
Lernpfad
Associate AI Engineer für Entwickler
26 Std.
Während dein Python-Skript geduldig auf API-Antworten, Datenbankabfragen oder Dateioperationen wartet, bleibt diese Zeit oft ungenutzt. Mit der asynchronen Programmierung in Python kann dein Code mehrere Aufgaben gleichzeitig erledigen. Während also ein Vorgang wartet, machen andere weiter, verwandeln Leerlaufzeiten in produktive Arbeit und verkürzen Wartezeiten oft von Minuten auf nur wenige Sekunden.
In diesem Leitfaden zeige ich dir die Grundlagen der asynchronen Programmierung in Python anhand von kleinen Projekten. Du wirst sehen, wie Coroutinen, Ereignisschleifen und asynchrone E/A deinen Code viel reaktionsschneller machen können.
Wenn du lernen willst, wie man asynchrone Web-APIs erstellt, solltest du dir unbedingt diesen Kurs zu FastAPI ansehen.
Im normalen synchronen Python wird dein Code Zeile für Zeile ausgeführt. Wenn du zum Beispiel eine API aufrufst, hält dein Programm an und wartet auf die Antwort. Wenn das zwei Sekunden dauert, steht dein ganzes Programm zwei Sekunden lang still. Mit asynchroner Programmierung kann dein Code einen API-Aufruf starten und dann mit anderen Aufgaben weitermachen.
Sobald die Antwort da ist, macht dein Code da weiter, wo er aufgehört hat. Anstatt zu warten, bis jeder Vorgang fertig ist, kannst du mehrere Vorgänge gleichzeitig machen. Das ist besonders wichtig, wenn dein Code darauf wartet, dass externe Systeme wie Datenbanken, APIs oder Dateisysteme reagieren.
Damit das klappt, nutzt das asynchrone System von Python ein paar Kernkonzepte:
Coroutinen: Funktionen, die mit „ async def ” statt mit „ def ” definiert sind. Sie können die Ausführung pausieren und wieder aufnehmen, was sie perfekt für Vorgänge macht, bei denen man warten muss.
await: Dieses Schlüsselwort sagt Python: „Halt diese Coroutine an, bis dieser Vorgang fertig ist, aber lass den Rest vom Code weiterlaufen.“
Ereignisschleife: Der Motor, der alle deine Coroutinen verwaltet und entscheidet, welche wann läuft und wann zwischen ihnen gewechselt wird.
Aufgaben: Coroutinen für die gleichzeitige Ausführung verpackt. Du erstellst sie mit „ asyncio.create_task() “, um mehrere Vorgänge gleichzeitig auszuführen.
Um Verwirrung darüber zu vermeiden, was asynchrone Programmierung kann (und was nicht), solltest du Folgendes beachten:
Async funktioniert am besten bei I/O-gebundenen Aufgaben wie HTTP-Anfragen, Datenbankabfragen und Dateioperationen, bei denen dein Code auf externe Systeme wartet.
Async hilft nicht bei CPU-gebundenen Aufgaben wie komplexen Berechnungen oder Datenverarbeitung, bei denen dein Code aktiv rechnet, anstatt zu warten.
Der beste Weg, diese Konzepte zu verstehen, ist, echten asynchronen Code zu schreiben. Im nächsten Abschnitt machst du deine erste asynchrone Funktion und siehst genau, wie Coroutinen und die Ereignisschleife zusammenarbeiten.
Bevor wir uns mit asynchronem Code beschäftigen, schauen wir uns mal eine normale synchrone Funktion an, die wartet, bevor sie was macht:
import time
def greet_after_delay():
print("Starting...")
time.sleep(2) # Blocks for 2 seconds
print("Hello!")
greet_after_delay()Starting...
Hello!Die Funktion läuft, aber „ time.sleep(2)“ blockiert dein ganzes Programm. In diesen zwei Sekunden kann nichts anderes laufen.
Hier ist die asynchrone Version:
import asyncio
async def greet_after_delay():
print("Starting...")
await asyncio.sleep(2) # Pauses, but doesn't block
print("Hello!")
asyncio.run(greet_after_delay())Starting...
Hello!Die Ausgabe sieht gleich aus, aber im Hintergrund läuft was anderes ab. Drei Änderungen haben das hier asynchron gemacht:
async def statt „ def “ wird das hier als Coroutine deklariert.
await asyncio.sleep(2) statt „ time.sleep(2) “ macht eine Pause, ohne zu blockieren.
asyncio.run() Startet die Ereignisschleife und lässt die Coroutine laufen.
Beachte, dass „ asyncio.sleep() ” selbst eine asynchrone Funktion ist, weshalb „ await ” nötig ist. Das ist echt wichtig: Jede asynchrone Funktion muss mit ` await` aufgerufen werden. Egal, ob es sich um eine eingebaute Funktion wie „ asyncio.sleep() ” handelt oder um eine, die du selbst schreibst – wenn du „ await ” vergisst, wird sie nicht ausgeführt.
Im Moment scheint die asynchrone Version nicht schneller zu sein. Das liegt daran, dass wir nur eine Aufgabe haben. Der eigentliche Vorteil zeigt sich, wenn du mehrere Coroutinen gleichzeitig ausführst, was wir im nächsten Abschnitt behandeln werden.
Noch was Wichtiges, das du wissen solltest: Du kannst eine asynchrone Funktion nicht einfach wie eine normale Funktion direkt aufrufen. Probieren wir's mal aus:
result = greet_after_delay()
print(result)
print(type(result))<coroutine object greet_after_delay at 0x...>
<class 'coroutine'>Wenn du „ greet_after_delay() “ aufrufst, kriegst du ein Coroutine-Objekt zurück, nicht das Ergebnis. Die Funktion läuft nicht wirklich. Du brauchst „ asyncio.run() ” oder „ await ”, um es in einer anderen Funktion auszuführen.
Die Ereignisschleife ist der Motor hinter der asynchronen Programmierung. Es kümmert sich um deine Coroutinen und entscheidet, was wann läuft. Hier ist, was Schritt für Schritt passiert, wenn du die asynchrone Funktion „ greet_after_delay() ” ausführst:
asyncio.run() macht eine Ereignisschleife.
Die Ereignisschleife startet greet_after_delay().
„Startet...“ wird gedruckt.
