquearán, te restringirán el acceso o te prohibirán el uso del servicio. Aunque la API no imponga límites, enviar miles de solicitudes simultáneamente puede saturar tu propio sistema o el servidor.
Necesitas una forma de controlar cuántas solicitudes están «en vuelo» en cada momento. Eso es lo que hace un semáforo.
Un semáforo funciona como un sistema de permisos. Imagina que tienes tres permisos. Cualquier tarea que desee realizar una solicitud debe obtener primero un permiso. Cuando termina, devuelve el permiso, de modo que una nueva solicitud puede utilizarlo. Si no hay permisos disponibles, la tarea espera hasta que se libere uno.
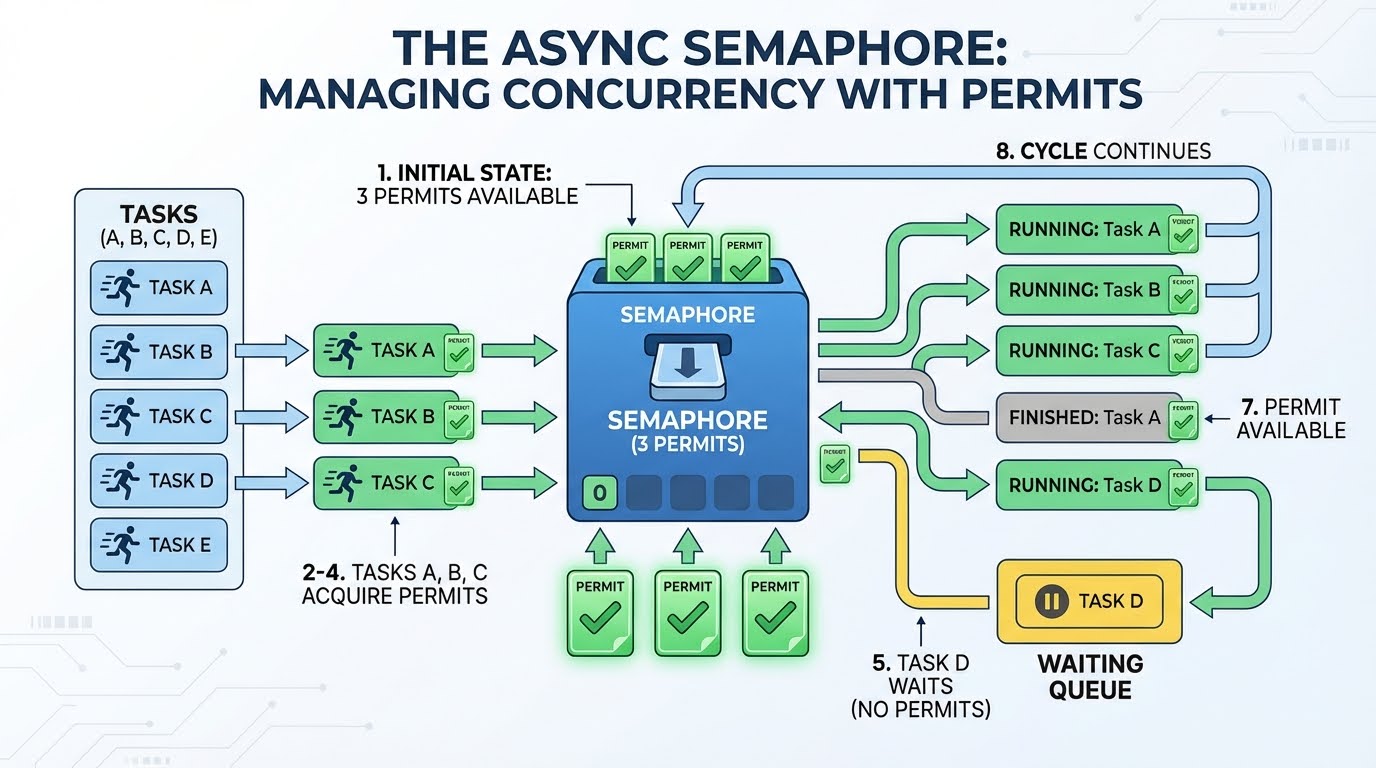
Así es como funciona con 3 permisos y 4 o más tareas:
Hay tres permisos disponibles.
