
Cursus
Associate AI Engineer pour développeurs
26 h
Pendant que votre script Python attend patiemment la fin des réponses API, des requêtes de base de données ou des opérations sur les fichiers, ce temps reste souvent inutilisé. Grâce à la programmation asynchrone Python, votre code peut traiter plusieurs tâches simultanément. Ainsi, pendant qu'une opération est en attente, les autres progressent, transformant les moments d'inactivité en travail productif et réduisant souvent les minutes d'attente à quelques secondes seulement.
Dans ce guide, je vous présenterai les principes fondamentaux de la programmation asynchrone en Python à travers la réalisation de mini-projets. Vous constaterez comment les coroutines, les boucles d'événements et les E/S asynchrones peuvent rendre votre code beaucoup plus réactif.
Si vous souhaitez apprendre à créer des API Web asynchrones, nous vous recommandons vivement de suivre ce cours sur FastAPI.
Dans le Python synchrone traditionnel, votre code s'exécute ligne par ligne. Par exemple, lorsque vous appelez une API, votre programme s'arrête et attend la réponse. Si cela prend deux secondes, l'ensemble de votre programme reste inactif pendant deux secondes. La programmation asynchrone permet à votre code de lancer un appel API, puis de poursuivre d'autres tâches.
Lorsque la réponse arrive, votre code reprend là où il s'était arrêté. Au lieu d'attendre que chaque opération soit terminée, il est possible d'exécuter plusieurs opérations simultanément. Ceci est particulièrement important lorsque votre code passe du temps à attendre la réponse de systèmes externes tels que des bases de données, des API ou des systèmes de fichiers.
Pour que cela fonctionne, le système asynchrone de Python repose sur quelques concepts fondamentaux :
Coroutines : Fonctions définies avec async def au lieu de def. Ils peuvent interrompre et reprendre l'exécution, ce qui les rend idéaux pour les opérations impliquant une attente.
await: Ce mot-clé indique à Python : « Veuillez suspendre cette coroutine jusqu'à ce que cette opération soit terminée, mais permettez aux autres codes de continuer à s'exécuter pendant ce temps. »
Boucle d'événements : Le moteur qui gère toutes vos coroutines, en déterminant laquelle exécuter et quand passer de l'une à l'autre.
Tâches : Coroutines encapsulées pour une exécution simultanée. Vous les créez à l'aide d'asyncio.create_task() s pour exécuter plusieurs opérations simultanément.
Afin d'éviter toute confusion quant à ce que la programmation asynchrone peut (et ne peut pas) accomplir, veuillez garder à l'esprit les points suivants :
L'asynchronisme fonctionne particulièrement bien avec les tâches liées aux E/S, telles que les requêtes HTTP, les requêtes de base de données et les opérations sur les fichiers, où votre code attend des systèmes externes.
L'asynchronisme n'est pas utile pour les tâches gourmandes en ressources CPU, telles que les calculs complexes ou le traitement de données, où votre code effectue des calculs actifs plutôt que d'attendre.
La meilleure façon d'assimiler ces concepts est de rédiger du code asynchrone réel. Dans la section suivante, vous allez créer votre première fonction asynchrone et découvrir précisément comment les coroutines et la boucle d'événements fonctionnent ensemble.
Avant de rédiger du code asynchrone, examinons une fonction synchrone classique qui attend avant d'effectuer une action :
import time
def greet_after_delay():
print("Starting...")
time.sleep(2) # Blocks for 2 seconds
print("Hello!")
greet_after_delay()Starting...
Hello!La fonction fonctionne, mais time.sleep(2)bloque l'ensemble de votre programme. Aucune autre opération ne peut être effectuée pendant ces deux secondes.
Voici maintenant la version asynchrone :
import asyncio
async def greet_after_delay():
print("Starting...")
await asyncio.sleep(2) # Pauses, but doesn't block
print("Hello!")
asyncio.run(greet_after_delay())Starting...
Hello!Le résultat semble identique, mais il existe une différence sous le capot. Trois modifications ont rendu cela asynchrone :
async def Au lieu de « def », cela est déclaré comme une coroutine.
await asyncio.sleep(2) Au lieu de « time.sleep(2) », il effectue une pause sans bloquer.
asyncio.run() démarre la boucle d'événements et exécute la coroutine.
Veuillez noter que asyncio.sleep() est elle-même une fonction asynchrone, raison pour laquelle elle nécessite await. Il s'agit d'une règle essentielle : chaque fonction asynchrone doit être appelée avec ` await`. Qu'il s'agisse d'un composant intégré tel qu' asyncio.sleep() ou d'un composant que vous créez vous-même, omettre await empêchera son exécution.
À l'heure actuelle, la version asynchrone ne semble pas plus rapide. En effet, nous n'avons qu'une seule tâche. Le véritable avantage apparaît lorsque vous exécutez plusieurs coroutines simultanément, ce que nous aborderons dans la section suivante.
Il est également important de noter que vous ne pouvez pas appeler une fonction asynchrone directement comme une fonction classique. Veuillez essayer ceci :
result = greet_after_delay()
print(result)
print(type(result))<coroutine object greet_after_delay at 0x...>
<class 'coroutine'>L'appel à greet_after_delay() renvoie un objet coroutine, et non le résultat. La fonction ne s'exécute pas réellement. Vous avez besoin de la fonction « asyncio.run() » ou « await » pour l'exécuter à l'intérieur d'une autre fonction.
La boucle d'événements est le moteur de la programmation asynchrone. Il gère vos coroutines et détermine ce qui s'exécute et à quel moment. Voici ce qui se produit étape par étape lorsque vous exécutez la fonction asynchrone greet_after_delay():
asyncio.run() crée une boucle d'événements.
La boucle d'événements commence l'greet_after_delay().
« Démarrage... » s'affiche.
Les résultats sont disponibles à l'adresse asyncio.sleep(2) → la coroutine est suspendue.