Treffer warten auf asyncio.sleep(2) → Coroutine pausiert.
Event-Loop-Prüfungen: Gibt's noch irgendwelche anderen Aufgaben, die erledigt werden müssen? (Im Moment nicht.)
2 Sekunden vergehen, der Ruhezustand ist vorbei.
Die Ereignisschleife wird fortgesetzt greet_after_delay().
„Hey!“ wird gedruckt.
Funktion beendet → Ereignisschleife wird verlassen.
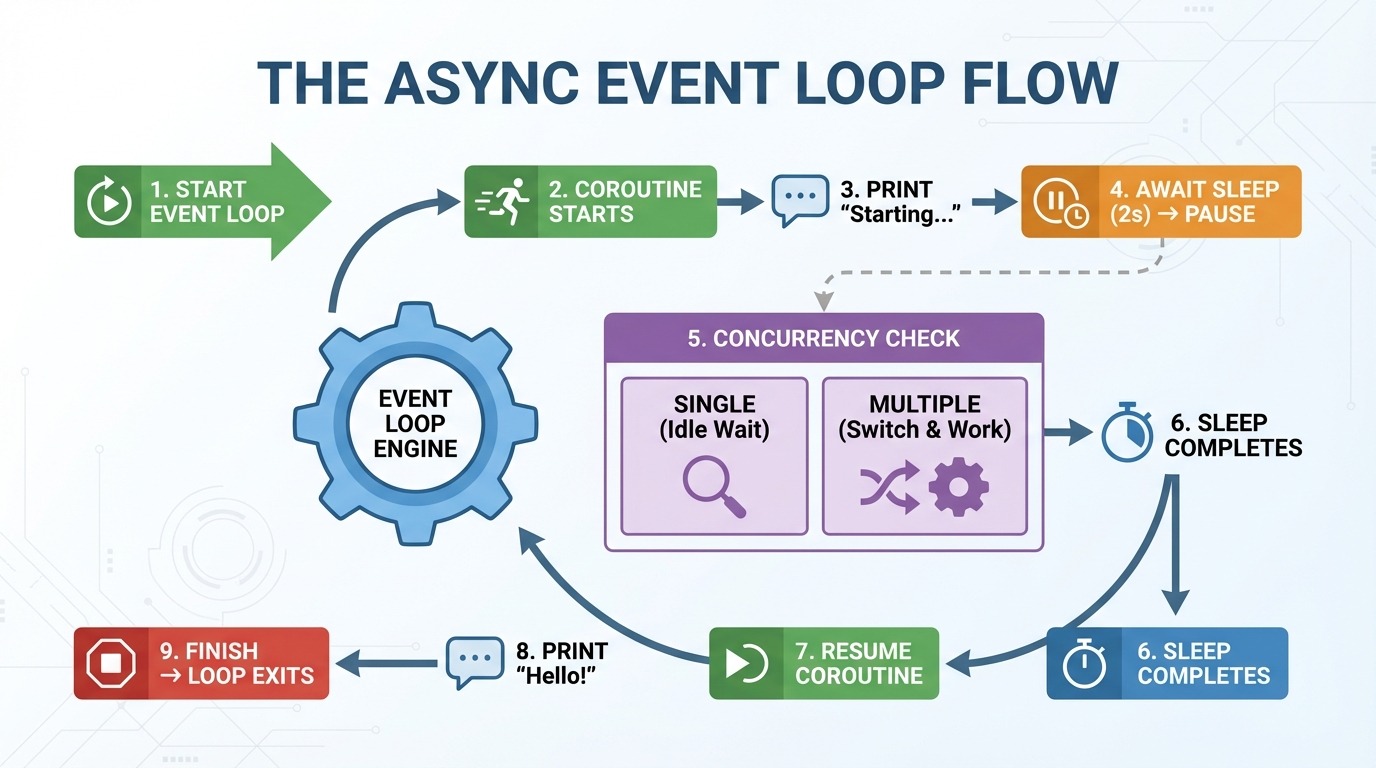
In Schritt 5 wird async interessant. Mit einer Coroutine gibt's sonst nichts zu tun. Aber wenn du mehrere Coroutinen hast, wechselt die Ereignisschleife zu anderen Aufgaben, während eine wartet. Anstatt während eines zweisekündigen Ruhezustands untätig zu sein, kann es anderen Code ausführen.
Stell dir die Ereignisschleife wie einen Verkehrsleiter vor. Es macht einzelne Autos nicht schneller. Es hält den Verkehr am Laufen, indem es andere Autos vorbeifahren lässt, während man selbst stehen bleibt.
Ein häufiger Anfängerfehler ist, beim Aufruf einer Coroutine innerhalb einer anderen asynchronen Funktion das Schlüsselwort ` await ` zu vergessen:
import asyncio
async def get_message():
await asyncio.sleep(1)
return "Hello!"
async def main():
message = get_message() # Missing await!
print(message)
asyncio.run(main())<coroutine object get_message at 0x...>
RuntimeWarning: coroutine 'get_message' was never awaitedOhne „ await “ kriegst du das Coroutine-Objekt statt des Rückgabewerts. Python sagt dir auch, dass die Coroutine nie ausgeführt wurde.
Die Lösung ist einfach:
async def main():
message = await get_message() # Added await
print(message)
asyncio.run(main())Hello!Wenn du eine Fehlermeldung „ RuntimeWarning ” wegen einer unerwarteten Coroutine siehst, check mal, ob du bei jedem asynchronen Funktionsaufruf „ await ” benutzt hast.
Im letzten Abschnitt haben wir eine Sync-Funktion in eine Async-Funktion umgewandelt. Aber es ging nicht schneller. Das liegt daran, dass wir nur eine Coroutine ausgeführt haben. Die wahre Stärke von Async zeigt sich, wenn du mehrere Coroutinen gleichzeitig laufen lässt.
Man könnte meinen, dass mehrere asynchrone Funktionen automatisch gleichzeitig ausgeführt werden, wenn man sie aufruft. Aber schau mal, was passiert, wenn wir dreimal „ greet_after_delay() “ aufrufen:
import asyncio
import time
async def greet_after_delay(name):
print(f"Starting {name}...")
await asyncio.sleep(2)
print(f"Hello, {name}!")
async def main():
start = time.perf_counter()
await greet_after_delay("Alice")
await greet_after_delay("Bob")
await greet_after_delay("Charlie")
elapsed = time.perf_counter() - start
print(f"Total time: {elapsed:.2f} seconds")
asyncio.run(main())Starting Alice...