La tarea A toma un permiso (quedan 2) y comienza su solicitud.
La tarea B toma un permiso (queda 1) y comienza su solicitud.
La tarea C toma un permiso (quedan 0) e inicia tu solicitud.
La tarea D necesita un permiso, pero no hay ninguno disponible, así que espera.
La tarea A finaliza y devuelve su permiso (1 disponible).
La tarea D toma ese permiso y comienza su solicitud.
Esto continúa hasta que se completan todas las tareas.
La espera en el paso 5 es eficiente. La tarea no gira en un bucle comprobando «¿ya hay un permiso libre?». Lo suspende y permite que se ejecute otro código. El bucle de eventos lo activa solo cuando hay un permiso disponible.
Ahora veamos el código. En asyncio, creas un semáforo con asyncio.Semaphore(n), donde n es el número de permisos. Para utilizarlo, envuelve tu código en async with semaphore:. Esto adquiere un permiso al entrar en el bloque y lo libera automáticamente al salir:
async def fetch_story_limited(session, story_id, semaphore):
async with semaphore: # Acquire permit (or wait if none available)
async with session.get(f"{HN_API}/item/{story_id}.json") as response:
return await response.json()
# Permit automatically released hereComparemos la obtención de 30 historias con y sin semáforo:
async def main():
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = (await response.json())[:30]
# Without rate limiting: all 30 at once
start = time.perf_counter()
await asyncio.gather(*[fetch_story(session, sid) for sid in story_ids])
print(f"No limit: {time.perf_counter() - start:.2f}s (30 concurrent)")
# With Semaphore(5): max 5 at a time
semaphore = asyncio.Semaphore(5)
start = time.perf_counter()
await asyncio.gather(*[fetch_story_limited(session, sid, semaphore) for sid in story_ids])
print(f"Semaphore(5): {time.perf_counter() - start:.2f}s (5 concurrent)")
asyncio.run(main())No limit: 0.62s (30 concurrent)
Semaphore(5): 1.50s (5 concurrent)La versión semáforo es más lenta porque procesa las solicitudes en lotes de cinco. Pero esa es la contrapartida: sacrificas velocidad a cambio de un comportamiento predecible y compatible con el servidor.
Una cosa a tener en cuenta: un semáforo limita las solicitudes simultáneas, no las solicitudes por unidad de tiempo. « Semaphore(10) » significa «como máximo 10 solicitudes simultáneas», no «10 solicitudes por segundo». Si necesitas una limitación estricta de la velocidad basada en el tiempo (por ejemplo, exactamente 10 solicitudes por segundo), puedes combinar un semáforo con retrasos entre lotes, o utilizar una biblioteca como aiolimiter.
Incluso con la concurrencia controlada, las solicitudes individuales pueden bloquearse. Es posible que un servidor acepte tu conexión, pero nunca responda. Sin un tiempo de espera, tu programa espera indefinidamente.
La función ` asyncio.wait_for() ` envuelve cualquier corrutina con una fecha límite. Le pasas la corrutina y un timeout en segundos. Si la operación no se completa a tiempo, se genera un error de tiempo de espera ( asyncio.TimeoutError):
async def slow_operation():
print("Starting slow operation...")
await asyncio.sleep(5)
return "Done"
async def main():
try:
result = await asyncio.wait_for(slow_operation(), timeout=2.0)
print(f"Success: {result}")
except asyncio.TimeoutError:
print("Operation timed out after 2 seconds")
asyncio.run(main())Starting slow operation...
Operation timed out after 2 secondsCuando expira el tiempo de espera, wait_for() cancela la corrutina. Puedes detectar una excepción « TimeoutError » y decidir qué hacer: omitir la solicitud, devolver un valor predeterminado o volver a intentarlo.