Vérifications de la boucle d'événements : Y a-t-il d'autres tâches à exécuter ? (aucune pour le moment).
Deux secondes s'écoulent, la mise en veille est terminée.
La boucle d'événements reprend l'greet_after_delay().
« Bonjour ! » s'affiche.
La fonction se termine → la boucle d'événements se termine.
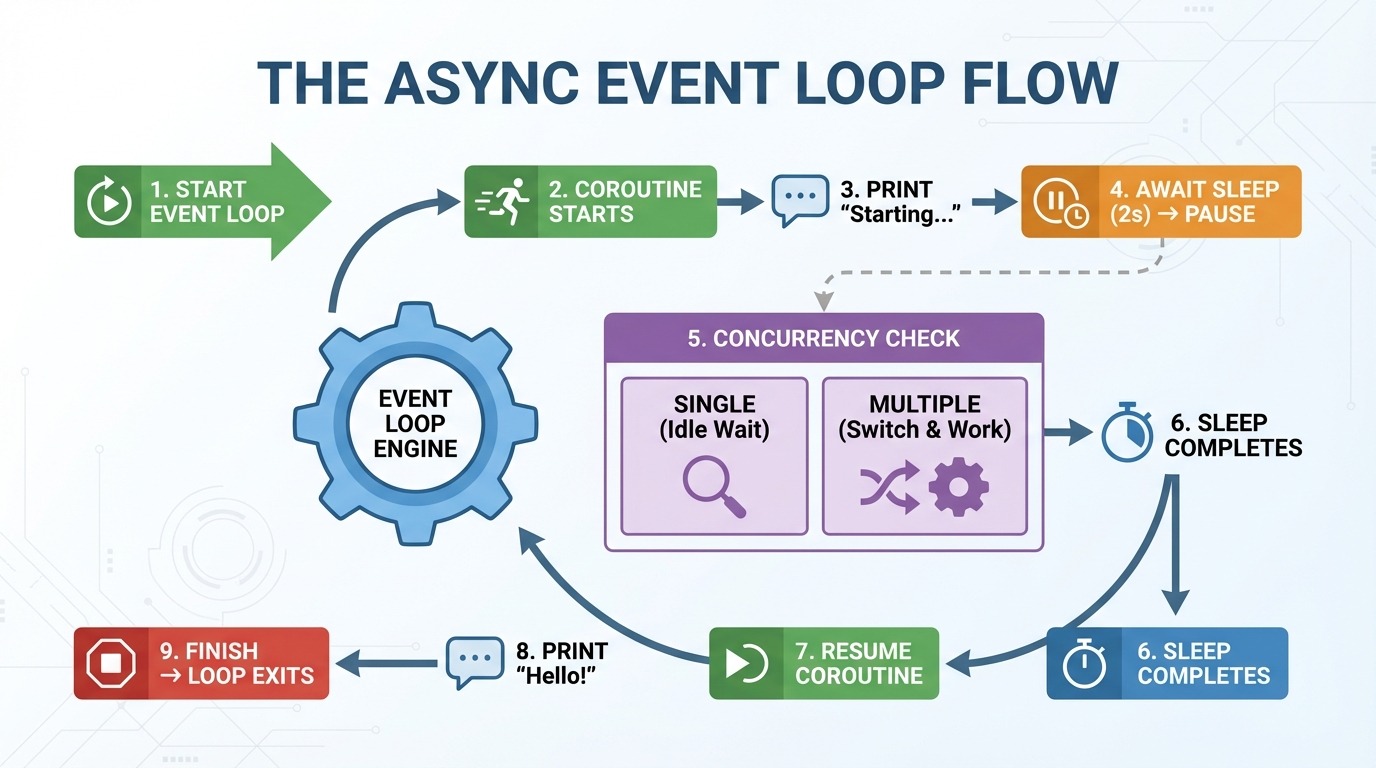
C'est à l'étape 5 que l'asynchronisme devient particulièrement intéressant. Avec une coroutine, il n'y a rien d'autre à faire. Cependant, lorsque vous avez plusieurs coroutines, la boucle d'événements passe à une autre tâche pendant qu'une autre est en attente. Au lieu de rester inactif pendant un sommeil de deux secondes, il peut exécuter d'autres codes.
Considérez la boucle d'événements comme un contrôleur de trafic. Cela n'augmente pas la vitesse des voitures individuelles. Il permet de fluidifier la circulation en laissant passer les autres véhicules lorsqu'un véhicule est à l'arrêt.
Une erreur fréquente chez les débutants consiste à omettre d'utiliser ` await ` lorsqu'ils appellent une coroutine à l'intérieur d'une autre fonction asynchrone :
import asyncio
async def get_message():
await asyncio.sleep(1)
return "Hello!"
async def main():
message = get_message() # Missing await!
print(message)
asyncio.run(main())<coroutine object get_message at 0x...>
RuntimeWarning: coroutine 'get_message' was never awaitedSans l'await, vous obtenez l'objet coroutine au lieu de la valeur de retour. Python vous avertit également que la coroutine n'a jamais été exécutée.
La solution est simple :
async def main():
message = await get_message() # Added await
print(message)
asyncio.run(main())Hello!Si vous rencontrez une exception « RuntimeWarning » concernant une coroutine inattendue, veuillez vérifier que vous avez utilisé « await » pour chaque appel de fonction asynchrone.
Dans la section précédente, nous avons converti une fonction synchrone en fonction asynchrone. Cependant, cela n'a pas été plus rapide. En effet, nous n'avons exécuté qu'une seule coroutine. La véritable puissance de l'asynchrone apparaît lorsque vous exécutez plusieurs coroutines simultanément.
