Curso
Introducción a SQL Server
4 h
170.3K
Las consultas SQL pueden hacer mucho más que recuperar o manipular datos. SQL tiene muchas funciones que nos permiten realizar análisis avanzados que pueden ser cruciales en nuestros informes de inteligencia empresarial.
Una de estas potentes funciones es la función LAG(), que es una de las funciones de ventana más utilizadas. Abre la puerta a comparar y calcular el cambio de valores a lo largo de una secuencia de datos. Por eso las funciones pueden ser cruciales, especialmente para el análisis de series temporales en SQL.
La función LAG() es una de las funciones de ventana de SQL que te permite crear una nueva columna que accede a una fila anterior de otra columna. Recibe su nombre del hecho de que cada fila de la nueva columna que crees se retrasaría para obtener un valor de una fila anterior de la otra columna que especifiques.
Veamos la sintaxis básica en acción. Supongamos que tenemos una simple tabla de dos columnas con las cotizaciones diarias de las acciones que tiene este aspecto:
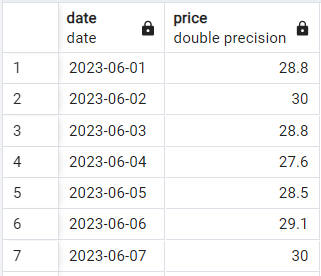
Muestra de datos de cotizaciones bursátiles. Imagen del autor.
Podemos utilizar la siguiente consulta para crear una nueva columna que obtenga el precio del día anterior en cada fila con la siguiente consulta:
SELECT date,
price,
LAG(price) OVER(ORDER BY date) AS one_day_before
FROM stock_price;Y tendríamos el siguiente resultado
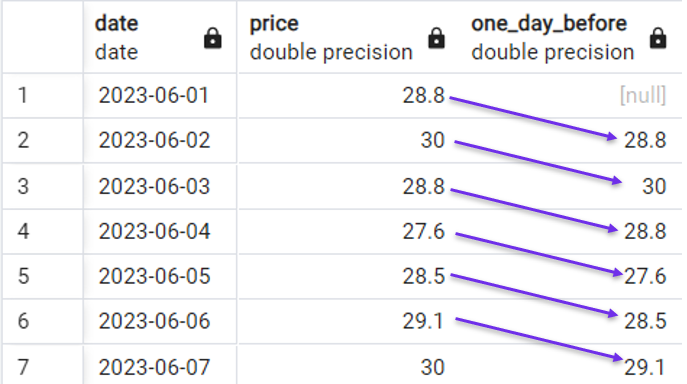
Ejemplo rápido de utilización de la función LAG(). Imagen del autor.
Observa que hemos introducido un valor [null] porque no hay valor del día anterior para la primera fila.
La función LAG() se escribe como parte de la cláusula SELECT. En su sintaxis más básica, la función puede escribirse así:
LAG(column1) OVER(ORDER BY column2)Aquí tienes la misma función LAG() aplicada en una consulta independiente:
SELECT
column1,
column2,
LAG(column1) OVER (ORDER BY column2) AS previous_value
FROM
table_name;Como puedes ver, la sintaxis básica consta de varias partes. Vamos a desglosarlos juntos:
OVER() es una palabra clave obligatoria para todas las funciones de ventana. La cláusula define el marco sobre el que se ejecutará la función ventana. En el ejemplo anterior, la función ventana se ejecutará sobre la ordenada column2.ORDER BY no es obligatorio, pero es muy recomendable cuando se utiliza con la función LAG(); normalmente, la función no tiene sentido sin ella. LAG(). Se puede utilizar más de una columna como base para la clasificación.Quizá te preguntes qué tiene de bueno la función LAG(). Pues bien, la respuesta es que la nueva columna de retraso puede utilizarse para comparar valores de dos filas diferentes.