Hello, Alice!
Starting Bob...
Hello, Bob!
Starting Charlie...
Hello, Charlie!
Total time: 6.01 secondsSechs Sekunden für drei Aufgaben, die jeweils zwei Sekunden dauern. Jedes „ await “ wartet, bis seine Coroutine fertig ist, bevor es zur nächsten Zeile geht. Der Code ist asynchron, läuft aber nacheinander ab.
Um Coroutinen gleichzeitig auszuführen, nimm „ asyncio.gather() “ (Parallelisierung der Ausführung). Es nimmt mehrere Coroutinen und lässt sie gleichzeitig laufen:
async def main():
start = time.perf_counter()
await asyncio.gather(
greet_after_delay("Alice"),
greet_after_delay("Bob"),
greet_after_delay("Charlie"),
)
elapsed = time.perf_counter() - start
print(f"Total time: {elapsed:.2f} seconds")
asyncio.run(main())Starting Alice...
Starting Bob...
Starting Charlie...
Hello, Alice!
Hello, Bob!
Hello, Charlie!
Total time: 2.00 secondsZwei Sekunden statt sechs. Alle drei Coroutinen sind sofort losgelegt, haben gleichzeitig eine Pause gemacht und sind zusammen fertig geworden. Das ist eine 3-fache Beschleunigung mit nur einer Änderung.
Schau dir die Reihenfolge der Ausgabe an: Alle drei „Starting...“-Meldungen werden vor den „Hello...“-Meldungen angezeigt. Das zeigt, dass alle Coroutinen im selben Zwei-Sekunden-Fenster laufen, anstatt aufeinander zu warten.
asyncio.gather() gibt eine Liste mit Ergebnissen in derselben Reihenfolge zurück, in der du die Coroutinen übergeben hast. Wenn deine Coroutinen Werte zurückgeben, kannst du sie erfassen:
async def fetch_number(n):
await asyncio.sleep(1)
return n * 10
async def main():
results = await asyncio.gather(
fetch_number(1),
fetch_number(2),
fetch_number(3),
)
print(results)
asyncio.run(main())[10, 20, 30]Die Ergebnisse kommen in der Reihenfolge [10, 20, 30] zurück, genau wie die Reihenfolge der Coroutinen, die an gather() übergeben wurden.
Bisher haben wir „ asyncio.sleep() “ benutzt, um Verzögerungen zu simulieren. Jetzt machen wir mal echte HTTP-Anfragen. Du könntest nach der Bibliothek „ requests ” suchen, aber die wird hier nicht funktionieren. „ requests ” läuft synchron und blockiert die Ereignisschleife, was den Zweck von „async” zunichte macht.
Benutze stattdessen aiohttp, einen asynchronen HTTP-Client, der genau dafür gemacht ist.
So holst du eine URL mit aiohttp rein:
import aiohttp
import asyncio
async def fetch(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
return await response.text()
async def main():
html = await fetch("https://example.com")
print(f"Fetched {len(html)} characters")
asyncio.run(main())Fetched 513 charactersSchau dir die beiden verschachtelten „ async with “-Blöcke an. Jeder verwaltet eine andere Ressource, und zu verstehen, was sie machen, ist wichtig, um „ aiohttp “ richtig zu nutzen.
Hier ist, was Schritt für Schritt passiert, wenn du Anfragen mit aiohttp machst:
aiohttp.ClientSession() Erstellt einen Verbindungspool (zuerst leer).
session.get(url) schaut nach dem Pool: Gibt's irgendwelche offenen Verbindungen zu diesem Host (dem Server der Website)?
Wenn keine Verbindung da ist, werden eine neue TCP-Verbindung (das grundlegende Protokoll zum Senden von Daten über das Internet) und ein SSL-Handshake (die Verschlüsselungseinrichtung für HTTPS) erstellt.
Wir schicken eine HTTP-Anfrage und warten auf die Antwort-Header.
Das Antwortobjekt behält die Verbindung bei.
await response.text() liest die Körperdaten aus dem Netzwerk.
Ausstieg aus der inneren Schleife von async with: Die Verbindung geht wieder zum Pool zurück (bleibt offen!).
Die nächste Anfrage an denselben Host wird gemacht, wobei die Verbindung aus dem Pool wiederverwendet wird (Schritt 3 wird übersprungen).
Verlass die äußere Schleife von ` async with `: Alle zusammengefassten Verbindungen werden geschlossen.
Schritte 7 und 8 sind die wichtigsten Erkenntnisse. Der Verbindungspool hält die Verbindungen zwischen den Anfragen offen. Wenn du eine weitere Anfrage an denselben Host sendest, wird der TCP- und SSL-Handshake komplett übersprungen.