Vous pourriez penser qu'appeler plusieurs fonctions asynchrones les exécuterait automatiquement de manière simultanée. Cependant, veuillez noter ce qui se produit lorsque nous appelons greet_after_delay() trois fois :
import asyncio
import time
async def greet_after_delay(name):
print(f"Starting {name}...")
await asyncio.sleep(2)
print(f"Hello, {name}!")
async def main():
start = time.perf_counter()
await greet_after_delay("Alice")
await greet_after_delay("Bob")
await greet_after_delay("Charlie")
elapsed = time.perf_counter() - start
print(f"Total time: {elapsed:.2f} seconds")
asyncio.run(main())Starting Alice...
Hello, Alice!
Starting Bob...
Hello, Bob!
Starting Charlie...
Hello, Charlie!
Total time: 6.01 secondsSix secondes pour trois tâches de deux secondes chacune. Chaque await attend que sa coroutine se termine avant de passer à la ligne suivante. Le code est asynchrone, mais il s'exécute de manière séquentielle.
Pour exécuter des coroutines simultanément, veuillez utiliser asyncio.gather(). Il utilise plusieurs coroutines et les exécute simultanément :
async def main():
start = time.perf_counter()
await asyncio.gather(
greet_after_delay("Alice"),
greet_after_delay("Bob"),
greet_after_delay("Charlie"),
)
elapsed = time.perf_counter() - start
print(f"Total time: {elapsed:.2f} seconds")
asyncio.run(main())Starting Alice...
Starting Bob...
Starting Charlie...
Hello, Alice!
Hello, Bob!
Hello, Charlie!
Total time: 2.00 secondsDeux secondes au lieu de six. Les trois coroutines ont démarré immédiatement, se sont mises en veille simultanément et se sont terminées ensemble. Cela représente une accélération de 3 fois la vitesse avec un seul changement.
Veuillez noter l'ordre d'affichage : les trois messages « Starting... » s'affichent avant les messages « Hello... ». Cela démontre que toutes les coroutines s'exécutent pendant la même fenêtre de deux secondes plutôt que d'attendre les unes les autres.
asyncio.gather() Renvoie une liste de résultats dans le même ordre que celui dans lequel vous avez transmis les coroutines. Si vos coroutines renvoient des valeurs, vous pouvez les capturer :
async def fetch_number(n):
await asyncio.sleep(1)
return n * 10
async def main():
results = await asyncio.gather(
fetch_number(1),
fetch_number(2),
fetch_number(3),
)
print(results)
asyncio.run(main())[10, 20, 30]Les résultats sont renvoyés dans l'ordre [10, 20, 30], correspondant à l'ordre des coroutines transmises à gather().
Jusqu'à présent, nous avons utilisé asyncio.sleep() pour simuler des retards. Maintenant, procédons à de véritables requêtes HTTP. Vous pourriez envisager d'utiliser la bibliothèque requests, mais elle ne fonctionnera pas dans ce cas. requests est synchrone et bloque la boucle d'événements, ce qui va à l'encontre de l'objectif de l'asynchronisme.
Veuillez utiliser aiohttp, un client HTTP asynchrone conçu à cet effet.
Voici comment récupérer une URL avec aiohttp:
import aiohttp
import asyncio
async def fetch(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
return await response.text()
async def main():
html = await fetch("https://example.com")
print(f"Fetched {len(html)} characters")
asyncio.run(main())Fetched 513 charactersVeuillez noter les deux blocs d'async with s imbriqués. Chacun gère une ressource différente, et il est essentiel de comprendre leur fonctionnement pour utiliser correctement aiohttp.
Voici ce qui se produit étape par étape lorsque vous effectuez des requêtes avec aiohttp:
aiohttp.ClientSession() crée un pool de connexions (initialement vide).
session.get(url) vérifie la piscine : Existe-t-il une connexion ouverte vers cet hôte (le serveur du site Web) ?
Si aucune connexion n'existe, une nouvelle connexion TCP (le protocole de base pour l'envoi de données sur Internet) et une négociation SSL (la configuration de cryptage pour HTTPS) sont établies.
Une requête HTTP est envoyée, et nous attendons les en-têtes de réponse.
L'objet réponse contient la connexion.
await response.text() lit les données du corps à partir du réseau.
Sortie de la boucle d'async with e interne : La connexion est rétablie avec le pool (et reste ouverte).
La requête suivante vers le même hôte est effectuée en réutilisant la connexion du pool (étape 3 est ignorée).
Sortie de la boucle d'async with s externe : Toutes les connexions mises en commun sont fermées.
Les étapes 7 et 8 constituent les points essentiels. Le pool de connexions maintient les connexions actives entre les requêtes. Lorsque vous effectuez une autre requête vers le même hôte, il ignore complètement la négociation TCP et SSL.