Por eso se suele utilizar la función LAG() con datos de series temporales. Por ejemplo, en nuestro conjunto de datos de demostración, podemos calcular fácilmente la variación diaria del precio de las acciones con la siguiente consulta:
SELECT date,
price,
LAG(price) OVER(ORDER BY date) AS one_day_before,
price - LAG(price) OVER(ORDER BY date) AS daily_change
FROM stock_price; 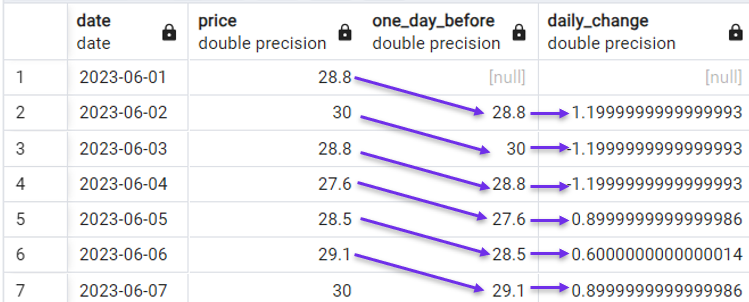
Calcular el cambio diario con LAG(). Imagen del autor.
También podemos pasar a un cálculo más sofisticado y considerar en su lugar las variaciones porcentuales diarias.
SELECT date,
price,
LAG(price) OVER(ORDER BY date) AS one_day_before,
price - LAG(price) OVER(ORDER BY date) AS daily_change,
((price - LAG(price) OVER(ORDER BY date))*100 /
(LAG(price) OVER(ORDER BY date))) AS daily_perc_change
FROM stock_price; 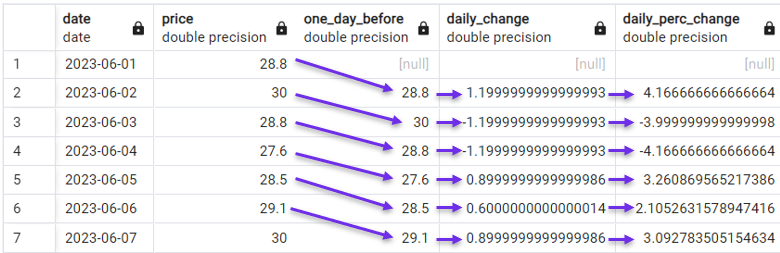
Calcular el cambio porcentual diario con LAG(). Imagen del autor.
Ahora que ya conocemos el uso básico de la función LAG(), vamos a subir de nivel paso a paso y ver qué más podemos hacer con ella.
Aquí pasaremos a otro conjunto de datos de demostración que registra los ingresos mensuales de tres empresas imaginarias: Welsh LLC, Jones Group y Green-Keebler, desde principios de 2022 hasta mediados de 2024. Así se estructuran los datos:
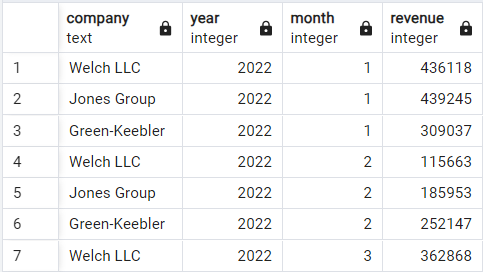
Conjunto de datos de ingresos de demostración. Imagen del autor.
En nuestro nuevo conjunto de datos, la columna de retraso debe ordenarse en función de dos columnas: year y month. Como hemos dicho antes, esto puede hacerse dando las dos columnas a la cláusula ORDER BY.
En la siguiente consulta creamos una columna de retraso y una columna de diferencia de ingresos mes a mes (MoM), ordenadas según year y month. También filtramos nuestra consulta con una cláusula WHERE para centrarnos por ahora en una sola empresa.
SELECT *,
LAG(revenue) OVER(ORDER BY year, month) AS one_month_before,
revenue - LAG(revenue) OVER(ORDER BY year, month) AS mom_difference
FROM revenues
WHERE company = 'Welch LLC'; 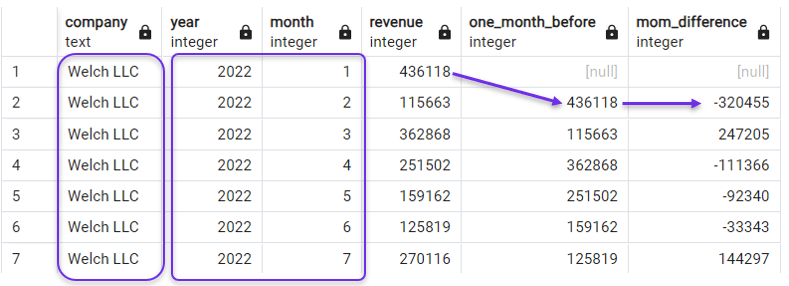
Ordenar por año y mes para LAG(). Imagen del autor.