Para solicitudes simultáneas, envuelve cada una individualmente. Aquí hay un ayudante que devuelve un diccionario de errores en lugar de generar un error:
async def fetch_story_with_timeout(session, story_id, timeout=5.0):
try:
coro = fetch_story(session, story_id)
return await asyncio.wait_for(coro, timeout=timeout)
except asyncio.TimeoutError:
return {"error": f"Story {story_id} timed out"}Cuando se cancela una corrutina (por tiempo de espera agotado o cualquier otro motivo), Python genera una excepción ` asyncio.CancelledError ` en su interior. Si tu corrutina contiene recursos como manejadores de archivos o conexiones, utiliza try/finally para garantizar que la limpieza se realice incluso en caso de cancelación:
async def fetch_with_cleanup(session, url):
print("Starting fetch...")
try:
async with session.get(url) as response:
return await response.text()
finally:
print("Cleanup complete") # Runs even on cancellationLos tiempos de espera detectan las solicitudes lentas. Sin embargo, algunas solicitudes fallan inmediatamente y generan un error. Veamos qué sucede cuando falla una solicitud en un lote.
En primer lugar, necesitamos una versión de fetch_story() que genere una excepción en caso de ID no válidos:
async def fetch_story_strict(session, story_id):
story = await fetch_story(session, story_id)
if story is None:
raise ValueError(f"Story not found: {story_id}")
return storyAhora vamos a recuperar cuatro historias válidas más un ID no válido:
async def main():
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
ids_to_fetch = story_ids[:4] + [99999999999] # 4 valid + 1 invalid
try:
stories = await asyncio.gather(
*[fetch_story_strict(session, sid) for sid in ids_to_fetch]
)
print(f"Got {len(stories)} stories")
except ValueError as e:
print(f"ERROR: {e}")
asyncio.run(main())ERROR: Story not found: 99999999999Con un ID no válido, perdemos los cuatro resultados correctos. Por defecto, gather() utiliza un comportamiento de fallo rápido: una excepción lo cancela todo y se propaga hacia arriba.
Para conservar los resultados parciales, añade return_exceptions=True. Esto cambia el comportamiento de gather(): en lugar de generar excepciones, las devuelve como elementos en la lista de resultados junto con los valores correctos:
async def main():
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
ids_to_fetch = story_ids[:4] + [99999999999]
results = await asyncio.gather(
*[fetch_story_strict(session, sid) for sid in ids_to_fetch],
return_exceptions=True # Don't raise, return exceptions in list
)
# Separate successes from failures using isinstance()
stories = [r for r in results if not isinstance(r, Exception)]
errors = [r for r in results if isinstance(r, Exception)]
print(f"Got {len(stories)} stories, {len(errors)} failed")
asyncio.run(main())Got 4 stories, 1 failedLa comprobación ` isinstance(result, Exception) ` te permite separar los resultados correctos de los errores. A continuación, puedes procesar lo que ha funcionado y registrar o reintentar los fallos.
Algunos fracasos son temporales. Un servidor puede estar sobrecargado momentáneamente, o un fallo en la red puede interrumpir tu conexión. En estos casos, tiene sentido volver a intentarlo.
Pero volver a intentarlo inmediatamente puede empeorar las cosas. Si un servidor está teniendo problemas, bombardearlo con reintentos agrava el problema. El retroceso exponencial resuelve este problema esperando más tiempo entre cada intento.