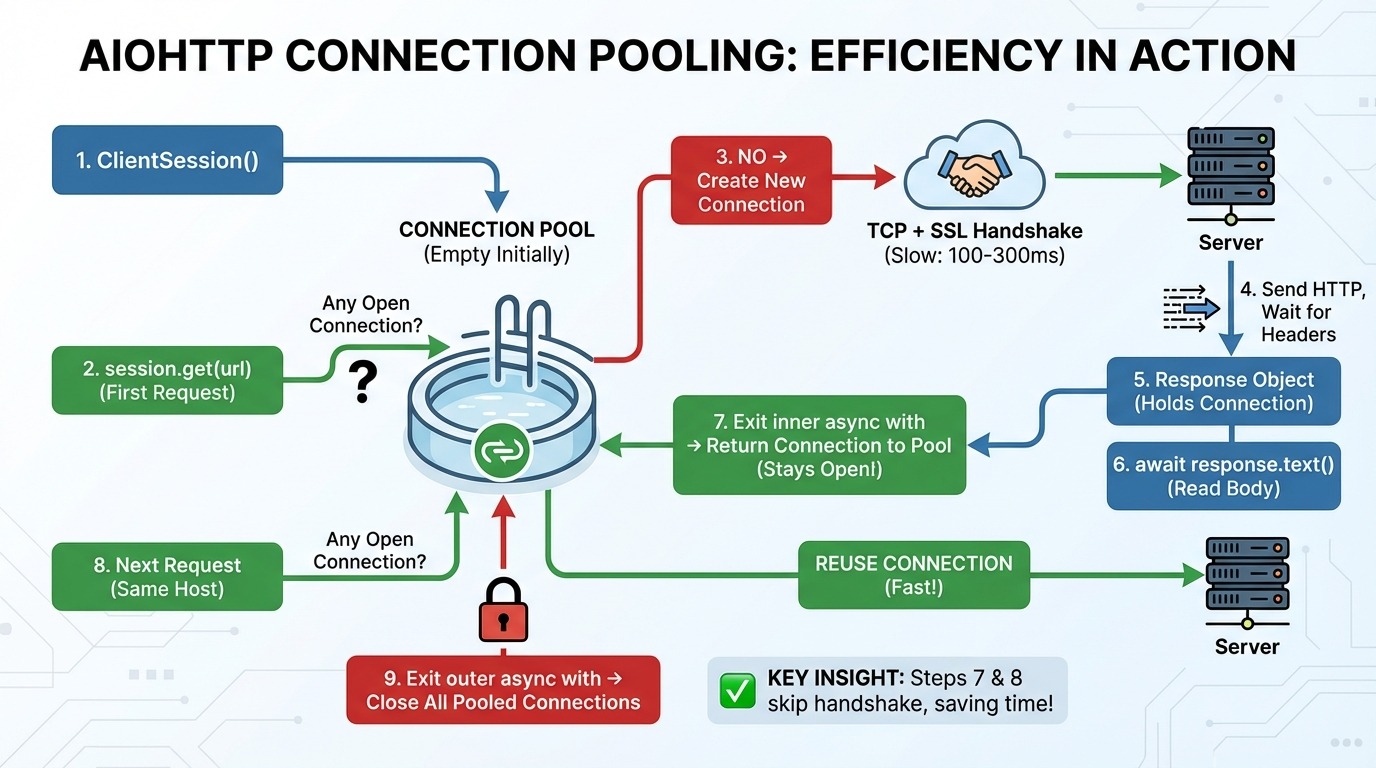
Ceci est important car l'établissement d'une nouvelle connexion est un processus lent. Une poignée de main TCP nécessite un aller-retour vers le serveur. Une négociation SSL nécessite deux étapes supplémentaires. En fonction de la latence, cela représente 100 à 300 ms avant même d'envoyer votre premier octet de données.
Vous comprenez maintenant pourquoi la création d'une nouvelle session pour chaque requête peut poser problème :
# Wrong: new session for each request
async def fetch_bad(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
return await response.text()
async def main():
urls = ["https://example.com"] * 10
results = await asyncio.gather(*[fetch_bad(url) for url in urls])Chaque appel à fetch_bad() crée une nouvelle session avec un pool vide. Chaque requête paie l'intégralité du coût de la poignée de main, même si elles sont toutes destinées au même hôte.
La solution consiste à créer une session et à la transmettre à votre fonction fetch :
# Right: reuse a single session
async def fetch_good(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
urls = ["https://example.com"] * 10
async with aiohttp.ClientSession() as session:
results = await asyncio.gather(*[fetch_good(session, url) for url in urls])Dans le cas d'une session partagée, la première requête établit la connexion, et les neuf requêtes restantes la réutilisent. Une poignée de main au lieu de dix.
Mettons cela en pratique avec l'API Hacker News. Cette API est idéale pour illustrer le comportement asynchrone, car la récupération d'articles nécessite plusieurs requêtes. Si vous débutez avec les API REST en Python, veuillez consulter les API Python d' . Guide de création et d'utilisation des API pour les concepts fondamentaux.
Structure de l'API Hacker News :
https://hacker-news.firebaseio.com/v0/topstories.json renvoie une liste d'identifiants d'articles (simplement des numéros)
https://hacker-news.firebaseio.com/v0/item/{id}.json fournit les détails d'une histoire
Pour obtenir 10 articles, il est nécessaire d'effectuer 11 requêtes : une pour la liste d'identifiants, puis une pour chaque article. C'est précisément là que la programmation asynchrone démontre ses avantages.
Tout d'abord, examinons ce que renvoie l'API lorsque nous essayons de récupérer la première histoire :
import aiohttp
import asyncio
HN_API = "https://hacker-news.firebaseio.com/v0"
async def main():
async with aiohttp.ClientSession() as session:
# Get top story IDs
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
print(f"Found {len(story_ids)} stories")
print(f"First 5 IDs: {story_ids[:5]}")
# Fetch first story details
first_id = story_ids[0]
async with session.get(f"{HN_API}/item/{first_id}.json") as response:
story = await response.json()
print(f"\nStory structure:")
for key, value in story.items():
print(f" {key}: {repr(value)[:50]}")
asyncio.run(main())Found 500 stories
First 5 IDs: [46051449, 46055298, 46021577, 46053566, 45984864]
Story structure:
by: 'mikeayles'
descendants: 22
id: 46051449
kids: [46054027, 46053889, 46053275, 46053515, 46053002,
score: 217
text: 'I got DOOM running in KiCad by rendering it with
time: 1764108815
title: 'Show HN: KiDoom – Running DOOM on PCB Traces'
type: 'story'
url: 'https://www.mikeayles.com/#kidoom'L'API renvoie 500 identifiants d'articles, et chaque article comporte des champs tels que title, url, score et by (l'auteur).