Supongamos que queremos calcular las mismas dos columnas para las tres empresas que tenemos en nuestro conjunto de datos. Si las calculamos de la misma forma que hemos venido utilizando hasta ahora la función LAG(), la columna de desfase recorrería las tres empresas, y la columna de diferencia se mezclaría entre los ingresos de todas ellas, y eso no es lo que queremos.
Lo que queremos es obtener los ingresos del mes anterior, y calcular la diferencia MoM para cada empresa sola, y luego volver a empezar para la nueva empresa.
Para ello, introducimos una nueva cláusula en nuestra sintaxis de la función LAG(). Esa cláusula es PARTITION BY, y puede añadirse a nuestra sintaxis básica del siguiente modo:
LAG(column1) OVER(PARTITION BY column3 ORDER BY column2)La columna por la que tenemos que particionar en nuestro ejemplo es company. Por tanto, modificaremos nuestra consulta anterior añadiendo la cláusula PARTITION BY y eliminando la sentencia WHERE.
SELECT *,
LAG(revenue) OVER(PARTITION BY company ORDER BY year, month) AS one_month_before,
revenue - LAG(revenue) OVER(PARTITION BY company ORDER BY year, month) AS mom_difference
FROM revenues;En el resultado, veríamos que las columnas de retraso y MoM ahora recorren sólo los ingresos mensuales de la primera empresa, y luego vuelven a empezar para la siguiente. Podemos verlo en la siguiente captura de pantalla, que muestra los últimos meses de Green-Keebler y los primeros de Jones Group.
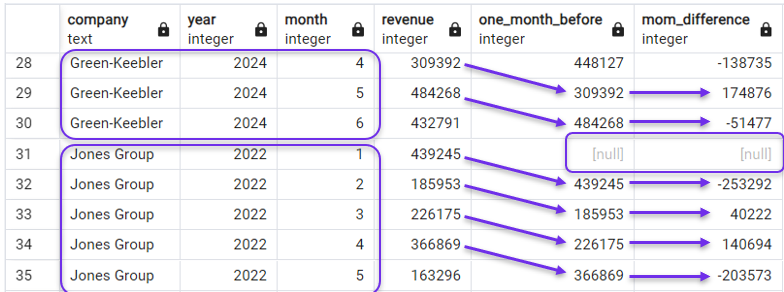
Utilizar PARTITION BY con LAG(). Imagen del autor.
¿Y si no necesitamos obtener el valor de la fila anterior, sino de seis filas o doce filas más arriba? En otras palabras, ¿qué ocurre si tenemos que calcular la diferencia interanual en lugar de la intermensual?
En este caso, añadiríamos un nuevo parámetro a la sintaxis de la función LAG(). Este parámetro se llama desplazamiento, y especifica de cuántas filas por encima de la fila actual queremos que obtenga el valor la función LAG(). Su posición en la sintaxis se muestra a continuación:
LAG(column1, offset) OVER(PARTITION BY column3 ORDER BY column2)Por defecto, y por la forma en que hemos utilizado la función hasta ahora, el valor del desplazamiento es igual a uno. Sin embargo, especificando explícitamente el desplazamiento en la expresión LAG(), podemos cambiar este parámetro por defecto.
Volviendo a nuestro ejemplo, para obtener la variación interanual de los ingresos, tenemos que obtener los ingresos del mismo mes del año anterior. Podemos hacerlo con la siguiente consulta, en la que especificamos 12 como nuestro desplazamiento:
SELECT *,
LAG(revenue, 12) OVER(PARTITION BY company ORDER BY year, month) AS one_year_before,
revenue - LAG(revenue, 12) OVER(PARTITION BY company ORDER BY year, month) AS yoy_difference
FROM revenues;Y el resultado sería
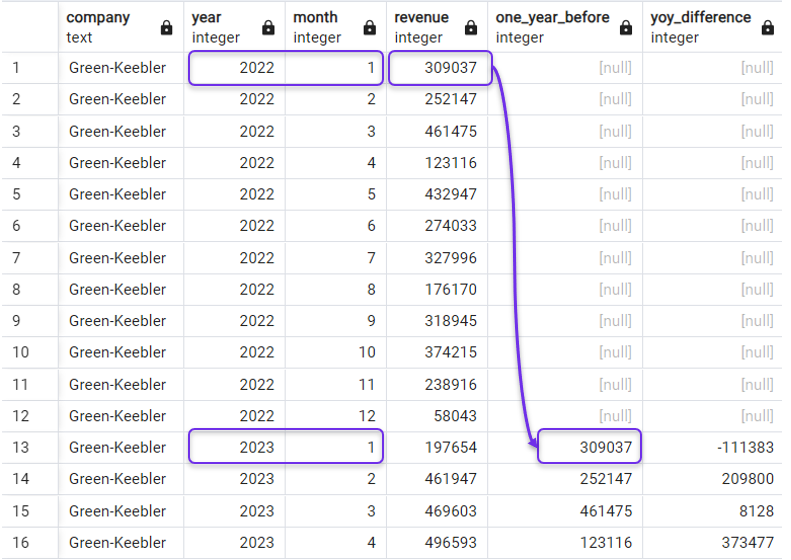
Diferencia interanual con LAG(). Imagen del autor.