El patrón utiliza 2 ** attempt para calcular los tiempos de espera: el intento 0 espera un segundo (2⁰), el intento 1 espera dos segundos (2¹), el intento 2 espera cuatro segundos (2²), y así sucesivamente. Esto le da al servidor cada vez más tiempo para recuperarse:
async def fetch_with_retry(session, story_id, max_retries=3):
for attempt in range(max_retries):
try:
story = await fetch_story(session, story_id)
if story is None:
raise ValueError(f"Story {story_id} not found")
return story
except (aiohttp.ClientError, ValueError): # Catch specific exceptions
if attempt == max_retries - 1:
print(f"Story {story_id}: Failed after {max_retries} attempts")
return None
backoff = 2 ** attempt # 1s, 2s, 4s...
print(f"Story {story_id}: Attempt {attempt + 1} failed, retrying in {backoff}s...")
await asyncio.sleep(backoff)Observa que captamos excepciones específicas (aiohttp.ClientError, ValueError) en lugar de un simple except. Esto garantiza que solo se vuelva a intentar en caso de errores que puedan ser transitorios. Un error « KeyError » (Error de red: no se ha podido establecer una conexión) debido a un código incorrecto no debería activar reintentos.
Probemos con una mezcla de ID válidos e inválidos:
async def main():
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
test_ids = [story_ids[0], 99999999999, story_ids[1], 88888888888, story_ids[2]]
results = await asyncio.gather(*[fetch_with_retry(session, sid) for sid in test_ids])
successful = [r for r in results if r is not None]
print(f"\nSuccessful: {len(successful)}, Failed: {len(test_ids) - len(successful)}")
asyncio.run(main())Story 99999999999: Attempt 1 failed, retrying in 1s...
Story 88888888888: Attempt 1 failed, retrying in 1s...
Story 99999999999: Attempt 2 failed, retrying in 2s...
Story 88888888888: Attempt 2 failed, retrying in 2s...
Story 99999999999: Failed after 3 attempts
Story 88888888888: Failed after 3 attempts
Successful: 3, Failed: 2En producción, también añadirías jitter (pequeños retrasos aleatorios) para evitar que varias solicitudes fallidas se reintenten exactamente en el mismo momento. Además, solo volverías a intentar los errores transitorios (problemas de red del lado del servidor, como 503) y abandonarías inmediatamente los permanentes (por ejemplo, 404 o 401).
Hemos estado recopilando noticias de Hacker News con la limitación de velocidad, los tiempos de espera y el manejo de errores adecuados. Ahora vamos a almacenarlos en una base de datos.
El uso de una biblioteca de bases de datos síncronas habitual, como sqlite3, bloquearía el bucle de eventos durante las consultas, lo que iría en contra del objetivo de la programación asíncrona. Mientras tu código espera a la base de datos, no se puede ejecutar ninguna otra corrutina. Para aplicaciones asíncronas, necesitas una biblioteca de bases de datos asíncronas.
aiosqlite envuelve la función integrada de Python sqlite3 en una interfaz asíncrona. Ejecuta operaciones de base de datos en un grupo de subprocesos para que no bloqueen el bucle de eventos. SQLite no requiere ninguna configuración de servidor, solo es un archivo, por lo que puedes ejecutar este código inmediatamente. Si eres nuevo en el trabajo con bases de datos en Python, el curso Introducción a las bases de datos en Python cubre los fundamentos sincrónicos en los que se basa aiosqlite.
El patrón debería resultarte familiar. Al igual que aiohttp.ClientSession, utilizas async with para gestionar la conexión:
import aiosqlite
async def init_db(db_path):
async with aiosqlite.connect(db_path) as db:
await db.execute("""
CREATE TABLE IF NOT EXISTS stories (
id INTEGER PRIMARY KEY,
title TEXT,
url TEXT,
score INTEGER,
fetched_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
""")
await db.commit()
asyncio.run(init_db("stories.db"))Las funciones principales:
aiosqlite.connect(path) abre (o crea) un archivo de base de datos.
await db.execute(sql) ejecuta una instrucción SQL.
await db.commit() guarda los cambios en el disco.
Aquí tienes una función para guardar una sola historia:
async def save_story(db, story):
await db.execute(
"INSERT OR REPLACE INTO stories (id, title, url, score) VALUES (?, ?, ?, ?)",
(story["id"], story.get("title", ""), story.get("url", ""), story.get("score", 0))
)Los marcadores de posición ? evitan la inyección SQL; nunca utilices cadenas f para insertar valores en SQL. INSERT OR REPLACE actualiza las historias existentes si las recuperamos de nuevo.