Maintenant, récupérons 10 articles de manière séquentielle :
import aiohttp
import asyncio
import time
HN_API = "https://hacker-news.firebaseio.com/v0"
async def fetch_story(session, story_id):
async with session.get(f"{HN_API}/item/{story_id}.json") as response:
return await response.json()
async def main():
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
start = time.perf_counter()
stories = []
for story_id in story_ids[:10]:
story = await fetch_story(session, story_id)
stories.append(story)
elapsed = time.perf_counter() - start
print(f"Sequential: Fetched {len(stories)} stories in {elapsed:.2f} seconds")
asyncio.run(main())Sequential: Fetched 10 stories in 2.41 secondsMaintenant, récupérons les mêmes articles simultanément :
async def main():
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
start = time.perf_counter()
tasks = [fetch_story(session, story_id) for story_id in story_ids[:10]]
stories = await asyncio.gather(*tasks)
elapsed = time.perf_counter() - start
print(f"Concurrent: Fetched {len(stories)} stories in {elapsed:.2f} seconds")
print("\nTop 3 stories:")
for story in stories[:3]:
print(f" - {story.get('title', 'No title')}")
asyncio.run(main())Concurrent: Fetched 10 stories in 0.69 seconds
Top 3 stories:
- Show HN: KiDoom – Running DOOM on PCB Traces
- AWS is 10x slower than a dedicated server for the same price [video]
- Surprisingly, Emacs on Android is pretty goodLa version concurrente est 3,5 fois plus rapide. Au lieu d'attendre que chaque requête soit terminée avant de passer à la suivante, les 10 requêtes s'exécutent simultanément. C'est là que la programmation asynchrone démontre son efficacité avec les E/S réseau réelles.
Lors de la récupération simultanée de données, plusieurs problèmes peuvent survenir. Vous risquez de surcharger le serveur avec un nombre excessif de requêtes. Certaines requêtes peuvent rester en attente indéfiniment. D'autres pourraient échouer complètement. Et lorsque des échecs surviennent, il est nécessaire de disposer d'une stratégie de reprise.
Cette section aborde chaque préoccupation dans l'ordre où elles se présentent : contrôler le nombre de requêtes envoyées, définir des limites de temps, gérer les échecs et réessayer lorsque cela est pertinent. Si vous avez besoin d'une mise à jour sur les principes fondamentaux de la gestion des exceptions en Python, veuillez consulter Gestion des exceptions et des erreurs en Python. Nous utiliserons cette configuration de base tout au long du processus :
import aiohttp
import asyncio
import time
HN_API = "https://hacker-news.firebaseio.com/v0"
async def fetch_story(session, story_id):
async with session.get(f"{HN_API}/item/{story_id}.json") as response:
return await response.json()Dans la section précédente, nous avons envoyé 10 requêtes simultanément. Cela a bien fonctionné. Cependant, que se produit-il lorsque vous devez récupérer 500 articles ? Ou bien récupérer 10 000 pages ?
La plupart des API imposent des limites de débit. Ils peuvent autoriser 10 requêtes par seconde ou 100 connexions simultanées. Si vous dépassez ces limites, vous serez bloqué, ralenti ou banni. Même si l'API n'impose pas de limites, l'envoi simultané de milliers de requêtes peut surcharger votre propre système ou le serveur.
Il est nécessaire de disposer d'un moyen pour contrôler le nombre de requêtes en cours à tout moment. C'est la fonction d'un sémaphore.
Un sémaphore fonctionne comme un système de permis. Veuillez imaginer que vous disposez de trois permis. Toute tâche nécessitant une demande doit d'abord obtenir une autorisation. Une fois terminé, il renvoie le permis afin qu'une nouvelle demande puisse l'utiliser. Si aucun permis n'est disponible, la tâche attend qu'un permis se libère.
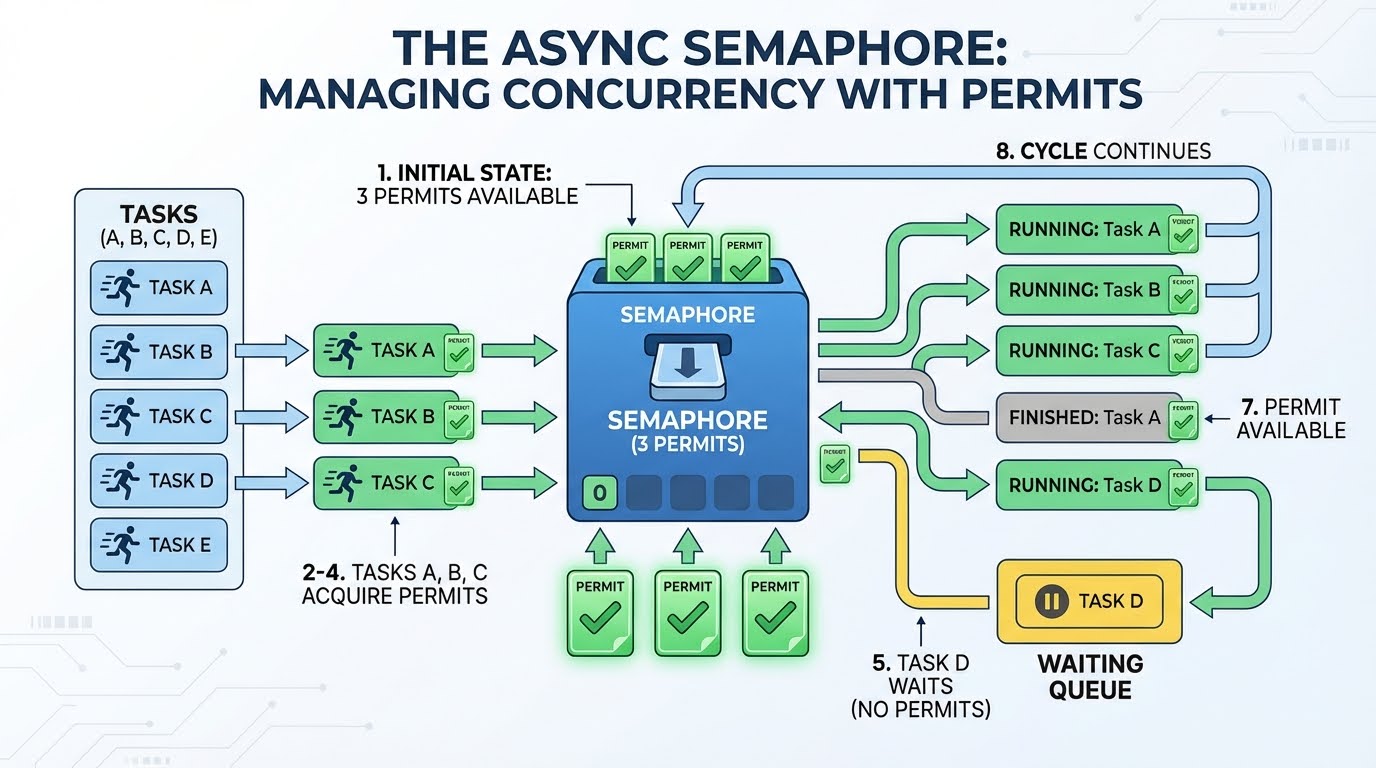
Voici comment cela se présente avec 3 permis et 4 tâches ou plus :
Trois permis sont disponibles.