Habrás observado que la función LAG() devuelve NULL en las filas en las que no se dispone de periodos anteriores, como en las filas del año 2022 de nuestra consulta anterior.
Éste es el comportamiento por defecto de la función LAG(), pero puede modificarse especificando explícitamente un nuevo parámetro llamado "por defecto". Este parámetro puede tomar cualquier valor numérico entero o flotante. En la sintaxis de la función, el parámetro se coloca de la siguiente manera:
LAG(column1, offset, default) OVER(PARTITION BY column3 ORDER BY column2)El caso de uso habitual del parámetro "por defecto" es cuando los valores parten realmente de cero en los datos de la serie temporal.
En nuestro ejemplo, podemos suponer que las tres empresas se fundaron en enero de 2022 (la fecha más temprana de nuestro conjunto de datos), por lo que podemos considerar que los ingresos anteriores a la fundación son cero. Al hacerlo, calcularemos con más precisión el cambio en los ingresos, ya que cualquier ingreso obtenido en los primeros meses sería un cambio positivo.
En nuestra consulta, especificaremos cero como parámetro "por defecto" en nuestras dos expresiones LAG() de la siguiente manera:
SELECT *,
LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS one_year_before,
revenue - LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS yoy_difference
FROM revenues;Y el resultado arrojaría ceros en la columna de retardo, y los ingresos netos de cero en la columna de variación interanual de ingresos:
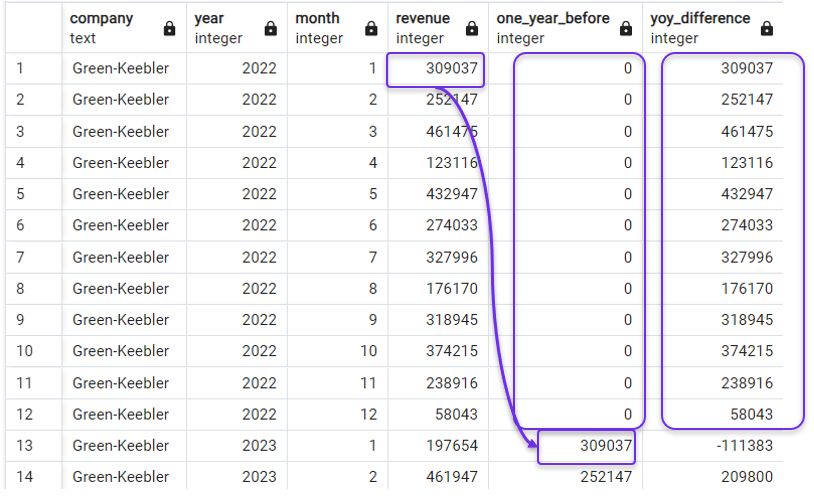
Sustitución de NULL por ceros en LAG(). Imagen del autor.
Ten en cuenta que para poder especificar explícitamente un valor para el parámetro "por defecto", es obligatorio especificar también explícitamente un valor para el desplazamiento, ya que el primer número dado después del nombre de la columna dentro de la función LAG() se tomará como desplazamiento de todos modos.
Si necesitas cambiar el "valor por defecto" pero no el desplazamiento, establece el parámetro desplazamiento como uno, y se comportará como lo hace normalmente.
Es útil saber que el orden del que depende la función LAG() no tiene por qué ser el mismo orden de la vista resultante. Siempre puedes cambiar ese orden utilizando normalmente la cláusula ORDER BY en tu consulta.