Ahora combinemos todo lo aprendido en este tutorial en un proceso completo. Recuperaremos 20 noticias de Hacker News con limitación de velocidad y las almacenaremos en una base de datos:
import aiohttp
import aiosqlite
import asyncio
HN_API = "https://hacker-news.firebaseio.com/v0"
async def fetch_story(session, story_id):
async with session.get(f"{HN_API}/item/{story_id}.json") as response:
return await response.json()
async def fetch_story_limited(session, story_id, semaphore):
async with semaphore:
story = await fetch_story(session, story_id)
if story:
return story
return None
async def save_story(db, story):
await db.execute(
"INSERT OR REPLACE INTO stories (id, title, url, score) VALUES (?, ?, ?, ?)",
(story["id"], story.get("title", ""), story.get("url", ""), story.get("score", 0))
)
async def main():
# Initialize database
async with aiosqlite.connect("hn_stories.db") as db:
await db.execute("""
CREATE TABLE IF NOT EXISTS stories (
id INTEGER PRIMARY KEY,
title TEXT,
url TEXT,
score INTEGER,
fetched_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
""")
# Fetch stories
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
semaphore = asyncio.Semaphore(5)
tasks = [fetch_story_limited(session, sid, semaphore) for sid in story_ids[:20]]
stories = await asyncio.gather(*tasks)
# Save to database
for story in stories:
if story:
await save_story(db, story)
await db.commit()
# Query and display
cursor = await db.execute("SELECT id, title, score FROM stories ORDER BY score DESC LIMIT 5")
rows = await cursor.fetchall()
print(f"Saved {len([s for s in stories if s])} stories. Top 5 by score:")
for row in rows:
print(f" [{row[2]}] {row[1][:50]}")
asyncio.run(main())Saved 20 stories. Top 5 by score:
[671] Google Antigravity exfiltrates data via indirect p
[453] Trillions spent and big software projects are stil
[319] Ilya Sutskever: We're moving from the age of scali
[311] Show HN: We built an open source, zero webhooks pa
[306] FLUX.2: Frontier Visual IntelligenceEl canal utiliza patrones de todas las secciones: ClientSession para el agrupamiento de conexiones, Semaphore(5) para la limitación de velocidad, gather() para la obtención simultánea y, ahora, aiosqlite para el almacenamiento asíncrono. Cada componente se encarga de su parte sin bloquear a los demás.
Cada vez que ejecutes este flujo de trabajo, recibirás las noticias más destacadas del día.
Este tutorial te ha llevado desde la sintaxis básica de async/await hasta un canal de datos completo. Has aprendido cómo las corrutinas se pausan y se reanudan, cómo el bucle de eventos gestiona las tareas concurrentes y cómo asyncio.gather() ejecuta varias operaciones a la vez. Añadiste solicitudes HTTP reales con aiohttp, controlaste la concurrencia con semáforos, gestionaste los fallos con tiempos de espera y reintentos, y almacenaste los resultados en una base de datos con aiosqlite.
Utiliza async cuando tu código espere en sistemas externos: API HTTP, bases de datos, E/S de archivos o sockets de red. Para tareas que requieren un uso intensivo de la CPU, como el procesamiento de datos o el cálculo numérico, async no será de ayuda; en su lugar, consulta multiprocessing o concurrent.futures. Para ir más allá, puedes explorar la documentación de asyncio y considerar FastAPI para crear API web asíncronas.
Si deseas ampliar estos conocimientos y aprender a diseñar aplicaciones inteligentes, no te pierdas el programa de ingeniero asociado de IA para programadores.
Cursos de Python
programa
Curso
Curso
blog
Matt Crabtree
15 min
Tutorial
Oluseye Jeremiah
Tutorial
Kurtis Pykes
Tutorial
Moez Ali
Tutorial
Serhii Orlivskyi
Tutorial
Abid Ali Awan