La tâche A nécessite un permis (il en reste 2) et commence sa demande.
La tâche B utilise un permis (il en reste un) et commence sa demande.
La tâche C utilise un permis (il en reste 0) et commence sa demande.
La tâche D nécessite un permis, mais aucun n'est disponible ; elle est donc en attente.
La tâche A est terminée, renvoie son permis (1 disponible).
La tâche D utilise ce permis et commence sa demande.
Ce processus se poursuit jusqu'à ce que toutes les tâches soient terminées.
L'attente à l'étape 5 est efficace. La tâche ne tourne pas en boucle pour vérifier si « un permis est disponible ». Il suspend et permet à d'autres codes de s'exécuter. La boucle d'événements ne le réveille que lorsqu'un permis devient disponible.
Examinons maintenant le code. Dans asyncio, vous créez un sémaphore avec asyncio.Semaphore(n), où n correspond au nombre d'autorisations. Pour l'utiliser, veuillez encapsuler votre code dans async with semaphore:. Ceci acquiert un permis lors de l'entrée dans le bloc et le libère automatiquement lors de la sortie :
async def fetch_story_limited(session, story_id, semaphore):
async with semaphore: # Acquire permit (or wait if none available)
async with session.get(f"{HN_API}/item/{story_id}.json") as response:
return await response.json()
# Permit automatically released hereComparons le chargement de 30 articles avec et sans sémaphore :
async def main():
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = (await response.json())[:30]
# Without rate limiting: all 30 at once
start = time.perf_counter()
await asyncio.gather(*[fetch_story(session, sid) for sid in story_ids])
print(f"No limit: {time.perf_counter() - start:.2f}s (30 concurrent)")
# With Semaphore(5): max 5 at a time
semaphore = asyncio.Semaphore(5)
start = time.perf_counter()
await asyncio.gather(*[fetch_story_limited(session, sid, semaphore) for sid in story_ids])
print(f"Semaphore(5): {time.perf_counter() - start:.2f}s (5 concurrent)")
asyncio.run(main())No limit: 0.62s (30 concurrent)
Semaphore(5): 1.50s (5 concurrent)La version sémaphore est plus lente car elle traite les requêtes par lots de cinq. Cependant, il s'agit d'un compromis : vous sacrifiez la vitesse au profit d'un comportement prévisible et adapté au serveur.
Il est important de noter qu'un sémaphore limite les requêtes simultanées, et non les requêtes par unité de temps. « Semaphore(10) » signifie « au maximum 10 requêtes simultanées », et non « 10 requêtes par seconde ». Si vous avez besoin d'une limitation stricte du débit en fonction du temps (par exemple, exactement 10 requêtes par seconde), vous pouvez combiner un sémaphore avec des délais entre les lots, ou utiliser une bibliothèque telle que aiolimiter.
Même avec une concurrence contrôlée, certaines requêtes individuelles peuvent se bloquer. Un serveur peut accepter votre connexion sans jamais répondre. Sans délai d'attente, votre programme attendra indéfiniment.
La fonction ` asyncio.wait_for() ` encapsule toute coroutine avec une échéance. Vous lui transmettez la coroutine et une timeout en quelques secondes. Si l'opération ne s'achève pas dans les délais impartis, elle génère une exception « asyncio.TimeoutError » :
async def slow_operation():
print("Starting slow operation...")
await asyncio.sleep(5)
return "Done"
async def main():
try:
result = await asyncio.wait_for(slow_operation(), timeout=2.0)
print(f"Success: {result}")
except asyncio.TimeoutError:
print("Operation timed out after 2 seconds")
asyncio.run(main())Starting slow operation...
Operation timed out after 2 secondsLorsque le délai expire, wait_for() annule la coroutine. Vous pouvez intercepter l'exception TimeoutError et décider de la marche à suivre : ignorer la requête, renvoyer une valeur par défaut ou réessayer.
Pour les requêtes simultanées, veuillez encapsuler chacune d'elles individuellement. Voici une fonction d'aide qui renvoie un dictionnaire d'erreurs au lieu de générer une erreur :
async def fetch_story_with_timeout(session, story_id, timeout=5.0):
try:
coro = fetch_story(session, story_id)
return await asyncio.wait_for(coro, timeout=timeout)
except asyncio.TimeoutError:
return {"error": f"Story {story_id} timed out"}Lorsqu'une coroutine est annulée (en raison d'un délai d'attente ou pour toute autre raison), Python génère une exception d'annulation ( asyncio.CancelledError ) à l'intérieur de celle-ci. Si votre coroutine détient des ressources telles que des descripteurs de fichiers ou des connexions, veuillez utiliser try/finally afin de garantir que le nettoyage s'effectue même en cas d'annulation :
async def fetch_with_cleanup(session, url):
print("Starting fetch...")
try:
async with session.get(url) as response:
return await response.text()
finally:
print("Cleanup complete") # Runs even on cancellationLes délais d'attente permettent de détecter les requêtes lentes. Cependant, certaines requêtes échouent immédiatement et génèrent une erreur. Observons ce qui se produit lorsqu'une requête d'un lot échoue.