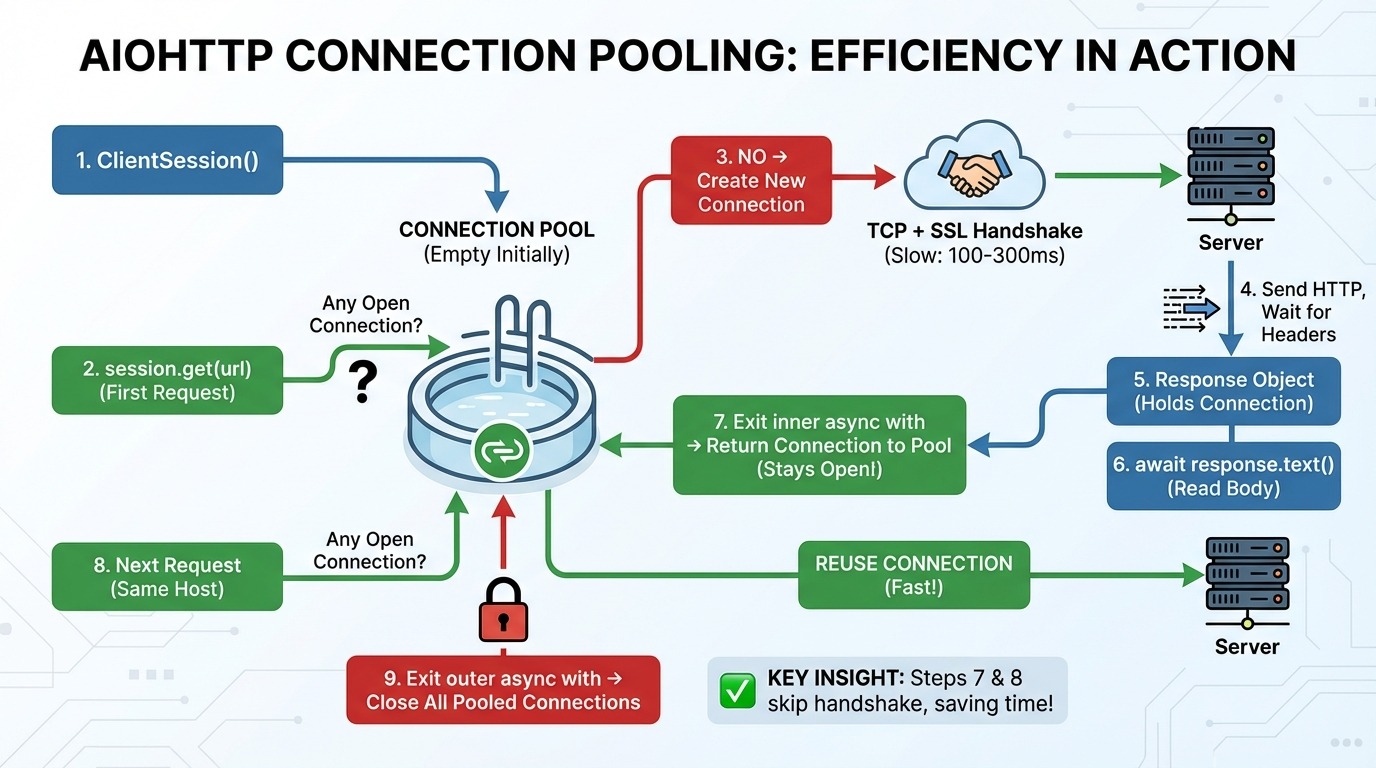
Das ist wichtig, weil das Einrichten einer neuen Verbindung ziemlich langsam ist. Ein TCP-Handshake braucht eine Runde zum Server und zurück. Ein SSL-Handshake braucht noch zwei weitere. Je nach Latenz dauert das 100 bis 300 ms, bevor du überhaupt dein erstes Datenbyte sendest.
Jetzt kannst du sehen, warum es ein Problem ist, für jede Anfrage eine neue Sitzung zu erstellen:
# Wrong: new session for each request
async def fetch_bad(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
return await response.text()
async def main():
urls = ["https://example.com"] * 10
results = await asyncio.gather(*[fetch_bad(url) for url in urls])Jeder Aufruf von „ fetch_bad() “ startet eine neue Sitzung mit einem leeren Pool. Jede Anfrage kostet die vollen Handshake-Kosten, auch wenn sie alle zum selben Host gehen.
Die Lösung ist, eine Sitzung zu erstellen und sie an deine Abruffunktion weiterzugeben:
# Right: reuse a single session
async def fetch_good(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
urls = ["https://example.com"] * 10
async with aiohttp.ClientSession() as session:
results = await asyncio.gather(*[fetch_good(session, url) for url in urls])Bei einer geteilten Sitzung baut die erste Anfrage die Verbindung auf, und die restlichen neun Anfragen nutzen sie einfach wieder. Ein Handschlag statt zehn.
Probieren wir das mal mit der Hacker News API aus. Diese API ist super, um asynchrones Verhalten zu zeigen, weil das Abrufen von Stories mehrere Anfragen braucht. Wenn du noch keine Erfahrung mit REST-APIs in Python hast, schau dir die Python-APIs von „ “ an: Ein Leitfaden zum Erstellen und Verwenden von APIs für grundlegende Konzepte.
Die Struktur der Hacker News API:
https://hacker-news.firebaseio.com/v0/topstories.json gibt eine Liste mit Story-IDs zurück (nur Zahlen)
https://hacker-news.firebaseio.com/v0/item/{id}.json gibt Details zu einer Geschichte zurück
Um 10 Geschichten zu kriegen, brauchst du 11 Anfragen: eine für die ID-Liste und dann eine für jede Geschichte. Genau da zeigt die asynchrone Programmierung ihre Stärken.
Schauen wir mal, was die API zurückgibt, wenn wir versuchen, die erste Story abzurufen:
import aiohttp
import asyncio
HN_API = "https://hacker-news.firebaseio.com/v0"
async def main():
async with aiohttp.ClientSession() as session:
# Get top story IDs
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
print(f"Found {len(story_ids)} stories")
print(f"First 5 IDs: {story_ids[:5]}")
# Fetch first story details
first_id = story_ids[0]
async with session.get(f"{HN_API}/item/{first_id}.json") as response:
story = await response.json()
print(f"\nStory structure:")
for key, value in story.items():
print(f" {key}: {repr(value)[:50]}")
asyncio.run(main())Found 500 stories
First 5 IDs: [46051449, 46055298, 46021577, 46053566, 45984864]
Story structure:
by: 'mikeayles'
descendants: 22
id: 46051449
kids: [46054027, 46053889, 46053275, 46053515, 46053002,
score: 217
text: 'I got DOOM running in KiCad by rendering it with
time: 1764108815
title: 'Show HN: KiDoom – Running DOOM on PCB Traces'
type: 'story'
url: 'https://www.mikeayles.com/#kidoom'Die API gibt 500 Story-IDs zurück, und jede Story hat Felder wie „ title “, „ url “, „ score “ und „ by “ (der Autor).