En nuestro ejemplo, podemos reordenar nuestro resultado para que muestre el mismo mes del mismo año para las tres empresas antes de pasar al siguiente mes del año, ordenando la consulta según el año y el mes en la cláusula externa ORDER BY:
SELECT *,
LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS one_year_before,
revenue - LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS yoy_difference
FROM revenues
ORDER BY year, month;Y tendríamos lo que necesitamos:
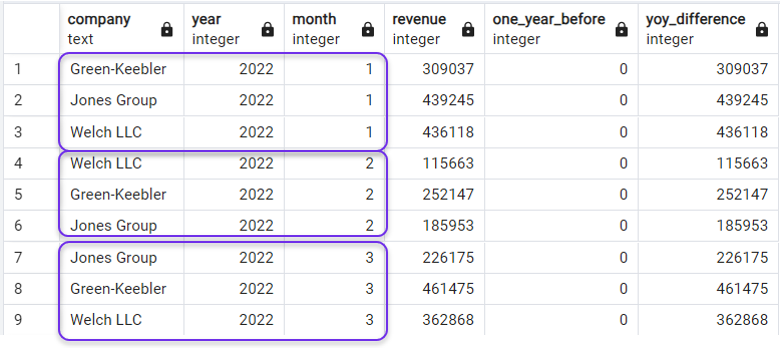
Ordenar la consulta después de LAG(). Imagen del autor.
Echemos un vistazo a los problemas más comunes, por si necesitas ayuda para solucionarlos.
ORDER BY en la declaración LAG() puede dar lugar a resultados incorrectos. Aunque el orden original de la tabla de origen sea adecuado para la función, nunca dependas de ese orden original, ya que puede cambiar con el tiempo.ORDER BY en la declaración LAG(), y asegúrate de ordenar por la columna correcta.LAG() incorrecto por pasar por alto el uso de la cláusula PARTITION BY o utilizarla con la columna equivocada. LAG().NULL en la salida de la función LAG() cuando es más adecuado otro valor, al no declarar el parámetro "por defecto".LAG() en más de una columna, tendrías que escribir la sentencia LAG() completa en la segunda columna, no su alias. Utilizar el alias de la primera columna LAG() provocaría un error.LAG() completas dentro de la declaración SELECT.LAG(), como todas las funciones de ventana, puede ser costosa computacionalmente con grandes conjuntos de datos. Por lo tanto, ignorar la indexación de las columnas utilizadas en las cláusulas PARTITION BY y ORDER BY puede dar lugar a un rendimiento deficiente.PARTITION BY y ORDER BY están indexadas, si es posible, para mejorar el rendimiento de la consulta.LAG() y otras funciones de ventana pueden quedar desordenadas y no ser fáciles de leer o entender, sobre todo cuando se utiliza más de una función.LAG() y otras funciones de ventana, asegúrate de añadir comentarios y documentar lo que intenta conseguir la consulta. Esto ayuda a los demás y a ti mismo a comprender la finalidad y la lógica del uso de LAG(), siempre que se vuelva a realizar la consulta.En este tutorial, hemos visto qué es la función LAG() y cómo puede ser una potente herramienta para realizar análisis de series temporales. Además, exploramos sus argumentos y las cláusulas relacionadas con él. La próxima vez que trabajes con datos relacionados con el tiempo, o con cualquier dato secuenciado, en SQL, considera el uso de la función LAG() y lo que te permite hacer. En otros contextos, la función LAG() es útil para encontrar autocorrelaciones, suavizar datos o comprobar si hay intervalos irregulares como parte de la limpieza de datos.
Si te intriga lo que puede hacer una función de ventana, puedes aprender sobre toda la familia y subir de nivel tus habilidades de análisis en SQL con nuestro completo curso interactivo PostgreSQL Estadísticas de Resumen y Funciones de Ventana . Y si te ha gustado este artículo, ¡probablemente disfrutarás recorriendo la Trayectoria Profesional de Analista de Datos Asociado en SQL y obteniendo al final la Certificación de Asociado en SQL!
Aprende SQL con DataCamp
Curso
Curso
Curso
Tutorial
Travis Tang
Tutorial
Travis Tang
Tutorial
Travis Tang
Tutorial
Allan Ouko
Tutorial
Eugenia Anello
Tutorial
Travis Tang