Tout d'abord, nous avons besoin d'une version d'fetch_story(). qui génère une exception en cas d'identifiants non valides :
async def fetch_story_strict(session, story_id):
story = await fetch_story(session, story_id)
if story is None:
raise ValueError(f"Story not found: {story_id}")
return storyMaintenant, récupérons quatre récits valides et un identifiant non valide :
async def main():
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
ids_to_fetch = story_ids[:4] + [99999999999] # 4 valid + 1 invalid
try:
stories = await asyncio.gather(
*[fetch_story_strict(session, sid) for sid in ids_to_fetch]
)
print(f"Got {len(stories)} stories")
except ValueError as e:
print(f"ERROR: {e}")
asyncio.run(main())ERROR: Story not found: 99999999999Avec un identifiant invalide, nous perdons les quatre résultats positifs. Par défaut, gather() utilise un comportement « fail-fast » : une exception annule tout et se propage vers le haut.
Pour conserver des résultats partiels, veuillez ajouter return_exceptions=True. Cela modifie le comportement de gather(): au lieu de lever des exceptions, il les renvoie sous forme d'éléments dans la liste des résultats, aux côtés des valeurs réussies :
async def main():
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
ids_to_fetch = story_ids[:4] + [99999999999]
results = await asyncio.gather(
*[fetch_story_strict(session, sid) for sid in ids_to_fetch],
return_exceptions=True # Don't raise, return exceptions in list
)
# Separate successes from failures using isinstance()
stories = [r for r in results if not isinstance(r, Exception)]
errors = [r for r in results if isinstance(r, Exception)]
print(f"Got {len(stories)} stories, {len(errors)} failed")
asyncio.run(main())Got 4 stories, 1 failedLa vérification de l'isinstance(result, Exception) vous permet de distinguer les résultats positifs des erreurs. Vous pouvez ensuite traiter ce qui a fonctionné et enregistrer ou réessayer les échecs.
Certains échecs sont temporaires. Un serveur peut être temporairement surchargé, ou un problème réseau peut entraîner une interruption de votre connexion. Dans ces cas, il est judicieux de réessayer.
Cependant, réessayer immédiatement peut aggraver la situation. Si un serveur rencontre des difficultés, le surcharger de tentatives de reconnexion ne fait qu'aggraver le problème. Le backoff exponentiel résout ce problème en prolongeant le délai entre chaque tentative.
Le modèle utilise la loi de Poisson ( 2 ** attempt ) pour calculer les temps d'attente : la tentative 0 attend une seconde (2⁰), la tentative 1 attend deux secondes (2¹), la tentative 2 attend quatre secondes (2²), et ainsi de suite. Cela accorde au serveur davantage de temps pour se rétablir :
async def fetch_with_retry(session, story_id, max_retries=3):
for attempt in range(max_retries):
try:
story = await fetch_story(session, story_id)
if story is None:
raise ValueError(f"Story {story_id} not found")
return story
except (aiohttp.ClientError, ValueError): # Catch specific exceptions
if attempt == max_retries - 1:
print(f"Story {story_id}: Failed after {max_retries} attempts")
return None
backoff = 2 ** attempt # 1s, 2s, 4s...
print(f"Story {story_id}: Attempt {attempt + 1} failed, retrying in {backoff}s...")
await asyncio.sleep(backoff)Veuillez noter que nous interceptons des exceptions spécifiques (aiohttp.ClientError, ValueError) plutôt qu'une simple exception except. Cela garantit que nous ne réessayons qu'en cas d'erreurs qui pourraient être temporaires. Une exception d' KeyError e due à un code incorrect ne devrait pas déclencher de nouvelles tentatives.
Vérifions avec un mélange d'identifiants valides et non valides :
async def main():
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
test_ids = [story_ids[0], 99999999999, story_ids[1], 88888888888, story_ids[2]]
results = await asyncio.gather(*[fetch_with_retry(session, sid) for sid in test_ids])
successful = [r for r in results if r is not None]
print(f"\nSuccessful: {len(successful)}, Failed: {len(test_ids) - len(successful)}")
asyncio.run(main())Story 99999999999: Attempt 1 failed, retrying in 1s...
Story 88888888888: Attempt 1 failed, retrying in 1s...
Story 99999999999: Attempt 2 failed, retrying in 2s...
Story 88888888888: Attempt 2 failed, retrying in 2s...
Story 99999999999: Failed after 3 attempts
Story 88888888888: Failed after 3 attempts
Successful: 3, Failed: 2En production, il est également recommandé d'ajouter une gigue (c'est-à-dire de petits délais aléatoires) afin d'éviter que plusieurs requêtes ayant échoué ne soient réessayées exactement au même moment. De plus, il est recommandé de ne réessayer que les erreurs transitoires (problèmes réseau côté serveur, tels que 503) et d'abandonner immédiatement les erreurs permanentes (par exemple, 404 ou 401).
Nous avons récupéré les articles de Hacker News en respectant les limites de débit, les délais d'attente et la gestion des erreurs appropriés. Maintenant, enregistrons-les dans une base de données.