Jetzt holen wir uns 10 Geschichten nacheinander:
import aiohttp
import asyncio
import time
HN_API = "https://hacker-news.firebaseio.com/v0"
async def fetch_story(session, story_id):
async with session.get(f"{HN_API}/item/{story_id}.json") as response:
return await response.json()
async def main():
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
start = time.perf_counter()
stories = []
for story_id in story_ids[:10]:
story = await fetch_story(session, story_id)
stories.append(story)
elapsed = time.perf_counter() - start
print(f"Sequential: Fetched {len(stories)} stories in {elapsed:.2f} seconds")
asyncio.run(main())Sequential: Fetched 10 stories in 2.41 secondsJetzt holen wir uns die gleichen Geschichten gleichzeitig:
async def main():
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
start = time.perf_counter()
tasks = [fetch_story(session, story_id) for story_id in story_ids[:10]]
stories = await asyncio.gather(*tasks)
elapsed = time.perf_counter() - start
print(f"Concurrent: Fetched {len(stories)} stories in {elapsed:.2f} seconds")
print("\nTop 3 stories:")
for story in stories[:3]:
print(f" - {story.get('title', 'No title')}")
asyncio.run(main())Concurrent: Fetched 10 stories in 0.69 seconds
Top 3 stories:
- Show HN: KiDoom – Running DOOM on PCB Traces
- AWS is 10x slower than a dedicated server for the same price [video]
- Surprisingly, Emacs on Android is pretty goodDie parallele Version ist 3,5-mal schneller. Anstatt zu warten, bis jede Anfrage fertig ist, bevor die nächste gestartet wird, laufen alle 10 Anfragen gleichzeitig. Hier zeigt sich, wie sich asynchrone Programmierung bei echten Netzwerk-E/A-Vorgängen auszahlt.
Beim gleichzeitigen Abrufen von Daten kann einiges schiefgehen. Du könntest den Server mit zu vielen Anfragen überlasten. Manche Anfragen können ewig hängen bleiben. Andere könnten komplett scheitern. Und wenn es mal nicht so läuft, brauchst du einen Plan, wie du das wieder hinbekommst.
In diesem Abschnitt werden alle Punkte in der Reihenfolge durchgegangen, in der sie auftreten: Kontrollieren, wie viele Anfragen rausgehen, Zeitlimits setzen, Fehler behandeln und Wiederholungen durchführen, wenn es sinnvoll ist. Wenn du eine Auffrischung der Grundlagen der Ausnahmebehandlung in Python brauchst, schau dir „Ausnahme- und Fehlerbehandlung in Python” an. Wir werden diese Grundkonfiguration durchgehend verwenden:
import aiohttp
import asyncio
import time
HN_API = "https://hacker-news.firebaseio.com/v0"
async def fetch_story(session, story_id):
async with session.get(f"{HN_API}/item/{story_id}.json") as response:
return await response.json()Im letzten Abschnitt haben wir 10 Anfragen auf einmal abgeschickt. Das hat super geklappt. Aber was passiert, wenn du 500 Geschichten abrufen musst? Oder 10.000 Seiten durchforsten?
Die meisten APIs haben Geschwindigkeitsbegrenzungen. Sie könnten 10 Anfragen pro Sekunde oder 100 gleichzeitige Verbindungen zulassen. Wenn du diese Grenzen überschreitest, wirst du gesperrt, gedrosselt oder gebannt. Auch wenn die API keine Beschränkungen hat, kann das gleichzeitige Senden von Tausenden von Anfragen dein eigenes System oder den Server überlasten.
Du musst irgendwie kontrollieren können, wie viele Anfragen gerade „in der Warteschlange“ sind. Das macht ein Semaphor.
Ein Semaphor ist wie ein Genehmigungssystem. Stell dir vor, du hast drei Genehmigungen. Jede Aufgabe, die eine Anfrage stellen will, muss erst mal eine Genehmigung einholen. Wenn es fertig ist, gibt es die Berechtigung zurück, sodass sie für eine neue Anfrage genutzt werden kann. Wenn keine Lizenzen verfügbar sind, wartet die Aufgabe, bis eine frei wird.
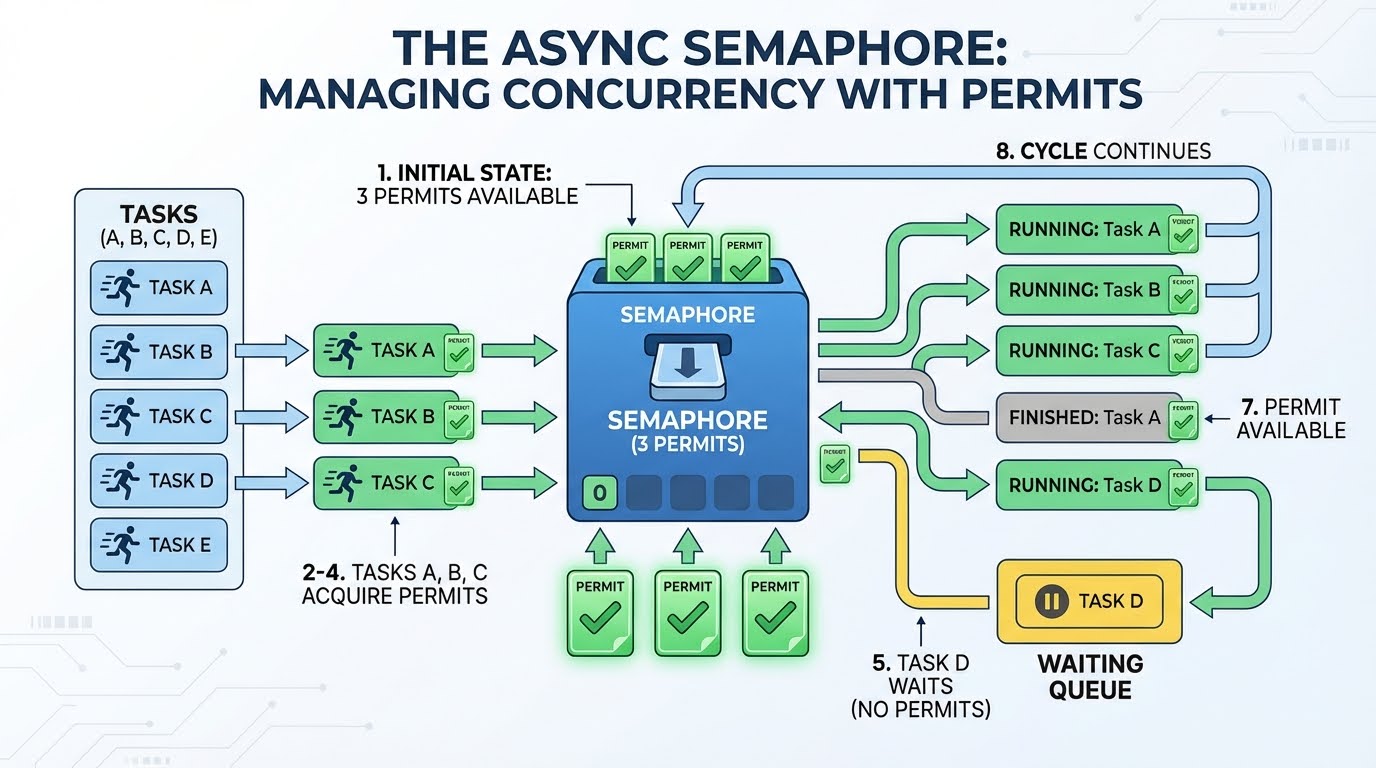
So läuft's mit 3 Genehmigungen und 4 oder mehr Aufgaben ab:
Es gibt drei Genehmigungen.
Aufgabe A braucht eine Genehmigung (noch 2 übrig) und fängt mit der Anfrage an.
Aufgabe B braucht eine Genehmigung (noch 1 übrig) und fängt mit der Anfrage an.
Aufgabe C braucht eine Genehmigung (noch 0 übrig) und fängt mit der Anfrage an.
Aufgabe D braucht eine Genehmigung, aber es gibt keine – sie wartet.
Aufgabe A ist fertig und gibt die Genehmigung zurück (1 verfügbar).
Aufgabe D nimmt diese Erlaubnis und startet ihre Anfrage.
Das geht so weiter, bis alle Aufgaben erledigt sind.
Das Warten in Schritt 5 ist echt effizient. Die Aufgabe dreht sich nicht in einer Schleife und fragt ständig: „Ist die Genehmigung schon da?“ Es hält den Code an und lässt anderen Code laufen. Die Ereignisschleife weckt es nur, wenn eine Berechtigung verfügbar wird.
Schauen wir uns jetzt den Code an. In asyncio machst du einen Semaphor mit ` asyncio.Semaphore(n)`, wobei ` n ` die Anzahl der Berechtigungen ist. Um es zu benutzen, pack deinen Code in async with semaphore: ein. Das holt sich beim Betreten des Blocks eine Berechtigung und gibt sie beim Verlassen automatisch wieder frei:
async def fetch_story_limited(session, story_id, semaphore):
async with semaphore: # Acquire permit (or wait if none available)
async with session.get(f"{HN_API}/item/{story_id}.json") as response:
return await response.json()
# Permit automatically released hereVergleichen wir mal das Abrufen von 30 Stories mit und ohne Semaphor:
async def main():
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = (await response.json())[:30]
# Without rate limiting: all 30 at once
start = time.perf_counter()
await asyncio.gather(*[fetch_story(session, sid) for sid in story_ids])
print(f"No limit: {time.perf_counter() - start:.2f}s (30 concurrent)")
# With Semaphore(5): max 5 at a time
semaphore = asyncio.Semaphore(5)
start = time.perf_counter()
await asyncio.gather(*[fetch_story_limited(session, sid, semaphore) for sid in story_ids])
print(f"Semaphore(5): {time.perf_counter() - start:.2f}s (5 concurrent)")
asyncio.run(main())No limit: 0.62s (30 concurrent)
Semaphore(5): 1.50s (5 concurrent)Die Semaphor-Version ist langsamer, weil sie Anfragen in Fünfergruppen verarbeitet. Aber das ist der Kompromiss: Du gibst Geschwindigkeit auf, um ein vorhersehbares, serverfreundliches Verhalten zu bekommen.
Eins ist wichtig: Ein Semaphor begrenzt die Anzahl der gleichzeitigen Anfragen, nicht die Anfragen pro Zeiteinheit. „ Semaphore(10) ” heißt „maximal 10 Anfragen gleichzeitig”, nicht „10 Anfragen pro Sekunde”. Wenn du eine strenge zeitbasierte Ratenbegrenzung brauchst (z. B. genau 10 Anfragen pro Sekunde), kannst du ein Semaphor mit Verzögerungen zwischen den Batches kombinieren oder eine Bibliothek wie aiolimiter verwenden.
Auch bei kontrollierter Parallelität können einzelne Anfragen hängen bleiben. Ein Server könnte deine Verbindung annehmen, aber nie antworten. Ohne eine Zeitüberschreitung wartet dein Programm ewig.
Die Funktion „ asyncio.wait_for() “ packt jede Coroutine mit einer Deadline ein. Du gibst ihm die Coroutine und eine „ timeout “ in Sekunden. Wenn der Vorgang nicht rechtzeitig fertig wird, wird die Fehlermeldung „ asyncio.TimeoutError ” angezeigt:
async def slow_operation():
print("Starting slow operation...")
await asyncio.sleep(5)
return "Done"
async def main():
try:
result = await asyncio.wait_for(slow_operation(), timeout=2.0)
print(f"Success: {result}")
except asyncio.TimeoutError:
print("Operation timed out after 2 seconds")
asyncio.run(main())Starting slow operation...
Operation timed out after 2 secondsWenn die Zeitüberschreitung passiert, bricht „ wait_for() “ die Coroutine ab. Du kannst „ TimeoutError “ abfangen und entscheiden, was zu tun ist: die Anfrage überspringen, einen Standardwert zurückgeben oder es erneut versuchen.
Bei mehreren Anfragen gleichzeitig solltest du jede einzeln einpacken. Hier ist ein Helfer, der ein Fehlerwörterbuch zurückgibt, anstatt einen Fehler auszulösen:
async def fetch_story_with_timeout(session, story_id, timeout=5.0):
try:
coro = fetch_story(session, story_id)
return await asyncio.wait_for(coro, timeout=timeout)
except asyncio.TimeoutError:
return {"error": f"Story {story_id} timed out"}Wenn eine Coroutine abgebrochen wird (wegen Zeitüberschreitung oder aus einem anderen Grund), löst Python darin einen Fehler „ asyncio.CancelledError “ aus. Wenn deine Coroutine Ressourcen wie Datei-Handles oder Verbindungen hat, benutze try/finally, um sicherzustellen, dass die Bereinigung auch bei einer Stornierung passiert:
async def fetch_with_cleanup(session, url):
print("Starting fetch...")
try:
async with session.get(url) as response:
return await response.text()
finally:
print("Cleanup complete") # Runs even on cancellationTimeouts fangen langsame Anfragen ab. Aber manche Anfragen schlagen sofort mit einem Fehler fehl. Mal sehen, was passiert, wenn eine Anfrage in einem Stapel nicht klappt.