L'utilisation d'une bibliothèque de base de données synchrone classique telle que sqlite3risquerait de bloquer la boucle d'événements pendant les requêtes, ce qui irait à l'encontre de l'objectif de la programmation asynchrone. Pendant que votre code attend la base de données, aucune autre coroutine ne peut s'exécuter. Pour les applications asynchrones, il est nécessaire de disposer d'une bibliothèque de base de données asynchrone.
aiosqlite encapsule la fonction intégrée d' sqlite3 ation de Python dans une interface asynchrone. Il exécute les opérations de base de données dans un pool de threads afin qu'elles ne bloquent pas la boucle d'événements. SQLite ne nécessite aucune configuration de serveur, il s'agit simplement d'un fichier, vous pouvez donc exécuter ce code immédiatement. Si vous débutez dans l'utilisation des bases de données en Python, le cours Introduction aux bases de données en Python couvre les principes fondamentaux synchrones sur lesquels s'appuie aiosqlite.
Le modèle devrait vous sembler familier. Tout comme aiohttp.ClientSession, vous pouvez utiliser async with pour gérer la connexion :
import aiosqlite
async def init_db(db_path):
async with aiosqlite.connect(db_path) as db:
await db.execute("""
CREATE TABLE IF NOT EXISTS stories (
id INTEGER PRIMARY KEY,
title TEXT,
url TEXT,
score INTEGER,
fetched_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
""")
await db.commit()
asyncio.run(init_db("stories.db"))Les fonctions principales :
aiosqlite.connect(path) ouvre (ou crée) un fichier de base de données.
await db.execute(sql) exécute une instruction SQL.
await db.commit() enregistre les modifications sur le disque.
Voici une fonction permettant d'enregistrer une seule histoire :
async def save_story(db, story):
await db.execute(
"INSERT OR REPLACE INTO stories (id, title, url, score) VALUES (?, ?, ?, ?)",
(story["id"], story.get("title", ""), story.get("url", ""), story.get("score", 0))
)Les espaces réservés ? empêchent l'injection SQL. Veuillez ne jamais utiliser de chaînes f pour insérer des valeurs dans SQL. INSERT OR REPLACE met à jour les articles existants si nous les récupérons à nouveau.
Maintenant, intégrons tous les éléments de ce tutoriel dans un pipeline complet. Nous allons récupérer 20 articles de Hacker News avec limitation du débit et les stocker dans une base de données :
import aiohttp
import aiosqlite
import asyncio
HN_API = "https://hacker-news.firebaseio.com/v0"
async def fetch_story(session, story_id):
async with session.get(f"{HN_API}/item/{story_id}.json") as response:
return await response.json()
async def fetch_story_limited(session, story_id, semaphore):
async with semaphore:
story = await fetch_story(session, story_id)
if story:
return story
return None
async def save_story(db, story):
await db.execute(
"INSERT OR REPLACE INTO stories (id, title, url, score) VALUES (?, ?, ?, ?)",
(story["id"], story.get("title", ""), story.get("url", ""), story.get("score", 0))
)
async def main():
# Initialize database
async with aiosqlite.connect("hn_stories.db") as db:
await db.execute("""
CREATE TABLE IF NOT EXISTS stories (
id INTEGER PRIMARY KEY,
title TEXT,
url TEXT,
score INTEGER,
fetched_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
""")
# Fetch stories
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
semaphore = asyncio.Semaphore(5)
tasks = [fetch_story_limited(session, sid, semaphore) for sid in story_ids[:20]]
stories = await asyncio.gather(*tasks)
# Save to database
for story in stories:
if story:
await save_story(db, story)
await db.commit()
# Query and display
cursor = await db.execute("SELECT id, title, score FROM stories ORDER BY score DESC LIMIT 5")
rows = await cursor.fetchall()
print(f"Saved {len([s for s in stories if s])} stories. Top 5 by score:")
for row in rows:
print(f" [{row[2]}] {row[1][:50]}")
asyncio.run(main())Saved 20 stories. Top 5 by score:
[671] Google Antigravity exfiltrates data via indirect p
[453] Trillions spent and big software projects are stil
[319] Ilya Sutskever: We're moving from the age of scali
[311] Show HN: We built an open source, zero webhooks pa
[306] FLUX.2: Frontier Visual IntelligenceLe pipeline utilise des modèles provenant de chaque section : ClientSession pour la mise en commun des connexions, Semaphore(5) pour la limitation du débit, gather() pour la récupération simultanée, et désormais aiosqlite pour le stockage asynchrone. Chaque composant exécute sa tâche sans entraver les autres.
Chaque fois que vous exécuterez ce flux de travail, vous recevrez les actualités principales du jour.
Ce tutoriel vous a guidé depuis la syntaxe de base d'async/await jusqu'à la création d'un pipeline de données complet. Vous avez appris comment les coroutines se mettent en pause et reprennent, comment la boucle d'événements gère les tâches simultanées et comment l'asyncio.gather() e exécute plusieurs opérations à la fois. Vous avez intégré de véritables requêtes HTTP avec aiohttp, contrôlé la concurrence avec des sémaphores, géré les échecs avec des délais d'attente et des tentatives de reconnexion, et stocké les résultats dans une base de données avec aiosqlite.
Veuillez utiliser async lorsque votre code attend des systèmes externes : API HTTP, bases de données, E/S de fichiers ou sockets réseau. Pour les tâches gourmandes en ressources CPU telles que le traitement de données ou les calculs intensifs, async ne sera pas d'une grande utilité. Nous vous recommandons plutôt de vous tourner vers multiprocessing ou concurrent.futures. Pour approfondir vos connaissances, vous pouvez consulter la documentation asyncio et envisager FastAPI pour créer des API web asynchrones.
Si vous souhaitez approfondir ces connaissances et apprendre à concevoir des applications intelligentes, nous vous invitons à consulter le cursus Ingénieur IA associé pour développeurs.
Cours Python
Cursus
Cours
Cours
Tutoriel
Satyabrata Pal
Tutoriel
Kurtis Pykes
Tutoriel
Moez Ali
Tutoriel
Sejal Jaiswal
Tutoriel
Derrick Mwiti
Tutoriel
DataCamp Team