Zuerst brauchen wir eine Version von „ fetch_story() “, die bei ungültigen IDs eine Ausnahme auslöst:
async def fetch_story_strict(session, story_id):
story = await fetch_story(session, story_id)
if story is None:
raise ValueError(f"Story not found: {story_id}")
return storyJetzt holen wir uns vier gültige Geschichten und eine ungültige ID:
async def main():
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
ids_to_fetch = story_ids[:4] + [99999999999] # 4 valid + 1 invalid
try:
stories = await asyncio.gather(
*[fetch_story_strict(session, sid) for sid in ids_to_fetch]
)
print(f"Got {len(stories)} stories")
except ValueError as e:
print(f"ERROR: {e}")
asyncio.run(main())ERROR: Story not found: 99999999999Mit einer ungültigen ID verlieren wir alle vier erfolgreichen Ergebnisse. Standardmäßig nutzt „ gather() “ das Fail-Fast-Verhalten: Eine Ausnahme bricht alles ab und wird weitergeleitet.
Um Teilergebnisse zu behalten, füge return_exceptions=True hinzu. Das ändert das Verhalten von ` gather()`: Anstatt Ausnahmen auszulösen, gibt es sie jetzt als Elemente in der Ergebnisliste zusammen mit den erfolgreichen Werten zurück:
async def main():
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
ids_to_fetch = story_ids[:4] + [99999999999]
results = await asyncio.gather(
*[fetch_story_strict(session, sid) for sid in ids_to_fetch],
return_exceptions=True # Don't raise, return exceptions in list
)
# Separate successes from failures using isinstance()
stories = [r for r in results if not isinstance(r, Exception)]
errors = [r for r in results if isinstance(r, Exception)]
print(f"Got {len(stories)} stories, {len(errors)} failed")
asyncio.run(main())Got 4 stories, 1 failedMit der Funktion „ isinstance(result, Exception) “ kannst du erfolgreiche Ergebnisse von Fehlern trennen. Du kannst dann die erfolgreichen Vorgänge bearbeiten und die fehlgeschlagenen Vorgänge protokollieren oder erneut versuchen.
Manche Probleme sind nur vorübergehend. Ein Server kann kurzzeitig überlastet sein oder eine Netzwerkstörung kann deine Verbindung unterbrechen. In diesen Fällen ist ein erneuter Versuch sinnvoll.
Aber wenn du es sofort nochmal versuchst, kann das alles noch schlimmer machen. Wenn ein Server Probleme hat, macht es die Sache nur noch schlimmer, wenn man ihn mit wiederholten Versuchen bombardiert. Exponentielles Backoff löst das, indem es zwischen den einzelnen Versuchen länger wartet.
Das Muster nutzt „ 2 ** attempt “, um Wartezeiten zu berechnen: Versuch 0 wartet eine Sekunde (2⁰), Versuch 1 wartet zwei Sekunden (2¹), Versuch 2 wartet vier Sekunden (2²) und so weiter. Dadurch hat der Server immer mehr Zeit, sich zu erholen:
async def fetch_with_retry(session, story_id, max_retries=3):
for attempt in range(max_retries):
try:
story = await fetch_story(session, story_id)
if story is None:
raise ValueError(f"Story {story_id} not found")
return story
except (aiohttp.ClientError, ValueError): # Catch specific exceptions
if attempt == max_retries - 1:
print(f"Story {story_id}: Failed after {max_retries} attempts")
return None
backoff = 2 ** attempt # 1s, 2s, 4s...
print(f"Story {story_id}: Attempt {attempt + 1} failed, retrying in {backoff}s...")
await asyncio.sleep(backoff)Beachte, dass wir bestimmte Ausnahmen abfangen (aiohttp.ClientError, ValueError) und nicht einfach nur except. So stellen wir sicher, dass wir nur bei Fehlern, die vielleicht nur vorübergehend sind, einen erneuten Versuch starten. Ein Fehler „ KeyError ” wegen fehlerhaftem Code sollte keine Wiederholungsversuche auslösen.
Probieren wir's mal mit einer Mischung aus gültigen und ungültigen IDs aus:
async def main():
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
test_ids = [story_ids[0], 99999999999, story_ids[1], 88888888888, story_ids[2]]
results = await asyncio.gather(*[fetch_with_retry(session, sid) for sid in test_ids])
successful = [r for r in results if r is not None]
print(f"\nSuccessful: {len(successful)}, Failed: {len(test_ids) - len(successful)}")
asyncio.run(main())Story 99999999999: Attempt 1 failed, retrying in 1s...
Story 88888888888: Attempt 1 failed, retrying in 1s...
Story 99999999999: Attempt 2 failed, retrying in 2s...
Story 88888888888: Attempt 2 failed, retrying in 2s...
Story 99999999999: Failed after 3 attempts
Story 88888888888: Failed after 3 attempts
Successful: 3, Failed: 2In der Produktion würdest du auch Jitter (kleine zufällige Verzögerungen) hinzufügen, um zu verhindern, dass mehrere fehlgeschlagene Anfragen genau im selben Moment erneut versucht werden. Außerdem würdest du nur vorübergehende Fehler (serverseitige Netzwerkprobleme, wie z. B. 503) erneut versuchen, während du bei dauerhaften Fehlern (z. B. 404 oder 401) sofort aufgeben würdest.
Wir haben Hacker News-Artikel mit der richtigen Ratenbegrenzung, Zeitüberschreitungen und Fehlerbehandlung geholt. Jetzt speichern wir sie in einer Datenbank.
Wenn man eine normale synchrone Datenbankbibliothek wie sqlite3benutzt, wird die Ereignisschleife während der Abfragen blockiert, was den Sinn der asynchronen Programmierung zunichte macht. Während dein Code auf die Datenbank wartet, können keine anderen Coroutinen laufen. Für asynchrone Anwendungen brauchst du eine asynchrone Datenbankbibliothek.
aiosqlite verpackt die in Python eingebaute Funktion „ sqlite3 “ in eine asynchrone Schnittstelle. Es führt Datenbankoperationen in einem Thread-Pool aus, damit sie die Ereignisschleife nicht blockieren. SQLite braucht keinen Server – es ist einfach nur eine Datei –, also kannst du diesen Code sofort ausführen. Wenn du noch keine Erfahrung mit Datenbanken in Python hast, dann ist der Kurs „Einführung in Datenbanken in Python“ genau das Richtige für dich. Er behandelt die Grundlagen, auf denen „ aiosqlite “ aufbaut.
Das Muster sollte dir bekannt vorkommen. Genau wie bei aiohttp.ClientSession kannst du async with nutzen, um die Verbindung zu verwalten:
import aiosqlite
async def init_db(db_path):
async with aiosqlite.connect(db_path) as db:
await db.execute("""
CREATE TABLE IF NOT EXISTS stories (
id INTEGER PRIMARY KEY,
title TEXT,
url TEXT,
score INTEGER,
fetched_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
""")
await db.commit()
asyncio.run(init_db("stories.db"))Die wichtigsten Funktionen:
aiosqlite.connect(path) öffnet (oder erstellt) eine Datenbankdatei.
await db.execute(sql) führt eine SQL-Anweisung aus.
await db.commit() Speichert die Änderungen auf der Festplatte.
Hier ist eine Funktion zum Speichern einer einzelnen Story:
async def save_story(db, story):
await db.execute(
"INSERT OR REPLACE INTO stories (id, title, url, score) VALUES (?, ?, ?, ?)",
(story["id"], story.get("title", ""), story.get("url", ""), story.get("score", 0))
)Die Platzhalter „ ? “ verhindern SQL-Injection – benutze niemals f-Strings, um Werte in SQL einzufügen. „ INSERT OR REPLACE “ aktualisiert vorhandene Stories, wenn wir sie erneut abrufen.
Jetzt packen wir alles aus diesem Tutorial zusammen und machen eine komplette Pipeline. Wir holen 20 Hacker News-Artikel mit Ratenbegrenzung und speichern sie in einer Datenbank:
import aiohttp
import aiosqlite
import asyncio
HN_API = "https://hacker-news.firebaseio.com/v0"
async def fetch_story(session, story_id):
async with session.get(f"{HN_API}/item/{story_id}.json") as response:
return await response.json()
async def fetch_story_limited(session, story_id, semaphore):
async with semaphore:
story = await fetch_story(session, story_id)
if story:
return story
return None
async def save_story(db, story):
await db.execute(
"INSERT OR REPLACE INTO stories (id, title, url, score) VALUES (?, ?, ?, ?)",
(story["id"], story.get("title", ""), story.get("url", ""), story.get("score", 0))
)
async def main():
# Initialize database
async with aiosqlite.connect("hn_stories.db") as db:
await db.execute("""
CREATE TABLE IF NOT EXISTS stories (
id INTEGER PRIMARY KEY,
title TEXT,
url TEXT,
score INTEGER,
fetched_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
""")
# Fetch stories
async with aiohttp.ClientSession() as session:
async with session.get(f"{HN_API}/topstories.json") as response:
story_ids = await response.json()
semaphore = asyncio.Semaphore(5)
tasks = [fetch_story_limited(session, sid, semaphore) for sid in story_ids[:20]]
stories = await asyncio.gather(*tasks)
# Save to database
for story in stories:
if story:
await save_story(db, story)
await db.commit()
# Query and display
cursor = await db.execute("SELECT id, title, score FROM stories ORDER BY score DESC LIMIT 5")
rows = await cursor.fetchall()
print(f"Saved {len([s for s in stories if s])} stories. Top 5 by score:")
for row in rows:
print(f" [{row[2]}] {row[1][:50]}")
asyncio.run(main())Saved 20 stories. Top 5 by score:
[671] Google Antigravity exfiltrates data via indirect p
[453] Trillions spent and big software projects are stil
[319] Ilya Sutskever: We're moving from the age of scali
[311] Show HN: We built an open source, zero webhooks pa
[306] FLUX.2: Frontier Visual IntelligenceDie Pipeline nutzt Muster aus allen Bereichen: ClientSession für Connection Pooling, Semaphore(5) für Rate Limiting, gather() für Concurrent Fetching und jetzt aiosqlite für Async Storage. Jede Komponente macht ihren Teil, ohne die anderen aufzuhalten.
Jedes Mal, wenn du diesen Workflow startest, bekommst du die Top-Nachrichten des Tages.
Dieses Tutorial hat dir gezeigt, wie du von der grundlegenden Syntax von async/await zu einer kompletten Datenpipeline kommst. Du hast gelernt, wie Coroutinen pausieren und wieder starten, wie die Ereignisschleife gleichzeitige Aufgaben verwaltet und wie „ asyncio.gather() “ mehrere Vorgänge gleichzeitig ausführt. Du hast echte HTTP-Anfragen mit ` aiohttp` hinzugefügt, die Parallelität mit Semaphoren geregelt, Fehler mit Timeouts und Wiederholungsversuchen abgewickelt und die Ergebnisse in einer Datenbank mit ` aiosqlite` gespeichert.
Benutz async, wenn dein Code auf externe Systeme wartet: HTTP-APIs, Datenbanken, Datei-I/O oder Netzwerk-Sockets. Für CPU-intensive Aufgaben wie Datenverarbeitung oder Zahlenkalkulation hilft Async nicht weiter – schau dir stattdessen multiprocessing oder concurrent.futures an. Wenn du noch mehr wissen willst, kannst du dir die asyncio-Dokumentation anschauen und FastAPI für die Erstellung von asynchronen Web-APIs in Betracht ziehen.
Wenn du auf diesem Wissen aufbauen und lernen möchtest, intelligente Anwendungen zu entwickeln, solltest du dir unbedingt den Lernpfad „Associate AI Engineer for Developers” anschauen.
Python-Kurse
Lernpfad
Kurs
Kurs
Tutorial
Mark Pedigo
Tutorial
Kurtis Pykes
Tutorial
Moez Ali
Tutorial
Satyabrata Pal
Tutorial
Sejal Jaiswal
Tutorial
Matt Crabtree